1. 论文思想概要介绍
现有的推理模型已经显⽰出强化学习(RL)在增强⼤型语⾔模型(llm)复杂推理能⼒⽅⾯的潜⼒。虽然它们在数学和编码等具有挑战性的任务上取得了卓越的表现,但它们往往依赖于⾃⼰的内部知识来解决问题,这对于时间敏感或知识密集型问题可能是不够的,从⽽导致不准确和幻觉。为了解决这个问题,近期有学者推出了R1-Searcher,是⼀种新的基于结果的两阶段RL⽅法,增强 llm的搜索能⼒。该⽅法允许llm在推理过程中⾃主调⽤外部搜索系统来访问额外的知识。框架完全依赖于RL,不需要过程奖励或冷启动的蒸馏。 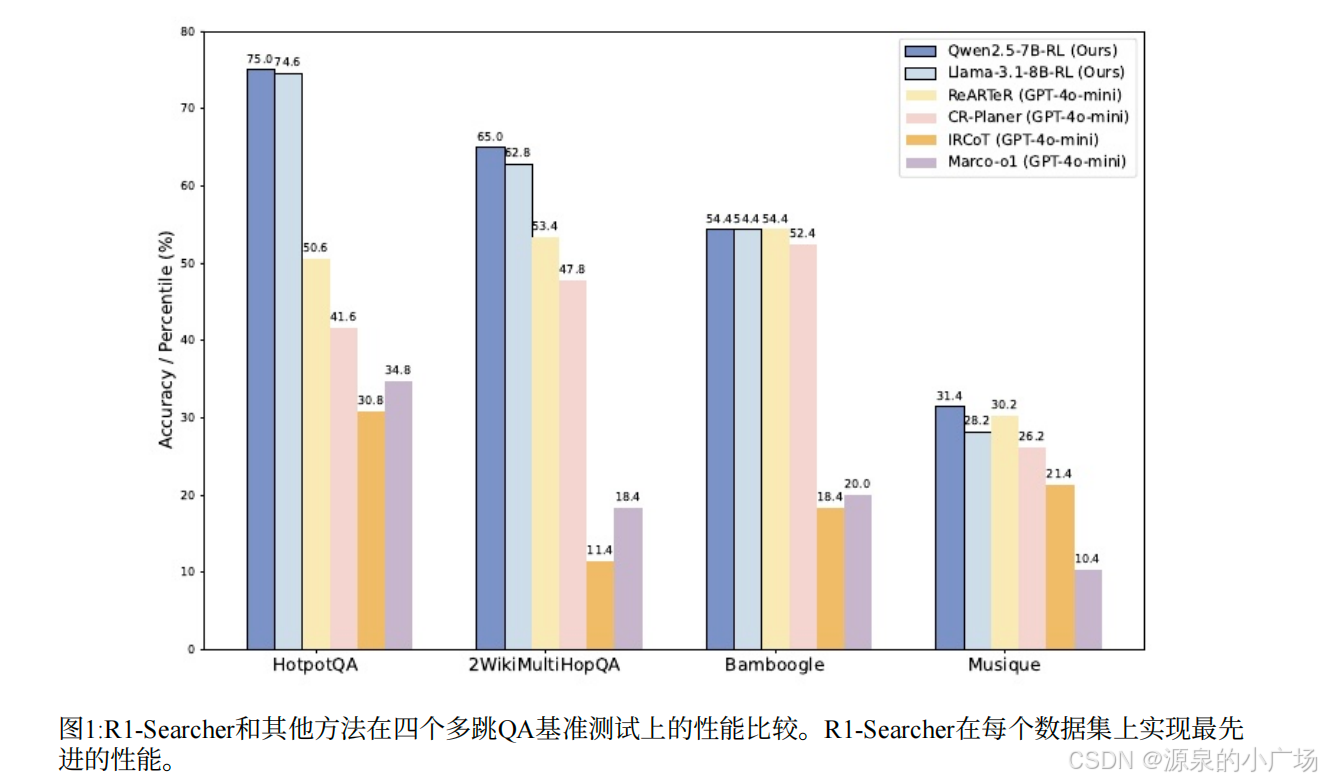

