前言
众所周知,运行GPT这样的大模型应用非常昂贵,需要大量的硬件加速器,如GPU「我司过去半年做了一系列大模型应用,比如基于大模型的论文审稿、翻译、修订、对话、idea提炼,对此深有感触」
根据最近的估算,处理一个LLM请求的成本可能是传统关键词查询的10倍[43]。鉴于这些高昂的成本,提高吞吐量——从而降低成本——变得尤为重要
- 而GPT的核心是一个自回归的Transformer模型[53]。该模型根据输入(提示)和之前生成的输出序列的tokens逐个生成单词(tokens)。对于每个请求,这个昂贵的过程会重复进行,直到模型输出终止token
- 这个顺序生成过程使得工作负载受限于内存,未能充分利用GPU的计算能力,并限制了服务吞吐量。通过将多个请求批处理在一起,可以提高吞吐量。然而,要在一个批处理中处理多个请求,就必须有效管理每个请求的内存空间
vLLM由此应用而生,其实vLLM我早就想写了,加之我们自己在做论文审稿GPT时,部署llama3.1便用的vLLM,只是之前一直忙于项目开发、具身研究,故一直拖到现今,好在,本文到底还是来了
本文会特别侧重以下两点
- 在背景知识的交待上,尽可能交待好一切必须的背景知识
比如原vLLM论文中的图示画的特别好,但论文毕竟面向专业人士,所以背景知识的交待上,不会花太多心思精力(比如操作系统中的内存管理知识,大部分人除非做OS的,不然 基本都忘了不少),如此便会让初学者屡屡犯难 - 在遣词造句上,尽可能用相对比较通俗易懂的语言
第一部分 从OS虚拟内存起步,逐步理解Paged Attention
1.1 背景知识回顾:Transformer、LLM服务与自回归生成
1.1.1 基于Transformer的大型语言模型
语言建模的任务是对一个token列表()的概率进行建模,由于语言具有自然的顺序排列,通常将整个序列的联合概率分解为条件概率的乘积(取自回归分解[3]),定义为方程1
而transformer已成为大规模建模上述概率的标准架构,而transformer中最重要的组件是其自注意力层「如果你还不了解什么transformer及其中的自注意力机制,请参见此文《Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT》」
对于输入隐藏状态序列,自注意力层首先对每个位置
应用线性变换以获得查询、键、值向量
然后,自注意力层通过将一个位置的查询向量与其前面的所有键向量相乘来计算注意力分数,并计算输出
作为值向量的加权平均值
1.1.2 LLM服务与自回归生成
一旦训练完成,LLM通常被部署为条件生成服务(例如,完成API [34] 或聊天机器人[19,35])
对LLM服务的请求提供了一系列输入prompt token,LLM服务根据方程1生成一系列输出token
,我们将prompt和输出列表的连接称为序列
- 由于方程1中的分解,LLM只能逐个采样和生成新token,并且每个新token的生成过程依赖于该序列中所有先前的token,特别是它们的键和值向量
Due to the decomposition in Eq. 1, the LLM can only sam-ple and generate new tokens one by one, and the generation process of each new token depends on all the previous tokensin that sequence, specifically their key and value vectors. - 在这个顺序生成过程中,现有token的键和值向量通常被缓存以生成未来的token,称为KV缓存
Inthis sequential generation process, the key and value vectorsof existing tokens are often cached for generating futuretokens, known as KV cache
举个例子,比如基于x1 x2 x3 x4预测下一个token x5
则在x5之前,已经计算了x1~x4的注意力
q1k1 v1、q1k2 v2、q1k3 v3、q1k4 v4
q2k1 v1、q2k2 v2、q2k3 v3、q2k4 v4
q3k1 v1、q3k2 v2、q3k3 v3、q3k4 v4
q4k1 v1、q4k2 v2、q4k3 v3、q4k4 v4
在计算x5与之前token的注意力时,势必又得如下计算
q5k1 v1、q5k2 v2、q5k3 v3、q5k4 v4、q5k5 v5
而k1v1、k2v2 k3v3、k4v4在之前的注意力计算中已被缓存
