本文来源公众号“AI生成未来”,仅用于学术分享,侵权删,干货满满。
原文链接:19款模型大PK!李飞飞团队发布首个世界生成基准WorldScore:曝出世界生成三大致命伤

文章链接:https://arxiv.org/pdf/2504.00983
开源地址:https://haoyi-duan.github.io/WorldScore/
亮点直击
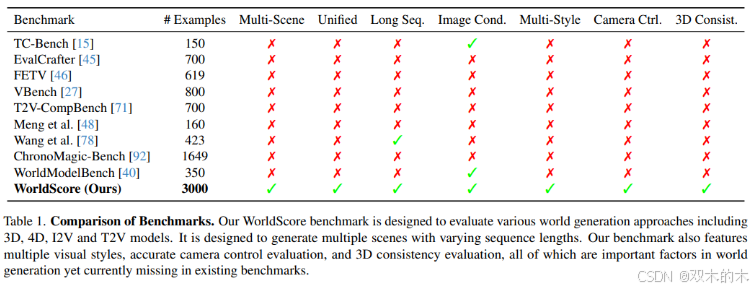
提出了首个世界生成基准 WorldScore,支持对 3D、4D、图像到视频(I2V) 和 文本到视频(T2V) 等多种方法进行统一评估。
为基准测试精心构建了一个高质量、多样化的数据集,涵盖不同类别的静态与动态场景,并包含多种视觉风格。
提出了 WorldScore 评估指标,综合衡量世界生成模型的关键性能,包括 可控性、质量 和 动态性。
通过对 17 个开源模型 和 2 个闭源模型 的全面评估,揭示了当前世界生成方法的关键洞见与挑战,为未来研究提供了宝贵指导。


