目录
前言
今天zty带来的是指针的详解,说实话,这个指针在我还没有写这篇博客之前,我都弄不明白,我也就是上网学学,然后学完之后给大家写个博客,
先 赞 后 看 养 成 习 惯
众所周知,一篇博客需要一个头图

先 赞 后 看 养 成 习 惯
演示用编译器
Dev C++ 6.7.5 Red panda
想下载编辑器的宝宝们点我
语言标准
C++14
先 赞 后 看 养 成 习 惯
正文
先来一波简介
在C++中,指针是一种极为特殊且关键的变量类型,它存储的是数据的内存地址而非数据值本身。尽管指针的概念相对抽象,用法也颇为复杂,使得不少初学者感到晕头转向(比如我),但一旦能灵活运用指针,你便能实现对程序内存的精准把控,甚至细化到字节级别的控制。因此,学会并熟练使用指针,无疑是掌握C++的必经之路。(所以你必须要看完这个博客,并且给这个博客来一个三连)
指针入门
1,初见指针
在正式介绍指针之前,需要先简单介绍一下计算机内存。首先需要明确的一点是,程序是运行在计算机内存里的,你可以将内存看成一个个可以存储数据的小盒子(内存单元),而且这些小盒子有自己在内存中唯一的编号(地址),而指针实际上存储的就是这些编号的值。
假设你家内存是这样的
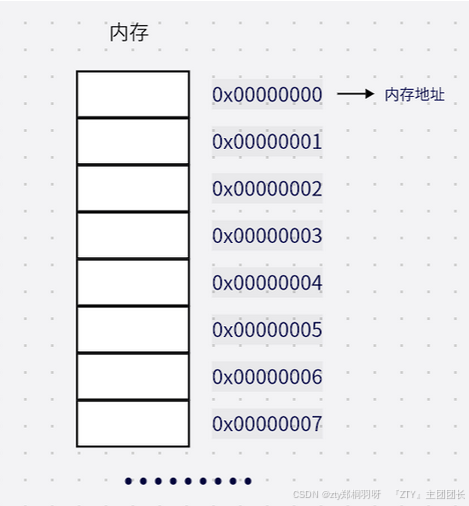
接下来介绍一下指针的基础语法。
声明一个指针的语法很简单:类型* 变量名,然后因为指针存放的是变量的内存地址,所以C++中可以通过 “&” 这个关键字来获取一个变量的地址,具体用法为:&变量 。具体使用如下代码所示:
#include <bits/stdc++.h>
using namespace std;
//你有没有给 zty郑桐羽呀 三连?什么?没有那你还在等什么?
int main() {
