【1】引言
前序学习过程中,已经探索了模拟退火算法、遗传算法和差分进化算法,相关文章链接为:
python学智能算法(一)|模拟退火算法:原理解释和最小值求解_模拟退火算法python-CSDN博客
python学智能算法(二)|模拟退火算法:进阶分析-CSDN博客
python学智能算法(三)|模拟退火算法:深层分析-CSDN博客
python学智能算法(四)|遗传算法:原理认识和极大值分析-CSDN博客
python学智能算法(五)|差分进化算法:原理认识和极小值分析-CSDN博客
神经网络算法和这几个算法虽然同属于智能算法,但原理上已经关联不大。
粗略概括,模拟退火算法是简单的变异造作;遗传算法叠加了选择、交叉和变异三种操作;差分进化算法则是先变异、再交叉,最后选择。这三种智能算法在学习上具有一定的类似性,实际应用中,对于求既有数据的极值都有大显身手的地方,学习上适合放到一起。
神经网络算法,具体到BP神经网络算法,和上述三种智能算法的一个重大区别是:BP神经网络算法还没有发现具体的目标函数,运行这个算法的过程,一定程度上也是找目标函数的过程,或者说散点拟合的过程。
- 声明:上述说法仅适用于初步学习阶段,仅代表个人理解。
在更早地学习中,我们也对神经网络进行了初步探索,相关文章链接为:
神经网络|(二)sigmoid神经元函数_segmod函数-CSDN博客
在此基础上,今天就学习一个简单的BP神经网络算法入门python程序,感受一下BP神经网络算法的运行过程。
【2】代码分析
【2.1】模块引入
首先引入必要的模块:
import numpy as np #引入numpy模块
import matplotlib.pyplot as plt #引入matplotlib模块【2.2】主函数
然后直接来看主函数:
# 主函数
def main():
# 生成数据
num_samples = 100
X, Y = generate_data(num_samples)
# 训练模型
hidden_size = 10
num_iterations = 1000
learning_rate = 0.1
# 训练参数
W1, b1, W2, b2, costs = train_model(X, Y, hidden_size, num_iterations, learning_rate)
# 生成测试数据
x_test = np.linspace(0, 2 * np.pi, 200).reshape(-1, 1)
y_test = np.sin(x_test)
# 进行预测
# 预测只在往前传递的运算中执行
_, _, _, y_pred = forward_propagation(x_test, W1, b1, W2, b2)
# 绘制结果
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.scatter(X, Y, label='Training Data', color='blue')
plt.plot(x_test, y_test, label='True Function', color='green')
plt.plot(x_test, y_pred, label='Predicted Function', color='red')
plt.legend()
plt.title('BP Neural Network')
plt.xlabel('x')
plt.ylabel('y')
plt.subplot(1, 2, 2)
plt.plot(np.arange(0, num_iterations, 100), costs)
plt.title('Cost over iterations')
plt.xlabel('Iterations')
plt.ylabel('Cost')
plt.show()
if __name__ == "__main__":
main()这里直接看代码构成:主函数定义后,调用了一个子函数generate_data()生成数据,然后调用train_model()来训练数据,然后生成了一堆测试数据,把测试数据代入了forward_propagation()函数进行验证。
