【1】引言
前序学习进程中,已经对图像检测有了各式各样的探究,相关文章包括且不限于:
python学opencv|读取图像(六十四)使用cv2.findContours()函数+cv2.drawContours()函数实现图像轮廓识别和标注-CSDN博客
python学opencv|读取图像(六十五)使用cv2.boundingRect()函数实现图像轮廓矩形标注-CSDN博客
python学opencv|读取图像(六十六)使用cv2.minEnclosingCircle函数实现图像轮廓圆形标注-CSDN博客
python学opencv|读取图像(六十七)使用cv2.convexHull()函数实现图像轮廓凸包标注-CSDN博客
python学opencv|读取图像(六十八)使用cv2.Canny()函数实现图像边缘检测-CSDN博客
python学opencv|读取图像(六十九)使用cv2.HoughLinesP()函数实现图像中的霍夫直线检测-CSDN博客
python学opencv|读取图像(七十)使用cv2.HoughCircles()函数实现图像中的霍夫圆形检测-CSDN博客
在此基础上,对实物具体标注效果的展示,深刻吸引我们。
本次学习的目标是掌握基本的人脸识别操作技巧,需要学习cv2.CascadeClassifier()函数+detectMultiScale()函数。
【2】官网教程
点击下方链接,直达cv2.CascadeClassifier()函数官网教程:
OpenCV: cv::CascadeClassifier Class Reference
在官网, 对cv2.CascadeClassifier()函数的说明较长,主要关注下述内容:
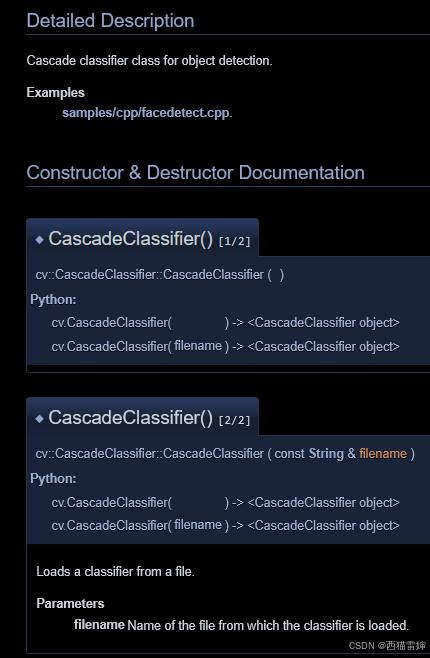
图1 官网对cv2.CascadeClassifier()函数的说明
实际应用中,多使用2/2所描述的格式,也就是需要引入一个filename作为参数,这个filename具体指向级联分类器,级联分类器在安装cv2模块的时候,已经一起安装到了电脑里,具体的位置一般为:python安装文件夹\Lib\site-packages\cv2\data。在data文件夹,会看到类似的级联分类器:
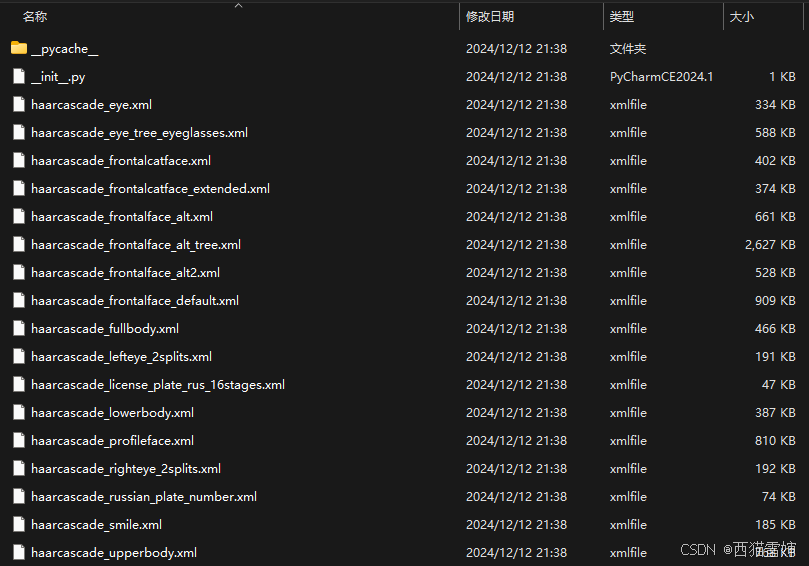
图2 安装cv2模块时存储的cv2.CascadeClassifier()函数级联分类器
实际上,cv2.CascadeClassifier()函数是加载这些级联分类器,detectMultiScale()函数才是使用这些级联分类器的实现人脸检测的真正行动者。
点击下方链接,直达detectMultiScale()函数的官网教程:
OpenCV: cv::BaseCascadeClassifier Class Reference
在这个页面其实可以先后看到cv2.CascadeClassifier()函数和detectMultiScale()函数,具体有:
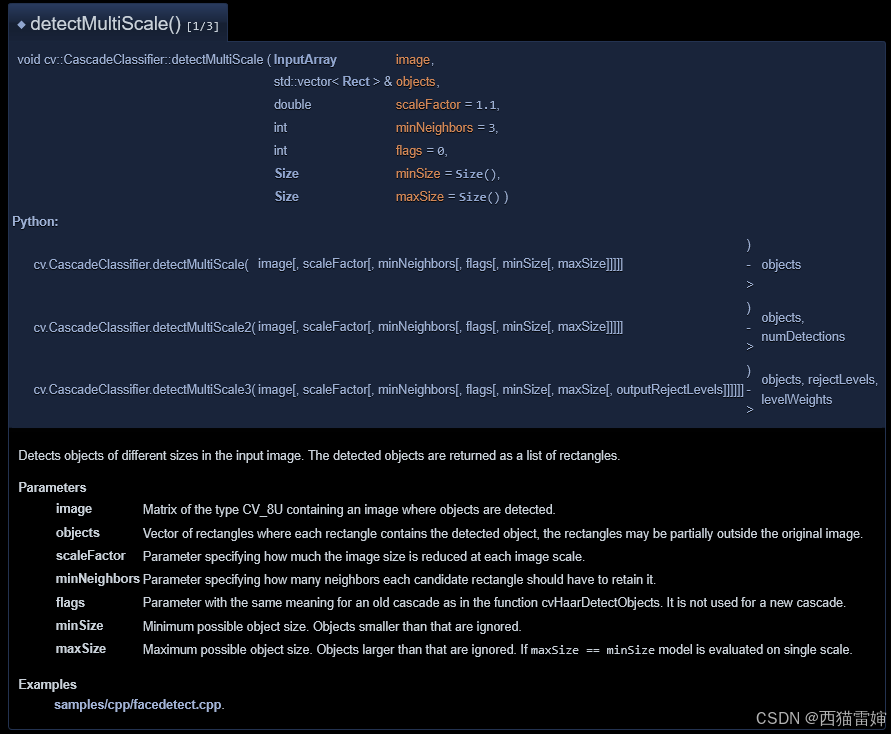
图3 官网对detectMultiScale()函数的说明。
具体的,官网对detectMultiScale()函数的参数说明有:
cv.CascadeClassifier.detectMultiScale(
image #输入图像
scaleFactor #图像缩放比例,实际缩小为原来的1/scaleFactor,取值>1
minNeighbors #可选参数,每个检测区域可检测出人脸应至少保存的特征数量
flags #可选参数,无需关注
minSize #可选参数,最小目标尺寸
maxSize) #可选参数,最大目标尺寸
在上述参数中,其实主要需要自主设置的是scaleFactor,此外图像的人脸检测尺寸只在(minSize,maxSize)区间内有效。
【3】代码测试
进入代码测试阶段。先对代码做结构设计:第一步引入图像,第二步加兹安级联分类器,第三步应用级联分类器实现人脸检测,第四步进行图像的输出处理,第五步显示和保存图像。
按照这个思路,首先引入模块和读取图像:
import cv2 as cv #引入cv2模块
import numpy as np #引入numpy模块