int a = 114514; //声明一个变量
int* p = &a; //通过&对变量a取地址,并将地址赋值给指针p
cout << p << endl; // 0x28ff28,变量a在内存中的地址编号
return 0;
}
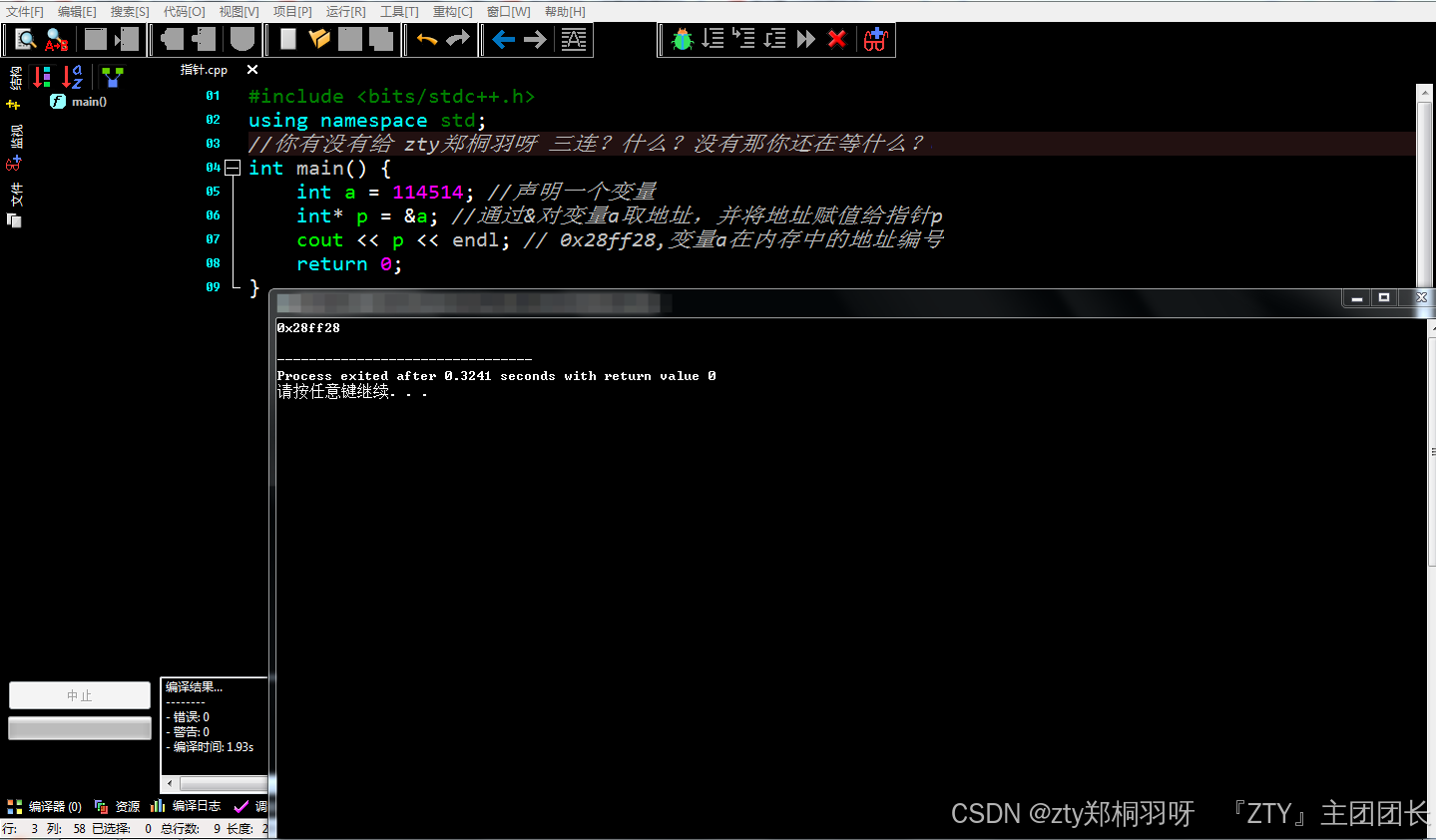
然后是指针占用的内存大小。
指针变量的大小取决于你所使用的平台以及编译器设置,一般来说,32位平台的指针大小就为32位(4字节),不会因为指针的类型不同而改变。同样,64位平台的指针大小就为64位(8字节),也不会因为指针的类型不同而改变。这里 zty 使用的是默认的32位,所以指针大小为4字节。
cout << sizeof(p) << endl; // 4
2,指针解引用
我们之前说过,指针是存储变量地址的变量类型,直接输出指针的值,得到的也只是一个地址编号,但是我们可以使用“解引用”这一操作来获取指针所指向的变量的值。
解引用的方法也很简单,通过*这一关键字来实现。具体语法为“*指针变量名”,具体使用如下所示:
int main() {
int a = 10; //声明一个变量
int* p = &a; //通过&对变量a取地址,并将地址赋值给指针p
cout << p << endl; // 0xfffaa8,变量a在内存中的地址编号
cout << *p << endl; // 10,p所指向的内存的值,即a的值
return 0;
}
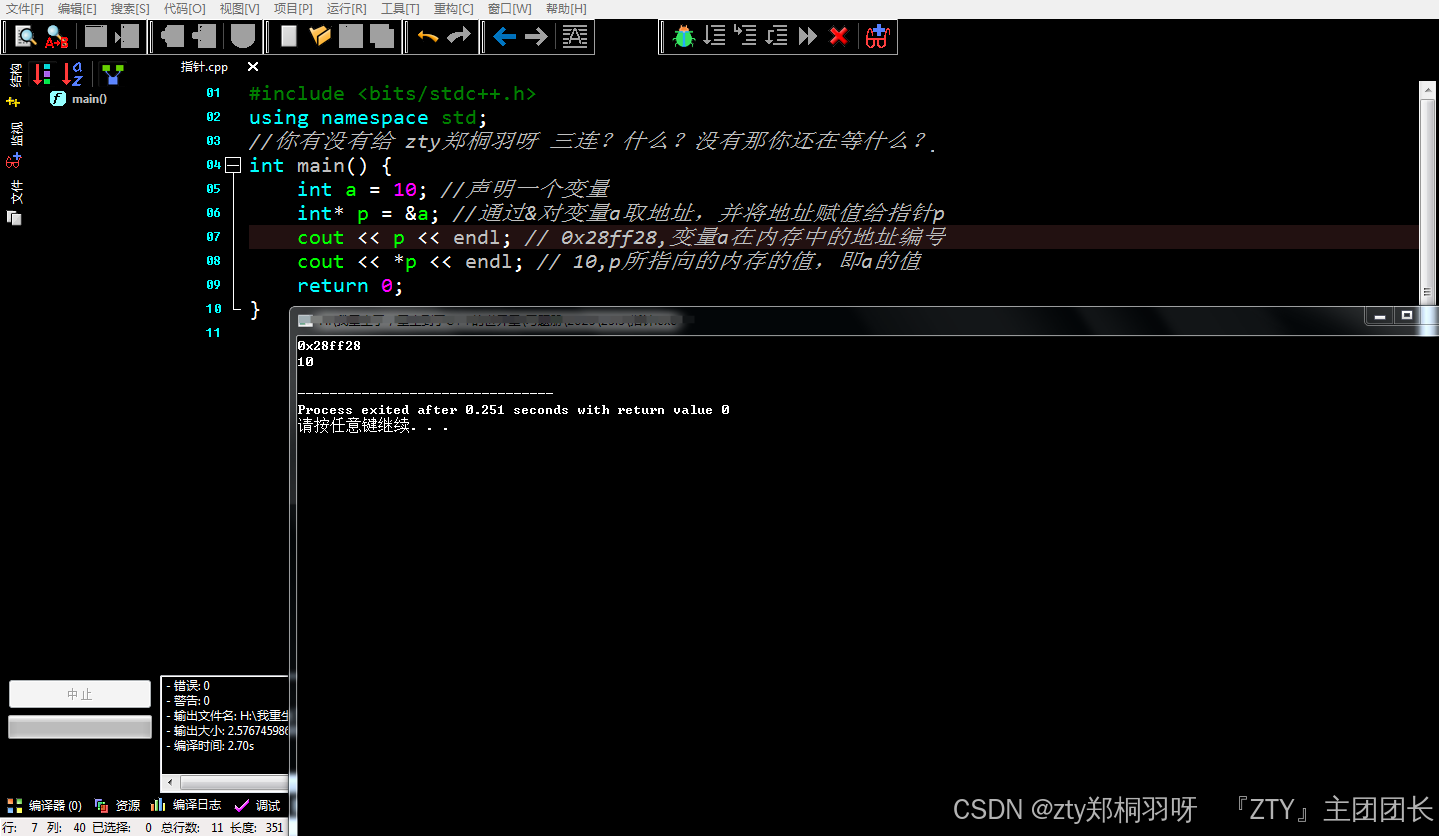 需要注意的是,指针解引用后也可以被赋值,当你对解引用的指针赋值时,会改变其所指向的内存中的值,而不会改变指针本身的值(因为指针本身存放的是地址),这个非常重要,需要尤其注意。