注意,一个token的KV缓存依赖于它所有的先前token。这意味着同一token在序列中不同位置出现时的KV缓存会有所不同
在给定一个请求提示时,LLM服务中的生成计算可以分解为两个阶段
- 提示阶段
将整个用户提示作为输入,并计算第一个新token的概率
在此过程中,还生成了键向量和值向量
由于提示token都是已知的,提示阶段的计算可以通过矩阵-矩阵乘法操作进行并行化。因此,该阶段可以高效利用 GPU 中固有的并行性
- 自回归生成阶段
按顺序生成其余的新token。在迭代时,模型将一个token
作为输入,并使用键向量
和值向量
去计算概率
注意,在位置到
的键和值向量在之前的迭代中已被缓存,只有新的键和值向量
和
在此选代中计算
此阶段在序列达到最大长度(由用户指定或受限于 LLM)或发出序列结束(<eos>)token时完成
由于数据依赖性,不同迭代的计算无法并行化,通常使用矩阵-向量乘法,这效率较低。因此,此阶段严重低效利用 GPU 计算并变得受限于内存,成为单个请求延迟的大部分原因
1.2 Paged Attention是如何推出的
1.2.1 常规的KV cache分配造成的内存碎片
下图图1(左)展示了在具有40GB RAM的NVIDIA A100 GPU上一个13B参数的LLM的内存分布
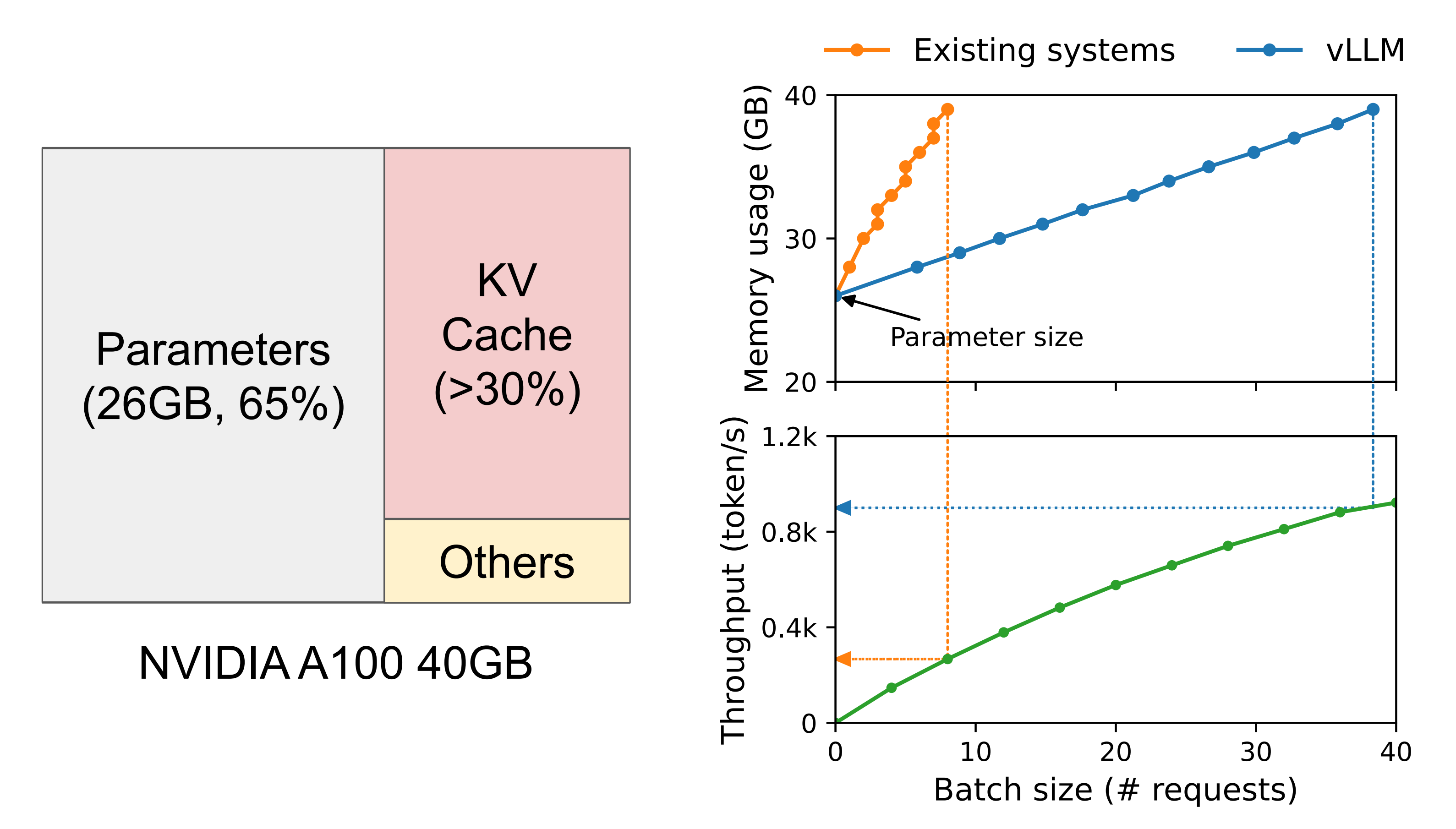
- 大约65%的内存分配给模型权重,在服务期间保持静态
- 接近30%的内存用于存储请求的动态状态
对于Transformers,这些状态由与注意力机制相关的键和值张量组成,通常称为KV缓存[41],它代表了从早期tokens生成新输出tokens的上下文 - 剩下的一小部分内存的百分比用于其他数据,包括激活——评估LLM时创建的临时张量
由于模型权重是恒定的,而激活只占用GPU内存的一小部分,因此KV缓存的管理方式对确定最大批处理大小至关重要
如果管理不当,KV缓存内存可能会显著限制批处理大小,从而限制LLM的吞吐量,如上图图1(右)所示
所以,如下图图 2 中的分析结果显示,vLLM之外的现有系统中只有20.4 % -38.2% 的KV 缓存内存用于存储实际的token状态,为何会造成这个结果呢
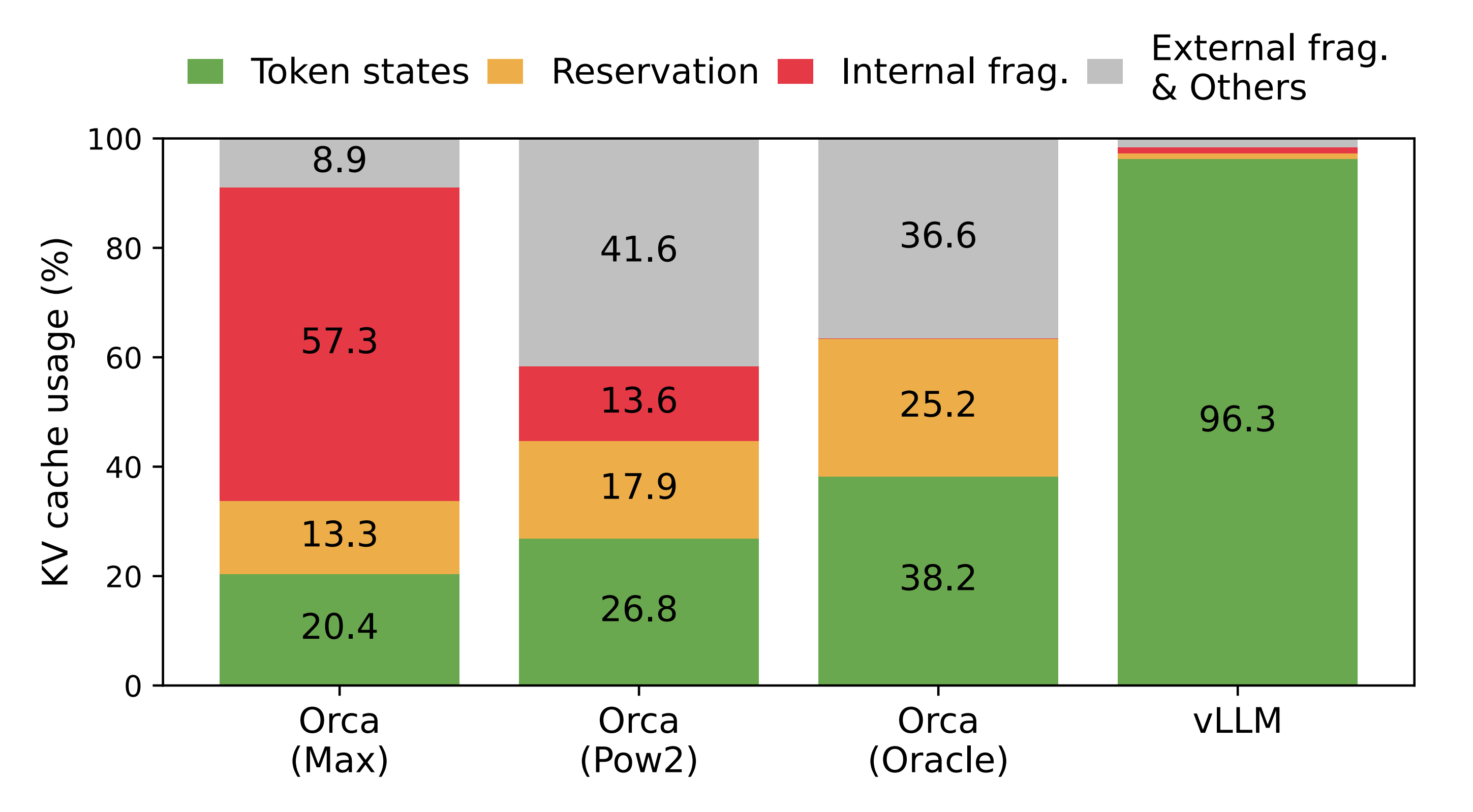
- 首先,现有系统[31,60]存在内部和外部内存碎片问题。为了在连续空问中存储请求的 KV 缓存,它们预分配了一个具有请求最大长度(例如 ,2048 个token)的连续内存块。这可能导致严重的内部碎片,因为请求的实际长度可能远短于其最大长度
如下图所示,现有系统中的KV缓存内存管理。存在三种类型的内存浪费——保留、内部碎片和外部碎片——阻止其他请求适应内存。每个内存槽中的token代表其KV缓存。请注意,相同的token在不同位置时可以具有不同的KV缓存「Three types of memory wastes – reserved, internal fragmentation,and external fragmentation – exist that prevent other requests from fitting into the memory. The token in each memory slotrepresents its KV cache. Note the same tokens can have different KV cache when at different positions」
此外,即使事先知道实际长度,预分配仍然低效:由于在请求的整个生命周期内整个块都是保留的,其他较短的请求无法利用当前未使用的块的任何部分。此外,外部内存碎片也可能很显著,因为每个请求的预分配大小可能不同
为了方便大家更好的理解,特再举个例子,如下图所示(图源于大猿搬砖简记),如果最大请求长度max_seq_len = 8的话,则
当第1条请求(prompt1)过来时,推理框架会为它安排(1, 8)大小的连续存储空间
当第2条请求(prompt2)过来时,同样也需要1块(1, 8)大小的存储空间。但此时prompt1所在的位置上,只剩3个空格子了,所以它只能另起一行做存储。对prompt3也是同理
其中,浅色块是prefill阶段prompt的KV cache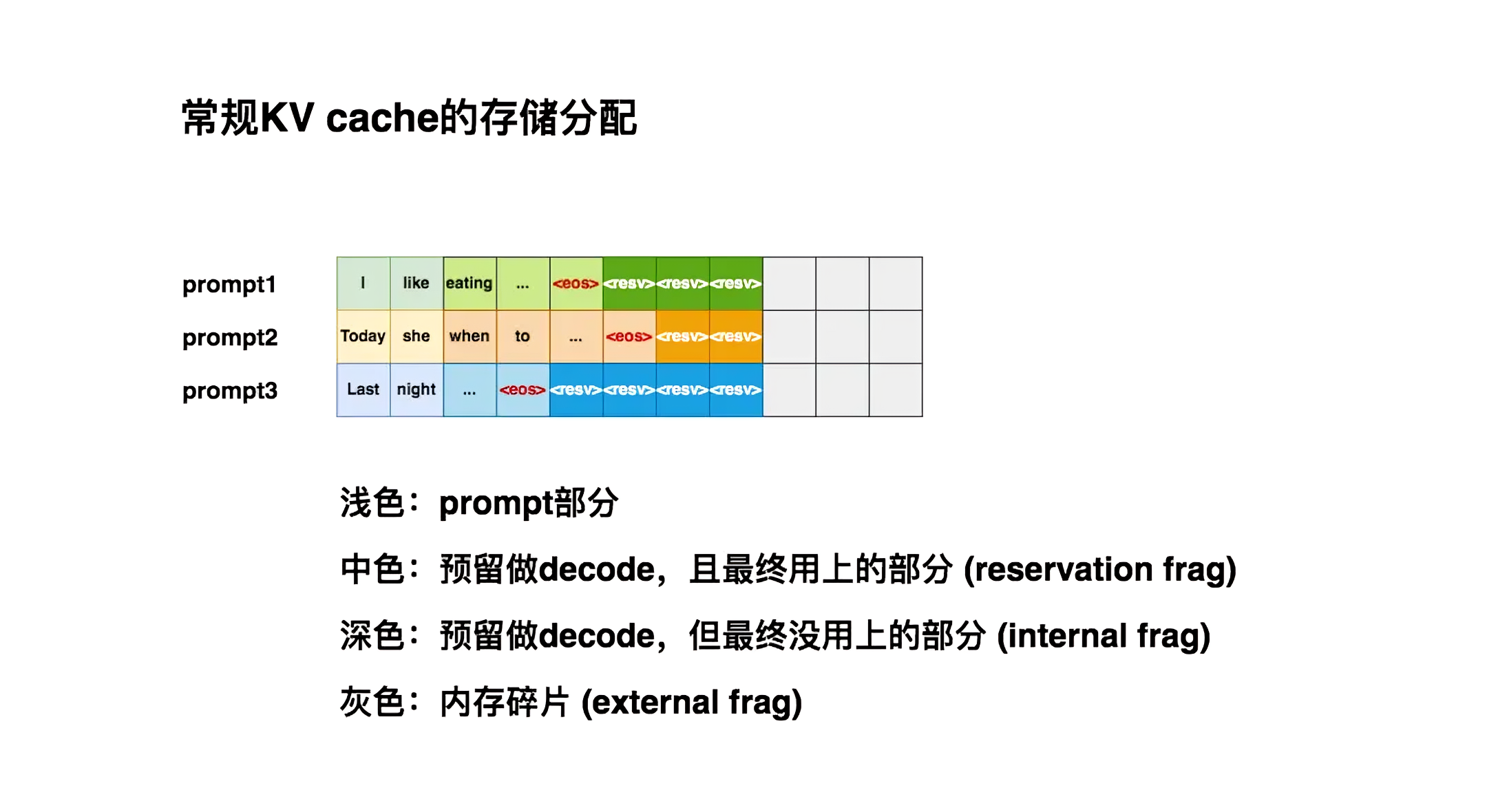
中色块是decode阶段的KV cache,其中<eos>表示序列生成的截止符
深色块,它也是decode阶段的KV cache,但直到序列生成完毕,它都没有被用上。由于这些深色块是预留的KV cache的一部分,所以称其为内部碎片(internal fragment)
