软件分析是由南京大学李樾老师和谭添老师共同开设的一门课程。本文旨在解析南京大学软件分析期末考纲中的各个考点,内容均为笔者根据课程ppt以及静态分析课程笔记整理所得。
全文约1.8万字,适合学完该课程的同学进行查缺补漏考前突击。
本文针对考纲进行解析,便于同学们根据考纲复习重点内容。详细细节可以根据课程ppt和静态分析笔记查缺补漏。
目录
4. 抽象abstraction与过近似over-approximation
3. 控制流分析(Control Flow Analysis, CFA)

10. 迭代算法与MOP(meet-over-all-paths)算法的精度对比
1. 使用类层次结构分析(CHA)来构建调用图(call graph)
11. 即时调用图构建(On-the-fly Call Graph Construction)的含义
12. 什么是上下文敏感(Context Sensitive C.S.)
14. 为什么C.S.和C.S. Heap能够提高分析精度:
17. 上下文敏感性的变体(Context Sensitivity Variants)
1. 信息流安全的概念(Information flow sensitive)
3. 什么是显式流Explicit,什么是隐蔽信道Covert Channels?
一、 软件分析概述
1. 静态分析和动态测试的区别?
- 定义:静态分析(Static Analysis) 是指在实际运行程序 P 之前,通过分析静态程序 P 本身来推测程序的行为,并判断程序是否满足某些特定的性质(Property):类私有信息泄露?类型转换是否合理?空指针?某些指针是否指向同一对象?;动态测试会根据被测试程序设计测试用例,通过动态运行代码检查程序是否能够通过所有用例。
- 目的:分析在于分析程序的性质,提高程序可靠性reliability、安全性security,进行编译器优化compiler optimization,有助于程序理解program understanding;测试在于发现程序中的bug,保证程序对于正确的输入能够给出正确的输出。
2. 概念理解
- 定义静态分析S对于程序P的某个非平凡性质Q的真相集合为T,静态分析程序给出的答案集合为A,则完全性和正确性用来描述集合T与A的包含关系,假积极和假消极用来描述集合T和A中某个实例a的性质。
- 完全性soundness和正确性completeness

- 假积极False positive和假消极False negative

3. 为什么静态分析首要保证完全性Soundness?
- Soundness对于一系列重要的(静态分析)应用程序至关重要,如编译器优化和程序验证。
- Soundness也优于其他不需要Soundness的(静态分析)应用程序,例如,bug检测,因为更好的可靠性意味着可以发现更多的bug。
- 更进一步:大多数的静态分析会妥协正确性,保证完全性,即 Sound 的静态分析居多,这样的静态分析虽然不是完美的,但是有用的。以 debug 为例,在实际的开发过程中,Sound 的静态分析可以帮助我们有效的缩小 debug 的范围,我们最多只需要暴力排查掉所有的假积极实例(False Positive Instance)就可以了。由于假积极实例 a∈A,所以这个人工排查a的代价仍然是可控的,假设暴力排查一个程序点是否为 bug 的平均代价是常数项时间,则排查假积极的代价在O(∣A∣) 以内。除非该 Sound 的分析极其不精确,导致∣A∣ 特别的大,否则O(∣A∣) 是一个可以接受的代价,有一点错误的 Warning 问题不大。
- 现实中的静态分析(Real-World Static Analysis) 需要保证(或者尽可能保证)完全性(Soundness) ,并在 速度(Speed) 和 精度(Precision) 之间做出一个合适的权衡(Trade-off) 。
4. 抽象abstraction与过近似over-approximation
- 抽象:用抽象的符号来描述系统,定义了一种从源系统Dc到目标系统Da的映射f,通过使用抽象符号来描述系统,起到一个简化问题的效果。(这种将程序P中的值和我们需要研究的性质Q 相关的性质提取出来,从而忽略其他细节的过程,就是一个抽象的过程。)
- 过近似:当我们不确定对于抽象数值的某些操作是否会引发错误时,过近似会认为它可能引发错误(may analysis)。过近似具体表现为transfer functions与control flows,前者定义程序某个语句对抽象值的操作,后者定义分支等语句中数据流对抽象值的操作(数据汇合)。
二、 程序的中间表示
1. 编译器与静态分析器的关系
静态分析器是编译器的一部分,在编译器中起到代码优化的功能。为了进行静态分析优化,要将AST转换为中间表示(IR),这里的IR一般为三地址码,再进行静态分析,最后通过代码生成器将优化后的代码生成机器码传给机器。实际上,静态分析就是做code优化的,静态分析器在IR的基础上进行分析。
2. 三地址码3AC
- 定义:指令右侧最多包含一个操作符,一条指令最多涉及三个地址。地址可以对应名字(变量、跳转标签)、字面常量和编译器生成的临时变量。
- 形式:

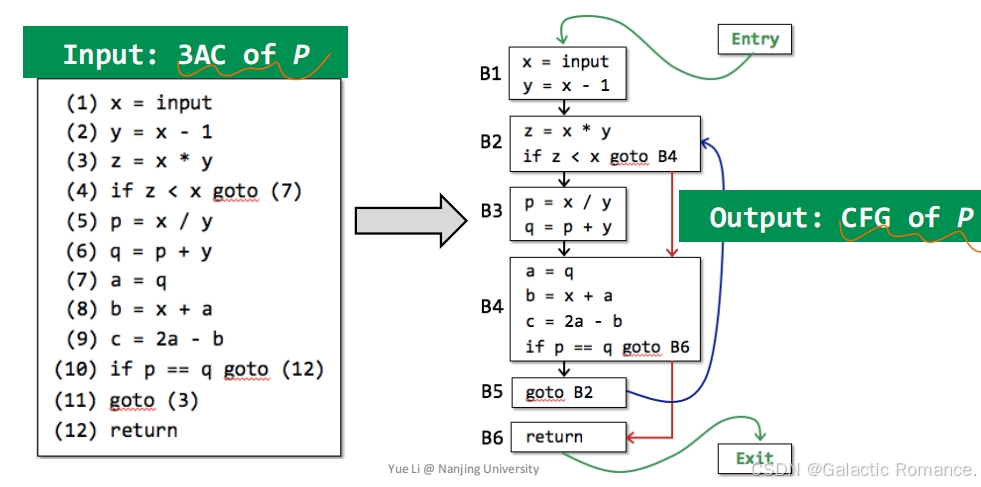
3. 控制流分析(Control Flow Analysis, CFA)
通常是指构建控制流图(Control Flow Graph,CFG)的过程。
4. 如何在IR基础上构建BB(basic block)?
- BB是满足以下性质的最长的IR块:只有第一条指令作为输入,只有最后一条指令作为输出。
- 首先,找leader
- 程序P的第一条指令
- 条件或无条件跳转语句的目标语句
- 条件或无条件跳转语句紧跟着的下一条语句
- 构建BB:由一个领导及其所有后续指令组成,直到下一个领导。
5. 在BB基础上构建控制流图CFG(过程内的):
- CFG的节点是BB,对于两个BB 记为A和B,两个BB之间存在一条边,仅当
- A的最后一条指令可以条件或无条件跳转到B的第一条指令。
- B立即按照指令的原始输入顺序跟随A。
三、 数据流分析
1. 数据流分析DFA:
在每个数据流分析应用程序中,我们将每个程序点关联一个数据流值,该值表示该点可以观察到的所有可能的程序状态集的抽象。
2. 三种分析的含义(有必要看ppt的例题)
- 定义可达性分析:变量v的定义是一个为v赋值的语句。变量v在程序点p的定义到达点q,如果有一条路径从p到q,在这条路径上就不会出现对v的新定义。定义可达可用于检测可能的未定义变量。(sound)
- 活跃变量分析:活跃变量分析告诉变量v在程序点p的值是否可以沿着CFG中从p开始的某个路径使用。如果是,v在p处活跃;否则,v在p处死亡。活跃变量的信息可以用于寄存器分配(优先释放dead value)。(sound)
- 可用表达式分析:如果(1)从入口到p的所有路径必须通过x op y的求值,并且(2)在x op y的最后一次求值之后,x或y没有重新定义,则表达式x op y在程序点p可用。这个定义意味着在程序p上,我们可以用表达式x op y的结果替换表达式x op y。可用表达式的信息可用于检测全局公共子表达式。(safe-approximation/must/complete,因为该分析主要进行优化,可以漏掉一些优化,但是不能错误优化(允许Fasle Positive))
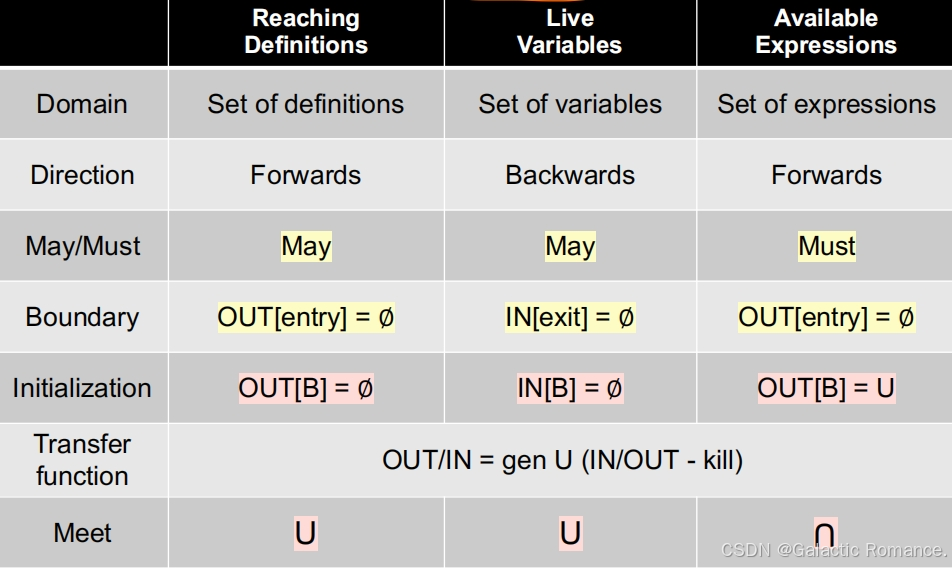
3. 三种数据流分析的不同点与相似处
- 不同点:定义域、方向、分析类型(May->sound; Must->complete)、边界、初始化、meet方法(control flow handling)
- 相似处:
- transfer function的形式(kill左值相关,gen右值相关!)。
- 算法输入和输出:输入都是CFG(每个BB的kill和gen),输出都是每个BB的In和Out。
4. 如何理解数据流分析的迭代算法?该算法为何能收敛?
见软件分析课程笔记。


