使用 Ollama、LangChain、LangGraph (无 GPU,无 APIKEY)

简介
你好,我是悦创。
提示工程(Prompt Engineering)是设计和优化提示(文本输入)以提升大型语言模型(LLMs)表现的实践。其目标是通过精心设计指令,使模型输出期望的答案。最常用的提示技术包括:
- 思维链(Chain-of-Thought):通过生成逐步的推理过程来得出结论。模型被引导“开口思考”,明确展示通向最终答案的逻辑步骤。
- ReAct(Reason+Act):将推理与行动相结合。模型不仅对问题进行思考,还会基于推理采取相应的行动,从而实现更交互的过程——在推理步骤与行动之间交替迭代。基本上,这是一个“思考”、“行动”、“观察”的循环。
举个例子:假设让 AI “寻找 1000 美元以下的最佳笔记本电脑”。
- 普通回答: “联想 Thinkpad”。
- 思维链回答: “我需要考虑性能、电池续航和做工等因素。接着,我会查看哪些笔记本电脑的价格低于 1000 美元。根据我的知识库,联想 Thinkpad 是最佳选择”。
- ReAct 回答: 与思维链回答相同,再加上执行网络搜索“2024 年 1000 美元以下最佳笔记本电脑”并分析结果的动作(结果可能不会是“联想 Thinkpad”)。
代理(Agent)是基于 ReAct 技术创建的,因此与传统 LLM 的主要区别在于其 具备采取行动的能力。代理是一种能够处理连续推理并在 LLM 通用知识不足时执行外部工具(例如数据库查询、网络搜索)的 AI 系统。简单来说,当普通聊天机器人在不知道如何回答问题时会生成随机文本,而代理会激活其工具来填补信息空缺,给出更具体的答案。
在本教程中,我将从零开始构建一个多代理系统,并引入“人工参与”(Human-in-the-Loop)的概念。我会展示一些有用的 Python 代码,这些代码可以轻松应用于其他类似场景(复制、粘贴、运行即可),并逐行讲解代码,帮助你复现这一示例(完整代码见下方链接)。
https://github.com/AndersonHJB/BornforthisData
具体来说,我将涵盖以下内容:
- 环境与 LLM 的搭建
- 使用 LangChain 构建工具
- 使用 Ollama 进行决策
- 使用 Pydantic 构建代理结构
- 使用 LangGraph 构建图形工作流
- 多代理协作与人工参与
环境搭建
目前市场上有两个主要的 LLM 及代理库,它们正试图成为主流框架:
- LangChain —— 非常适合构建需要复杂交互和工作流的大规模 LLM 应用。它提供了一整套工具,专注于构建复杂工作流。其基于“组件链”理念,允许不同处理步骤,每个步骤都可涉及不同的 LLM。此外,LangChain 还为复杂的多代理系统提供了专门的模块: LangGraph
- LLamaIndex —— 适用于那些更侧重搜索和检索能力的应用,尤其是针对大数据集。它侧重于摄取、结构化以及访问特定领域的数据,从而优化 LLM 对数据的消费。其设计目标是高速且精准的数据检索,适合需要快速访问大量数据的应用。同时,LlamaIndex 也提供了自己的代理模块: Llama-Agents
我将采用前者,因为它更灵活。通过安装 LangChain(pip install langchain)你可以使用所有 模块。
- langchain: 包含链、代理以及检索策略的主包
- langchain-core: 包含 langchain 使用的基本抽象(如 LLM、向量存储、检索器)
- langchain-community: 由社区维护的第三方集成
- langchain-experimental: 包含较为“危险”的内容(例如允许代理执行代码的工具)
- 合作包如 langchain-openai、langchain-anthropic
- 部署工具如 LangServe 和 LangSmith
另外,我还会安装 LangGraph(pip install langgraph)来构建基于节点—边工作流的代理。

