《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》

论文地址:https://openaccess.thecvf.com/content/CVPR2024/papers/Zhou_Adapt_or_Perish_Adaptive_Sparse_Transformer_with_Attentive_Feature_Refinement_CVPR_2024_paper.pdf
代码地址:https://github.com/joshyZhou/AST
摘要
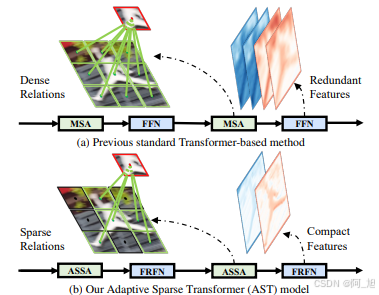
本文提出了一种名为自适应稀疏Transformer(Adaptive Sparse Transformer, AST)的模型,用于图像恢复任务。传统的Transformer模型在处理图像恢复时,虽然能够建模长距离依赖关系,但通常会引入冗余信息和噪声交互。AST通过引入自适应稀疏自注意力(Adaptive Sparse Self-Attention, ASSA)和特征精炼前馈网络(Feature Refinement Feed-forward Network, FRFN),减少了空间和通道域中的冗余信息。ASSA通过稀疏和密集两个分支自适应地过滤掉低匹配分数的查询-键对,确保信息流的充分传递。FRFN则通过增强和简化机制,消除通道中的冗余特征,提升图像恢复效果。实验结果表明,AST在去雨、去雾和去雨滴等任务中表现出色,代码和预训练模型已开源。
创新点