5. 如何从函数角度看待数据流分析的迭代算法?

6. 偏序关系
- 自反性
- 反对称性:a<=b 且 b<=a,则a == b
- 传递性
- 偏序集合中不是任意两个元素都可比较,任意两个元素都可比的称为全序集。
- 不是所有偏序集合都有最小上界lub和最大下界glb,但是如果存在必定唯一。
7. 格和全格的定义?
- 格:一个偏序集(P, ≤)中,任意两个元素的glb和lub都存在,则该偏序集为格。判断是否为格:先找上/下界集,判断上/下界集的元素是否可比,可比则存在lub或glb。
- 半格:一个偏序集中,任意两个元素的glb(交半格meet)或lub(并半格join)存在.
- 完全格:一个偏序集中,任意子集S都存在glb和lub。Bound的定义意味着边界不一定在子集S中(但它们必须在格中)。
8. 不动点定理
- 条件:transfer function是单调的;格是有限的。
- 从最大下界开始,不断迭代使用transfer function f,最终会到达最小不动点。
- 从最小上界开始,不断迭代使用f,最终会到达最大不动点。
- 证明:(1)最大/最小不动点存在(鸽巢原理);(2)最大/最小不动点唯一(反证法,假设存在另一个不动点)。
- 最坏需要nk次才能收敛,n为节点个数|V|,k为格的高度:最坏情况下每个节点都要从格的top走到bottom。

9. 用格来解释可能性分析与必然性分析
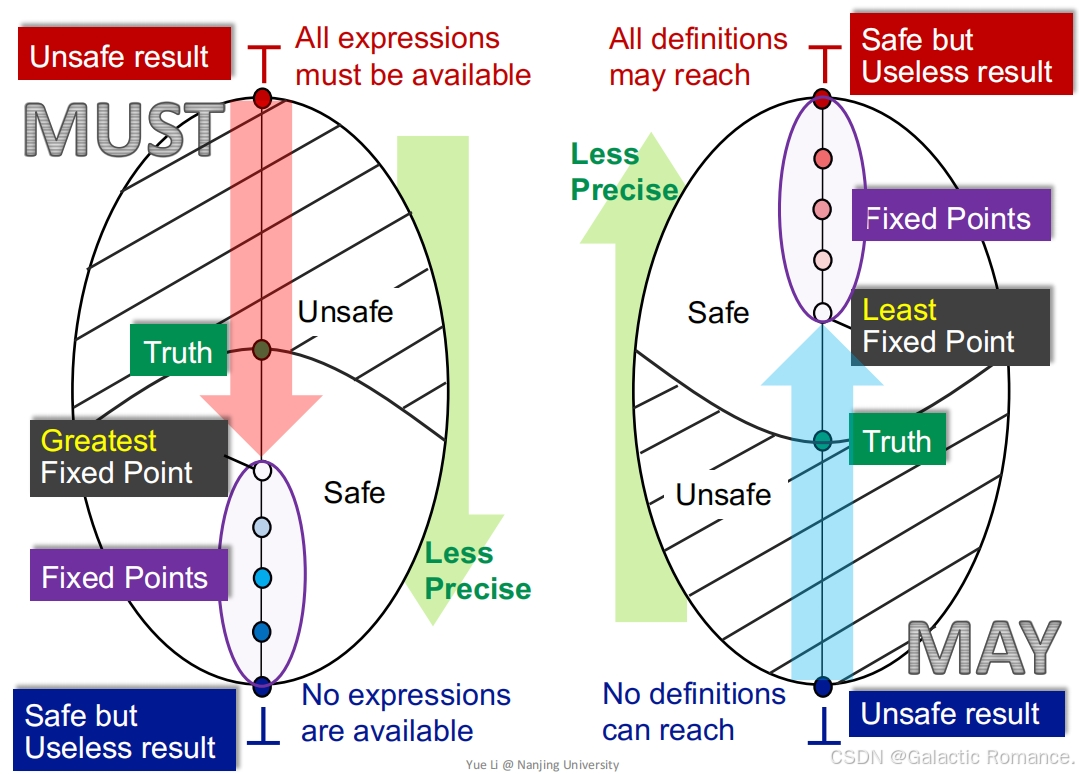
- 数据流分析的过程是从不安全到安全(From Unsafe to Safe)(false negative越多,分析越不安全),然后从准到不准(From Precise to Less Precise)的过程(false positive越多,分析越不准确)。可能性分析如此,必然性分析也是如此。
- 可能性分析:
- 我们以典型的可能性分析——Reaching Definitions为例。从某个程序点的视角来看,我们初始化的时候是⊥,即没有任何定义可以到达此处(完全的false negative),然后我们一次次迭代,每次迭代向前走最安全的一步,发现越来越多的定义能够到达此处,直到算法在一个最小的不动点处停了下来。
- 首先,初始化的状态是不安全的,因为没有任何定义可达显然是一个最不正确的结论(我们错误的认为系统中不存在未定义的变量)。其次,⊤状态是最安全的,所有的定义都“可能”到达此处,但这是一个没有用的平凡的结论(包含大量false positive),因为它并不能帮到我们什么,且我们啥也不干都知道这个结论。
- 我们假设这个程序点处真实可达的定义集合为 Truth,那么包含Truth 且越接近Truth 的答案才是最有价值的。因此,在包含Truth 的前提下最小的不动点是最好的。
- 至于最小的不动点为什么会包含Truth,这是由我们设计的转移方程和控制流约束函数所决定的,需要具体的问题具体分析。言下之意,如果我们设计的状态转移方程和控制流约束函数不合理,最小不动点可能会是不安全的,也就是算法可能会出错。
- 必然性分析:
- 我们以典型的必然性分析——Avaliable Expressions为例。从某个程序点的视角来看,我们初始化的时候是⊤,即所有的表达式都是可用的,然后我们一次次迭代,每次迭代向前走最安全的一步,发现越来越少的表达式是可用的(可达表达式是为了优化一些共有的表达式计算而设计的。表达式越少,我们能够优化的点越少,系统其实更安全,因为不容易发生错误优化),直到算法在一个最大的不动点处停了下来。
- 首先,初始化的状态是不安全的,因为所有的表达式都可用显然是一个最不正确的结论(如果我们用这个结论来作表达式优化,是会导致程序错误的)。其次,⊥状态是最安全的,所有的表达式都不可用(也就是我们并不能优化,啥也不用干就行),但这是一个没有用的结论,因为它并不能帮助我们优化表达式,减少计算次数。
- 我们假设这个程序点处真实可用的表达式集合为Truth,那么包含于Truth (注意,可能性分析里面是包含,必然性分析里面是包含于)且越接近Truth 的答案才是最有价值的。因为包含于Truth 说明用这个结果做优化一定不会错,越接近Truth 那么我能够优化掉的表达式才越多,优化效果越好。因此,在包含于Truth 的前提下最大的不动点是最好的。
10. 迭代算法与MOP(meet-over-all-paths)算法的精度对比
- MOP:计算每个路径末尾的数据流值,并对这些值应用连接/ meet运算符来找到它们的lub / glb。不完全精确(false positive),因为对于特定的输入,某些路径不会走;难以实现,因为实际路径不可美剧
- MOP总体上比迭代算法更精确:MOP≤Ours,说明其在图中更接近truth。

