1. Checkpoint Averaging
Checkpoint Averaging 是指在训练过程中保存多个模型检查点(checkpoints),并在训练结束后对这些检查点的参数取平均值,作为最终的模型参数。
为什么要用 Checkpoint Averaging?
- 训练过程中,模型的参数会不断变化,可能会在某些时间段达到局部最优。
- 通过取多个检查点的平均值,可以平滑训练过程中的波动,得到更稳定、泛化能力更强的模型。
如何实现?
- 在训练过程中定期保存模型的检查点(例如每 10,000 步保存一次)。
- 训练结束后,加载多个检查点的模型参数(如最后 5 个检查点)。
- 对这些检查点的参数取平均值,得到最终的模型。
2. ADAM Optimizer
ADAM(Adaptive Moment Estimation) 是一种常用的优化算法,结合了动量(Momentum)和自适应学习率的特点。
ADAM 的优点:
- 自适应学习率:为每个参数单独调整学习率,适合处理稀疏数据。
- 快速收敛:结合了动量方法,能够快速收敛。
- 稳定性:对学习率的选择不太敏感。
ADAM 的工作原理:
- 计算梯度的指数移动平均值(一阶矩)和梯度平方的指数移动平均值(二阶矩)。
- 使用这两个值调整每个参数的学习率。
- 更新参数。
公式:
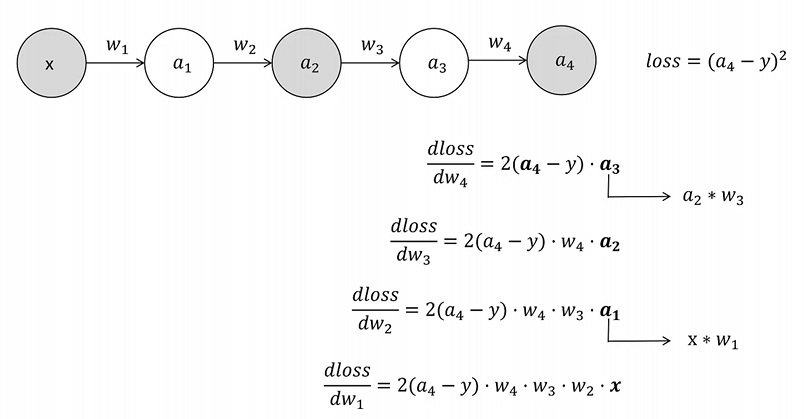
m t = β 1 m t − 1 + ( 1 − β 1 ) g t v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 θ t = θ t − 1 − η ⋅ m t v t + ϵ m_t = \beta_1 m_{t-1} + (1-\beta_1) g_t \\ v_t = \beta_2 v_{t-1} + (1-\beta_2) g_t^2 \\ \theta_t = \theta_{t-1} - \eta \cdot \frac{m_t}{\sqrt{v_t} + \epsilon} mt=β1mt−1+(1−β1)gtvt=β2vt−1+(1−β2)gt2θt=θt−1−η⋅vt+ϵmt
其中, m t m_t mt 是一阶矩, v t v_t vt 是二阶矩, η \eta η 是学习率, ϵ \epsilon ϵ 是一个极小值(用于数值稳定性)。
3. Dropout during Training at Every Layer Just Before Adding Residual
Dropout 是一种正则化技术,通过在训练过程中随机丢弃一定比例的神经元(设置为 0)来防止过拟合。
在 Transformer 中的应用:
- 在每个子层(如多头注意力层和前馈神经网络层)的输出上应用 Dropout。
- Dropout 的位置是在残差连接之前,即:
output = LayerNorm ( x + Dropout ( Sublayer ( x ) ) ) \text{output} = \text{LayerNorm}(x + \text{Dropout}(\text{Sublayer}(x))) output=LayerNorm(x+Dropout(Sublayer(x)))
放置位置
-
嵌入层之后
词嵌入输出的向量在进入编码器/解码器主结构前,会经过一次嵌入dropout(概率0.1)。例如将"apple"映射为[0.3, 0.5…]后,随机将其中10%的维度置零,相当于给每个词语增加了"同义词扰动"。 -
注意力计算后
每个多头注意力模块的输出会经过dropout层(参考代码中设置概率为0.1)。例如在自注意力计算过程中,QKV矩阵相乘得到注意力权重后,先进行dropout再与value向量加权求和。这相当于给注意力机制增加了随机"分心",防止模型过度依赖某些特定词语的关联。 -
前馈神经网络内部
Feed Forward层的两个线性变换之间加入了dropout。具体结构是:
输入 → 线性层(512→2048) → ReLU → dropout → 线性层(2048→512)
这种设计让前馈网络在特征变换时随机丢失部分神经元,增强泛化能力。实验显示将该处dropout从0.1提升到0.3时,验证集BLEU下降了1.2,说明需要谨慎设置。
为什么在残差连接之前?