灰色块,它不是预留的KV cache的一部分,且最终也没有被用上,称这些灰色块为外部碎片(external fragment)
如猛猿所说,“想象一下,此时新来了一条prompt4,它也要求显存中的8个格子作为KV cache。此时你的显存上明明有9个空格子,但因为它们是不连续的碎片,所以无法被prompt4所使用。这时prompt4的这条请求只好在队列中等待,直到gpu上有足够显存资源时再进行推理,这不就对模型推理的吞吐量造成显著影响了吗?” - 其次,LLM服务通常使用先进的解码算法,例如并行采样和束搜索,会在每个请求中生成多个输出。在这些场景中,请求由多个序列组成,这些序列可以部分共享它们的KV缓存
然而,由于序列的KV缓存存储在单独的连续空间中,现有系统中无法实现内存共享
1.2.2 Paged Attention:受OS解决内存碎片化和共享的虚拟内存分页机制启发的算法
为了解决上述限制,来自1 UC Berkeley、2 Stanford University、3 Independent Researcher、4 UC San Diego的研究者提出了PagedAttention——一种受操作系统OS解决内存碎片化和共享的虚拟内存分页机制启发的注意力算法
- 其对应的作者包括
Woosuk Kwon1,、∗ Zhuohan Li1,、∗ Siyuan Zhuang1、Ying Sheng1,2、Lianmin Zheng1、Cody Hao Yu3、Joseph E. Gonzalez1、Hao Zhang4、Ion Stoica1 - 其对应的论文为《Efficient Memory Management for Large Language Model Serving with PagedAttention》
- 其对应的GitHub为:vllm-project/vllm,截止到24年12月初,目前已3万多star,比我July的2万多star多,可见其影响力之广
最终,vLLM——一个基于Paged Attention的高吞吐量分布式LLM服务引擎,vLLM使用与PagedAttention共同设计的块级内存管理和抢占式请求调度「比如允许KV块存储在非连续的物理内存中」,从而在vLLM中实现更灵活的分页内存管理,使得KV缓存内存的接近零浪费
且vLLM支持流行的LLM,如GPT [5]、OPT [62]和LLaMA [52],其大小各异,包括那些超过单个GPU内存容量的模型
1.3 如何更好理解Paged Attention的算法原理(含OS的内存管理)
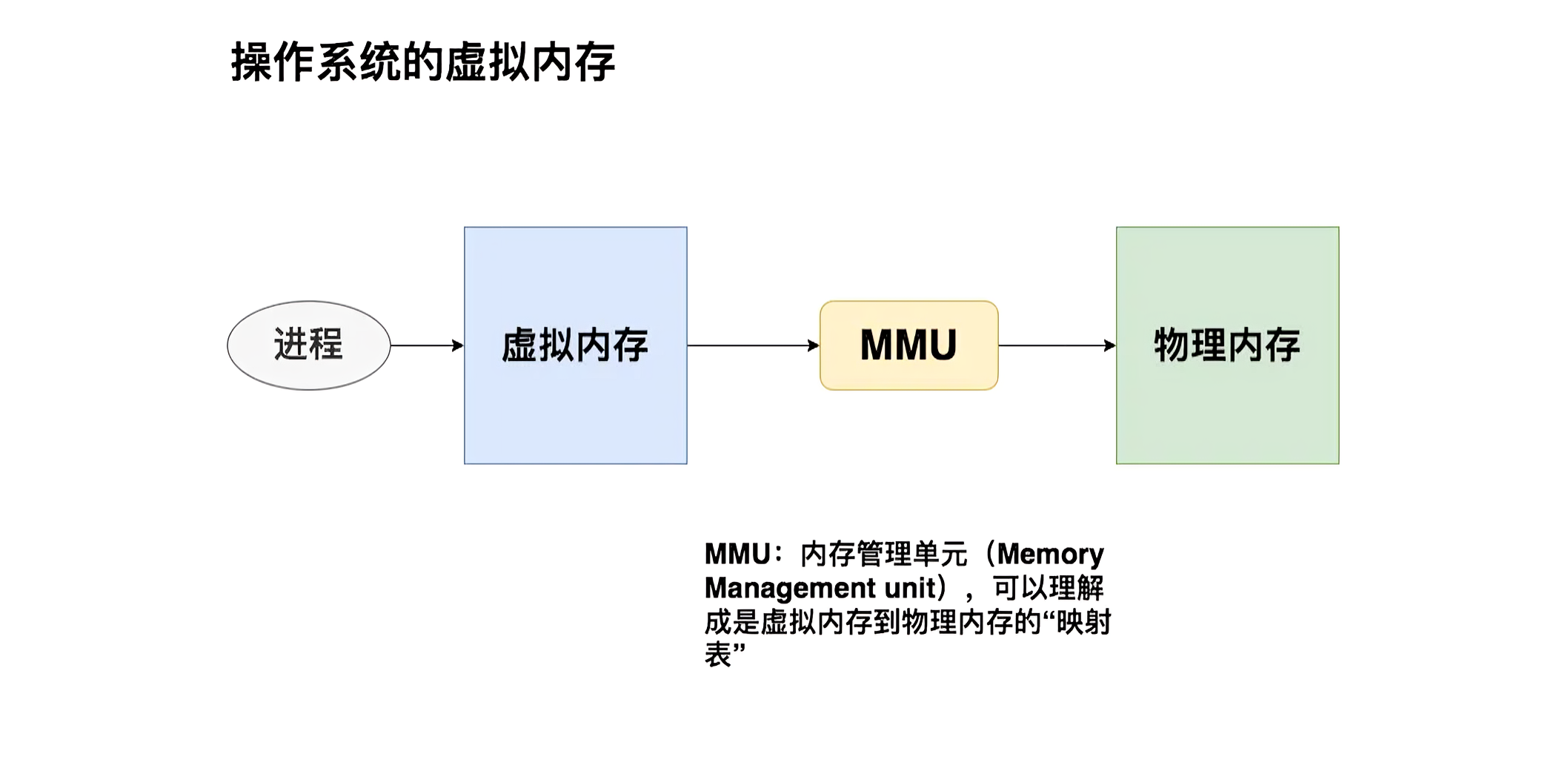
由于PagedAttention的设计灵感来自操作系统中虚拟内存的分页管理技术。所以咱们先回顾下操作系统的虚拟内存技术
1.3.1 操作系统的虚拟内存、分段式内存管理、分页式内存管理
如猛禽所说(本小节的内容主要来自猛禽的大猿搬砖简记),程序运行时,会将代码、数据等内容存放在物理内存上。在最原始的做法中(没有操作系统,例如单片机),程序直接对物理内存进行操作,决定使用它的哪些存储地址
如果要运行多个进行,如何让各个进程间的开发能够相互独立呢?一种直觉的做法是:
- 给每个进程分配一个虚拟内存。每个进程在开发和运行时,可以假设这个虚拟内存上只有自己在跑,这样它就能大胆操作
- 虚拟内存负责统一规划代码、数据等如何在物理内存上最终落盘。这个过程对所有进程来说都是透明的,进程无需操心
虚拟内存的核心思想可简化成下图:
在分段式内存管理中,虚拟内存会尽量为每个进程在物理内存上找到一块连续的存储空间,让进程加载自己的全部代码、数据等内容。如下图,是一个具体的例子(来源于大猿搬砖简记)
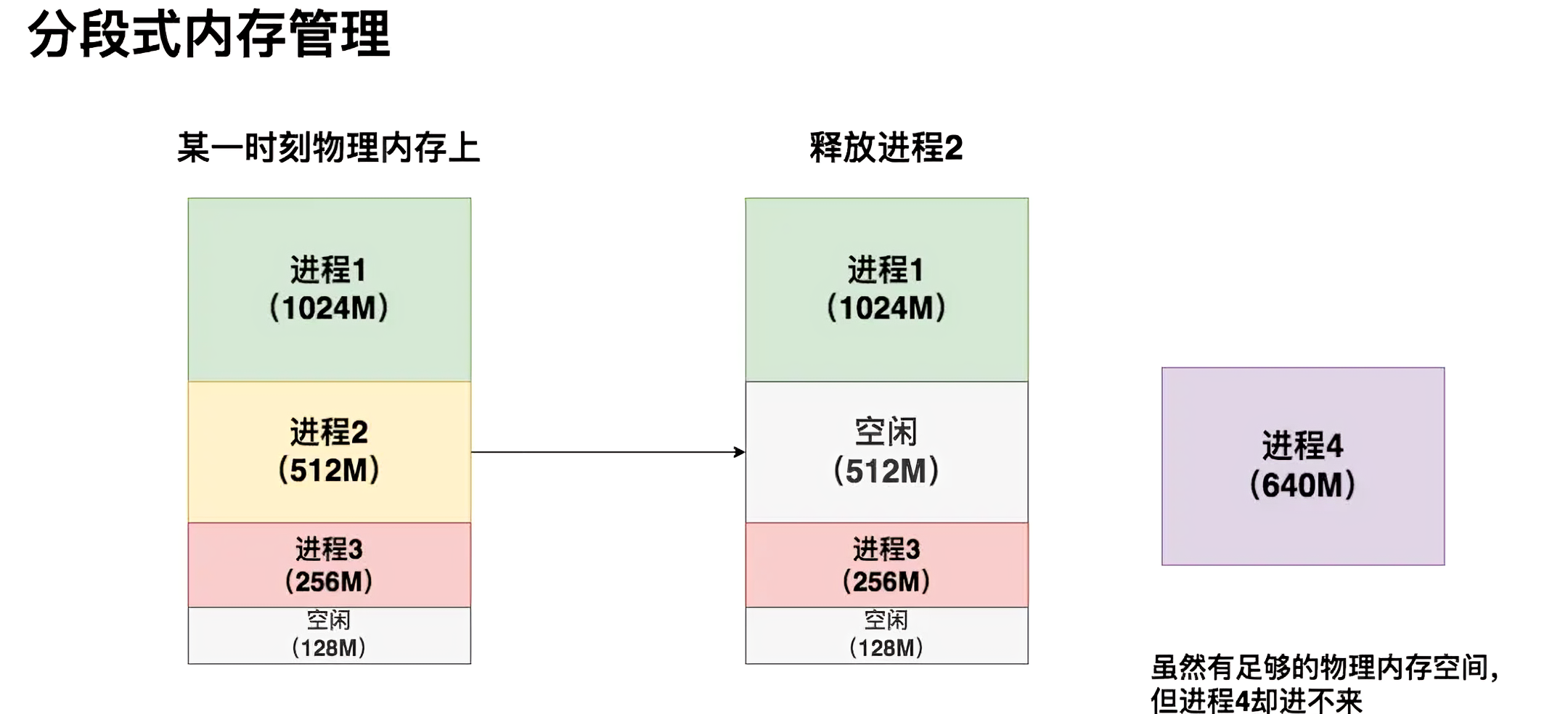
- 在这个例子中,3个进程的虚拟内存各自为它们在物理内存上映射了一块连续的存储空间
在某一时刻,释放了进程2,同时想运行640M的进程4
这时尴尬地发现,虽然物理内存上有640M的空间剩余(空闲的512M + 空闲的128M),但因为是碎片化的,进程4无法加载进去,因此它只能等待 - 在这个情况下,如果硬要运行进程4,也是有办法的:可以先把进程3从物理内存上交换(swap)到磁盘上,然后把进程4装进来,然后再把进程3从磁盘上加载回来。通过这种方法重新整合了碎片,让进程4能够运行
- 但这种办法的显著缺点是:如果进程3过大,同时内存到磁盘的带宽又不够,整个交换的过程就会非常卡顿。这就是分段式内存管理的缺陷
这时,你可能会想到:为什么要给所有进程都预分配一个固定的存储块(段)呢?即能否进程运行到哪里,或者想用哪个具体功能时,再加载这部分相关的内容去内存,以此让整个内存分配更加动态?
