本文来源公众号“阿旭算法与机器学习”,仅用于学术分享,侵权删,干货满满。
原文链接:【实战】使用GroundingDino实现零样本自动标注【附源码】
引言

目前,深度学习已经产生了很多基础模型。这些以一般方式在大规模数据集上训练的大型模型,使它们能够适应各种任务。这些模型的例子包括用于图像分类的[CLIP],用于分割的SAM和用于对象检测的GroundingDino。基础模型通常很大,计算要求很高。当没有资源限制时,它们可以直接用于零样本推理。它们也可以用于标记数据集,以便训练更具体的模型。
在本文中,我们将学习如何使用GroundingDino模型对番茄图像进行零样本推理。我们将探索该算法的功能,并使用它来标记整个番茄数据集。然后,可以使用生成的数据集来训练下游目标模型,例如YOLO。
GroundingDino简介
背景
GroundingDino是由IDEA-Research于2023年开发的最先进(SOTA)算法。它使用文本提示从图像中检测对象。“GroundingDino”这个名字是“grounding”(人工智能系统中连接视觉和语言理解的过程)和基于ransformer的探测器“DINO”的组合。该算法是一个零样本对象检测器,这意味着它可以从它没有专门训练过的类别中识别对象,而不需要看到任何示例样本。
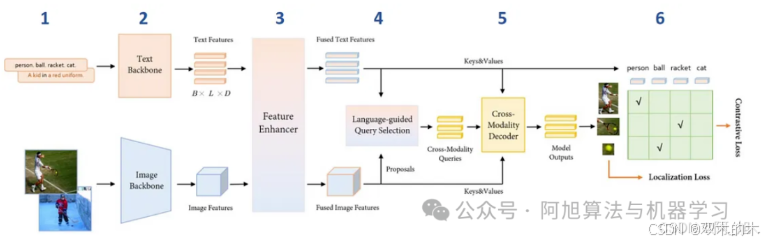
基本架构
-
该模型以成对的图像和文本描述作为输入。
-
图像特征是用图像主干(如Swin Transformer)提取的,文本特征是用文本主干(如BERT)提取的。
-
特征增强器模块通过多模态细化将文本和图像特征结合起来,使用交叉注意机制来促进这两种模态之间的交互。
-
接下来,“搜索引导查询选择”模块选择与输入文本最相关的特征用作解码器查询。
-
然后,这些查询被送到解码器中,以细化与文本信息最佳对齐的对象检测框的预测。它输出最终的边界框建议。
-
该模型输出900个对象边界框及其与输入单词的相似性得分。选择相似度分数高于
box_threshold的框,并将相似度高于text_threshold的词作为预测标签。
在这里插入图片描述
提示工程
GroundingDino模型将文本提示编码到学习的潜在空间中。更改提示可能会导致不同的文本特征,从而影响检测器的性能。为了提高预测性能,建议使用多个提示进行试验,选择提供最佳结果的提示。值得注意的是,在写这篇文章时,我们会尝试几个不同的提示,然后才找到理想的提示,有时会遇到意想不到的结果。
代码实现
入门
开始,我们将从GitHub克隆GroundingDino仓库,通过安装必要的依赖项来设置环境,并下载预训练的模型权重。
# Clone:
!git clone https://github.com/IDEA-Research/GroundingDINO.git
# Install
%cd GroundingDINO/
!pip install -r requirements.txt
!pip install -q -e .
# Get weights
!wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
图像推理
我们将通过将对象检测算法应用于单个西红柿图像来开始探索该算法。我们最初的目标是检测图像中的所有西红柿,因此我们将使用文本提示tomato。如果你想使用不同的类别名称,你可以用一个点来分隔它们。.请注意,边界框的颜色是随机的,没有特定的含义。
python3 demo/inference_on_a_image.py \
--config_file 'groundingdino/config/GroundingDINO_SwinT_OGC.py' \
--checkpoint_path 'groundingdino_swint_ogc.pth' \
--image_path 'tomatoes_dataset/tomatoes1.jpg' \
--text_prompt 'tomato' \
--box_threshold 0.35 \
--text_threshold 0.01 \
--output_dir 'outputs'
结果如下:

