前言
之所以关注到Qwen多模态大模型,是因为去年我司在实现提问VLM时(今年过年之前便已嵌入在七月在线官网教育层面的每一个视频中),当时面临两个模型的选择,一个是GPT4o,一个便是Qwen2-vl-72b
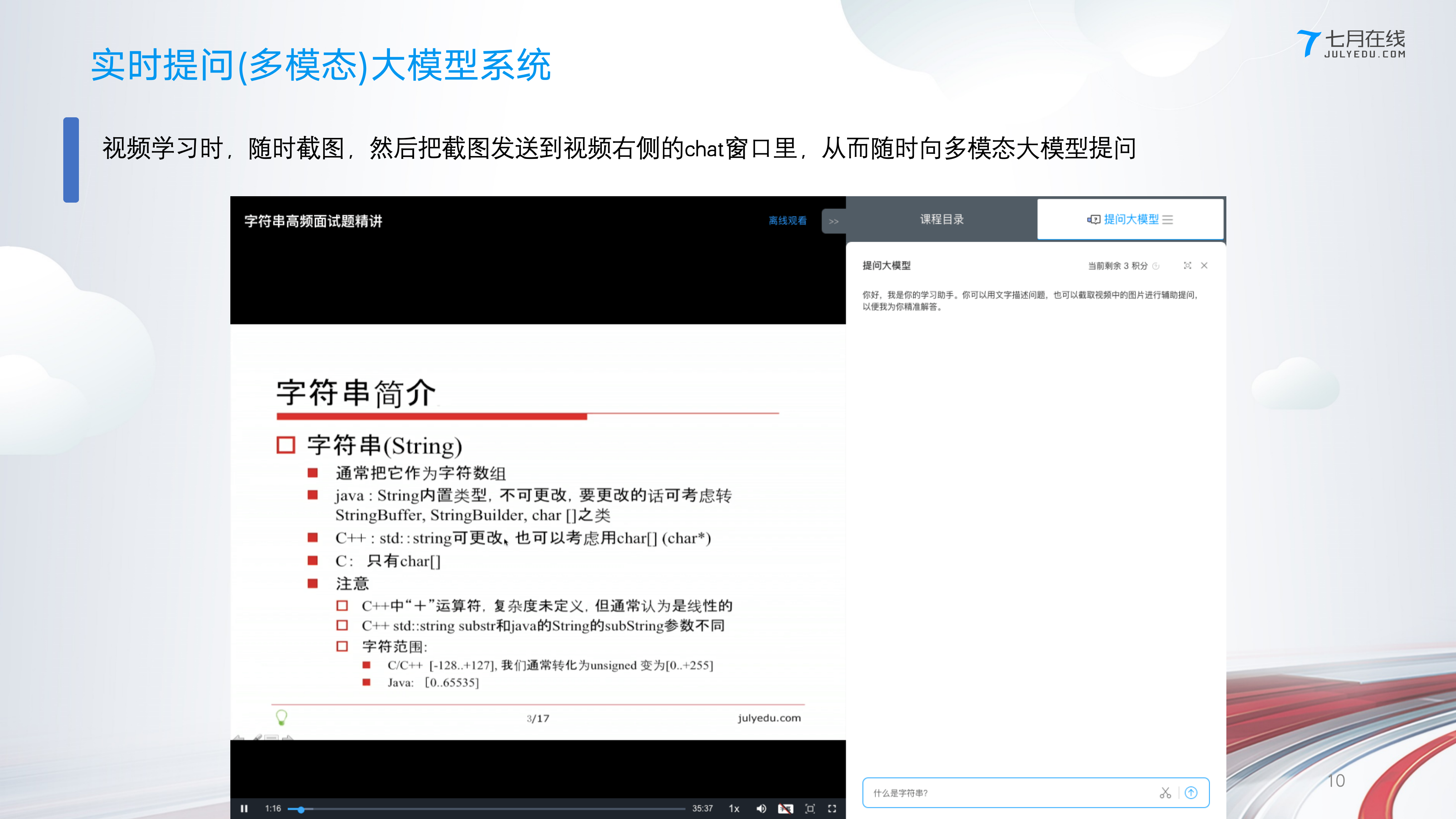
最终因为后者的性价比更高,便选择了Qwen2-vl-72b
此外,也不用对deepseek之外的模型抱有偏见,虽然可能没有那么轰动的创新,但其他模型比如Qwen系列还是一直创新不断的
第一部分 Qwen-VL:多功能的视觉语言模型
23年10月份,阿里通义千问团队发布了两款多模态大模型
- Qwen-VL,是经过多任务训练后的模型
能够感知和理解视觉输入,根据给定的提示生成所需的响应,并完成各种视觉语言任务,如图像描述、问答、文本导向的问答和视觉定位
且支持中文、英文等多种语言,以及允许任意交错的图文数据作为Qwen-VL的输入 - Qwen-VL-Chat,是经过监督微调(SFT)阶段后的模型
即基于Qwen-VL的指令调优视觉语言聊天机器人
1.1 模型架构
Qwen-VL 的整体网络架构由三个组件组成「相关的模型参数为Vision Encoder 1.9B,VL Adapter 0.08B,LLM 7.7B,全部加起来总计9.6B」
1.1.1 大型语言模型:Qwen-7B的简介
Qwen-VL 采用大型语言模型作为其基础组件,该模型使用 Qwen-7B(Qwen,2023) 的预训练权重进行初始化
// 待更
1.1.2 视觉编码器
Qwen-VL 的视觉编码器使用 Vision Transformer (ViT)(Dosovitskiy 等人,2021)架构,初始化时采用了 Openclip 的 ViT-bigG(Ilharco 等人,2021)的预训练权重
在训练和推理过程中,输入图像会被调整为特定分辨率。视觉编码器通过以 14 的步幅将图像分割为多个patch来处理图像,从而生成一组图像特征