主函数构成的逻辑非常通畅,为此,转向对子函数的追溯。
【2.3】子函数
【2.3.1】generate_data()函数生成数据
# 生成带有噪声的正弦数据
def generate_data(num_samples):
x = np.linspace(0, 2 * np.pi, num_samples)
# 白噪声符合正态分布,并使用了0.1来控制噪声的幅度
y = np.sin(x) + 0.1 * np.random.randn(num_samples)
#print('y=',y)
#print('noise=',np.random.randn(num_samples))
#将x和y都输出为num_samples行一列的数组
return x.reshape(-1, 1), y.reshape(-1, 1)自定义的generate_data()函数用于生成数据,数据的主体是正弦函数,但在这个基础上叠加了符合正态分布的白噪声。
之后,代码经自变量x和因变量y都按照数组的形式输出。
【2.3.2】train_model()函数训练数据
# 训练模型
def train_model(X, Y, hidden_size, num_iterations, learning_rate):
# 定义input_size是X的列数
input_size = X.shape[1]
# 定义output_size是Y的列数
output_size = Y.shape[1]
# 调用initialize_parameters()函数获得连接权重和偏置量
# W1是按照正态分布获得的随机数值
# b1是纯0矩阵
# W2是按照正态分布获得的随机数值
# b2是纯0矩阵
W1, b1, W2, b2 = initialize_parameters(input_size, hidden_size, output_size)
# 定义空矩阵costs
costs = []
#迭代运算
for i in range(num_iterations):
# 调用forward_propagation()函数获得正向运算值
# Z1是将输入层连接隐藏层的权重代入X,再叠加偏置量后的输出
# A1是将Z1代入激活函数后的输出
# Z2是将隐藏层连接输出层的权重代入A1,再叠加偏置量后的输出
# A2是Z2的直接赋值,没有新的变化
# Z1是个线性变化量,A2叠加了激活函数中的非线性因素
Z1, A1, Z2, A2 = forward_propagation(X, W1, b1, W2, b2)
# 运算值和目标值差分
cost = compute_cost(A2, Y)
# 计算连接权重和偏置量的逆向变化量
# dW2是A1的转置和(A2-Y)求均值后再矩阵相乘的值
# db2是(A2-Y)按列求和之后再求均值后的值
# dW1是X的转置和dZ1矩阵相乘的值
# dZ1是(A2-Y)和W2的转置先矩阵相乘,再乘以Z1代入激活函数导函数后的值
# db1是dZ1列求和之后再求均值后的值
dW1, db1, dW2, db2 = backward_propagation(X, Y, Z1, A1, A2, W1, W2)
# 更新所有连接权重和偏置量
# W1是将上一步的dW1和学习效率相乘后,和原W1作差后的值
# b1是将上一步的db1和学习效率相乘后,和原b1作差后的值
# W2是将上一步的dW2和学习效率相乘后,和原W2作差后的值
# b2是将上一步的db2和学习效率相乘后,和原b2作差后的值
W1, b1, W2, b2 = update_parameters(W1, b1, W2, b2, dW1, db1, dW2, db2, learning_rate)
if i % 100 == 0:
costs.append(cost)
print(f"Cost after iteration {i}: {cost}")
return W1, b1, W2, b2, costs自定义的train_model()函数用于训练数据,训练数据的目的是获得输入层到隐藏层、隐藏层到输出层的连接权重和偏置量等参数。
为了获得连接权重和偏置量等参数,train_model()函数继续调用了新的子函数:
- 调用initialize_parameters()函数初始化连接权重和偏置量;
- 定义激活函数sigmoid()及其导数;
- 在迭代计算中:
- 调用forward_propagation()函数获得隐藏层和输出层的运算值,以及运算值代入激活函数后的输出;
- 调用compute_cost()函数获得运算值和实际值之间的差异;
- 调用backward_propagation()函数获得初始化连接权重和偏置量的变化量:
- 调用update_parameters()函数获得新的连接权重和偏置量。
【2.3.3】 initialize_parameters()函数
# 初始化网络参数
def initialize_parameters(input_size, hidden_size, output_size):
# 输入的基本参数包括输入层、隐藏层和输出层大大小,实际对应各层的行数
# W1是从输入层进入隐藏层的连接权重
# W1=先按照正态分布的形式生成随机数,然后乘以系数0.01
# W1是一个input_size行hidden_size列的矩阵
W1 = np.random.randn(input_size, hidden_size) * 0.01
# b1是一个1行hidden_size列的矩阵
b1 = np.zeros((1, hidden_size))
# W2是从输入层进入隐藏层的连接权重
# W2=先按照正态分布的形式生成随机数,然后乘以系数0.01
# W2是一个hidden_size行output_size列的矩阵
W2 = np.random.randn(hidden_size, output_size) * 0.01
# b2是一个1行output_size列的矩阵
b2 = np.zeros((1, output_size))
return W1, b1, W2, b2自定义的initialize_parameters()函数生成了初始连接权重和偏置量参数:
连接权重都是符合正态分布的随机数乘以微小系数0.01后获得;
偏置量都是0。
【2.3.4】 sigmoid()函数及其导函数
# 定义激活函数及其导数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
return sigmoid(x) * (1 - sigmoid(x))自定义的 sigmoid()函数及其导函数是为了在连接权重中引入非线性成分。
【2.3.5】forward_propagation()函数
# 前向传播
def forward_propagation(X, W1, b1, W2, b2):
# 按照矩阵乘法的运算原则,将X和W1相乘,然后叠加偏置量b1
# X、W1和b1都是矩阵数据,会按照顺序注意叠加,类似于x[1]w1[1]+b1[1]
# 这一步的计算是从输入层接入隐藏层
# Z1是一个num_samples行hidden_size列的矩阵
Z1 = np.dot(X, W1) + b1
# 把A1代入激活函数
# 这一步的计算式获得隐藏层的输出
# 获得的A1是一个num_samples行hidden_size列的矩阵向量
A1 = sigmoid(Z1)
# 按照矩阵乘法的运算原则,将A1和W2相乘,然后叠加偏置量b2
# A1、W2和b2都是矩阵数据,会按照顺序注意叠加,类似于A1[1]w2[1]+b2[1]
# 获得的Z2是一个num_samples行output_size列的矩阵
Z2 = np.dot(A1, W2) + b2
# 这一步的计算是从隐藏层接入输出层,可以理解为所有权重都是1,偏置量都是0
# 获得的A2是一个num_samples行output_size列的矩阵
A2 = Z2
return Z1, A1, Z2, A2自定义的 forward_propagation()函数包括线性运算和激活函数运算:
先进行线性运算,让所有输入层的自变量分别和输入层到隐藏层之间的连接权重相乘,再叠加偏置量;
然后把计算值代入激活函数,激活函数运算获得的值再和隐藏层到输出层之间的连接权重相乘,此时的值直接赋给输出值。