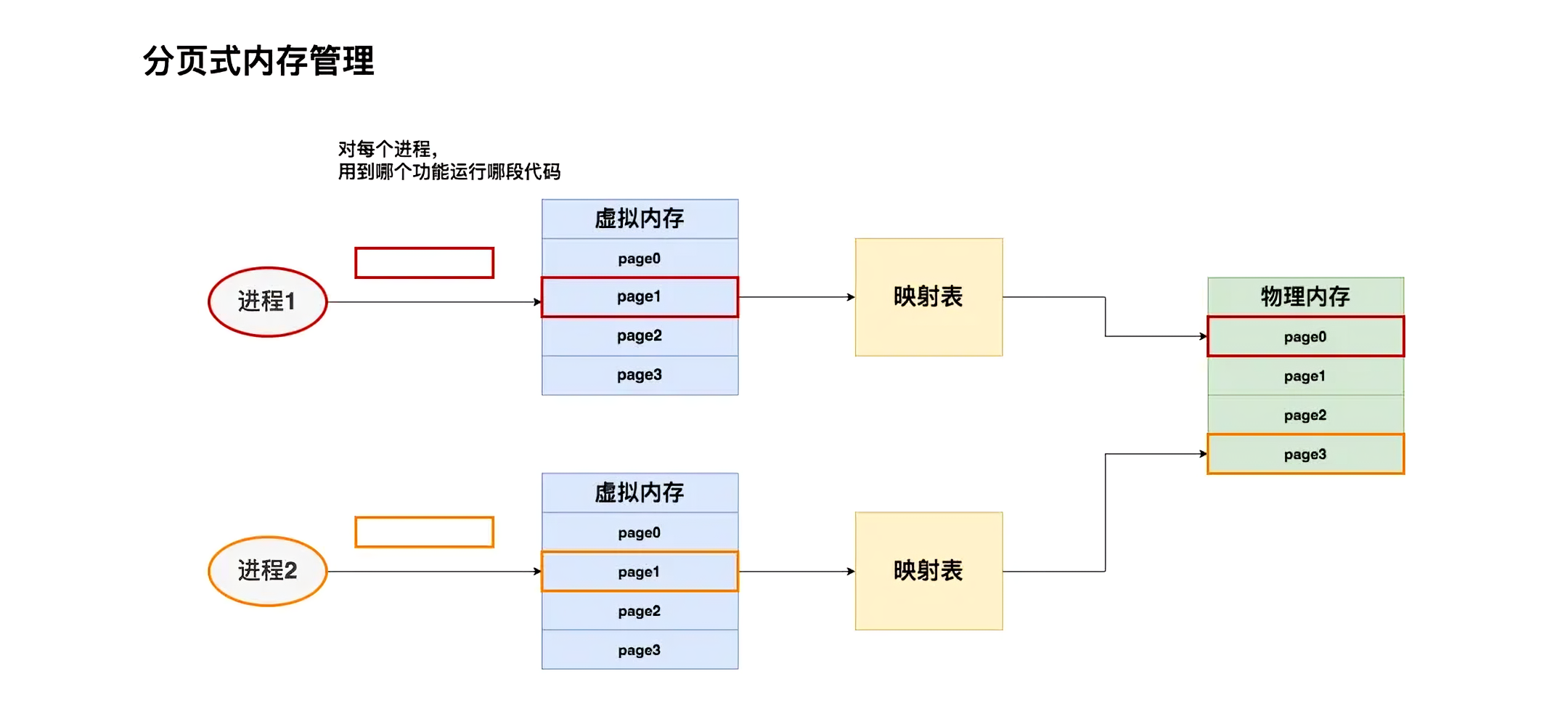
即完全可以将进程1、进程2想成是两本书。代码分布在书的不同page上。希望想读哪一页,就加载哪一页,而不是一下把两本书都加载进来。同时,当不想读某些页的时候,也能根据页码将其清空
现在,我们希望读进程1和进程2的page1,就将其加载到物理内存上。虚拟内存会帮我们做好映射,把来自不同进程的这两页分别加载到物理内存对应位置
虚拟内存的分页管理技术总结起来就是:
- 将物理内存划分为固定大小的块,称每一块为页(page)。从物理内存中模拟出来的虚拟内存也按相同的方式做划分
- 对于1个进程,不需要静态加载它的全部代码、数据等内容。想用哪部分,或者它当前跑到哪部分,就动态加载这部分到虚拟内存上,然后由虚拟内存帮我们做物理内存的映射
- 对于1个进程,虽然它在物理内存上的存储不连续(可能分布在不同的page中),但它在自己的虚拟内存上是连续的。通过模拟连续内存的方式,既解决了物理内存上的碎片问题,也方便了进程的开发和运行
1.3.2 PagedAttention:可处理单个请求(先prefill后decode)和多个请求
受操作系统重经典分页思想的启发,vLLM的作者引入了分页注意力Paged Attention,分页注意力允许在非连续的内存空间中存储连续的键和值「PagedAttention allows storing continu-ous keys and values in non-contiguous memory space」
为方便大家的理解,举个例子,假设现在你向模型server发送一条请求,prompt:“ Four score and seven years ago our ”,你希望模型能做续写。Paged Attention的运作流程如下图:
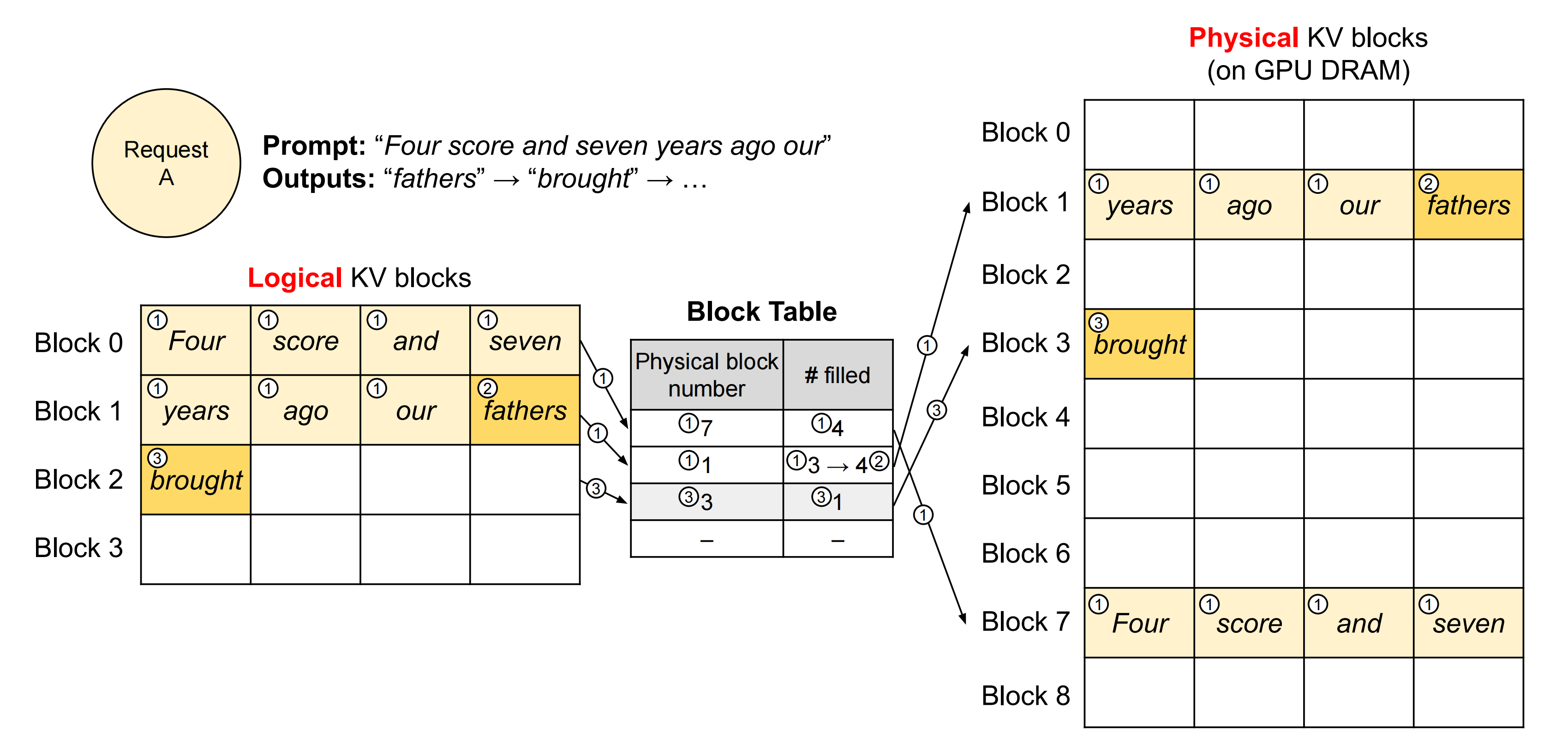
在上图中「图中带圈的序号表示操作步骤」,请求(request)——比如上图左上角的Request A 可理解为操作系统中的一个进程
- 逻辑内存(logical KV blocks)可理解为操作系统中的虚拟内存
每个block类比于虚拟内存中的一个page。每个block的大小是固定的,在vLLM中默认大小为16(所以是一个4×4的表格),即可装16个token的K/V值 - 块表(block table)可理解为操作系统中的虚拟内存到物理内存的映射表
- 物理内存(physical KV blocks)可理解为操作系统中的物理内存
物理块在gpu显存上,每个block类比于虚拟内存中的一个page,比如上图8个block 便对应的8页
在prefill阶段
- 划分逻辑块:vLLM拿到这条prompt,先按照设定好的block大小B(本例中B=4),为prompt划分逻辑块(Logical KV blocks)
由于prompt——Four score and seven years ago our 中有7个token,所以vLLM用可以装8个prompt的2个逻辑块(即block 0, block 1)来装它们的KV值
其中,在逻辑块Logical Block 1中目前只装了"years", "ago", "our"这3个token的KV值,有1个位置是空余的,这个位置就被称为保留位(reservation) - 划分物理块:划分好逻辑块后,就可以将其映射到物理块中去了。物理块是实际存放KV值的地方
对此,通过一张block table来记录逻辑块和物理块的映射关系,block table的主要内容包括:逻辑块和物理块的映射关系(physical block number),例如
逻辑块Logical Block 0对应物理块physical Block 7
所以你可以看到在Logical Block 0的Four score and seven,映射到了physical Block 7
故logical KV blocks的第一行有个小箭头下来指向Block Table第二行第一个格子里面的数字7(该数字7代表physical Block number 7),最后再有个大箭头指向physical Block 7