1.1.3 位置感知视觉-语言适配器,即Position-aware Vision-Language Adapter
为了缓解长图像特征序列带来的效率问题,Qwen-VL 引入了一种视觉-语言适配器,用于压缩图像特征
该适配器由一个随机初始化的单层交叉注意力模块组成。该模块使用一组可训练向量(嵌入)作为查询向量,并使用来自视觉编码器的图像特征作为交叉注意力操作的键。此机制将视觉特征序列压缩为固定长度256。关于查询数量的消融实验见附录E.2
此外,为了对细粒度图像进行更好的理解,2D绝对位置编码被引入到交叉注意力机制的查询-键对中,以减轻压缩过程中可能导致的位置细节丢失。长度为256的压缩图像特征序列随后被输入到大型语言模型中
最终,在模型的输入输出上
- 图像输入
图像通过视觉编码器和适配器进行处理,产生固定长度的图像特征序列
为了区分图像特征输入和文本特征输入,在图像特征序列的开头和结尾分别附加两个特殊token(<img> 和</img>),表示图像内容的开始和结束 - 边界框输入和输出
为了增强模型对细粒度视觉理解和定位的能力,Qwen-VL 的训练涉及区域描述、问题和检测形式的数据
不同于涉及图像-文本描述或问题的常规任务,此任务要求模型准确理解并生成指定格式的区域描述。对于任何给定的边界框,应用一个归一化过程(范围在[0, 1000) 内)并转换为指定的字符串格式:” (Xtopleft , Ytopleft ) , (Xbottom right , Ybottom right ) ”
字符串被tokenized为文本,不需要额外的位置词汇。为了区分检测字符串和常规文本字符串,在边界框字符串的开头和结尾添加了两个特殊token(< box >和< /box >
此外,为了适当地将边界框与其对应的描述性词语或句子关联起来,引入了另一组特殊token(<ref> 和</ref>),以标记边界框所指的内容