我将使用 Ollama 在本地运行 LLM(pip install ollama),并选择 Meta 的 Llama 3.1,因为这是在无 GPU 条件下可运行的最智能 LLM。

正如预期,LLM 的知识仅限于其最近一次训练的日期。请注意,与 LLM 聊天机器人的交互包含以下 3 种角色:
- “role”:“system” —— 用于向模型传递如何进行对话的核心指令
- “role”:“user” —— 用于传递用户提问
- “role”:“assistant” —— 模型的回复
工具
最常见的工具之一是 搜索互联网 的能力。在 Python 中,最简单的实现方式是使用著名的私有浏览器 DuckDuckGo(pip install duckduckgo-search)。
由于我使用的是 Ollama,创建工具有两种方式。第一种方式是使用 LangChain 提供的标准装饰器(这是最常用的方法)。

第二种方式是创建一个普通函数,并通过 Semantic Router(pip install semantic-router)将其转换为 Ollama 模式下的 schema,这个库简化了工具的制作过程。

在众多工具中,我们还将包含 最终答案 工具:在每次用户提问后,代理必须决定是使用工具还是直接给出最终答案。请注意,描述答案结构越具体,效果越好。
决策过程
我们需要进行一些 提示工程 来定义代理需要执行的操作和方式。
使用 Ollama,我们可以立刻测试代理的决策过程。我们需要告知代理哪些工具可供使用。

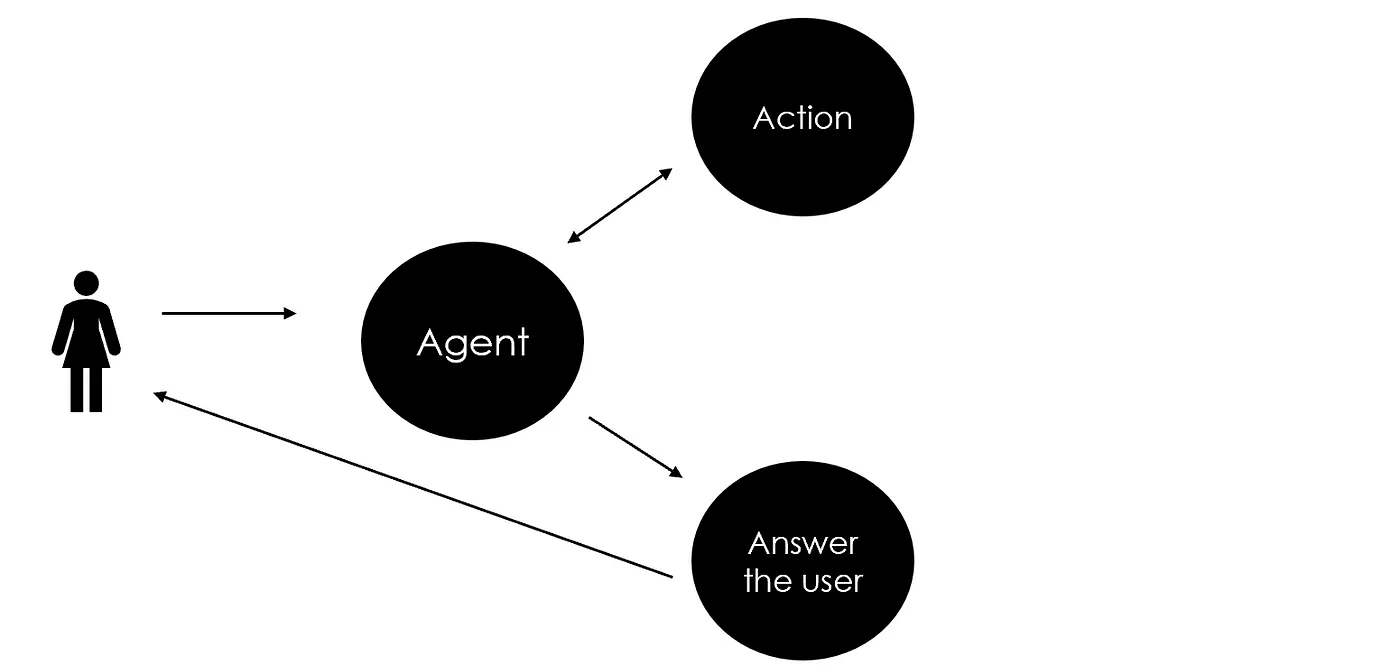
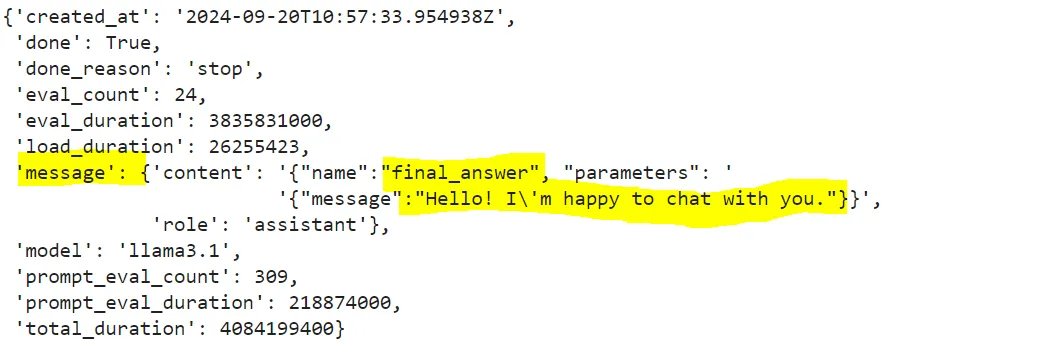
提示、工具和 LLM 共同构成了代理的核心。此时,如果我没有提出具体问题,AI 应该直接使用 final_answer 工具给出回答。
相反,当我提出具体问题时,代理应使用网络搜索工具,并基于我的请求生成查询输入。