你是⼀个有⽤的助⼿。给你⼀个问题,你应该先在脑海中思考推理过程,然后给出最后的答案。推理过程和最终答案的输出格式分别封装在 <think> </think> 和 <answer> </answer> 标签中,即“ <think> here 推理过程 </think><answer> here 最终答案 </answer> ”。你应该⽤分解、反思、头 脑⻛暴、验证、提炼、修正来进⾏思考。此外,如果有必要,你可以“<|begin_of_query|>search query (only keywords) here <|end_of_query|> ”的格式来进⾏不确定知识的搜索。然后,搜索系统会以“<|begin_of_documents|> …”的格式为你提供检索信息。搜索结果… < | end_of_documents | >”。
由于训练数据中没有中间标注,RL过程主要受结果奖励的影响。通过在两个阶段分配不同的奖励,模型逐渐学会调⽤外部检索系统,并有效地将检索到的⽂档集成到推理过程中以回答问题。 在Stage-1中,奖励函数包括检索奖励和格式奖励。这⾥的主要⽬标是使模型能够识别其调 ⽤外部检索系统的能⼒并学习其使⽤,⽽不考虑模型答案的正确性。模型是明确的⿎励发起搜索查询,因此,在这个阶段没有分配答案奖励。具体来说,检索奖励定义如下:
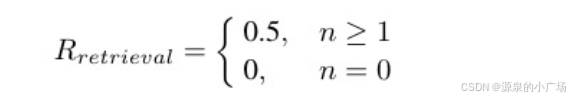
1. 模型的思考过程和最终答案应该包含在 <think> … </think> 和 <answer> …分别为 </answer>标签。另外,在 < / answer> …回答 < / > 标记。2. ⽣成的输出必须没有任何乱码或不可读的内容。3. 当调⽤检索时,模型应该提出⼀个查询,并将查询封装在 <begin_of_query> … < / end_of_query > 标签。此外,模型⽆法在不调⽤检索的情况下直接⽣成⽂档。



其中PN表⽰预测答案的字数,RN表⽰参考答案的字数,IN表⽰两个答案相交的字数。因此,第⼆阶段的最终奖励是答案奖励和格式奖励的总和。
训练算法基于reinforcement ++算法,作者对其进⾏了修改,以适应检索增强⽣成场景。在推理过程中,模型使⽤外部检索系统来解决问题,并获得正确解决⽅案的奖励。通过最⼤化这个奖励来增强模型在推理过程中利⽤检索的能⼒。⽬标是使模型在⾯对不确定性时能够⾃主访问外部知识,有效地整合推理和检索。为了⽆缝地整合检索到的⽂档并确保合理的模型优化,需要对原始算法进⾏了两个修改:基于rag的Rollout和基于检索掩码的Loss Calculation。
基于rag的Rollout:
⽤⼾提出问题,助⼿解决问题。助⼿⾸先在头脑中思考推理过程,然后为⽤⼾提供最终的答案。推理过程和最终答案的输出格式分别封装在 <think> </think> 和 <answer> </answer> 标签中,即“ <think> here 推理过程 </think><answer> here 最终答案 </answer> ”。在思考过程中, ** 助⼿可以在必要时以“ <|begin_of_query|> 搜索查询(仅列出关键字,如“ keyword_1 keyword_2 …”) <|end_of_query|> ”的格式对不确定知识进⾏搜索 ** 。 ** 查询必须只涉及单个三元组 ** 。然后,搜索系统会以“ <|begin_of_documents|> …”的格式向 Assistant 提供检索信息。搜索结果… < | end_of_documents | > ”。
2. 相关对比分析及讨论
与SFT相⽐,RL在⾃⼰不知道如何回答的情况下,更擅⻓调⽤外部检索进⾏查询。然⽽,SFT容易受到内部知识的影响,直接使⽤不正确的内部知识进⾏回答,最终导致错误的答案。
如下表所⽰:

此外,经过RL后,Qwen-2.5-7B-Base模型⽐Llama-3.1-8B-Instruct模型更有效地分解复杂问题。它通过将多步问题分解成⼦问题并顺序检索相关信息来细化推理,从⽽增加检索相关⽂档的可能性,提⾼准确性,如下表所示: 
总结:论文提出了⼀种将 RAG 与 RL 相结合的 R1-Searcher 框架。该框架采⽤两阶段结果监督 RL ⽅法,通过设计的奖励机制,使模型能够在推理过程中学习调⽤外部搜索引擎以获取相关知识。所提出的⽅法完全依赖于RL ,允许模型通过探索⾃主学习,⽽不需要任何指令微调冷启动。它展⽰了从域内训练数据集推⼴到域外测试数据集的能⼒,同时⽆缝切换到在线搜索以获取最新信息。此外,R1-Searcher既适⽤于基本模型,也适⽤于指令调优模型。在多个数据集上进⾏的⼤量实验表明,R1-Searcher 优于传统的RAG ⽅法和其他推理⽅法。此外,论文从多个⽅⾯分析了训练过程,包括训练⽅法、数据和奖励设计。
3. 参考材料
【1】R1-Searcher: Incentivizing the Search Capability in LLMs via Reinforcement Learning