【2.3.6】compute_cost()函数
# 计算损失(均方误差)
def compute_cost(A2, Y):
# 将矩阵Y的行数取出来赋值给m
m = Y.shape[0]
# A2是输出值,先将所有输出值和目标值作差,然后再对差进行平方求和,再对差平方和取均值
cost = (1 / (2 * m)) * np.sum(np.square(A2 - Y))
return cost自定义的compute_cost()函数将运算所的值和实际值做差分运算,然后所有差分值求平方和再求均值。
【2.3.7】backward_propagation()函数
# 反向传播
def backward_propagation(X, Y, Z1, A1, A2, W1, W2):
# 将矩阵X的行数取出来赋值给m
m = X.shape[0]
# A2是输出值,将所有输出值和目标值作差后赋值给DZ2
# dZ2是一个num_samples行output_size列的矩阵
dZ2 = A2 - Y
# 首先将A1转置为hidden_size行num_samples列的矩阵A1.T
# 然后A1和dZ2按照矩阵乘法的原则进行计算获得dW2
# dW2是一个hidden_size行output_size列的矩阵
dW2 = (1 / m) * np.dot(A1.T, dZ2)
# db2是将所有的dZ2叠加后求平均值
# axis=0表示每列从上到下求和
# dZ2有output_size列,所以会获得output_size个值
# keepdims=True会将output_size个值记录为1行output_size列的矩阵
# db2表示将1行output_size列的矩阵取均值,依然是1行output_size列的矩阵
db2 = (1 / m) * np.sum(dZ2, axis=0, keepdims=True)
# 首先将W2转置为output_size行hidden_size列的矩阵
# dZ2是一个num_samples行output_size列的矩阵
# dZ2和W2.T按照矩阵乘法的原则计算后,获得num_samples行hidden_size列的矩阵
# Z1是一个num_samples行hidden_size列的矩阵
# sigmoid_derivative(Z1)是把Z1代入激活函数的导函数的计算值,是一个num_samples行hidden_size列的矩阵
dZ1 = np.dot(dZ2, W2.T) * sigmoid_derivative(Z1)
# dZ1是np.dot(dZ2, W2.T)和sigmoid_derivative(Z1)相同位置的元素彼此相乘获得的
# dZ1是一个num_samples行hidden_size列的矩阵
# 首先将X转置成一个一行num_samples列的矩阵X.T
# 然后X.T再和num_samples行hidden_size列的矩阵dZ1相乘,获得dW1
# dW1是一个num_samples行hidden_size列的矩阵
dW1 = (1 / m) * np.dot(X.T, dZ1)
# dZ1先每一列求和,获得hidden_size个数,keepdims=True将求和结果转化为1行hidden_size列矩阵,然后再求均值
# db1是一个一行hidden_size列的矩阵
db1 = (1 / m) * np.sum(dZ1, axis=0, keepdims=True)
return dW1, db1, dW2, db2自定义的backward_propagation()函数获得四个参数:
先获得运算值和实际值的差分值;
对隐藏层的输出值和差分值做矩阵运算,此时获得隐藏层和输出层之间的权重偏移量;
将差分值求均值,获得隐藏层到输出层的偏置量偏移量;
再计算输入层打破隐藏层的线性运算值,这个线性运算值代入激活函数的导函数后获得导函数值,差分值和隐藏层到输出层的连接权重做矩阵运算,然后矩阵运算值和导函数值相乘,获得隐藏层的输出偏移量;
将输入层的自变量和隐藏层的输出偏移量做矩阵运算,获得输入层到隐藏层的连接权重偏移量;
将隐藏层的输出偏移量求均值,获得输入层到隐藏层的偏置量偏移量。
