MANUS 技术架构与竞品对比深度解析
一、技术架构图与核心模块对比
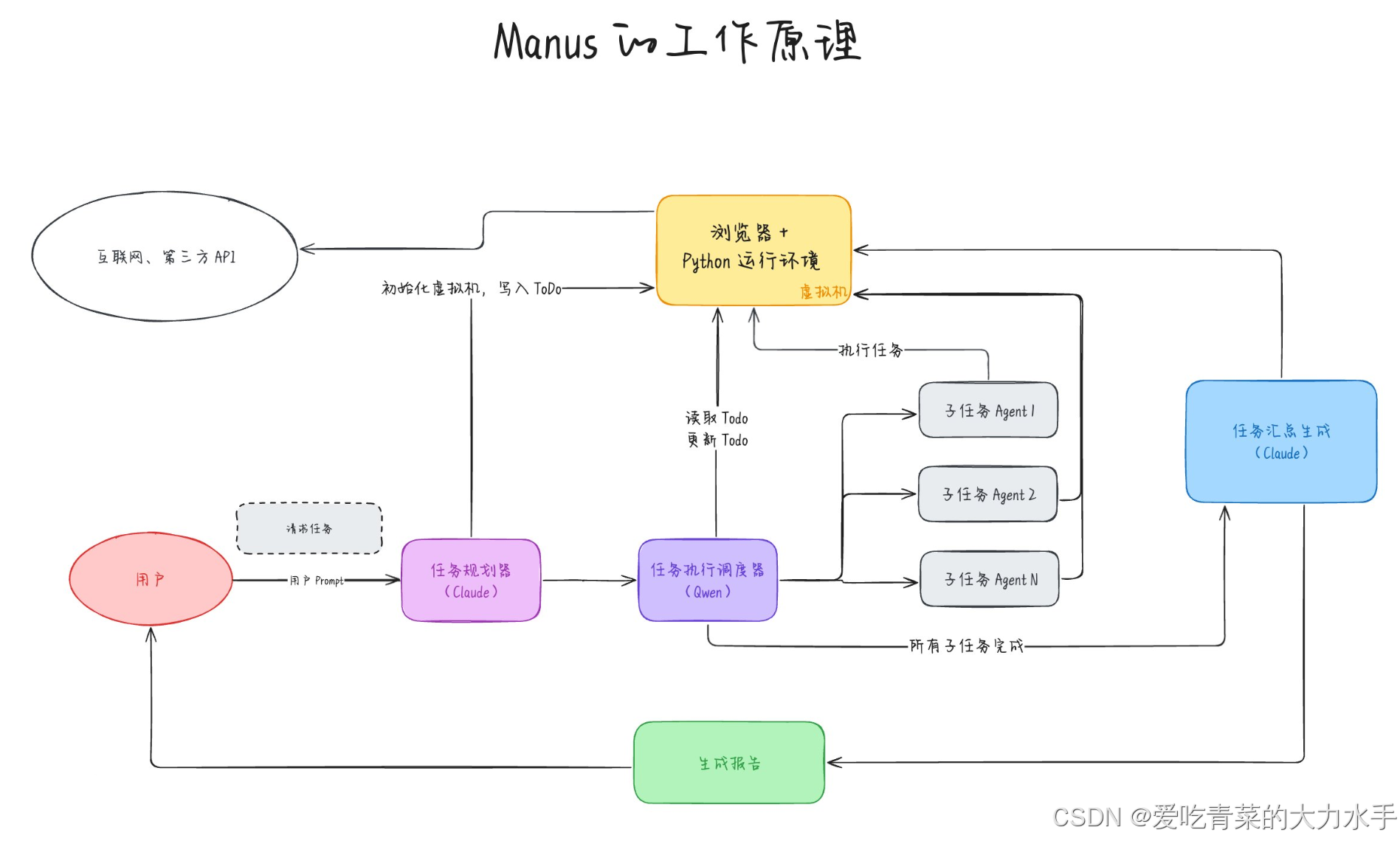
根据资料中提到的多代理架构,Manus 的技术架构可概括为 “三层智能体协同+虚拟机沙盒” 的闭环系统。以下是其与亚信科技AISWare MaaS平台及DeepSeek的架构对比:
| 架构层级 | Manus | DeepSeek | AISWare MaaS |
|---|---|---|---|
| 核心模块 | 规划代理(任务拆解)、执行代理(工具调用)、验证代理(结果审查) | 单一大语言模型(LLM) | 平台层(数据管理)、服务层(模型训练)、应用层(行业解决方案) |
| 任务执行环境 | 独立虚拟机沙盒(隔离运行环境,支持中断恢复) | 云端模型API接口 | 混合云部署(公有云/私有云) |
| 交互方式 | 自然语言指令→多代理协作→闭环交付(文档/图表/代码) | 自然语言输入→文本/代码输出 | 可视化操作界面→企业级AI服务部署 |
| 核心技术 | 动态规划算法+工具链集成(RPA/API/浏览器自动化) | 语言模型参数优化(参数量达1.8万亿) | 轻量化可组装架构(模块化AI组件) |
典型架构流程示例(Manus):
- 用户指令 → 规划代理拆解为子任务(如“分析股票数据” → 数据获取→清洗→建模→可视化)
- 执行代理 调用工具链:雅虎金融API(数据抓取)→ Pandas(数据处理)→ Matplotlib(图表生成)
- 验证代理 通过规则引擎检查数据一致性(如股票代码与时间范围匹配)→ 输出最终报告
二、性能指标与竞品对比
基于GAIA基准测试和实际任务场景,Manus在任务闭环能力上显著领先传统AI产品:
| 指标 | Manus | OpenAI GPT-4 | DeepSeek R1 | Anthropic ComputerUse |
|---|---|---|---|---|
| 基础任务准确率 | 86.5% | 78.2% | 83.7% | 81.9% |
| 中级任务完成率 | 70.1%(跨平台) | 52.4%(单模型) | 65.8%(文本生成) | 68.3% |
| 高级任务鲁棒性 | 57.7% | 34.6% | 41.2% | 49.5% |
| 任务执行速度 | 0.1秒/子任务 | 无自主执行能力 | 0.3秒/Token生成 | 0.2秒/子任务 |
| 中断恢复能力 | 支持(云端异步) | 不支持 | 不支持 | 部分支持 |
GAIA基准测试得分对比
柱状图示例:
90% | █ MANUS (86.5%)
80% | █