逻辑块Logical Block 1对应物理块physical Block 1
所以你可以看到在Logical Block 1的years ago our + fathers,映射到了physical Block 1
logical KV blocks的第二行有个小箭头下来指向Block Table第三行第一个格子里面的数字1(该数字1代表physical Block number 1),最后再有个大箭头指向physical Block 1
逻辑块Logical Block 2对应物理块physical Block 3
所以你可以看到在Logical Block 2的brought,映射到了physical Block 3
logical KV blocks的第三行有个小箭头下来指向Block Table第四行第一个格子里面的数字3(该数字3代表physical Block number 3),最后再有个大箭头指向physical Block 3
对于physical Block物理块7,其4个槽位都被填满,故 #filled那一列写着4;
对于physical Block物理块1,其3-4个槽位被填满,故 #filled那一列第①步骤时写着3,之后第②步骤时写着4
对于physical Block物理块3,其1个槽位被填满,故 #filled那一列写着1 - 正常计算prompt的KV值,并通过划分好的关系填入物理块中
而在Decode阶段,则依次生成第1个词、第2个词(虽然上文其实已经涉及到了decode生成词的情况,但咱们还是来总结下)
比如生成第一个词时
- 使用KV cache计算attention,生成第1个词fathers。不难发现,当我们计算时,使用的是逻辑块,即形式上这些token都是连续的。与此同时,vLLM后台会通过block table这个映射关系,帮我们从物理块上获取数据做实际计算。通过这种方式,每个request都会认为自己在一个连续且充足的存储空间上操作,尽管物理上这些数据的存储并不是连续的
- 基于新生成的词,更新逻辑块、物理块和block table
对于block table,vLLM将它filled字段由3更新至4 - 分配新的逻辑块和物理块。当fathers更新进去后,逻辑块已装满
所以vLLM将开辟新的逻辑块logical block 2,并同时更新对应的block table和物理块
至于生成第二个词时,类比上面的步骤来进行
有了上面的解释,再来看下图就相对一目了然了,其对于多个请求prompt——比如下图左侧的Request A和下图右侧的Request B,同时做推理

最后,再用论文中的表述总结一下
vLLM使用PagedAttention内核访问以逻辑KV块形式存储的先前KV缓存,并将新生成的KV缓存保存到物理KV块中。在一个KV块中存储多个tokens(块大小> 1)使PagedAttention内核能够并行处理更多位置的KV缓存,从而提高硬件利用率并减少延迟
- 分页注意力将每个序列的KV缓存划分为KV块。每个块包含固定数量的token的键和值向量,称之为KV大小块(B)
定义键块和值块之后,注意力计算便可以转化为如下的逐块计算
其中是第
个KV块上的注意力得分的行向量
- 在注意力计算过程中,PagedAttention内核分别识别并提取不同的KV块
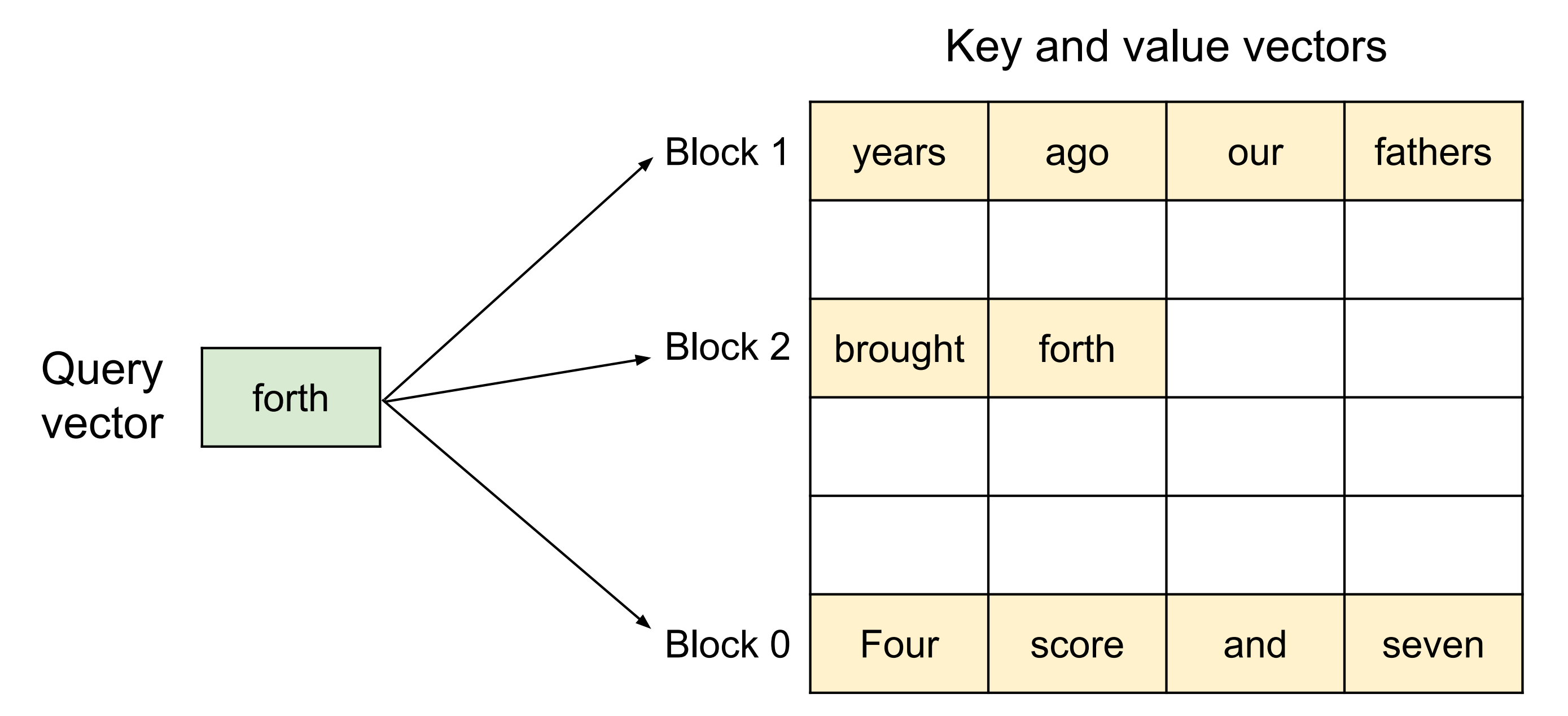
在下图图5中展示了PagedAttention的一个例子:键和值向量分布在三个块中,这三个块在物理内存中并不连续「此图相当于是PagedAttention算法的示意图,其中注意力键和值向量作为非连续块存储在内存中」每次,内核将查询token “forth”的查询向量
与一个块中的键向量
(例如,块0中“Four score and seven”的键向量)相乘以计算注意力得分
,随后再将
相乘以得出最终的注意力输出
1.4 PagedAttention在并行采样、束搜索中的应用
1.4.1 Parallel Sampling
给模型发送一个请求,希望它对prompt做续写,并给出三种不同的回答,咱们管这个场景叫parallel sampling,那传统KV cache和vLLM在做并行采样时 都会咋做呢?