1.2 训练:预训练、多任务预训练、监督微调
如下图图3所示,Qwen-VL模型的训练过程分为三个阶段:两个阶段的预训练和最后一个阶段的指令微调训练
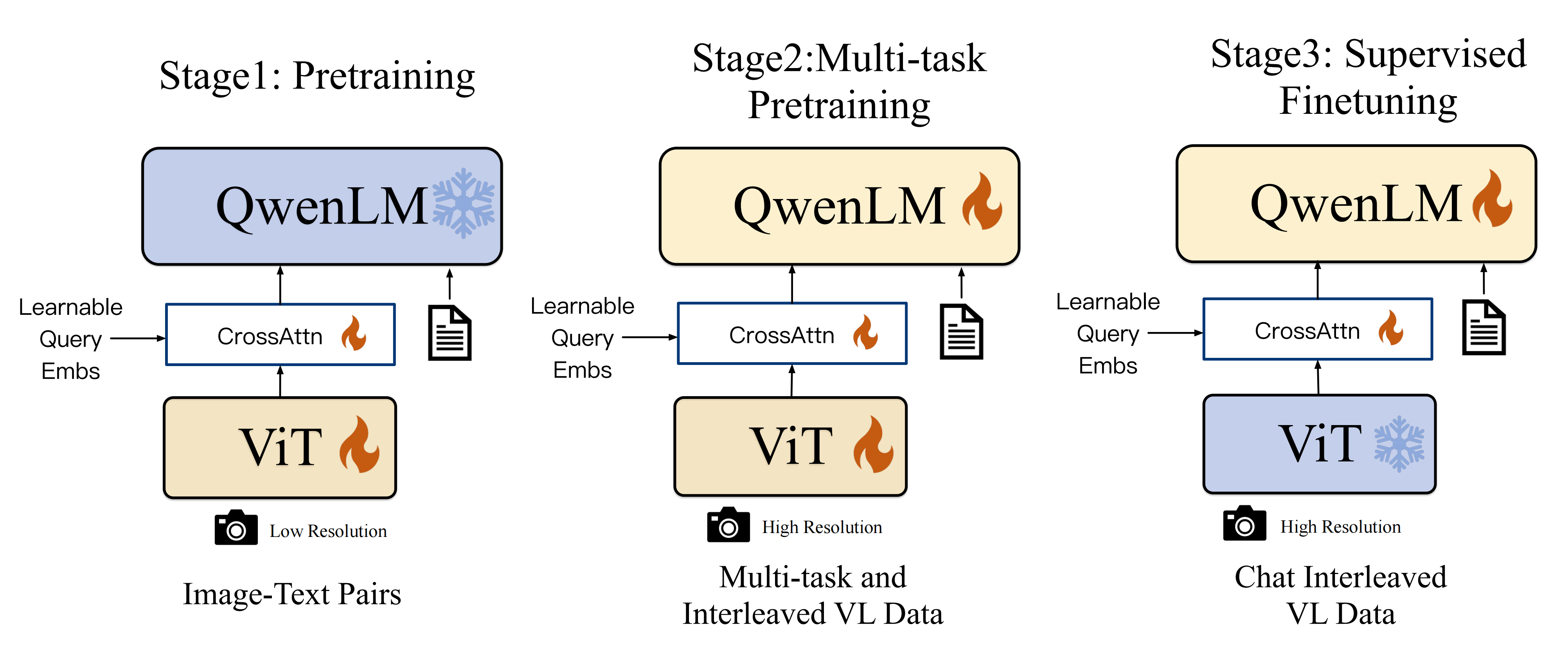
1.2.1 预训练
在预训练的第一阶段,他们主要利用一个大规模、弱labeled的网络抓取图文对集合,其预训练数据集由几个公开可访问的来源和一些内部数据组成。且努力清理数据集中的某些模式
如下表表2-Qwen-VL预训练数据的详细信息 所示,原始数据集包含总共50 亿个图文对,清理后剩余14 亿数据,其中77.3 % 是英文(文本)数据,22.7 % 是中文(文本)数据
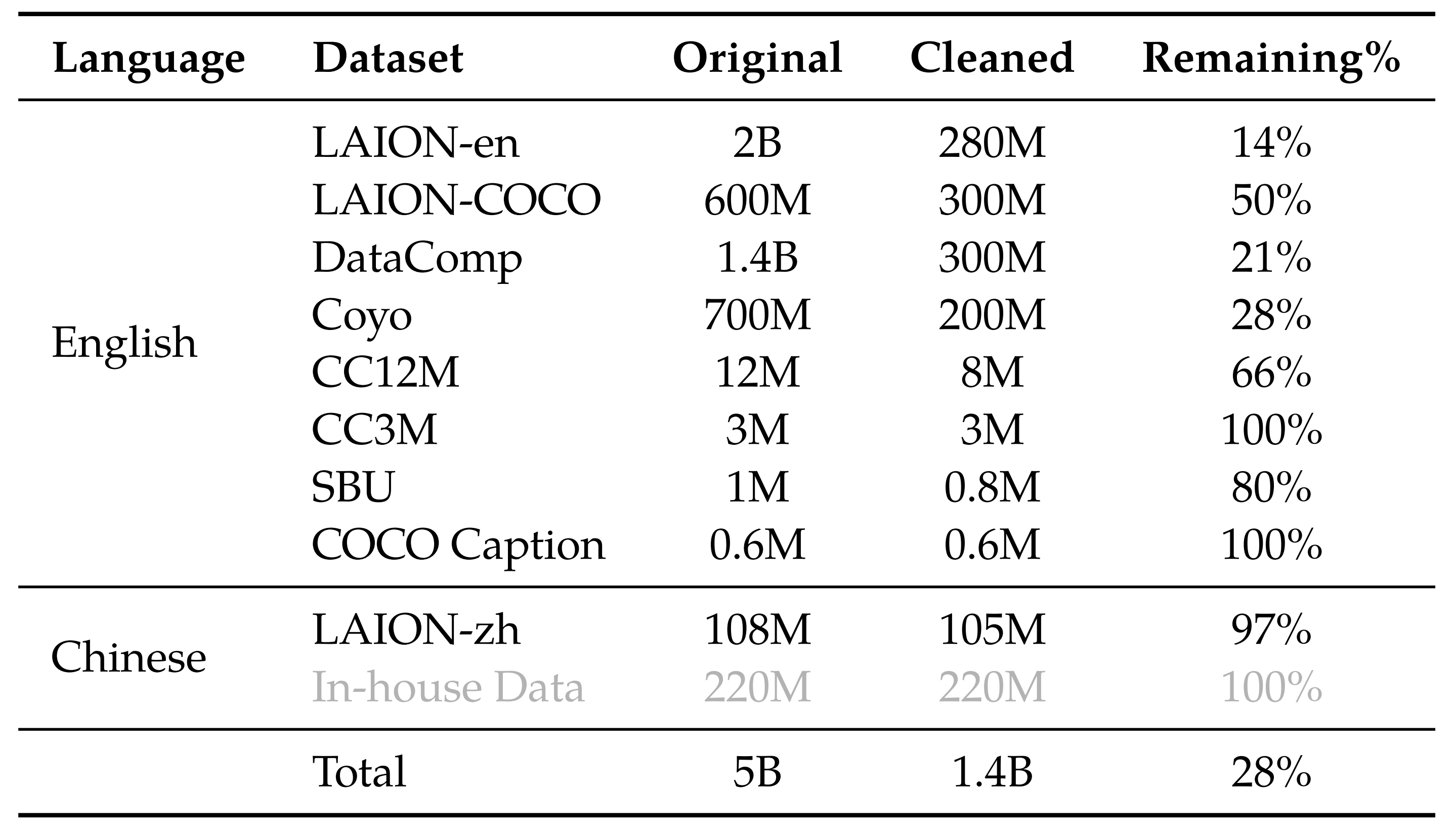
- LAION-en和LAION-zh分别是LAION-5B(Schuhmann等,2022a)的英文和中文子集
- LAION-COCO(Schuhmann等,2022b)是从LAION-en生成的合成数据集
- DataComp(Gadre等,2023)和Coyo(Byeon等,2022)是图文对集合
- CC12M(Changpinyo等,2021)、CC3M(Sharma等,2018)、SBU(Ordonez等,2011)和COCO Caption(Chen等,2015)是学术性描述数据集
预训练过程中,他们冻结大型语言模型,仅优化视觉编码器和VL 适配器
- 在此阶段,输入图像被调整为224 × 224
- 训练目标是最小化文本token的交叉熵
The training objective is to minimize the cross-entropy of the text tokens. - 最大学习率为2e−4,训练过程使用30720 的批量大小进行图像-文本对
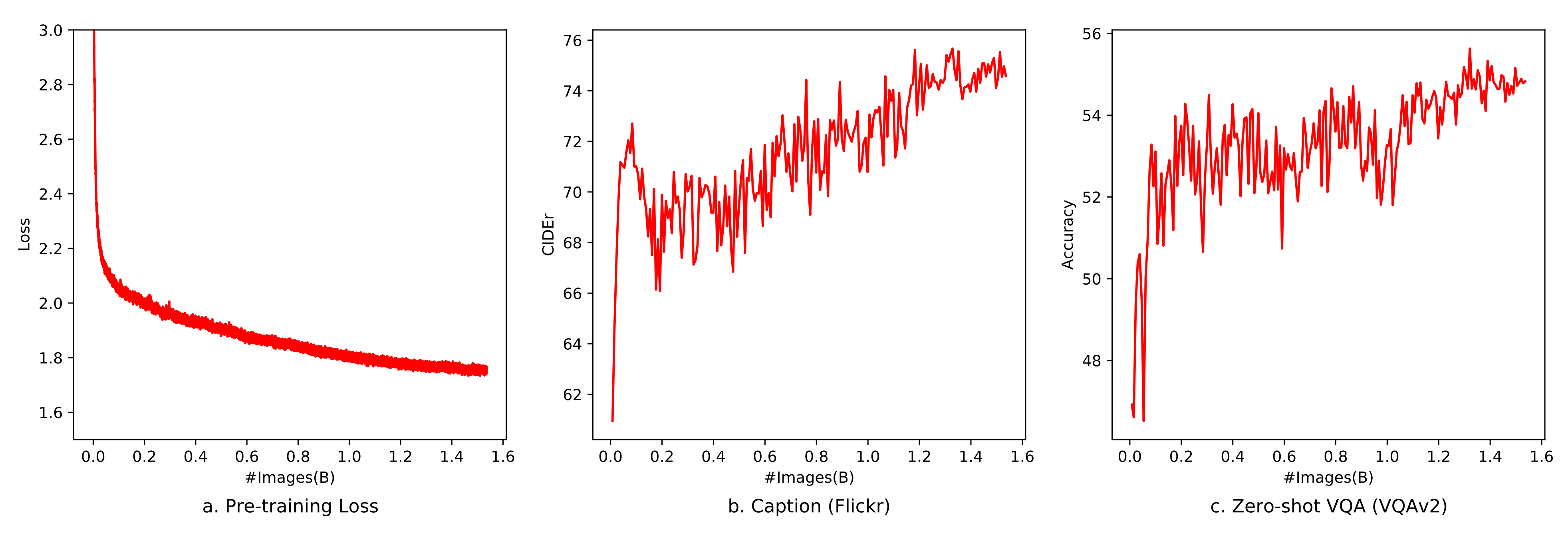
