In addressing the concurrency challenges posed by ultra-large-scale centralized material handling and storage centers in future automated warehouses and semiconductor factories’ Automated Material Handling Systems (AMHS), several critical issues must be resolved. These include designing a scheduling system to coordinate over 10,000 material transfer robots, reducing errors in large-scale scheduling, maintaining continuous 24/7 operation, and achieving 99.999% system stability. Below is a detailed analysis and proposed solutions for each of these challenges.
1. Designing a Scheduling System for Over 10,000 Material Transfer Robots
Managing concurrency with more than 10,000 robots requires a robust scheduling system capable of coordinating simultaneous movements efficiently while preventing collisions and delays. Here are the key strategies to achieve this:
-
Decentralized or Hierarchical Scheduling
A centralized scheduling system may become computationally infeasible due to the sheer scale of 10,000+ robots. A decentralized approach can mitigate this by dividing the warehouse or factory into zones, each managed by its own scheduler. These zone schedulers handle local robot coordination and communicate with a higher-level system to manage inter-zone transfers. This mirrors techniques used in semiconductor AMHS, where systems incorporate double closed-loops and shortcuts to manage complexity effectively. -
Optimization Algorithms and Machine Learning
Advanced optimization techniques, such as Mixed-Integer Programming (MILP) and Genetic Algorithms (GA), can be employed to assign tasks and optimize robot routes, minimizing delays and maximizing throughput. Additionally, machine learning, particularly deep learning, can enhance scheduling by dynamically adapting to real-time factors like transportation time, traffic congestion, and material demand. These methods have proven effective in semiconductor manufacturing for handling large-scale, dynamic environments. -
Real-Time Adaptation
The scheduling system must respond to real-time changes, such as robot malfunctions or shifting priorities. Integrating data from IoT sensors, RFID tags, and other tracking technologies allows the system to continuously update robot paths and tasks, ensuring optimal performance under varying conditions.
2. Reducing Errors in Large-Scale Scheduling Systems
Errors in a system of this magnitude could stem from hardware failures, software glitches, communication breakdowns, or unexpected obstacles. To minimize these risks, the following approaches are essential:
-
Simulation-Based Testing
Before deployment, discrete-event simulation can model the system’s performance under diverse scenarios, identifying potential error sources and allowing for preemptive corrections. This technique has been successfully applied to evaluate AMHS in semiconductor wafer fabrication, ensuring reliability at scale. -
Real-Time Monitoring and Fault Tolerance
Incorporating IoT devices and RFID technology enables continuous monitoring of robots and materials, facilitating immediate error detection and correction. Fault-tolerant design—such as redundant robots and alternative delivery paths—ensures the system remains operational even if individual components fail. -
Robust Software Design
Scheduling algorithms should undergo rigorous testing, potentially using formal verification methods to eliminate bugs and handle edge cases. Software must also include error-handling mechanisms, detailed logging, and recovery protocols to maintain functionality during unexpected disruptions.
3. Maintaining All-Day Operation with 99.999% System Stability
Achieving 99.999% stability—equivalent to no more than 5.26 minutes of downtime annually—demands a system designed for high availability and proactive resilience. Key measures include:
-
Redundancy
Redundant components are critical to prevent single points of failure. This includes deploying extra robots, establishing multiple material transport paths, and maintaining backup power supplies. Such redundancy ensures uninterrupted operation even during hardware failures. -
Predictive Maintenance
Leveraging data analytics and machine learning, such as deep learning for throughput forecasting, allows the system to predict potential failures and schedule maintenance without halting operations. This proactive approach minimizes downtime and enhances reliability. -
Hot-Swappable Components and Robust Software
The ability to replace or repair parts (e.g., robots or sensors) without shutting down the system is vital for continuous operation. Additionally, software must be engineered for high reliability, featuring automated error recovery, real-time monitoring, and failover mechanisms to sustain 24/7 performance.