- Dropout 会引入噪声,如果在残差连接之后应用 Dropout,可能会破坏输入的原始信息。
- 在残差连接之前应用 Dropout,可以确保残差连接传递的是未受干扰的信息。
4. Label Smoothing
Label Smoothing 是一种正则化技术,通过软化真实标签(ground truth labels)来防止模型过于自信。
为什么要用 Label Smoothing?
- 标准的交叉熵损失会鼓励模型对正确标签的输出概率接近 1,这可能导致模型过拟合。
- Label Smoothing 通过给非正确标签分配一个小概率,来缓解这个问题。
公式:

其中, ϵ \epsilon ϵ 是平滑系数(通常设为 0.1), K K K 是类别数。


优点:
- 提高模型的泛化能力。
- 防止模型过于自信。
5. Auto-regressive Decoding with Beam Search and Length Penalties
在训练和推理阶段,Transformer 使用 自回归解码(Auto-regressive Decoding) 和 Beam Search 来生成序列。
自回归解码:
- 模型逐个生成 token,每个生成的 token 都会作为下一个 step 的输入。
- 例如,生成句子时,模型依次生成每个词。
Beam Search:
- Beam Search 是一种启发式搜索算法,通过维护一个固定大小的候选集(beam width)来生成序列。
- 在每一步,模型会保留概率最高的 k k k 个候选序列,而不是只保留概率最高的一个。
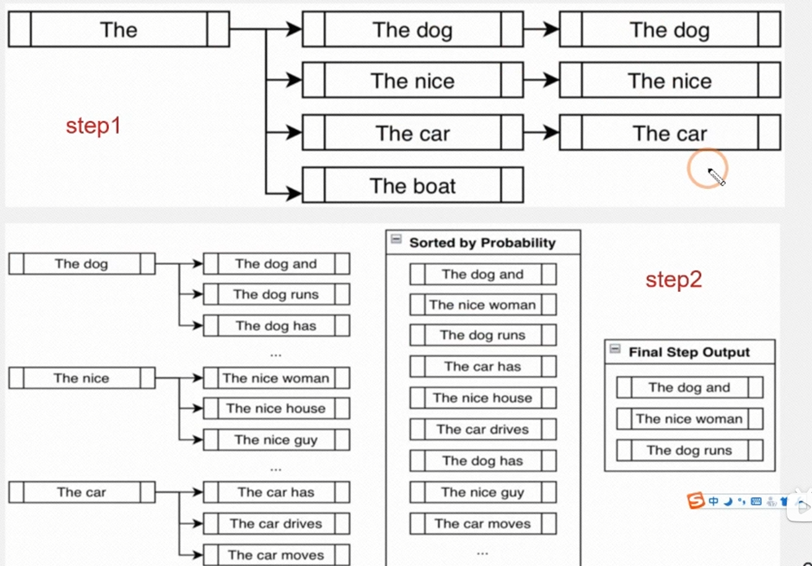
结合代码实现:
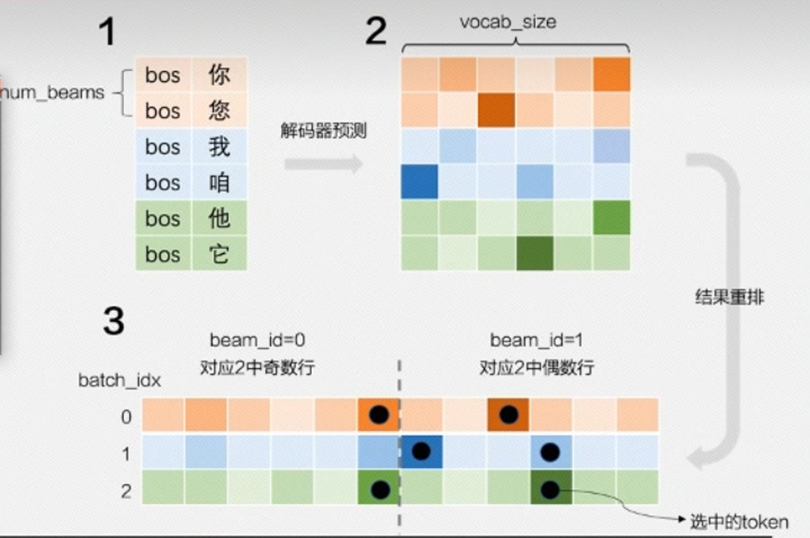
Length Penalties:
- Beam Search 倾向于生成较短的序列,因为较短的序列通常有更高的概率。
- 为了解决这个问题,引入了 长度惩罚(Length Penalties):
score = log P ( y ∣ x ) length α \text{score} = \frac{\log P(y|x)}{\text{length}^\alpha} score=lengthαlogP(y∣x)
其中, α \alpha α 是惩罚因子(通常设为 0.6 到 1.0)。
优点:
- Beam Search 可以在生成序列时平衡质量和多样性。
- 长度惩罚可以避免生成过短的序列。
总结
- Checkpoint Averaging:通过取多个检查点的平均值,提升模型的稳定性和泛化能力。
- ADAM Optimizer:自适应优化算法,适合 Transformer 的强大计算需求。
- Dropout:在残差连接之前应用,防止过拟合。
- Label Smoothing:软化真实标签,防止模型过于自信。
- Auto-regressive Decoding with Beam Search and Length Penalties:生成高质量序列的启发式搜索方法。
6. Warmup 策略
Warmup 策略 是一种优化学习率调度的技术,旨在帮助模型在训练初期更稳定地收敛。它的核心思想是:在训练开始时,逐步增加学习率,而不是直接使用较大的学习率。
为什么要用 Warmup 策略?
-
稳定训练初期:
- 在训练初期,模型的参数是随机初始化的,梯度可能较大。
- 如果直接使用较大的学习率,可能会导致参数更新不稳定,甚至训练失败。
-
避免过拟合:
- 在训练初期,模型尚未学习到有效的特征。
- 使用较小的学习率可以避免模型过早地拟合噪声数据。
-
更好地收敛:
- 逐步增加学习率,可以让模型在初期更平滑地更新参数,找到更好的优化方向。
- 逐步增加学习率,可以让模型在初期更平滑地更新参数,找到更好的优化方向。
Warmup 策略的工作原理
Warmup 策略通常与 学习率调度器(Learning Rate Scheduler) 结合使用。具体步骤如下:
-
设定 Warmup 步数:
- 在训练的前 N N N步(称为 Warmup 阶段),学习率从 0 逐步增加到初始学习率。
- 例如,Warmup 步数可能设置为 4000 步。
-
线性增加学习率:
- 在 Warmup 阶段,学习率按线性增长:
learning rate = initial learning rate × current step warmup steps \text{learning rate} = \text{initial learning rate} \times \frac{\text{current step}}{\text{warmup steps}} learning rate=initial learning rate×warmup stepscurrent step
- 在 Warmup 阶段,学习率按线性增长:
-
正常训练阶段:
- 在 Warmup 阶段结束后,学习率按预设的调度策略(如指数衰减或余弦衰减)进行调整。
Warmup 策略的公式
假设:
- 初始学习率为 lr init \text{lr}_{\text{init}} lrinit
- Warmup 步数为 warmup_steps \text{warmup\_steps} warmup_steps
- 当前训练步数为 t t t
在 Warmup 阶段,学习率 lr t \text{lr}_t lrt的计算公式为:
lr t = lr init × t warmup_steps \text{lr}_t = \text{lr}_{\text{init}} \times \frac{t}{\text{warmup\_steps}} lrt=lrinit×warmup_stepst
在 Warmup 阶段结束后,学习率按正常调度策略调整。
Warmup 策略的优点
-
稳定训练:
- 避免训练初期的梯度爆炸或不稳定现象。
-
更好的收敛:
- 通过逐步增加学习率,模型更容易找到全局最优解。
-
防止过拟合:
- 在训练初期使用较小的学习率,避免模型过早拟合噪声数据。
Warmup 策略在 Transformer 中的应用
在 Transformer 的训练中,Warmup 策略通常与 Adam 优化器 和 学习率调度器 结合使用。例如:
- 前 4000 步为 Warmup 阶段,学习率从 0 线性增加到 1 0 − 4 10^{-4} 10−4。
- Warmup 阶段结束后,学习率按余弦衰减或指数衰减调整。
Scheduled Sampling
背景:在机器翻译任务中,模型在训练时通常使用“教师强制”(Teacher Forcing)方法,即使用真实的目标序列作为输入来预测下一个词。然而,在推理阶段,模型只能依赖自己生成的序列作为输入,这可能导致错误累积,因为模型从未在训练时见过自己生成的错误序列。Scheduled Sampling 是一种用于训练序列生成模型(如Transformer)的技术,旨在缓解训练和推理阶段之间的“暴露偏差”(Exposure Bias)问题。
Scheduled Sampling 是一种用于训练序列生成模型(如Transformer)的技术,旨在缓解训练和推理阶段之间的“暴露偏差”(Exposure Bias)问题。在机器翻译任务中,模型在训练时通常使用“教师强制”(Teacher Forcing)方法,即使用真实的目标序列作为输入来预测下一个词。然而,在推理阶段,模型只能依赖自己生成的序列作为输入,这可能导致错误累积,因为模型从未在训练时见过自己生成的错误序列。
Scheduled Sampling 的核心思想
Scheduled Sampling 通过在训练过程中逐步引入模型自身生成的词作为输入,从而让模型逐渐适应推理阶段的行为。具体来说,它通过一个调度策略,动态地决定在训练时是使用真实的目标词(来自真实序列)还是使用模型预测的词作为输入。
实现步骤
-
训练初期:在训练开始时,模型主要使用真实的目标词作为输入(即完全依赖教师强制),因为此时模型的预测能力较弱,直接使用自身生成的词可能导致训练不稳定。
-
训练中期:随着训练的进行,逐步增加使用模型自身生成的词的概率。这可以通过一个调度函数来控制,例如线性衰减、指数衰减或其他自定义策略。
-
训练后期:在训练接近尾声时,模型主要依赖自身生成的词作为输入,从而更好地模拟推理阶段的行为。
调度策略
调度策略决定了在训练过程中如何调整使用真实目标词和模型生成词的概率。常见的调度策略包括:
- 线性调度:概率随时间线性减少,例如从1.0(完全使用真实词)线性减少到0.0(完全使用模型生成的词)。
