2024-12-18 ,由宾夕法尼亚大学创建的 NAVCON ,这是一个大规模的视觉语言导航语料库,基于 R2R 和 RxR 数据集构建。该数据集通过标注导航指令中的核心概念,为模型提供更透明的跨模态对齐训练资源,显著提升了导航任务的可解释性和泛化能力。
一、研究背景
视觉语言导航(VLN)任务的目标是让机器人或其他代理能够根据语言指令在各种空间中导航。然而,当前的 VLN 模型大多为端到端的黑箱模型,缺乏对导航概念的理解和解释能力。为了提升模型的透明性和泛化能力,需要构建更高质量、标注更丰富的数据集。
目前遇到的困难和挑战:
1、数据标注成本高:构建大规模、高质量的标注数据集需要大量的人力和时间。
2、模型泛化能力不足:现有的 VLN 数据集和模型在新环境或未见指令下的表现不佳,难以泛化。
3、跨模态对齐问题:当前模型在文本和视觉输入的对齐上存在不足,影响了导航的可靠性。
数据集地址:NAVCON|视觉语言导航数据集|机器人导航数据集
二、让我们一起来看一下NAVCON
NAVCON 是一个基于 R2R 和 RxR 数据集构建的大规模视觉语言导航数据集,标注了导航指令中的核心概念,并提供了与之对应的视频片段。
NAVCON 数据集包含 30,815 条导航指令,覆盖 236,316 个概念标注,以及 270 万张与指令对应的视频帧。这些指令和视频帧均来自真实的室内场景,为模型提供了丰富的视觉和语言信息。
数据集构建:
数据集基于 R2R 和 RxR 数据集构建,通过自然语言处理技术提取指令中的核心导航概念(如“定位自己”、“改变方向”等),并利用时间戳将指令与视频帧对齐。
数据集特点:
1、大规模标注:包含超过 23 万条概念标注,覆盖 30,000 多条指令。
2、多模态对齐:提供与指令对应的视频片段,支持跨模态学习。
3、高质量验证:通过人类评估和模型验证,确保标注的准确性和可靠性。
基准测试:
研究者在 NAVCON 数据集上训练了一个导航概念分类器(NCC),准确率达到 96.53%。此外,使用 GPT-4o 的少样本学习也取得了 82.12% 的准确率,验证了数据集的有效性。
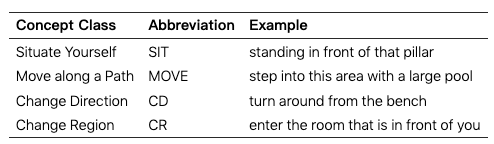
导航概念类和示例实例化

生成 NAVCON 注释的处理步骤概述
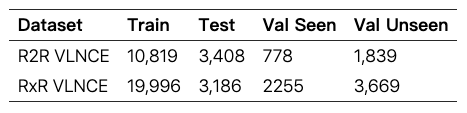
R2R & RxR 数据集中的英文指令大小
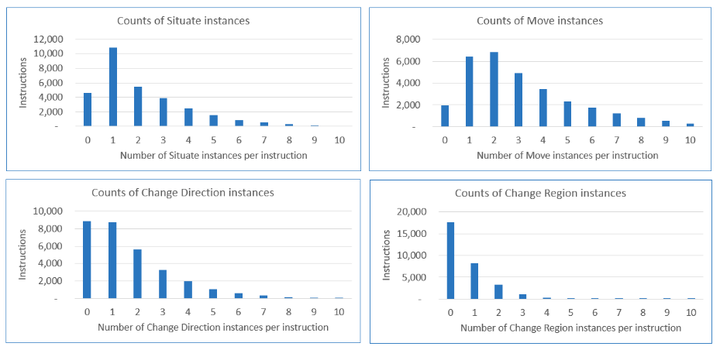
导航概念在 NAVCON 中的分布。为了直观起见,图表中省略了每条指令超过 10 个实例的指令计数和百分比。
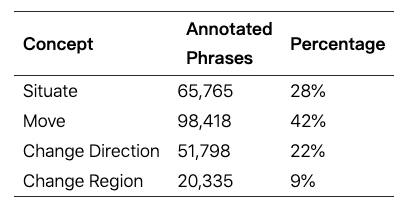
NAVCON 注释的分布
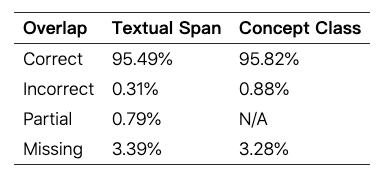
对自动注释的概念和相应的文本跨度进行人工评估