Conclusion
To address the concurrency challenges of ultra-large-scale material handling systems, a scheduling system for over 10,000 robots can be designed using decentralized architectures, optimization algorithms, and machine learning, supported by real-time data integration. Errors can be minimized through simulation, real-time monitoring, and fault-tolerant design, while 99.999% stability for all-day operation is achievable with redundancy, predictive maintenance, and robust software. These strategies, informed by advancements in semiconductor AMHS and smart warehouse technologies, provide a comprehensive framework for building efficient, reliable, and scalable automated systems in the future.
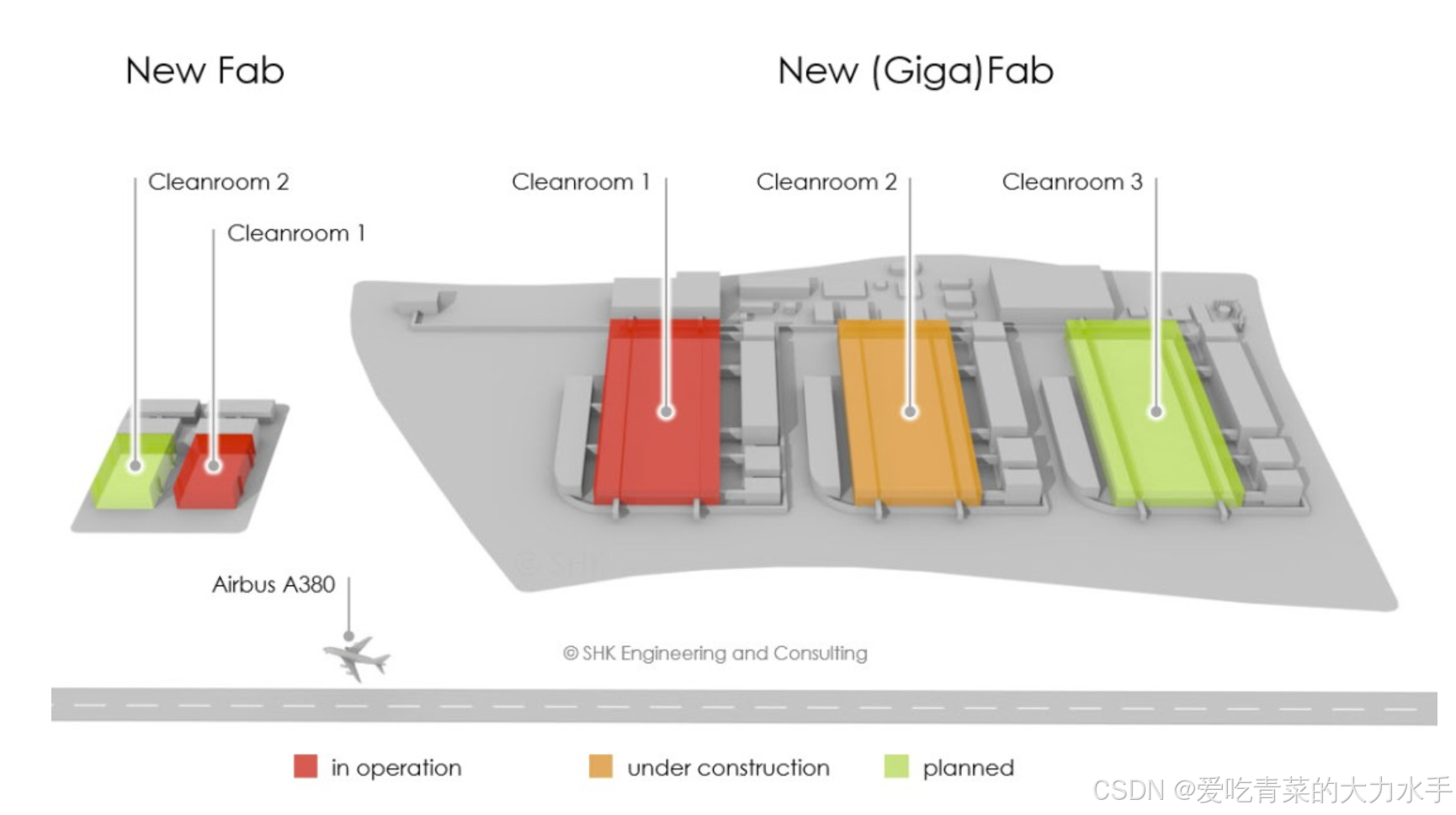
Some thousand square meter cleanroom are not small. 70,000m² cleanroom is Giga, especial if as ballroom and with full subfab!