- 指数调度:概率随时间指数减少,例如从1.0指数减少到0.0。
- 逆时序调度:根据训练步数的倒数来调整概率。
优点
- 缓解暴露偏差:通过让模型在训练时接触自身生成的序列,减少了训练和推理阶段的差异,从而提高了模型的鲁棒性。
- 更好的泛化能力:模型在训练时学会了如何处理自身生成的错误,从而在推理时能够更好地纠正错误。
缺点
- 训练复杂度增加:由于需要在训练时动态调整输入策略,增加了训练的复杂性和计算开销。
- 潜在的不稳定性:在训练初期,如果过早引入模型生成的词,可能导致训练不稳定或收敛困难。
Scheduled Sampling 是一种通过动态调整训练输入策略来缓解暴露偏差的技术。它通过在训练过程中逐步引入模型自身生成的词作为输入,使得模型能够更好地适应推理阶段的行为,从而提高序列生成任务的表现。
对词嵌入(embedding)进行缩放(乘以根号d)
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
# Embedding层
self.lut = nn.Embedding(vocab, d_model)
# Embedding维数
self.d_model = d_model
def forward(self, x):
# 返回x对应的embedding矩阵(需要乘以math.sqrt(d_model))
return self.lut(x) * math.sqrt(self.d_model)
代码中为什么要乘以sqrt(self.d_model):
-
梯度传播的稳定性
在神经网络中,尤其是在深层网络中,梯度的大小可能会随着层数的增加而变得不稳定(例如,梯度消失或梯度爆炸)。如果嵌入向量的值过大或过小,可能会导致梯度在传播过程中出现不稳定现象。
通过将嵌入向量乘以sqrt(d_model),可以将嵌入向量的数值范围调整到一个合适的区间,从而有助于保持梯度的稳定性。 -
初始化的一致性
权重矩阵进行初始化,例如使用Xavier(威尔)初始化或Kaiming初始化。这些初始化方法假设输入的方差在合理的范围内(例如,方差为1)。如果嵌入向量的值过小,可能会导致后续层的输入方差过小,从而影响模型的训练效果。 通过将嵌入向量乘以sqrt(d_model),可以将嵌入向量的数值范围调整到一个合适的区间,从而有助于保持梯度的稳定性。
# time: 2025/3/15 14:29
# author: YanJP
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
# 定义一个简单的随机数据集
class RandomDataset(Dataset):
def __init__(self, num_samples, seq_length, vocab_size):
self.num_samples = num_samples
self.seq_length = seq_length
self.vocab_size = vocab_size
def __len__(self):
return self.num_samples
def __getitem__(self, idx):
# 生成随机的源序列和目标序列
src = torch.randint(0, self.vocab_size, (self.seq_length,))
tgt = torch.randint(0, self.vocab_size, (self.seq_length,))
return src, tgt
# Transformer 模型
class TransformerModel(nn.Module):
def __init__(self, vocab_size, d_model, nhead, num_encoder_layers, num_decoder_layers):
super(TransformerModel, self).__init__()
self.transformer = nn.Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers)
self.embedding = nn.Embedding(vocab_size, d_model)