- 传统KV cache
假设模型的max_seq_len = 2048,传统KV cache可能在显存中分配两块长度是2048的空间
由于prompt一致,这两块2048的空间中存在大量重复的KV cache - vLLM PagedAttention
假定发给模型1个request,这个request中包含2个prompt/sample,记为Sample A1和Sample A2,这两个prompt完全一致,都为Four score and seven years ago our
我们希望模型对这两个prompt分别做续写任务
首先,Prefill阶段,vLLM拿到Sample A1和Sample A2,根据其中的文字内容,为其分配逻辑块Logical Block和物理块Physical Block
- 分配逻辑块
对于A1,vLLM为其分配逻辑块Logical Block:block0和block1
对于A2,vLLM为其分配逻辑块Logical Block:block0和block1
需要注意的是,A1的逻辑块和A2的逻辑块是独立的(尽管它们都叫block0和block1),你可以将A1和A2视作操作系统中两个独立运行的进程 - 分配物理块
对于A1和A2,虽然逻辑块独立,但因为它们的token完全相同,所以可以在物理内存上共享相同的空间
所以A1的逻辑块block0/1分别指向物理块block7/1;A2的逻辑块block0/1分别指向物理块block7/1,相当于一开始都指向物理块block7/1,所以才有上图左右两侧都是分别两个大箭头指向物理块block7/1
设每个物理块下映射的逻辑块数量为ref count,所以对物理块block7/1来说,它们的ref count都为2
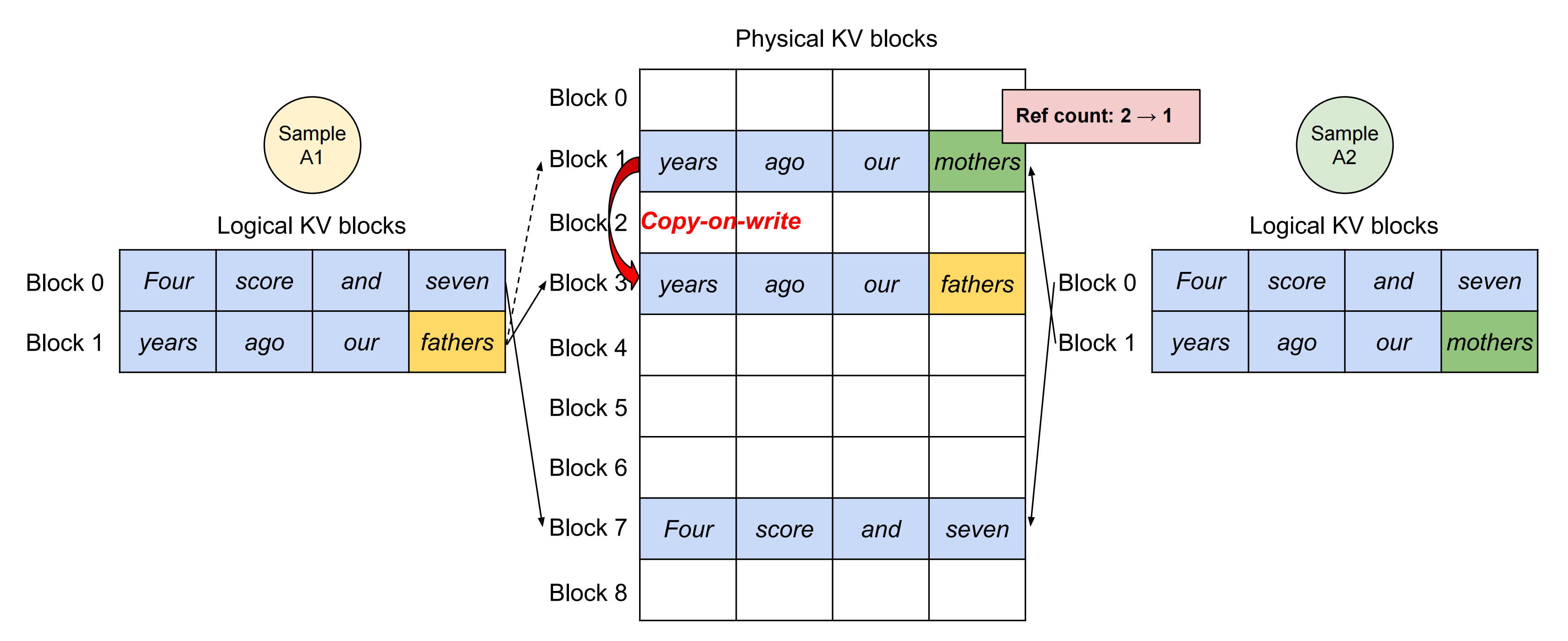
然后,进入decode阶段,A1和A2各自做推理,得到第一个token,分别为fathers和mothers
- 将生成的token装入逻辑块:对于A1和A2来说,将其生成的token装入各自的逻辑块block1
- 触发物理块copy-on-write机制:由于fathers/mothers是两个完全不同的token,因此对物理块block1触发复制机制,即在物理内存上新开辟一块空间block3
此时
物理块block1只和A2的逻辑块block1映射,将其ref count减去1
物理块block3只和A1的逻辑块block1映射,将其ref count设为1
总结起来,vLLM节省KV cache显存的核心思想是,对于相同数据对应的KV cache,能复用则尽量复用;无法复用时,再考虑开辟新的物理空间
1.4.2 束搜索
// 待更
第二部分 我司七月之项目实践:vLLM的使用(含安装、部署、推理)
通过上文的第一部分,我们已经知道
- vLLM 是一个开源的大模型推理加速框架,其通过 PagedAttention 高效地管理attention中缓存的张量,实现了比 HuggingFace Transformers 高14-24倍的吞吐量
- PagedAttention 是 vLLM 的核心技术,它解决了LLM服务中内存的瓶颈问题
毕竟传统的注意力算法在自回归解码过程中,需要将所有输入Token的注意力键和值张量存储在GPU内存中,以生成下一个Token,而这些缓存的键和值张量通常被称为KV缓存
且其在工程应用中 也相对好用,比如
- 通过 PagedAttention 对 KV Cache 的有效管理
- 传入请求的 continus batching,而不是 static batching
- 支持张量并行推理
- 支持流式输出
- 兼容 OpenAI 的接口服务
- 与 HuggingFace 模型无缝集成
接下来,咱们就来看下在实际的项目应用中是如何使用vLLM的(以下内容主要为我司七月在线审稿项目组成员不染所写)
2.1 vLLM的使用:离线推理模型与在线服务的启动
2.1.1 vLLM的安装与离线推理模型
首先,安装vLLM库
pip install vllm -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com问题:vllm=0.3.3要求torch版本是2.1.2,会出现如下环境问题
the vllm whl depend on cupy_cuda12x解决方案:
pip install bitsandbytes==0.39.0然后执行
python -m bitsandbytes其次,离线推理模型
以Llama-2-7b-chat为例,直接用Python代码进行推理
from vllm import LLM
prompts = ["Hello, my name is", "The capital of France is"] # Sample prompts
llm = LLM(model="/path/to/weights/Llama-2-7b-chat") # Create an LLM.