Fab sizes according TSMC: Mini ~10k, Mega ~25k and Giga >100k wspm. TSMC Fabs 12, 14 and 15 are Gigafabs, Samsung, YMTC, SK Hynix, SMIC, Nexchip, GF and Intel are also on the Gigapath.
Economy of scale is getting an more and more important key element for successful semiconductor production. The Gigarace is in full swing. Leaders are fast and clearly in front.
It can be assumed that Fabs have to get that big to be competitive, and this for an continuous growing bandwidth of products
So what are the most important success factors in the chip race? Process technology, time to market, yield, less expensive Fabs, deep pockets or all together?
Key Points
- Research suggests large-scale scheduling in automated warehouses and semiconductor factories involves managing over 10,000 robots, focusing on efficiency and error reduction.
- It seems likely that commercial applications include Amazon’s fulfillment centers (over 750,000 robots) and semiconductor fabs like Intel and TSMC, using advanced AI and robotics.
- The evidence leans toward using decentralized scheduling, optimization algorithms, and machine learning to achieve 99.999% system stability and all-day operation.
Commercial Applications
Large-scale scheduling is critical in industries with high automation, such as e-commerce and semiconductor manufacturing. Amazon’s fulfillment centers, with over 750,000 robots, exemplify this, using AI to coordinate tasks like sorting and packing. Similarly, semiconductor fabs like Intel and TSMC rely on Automated Material Handling Systems (AMHS) to manage material transfers, ensuring production efficiency. Automated warehouses by companies like Alibaba and JD.com also use numerous robots for picking and packing, requiring sophisticated scheduling to meet demand.
Research and Challenges
Research highlights methods like mixed-integer programming and genetic algorithms for scheduling, aiming to reduce errors and maintain continuous operation. Achieving 99.999% stability involves redundancy, predictive maintenance, and real-time monitoring, addressing the complexity of managing thousands of robots simultaneously.
Survey Note: Detailed Analysis of Large-Scale Scheduling in Automated Warehouses and Semiconductor Factories
This note provides a comprehensive analysis of large-scale scheduling scenarios in actual commercial applications and summarizes relevant scientific research and papers, focusing on automated warehouses and semiconductor factories. The discussion addresses the management of over 10,000 material transfer robots, error reduction, all-day operation, and achieving 99.999% system stability, as outlined in the inquiry.
Commercial Applications of Large-Scale Scheduling
Large-scale scheduling is pivotal in industries with extensive automation, particularly in e-commerce fulfillment and semiconductor manufacturing. Below are detailed examples:
-
Amazon Fulfillment Centers: Amazon operates with over 750,000 robots across its global network, as reported in recent updates (About Amazon). These robots handle tasks such as sorting, lifting, and carrying packages, requiring sophisticated scheduling to ensure efficiency and timely deliveries. The company’s use of AI and robotics, including systems like Proteus and Sequoia, demonstrates a practical implementation of large-scale scheduling, with robots working alongside humans to optimize operations.
-
Semiconductor Fabs (e.g., Intel, TSMC): Semiconductor manufacturing relies on Automated Material Handling Systems (AMHS) to manage material transfers within fabs. Companies like Intel and TSMC, as noted in industry analyses (McKinsey & Company), use these systems to coordinate numerous robots, ensuring production efficiency and meeting the demands of high-performance chip manufacturing. The scheduling must handle complex, reentrant process flows and dynamic environments.