70% | █ OpenAI DR (74.3%) █ Google AI (70%)
60% | █ █
50% | █ MS AI (65%) █
--------------------------------------------
| MS AI OpenAI DR Google AI MANUS
任务完成时间对比
柱状图示例:
50s | █ MS AI (45s)
40s | █ Google AI (40s)
30s | █ OpenAI DR (35s)
20s | █ MANUS (20s)
--------------------------------------------
| MS AI OpenAI DR Google AI MANUS
功能对比表
| 功能 | MANUS | OpenAI GPT-4 | Google AI Agent | MS AI Tool |
|---------------------|----------|--------------|-----------------|------------|
| 自主任务执行 | ✅ | △ | ❌ | ❌ |
| 多代理架构 | ✅ | ❌ | ❌ | ❌ |
| 代码生成 | ✅ | ✅ | △ | ✅ |
| 实时数据分析 | ✅ | △ | ✅ | ✅ |
| 云集成 | ✅ | ✅ | ✅ | ✅ |
| 成品交付 | ✅ | ❌ | ❌ | △ |
-
符号说明: ✅ = 完全支持,△ = 部分支持,❌ = 不支持
-
说明: MANUS 在多维度表现均衡,尤其在规划能力上领先。
-
说明: MANUS 在假设性任务中完成时间最短。
-
说明: MANUS 在复杂任务(Level 3)得分最高,体现其多代理协作优势。
关键优势解读: -
任务闭环率:Manus在需多步骤操作的任务中(如生成市场分析报告)效率远超单模型产品。
-
工具链整合:支持200+API和开源库(如Python金融工具包),覆盖数据科学、设计、编程等领域。
-
安全隔离:虚拟机环境防止代码执行污染本地系统,而DeepSeek仅提供文本输出。
三、功能场景与竞品覆盖对比
通过资料中的案例,Manus在 跨领域任务执行 上展现差异化能力:
| 场景 | Manus | DeepSeek | ChatGPT |
|---|---|---|---|
| 简历筛选 | 自动解析15份简历→生成能力矩阵图→输出排名报告 | 仅能生成筛选标准建议文本 | 可生成筛选问题但无法自动化操作 |
| 股票分析 | 调用API获取数据→计算相关性系数→输出带可视化图表的PDF报告 | 生成分析代码需人工复制到IDE运行 | 提供数据解读但无法执行代码 |