11. DFA framework
- Direction:分析方向,正向,反向。
- Lattice:格,定义了值域和交并操作(control flow)。
- F:transfer function,定义了节点的映射
12. 常量传播分析
- 定义:在程序点p处给定一个变量x,确定x是否保证在p处保持一个常数值。如果我们知道了某些程序点处的某些变量一定是一个常量的话,我们就可以直接优化,将这个变量视为常量,从而减少内存的消耗。
- 常量传播的要素
- Direction:正向。
- Lattice:
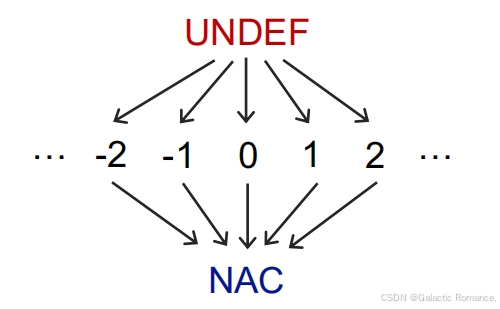
- 值域:UNDEF + NAC + CONSTANT
- Meet(最大下界):根据下图中的格构建,比如UNDEF∩c = c。要能够证明单调性 -> x≤y,则x∩z≤y∩z。
- Transfer function:kill为删除等式左边变量对应的项,gen为添加根据赋值语句s产生的新项。要能够证明单调性 -> kill / gen。

13. 工作表worklist算法
用来优化迭代算法。用一个集合储存下一次遍历会发生变化的基块BB,这样,已经达到不动点的基块就可以不用重复遍历了。BFS + 剪枝。

四、 过程间分析
1. 使用类层次结构分析(CHA)来构建调用图(call graph)
- 通过查找类的层级结构来解析目标方法的过程,称之为类层级结构分析(Class Hierarchy Analysis,CHA)。指针分析也可以用来构建CG,且精度更高。
- 方法派发算法:从接受对象o所在的类c开始,按照从子类到基类的顺序查找,直到找到一个方法名和描述符(方法签名相同)都相同的非抽象方法m为止。

- 调用解析算法:找到一个调用点实际可能调用的所有方法。
- CHA需要知道整个程序的类之间的继承关系,也就是层级结构;
- CHA会根据调用点处的接收变量(Receiver Variable)的声明类型(Declare Type)来解析虚调用;对于special调用,可能涉及父类实例方法调用,也需要dispatch(用来找到调用点对象对应的类可能调用的某个方法)。
- CHA假设声明类型为 A 的接收变量 a 可能会指向 A 类以及 A 的所有子类(Subclass)的对象。

- Call graph构建算法
- 从入口方法开始(通常为main方法);
- 对于每个可达的方法m ,通过CHA解析m中的每个调用点cs的目标方法,即Resolve(cs);
- 重复上述过程,直到没有发现新的方法为止。

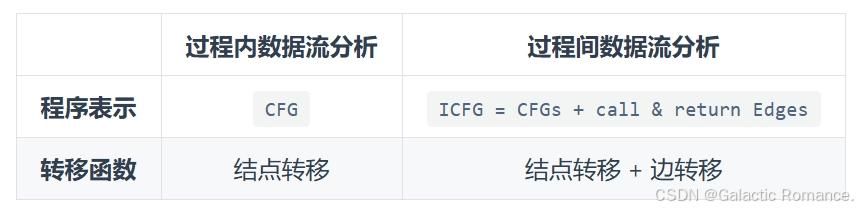
2. 过程间控制流图ICFG
CFG代表了一个独立方法的控制流结构。类似的,我们可以用ICFG(Interprocedural Control Flow Graph)来代表整个程序的控制流结构。
- ICFG的两个组成部分:ICFG = CFG + call & return edges
- 程序中所有方法的控制流图,其中的边称为CFG边(CFG Edge);
- CFG Edges = Call-to-return Edges + Normal Edges 。
- CFG边中从调用点到对应返回点的边称为调用-返回边(Call-to-return edges),除此之外的边称为普通边(Normal Edges)。
- 调用-返回边相当于为子过程不需要用到的外部状态提供了一条传播的捷径。
- 两种额外的边,需要根据CG进行连接:
- 调用边(Call Edge):从调用点(Call Site)到被调用者(Callee)的入口结点(Entry Node)的边;
- 返回边(Return Edge):从被调用者的出口结点(Exit Node)到返回点(Return Site, 控制流中紧接着调用点的语句) 的边。
- 程序中所有方法的控制流图,其中的边称为CFG边(CFG Edge);
3. 过程间数据流分析(IDFA)
基于ICFG的分析 + 节点转移与边转移
- 过程内数据流分析:结合过程内的CFG进行分析,边上没有转移函数,只在节点上进行转移。
- 过程间数据流分析:在ICFG上进行分析,需要考虑不同边对转移的影响
- 普通变:恒等映射。
- 调用-返回边:数据流从调用点沿着调用-返回边到返回点的边转移函数。
- 调用边:从调用点到被调用者的入口节点。
- 返回边:调用者的出口节点到返回点。
4. 以过程间常量传播为例,演示过程间数据流分析。
- 转移函数
- 结点转移:
- 调用结点转移:恒等函数(Identity Function,将输入当输出返回的函数);调用点的左值变量留给调用-返回边处理(需要kill掉);
- 其他结点转移:和过程内的常量传播一致;
- 边转移:
- 普通边:恒等函数
- 调用-返回边:消除调用点的左值变量(Left-hand-side Variable, LHS Variable)的值,传播其他本地变量的值;
- 调用边:传递参数值;
- 返回边:传递返回值。
- 结点转移:
五、 指针分析
1. 什么是指针分析?
- 指针分析是一种基本的静态分析,它分析程序中的一个指针可能会指向哪些内存区域。对于面向对象的语言来说(比如Java),指针分析会分析程序中的一个指针(可能是变量或者字段)能够指向哪些对象。
- 指针分析是一种可能性分析(May Analysis),我们会过近似(Over-approximation)一个指针可能指向的对象集合,也就是说,一个指针可能指向的所有对象,我们都会把它考虑在内。
2. 理解指针分析的关键要素Key
4种,能够影响指针分析的精度和效率.
- 堆抽象:对指针分析的对象进行建模。
- 定义:为了保证静态分析能够正常终止,将动态分配的、无界的具体对象建模成有限/有界的抽象对象(Finite/Bounded Abstract Objects)的过程。
- 分配点抽象技术:最常用的堆抽象方法,将同一分配点(Allocation Site,通常是一条 new 语句)处分配内存而产生的所有具体对象抽象成一个抽象的对象(o_{行号})。分配点有限,因此能够保证创建的抽象对象是有限的。