上图是带有“tomato”提示词的标注。GroundingDino不仅可以将对象检测为类别,例如西红柿,还可以对输入文本进行解析,这是一项称为引用表达式理解(REC)的任务。让我们将文本提示符从tomato更改为ripped tomato,并获得结果:
python3 demo/inference_on_a_image.py \
--config_file 'groundingdino/config/GroundingDINO_SwinT_OGC.py' \
--checkpoint_path 'groundingdino_swint_ogc.pth' \
--image_path 'tomatoes_dataset/tomatoes1.jpg' \
--text_prompt 'ripened tomato' \
--box_threshold 0.35 \
--text_threshold 0.01 \
--output_dir 'outputs'
结果如下:

带有“成熟的番茄”提示词的标注。
值得注意的是,该模型可以“理解”文本,并区分“西红柿”和“成熟的西红柿”。它甚至可以标记未完全红色的部分成熟的西红柿。如果我们的任务只需要标记完全成熟的红番茄,我们可以将box_threshold从默认值0.35调整为0.5。
python3 demo/inference_on_a_image.py \
--config_file 'groundingdino/config/GroundingDINO_SwinT_OGC.py' \
--checkpoint_path 'groundingdino_swint_ogc.pth' \
--image_path 'tomatoes_dataset/tomatoes1.jpg' \
--text_prompt 'ripened tomato' \
--box_threshold 0.5 \
--text_threshold 0.01 \
--output_dir 'outputs'
结果如下:

在这里插入图片描述
带有“ripened tomato”提示词的标注,**box_threshold = 0.5**。
标记数据集的生成
尽管GroundingDino具有卓越的功能,但它是一个庞大而缓慢的模型。如果需要实时目标检测,请考虑使用更快的模型,如YOLO。训练YOLO和类似的模型需要大量的标记数据,这可能是昂贵和耗时的。但是,如果你的数据不是唯一的,你可以使用GroundingDino来标记它。
GroundingDino库包含一个脚本,用于以COCO格式标注图像数据集,例如,该格式适用于YOLOx。
from demo.create_coco_dataset import main
main(image_directory= 'tomatoes_dataset',
text_prompt= 'tomato',
box_threshold= 0.35,
text_threshold = 0.01,
export_dataset = True,
view_dataset = False,
export_annotated_images = True,
weights_path = 'groundingdino_swint_ogc.pth',
config_path = 'groundingdino/config/GroundingDINO_SwinT_OGC.py',
subsample = None
)
-
export_dataset -如果设置为True,COCO格式注释将保存在名为'coco_dataset'的目录中。
-
view_dataset -如果设置为True,注释的数据集将在FiftyOne应用程序中显示以进行可视化。
-
export_annotated_images -如果设置为True,则带注释的图像将存储在名为“images_with_bounding_boxes”的目录中。
-
subsample(int)-如果指定,则仅注释数据集中的此数量的图像。
不同的YOLO算法需要不同的注释格式。如果您计划训练YOLOv5或YOLOv8,则需要以YOLOv5格式导出数据集。尽管导出类型在主脚本中是硬编码的,但您可以通过调整create_coco_dataset.main中的dataset_type参数来轻松更改它,从fo.types.COCODetectionDataset更改为fo.types.YOLOv5Dataset(第72行)。为了保持有序,我们还将输出目录名从'coco_dataset'更改为'yolov5_dataset'。更改脚本后,再次运行create_coco_dataset.main。
if export_dataset:
dataset.export(
'yolov5_dataset',
dataset_type=fo.types.YOLOv5Dataset
)
总结
GroundingDino通过使用文本提示,在对象检测注释方面实现了重大飞跃。在本教程中,我们探索了如何使用模型自动标记图像或整个数据集。然而,在训练后续模型之前,手动检查和验证这些注释是至关重要的。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。