《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
摘要

- 核心问题:现有CNN架构在低分辨率图像和小物体检测任务中性能显著下降,根源在于普遍使用的跨步卷积(strided convolution)和池化层会导致细粒度信息丢失。
- 解决方案:提出新型CNN构建模块SPD-Conv,完全替代跨步卷积和池化层,由空间到深度(SPD)层+非跨步卷积层组成。
- 效果:
- 在目标检测(YOLOv5改造)和图像分类(ResNet改造)任务中验证
- 在COCO、Tiny ImageNet等数据集上显著提升AP和top-1准确率
- 对小物体检测(APs提升最高达19%)和低分辨率图像效果尤为突出

方法详解
1. SPD-Conv结构

| 组件 | 功能 | 数学表达 | 特点 |
|---|---|---|---|
| SPD层 | 特征图下采样 | 输入: X ( S , S , C 1 ) X(S,S,C_1) X(S,S,C1) → 输出: X ′ ( S s c a l e , S s c a l e , s c a l e 2 C 1 ) X'(\frac{S}{scale}, \frac{S}{scale}, scale^2C_1) X′(scaleS,scaleS,scale2C1) | 无信息丢失的下采样 |
| 非跨步卷积 | 通道数调整 | 使用stride=1的卷积核,输出 X ′ ′ ( S s c a l e , S s c a l e , C 2 ) X''(\frac{S}{scale}, \frac{S}{scale}, C_2) X′′(scaleS,scaleS,C2) | 保留全部判别性特征 |
2. 实现细节
-
SPD层工作流程:
- 按scale因子切片特征图(如scale=2时得到4个子图)
- 沿通道维度拼接子图
- 示例:640x640输入 → SPD(scale=2) → 320x320输出(通道数×4)
-
与传统方法对比:
方法 信息保留 适用场景 计算效率 跨步卷积 丢失高频信息 高分辨率场景 高 最大池化 丢失空间细节 大物体检测 高 SPD-Conv 完全保留 小物体/低分辨率 中等
创新点
-
架构革新:
- 首次完全消除CNN中的跨步操作
- 统一处理下采样(替代池化和跨步卷积)
-
理论突破:
- 证明传统下采样是性能瓶颈的理论依据
- 提出信息无损下采样范式
-
工程价值:
- 即插即用:兼容主流CNN架构(YOLO/ResNet等)
- 开源实现:提供PyTorch/TensorFlow支持
-
性能优势:
- COCO数据集小物体AP提升最高达19%
- Tiny ImageNet分类准确率提升2.84%
SPD-Conv的作用机制
在目标检测中的应用(YOLOv5-SPD)
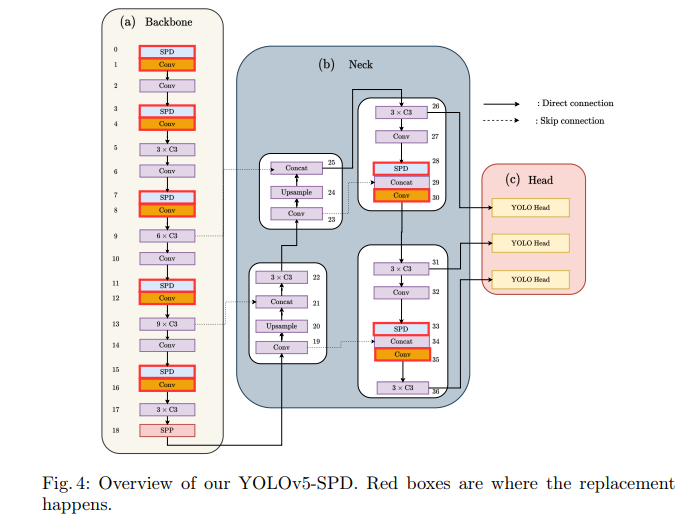
-
改造点:
- 替换7个stride=2卷积层(Backbone 5层 + Neck 2层)
- 保持原网络宽度/深度缩放策略
-
效果增强原理:
- 多尺度特征保留:SPD层将空间信息转化为通道信息
- 小物体检测:1/4分辨率下仍保持有效特征
-
可视化对比:
- 传统YOLOv5:漏检被遮挡物体(长颈鹿)
- YOLOv5-SPD:成功检测微小物体(人脸+长椅)
在图像分类中的应用(ResNet-SPD)

-
改造策略:
- 移除原始max pooling层(因输入分辨率已较低)
- 替换4个stride=2卷积
-
分类优势:
- 低分辨率图像(64x64)纹理特征保留更完整
- 错误案例分析:ResNet18误分类样本被SPD版本正确识别
总结与启示
-
核心结论:
- 传统下采样方法是小物体检测的性能瓶颈
- SPD-Conv在同等参数量下实现显著性能提升
-
应用指导:
- 推荐场景:监控摄像头、医学影像、卫星图像等小物体/低分辨率任务
- 慎用场景:高分辨率大物体检测(可能增加不必要计算量)
SPDConv模块源码与注释
#论文地址:https://arxiv.org/pdf/2208.03641.pdf
#代码地址:https://github.com/LabSAINT/SPD-Conv
import torch
import torch.nn as nn
# 自动填充函数,用于确保卷积操作后输出的特征图尺寸与输入相同
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""计算填充大小,使得卷积操作后输出尺寸与输入相同。
参数:
k (int or list): 卷积核大小
p (int or list, optional): 填充大小,默认为None
d (int or list, optional): 膨胀因子,默认为1
返回:
p (int or list): 计算后的填充大小
"""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # 计算实际卷积核大小
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # 自动计算填充大小
return p
# 定义SPDConv类,继承自nn.Module
class SPDConv(nn.Module):
"""标准卷积层,支持多种参数配置,包括输入通道数、输出通道数、卷积核大小、步幅、填充、分组、膨胀因子和激活函数。
参数:
c1 (int): 输入通道数
c2 (int): 输出通道数
k (int, optional): 卷积核大小,默认为1
s (int, optional): 步幅,默认为1
p (int or list, optional): 填充大小,默认为None
g (int, optional): 分组数,默认为1
d (int or list, optional): 膨胀因子,默认为1
act (bool or nn.Module, optional): 是否使用激活函数,默认为True
"""
default_act = nn.SiLU() # 默认激活函数为SiLU
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""初始化卷积层。
参数:
c1 (int): 输入通道数
c2 (int): 输出通道数
k (int, optional): 卷积核大小,默认为1
s (int, optional): 步幅,默认为1
p (int or list, optional): 填充大小,默认为None
g (int, optional): 分组数,默认为1
d (int or list, optional): 膨胀因子,默认为1
act (bool or nn.Module, optional): 是否使用激活函数,默认为True
"""
super().__init__()
c1 = c1 * 4 # 将输入通道数乘以4
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False) # 定义卷积层
self.bn = nn.BatchNorm2d(c2) # 定义批量归一化层
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity() # 定义激活函数
def forward(self, x):
"""前向传播函数,对输入进行卷积、批量归一化和激活操作。
参数:
x (torch.Tensor): 输入张量
返回:
torch.Tensor: 处理后的张量
"""
# 将输入张量按通道维度进行切片并拼接,增加通道数
x = torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
# 应用卷积、批量归一化和激活函数
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""前向传播函数(融合版本),对输入进行卷积和激活操作,不包含批量归一化。
参数:
x (torch.Tensor): 输入张量
返回:
torch.Tensor: 处理后的张量
"""
# 将输入张量按通道维度进行切片并拼接,增加通道数
x = torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
# 应用卷积和激活函数
return self.act(self.conv(x))

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!