风格化图像示例:预定义的风格集合包含7种不同的视觉艺术风格
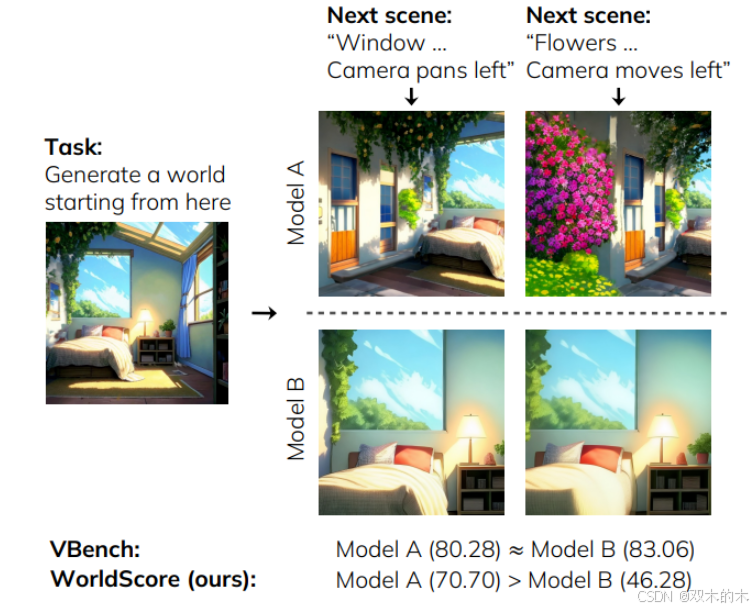
当现有视频评估基准(如VBench)基于单场景视频质量对模型A和B给出相似评分时,WorldScore基准通过识别模型B在生成新场景和执行指定摄像机运动方面的失败,有效区分了两者的世界生成能力
总结速览
解决的问题
-
缺乏统一评估标准:现有基准主要针对视频生成或单场景生成,缺乏对大规模、多样化世界生成的系统性评估。
-
控制能力不足:现有方法难以满足用户对多场景无缝集成和精确空间布局控制的需求。
-
兼容性局限:现有基准无法兼容3D/4D场景生成方法所需的相机轨迹和参考图像输入。
提出的方案
-
WorldScore 基准:首个统一的世界生成评估框架,将世界生成分解为一系列“下一场景生成”任务,每个任务包含三元组(当前场景、下一场景、布局)。
-
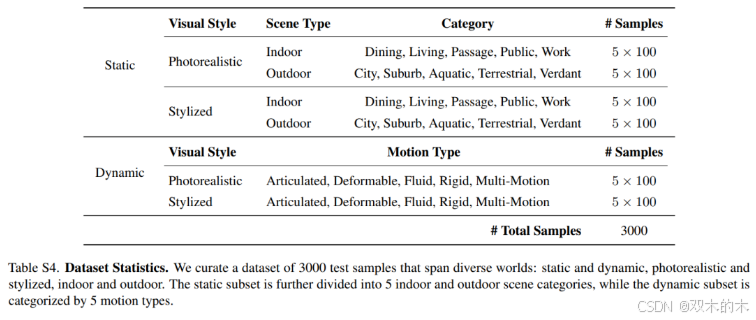
多样化数据集:涵盖静态与动态世界、室内与室外场景、写实与风格化视觉域,共3000个高质量测试样本。
-
多维度评估指标(WorldScore):
-
可控性(Controllability):生成结果对输入控制(如相机轨迹、文本描述)的遵循程度。
-
质量(Quality):生成内容的逼真性和一致性。
-
动态性(Dynamics):运动的准确性和稳定性。
-
应用的技术
-
任务分解:通过“下一场景生成”任务统一评估3D/4D场景生成、文本/图像到视频生成等多种方法。
-
统一输出格式:将所有模型的输出转换为视频格式,实现跨方法直接对比。
-
多模态输入支持:同时提供图像+文本描述作为当前场景输入,以及相机矩阵+文本描述作为布局输入,兼容不同模型需求。
达到的效果
-
全面评估:对19个代表性模型(开源/闭源)进行测试,涵盖图像到视频(5个)、文本到视频(7个)、3D场景生成(6个)和4D生成(1个)四大类。
-
关键洞见:揭示每类模型在世界生成中的优势与挑战,例如:
-
视频生成模型在动态性上表现较好,但可控性不足;
-
3D/4D生成模型在布局控制上更优,但动态场景生成能力有限。
-
-
推动领域发展:为世界生成任务提供标准化评估框架,促进多模态生成技术的融合与改进。
WorldScore 基准测试
设计概述
目标是建立一个统一不同方法论的世界生成评估基准。WorldScore 基准包含三个关键组成部分:
-
标准化的世界规范;
-
精心策划的数据集;
-
多维度的评估指标。
整体框架如下图2所示。将世界生成任务分解为一系列下一场景生成任务,其中每一步由一个包含空间布局和语义内容的世界规范定义(图2左上角)。该世界规范使得我们能够指导从3D/4D场景生成到视频生成等不同类型的模型。生成的输出结果统一以视频形式呈现(图2右下角),并通过WorldScore指标(图2右上角)评估三个关键方面:可控性、质量和动态性。这种统一的评估方法确保了不同方法论范式之间的公平比较。
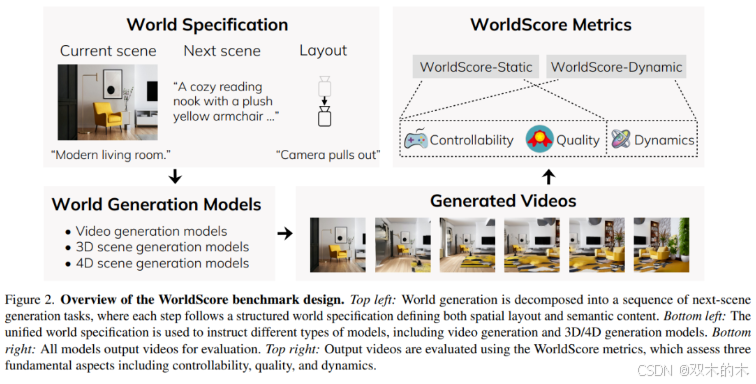
世界规范