import os #引入os模块
# 读取原始图像
src = cv.imread('srcc.png') # 请替换为你的实际图像文件名
if src is None:
print("无法读取图像,请检查图像路径。")
exit()然后因为级联分类器比较多,把它们复制出来,到另一个单独的文件夹(保证文件夹的路径为纯英文),然后建立一个矩阵储存这些分类器:
# 定义不同的级联分类器文件路径
cascade_files = [
r"D:\python\pythonworkspace\pythonProject1\cascades\haarcascade_frontalface_default.xml",
r"D:\python\pythonworkspace\pythonProject1\cascades\haarcascade_frontalface_alt.xml",
r"D:\python\pythonworkspace\pythonProject1\cascades\haarcascade_frontalface_alt_tree.xml",
r"D:\python\pythonworkspace\pythonProject1\cascades\haarcascade_frontalface_alt2.xml",
r"D:\python\pythonworkspace\pythonProject1\cascades\haarcascade_frontalcatface.xml",
r"D:\python\pythonworkspace\pythonProject1\cascades\haarcascade_fullbody.xml"# 可以添加更多的级联分类器文件路径
]使用一个矩阵储存级联分类器,是想在之后用循环依次调用这些级联分类器,可以使代码更紧凑。
下一步需要加载级联分类器和使用级联分类器,这个过程产生的人脸检测图像将存储起来:
result_images = [] #定义矩阵储存图像
# 遍历每个级联分类器文件
for cascade_file in cascade_files:
# 检查文件是否存在
if not os.path.exists(cascade_file):
print(f"级联分类器文件不存在: {cascade_file}")
continue
# 加载级联分类器
facecascade = cv.CascadeClassifier(cascade_file)
# 检查级联分类器是否成功加载
if facecascade.empty():
print(f"无法加载级联分类器文件: {cascade_file}")
continue
# 进行目标检测
faces = facecascade.detectMultiScale(src, 1.1)
print(f"使用 {cascade_file} 检测到的目标数量: {len(faces)}")
# 复制原始图像,避免修改原始图像
result = src.copy()
# 在检测到的目标周围绘制矩形框
for (x, y, w, h) in faces:
cv.rectangle(result, (x, y), (x + w, y + h), (200, 200, 55), 2)
# 将检测结果图像添加到列表中
result_images.append(result)然后为了综合对比,把所有的图像整理成上下两行的形式:
# 拼接所有检测结果图像
if result_images:
len=len(result_images) #获取图像数量
if len%2==0: #判断图像是否为偶数
len=len
else: #如果图像数量是奇数,加一个纯黑色图像,这样做的目标是补齐两行图像
len+=1
print('len=',len)
blank_image = np.zeros_like(src)
result_images.append(blank_image)
#图像拼接
first_row = result_images[:int(0.5*len)]
second_row = result_images[int(0.5*len):len]
# 水平拼接每行的图像
h_concat_first_row = cv.hconcat(first_row)