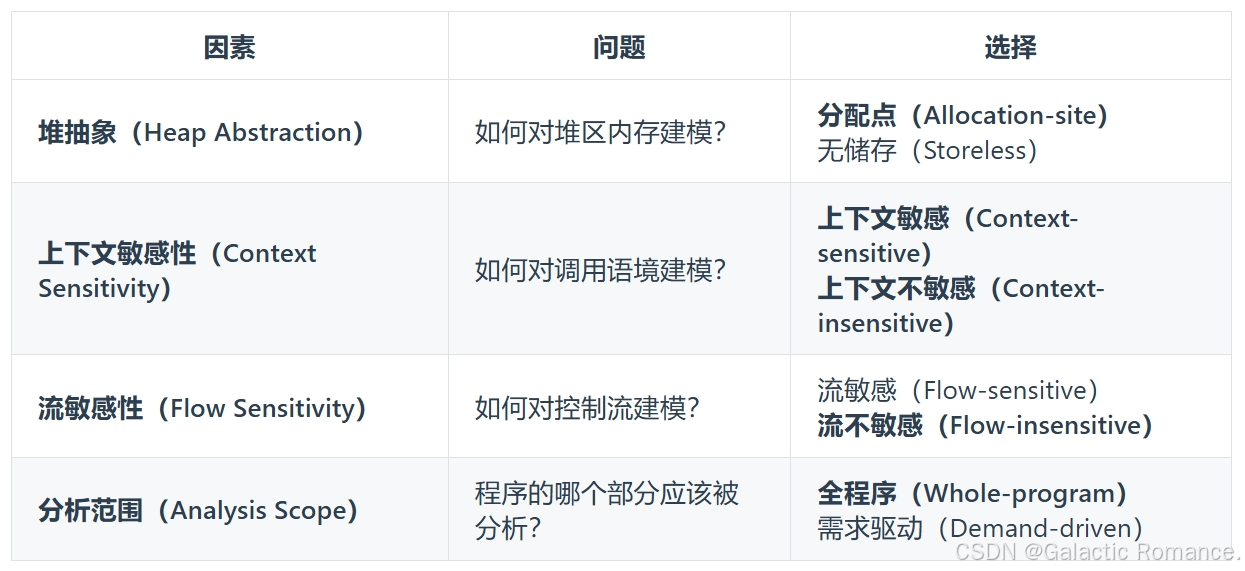
- 上下文敏感性:表示指针分析的调用上下文,通过隔离性影响数据流的精度。
- 定义:称一个静态分析是上下文敏感的(Context-Sensitive, C.S.),如果它区分一个方法的不同调用语境(Calling Context);称一个静态分析是上下文不敏感的(Context-Insensitive, C.I.),如果它将一个方法所有的调用语境汇合到一起分析。
- 数据流:左边两图为上下文敏感,右图为上下文非敏感(不会对不同调用产生的数据流进行隔离)。
- 流敏感:指针分析的语句顺序是否重要。
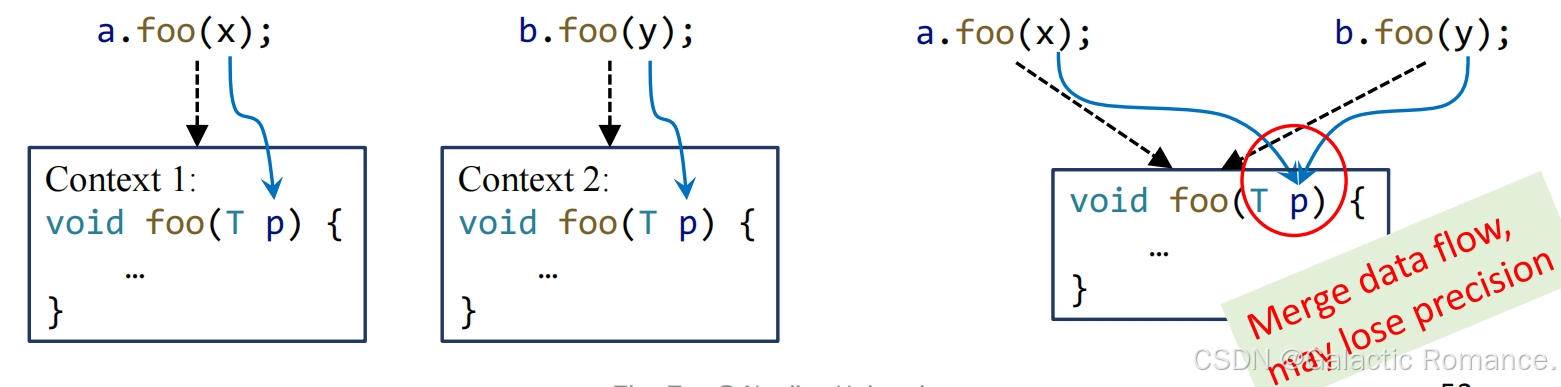
- 定义:称一个静态分析是流敏感的(Flow-sensitive),如果它尊重语句的执行顺序;称一个静态分析是流不敏感的(Flow-insensitive),如果它忽略控制流顺序,将程序视为一个无序语句的集合来对待。
- 直观展示:蓝底框为流敏感分析(我们之前的定义可达、活跃变量、可用表达式、常量传播都是流敏感的,按顺序计算每条语句的IN和OUT);红底框为流不敏感分析,会掉一些精度,有false positice(指针分析采用这种)。
- 分析范围:指针分析注重分析哪些部分。
- 定义:为程序中所有的指针计算指向信息的指针分析为全程序分析(本课程的选择);只计算会影响特定兴趣点(程序中的某一行)的指针的指向信息的指针分析为需求驱动分析。
- 直观展示:蓝底框为全程序分析,把整个程序的指针信息给出;红底框为兴趣点分析,只分析程序中第5行的指针信息。

3. 指针分析过程中,具体都分析了什么?
- 聚焦于指针影响型语句(Pointer-affecting Statements):对程序中指针的指向关系产生影响的语句。
- 四种指针类型:我们聚焦于本地变量(全局变量和本地变量是类似的)和实例字段(数组元素被转化成了实例字段)。
- 本地变量(Local Variable),形如 x ;
- 静态域(Static Field),形如C.f:有时候也称为全局变量(Global Variable);
- 实例域/实例字段(Instance Field),形如x.f:在指针分析的时候建模成x指向的对象的域f;
- 数组元素(Array Element),形如array[i]:在指针分析时,我们会忽略数组下标,建模成array指向的一个对象,这个对象只有一个字段arr,可能指向数组中存放的任意值。将数组抽象成单个字段的对象是因为数组的下标操作过于复杂,下标中可能还有变量,因此我们将数组的所有元素放在一个字段中,简化问题。(第6章ppt 86页)
- 五种指针影响型语句:对于方法调用Call有三种具体的类型(static\special\virtual),我们会重点聚焦于虚调用(Virtual Call),因为这是和指针的指向关系有关的(其他两种调用的解析结果是唯一的,不需要指针分析)。

4. 指针分析与别名分析的关系
- 指针分析回答的是一个指针可能会指向哪些对象,别名分析回答的是两个指针是否会指向同一个对象。
- 不过,别名分析可以基于指针分析来进行,因为如果程序中的指向关系确定了,那么别名关系也随之变得明显了。
5. 指针分析的规则
- 一些记号
- 指针points,本质就是变量v和实例字段field的集合。
- 指向关系pt,描述了一个指针可能对应的所有对象。