静态与动态世界

数据集构建
数据集包含3000个世界规范样本(2000静态/1000动态),详细统计见表S4。
当前场景 C 的构建


下一场景文本描述 N 的构建

布局 L 的构建
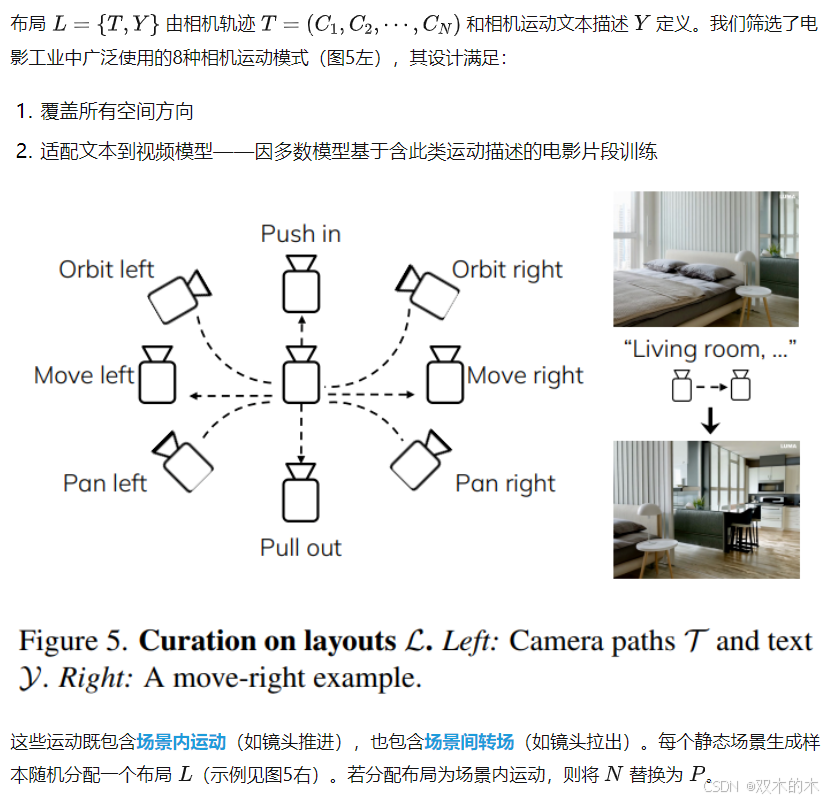
WorldScore评估指标
WorldScore包含两个综合得分:
-
WorldScore-Static:仅评估静态世界生成能力
-
WorldScore-Dynamic:额外评估动态世界生成能力
二者均通过三大关键维度的子指标聚合而成:
可控性

质量指标
3D一致性
静态世界视频的几何稳定性评估:
-
使用DROID-SLAM逐帧估计稠密深度
-
计算连续帧共视像素的重投影误差(示例见图6)

典型示例如下: 顶部:3D一致性右侧。不良示例出现几何形状突变,而非平滑过渡。中部:光度一致性。不良示例中山地草场的纹理发生严重偏移。底部:运动准确性。优秀示例中章鱼运动而水母保持静止(左),右侧不良示例则出现水母移动而章鱼静止的情况。
光度一致性
检测外观(如纹理)的稳定性:
-
计算连续帧光流的平均端点误差(AEPE)
-
有效识别纹理闪烁等问题(图6中排山脉的草纹理偏移)
风格一致性
通过Gram矩阵比较单次场景生成任务首尾帧的F-范数差异。
主观质量
结合CLIP-IQA+与CLIP审美评分的混合指标,经200人实验验证其与人类偏好最佳匹配。
动态性指标
运动准确性
量化指定区域运动的精确性:
-
对比目标区域(如汽车)与非目标区域(如行人)的光流差异
-
消除非预期相机运动带来的全局光流干扰(图6末行示例)
运动幅度
通过连续帧光流估计模型生成大幅运动的能力。
运动平滑度
利用视频插帧模型[93]生成平滑基准,评估生成视频 V 的时间连续性。
分数归一化与聚合
-
各指标线性归一化至[0,1]区间后乘以100
-
WorldScore-Static:可控性与质量维度得分的算术平均
-
WorldScore-Dynamic:额外加入动态性三个维度得分
-
不支持动态任务的3D生成模型,动态指标强制赋0
实验结果
评估模型
在WorldScore基准测试中评估了19个世界生成模型,包括:
-
12个视频生成模型:
-
2个领先闭源I2V模型:Gen-3、Hailuo
-
6个开源I2V模型:DynamiCrafter、VideoCrafter1/2、EasyAnimate、CogVideoX-I2V 、Allegro
-
4个开源T2V模型:VideoCrafter1-T2V、T2v-Turbo、Vchitect-2.0、CogVideoX-T2V
-
-
6个3D场景生成模型:SceneScape、Text2Room、LucidDreamer、WonderJourney、InvisibleStitch、WonderWorld
-
1个4D生成模型:4D-fy (完整模型细节见下表S1)