h_concat_second_row = cv.hconcat(second_row)
# 垂直拼接两行的图像
final_image = cv.vconcat([h_concat_first_row, h_concat_second_row])
最后显示和保存所有图像:
# 显示拼接后的大图
cv.imshow('Combined Results', final_image)
cv.imwrite('Combined Results.png', final_image)
# 等待按键事件
cv.waitKey(0)
# 关闭所有窗口
cv.destroyAllWindows()
else:
print("没有有效的检测结果。")代码运行相关的图像有:

图3 初始图像

图4 人脸检测效果
由图3到图4,可见不同的级联分类器的识别效果并不一样。经过参数调试,会发现scaleFactor参数的取值不同,会影响各个级联分类器的执行效果。
为了更清楚的显示效果,可以在各个子图上添加级联分类器的名字,增添新代码:
# 获取文件名 file_name = os.path.basename(cascade_file) # 在图像上方添加文件名 text_height = int(0.1* result.shape[0]) # 文本高度 text_width = result.shape[1] # 文本高度 text_image = np.zeros((text_height, text_width, 3), dtype=np.uint8) cv.putText(text_image, file_name, (int(0.2*text_width), int(0.6*text_height)), cv.FONT_HERSHEY_SIMPLEX, 0.58, (155, 100, 155), 2) result_with_text = cv.vconcat([text_image, result]) result_images.append(result_with_text)
此时获得的新图像为:

图5 人脸检测效果带级联分类器名称
由图5可见,此时的人脸检测效果上,清晰显示各个级联分类器的名称。
此时的完整代码为:
import cv2 as cv
import numpy as np
import os
# 读取原始图像
src = cv.imread('srcc.png') # 请替换为你的实际图像文件名
if src is None:
print("无法读取图像,请检查图像路径。")
exit()
# 定义不同的级联分类器文件路径
cascade_files = [
r"D:\python\pythonworkspace\pythonProject1\cascades\haarcascade_frontalface_default.xml",
r"D:\python\pythonworkspace\pythonProject1\cascades\haarcascade_frontalface_alt.xml",
r"D:\python\pythonworkspace\pythonProject1\cascades\haarcascade_frontalface_alt_tree.xml",
r"D:\python\pythonworkspace\pythonProject1\cascades\haarcascade_frontalface_alt2.xml",
r"D:\python\pythonworkspace\pythonProject1\cascades\haarcascade_frontalcatface.xml",
r"D:\python\pythonworkspace\pythonProject1\cascades\haarcascade_fullbody.xml"
# 可以添加更多的级联分类器文件路径
]
result_images = []
# 遍历每个级联分类器文件
for cascade_file in cascade_files:
# 检查文件是否存在
if not os.path.exists(cascade_file):
print(f"级联分类器文件不存在: {cascade_file}")
continue