- 具体规则:对应四种指针影响型语句,目前还不涉及过程间分析。
描述指针影响型语句如何影响对象在指针集中的流动。
6. 指针分析
在指针间propagate points-to信息。实现的关键:当pt(x)被更改时,将更改后的部分传播到与x相关的所有指针。与指针分析的4个关键点对应:
- 研究对象:堆抽象得到的对象。
- 上下文是否敏感
- 流不敏感:分析过程与语句顺序无关。
- 全程序分析。
7. 如何理解指针流图?
- 我们使用图的方式建模程序,来将对pt(x)的修改传递到图的所有后继上,这个图就是PFC:是一个有向图,它表示对象如何在程序中的指针之间流动。
- 图的要素
- 节点:指针(变量或实例属性)。
- 边:对象流动关系。x->y表示x指向的对象可能流动到指针y中。根据程序中的语句以及语句对应的规则添加PFG的边即可。
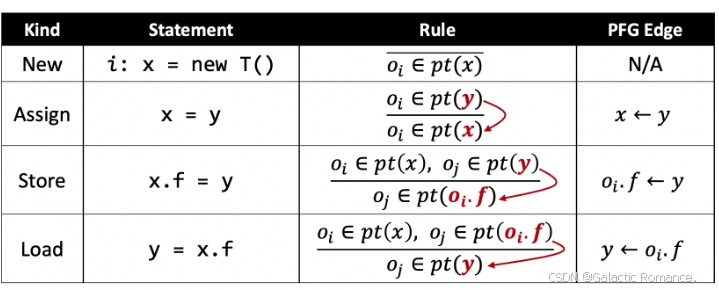
- 例子:根据语句与规则构建控制流图。在该例子中,e是从b可达的结点,这就意味着所有的b指向的对象都可能会流向e,也就是可能还会被e指向。
8. 指针分析算法的基本过程
- 指针分析包括两部分:构建PFG和传递pt信息,两者是同时进行、相互依赖的:
- 构建PFG需要依赖于pt信息的传递,对于同一条语句,如果涉及的指针x的指向对象发生变化,那么可能在PFG中产生新的边。
- pt信息的传递同样依赖于PFG,因为pt信息需要沿着PFG中定义的边进行传递(通过PFG找到指针x的后继节点)。
- 本质上对应两种操作
- 加单个对象:直接把对象加入x的对象集pt(x),并利用PFG更新后继指针的对象集。(对应直接将pair放入worklist,比如new语句)
- 加边:在PFG中构建一条新边,然后把对象加入x的对象集pt(x),并利用PFG更新后继指针对象集。(对应AddEdge:先加边,再将pair放入worklist)
- 在实现上,整个算法包括AddEdge、Propagate和Solve三个函数组成。
- 首先定义一个worklist,里面存放pair <x, pt>,x为一个指针,pt为一个对象集合,可以理解为这个对象集合pt会对指针x的pt(x)带来“变化”,因此我们需要solve这种变化。(如果我们solve掉所有变化,则指针分析结束)
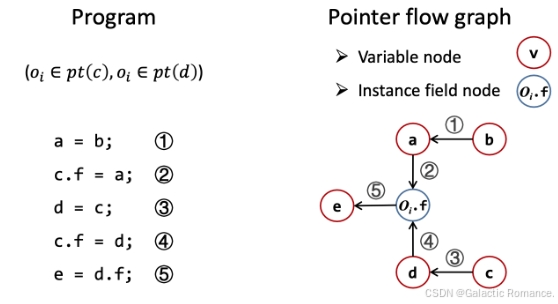
- AddEdge(s, t):在PFG中添加一条边s->t。因为出现了一条边,变量t的pt(t)可能会被“变化”,这种“变化”是pt(s)导致的,因此将<t, pt(s)>加入worklist(加边).
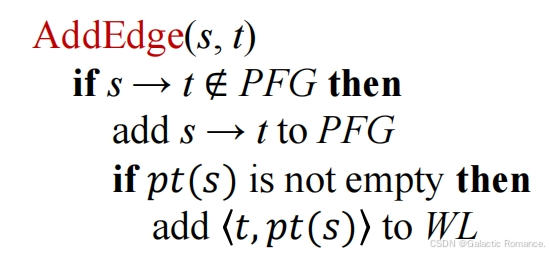
- Propagate(n, pts):pts是引发“变化”的“变量”,它首先影响了n,因此pt(n)中需要加入pts。它接下来会沿着PFG中的边n->s去影响节点n的后继节点s,这种“变化”同样是pts导致的,因此将<s, pts>加入worklist,后续会对这种“变化”进行solve。

- Solve(S):这是一种上下文不敏感的流不敏感全程序指针分析算法,输入为整个程序的语句集合S,是无序的。
- 首先处理new语句,它是最开始的“变化”。(“加单个对象”操作)
- 之后处理赋值语句,为PFG添加最开始的边。(“加边”操作)
- 从worklist中提取pair,来solve这些“变化”:
- 首先计算Δ,找到引起“变化”的真正“变量”。
- 传递“变量”,不仅影响当前指针n,还对后续指针带来“变化”。
- 我们的指针n现在多指向了新的对象(pts中的对象),我们应该处理与对象有关的load和store语句,它们带来新的PFG边和“变化”。(“加边”操作)

- 为什么只传递“变量”(Δ):
- 高性能:Δ相比于原始对象集很小,传递起来更高效。
- 没必要:已经在n的对象集中的对象肯定已经propagate过了,没必要再传递。
9. 如何理解方法调用中,指针分析的规则?
- 首先,在CHA中,Dispatch(C, k)用来根据对象的声明类型找到可能的调用方法;而在指针分析中,使用Dispatch(oi, k)直接根据对象的真实类型找到可能的调用方法,减少false positive,更准确。
- m_this是m方法对应的this变量;
- m_j 是m方法的第j个形参;
- m_ret是存放m方法返回值的变量。
- 为什么不添加x→this作为一条 PFG 边?(该操作属于"加单个对象",算法对于pt(x)的对象的处理在形式上把pt(x)的oi都放入pt(m_this),实际上只把接收对象oi放入worklist,而不考虑无关oi)
- 接收对象(Receiver Object)只应当流到对应目标方法的this变量中。比如说,如果 x 的指向集合里面有 T 类型的o_i,以及 C 类型的o_j,那么我们处理调用的时候,应当把o_i赋给T类中的 foo 方法的 this 变量,把o_j赋给 C 类中的 foo 方法的 this 变量。
- 如果我们在 x 和 this 之间建立了 PFG 边(“加边”操作),那么 x 指向集中的所有对象都会流到 this 中,这会导致一个父类的对象流到子类的方法中,或者子类的对象流到父类的方法中(假设子类中存在目标实例方法),这是错误的,为 this 变量增加了虚假的指向关系,因此我们不添加x→this作为PFG边。

10. 过程间的指针分析算法
- 过程间的指针分析只分析可达的方法,所以我们需要同时进行call graph构建与指针分析(指针分析又要同时进行PFG构建和pt信息的传播)。
- 相比于过程内指针分析,过程间指针分析增加了AddReachable和ProcessCall两个方法。
- AddReachable(m):将方法m标记为可达,同时处理方法m中出现的对象创建与赋值语句。(相当于把过程内指针分析的前几句初始化方法提取出来,对于每个可达的方法都执行这种初始化)。
- ProcessCall(x, oi):处理调用,参数为指针x与接收对象oi。对于指针x的所有调用语句,首先根据对象oi的类型dispatch找到真正的被调用方法m,在CG中添加边并将m标记为可达的,再根据规则添加“变化”到worklist中或者加边("加单个对象"或“加边”操作)。
- X->m_this,不加边,直接将pair放入worklist。("加单个对象")
- a_i->p_i和m_ret->r,先加边,再将pair放入worklist。(“加边”)