self.fc_out = nn.Linear(d_model, vocab_size)
self.d_model = d_model
def forward(self, src, tgt):
src = self.embedding(src) * (self.d_model ** 0.5)
tgt = self.embedding(tgt) * (self.d_model ** 0.5)
output = self.transformer(src, tgt)
return self.fc_out(output)
# Scheduled Sampling 调度函数
def scheduled_sampling_prob(epoch, max_epochs, method='linear'):
if method == 'linear':
return 1.0 - (epoch / max_epochs) # 线性衰减
elif method == 'exponential':
return 0.99 ** epoch # 指数衰减
else:
raise ValueError("Unknown scheduling method")
# 训练函数
def train(model, dataloader, criterion, optimizer, device, max_epochs):
model.train()
for epoch in range(max_epochs):
for src, tgt in dataloader:
src, tgt = src.to(device), tgt.to(device)
optimizer.zero_grad()
# 获取目标序列的长度
tgt_len = tgt.size(1)
# 初始化解码器输入(通常是 <SOS> 标记)
decoder_input = tgt[:, 0].unsqueeze(1) # 取第一个词作为初始输入
# 逐步生成目标序列
for i in range(1, tgt_len):
# 前向传播
output = model(src, tgt)
# 计算损失
loss = criterion(output[:, -1, :], tgt[:, i])
# 根据 Scheduled Sampling 决定是否使用真实词或模型生成的词
prob = scheduled_sampling_prob(epoch, max_epochs, method='linear')
use_ground_truth = torch.rand(1).item() < prob
if use_ground_truth:
# 使用真实词作为下一个输入
next_input = tgt[:, i].unsqueeze(1)
else:
# 使用模型预测的词作为下一个输入
_, predicted = torch.max(output[:, -1, :], dim=1)
next_input = predicted.unsqueeze(1)
# 将下一个输入拼接到解码器输入中
decoder_input = torch.cat([decoder_input, next_input], dim=1)
# 反向传播和优化
loss.backward()
optimizer.step()
print(f"Epoch [{
epoch+1}/{
max_epochs}], Loss: {
loss.item():.4f}")
# 主函数
if __name__ == "__main__":
# 参数设置
vocab_size = 1000 # 词汇表大小
d_model = 512 # 模型维度
nhead = 8 # 多头注意力头数
num_encoder_layers = 3 # 编码器层数
num_decoder_layers = 3 # 解码器层数
max_epochs = 10 # 最大训练轮数
batch_size = 32 # 批量大小
seq_length = 20 # 序列长度
num_samples = 1000 # 数据集样本数
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化模型、损失函数和优化器
