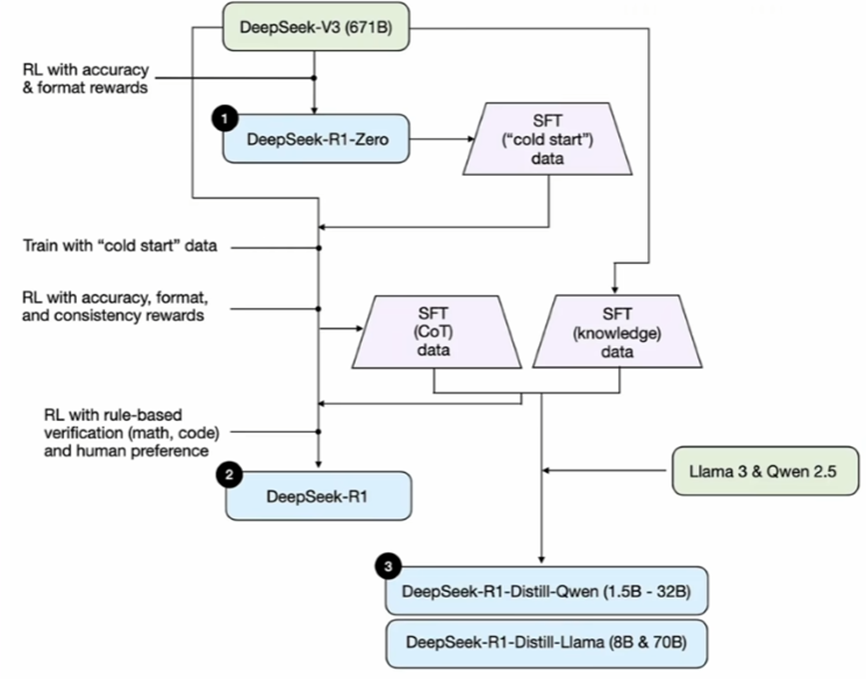
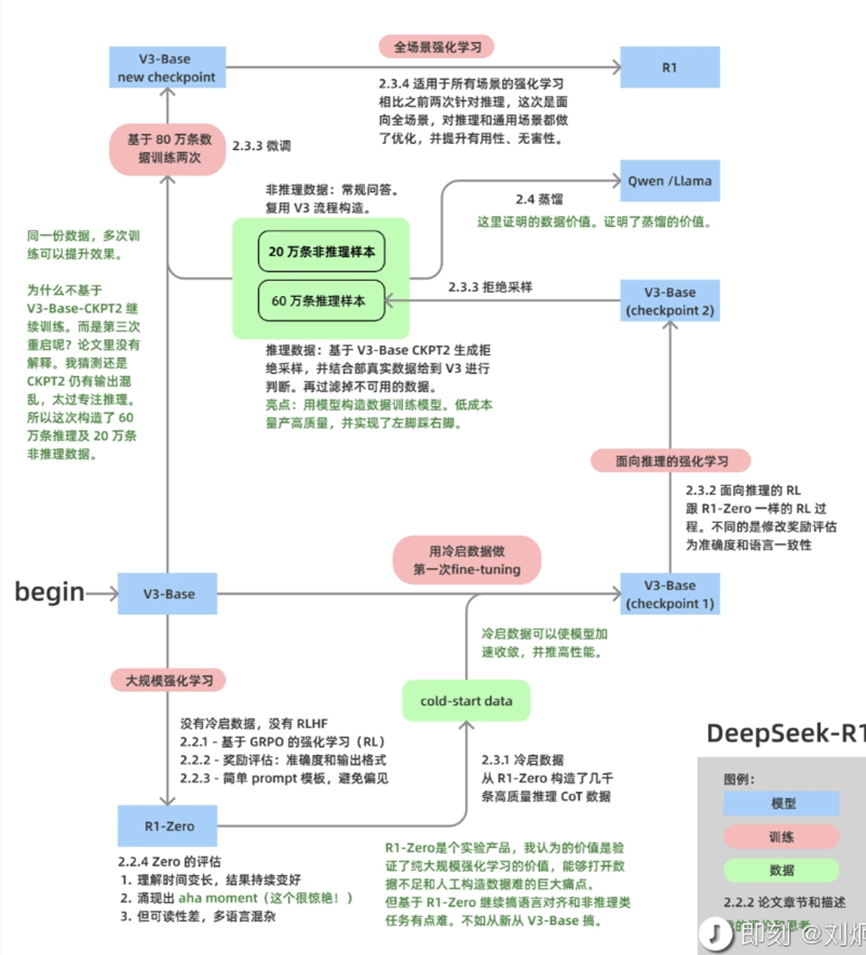
从DeepSeek-V3到DeepSeek-R1的演进分为两个阶段:R1-Zero阶段和R1阶段,具体技术路径如下:
一、从V3到R1-Zero(纯强化学习阶段)
目标:不依赖任何监督微调(SFT)数据,直接通过强化学习激活推理能力。
关键技术步骤:
-
基于规则的奖励设计
- 抛弃传统神经奖励模型(RM),采用双奖励机制:
- 答案正确性奖励:根据数学/代码题答案的客观准确性计算。
- 格式正确性奖励:强制输出符合特定标签格式(如
<think>与<answer>分段)。
- 优势:避免“奖励劫持”(Reward Hacking),提升训练稳定性。
- 抛弃传统神经奖励模型(RM),采用双奖励机制:
-
GRPO算法训练
- 群体相对策略优化(GRPO):
- 对每个问题生成16组回答(Group Size=16),计算组内奖励的均值和标准差。
- 归一化奖励:将每个回答的奖励减去均值并除以标准差,生成相对优势信号。
- 优化目标:最大化策略的期望奖励,同时通过KL散度约束防止策略偏离初始模型。
- 工程优化:采用动态截断的KL散度计算(k3 KL估计),避免蒙特卡洛估计的高方差。
- 群体相对策略优化(GRPO):
-
自演化推理能力
- 模型通过高温采样生成长思维链(CoT),逐步出现自我验证和反思行为。
- 思维链长度从数百token增长至数万token(如数学题解答过程逐步细化)。
- 结果:在MATH-500等数学基准上准确率提升至71%,代码生成Elo评分达1892。
局限性:输出可读性差(如语言混杂、格式混乱),泛化能力弱于R1。
二、从R1-Zero到R1(多阶段对齐优化)
目标:提升模型稳定性、可读性及通用能力。
关键技术步骤:
-
冷启动SFT
- 使用R1-Zero生成200条高质量思维链数据(含反思与验证步骤),对V3-Base微调。
- 目的:提供初始策略,缓解纯强化学习初期的不稳定性。
-
强化学习增强推理
- 继承GRPO框架,新增语言一致性奖励:强制输出语言统一(如仅用中文或英文)。
- 采用课程学习策略:优先训练简单推理任务,逐步提升问题复杂度。
-
自动化数据生成与筛选
- 用R1-Zero生成60万条推理数据(含数学、编程、逻辑题),通过规则过滤和V3打分筛选。
- 混合20万条通用数据(非推理任务),构建混合SFT数据集。
-
拒绝采样与二次微调
- 对R1-Zero的高分输出进行拒绝采样(Rejection Sampling),保留前10%高质量结果。
- 结合通用数据对模型进行二次监督微调,提升多任务泛化能力。
-
全场景强化学习对齐
- 最终阶段采用混合奖励函数:
- 推理奖励(60%权重)+ 语言一致性奖励(20%)+ 安全性奖励(20%)。
- 优化模型对人类偏好(如无害性、信息量)的响应能力。
- 最终阶段采用混合奖励函数:
三、关键技术创新对比
| 阶段 | 核心技术 | 数据依赖 | 效果提升重点 |
|---|---|---|---|
| R1-Zero | 纯GRPO强化学习、双规则奖励 | 无人工标注 | 推理能力突破 |
| R1 | 冷启动SFT、语言一致性奖励、拒绝采样 | 自生成SFT数据 | 可读性、泛化性、安全性对齐 |
总结
- R1-Zero:通过纯强化学习从V3-Base直接激发推理能力,但存在输出质量缺陷。
- R1:以R1-Zero为起点,通过冷启动SFT→强化学习→数据生成→二次微调四步迭代,平衡推理能力与通用性,最终成为兼顾性能与实用性的模型。
- 训练成本:R1-Zero训练消耗约120万GPU小时,R1全流程成本降至557万美元(仅为GPT-4同类训练的1/30)。