【2.3.8】update_parameters()函数
# 更新参数
def update_parameters(W1, b1, W2, b2, dW1, db1, dW2, db2, learning_rate):
# W1是一个input_size行hidden_size列的矩阵
# dW1是一个num_samples行hidden_size列的矩阵
# 实际上输入的input_size行=num_samples行
# 新获得的W1也是num_samples行hidden_size列的矩阵
W1 = W1 - learning_rate * dW1
# b1是一个1行hidden_size列的矩阵
# db1是一个一行hidden_size列的矩阵
# 新获得的b1是一个一行hidden_size列的矩阵
b1 = b1 - learning_rate * db1
# W2是一个hidden_size行output_size列的矩阵
# dW2是一个hidden_size行output_size列的矩阵
# 新获得的W2是一个hidden_size行output_size列的矩阵
W2 = W2 - learning_rate * dW2
# b2是一个1行output_size列的矩阵
# db2是一个1行output_size列的矩阵
# 新获得的b2是一个一行output_size列的矩阵
b2 = b2 - learning_rate * db2
return W1, b1, W2, b2自定义的update_parameters()函数,将上一步获得的连接权重和偏置量使用线性方程进行更新。
由于forward_propagation()函数、compute_cost()函数、backward_propagation()函数和update_parameters()函数是在迭代计算反复参与计算,所以最后会获得相对合理的连接权重和偏置量。
此时的完整代码为:
import numpy as np #引入numpy模块
import matplotlib.pyplot as plt #引入matplotlib模块
# 生成带有噪声的正弦数据
def generate_data(num_samples):
x = np.linspace(0, 2 * np.pi, num_samples)
# 白噪声符合正态分布,并使用了0.1来控制噪声的幅度
y = np.sin(x) + 0.1 * np.random.randn(num_samples)
#print('y=',y)
#print('noise=',np.random.randn(num_samples))
#将x和y都输出为num_samples行一列的数组
return x.reshape(-1, 1), y.reshape(-1, 1)
# 定义激活函数及其导数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(x):
return sigmoid(x) * (1 - sigmoid(x))
# 初始化网络参数
def initialize_parameters(input_size, hidden_size, output_size):
# 输入的基本参数包括输入层、隐藏层和输出层大大小,实际对应各层的行数
# W1是从输入层进入隐藏层的连接权重
# W1=先按照正态分布的形式生成随机数,然后乘以系数0.01
# W1是一个input_size行hidden_size列的矩阵
W1 = np.random.randn(input_size, hidden_size) * 0.01
# b1是一个1行hidden_size列的矩阵
b1 = np.zeros((1, hidden_size))
# W2是从输入层进入隐藏层的连接权重
# W2=先按照正态分布的形式生成随机数,然后乘以系数0.01
# W2是一个hidden_size行output_size列的矩阵
W2 = np.random.randn(hidden_size, output_size) * 0.01