11. 即时调用图构建(On-the-fly Call Graph Construction)的含义
- 称一边使用调用图,一边构建调用图的方式为即时调用图构建(On-the-fly Call Graph Construction)。
- 基于指针分析来构建调用图的过程中,反过来又会促进指针分析的过程,因为调用边和返回边也是会传递指向关系的,从而两者是相互依赖的,我们称这种调用图的构建方式为即时调用图构建(On-the-fly Call Graph Construction)。
12. 什么是上下文敏感(Context Sensitive C.S.)
- 上下文敏感性模型通过区分不同语境的不同数据流来调用上下文,以提高精度。
- 最古老的,也是最为人熟知的上下文敏感策略是调用点敏感(也称为调用串),用一连串的调用点来表示上下文。
- 基于克隆的上下文敏感分析是实现上下文敏感最直接的方法,我们将两个不同上下文中的 id 方法用两个结点表示,在前面分别用其上下文修饰。
- 每个方法都被一个或者多个上下文修饰;
- 变量也被上下文修饰(继承自声明该变量的方法);
- 对于每个上下文,都会恰有一个方法及该方法中的变量的克隆。
13. 什么是上下文敏感堆(C.S. Heap)
- 分配点处声明的变量已经上下文敏感了,那么分配点处分配的堆内存(对象)也应该是上下文敏感的,这样可以细化堆内存抽象的粒度,从而提高指针分析的精度。并且,面向对象语言(比如说Java)本身就是典型的堆密集型(heap-intensive)语言,会频繁地操作堆内存。
- 抽象的对象也应当用上下文来修饰(称为堆上下文),最普遍的选择是继承该对象分配点所在方法的上下文。上下文敏感的堆抽象在分配点抽象的基础上提供了一个粒度更精确的堆模型。
14. 为什么C.S.和C.S. Heap能够提高分析精度:
- C.S.:给变量添加上下文。在动态执行中,一个方法可以在不同的调用上下文下被多次调用,在不同的调用上下文下,该方法的变量可能指向不同的对象。在C. I.指针分析中,该变量在不同上下文下的对象被混合并传播到程序的其他部分(通过返回值或副作用),从而导致虚假的数据流。上下文敏感分析通过将对象赋予具体上下文下的变量,来隔离了不同上下文的数据流,不会造成混淆,精度更高。(区分不同上下文下同一变量指向的不同对象)
- C.S. Heap:给对象添加上下文。在动态执行的过程中,一个分配点可以在不同的调用语境下创建多个对象,不同的对象(有相同的分配点分配)可能会携带不同的数据流被操作,比如说在它们的字段中存储不同的值。在指针分析中,不带堆上下文分析这样的代码可能会由于合并不同上下文中的数据流到一个抽象对象中而丢失精度,而通过堆上下文来区分同一个分配点的不同对象能够获得不少的精度。(区分不同上下文下同一调用点产生的不同对象)
15. 上下文敏感的指针分析规则
- 语句处理规则(四种语句)
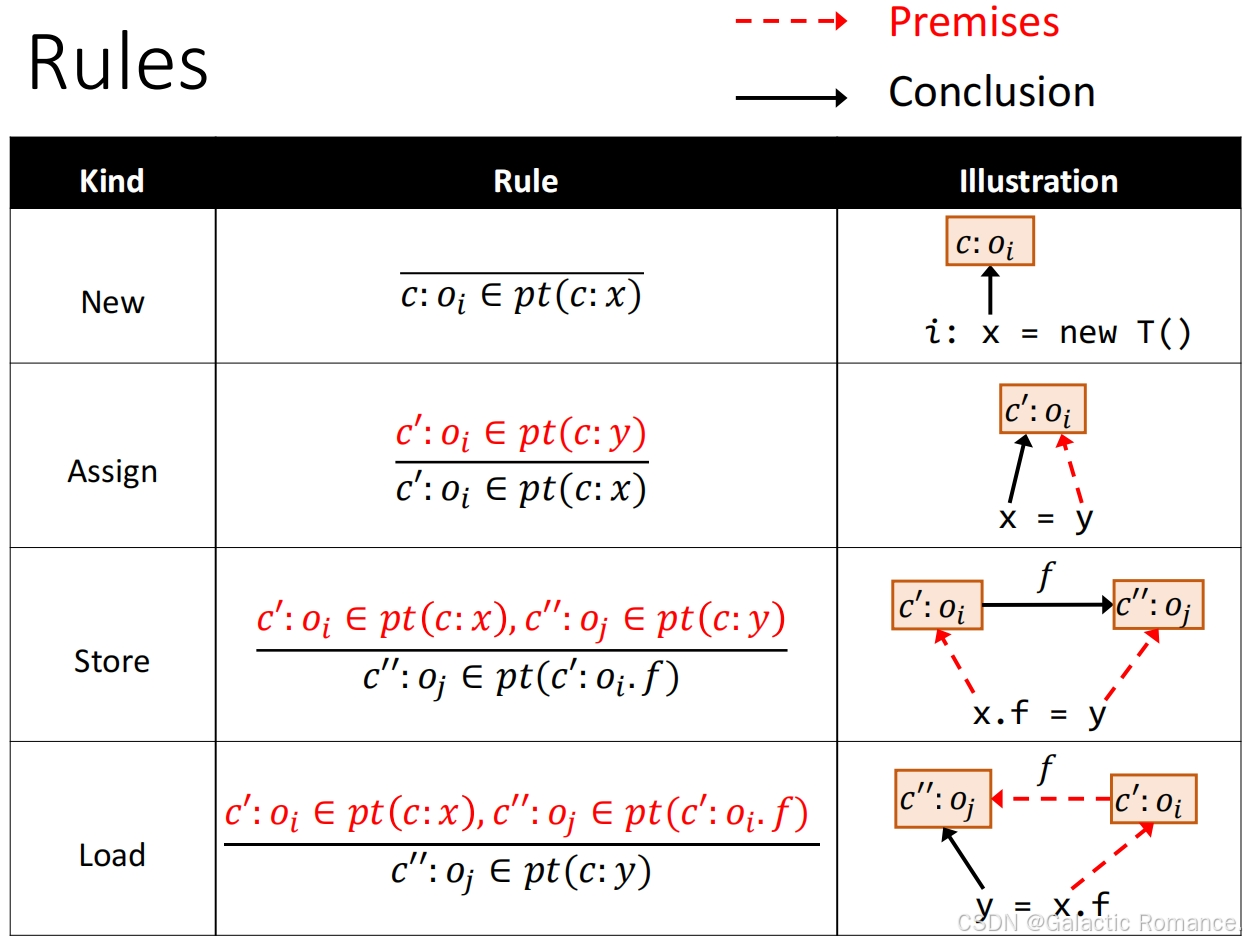
- 方法调用处理规则:三种对象(接收对象o_i,参数o_u,返回值o_v) + 两个操作(dispatch+select)

16. 上下文敏感的指针分析算法
- 相比于C.I.方法,在处理对象时明确了对象的上下文,同时引入用于选择上下文的Select函数。(AddEdge和Propagate函数没有变化)
- 入口方法只被系统调用了一次,因此不需要区分上下文。
- Reachable methods中保存带有上下文的方法c:m;CG中的边是从调用点指向某个明确上下文的方法c:m:不同上下文的同一方法m,按照不同方法处理。
- ProcessCall会处理变量x的所有调用,以oi为接收对象。

17. 上下文敏感性的变体(Context Sensitivity Variants)
- 其实就是Select的不同方式:Call-site sensitivity/Object sensitivity/Type sensitivity
- 定义一个指针分析的上下文敏感性(Context Sensitivity)为一个上下文生成子(Context Generator),记为Select(c,l,c′:oi) 。描述了实例方法调用的时候用怎样的上下文去修饰目标方法。Select 函数的输入是调用点处的上下文c,调用点l,以及调用方法的带有堆上下文的接收对象c′:oi。Select 函数的输出是用于修饰目标方法的上下文ct。Select 函数是从调用者上下文(Caller Context)到被调用者上下文(Callee Context)的映射。
- 如果 Select 输出的目标方法的上下文是和现有的所有的该方法的上下文不同的话,我们就发现了一个新的上下文敏感的可达方法,否则我们将会和现有的同名且同上下文的方法进行合并。如果 Select 经常出现上下文重叠(不同输入,输出相同上下文),指针分析的精度会受损,相应的,速度会提高;如果 Select 偶尔出现上下文重叠,指针分析的精度会提高,相应的,速度会减缓。
- 几种Select
- 调用点敏感:每个上下文都由一个调用点列表(调用链)组成,在一个方法调用中,将调用点附加到调用者上下文,本质上是对调用堆栈的抽象。
- 循环调用时会产生无穷个上下文。为了确保指针分析的终止,避免实际程序中过多的上下文(长调用链)破坏指针分析。
- 方法:设置一个上下文长度的上界,用k表示,选取列表中最后k个上下文(K-CFA,control flow analysis).
- 为什么这样就能避免无穷上下文:假设k=1,每个调用点只会产生一种上下文c,在循环调用时只会被当作c:m处理一次。