outputs = llm.generate(prompts) # Generate texts from the prompts.存在的问题:同样的模型、参数和prompt条件下,vLLM推理和HuggingFace推理结果不一致。具体请参考:LLM推理4:vllm和HF推理结果不一致
2.1.2 vLLM之在线服务的启动与调动
首先,在线服务启动
- 开启 openai接口 兼容的服务
以 Llama-2-7b-chat-4bit量化模型为例,在48G显卡A40上单GPU运行
参考模型:https://hf-mirror.com/TheBloke/Llama-2-7B-Chat-GPTQpython -m vllm.entrypoints.openai.api_server \ --model /path/to/weights/Llama-2-7b-chat-4bit \ --served-model-name meta/Llama-2-7b-chat-4bit \ --trust-remote-code \ --max-model-len 2048 -q gptq - 以 Llama-2-7b-chat模型为例,在48G显卡A40上多GPU运行
如果单卡显存不够,添加tensor-parallel-size 2,使用2张卡
参考模型:https://hf-mirror.com/meta-llama/Llama-2-7b-chatCUDA_VISIBLE_DEVICES=0,3 python -m vllm.entrypoints.openai.api_server \ --host 0.0.0.0 \ --port 8000 \ --model /path/to/weights/Llama-2-7b-chat \ --served-model-name meta/Llama-2-7b-chat \ --tensor-parallel-size 2 \ --trust-remote-code \ --max-model-len 3000 - 以 Llama-2-7b-chat模型为例,在16G显卡T4上多GPU运行
由于T4只支持float 16,添加dtype half;如果占用显存过大,添加max-num-seqs 32(可调)CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -m vllm.entrypoints.openai.api_server \ --model /path/to/weights/Llama-2-7b-chat \ --served-model-name meta/Llama-2-7b-chat \ --tensor-parallel-size 8 \ --trust-remote-code \ --max-model-len 4096 \ --dtype half \ --max-num-seqs 32 - 以外推 Llama-2-7b-longlora-12k-paper模型长度为例,在48G显卡A40上单GPU运行
在长度外推算法(LongLoRA)训练后,再打开Llama-2-7b-longlora-12k-paper的本地config文件,修改如下的“rope_scaling”中的null
即将下图的null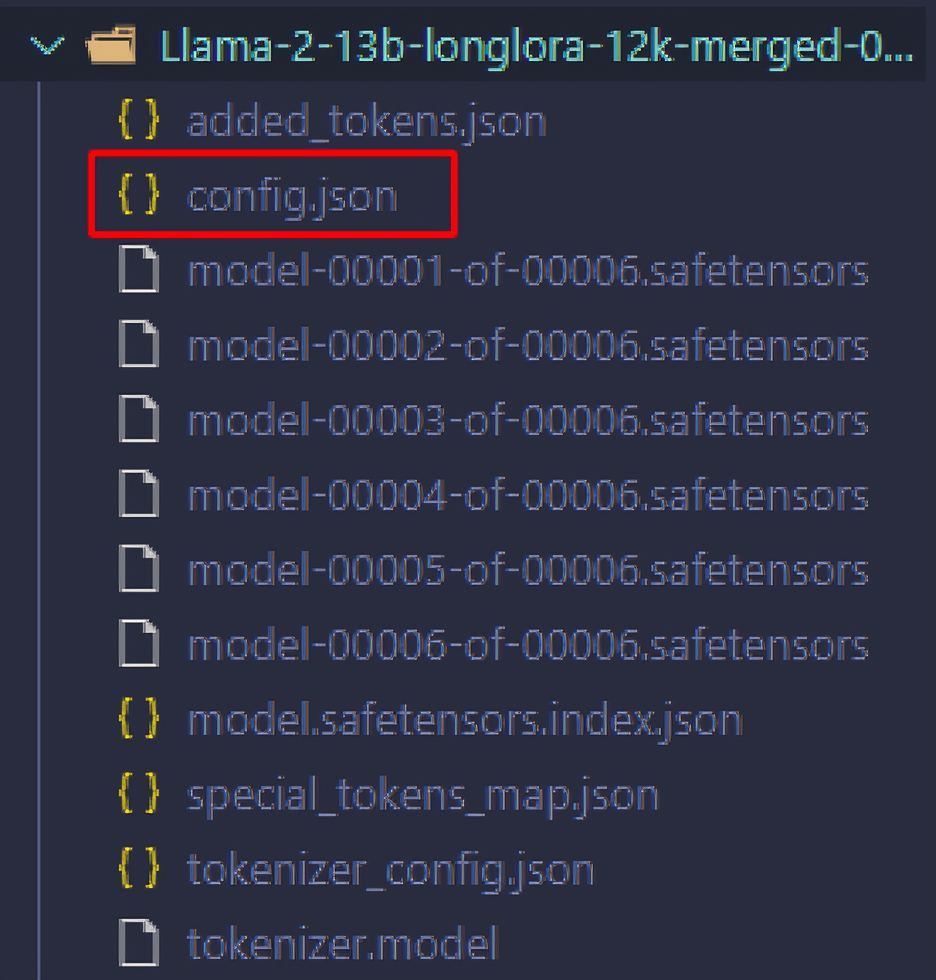
将 null 改为{"type": "linear", "factor": 3.0}。其中数学公式: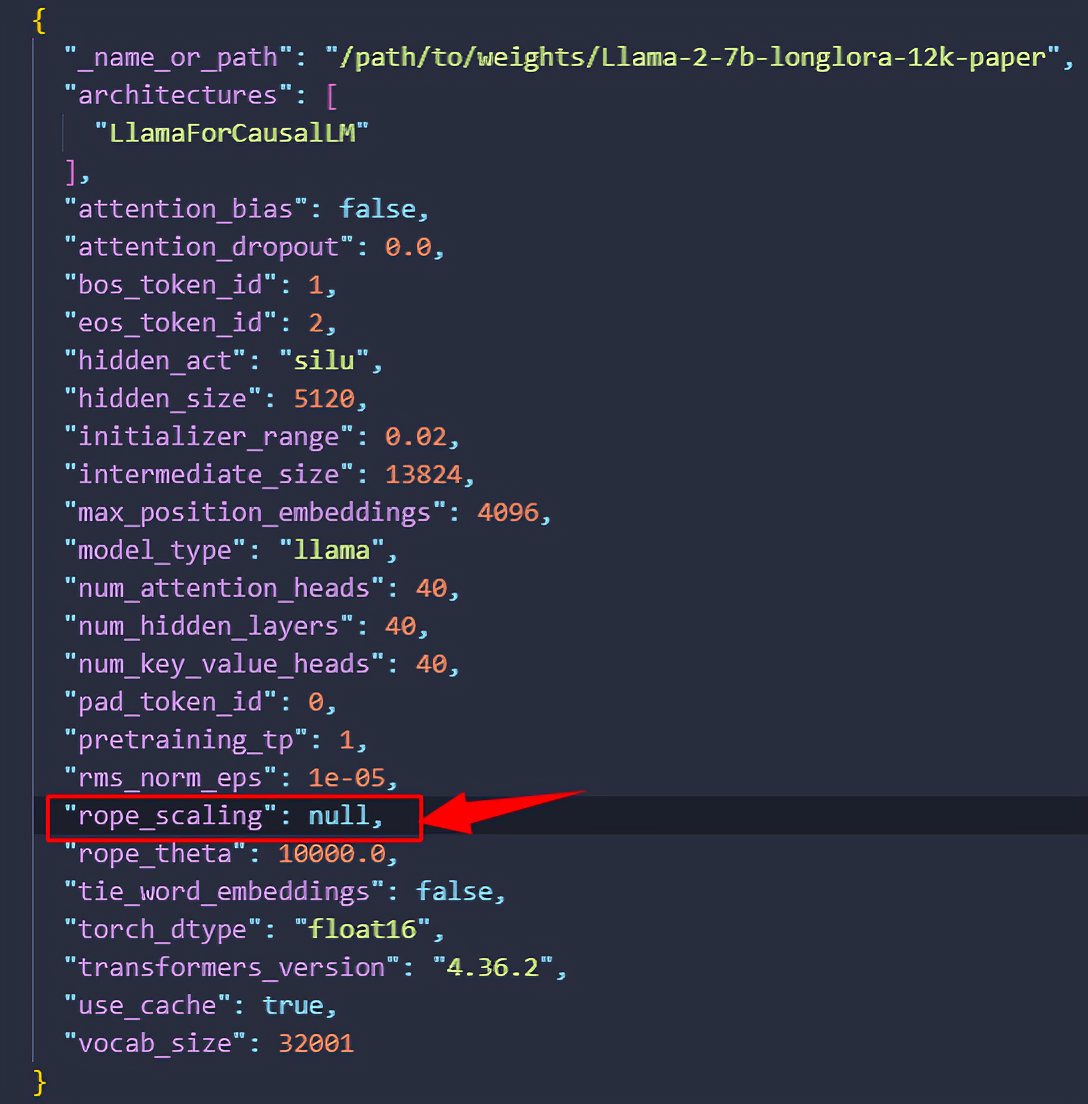
python -m vllm.entrypoints.openai.api_server \ --model /path/to/weights/Llama-2-7b-longlora-12k-paper \ --served-model-name July/Llama-2-7b-longlora-12k-paper \ --trust-remote-code
其次,在线服务调用
使用 curl 测试服务是否可用:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "July/Llama-2-7b-longlora-12k-paper",
"prompt": "What is your name?",
"max_tokens": 7,
"temperature": 0
}'使用 gradio 的 chat 组件测试 openai 兼容的 api server
执行python llama_chat.py --server_port 8001,至于完整的llama_chat.py 代码,请参见七月在线官网的「第三期 大模型项目开发线上营[新增提问VLM等商用项目]」
2.2 基于vLLM部署llama3.1
在此文《微调LLama 3.1——七月论文审稿GPT第5.5版:拿早期paper-review数据集微调LLama 3.1》中,我司审稿项目组使用1.5w paper-review样本微调llama3.1-8b模型,然后基于vLLM上线对外提供服务,详见我司官网首页的「论文审稿GPT项目“llama3.1”模型」
且为了节省GPU资源,审稿项目组成员青睐对llama3.1-8b模型进行4bit量化,推理效果与bf16效果差距不大
2.2.1 环境配置、代码下载、序列抑制、llama3.1量化为4bit
- 环境配置
absl-py==2.1.0 accelerate==0.32.0 aiofiles==23.2.1 aiohappyeyeballs==2.4.0 aiohttp==3.10.5 aiosignal==1.3.1 annotated-types==0.7.0 anyio==4.4.0 asttokens==2.4.1 attrs==24.2.0 audioread==3.0.1 bitsandbytes==0.43.3 certifi==2024.7.4 cffi==1.17.0 charset-normalizer==3.3.2 click==8.1.7 cloudpickle==3.0.0 comm==0.2.2 contourpy==1.2.1 cryptography==43.0.0 cycler==0.12.1 datasets==2.20.0 debugpy==1.8.7 decorator==5.1.1 Deprecated==1.2.14 dill==0.3.8 diskcache==5.6.3 distro==1.9.0 docker-pycreds==0.4.0 docstring_parser==0.16 einops==0.8.0 et-xmlfile==1.1.0 evaluate==0.4.2 exceptiongroup==1.2.2 executing==2.1.0 fastapi==0.112.2 ffmpy==0.4.0 filelock==3.15.4 fire==0.6.0 fonttools==4.53.1 frozenlist==1.4.1 fsspec==2024.5.0 gguf==0.9.1 gitdb==4.0.11 GitPython==3.1.43 gradio==4.42.0 gradio_client==1.3.0 grpcio==1.66.0 h11==0.14.0 hf_transfer==0.1.8 httpcore==1.0.5 httptools==0.6.1 httpx==0.27.0 huggingface-hub==0.24.6 idna==3.8 importlib_metadata==8.4.0 importlib_resources==6.4.4 interegular==0.3.3 ipykernel==6.29.5 ipython==8.29.0 jedi==0.19.1 Jinja2==3.1.4 jiter==0.5.0 joblib==1.4.2 jsonschema==4.23.0 jsonschema-specifications==2023.12.1 jupyter_client==8.6.3 jupyter_core==5.7.2 kiwisolver==1.4.5 lark==1.2.2 lazy_loader==0.4 librosa==0.10.2.post1 llvmlite==0.43.0 lm-format-enforcer==0.10.6 loguru==0.7.2 Markdown==3.7 markdown-it-py==3.0.0 MarkupSafe==2.1.5 matplotlib==3.9.2 matplotlib-inline==0.1.7 mdurl==0.1.2 mpmath==1.3.0 msgpack==1.0.8 msgspec==0.18.6 multidict==6.0.5 multiprocess==0.70.16 nest_asyncio==1.6.0 networkx==3.3 nltk==3.9.1 numba==0.60.0 numpy==1.26.4 nvidia-cublas-cu12==12.1.3.1 nvidia-cuda-cupti-cu12==12.1.105 nvidia-cuda-nvrtc-cu12==12.1.105 nvidia-cuda-runtime-cu12==12.1.105 nvidia-cudnn-cu12==9.1.0.70 nvidia-cufft-cu12==11.0.2.54 nvidia-curand-cu12==10.3.2.106 nvidia-cusolver-cu12==11.4.5.107 nvidia-cusparse-cu12==12.1.0.106 nvidia-ml-py==12.560.30 nvidia-nccl-cu12==2.20.5 nvidia-nvjitlink-cu12==12.6.20 nvidia-nvtx-cu12==12.1.105 