关键发现与挑战
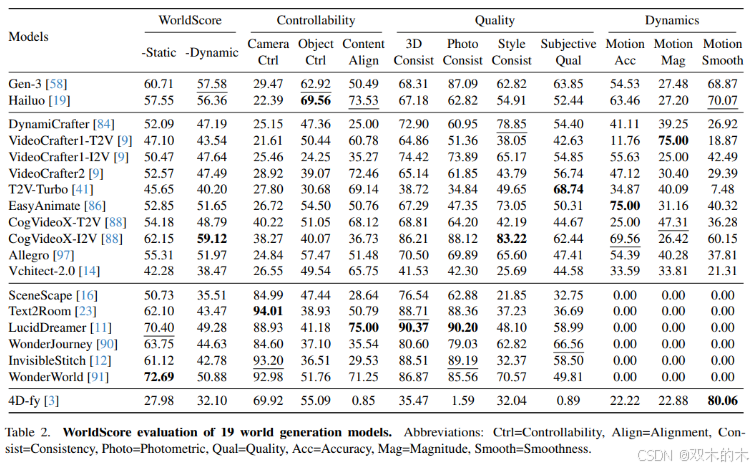
表2的基准测试结果揭示了以下结论:
3D模型在静态世界生成中占优
-
WorldScore-Static前三名均为3D模型:WonderWorld(72.69)、LucidDreamer(70.40),显著优于最佳视频模型CogVideoX-T2V(62.15)。
-
优势来源:3D模型天生具备更高的相机控制精度(通过显式3D表征)和内容对齐能力(可生成更大空间),以及优异的3D与光度一致性。
-
局限性:无法生成动态世界,扩展至4D的4D-fy表现欠佳(动态生成本身难度较高)。
视频模型的相机控制短板
-
最佳视频模型CogVideoX-T2V的相机控制得分(40.22)仍远低于任何3D/4D模型。
-
改进方向:近期相机条件注入方法[20,81]可能提供解决方案。
开源视频模型媲美闭源模型
-
CogVideoX-I2V在WorldScore-Static(62.15)和WorldScore-Dynamic(59.12)上均超过闭源模型Gen-3与Hailuo。
-
细节差异:CogVideoX-I2V相机控制更强,但物体控制与内容对齐稍弱。
运动幅度与平滑度的权衡
-
运动幅度大的模型(如Allegro)往往伴随更低的运动平滑度,反映当前视频模型难以兼顾大幅运动与自然过渡。
运动幅度≠运动准确性
-
运动幅度与准确性相关性弱(R<0.3),表明大运动模型可能产生非指令要求的相机运动或无关物体运动。
视频模型的场景局限性
-
长序列生成:视频模型在"大世界"任务(多场景序列)中表现显著下降(图7)。
-
室外场景:视频模型与3D模型的性能差距在室外场景中更大(室内场景差距较小)。
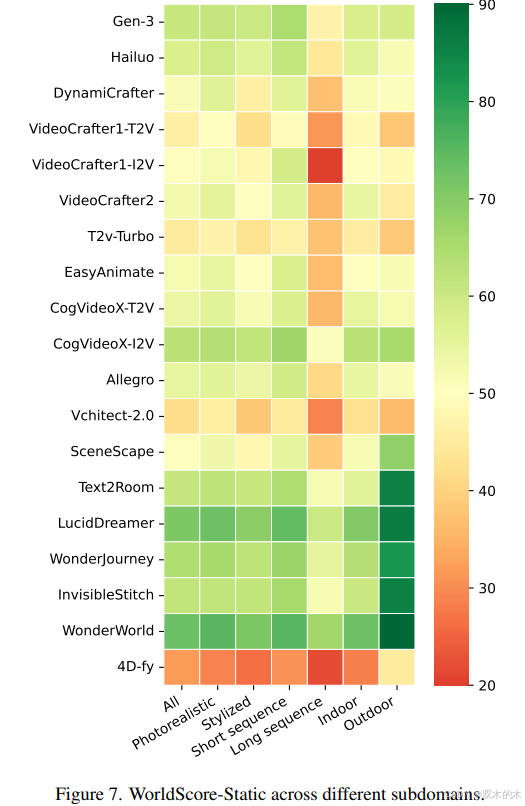
T2V vs I2V的控制差异
-
T2V模型:更易控制(可控性得分高+运动幅度大),但倾向于生成更大相机运动。
-
I2V模型:质量得分更高,但受输入图像视角限制,生成新场景内容的能力较弱。
结论
总之,WorldScore基准测试揭示了当前各类世界生成方法的局限性。对于3D场景生成模型,虽然它们在静态世界生成方面表现出色,但将其扩展到4D表征并融入动态性仍然具有挑战性。对于视频生成模型,主要挑战包括可控性、长序列生成以及室外场景的生成。这些发现为未来研究指明了清晰方向:弥合3D与4D表征之间的差距、开发更鲁棒的可控性机制、以及设计能够处理长场景序列的架构。我们相信WorldScore基准将成为衡量这些方向进展的有价值工具,最终推动该领域发展出更强大、更通用的世界生成系统。
参考文献
[1] WorldScore: A Unified Evaluation Benchmark for World Generation
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。