- 整个第一阶段的预训练持续50000 步,消耗大约15 亿图像-文本样本。更多超参数详见原论文的附录C,此阶段的收敛曲线如下图图6 所示
1.2.2 多任务预训练
在多任务预训练的第二阶段,他们引入了高质量和细粒度的VL注释数据,具有更高的输入分辨率和交错的图文数据
正如表3所总结的,同时在7个任务上训练了Qwen-VL
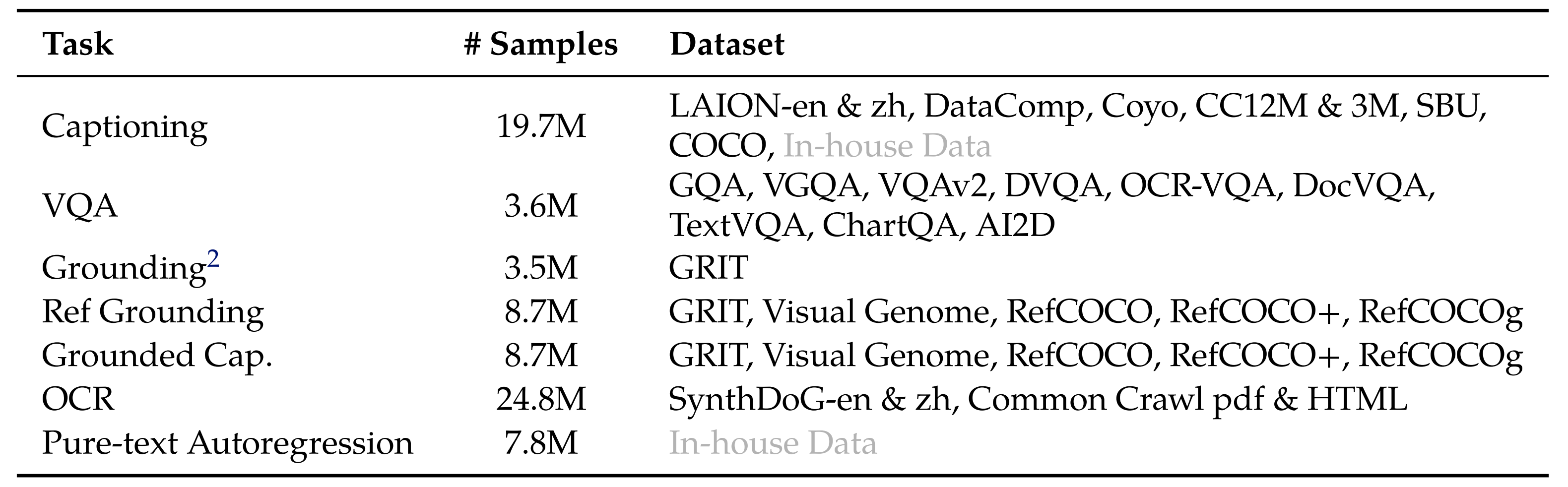
- 对于文本生成,使用内部收集的语料库来保持LLM的能力
- 图像描述Captioning数据与表2相同,但样本数量要少得多,并且不包括LAION-COCO
- 对于VQA任务,使用公开可用数据的混合,包括
GQA(Hudson和Manning,2019年)
VGQA(Krishna等,2017年)
VQAv2(Goyal等,2017年)
DVQA(Kafle等,2018年)
OCR-VQA(Mishra等,2019年)
和DocVQA(Mathew等,2021年)
且遵循Kosmos-2的做法,使用GRIT(Peng等,2023年)数据集进行定位任务,进行了少量修改 - Ref Grounding、Grounded Cap
对于参考定位和定位图像描述的二元性任务,从GRIT(Peng等,2023年)、Visual Genome(Krishna等,2017年)、RefCOCO(Kazemzadeh等,2014年)、RefCOCO+和RefCOCOg(Mao等2016年) - OCR
为了改进以文本为导向的任务,从Common Crawl1中收集PDF和HTML格式的数据,并生成带有自然风景背景的英文和中文合成OCR数据——遵循(Kim等,2022) - 最后,通过将相同任务的数据打包成长度为2048的序列,简单构建交错的图像-文本数据
此外,他们将视觉编码器的输入分辨率从224 × 224 提高到448 × 448,减少了图像下采样导致的信息损失
