随着人工智能技术的不断发展,嵌入模型和矢量数据库已经成为 AI 应用中不可或缺的组成部分。SpringAI 提供了对这些技术的强大支持,允许开发者在 Spring 环境中轻松实现基于嵌入的模型和矢量数据库的应用。本文将介绍 SpringAI 如何实现嵌入模型和矢量数据库的集成及其应用场景
1. 嵌入模型简介
嵌入(Embedding)是将高维数据(如文本、图像等)映射到低维空间的过程,通常是通过神经网络模型学习到的表示。在 NLP(自然语言处理)领域,嵌入模型被广泛用于将单词、句子或段落转化为固定长度的向量,这些向量能更好地表示文本的语义特征。
例如,在 SpringAI 中,我们通过集成 OpenAI 的模型来实现文本的嵌入。嵌入模型通常通过模型训练将输入的文本数据转化为向量表示,这些向量可以用于进一步的文本分析、语义匹配或搜索等任务。
嵌入模型的常见应用场景
- 文本相似度计算:通过将文本转换为向量,可以计算不同文本之间的相似度,适用于推荐系统、搜索引擎等。
- 分类与聚类:使用嵌入模型进行数据的分类或聚类分析,可以帮助识别相似的主题或分组。
- 问答系统:将问题和答案转化为嵌入向量,通过比较向量的相似度来找到最相关的答案。
模型的获取
首先还是接上一篇的配置,我们先去申请一个推理模型,也是免费的
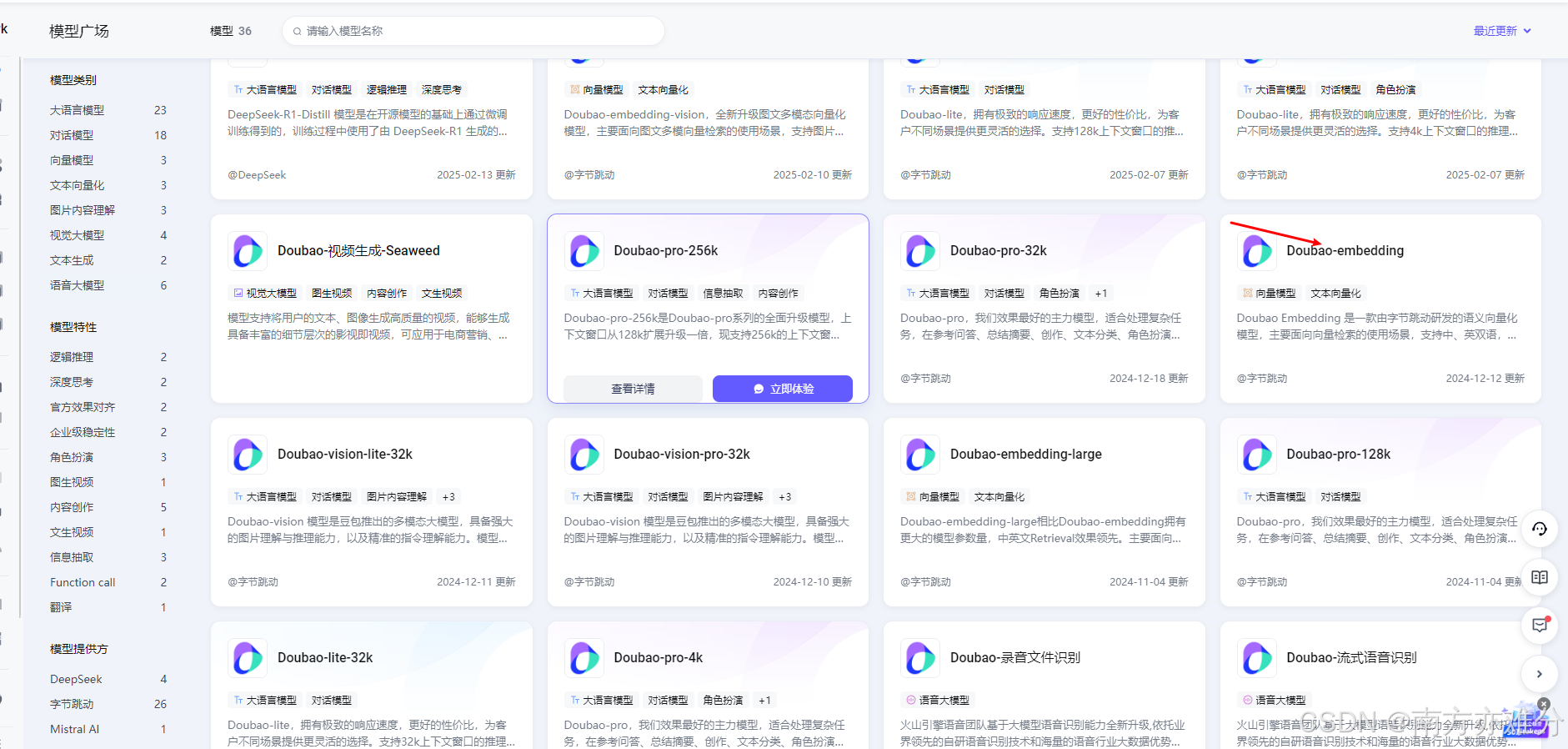
然后创建推理,在oneapi中添加,和上一篇文章一致,在渠道中添加新的向量推理key

然后更新令牌,填入推理key
2. 矢量数据库的介绍
矢量数据库(Vector Database)是专门用于存储和管理向量数据的数据库,通常用于高效的相似度搜索。矢量数据库通过存储经过嵌入模型处理后的向量,可以快速地进行相似度检索、最近邻搜索等操作。
在传统的数据库中,我们依赖于 SQL 查询来检索信息,但在矢量数据库中,我们使用基于 距离度量(如欧氏距离、余弦相似度等)的查询来进行检索。常见的矢量数据库包括 FAISS、