本文来源公众号“码科智能”,仅用于学术分享,侵权删,干货满满。
原文链接:边缘设备也能跑SOTA实时物体检测模型?DINOv2预训练+DETR端到端的黄金组合,第一个超60AP的模型!
前天的文章刚提到为了加速实时视觉检测的几种方法,其中介绍到Roboflow的异步处理方式能有效提高视觉应用的处理速度。具体可查看:码科智能 | 加速实时视觉检测应用,在边缘设备部署上实现2.4倍的加速!-CSDN博客
今天Roboflow就开源了SOTA 实时物体检测模型RF-DETR,其在现实世界数据集上的表现优于所有现有的物体检测模型,并且是第一个在 COCO 数据集上进行基准测试时达到 60+ 平均精度的实时模型。

RF-DETR 属于“DETR”(检测 Transformer)模型系列。RF-DETR 足够小,可以在边缘运行,这使其成为需要高精度和实时性能的部署的理想模型。从下图的指标上可以看到基本碾压了YOLO整个系列模型的效果!最小的模型只有29M的参数量,分为RF-DETR-base(29M 个参数)和 RF-DETR-large(128M 个参数)。
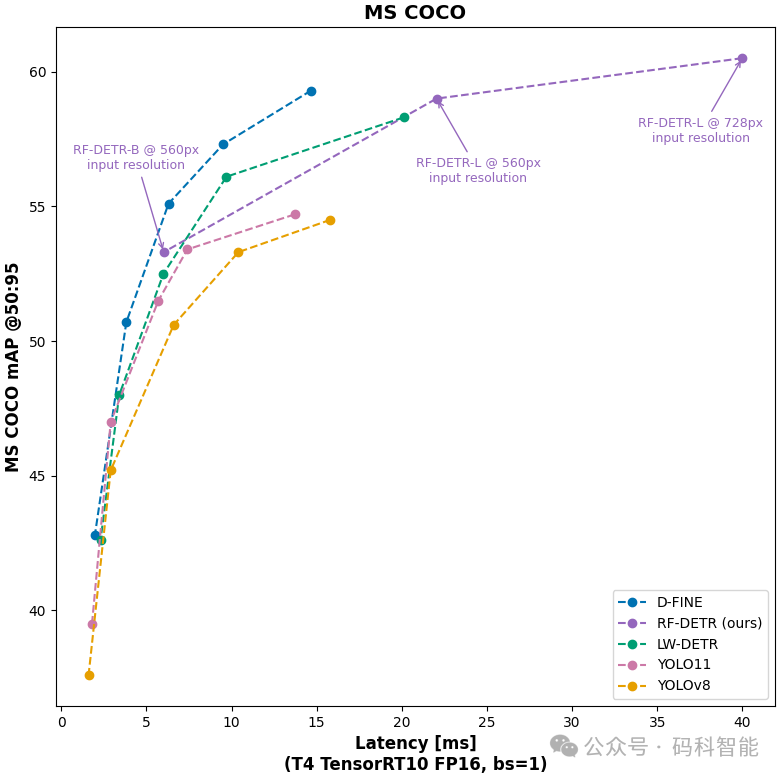
有同学就会提到了,不就是COCO的SOTA吗?新的检测模型在COCO上达不到SOTA还怎么好意思吹?
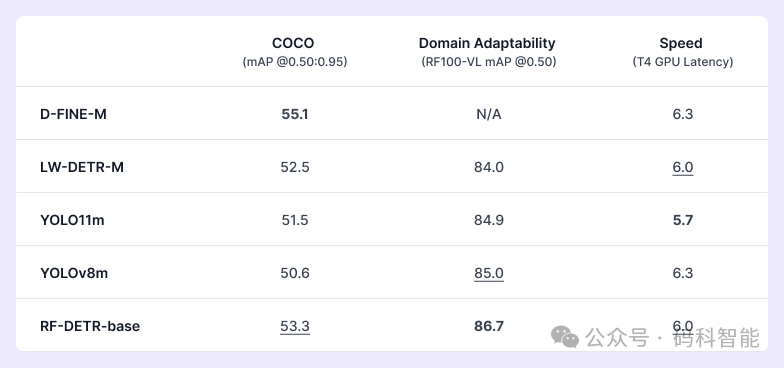
这里就得好好说下了,Roboflow团队除了在COCO上进行评估外,还希望展示为什么领域适应性是更重要的评估指标。他们从 Universe 的 500,000 多个开源数据集中挑选出来的 100 个数据集,构建了一个新数据集RF100-VL。它代表了计算机视觉如何实际应用于无人机监测、工业检测、安防监控、智能零售等问题。
RF-DETR 是所有类别中唯一排名第一或第二的模型,显示的速度是使用 TensorRT10 FP16 (ms/img) 的 T4 上的 GPU 延迟。