且在原论文的附录E.3 中对高分辨率的视觉Transformer 进行了窗口注意力和全局注意力的消融实验。更解锁了大型语言模型并训练了整个模型——至于训练目标与预训练阶段相同
具体而言,在模型中使用高分辨率Vision Transformer 将显著增加计算成本。减少模型计算成本的一种可能解决方案是,在Vision Transformer 中使用窗口注意力机制
- 即在模型的ViT 部分的大多数层中仅在224 × 224 的窗口中执行注意力机制,而在模型的ViT 部分的少数层(例如,每4 层中的1 层)中对完整的448 × 448或896 × 896 图像执行注意力机制
- 为此,他们进行了消融实验,以比较在视觉Transformer中使用全局注意力和窗口注意力时模型的性能。下表表10比较了实验结果,以分析计算效率与模型收敛之间的权衡
可以看到,当使用窗口注意力而不是普通注意力时,模型的损失显著增加。并且它们的训练速度相似。因此,最终作者决定在训练Qwen-VL时使用普通注意力而不是窗口注意力

1.2.3 监督微调
在此阶段,他们通过指令微调对Qwen-VL预训练模型进行了微调,以增强其指令跟随和对话能力,从而生成了交互式的Qwen-VL-Chat模型
多模态指令调优数据主要来自于通过LLM自指令生成的字幕数据或对话数据,这些数据通常仅涉及单图像对话和推理,并且局限于图像内容理解
- 他们通过人工标注、模型生成和策略拼接构建了一组额外的对话数据,以将本地化和多图像理解能力融入到Qwen-VL模型中
- 且确认模型能够有效地将这些能力转移到更广泛的语言和问题类型中
此外,他们在训练过程中混合多模态和纯文本对话数据,以确保模型在对话能力上的普遍性 - 指令调优数据总量为350k
在此阶段,他们冻结视觉编码器,并优化语言模型和适配器模块。并在附录B.2中展示了此阶段的数据格式
第二部分 Qwen2-VL
2.1 Qwen2-VL提出与其提出背景
24年6月份,千问团队发布Qwen2-VL系列模型