# b2是一个1行output_size列的矩阵
b2 = np.zeros((1, output_size))
return W1, b1, W2, b2
# 前向传播
def forward_propagation(X, W1, b1, W2, b2):
# 按照矩阵乘法的运算原则,将X和W1相乘,然后叠加偏置量b1
# X、W1和b1都是矩阵数据,会按照顺序注意叠加,类似于x[1]w1[1]+b1[1]
# 这一步的计算是从输入层接入隐藏层
# Z1是一个num_samples行hidden_size列的矩阵
Z1 = np.dot(X, W1) + b1
# 把A1代入激活函数
# 这一步的计算式获得隐藏层的输出
# 获得的A1是一个num_samples行hidden_size列的矩阵向量
A1 = sigmoid(Z1)
# 按照矩阵乘法的运算原则,将A1和W2相乘,然后叠加偏置量b2
# A1、W2和b2都是矩阵数据,会按照顺序注意叠加,类似于A1[1]w2[1]+b2[1]
# 获得的Z2是一个num_samples行output_size列的矩阵
Z2 = np.dot(A1, W2) + b2
# 这一步的计算是从隐藏层接入输出层,可以理解为所有权重都是1,偏置量都是0
# 获得的A2是一个num_samples行output_size列的矩阵
A2 = Z2
return Z1, A1, Z2, A2
# 计算损失(均方误差)
def compute_cost(A2, Y):
# 将矩阵Y的行数取出来赋值给m
m = Y.shape[0]
# A2是输出值,先将所有输出值和目标值作差,然后再对差进行平方求和,再对差平方和取均值
cost = (1 / (2 * m)) * np.sum(np.square(A2 - Y))
return cost
# 反向传播
def backward_propagation(X, Y, Z1, A1, A2, W1, W2):
# 将矩阵X的行数取出来赋值给m
m = X.shape[0]
# A2是输出值,将所有输出值和目标值作差后赋值给DZ2
# dZ2是一个num_samples行output_size列的矩阵
dZ2 = A2 - Y
# 首先将A1转置为hidden_size行num_samples列的矩阵A1.T
# 然后A1和dZ2按照矩阵乘法的原则进行计算获得dW2
# dW2是一个hidden_size行output_size列的矩阵
dW2 = (1 / m) * np.dot(A1.T, dZ2)
# db2是将所有的dZ2叠加后求平均值
# axis=0表示每列从上到下求和
# dZ2有output_size列,所以会获得output_size个值
# keepdims=True会将output_size个值记录为1行output_size列的矩阵
# db2表示将1行output_size列的矩阵取均值,依然是1行output_size列的矩阵
db2 = (1 / m) * np.sum(dZ2, axis=0, keepdims=True)
# 首先将W2转置为output_size行hidden_size列的矩阵
# dZ2是一个num_samples行output_size列的矩阵
# dZ2和W2.T按照矩阵乘法的原则计算后,获得num_samples行hidden_size列的矩阵
# Z1是一个num_samples行hidden_size列的矩阵
# sigmoid_derivative(Z1)是把Z1代入激活函数的导函数的计算值,是一个num_samples行hidden_size列的矩阵
dZ1 = np.dot(dZ2, W2.T) * sigmoid_derivative(Z1)
# dZ1是np.dot(dZ2, W2.T)和sigmoid_derivative(Z1)相同位置的元素彼此相乘获得的
# dZ1是一个num_samples行hidden_size列的矩阵
# 首先将X转置成一个一行num_samples列的矩阵X.T
# 然后X.T再和num_samples行hidden_size列的矩阵dZ1相乘,获得dW1
# dW1是一个num_samples行hidden_size列的矩阵
dW1 = (1 / m) * np.dot(X.T, dZ1)