NAVCON 中的概念剪辑对齐示例。时间步长从左到右进行

概念剪辑对齐的准确性
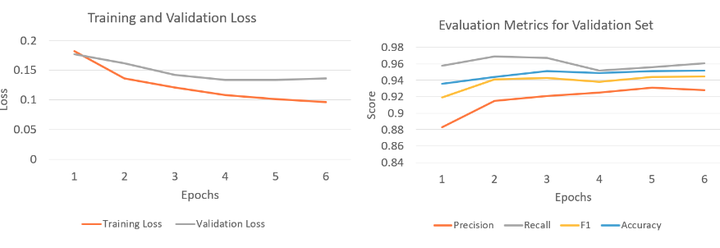
导航概念分类器 (NCC) 训练和验证特征
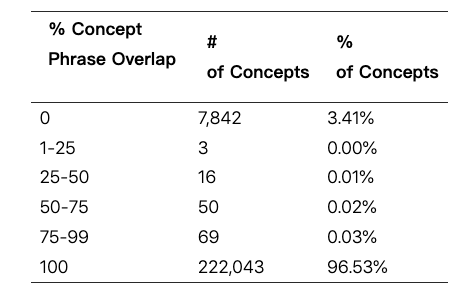
导航概念分类器 (NCC) 的评估
三、让我们一起来看一下NAVCON应用场景
在大型医院的体检中心,患者常常因为复杂的楼层布局和众多科室而迷路。尤其是对于老年人和行动不便的患者来说,找到指定的检查科室可能是一个巨大的挑战。
假如有一位老年患者需要进行心电图检查。他刚进入体检中心,面对复杂的指示牌和拥挤的人群,显得有些不知所措。这时,他可以召唤一台基于 NAVCON 数据集训练的智能导航机器人。
机器人导航过程:
1、接收指令:患者对机器人说:“带我去心电图室。”
2、理解指令:机器人通过 NAVCON 数据集训练的导航模型,迅速识别出“心电图室”是目标地点,并理解“去”意味着需要“改变区域(CR)”。
3、规划路径:机器人利用其视觉系统扫描周围环境,并结合内部地图,规划出一条从当前位置到心电图室的最佳路径。
4、导航执行:机器人开始移动,同时用语音提示患者:“请跟我来,我们先向左转,然后直走。” 在移动过程中,机器人不断识别环境中的标志物(如科室门牌),并根据 NAVCON 数据集中的“沿路径移动(MOVE)”概念,调整自己的行进方向。
5、实时调整:如果遇到临时障碍物(如其他患者或推车),机器人会自动识别并调整路径,同时用语音告知患者:“前方有障碍物,我将向右绕行。”
6、到达目标:最终,机器人顺利将患者带到心电图室门口,并说:“我们已经到达心电图室,请您进去检查。
NAVCON 数据集为智能机器人在医院场景中的导航应用提供了强大的技术支持,能够显著提升患者的就医体验。
更多开源数据集,请打开:遇见数据集
遇见数据集-让每个数据集都被发现,让每一次遇见都有价值。遇见数据集,领先的千万级数据集搜索引擎,实时追踪全球数据集,助力把握数据要素市场。![]() https://www.selectdataset.com/
https://www.selectdataset.com/