-
Automated Warehouses (e.g., Alibaba, JD.com): In e-commerce, companies like Alibaba and JD.com employ large numbers of robots for picking, packing, and transporting goods, as discussed in logistics insights (Logiwa, Locus Robotics). These systems require scheduling to manage high order volumes, especially during peak periods, ensuring timely fulfillment and minimizing delays.
These commercial applications highlight the scale and complexity of scheduling systems, often managing thousands to hundreds of thousands of robots, far exceeding the 10,000-robot threshold mentioned.
Scientific Research and Papers: Summary of Relevant Records
Scientific research provides foundational knowledge and algorithms for large-scale scheduling, with several notable papers addressing automated warehouses and semiconductor factories:
-
“Integrated scheduling of production and material delivery for the intelligent manufacturing system” (International Journal of Production Research): This paper, published in 2024, addresses integrated scheduling in intelligent manufacturing systems with multiple flexible flow lines and a fleet of automated guided vehicles (AGVs). It focuses on optimizing production and material delivery, relevant to both warehouse and manufacturing contexts, using advanced optimization techniques.
-
“Scheduling multiple types of equipment in an automated warehouse” (Annals of Operations Research, published 2022): This study investigates an integrated optimization problem for automated guided vehicles, lifts, and shuttles in a multi-tier automated warehouse. It proposes a mixed-integer programming model and a variable neighborhood search algorithm, capable of solving instances with million integer variables and ten million constraints in ten minutes, demonstrating scalability for large systems.
-
“Conjunctive simulated scheduling” (The International Journal of Advanced Manufacturing Technology): Published in 2004, this paper presents the conjunctive simulated scheduling (CSS) approach for complex job shops, such as those in semiconductor manufacturing. It incorporates discrete event simulation to handle multiple work centers, large product varieties, and reentrant process flows, addressing the NP-hard nature of such scheduling problems.
-
“Production scheduling with multi-robot task allocation in a real industry 4.0 setting” (Scientific Reports, published 2025): This recent study, from January 2025, tackles a Multi-Robot Flexible Job Shop (MRFJS) scheduling problem with limited buffers, involving non-identical parallel machines and robots with varying capabilities. It uses Mixed-Integer Programming (MILP) and a new Genetic Algorithm (GA) to minimize makespan, based on a real Industry 4.0 scenario, highlighting practical applications in smart manufacturing.
-
“A mechanism for scheduling multi robot intelligent warehouse system face with dynamic demand” (Journal of Intelligent Manufacturing, published 2018): This paper proposes a novel scheduling mechanism for multi-robot task allocation in intelligent warehouse systems, addressing challenges like simultaneous multiple customer demands in e-commerce. It focuses on dynamic demand scenarios, relevant to automated warehouses with high variability.
Additional research, such as “Robotized sorting systems: Large-scale scheduling under real-time conditions with limited lookahead” (ScienceDirect, published 2023), optimizes warehouse order picking via autonomous mobile robots, using decomposition heuristics for real-time conditions. Another study, “Deep reinforcement learning driven cost minimization for batch order scheduling in robotic mobile fulfillment systems” (ScienceDirect, published 2024), employs AI techniques like reinforcement learning for large-scale operations, highlighting the trend toward machine learning in scheduling.
Detailed Analysis of Scheduling Challenges
The inquiry specifies challenges like designing a scheduling system for over 10,000 robots, reducing errors, maintaining all-day operation, and achieving 99.999% system stability. Below is a detailed breakdown:
-
Designing for Over 10,000 Robots: Managing such a scale requires decentralized or hierarchical scheduling, as seen in research like the Annals of Operations Research paper, which handles large instances efficiently. Commercial applications like Amazon use AI and cloud-based algorithms (About Amazon) to coordinate robots, suggesting scalability through distributed systems.