# dZ1先每一列求和,获得hidden_size个数,keepdims=True将求和结果转化为1行hidden_size列矩阵,然后再求均值
# db1是一个一行hidden_size列的矩阵
db1 = (1 / m) * np.sum(dZ1, axis=0, keepdims=True)
return dW1, db1, dW2, db2
# 更新参数
def update_parameters(W1, b1, W2, b2, dW1, db1, dW2, db2, learning_rate):
# W1是一个input_size行hidden_size列的矩阵
# dW1是一个num_samples行hidden_size列的矩阵
# 实际上输入的input_size行=num_samples行
# 新获得的W1也是num_samples行hidden_size列的矩阵
W1 = W1 - learning_rate * dW1
# b1是一个1行hidden_size列的矩阵
# db1是一个一行hidden_size列的矩阵
# 新获得的b1是一个一行hidden_size列的矩阵
b1 = b1 - learning_rate * db1
# W2是一个hidden_size行output_size列的矩阵
# dW2是一个hidden_size行output_size列的矩阵
# 新获得的W2是一个hidden_size行output_size列的矩阵
W2 = W2 - learning_rate * dW2
# b2是一个1行output_size列的矩阵
# db2是一个1行output_size列的矩阵
# 新获得的b2是一个一行output_size列的矩阵
b2 = b2 - learning_rate * db2
return W1, b1, W2, b2
# 训练模型
def train_model(X, Y, hidden_size, num_iterations, learning_rate):
# 定义input_size是X的列数
input_size = X.shape[1]
# 定义output_size是Y的列数
output_size = Y.shape[1]
# 调用initialize_parameters()函数获得连接权重和偏置量
# W1是按照正态分布获得的随机数值
# b1是纯0矩阵
# W2是按照正态分布获得的随机数值
# b2是纯0矩阵
W1, b1, W2, b2 = initialize_parameters(input_size, hidden_size, output_size)
# 定义空矩阵costs
costs = []
#迭代运算
for i in range(num_iterations):
# 调用forward_propagation()函数获得正向运算值
# Z1是将输入层连接隐藏层的权重代入X,再叠加偏置量后的输出
# A1是将Z1代入激活函数后的输出
# Z2是将隐藏层连接输出层的权重代入A1,再叠加偏置量后的输出
# A2是Z2的直接赋值,没有新的变化
# Z1是个线性变化量,A2叠加了激活函数中的非线性因素
Z1, A1, Z2, A2 = forward_propagation(X, W1, b1, W2, b2)
# 运算值和目标值差分
cost = compute_cost(A2, Y)
# 计算连接权重和偏置量的逆向变化量
# dW2是A1的转置和(A2-Y)求均值后再矩阵相乘的值
# db2是(A2-Y)按列求和之后再求均值后的值
# dW1是X的转置和dZ1矩阵相乘的值
# dZ1是(A2-Y)和W2的转置先矩阵相乘,再乘以Z1代入激活函数导函数后的值
# db1是dZ1列求和之后再求均值后的值
dW1, db1, dW2, db2 = backward_propagation(X, Y, Z1, A1, A2, W1, W2)