- 该系列由三种大小的模型组成,分别为 Qwen2-VL-2B、Qwen2-VL-7B 和 Qwen2-VL-72B
- 在各种规模的 LLM 中采用了 675M 参数的 Vison Transformer(ViT),确保了 ViT 的计算负载在不同规模的 LLM 中保持恒定
这是在怎样的背景之下推出的呢?如Qwen2-VL的论文所说
在此之前,当前的大型视觉语言模型(LVLMs)通常受到固定图像输入尺寸的限制。标准的LVLMs将输入图像编码为固定分辨率(例如224×224),通常通过对图像进行下采样或上采样(Zhu等人,2023;Huang等人,2023a),或者采用缩放然后填充的方法(Liu等人,2023b,a)
- 虽然这种一刀切的策略使得图像可以在一致的分辨率下进行处理,但也限制了模型在不同尺度下捕捉信息的能力,特别是在高分辨率图像中导致显著的细节信息损失
因此,这类模型在感知视觉信息时无法达到人类视觉对尺度和细节的敏感度
此外,大多数LVLM依赖于静态的、冻结的CLIP风格(Radford等,2021年)视觉编码器,这引发了关于此类预训练模型生成的视觉表示是否足够的担忧,尤其是在复杂推理任务和处理图像细节方面 - 最近的研究(Bai等,2023b;Ye等,2023a)尝试通过在LVLM训练过程中微调视觉transformer(ViT)来解决这些局限性,这已被证明能产生更好的结果
为了进一步增强模型对不同分辨率的适应性,Qwen2-VL在LVLM训练过程中引入了动态分辨率训练
具体来说,Qwen2-VL在ViT中使用了二维旋转位置嵌入(RoPE),从而使模型能够更好地捕捉不同空间尺度的信息
对于视频内容而言,它本质上是一个帧序列,许多现有模型仍然将其视为独立的模态。然而,理解现实动态的本质,如在视频中表现的那样,对于旨在掌握现实世界复杂性的模型至关重要
即与本质上是单维的文本不同,现实世界的环境存在于三维空间中。当前模型中使用的一维位置嵌入极大地限制了它们有效建模三维空间和时间动态的能力