- 对象敏感(分配点敏感):每个上下文由一个抽象对象列表组成(由它们的分配点表示)在方法调用中,使用接收方对象及其堆上下文作为被调用上下文区分不同对象上的数据流操作。

- 类型敏感:在方法调用时,每个上下文由一个类型列表组成,使用包含接收对象及其堆上下文的分配点的类型(创建点所在的类的类型,与创建什么类型的对象没有关系,InType(oi)表示oi是在哪个类中被创建的)作为被调用上下文的对象敏感性的抽象。
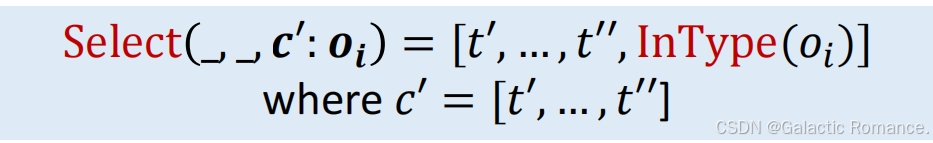
- 调用点敏感:每个上下文都由一个调用点列表(调用链)组成,在一个方法调用中,将调用点附加到调用者上下文,本质上是对调用堆栈的抽象。
18. 三种变体之间的差别与联系
- 使用情况不同
- 调用点敏感:多次调用同一段函数(函数中又调用其他函数,此时调用点相同),会导致调用点无法区分上下文。
- 对象敏感:相同receive object调用相同方法(比如this对象)会混淆,导致接收对象无法区分不同上下文。
- 类型敏感:多个调用处于同一个类中,上下文会混淆。
- 精度
- 在理论上,调用点敏感与对象敏感不可比。但实践中,在OO语言中,对象敏感效果更好
- 类型敏感是对对象敏感的粗粒度抽象,只考虑接收对象的类型信息。在相同的k限制下,类型敏感的精度不会优于对象敏感,但是效率更高。

六、 静态分析与安全
1. 信息流安全的概念(Information flow sensitive)
- 定义:如果变量x中的信息转移到了变量y中,则存在信息流(Information Flow)x→y 。信息流安全指通过追踪信息是如何在程序中流动的方式,来确保程序安全地处理了它所获得的信息。
- 目标:防止不必要的信息流,保护信息安全。
- 与访问控制access control之间的关系
- 访问控制:对于特定的信息检查请求访问该信息的程序是否具有相应的权限(rights)或者是否得到了相应的许可(permissions)。
- 信息流安全:跟踪信息如何在程序中流动,以确保程序安全地处理信息。关注信息如何传播。
- 信息流安全关心的是信息是如何被传播的。一个实用的系统既需要访问控制,也需要流控制来满足它的所有安全需求。
- 在实现上,将程序变量分类为不同的安全级别,制定信息流策略来限制信息在不同安全级别的变量间的流动。(安全级别 + 信息流策略)
- 安全级别:保密信息H,公开信息L。
- 信息流策略:这里介绍一种,不介入政策(Noninterference Policy),它要求高安全等级的变量H的信息不应当作用于,或者说不应当干涉低安全等级变量L的信息。不应当能够通过观察低安全等级变量的方式得出任何关于高安全等级变量的结论。保证了在安全等级格当中信息流只会自下而上流动(从低安全等级流向高安全等级)。
2. 机密性与完整性
- 机密性(Confidentiality)指的是阻止机密的信息泄漏,完整性(Integrity)指的是阻止不信任的信息污染受信任的关键信息。
- 破坏完整性的例子:命令注入(Command injection);SQL注入;XSS攻击(跨站脚本攻击)。
- 关系:两者是对偶的关系,机密性对读操作保护,完整性对写操作保护。
- 广义的完整性:To ensure the correctness, completeness, and consistency of data
- 正确性:为了实现信息流的完整性,(受信任的)关键数据不应被不受信任的数据破坏。
- 完全性:数据库系统应完全存储所有数据。(数据存储完全)
- 一致性:文件传输系统应确保两端(发送方和接收方)的文件内容相同。(文件传输一致性)
3. 什么是显式流Explicit,什么是隐蔽信道Covert Channels?
- 显式流动:信息可以通过直接拷贝的方式(即使数据流也是信息流)进行流动,这样的信息流称为显式流(Explicit Flow)。信息可以通过影响控制流的方式向外传递(不直接传递数据流,但是存在信息流),这样的信息流称为隐式流(Implicit Flow)。
- 称在计算系统中指示信息的机制为信道(Channels)。如果这个指示信息的机制的本意并不是信息传递,这样的信道称为隐蔽信道(Covert/Hidden Channels),包含如下类型:
- 控制流(if分支)
- 循环终止条件
- 执行时间
- 异常报错:throw或数组越界等异常

- 显式流通常比隐蔽通道携带更多的信息,所以我们关注显式流。
4. 利用污点分析来检测不想要的信息流
- 一些概念:污点分析(Taint Analysis)将程序中的数据分为两类,关心的敏感数据,我们会给这些数据加标签,加上标签后叫做污点数据(Tainted Data);其他数据,叫做 无污点数据(Untainted Data)。污点分析追踪污点数据是如何在程序中流动的,并且观察它们是否流动到了一些我们关心的敏感的地方。其中,污点数据产生的地方称为源头(Source),我们不希望污点数据流向的敏感地带称为槽(Sink)。
- 污点分析是最常用的信息流分析方法。在实践中,污点分析的源头通常是一些特殊的方法,这些方法会返回一些污点数据(比如说密码、命令之类的);而污点分析的槽通常也是一些敏感的方法(比如说写日志、执行命令之类的)。具体来讲,我们并不希望应当被保密的密码被写到公开的日志中,我们也不希望用户输入的非法命令被系统执行。
- 机密性:源头,保密数据源;槽,泄漏点;可以处理信息泄漏。
- 完整性:源头,不信任数据源;槽,关键计算;可以处理注入攻击。
- 污点分析的本质是追踪污点数据是如何在程序中流动的,而指针分析的本质是是追踪抽象对象是如何在程序中流动的;这两者其实是很像的。我们可以
- 将污点视为是一种人造的对象,随着数据一起流动;
- 将源头视作是污点的分配点;
- 借用我们的指针分析手段来分析污点数据的传播。
- 算法输入
- Sources:一组源方法(对这些方法的调用返回受污染的数据)。
- Sinks:一组具有敏感参数的汇聚方法(这些受污染的数据流向这些方法的参数违反了安全策略)。其元素形式为一个元祖,比如说 (m,i)表示方法m的第i 个参数是敏感的槽。
- 算法输出:污点流(TaintFlows),一个污点源和槽调用的元组的集合。(i,j,k)∈TaintFlows 表示从调用点i(调用污点源方法的调用点)流出的污点数据有可能流到调用点j(调用槽方法的调用点)的第k个参数中。
- 处理规则
- Propagate与指针分析一致(new, assign, load, store, call)。
- 添加对source(找到污点数据)和sink(产生污点报错)的处理。

