1. resid_dropout(残差模块的 Dropout 系数)
- 数值:0.1
- 作用:
- 控制模型残差连接部分的随机失活概率,防止模型过拟合。
- 不建议修改,因为默认设置通常已经针对一般任务优化。
2. embd_dropout(Embedding模块的 Dropout 系数)
- 数值:0
- 作用:
- 控制模型输入层(Embedding层)中神经元的随机失活概率,用于降低过拟合风险。
- 设置为0表示不启用dropout,不建议修改。
3. attn_dropout(Attention 模块的 Dropout 系数)
- 数值:0
- 作用:
- 控制Attention层(注意力机制)输出的随机失活概率,防止模型在注意力计算上过拟合。
- 设置为0表示不启用dropout,不建议修改。
4. learning_rate(学习率)
- 数值:0.00001
- 作用:
- 控制模型训练时每次权重更新的速度和幅度。
- 较高的学习率(如0.001)更新速度快,但可能引起训练过程不稳定,难以收敛;
- 较低的学习率(如0.00001)更新速度慢,但模型更加稳定,容易收敛到更好的最优点。
5. lora_rank(LoRA权重矩阵的秩)
- 作用:
- 表示LoRA中新增权重矩阵的秩(维度大小),秩越大,可训练的参数越多,模型学习能力越强。
- 当
lora_rank降低时,可训练参数减少,需适当提高学习率(learning_rate)来达到原有训练效果。 - 较大的秩会提高训练复杂性,可能导致过拟合,需谨慎调整。
6. lora_alpha(LoRA缩放系数)
- 数值:32
- 作用:
-
决定LoRA权重的最终缩放比例,具体计算方式:
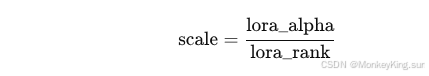
-
一般设为
32是常用的经验值,配合lora_rank控制LoRA模块的强度。
-
7. warmup_step_rate(Warmup阶段比例)
- 数值:0.05
- 作用:
- Warmup阶段指训练初期逐渐增加学习率到目标学习率的过程,有助于训练稳定。
warmup_step_rate = 0.05表示训练过程中前5%的步数用于逐渐提升学习率,后续学习率保持稳定或逐渐降低。
8. epoch(迭代轮次)
- 数值:1
- 作用:
- 一次epoch表示完整遍历整个训练数据集一次的过程。
- epoch越多,训练的总时间越长,模型对数据的拟合能力可能更好。
- 若epoch过多,有可能过拟合;过少则可能欠拟合。
9. gradient_accumulation_steps(梯度累积步数)
- 数值:1
- 作用:
- 梯度累积允许多个batch计算出的梯度相加后再统一进行一次参数更新,通常用于在显存不足时实现更大的有效batch size。
- 设置为1表示每个batch后都立即更新参数,若设为更大数值,如2或4,则多个batch的梯度相加后再更新一次。
10. lora_dropout(LoRA模块的 Dropout 系数)
- 数值:0.1
- 作用:
- 控制LoRA模块内部权重的随机失活概率,防止LoRA模块单独过拟合数据。
- 合理设置(如0.1)有助于提升模型泛化性能。
11. batch_size(批次大小)
- 作用:
- 每次训练时模型同时处理的样本数量。
- 更大的batch size可以提高训练效率,加快收敛,但也要求更多的显存。
- 较小的batch size占用资源少,但训练过程可能更长且可能不稳定。
12. use_rslora(是否开启RS-LoRA)
- 作用:
-
若开启,LoRA缩放系数(lora_scaling)的计算方式变为:
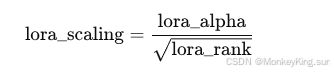
-
这种调整有助于在训练中获得更稳定的效果。
-
若使用
use_rslora,通常需要同时适当降低lora_alpha和学习率(learning_rate)来稳定训练。
-