我们可以测试代理如何处理查询结果,将其作为上下文传递给 LLM。

可以看到,核心模型运作正常。但有时 LLM 会生成错误或不一致的信息(所谓“幻觉”),因此通常需要指定模型必须遵循的数据结构。
代理结构
通常,LLM 通过 API 调用工作,因此输入与输出都必须遵循特定的 数据结构。在 Python 中,最常用的数据验证库是 Pydantic,它能确保程序使用的信息格式正确且数值符合预期。
基本上,目标是将 LLM 的响应(不稳定的)转换成结构化且经过验证的代理响应对象。

首先,你需要创建一个类来描述你所期望的数据,包括数据类型和必须遵循的规则。Pydantic 会检查数据是否正确,如果不正确,会提供明确的错误信息。这对于应对 LLM 每次运行时响应的变化非常有用。
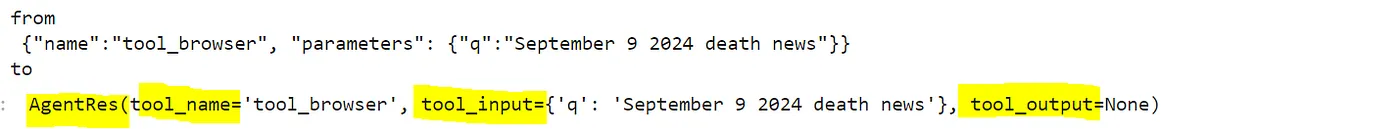
工具输出可以这样添加:

模型已经能够判断何时使用工具,但我们可以通过加入 记忆系统 让它变得更智能。记忆系统会包含聊天历史中与用户问题相关的信息以及原始请求的提醒。
对于聊天历史,我还会添加一段模拟对话,以确保代理理解我的意图。
现在,我们可以将所有内容组合起来 创建代理。
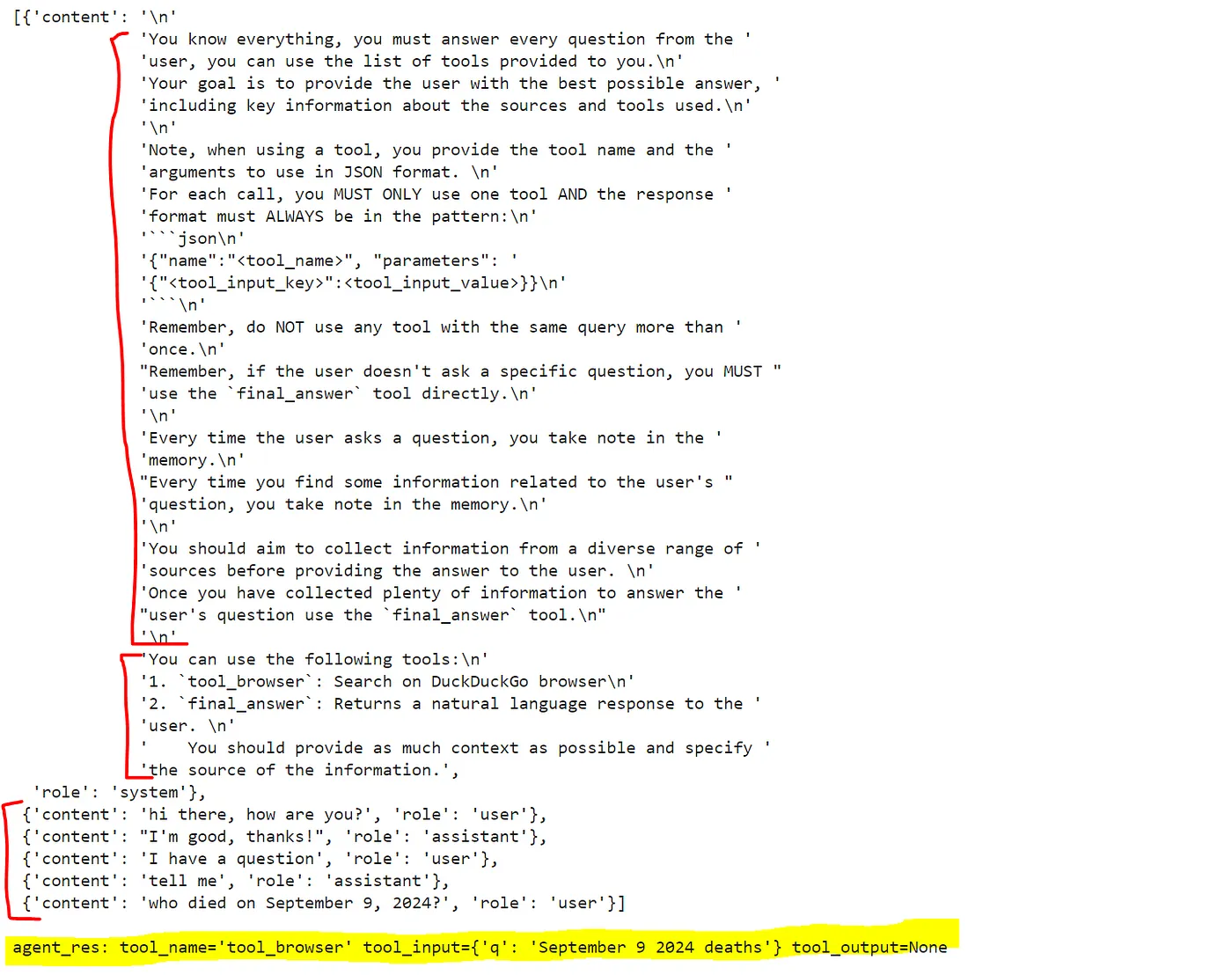
如你所见,我们的代理已通过 prompt、可用工具以及聊天历史启动。
图形工作流
LangGraph 是一个编排框架,它能让你对代理工作流有更精细的控制。其中一个关键概念是 状态:每次执行都会创建一个字典,该字典在图的各节点间传递,并在每次节点执行时更新其输出。
我们使用 Typing 定义初始状态,这是一个处理数据类型的 Python 库。