七、 Datalog程序分析
1. Datalog语言的基本语法和语义
- Datalog 的语法语义由两部分组成,数据(Data)和逻辑(Logic),这种语言没有副作用,没有控制流,没有函数,也不是图灵完备的语言。在 Datalog 中,用谓词表示数据,用规则表示逻辑。
- 谓词Predicates (Data)
- 在Datalog中,谓词(关系)是一组语句。本质上,谓词是一个数据表。
- 原子(atom)是datalog的基本元素,它将谓词表示为P(X1, X2,.., Xn),P为谓词的名字,Xn为参数项(变量,常量)。(原子 = 谓词 = 谓词名+参数项)
- 数据从哪里来?Datalog 中的谓词有两类: EDB 和 IDB。
- 先验定义的谓词称为外延数据库(Extensional Database),其中的关系是预先定义的、不可修改的,可视为输入关系。
- 由规则建立的谓词称为内涵数据库(Intensional Database),其中的关系是由规则推导出来的,可视为输出关系。
- 规则Datalog Rules (Logic)
- 规则是一种表达逻辑推理的方式,规则也用来指定如何推断事实,规则的形式是H <- B1,B2,…,Bn.
- H 称为头部(Header),是规则的结果(Consequent),其形式上是一个原子。
- B1,B2,...,Bn称为主体(Body),是规则的前提(Antecedent),其中的Bi是一个原子或者原子的否定,称为子目标(Subgoal)。
- 规则的含义是如果主体为真,则头部为真。这里“,”表示合取关系,即逻辑与,也就是说主体B1,B2,...,Bn为真当且仅当所有的子目标Bi(1≤i≤n)都为真。
- Datalog 会考虑子目标中变量的所有可能的组合,如果存在某个组合使得所有的子目标都为真,那么带有相应变量的头部原子也为真。头部谓词会包含所有为真的原子的项,作为该谓词的事实存下来。
- 或运算:写成两条规则,或者使用”;”运算符(与运算符”,”优先级更高)。 否运算:“!”运算符。
- 在Datalog本身的规约中,对于规则语句,其头部H只能是IDB,但主体部分B的原子(谓词)既可以是EDB,也可以是IDB,即Datalog 支持递归的规则(Recursive Rules):Reach(from, to) <- Reach(from, node),Edge(node, to)。有了递归, Datalog 就强大许多,并且能够表达出更复杂的程序分析,比如说指针分析。
- 规则安全:
- 如果一个规则中的每个变量都在至少一个非否定的关系型原子中出现过(保证不会出现无穷个结论被推导出来),那么这个规则是安全(Safe)的。

- 在 Datalog 中,一个原子的递归和否定必须分开,否则这个规则可能会包含矛盾,且逻辑推理无法收敛。
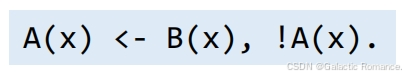
- 如果一个规则中的每个变量都在至少一个非否定的关系型原子中出现过(保证不会出现无穷个结论被推导出来),那么这个规则是安全(Safe)的。
- 规则是一种表达逻辑推理的方式,规则也用来指定如何推断事实,规则的形式是H <- B1,B2,…,Bn.
- 引擎:Datalog 语言本身只是一个规约,就像 SQL 一样,不同的 Datalog 引擎会有特性上的区别,不过不会违背语言本身的规约。Datalog 引擎会根据给定的规则和 EDB 推导事实,直到没有任何新的事实可以被推导出为止,程序终止。推理总会终止:Datalog 程序具有单调性,因为它只会推导新的事实,而无法删除已有的事实,且安全性保证推导是有限的(单调有界原理)。
2. 如何使用Datalog进行指针分析
- 定义元素:
- EDB:可以从程序语法中提取。(使用方式见ppt69页的例子)
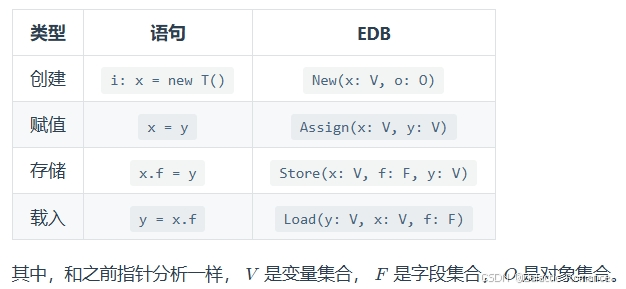
- IDB:指针分析的结果。

- 规则:指针分析规则。结合EDB和规则可以得到更多IDB。(使用方式见ppt75页的例子)
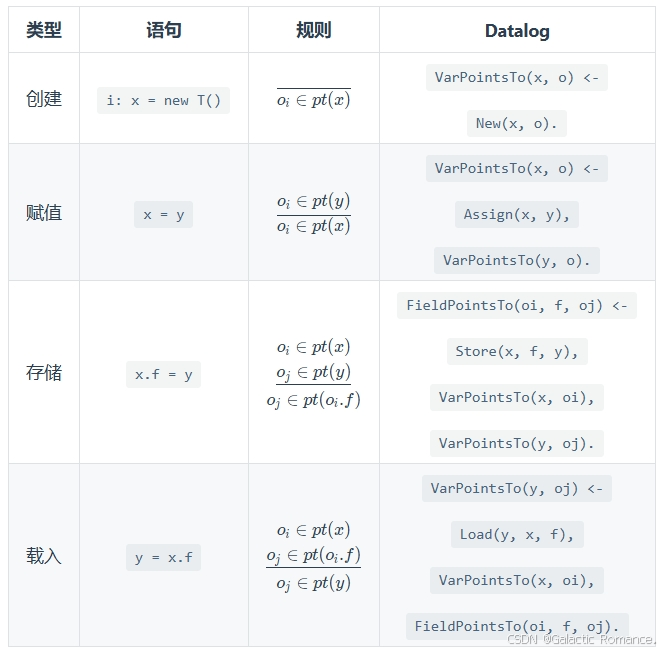
- EDB:可以从程序语法中提取。(使用方式见ppt69页的例子)
- 方法调用处理规则:需要自己定义几个EDB(具体见ppt84页例子)。写规则时”,”符号不能漏!!

- 反复执行规则,直到IDB对应的集合不再变化。需要添加入口处理规则。
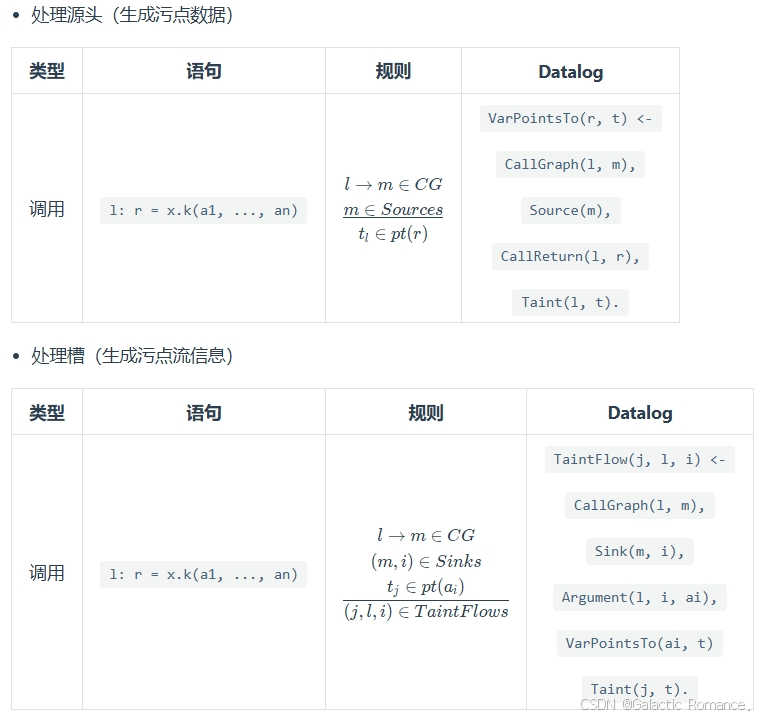
3. 如何使用Datalog进行污点分析
- EDB与IDB:T为污点类型的对象Taint Object。

- 处理规则
4. 基于Datalog的程序分析的优缺点
- 优点:
- 简洁易懂;
- 容易实现;
- 能够受益于现成的 Datalog 引擎的优化
- 缺点:
- 表达能力受限:比如说可能无法或者不方便表达某些逻辑。
- 无法完全控制其表现:因为这是一个声明式的语言,对于用户来说还是一个黑盒,有些东西是用户不可控的。
最后,希望本博客能帮助大家取得理想成绩顺利通过考试,祝各位同学考试顺利!!!
如果觉得本文不错,请点个赞再走吧~~~ 感谢您的阅读和支持!