# 加载级联分类器
facecascade = cv.CascadeClassifier(cascade_file)
# 检查级联分类器是否成功加载
if facecascade.empty():
print(f"无法加载级联分类器文件: {cascade_file}")
continue
# 进行目标检测
faces = facecascade.detectMultiScale(src, 1.1)
print(f"使用 {cascade_file} 检测到的目标数量: {len(faces)}")
# 复制原始图像,避免修改原始图像
result = src.copy()
# 在检测到的目标周围绘制矩形框
for (x, y, w, h) in faces:
cv.rectangle(result, (x, y), (x + w, y + h), (200, 200, 55), 2)
# 获取文件名
file_name = os.path.basename(cascade_file)
# 在图像上方添加文件名
text_height = int(0.1* result.shape[0]) # 文本高度
text_width = result.shape[1] # 文本高度
text_image = np.zeros((text_height, text_width, 3), dtype=np.uint8)
cv.putText(text_image, file_name, (int(0.2*text_width), int(0.6*text_height)), cv.FONT_HERSHEY_SIMPLEX, 0.58, (155, 100, 155), 2)
result_with_text = cv.vconcat([text_image, result])
result_images.append(result_with_text)
# 拼接所有检测结果图像
if result_images:
num_images = len(result_images)
if num_images % 2 == 0:
pass
else:
num_images += 1
print('num_images=', num_images)
blank_image = np.zeros_like(src)
text_height = 20
text_image = np.zeros((text_height, blank_image.shape[1], 3), dtype=np.uint8)
blank_image_with_text = cv.vconcat([text_image, blank_image])
result_images.append(blank_image_with_text)
# 图像拼接
first_row = result_images[:int(0.5 * num_images)]
second_row = result_images[int(0.5 * num_images):num_images]
# 水平拼接每行的图像
h_concat_first_row = cv.hconcat(first_row)
h_concat_second_row = cv.hconcat(second_row)
# 垂直拼接两行的图像
final_image = cv.vconcat([h_concat_first_row, h_concat_second_row])
# 显示拼接后的大图
cv.imshow('Combined Results', final_image)
cv.imwrite('Combined Results-named.png', final_image)
# 等待按键事件
cv.waitKey(0)
# 关闭所有窗口
cv.destroyAllWindows()
else:
print("没有有效的检测结果。")【4】细节说明
不同的级联分类器最佳的scaleFactor参数并不一致,上述代码都统一为同一个数,实际的效果并未获得最佳展示。
【5】总结
掌握了python+opencv使用cv2.CascadeClassifier()函数+detectMultiScale()函数实现图像中的人脸检测的技巧。