对于每个节点(代理和工具)以及每条边(动作),我们需要编写一个函数来定义模型的行为。让我们从 代理节点 开始(目前只有一个):
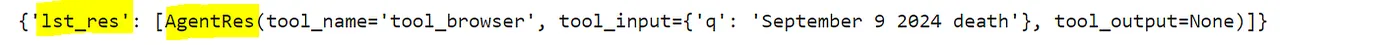
接下来,我们为 工具节点 编写类似的函数:
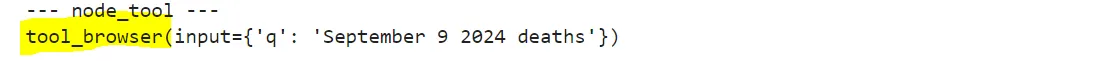
这里有两种边类型:
- 条件边 —— 调用函数判断下一步应转向哪个节点(例如,从代理节点判断是否使用工具)
- 普通边 —— 直接从一个节点传递到下一个节点(例如,从工具节点的输出返回给代理节点)

最后,我们可以创建工作流并可视化图形。
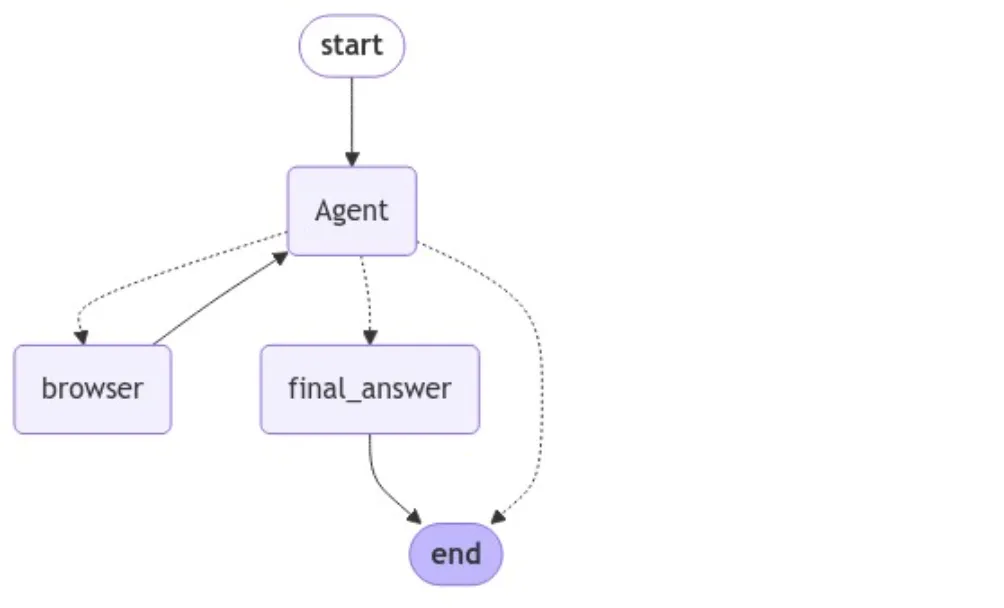
启动工作流时,必须传入初始状态。你可以通过两种方式 运行代理:

以上便是热身阶段。现在,真正的游戏开始了。
多代理与人工参与
单一代理通常能通过使用工具有效运作,但在同时处理多个工具时可能效果不佳。解决复杂任务的一种方法是采用“分而治之”策略:为每个任务创建专门的代理,从而实现 多代理工作流。
此外,实际工作流往往需要人工反馈。人工参与(Human-in-the-Loop)指的是在决策过程中,人类操作员与 AI 系统共同参与,充当类似其他工具的角色(常被称为“人工工具”)。这种方法结合了 AI 的速度与效率以及人类直觉和对复杂语境的理解能力。
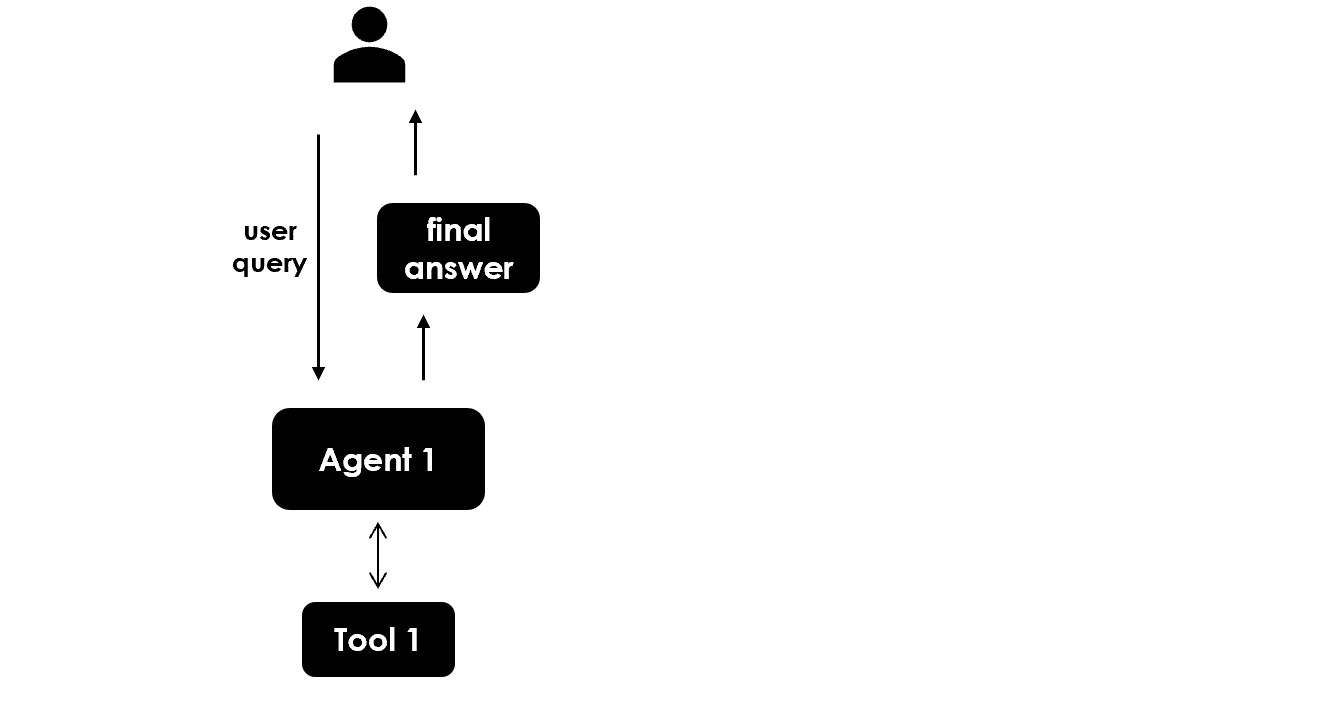
本工作流如下:
- 用户提问后,第一代理使用其工具给出最终答案(即前面所实现的过程)。
- 在给出最终答案后,系统询问用户返回的信息是否足够(人工参与)。
- 如果不足,第二代理激活,使用其工具进一步丰富最终答案(多代理协作)。
第二个代理将引入一个新工具:Wikipedia。