openai==1.42.0 openpyxl==3.1.5 orjson==3.10.7 outlines==0.0.46 packaging==24.1 pandas==2.2.2 parso==0.8.4 peft==0.12.0 pexpect==4.9.0 pickleshare==0.7.5 pillow==10.4.0 pip==24.2 platformdirs==4.2.2 pooch==1.8.2 prometheus_client==0.20.0 prometheus-fastapi-instrumentator==7.0.0 prompt_toolkit==3.0.48 protobuf==5.27.3 psutil==6.0.0 ptyprocess==0.7.0 pure_eval==0.2.3 py-cpuinfo==9.0.0 pyairports==2.1.1 pyarrow==17.0.0 pyarrow-hotfix==0.6 pycountry==24.6.1 pycparser==2.22 pydantic==2.8.2 pydantic_core==2.20.1 pydub==0.25.1 PyGithub==2.4.0 Pygments==2.18.0 PyJWT==2.9.0 PyNaCl==1.5.0 pyparsing==3.1.4 python-dateutil==2.9.0.post0 python-dotenv==1.0.1 python-multipart==0.0.9 pytz==2024.1 PyYAML==6.0.2 pyzmq==26.2.0 ray==2.34.0 referencing==0.35.1 regex==2024.7.24 requests==2.32.3 rich==13.8.0 rpds-py==0.20.0 ruff==0.6.2 safetensors==0.4.4 scikit-learn==1.5.1 scipy==1.14.1 semantic-version==2.10.0 sentencepiece==0.2.0 sentry-sdk==2.13.0 setproctitle==1.3.3 setuptools==72.1.0 shellingham==1.5.4 shtab==1.7.1 six==1.16.0 smmap==5.0.1 sniffio==1.3.1 soundfile==0.12.1 soxr==0.5.0 sse-starlette==2.1.3 stack-data==0.6.2 starlette==0.38.2 sympy==1.13.2 tensorboard==2.17.1 tensorboard-data-server==0.7.2 termcolor==2.4.0 threadpoolctl==3.5.0 tiktoken==0.7.0 tokenizers==0.19.1 tomlkit==0.12.0 torch==2.4.0 torchvision==0.19.0 tornado==6.4.1 tqdm==4.66.5 traitlets==5.14.3 transformers==4.44.2 transformers-stream-generator==0.0.5 triton==3.0.0 trl==0.9.6 typer==0.12.5 typing_extensions==4.12.2 tyro==0.8.9 tzdata==2024.1 urllib3==2.2.2 uvicorn==0.30.6 uvloop==0.20.0 vllm==0.5.5 vllm-flash-attn==2.6.1 wandb==0.17.7 watchfiles==0.23.0 wcwidth==0.2.13 websockets==12.0 Werkzeug==3.0.4 wheel==0.43.0 wrapt==1.16.0 xformers==0.0.27.post2 xxhash==3.5.0 yarl==1.9.4 zipp==3.20.1 - 编写上线部署的代码
此份vllm_llama3.1.rar的完整代码,详见七月在线的《第三期 大模型项目开发线上营[新增提问VLM等商用项目]》 - 序列抑制
序列抑制代码实现如下,思想可以概括为当生成的序列命中部分抑制的序列时,将会抑制下一个生成被抑制序列token的概率def sequences_penalty_logits_processor(self, token_ids: Union[List[int], Tuple[int]], # 输入的token序列,可以是列表或元组 logits: torch.Tensor, # 输入的logits张量 ) -> torch.Tensor: # 返回处理后的logits张量 sequences_penalty_factor = self.sequences_penalty_factor # 获取序列惩罚因子 target_sequences_ids = self.target_sequences_ids # 获取目标序列的ID列表 # 断言确保token_ids是列表或元组,且为一维;确保logits是一维张量 assert isinstance(token_ids, (list, tuple)) and \ np.array(token_ids).ndim == 1 and \ isinstance(logits, torch.Tensor) and logits.ndim == 1, f"'token_ids' and 'logits' must be list or tuple with 1D shape, and 'scores' must be torch.Tensor with 1D shape, but got {type(token_ids)} and {type(logits)} with {logits.ndim}D shape." if isinstance(token_ids, tuple): # 如果token_ids是元组,转换为列表 token_ids = list(token_ids) # 计算目标序列的最大长度 max_seq_length = max([len(i) for i in target_sequences_ids]) # 获取当前上下文,长度不超过最大序列长度 context = token_ids[-max_seq_length:] if token_ids else [] context_length = len(context) # 当前上下文的长度 # 遍历每个目标序列 for target_sequence in target_sequences_ids: seq_length = len(target_sequence) # 目标序列的长度 # 如果目标序列长度为1,直接应用惩罚因子 if seq_length == 1: next_token = torch.tensor(target_sequence, device=logits.device) # 获取下一个token logits[next_token] = logits[next_token] * sequences_penalty_factor # 应用惩罚因子 else: # 遍历上下文和目标序列的匹配长度 for i in range(1, min(seq_length, context_length) + 1): # 如果上下文的后i个token与目标序列的前i个token匹配 if context[-i:] == target_sequence[: - llama3.1量化为4bit
使用awq直接将llama3.1量化为 4bit模型
代码详见七月在线的《第三期 大模型项目开发线上营[新增提问VLM等商用项目]》
2.2.2 运行服务
首先,运行如下代码
nohup bash server_api/run_server_llama3.1.sh >> server_api/nohup_llama3.1_server.log 2>&1 &下面是其中的部分参数
python server_api/api_server_llama3.1.py --port 2000 \
--host 0.0.0.0 \
--model /root/autodl-tmp/merge/Meta-Llama-3.1-8B-Instruct_merged_checkpoint-1800-awq \
--tokenizer /root/autodl-tmp/merge/Meta-Llama-3.1-8B-Instruct_merged_checkpoint-1800 \
--served-model-name llama3.1-8b \
--api-key sk-july.com \
--max-model-len 12288 \
--quantization "awq_marlin" \
--cpu-offload-gb 0.5 \
--max-parallel-loading-workers 2 \
--gpu-memory-utilization 0.36 \
--max-seq-len-to-capture 8192 \
--disable-log-stats \
--disable-frontend-multiprocessing这是对上面参数的解释
参数
解析
port
端口号
host
0.0.0.0
model
模型的路径
tokenizer
tokenizer 路径
served-model-name
自定义api请求的模型名
api-key
自定义api-key
max-model-len
自定义最大的模型长度
quantization
量化方式
cpu-offload-gb
cpu卸载参数的大小,单位为GB
max-parallel-loading-workers
分批加载模型参数的数量
gpu-memory-utilization
最大的GPU占用比例
// 待更