- 自适应稀疏Transformer(AST):提出了一种新的Transformer架构,通过自适应稀疏自注意力(ASSA)和特征精炼前馈网络(FRFN)来减少冗余信息和噪声交互。
- 自适应稀疏自注意力(ASSA):ASSA采用稀疏和密集两个分支,自适应地过滤掉低匹配分数的查询-键对,确保信息流的充分传递。
- 特征精炼前馈网络(FRFN):FRFN通过增强和简化机制,消除通道中的冗余特征,提升图像恢复效果。
- 多任务性能:AST在去雨、去雾和去雨滴等多个图像恢复任务中表现出色,展示了其多功能性和竞争力。
方法
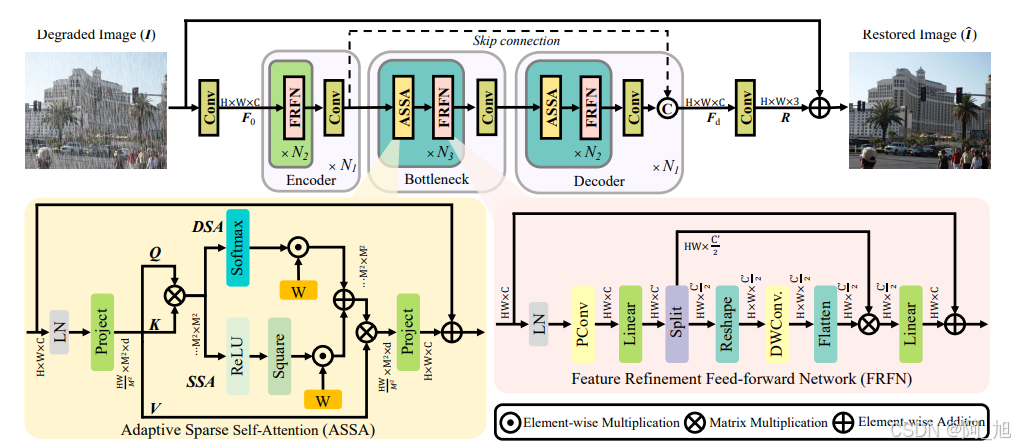
- 自适应稀疏自注意力(ASSA):ASSA由稀疏自注意力(SSA)和密集自注意力(DSA)两个分支组成。SSA通过平方ReLU激活函数过滤掉低匹配分数的查询-键对,DSA则通过softmax层保留必要的信息。两个分支的权重通过自适应机制进行调节,确保模型能够根据任务需求动态调整稀疏程度。
- 特征精炼前馈网络(FRFN):FRFN通过增强和简化机制,首先增强特征图中的有用信息,然后通过门控机制减少冗余信息。FRFN与ASSA互补,ASSA减少空间域中的冗余,FRFN则减少通道域中的冗余。
- 整体架构:AST采用对称的编码器-解码器结构,编码器和解码器分别包含多个基本块,每个基本块包含FRFN或ASSA模块。模型通过卷积层生成残差图像,最终恢复图像为输入图像与残差图像的和。
ASSA模块的作用
ASSA模块的主要作用是减少冗余信息和噪声交互,同时确保信息流的充分传递。具体来说:
- 稀疏自注意力(SSA):通过平方ReLU激活函数过滤掉低匹配分数的查询-键对,减少不相关区域的噪声交互。
- 密集自注意力(DSA):通过softmax层保留必要的信息,确保模型能够学习到有区分性的特征表示。
- 自适应机制:通过自适应权重调节稀疏和密集两个分支的贡献,使模型能够根据任务需求动态调整稀疏程度,从而在减少冗余的同时保留有用信息。
通过ASSA模块,AST能够在图像恢复任务中更有效地聚合特征,提升恢复效果。
ASSA源码与注释
import torch
import torch.nn as nn
from timm.models.layers import trunc_normal_
from einops import repeat
# 定义线性投影模块
class LinearProjection(nn.Module):
def __init__(self, dim, heads=8, dim_head=64, bias=True):
super().__init__()
# 计算内部维度
inner_dim = dim_head * heads
self.heads = heads
# 定义查询、键值对的线性变换
self.to_q = nn.Linear(dim, inner_dim, bias=bias)
self.to_kv = nn.Linear(dim, inner_dim * 2, bias=bias)
self.dim = dim
self.inner_dim = inner_dim
def forward(self, x, attn_kv=None):
B_, N, C = x.shape # 获取输入的批次大小、序列长度和特征维度
if attn_kv is not None:
# 如果提供了键值对输入,则扩展其批次大小以匹配查询输入
attn_kv = attn_kv.unsqueeze(0).repeat(B_, 1, 1)
else:
# 否则,键值对输入与查询输入相同
attn_kv = x
N_kv = attn_kv.size(1) # 获取键值对输入的序列长度
# 对查询和键值对进行线性变换并重塑为多头注意力所需的形状
q = self.to_q(x).reshape(B_, N, 1, self.heads, C // self.heads).permute(2, 0, 3, 1, 4)
kv = self.to_kv(attn_kv).reshape(B_, N_kv, 2, self.heads, C // self.heads).permute(2, 0, 3, 1, 4)
q = q[0] # 提取查询
k, v = kv[0], kv[1] # 提取键和值
return q, k, v
# 定义自适应稀疏自注意力模块
class WindowAttention_sparse(nn.Module):
def __init__(self, dim, win_size, num_heads=8, token_projection='linear', qkv_bias=True, qk_scale=None, attn_drop=0.,
proj_drop=0.):
super().__init__()
self.dim = dim # 输入特征维度
self.win_size = win_size # 窗口大小 (高度, 宽度)
self.num_heads = num_heads # 注意力头数
head_dim = dim // num_heads # 每个头的特征维度
self.scale = qk_scale or head_dim ** -0.5 # 缩放因子
# 定义相对位置偏差参数表
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * win_size[0] - 1) * (2 * win_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# 计算每个窗口内每个token的相对位置索引
coords_h = torch.arange(self.win_size[0]) # [0,...,Wh-1]
coords_w = torch.arange(self.win_size[1]) # [0,...,Ww-1]
coords = torch.stack(torch.meshgrid([coords_h, coords_w], indexing='ij')) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.win_size[0] - 1 # 调整以从0开始
relative_coords[:, :, 1] += self.win_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.win_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
trunc_normal_(self.relative_position_bias_table, std=.02)
# 定义查询、键值对的投影方式
if token_projection == 'linear':
self.qkv = LinearProjection(dim, num_heads, dim // num_heads, bias=qkv_bias)
else:
raise Exception("Projection error!")
self.token_projection = token_projection
self.attn_drop = nn.Dropout(attn_drop) # 注意力权重的dropout
self.proj = nn.Linear(dim, dim) # 输出的线性变换
self.proj_drop = nn.Dropout(proj_drop) # 输出的dropout
self.softmax = nn.Softmax(dim=-1) # softmax层
self.relu = nn.ReLU() # ReLU激活函数
self.w = nn.Parameter(torch.ones(2)) # 权重参数
def forward(self, x, attn_kv=None, mask=None):
B_, N, C = x.shape # 获取输入的批次大小、序列长度和特征维度
q, k, v = self.qkv(x, attn_kv) # 获取查询、键和值
q = q * self.scale # 缩放查询
attn = (q @ k.transpose(-2, -1)) # 计算注意力分数
# 获取相对位置偏差
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.win_size[0] * self.win_size[1], self.win_size[0] * self.win_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
ratio = attn.size(-1) // relative_position_bias.size(-1)
relative_position_bias = repeat(relative_position_bias, 'nH l c -> nH l (c d)', d=ratio)
attn = attn + relative_position_bias.unsqueeze(0) # 加上相对位置偏差
if mask is not None:
nW = mask.shape[0]
mask = repeat(mask, 'nW m n -> nW m (n d)', d=ratio)
attn = attn.view(B_ // nW, nW, self.num_heads, N, N * ratio) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N * ratio)
attn0 = self.softmax(attn) # softmax注意力分数
attn1 = self.relu(attn) ** 2 # ReLU平方注意力分数
else:
attn0 = self.softmax(attn)
attn1 = self.relu(attn) ** 2
w1 = torch.exp(self.w[0]) / torch.sum(torch.exp(self.w)) # 权重w1
w2 = torch.exp(self.w[1]) / torch.sum(torch.exp(self.w)) # 权重w2
attn = attn0 * w1 + attn1 * w2 # 加权注意力分数
attn = self.attn_drop(attn) # 对注意力分数应用dropout
# 计算输出
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x) # 线性变换
x = self.proj_drop(x) # dropout
return x
if __name__ == '__main__':
# 实例化WindowAttention_sparse类
dim = 64 # 输入特征维度
win_size = (64, 64) # 窗口大小 (高度, 宽度)
# 创建WindowAttention_sparse模块的实例
window_attention_sparse = WindowAttention_sparse(dim, win_size)
C = dim
input = torch.randn(1, 64 * 64, C) # 输入形状 (批次大小, 序列长度, 特征维度)
# 前向传播
output = window_attention_sparse(input)
# 打印输入和输出的形状
print(input.size())
print(output.size())

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!