与之前类似,新代理节点需要一个函数来运行,其中指定了新的提示和工具。
关于 人工参与,我们需要创建一个“虚拟”节点以及处理用户反馈的逻辑。

最后,我们构建 新图形工作流。
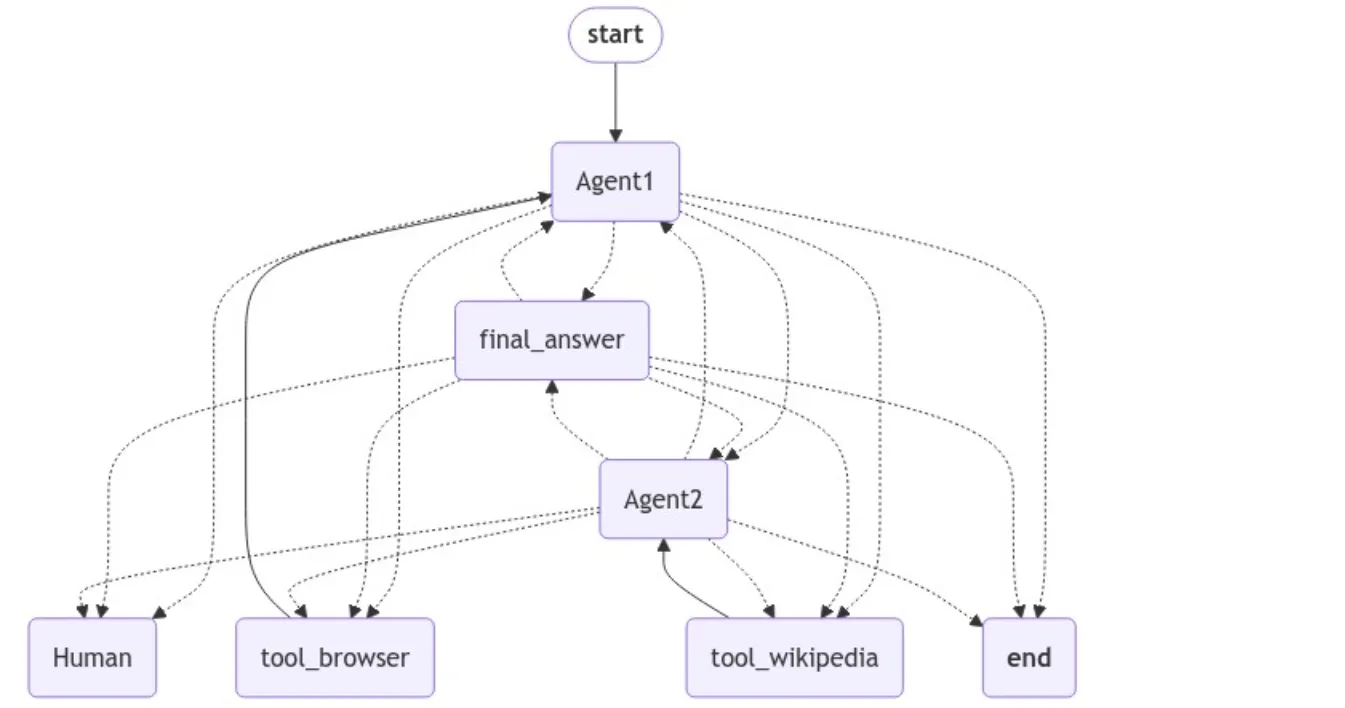
如常,你可以通过传入初始状态来运行工作流。

结论
本文是一篇教程,演示了 如何从零开始构建代理。利用 LangChain 和 Ollama,我们创建了工具和代理,接着使用 LangGraph 定义了工作流逻辑,最终构建了一个结合人工反馈的多代理系统。
总之,生成式 AI 社区正迅速发展,诸如 LangChain 和 LlamaIndex 等库也在不断变化。这主要归因于当前 LLM 领域尚无市场领导者,从而使得新工具和平台不断涌现。
希望你喜欢这篇教程!如有问题、反馈或想分享你的有趣项目,请随时联系我。