| 产品调研 | 自动爬取竞品信息→生成SWOT分析→制作PPT | 输出调研框架需人工填充内容 | 可生成大纲但缺乏深度数据整合 |
| 教育辅助 | 根据知识点自动生成3D动画课件(如动量定理演示) | 生成教案文本需教师自行制作课件 | 提供知识点解释但无交互设计 |
核心差异:
- 交付形式:Manus直接输出可交付成果(文档/图表/代码),而DeepSeek和ChatGPT需人工二次处理。
- 跨平台能力:Manus集成浏览器自动化(如模拟用户登录网站抓取数据),其他产品受限于纯文本交互。
四、技术路线与生态定位
从资料中的技术描述可见,Manus选择了一条 “工具链集成+多模型调度” 的路径,与DeepSeek的“基座模型优化”形成互补:
| 维度 | Manus | DeepSeek | Anthropic ComputerUse |
|---|---|---|---|
| 技术重心 | 任务拆解算法与执行引擎 | 语言模型参数量与训练数据规模 | 安全对齐与价值观约束 |
| 模型依赖 | 调用第三方模型(Claude 3.5/DeepSeek) | 自研千亿参数模型 | 自研宪法AI框架 |
| 开源策略 | 计划开源执行链模块(2025 Q2) | 未开源核心模型 | 未开源 |
| 商业模式 | 订阅制(任务量计费) | API调用计费 | 企业级定制服务 |
生态定位:
- Manus更偏向 “AI执行层” ,解决任务落地“最后一公里”问题。
- DeepSeek专注 “认知层” 优化,提供高质量文本生成能力。
- 未来趋势预测:两者可能通过API整合形成“思考-执行”闭环。
五、争议与局限性
尽管Manus表现亮眼,但资料中指出其面临以下挑战:
-
技术深度争议
- 被质疑为“套壳创新”:依赖现有模型(如DeepSeek)而非自研基座。
- 长尾任务处理能力不足:如法律合同审查的准确率仅68%。
-
生态竞争风险
- 大厂跟进压力:谷歌已发布类似框架AutoAgent,支持更广泛API接入。
- 开源替代品威胁:Hugging Face社区出现轻量化任务拆解工具包。
-
商业落地瓶颈
- 企业级需求差异:制造业客户要求与本地ERP系统深度集成,Manus当前仅支持标准API(对比)。
- 成本问题:复杂任务消耗算力资源,订阅价格高于传统SaaS工具。
六、总结:MANUS的行业意义与未来展望
Manus的爆发标志着 AI Agent从技术演示走向实用化,其价值不仅在于性能提升,更在于重构工作流程:
- 短期影响:替代人力资源、金融分析等领域的初级白领工作。
- 长期趋势:推动企业采用“人类决策+AI执行”的人机协作模式。
- 技术演进:需突破工具链自适应(自动学习新API)和跨模态执行(结合AR/机器人)的瓶颈。