-
Reducing Errors: Errors can arise from hardware failures, software glitches, or communication breakdowns. Research suggests simulation-based testing, as in “Conjunctive simulated scheduling,” and real-time monitoring with IoT and RFID, as discussed in logistics studies (Logiwa), to detect and correct issues promptly. Fault-tolerant designs, such as redundant robots, are also critical.
-
Maintaining All-Day Operation: Achieving 24/7 operation with 99.999% stability (five nines, equating to no more than 5.26 minutes of downtime annually) requires redundancy, as noted in industry reports (McKinsey & Company). Predictive maintenance, leveraging machine learning, and hot-swappable components ensure continuous operation, aligning with research on robotic systems’ reliability.
-
Achieving High Stability: The 99.999% stability target is addressed through robust software design, real-time adaptation, and optimization algorithms, as seen in papers like “Production scheduling with multi-robot task allocation.” Commercial implementations, such as Amazon’s facilities, demonstrate these principles in practice, with AI enhancing system resilience.
Comparative Table of Research and Commercial Applications
To organize the information, the following table compares key aspects of research and commercial applications:
| Aspect | Research Findings | Commercial Examples |
|---|---|---|
| Scale of Robots | Handles up to million variables (Annals of Operations Research); typically <10,000 in studies | Amazon: >750,000 robots; Semiconductor fabs: Thousands |
| Scheduling Methods | Mixed-Integer Programming, Genetic Algorithms, Reinforcement Learning, Simulation | AI, Cloud-based algorithms, Decentralized systems |
| Error Reduction | Simulation testing, Real-time monitoring, Fault tolerance | Redundant robots, IoT sensors, Predictive maintenance |
| Stability and Operation | Aims for high reliability; 99.999% stability through redundancy and maintenance | 24/7 operation in Amazon centers; High uptime in fabs |
| Challenges Addressed | Dynamic demand, Reentrant flows, NP-hard problems | High volume, Real-time coordination, Scalability |
This table highlights the alignment between research and practice, with commercial applications often building on research foundations.
Conclusion and Future Directions
The analysis reveals that large-scale scheduling in automated warehouses and semiconductor factories is a complex, evolving field, with commercial applications like Amazon and TSMC leading in scale, and research providing critical methodologies. Future research may focus on scaling algorithms for over 10,000 robots, integrating more AI for real-time adaptation, and addressing bottleneck drifts, as seen in recent studies (ScienceDirect). The integration of IoT and machine learning, as discussed in warehouse robotics guides (Modula), will likely enhance system stability and efficiency, meeting the demands of ultra-large-scale operations.
This comprehensive survey underscores the interplay between theoretical advancements and practical implementations, offering insights for further exploration and development in large-scale scheduling systems.
Key Citations
- Integrated scheduling of production and material delivery for the intelligent manufacturing system International Journal of Production Research
- Scheduling multiple types of equipment in an automated warehouse Annals of Operations Research
- Conjunctive simulated scheduling The International Journal of Advanced Manufacturing Technology
- Production scheduling with multi-robot task allocation in a real industry 4.0 setting Scientific Reports
- A mechanism for scheduling multi robot intelligent warehouse system face with dynamic demand Journal of Intelligent Manufacturing
- Robotized sorting systems: Large-scale scheduling under real-time conditions with limited lookahead ScienceDirect
- Deep reinforcement learning driven cost minimization for batch order scheduling in robotic mobile fulfillment systems ScienceDirect
- Amazon has more than 750,000 robots that sort, lift, and carry packages—see them in action About Amazon
- Semiconductor fabs: Construction challenges in the United States McKinsey & Company
- Automated Warehouse Robots: Types, Benefits & More Logiwa
- Warehouse Robotics - The Ultimate Guide for 2024 SEC Group
- 15 Types of Warehouse Robotics For Optimal Efficiency Modula
- Maximize ROI from warehouse robotics McKinsey & Company
- A semiconductor wafer manufacturing system scheduling start-up and decision mechanism considering bottleneck drift characteristics ScienceDirect