因此,为了解决这个问题,他们开发了多模态旋转位置嵌入——其采用独立的组件来表示时间和空间信息。这使得模型能够自然地理解动态内容,如视频或流媒体数据,从而提高其理解和与世界互动的能力
2.2 Qwen2-VL的模型架构与训练方法
2.2.1 模型架构
下图图2展示了Qwen2-VL的完整结构——Qwen2-VL能够准确识别和理解图像中的内容,无论其清晰度、分辨率或极端纵横比如何
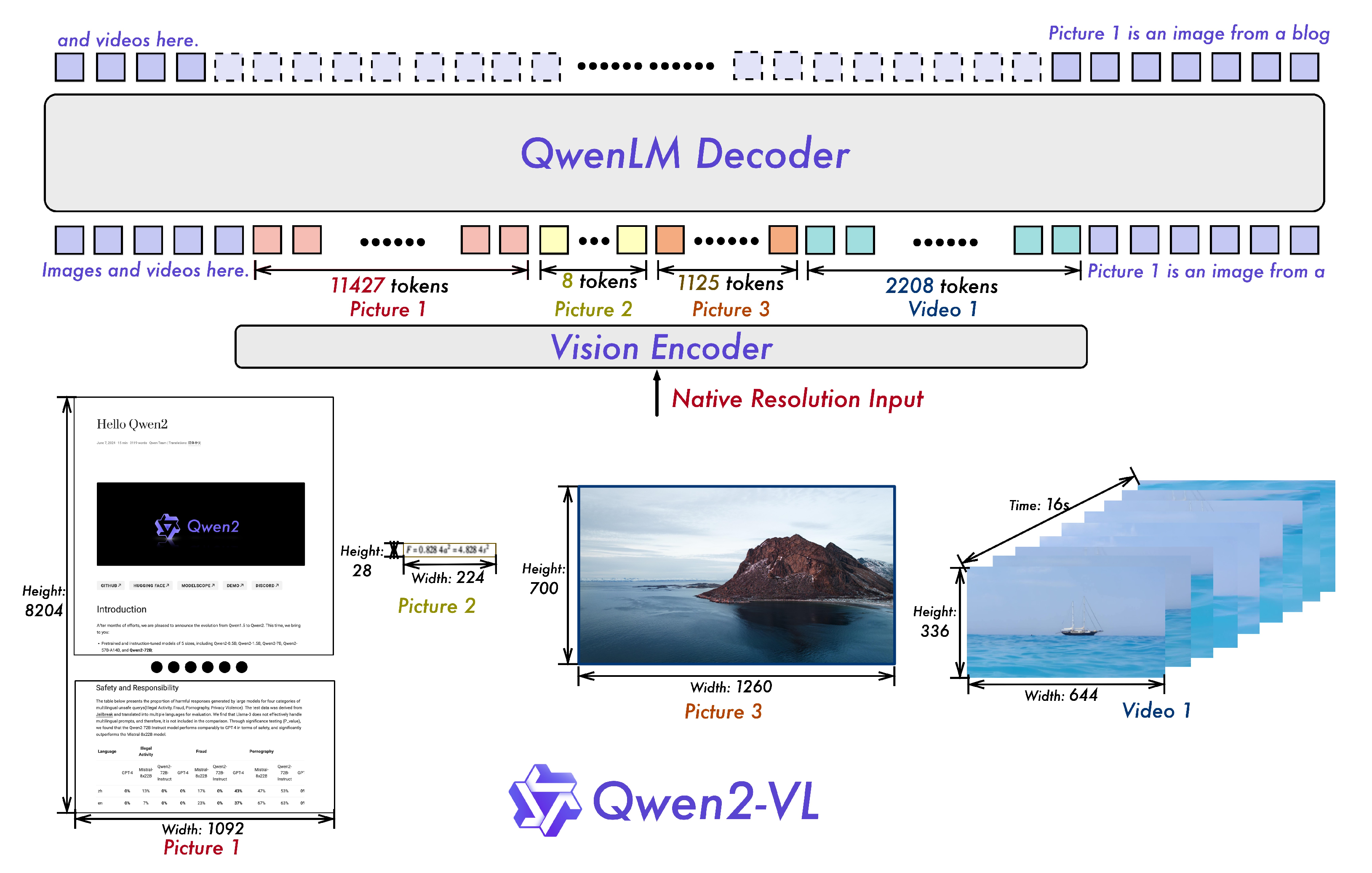
作者保留了Qwen-VL(Bai et al., 2023b)的框架,该框架集成了视觉编码器和语言模型
- 针对不同规模的适应,他们实现了一个具有大约675 百万参数的视觉Transformer (ViT) (Dosovitskiy et al., 2021),能够熟练处理图像和视频输入
- 在语言处理方面,选择了更强大的Qwen2 (Yang et al., 2024) 系列语言模型
且为了进一步增强模型有效感知和理解视频中视觉信息的能力,他们做了几个关键升级:
- Naive动态分辨率
Qwen2-VL的一个关键架构改进是引入了简单动态分辨率支持(Dehghani等,2024)
与Qwen-VL不同,Qwen2-VL现在可以处理任何分辨率的图像,动态地将它们转换为可变数量的视觉token
为了支持这一功能,他们通过去除原始的绝对位置嵌入并引入2D-RoPE(Su等,2024;Su,2021)来捕获图像的二维位置信息,从而修改了ViT
在推理阶段,不同分辨率的图像被打包成一个序列,并通过控制打包长度来限制GPU内存的使用
此外,为了减少每幅图像的视觉token,在ViT之后使用一个简单的MLP层将相邻的2×2 token压缩为一个token,并在压缩后的视觉标记的开头和结尾放置特殊的<|vision_start|>和<|vision_end|>token