RF-DETR 架构概述
YOLO目标检测在工业界的落地应用,使得CNN仍然是计算机视觉领域的核心组成部分,但CNN 本身无法像基于 Transformer 的方法那样从大规模预训练中获益。从目前LLM或者MLLM大模型来看,预训练对于实现出色的结果越来越重要。
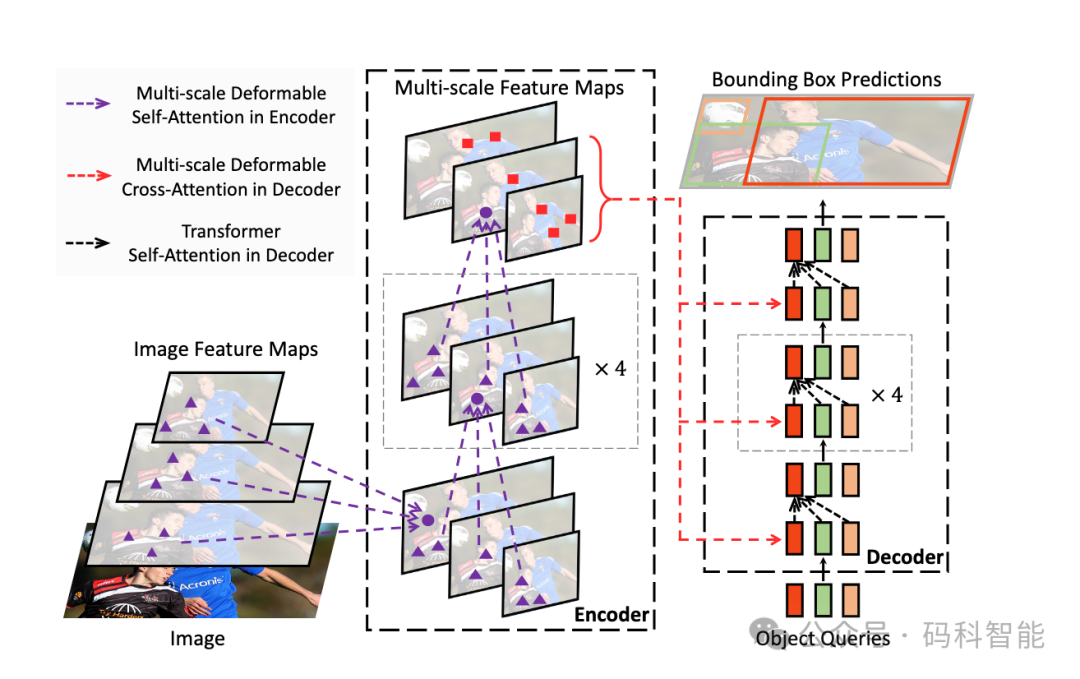
那我们来看下RT-DETR的技术原理:
-
预训练的DINOv2主干:DINOv2基于在大规模数据集上进行自监督预训练,这也是视觉大模型常用的模型架构。通过将 LW-DETR 与预训练的 DINOv2 主干相结合来创建 RF-DETR。这使模型能够根据预训练的 DINOv2 主干中存储的知识来适应新领域,在面对新领域和小数据集时具有适应能力和泛化能力。
-
单尺度特征提取:可变形 DETR 采用多尺度自注意力机制,而RT-DETR从单尺度主干中提取图像特征图,从而降低计算复杂度。
-
多分辨率训练:用户根据实际需求灵活调整,无需重新训练模型,实现精度与延迟的动态平衡。
-
优化的后处理策略:在评估模型性能时,RF-DETR基于优化的非极大值抑制(NMS)策略,确保在考虑NMS延迟的情况下,模型的总延迟(TotalLatency)保持在较低水平,真实地反映模型在实际应用中的运行效率。

RF-DETR 模型微调
可以使用 rfdetr Python 包对 RF-DETR 进行微调,Roboflow Train 支持将在未来几天内提供。

也可以查看模型微调指南,其中逐步介绍如何训练您自己的 RF-DETR 模型。还可以在 GitHub 上查看该模型背后的源代码:
Code:https://github.com/roboflow/rf-detr
Demo:https://huggingface.co/spaces/SkalskiP/RF-DETR
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。