需要注意的是,指针解引用后也可以被赋值,当你对解引用的指针赋值时,会改变其所指向的内存中的值,而不会改变指针本身的值(因为指针本身存放的是地址),这个非常重要,需要尤其注意。
int main() {
int a = 10;
int *p = &a;
cout << p << endl; // 0x28ff28
cout << a << endl; // 10
*p = 20; // p解引用后对其赋值,即修改p所指向的内存中的值
cout << p << endl; // 0x28ff28
cout << a << endl; // 20
}
(我也不知道为什么我的内存地址总是0x28ff28)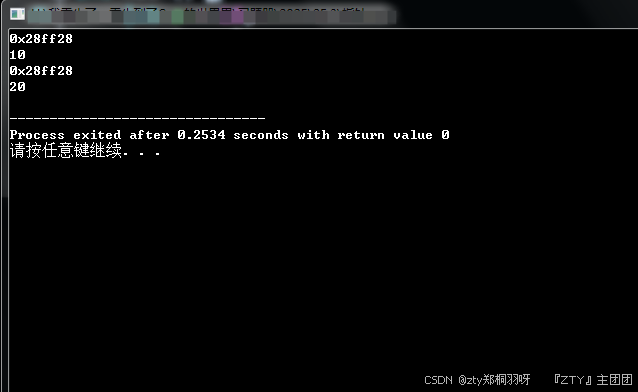
可以发现,我们在中途对
p进行解引用并赋值,最终改变了a的值,因为p指向的是变量a所在的内存,而p的值(a的地址)并没有改变。
补充:
很多同学容易将 *p 和 int* p 混淆,这里 zty 再特意强调一下,p 是指针的变量名,可以任意(前提需符合变量命名规则),int*是指针类型,代表p是一个指向int类型变量的指针,而*p则表示对指针p进行解引用,以获取其指向的变量的值,可以把解引用后得到的值赋值给其他相同类型的变量,也可以将值赋值给解引用后的指针,即修改指向的内存中的值。
3,指针的类型
虽然上述例子全是使用int变量来举例,但实际上指针可以指向任意类型的数据。有的同学可能会感到疑惑,既然指针的大小都是固定的4字节或8字节,那么为什么声明指针时,还要指明指针的类型?接下来将介绍指针类型的作用。
指针可以指向任意类型的数据,所以指针有多种多样的类型。
int main() {
int a = 10;
char c = 'a';
float f = 1.0f;
int* p_a = &a;