结果是,一个分辨率为224×224的图像,在使用patch_size=14的ViT编码后,将在进入LLM之前被压缩为66个token - 多模态旋转位置嵌入(M-RoPE)
另一个关键的架构增强是创新的多模态旋转位置嵌入(M-RoPE)
与传统的大型语言模型中的一维旋转位置嵌入(1D-RoPE)不同,后者仅限于编码一维位置信息,M-RoPE能够有效地建模多模态输入的位置信息
这是通过将原始的旋转嵌入分解为三个组件:时间、高度和宽度来实现的
对于文本输入,这些组件使用相同的位置ID,使M-RoPE在功能上等同于1D-RoPE(Su, 2024)
在模型输入包含多种模式的情况下,每种模式的位置编号通过将前一种模式的最大位置ID递增一来初始化
下图图3展示了M-RoPE的一个示例
总之,M-RoPE不仅增强了位置信息的建模,还减少了图像和视频的位置ID值,使模型能够在推理过程中外推到更长的序列 - 统一图像和视频理解
Qwen2-VL采用了一种混合训练方案,结合了图像和视频数据,确保在图像理解和视频理解方面的熟练度
为了尽可能完整地保留视频信息,他们以每秒两帧的速率对每个视频进行采样
此外,他们将3D卷积(Carreira和Zisserman,2017)与深度为二的卷积结合起来处理视频输入,使模型能够处理3D tubes而不是2D patch,从而在不增加序列长度的情况下处理更多的视频帧(Arnab等,2021)
且为了保持一致性,每幅图像被视为两个相同的帧。为了在长视频处理的计算需求与整体训练效率之间取得平衡,他们动态调整每个视频帧的分辨率,将每个视频的token总数限制为16384。这种训练方法在模型理解长视频的能力与训练效率之间取得了平衡
// 待更
第三部分 Qwen2.5-VL
Qwen2.5-VL暂时还没出来技术报告或论文,只有对应的技术blog:Qwen2.5 VL! Qwen2.5 VL! Qwen2.5 VL! | Qwen
// 待更