model = TransformerModel(vocab_size, d_model, nhead, num_encoder_layers, num_decoder_layers).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 创建随机数据集和 DataLoader
dataset = RandomDataset(num_samples, seq_length, vocab_size)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 开始训练
train(model, dataloader, criterion, optimizer, device, max_epochs)
梯度检查点降低显存
梯度检查点(Gradient Checkpointing)是一种显存优化技术,其核心思想是通过选择性存储和重新计算来减少显存占用。在深度学习中,训练神经网络时需要存储前向传播的中间结果(激活值)以用于反向传播计算梯度,这些中间结果会占用大量显存,尤其是对于深层网络或大模型。梯度检查点通过以下方式节省显存:
-
选择性存储:
- 在前向传播过程中,梯度检查点只存储部分关键层的激活值,而不是所有层的激活值。
- 其他层的激活值在需要时通过重新计算得到。
-
重新计算:
- 在反向传播时,对于未存储的中间结果,梯度检查点会从最近的检查点重新运行前向传播,计算所需的激活值。
- 这种方式用额外的计算时间换取了显存的节省。
-
显存与计算时间的权衡:
- 梯度检查点通过减少显存占用,使得模型可以训练更大的批次或更深的网络,这在显存受限的场景下非常有用。
- 虽然重新计算会增加计算时间,但增加的额外时间通常是可以接受的,尤其是在显存瓶颈的情况下。
-
应用场景:
- 梯度检查点特别适用于显存需求远大于计算资源的场景,例如训练超大模型(如 GPT、BERT)或使用深层网络(如 ResNet-101、ResNet-152)。
视频
总结:梯度检查点通过在前向传播中选择性存储中间结果,并在反向传播时重新计算未存储的激活值,显著减少了显存占用。虽然这会引入额外的计算开销,但它在显存受限的情况下能够显著扩展模型的训练能力,是一种高效的“时间换空间”策略。
- 梯度检查点特别适用于显存需求远大于计算资源的场景,例如训练超大模型(如 GPT、BERT)或使用深层网络(如 ResNet-101、ResNet-152)。
梯度累积增大batch_size而不增加内存开销
gradient_accumulation_steps(梯度累积步数)的核心作用是 “模拟更大的 batch size”,尤其是在显存(GPU 内存)不足时,通过多次小 batch 的前向传播和反向传播累积梯度,最后再统一更新模型参数。这样可以达到和大 batch 训练类似的效果,同时节省显存。
例如,直接设置 batch_size=32 会导致 GPU 显存不足(OOM)。这时可以用 gradient_accumulation_steps=4,让模型:
- 连续处理 4 个小 batch(每个 batch=8),共 32 条样本。
- 累积这 4 步的梯度(不立即更新参数)。
- 累积完成后,用 平均梯度 更新一次参数。
这样等效于 batch_size=32,但显存占用和 batch_size=8 相同。
# 不使用梯度累积
for batch in dataloader:
outputs = model(batch) # 前向传播(batch_size=8)
loss = compute_loss(outputs) # 计算损失
loss.backward() # 反向传播,计算梯度
optimizer.step() # 立即用梯度更新参数
optimizer.zero_grad() # 清空梯度
# 使用梯度累积
optimizer.zero_grad() # 初始清空梯度
for step, batch in enumerate(dataloader):
outputs = model(batch) # 前向传播(batch_size=8)
loss = compute_loss(outputs) # 计算损失
loss.backward() # 反向传播,梯度累积到 .grad 中
# 每累积 4 步才更新一次参数
if (step + 1) % 4 == 0:
optimizer.step() # 用累积的梯度更新参数
optimizer.zero_grad() # 清空梯度,准备下一轮累积
参考链接:知乎
归一化方式
Layer Norm
Transformer 中的 Layer Norm 比较特殊,针对单个 token 的所有 features 做标准化(下图右三),并不是对单个样本内所有 tokens、所有 features 一起做标准化。所以和句子长度和 batch 大小无关

Layer Normalization的平移不变性 和 缩放不变性 共同保证了 Layer Normalization 对输入数据的绝对数值和尺度不敏感,只关注数据的分布形状,从而提高了模型的鲁棒性和训练效率。。
RMS Norm
layer normalization 重要的两个部分是平移不变性和缩放不变性。 Root Mean Square Layer Normalization 认为 layer normalization 取得成功重要的是缩放不变性,而不是平移不变性。因此,去除了计算过程中的平移,只保留了缩放,进行了简化,提出了RMS Norm(Root Mean Square Layer Normalization),即均方根 norm。计算过程如下:
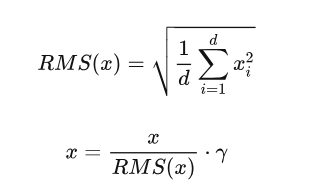
相比于普通的 Layer Norm,RMS norm 避免了计算均值,因此训练速度更快。并且效果基本相当,甚至略有提升。Gopher、LLaMA、Chinchilla、T5 等 LLM 都采用了 RMS norm。
激活函数
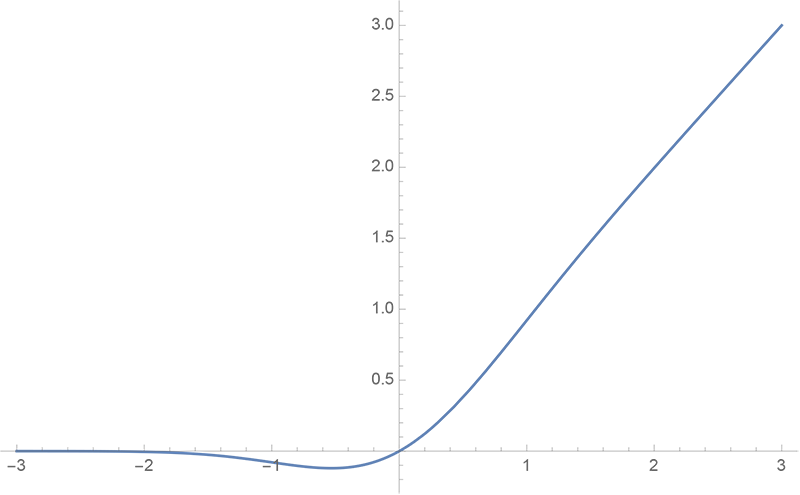
GeLU
GeLU,全称为 Gaussian Error Linear Unit,它在激活函数中引入了随机正则的思想。
GPT-3,BLOOM 采用的激活函数就是 GeLU。

门控线形单元GLU
利用门控线形单元 —— GLU(Gated Linear Units)对激活函数进行改进。

位置编码
绝对位置编码
可以继续分为正弦编码和可训练编码。
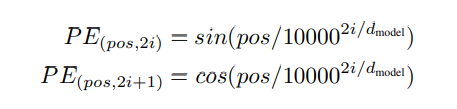
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term) ## 这里需要注意的是pe[:, 0::2]这个用法,就是从0开始到最后面,补长为2,其实代表的就是偶数位置
pe[:, 1::2] = torch.cos(position * div_term)

可训练编码设置一个可训练的位置编码矩阵。它的缺点是没有外推性:如果训练时最大序列长度为 2048(矩阵第一个维度为 2048),那么在推断时最多只能处理长度为 2048 的序列,因为模型不知道超过这个长度该怎么编码。
相对位置编码
相对位置编码直接建模元素之间的相对距离,从而更好地捕捉序列中的局部和全局依赖关系。

可以看到相对位置编码引入了额外的偏置项和位置信息,通过这种方式捕捉到序列中的长距离依赖关系。
旋转位置编码
RoPE 渐渐成为位置编码的主流选择,被 LLaMA-1、GLM、PaLM、LLaMA-2 等 LLM 采用。
CSDN
| 位置编码方式 | 特点 | 典型应用场景 | 代表模型 |
|---|---|---|---|
| 正弦余弦编码 | 固定编码,平移不变性 | 长序列任务(如BERT、GPT) | Transformer |
| 可学习绝对位置编码 | 灵活,适应任务需求 | 短序列任务(如机器翻译) | BERT, GPT |
| Transformer-XL 相对编码 | 建模长程依赖,适合超长序列 | 超长序列(如Transformer-XL) | Transformer-XL |
| T5 相对位置编码 | 简化计算,适合大规模预训练 | 大规模预训练(如T5) | T5 |
| RoPE | 旋转矩阵,保持向量模长 | 长序列任务(如LLaMA) | LLaMA |
| 分段位置编码 | 多段落任务 | 文本摘要、问答 | BERT |
| 自适应位置编码 | 动态生成,灵活 | 生成任务(如GPT-3) | GPT-3 |
| 无位置编码 | 简化模型结构 | 某些变体(如ByT5) | ByT5 |