# 更新所有连接权重和偏置量
# W1是将上一步的dW1和学习效率相乘后,和原W1作差后的值
# b1是将上一步的db1和学习效率相乘后,和原b1作差后的值
# W2是将上一步的dW2和学习效率相乘后,和原W2作差后的值
# b2是将上一步的db2和学习效率相乘后,和原b2作差后的值
W1, b1, W2, b2 = update_parameters(W1, b1, W2, b2, dW1, db1, dW2, db2, learning_rate)
if i % 100 == 0:
costs.append(cost)
print(f"Cost after iteration {i}: {cost}")
return W1, b1, W2, b2, costs
# 主函数
def main():
# 生成数据
num_samples = 100
X, Y = generate_data(num_samples)
# 训练模型
hidden_size = 10
num_iterations = 1000
learning_rate = 0.1
# 训练参数
W1, b1, W2, b2, costs = train_model(X, Y, hidden_size, num_iterations, learning_rate)
# 生成测试数据
x_test = np.linspace(0, 2 * np.pi, 200).reshape(-1, 1)
y_test = np.sin(x_test)
# 进行预测
# 预测只在往前传递的运算中执行
_, _, _, y_pred = forward_propagation(x_test, W1, b1, W2, b2)
# 绘制结果
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.scatter(X, Y, label='Training Data', color='blue')
plt.plot(x_test, y_test, label='True Function', color='green')
plt.plot(x_test, y_pred, label='Predicted Function', color='red')
plt.legend()
plt.title('BP Neural Network')
plt.xlabel('x')
plt.ylabel('y')
plt.subplot(1, 2, 2)
plt.plot(np.arange(0, num_iterations, 100), costs)
plt.title('Cost over iterations')
plt.xlabel('Iterations')
plt.ylabel('Cost')
plt.show()
if __name__ == "__main__":
main()代码运行获得的图像为:
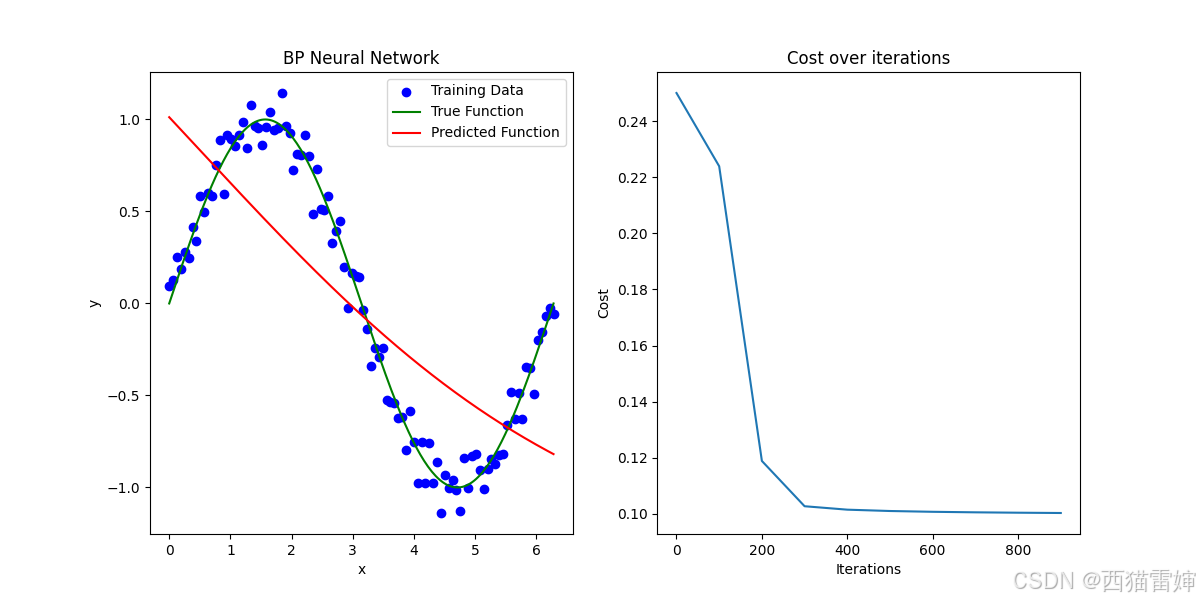
图1 BP神经网络运算效果-1000次循环
【3】代码改写
图1所示的BP神经网络运算效果实际上尚未实现很好拟合,因为左侧图的预测曲线红色线和实际的正弦函数曲线相差较大,因此还有继续优化的空间。
最简单的方法之一就是想办法增加循环次数,获得更准确的连接权重和偏置量参数:
先将循环次数从1000增加到10000:
num_iterations = 10000获得的运算图像为:
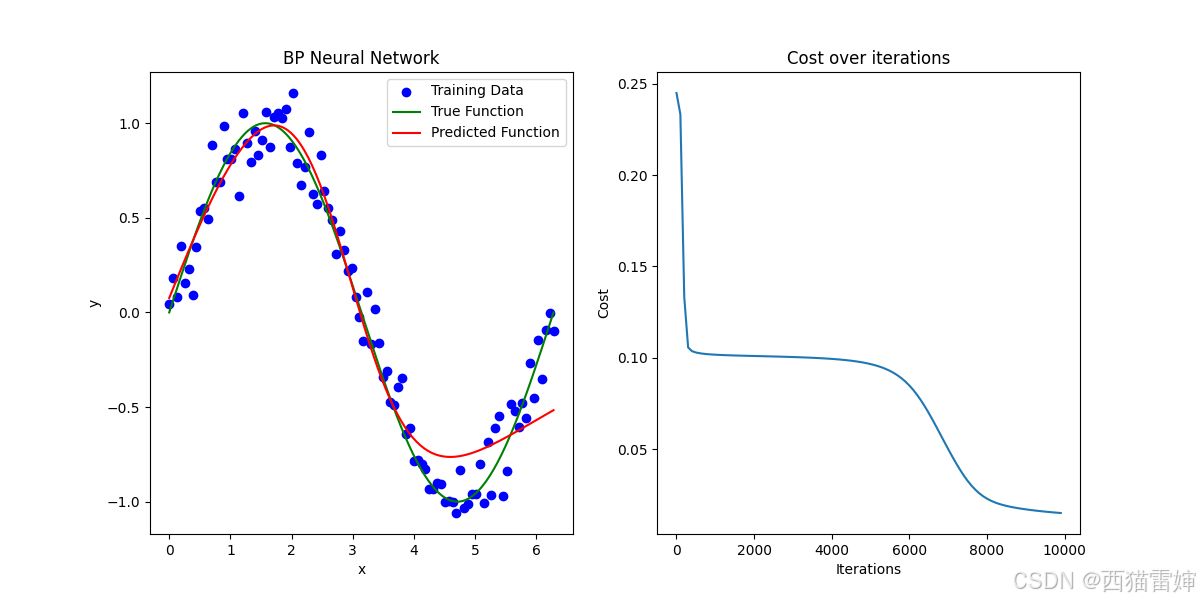
图2 BP神经网络运算效果-10000次循环
由图2可见,增大循环次数后,预测曲线和实际正弦曲线已经非常接近。
继续增加循环次数到100000次:
num_iterations = 100000获得的运算图像为:
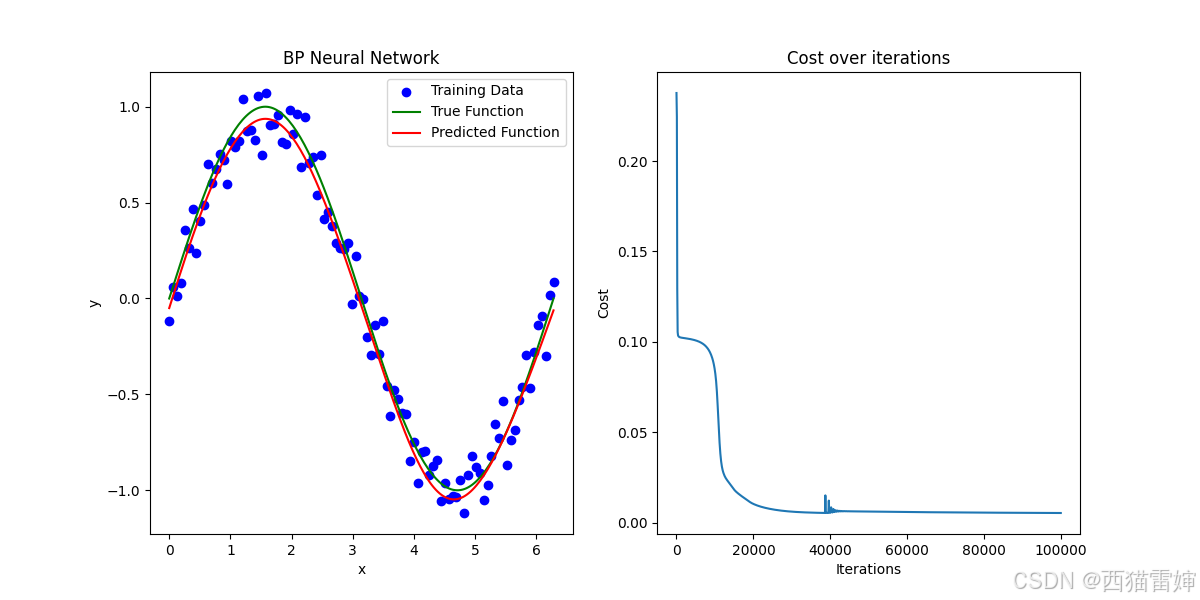
图3 BP神经网络运算效果-100000次循环
由图3可见,继续增加循环次数到100000次以后,图像的拟合效果已经较为准确。
【4】细节说明
激活函数的定义还有很多方法,此处只选择了其中一种常用的函数。
【5】总结
进行了BP神经网络算法入门学习,掌握了python使用BP神经网络算法进行函数拟合的初步技巧。