char* p_c = &c;
float* p_f = &f;
return 0;
}
但我们都知道,不同的数据类型所占用的内存大小是不相同的,例如
int占了4个字节,而char只占一个字节,因此需要为指针区分类型的一大原因就是要保证指针在解引用时能获取正确大小内存的数据,本质目的还是为了内存安全。例如,int*的指针解引用会得到4字节大小的数据,而char*解引用则会得到1字节大小的数据,其获取多大内存的数据其实就是指针的类型。其他类型的指针也是同理。
int main() {
int a = 10;
char c = 'a';
int* p_a = &a;
char* p_c = &c;
cout << sizeof(p_a) << endl; // 输出4,占用4字节
cout << sizeof(p_c) << endl; // 输出4,占用4字节
cout << *p_a << endl; // 10
cout << *p_c << endl; // a
cout << sizeof(*p_a) << endl; // 输出4,占用4字节
cout << sizeof(*p_c) << endl; // 输出1,占用1字节
return 0;
}
自定义复杂类型,如结构体,对象(不是那个对象奥,再说你也没有),也可进行取地址,并且尤其自己对应的指针类型。例如:
struct A {
int id;
char ch;
};
int main() {
A a;
A* p = &a; // 对结构体取地址,赋值给指针p
return 0;
}
4,野指针和空指针
(1)野指针
野指针是指向一个无效的内存地址的指针,即指针的值不是有效的内存地址。这些无效的内存地址可能已经被释放或者尚未分配,因此野指针的使用会导致程序崩溃或产生不可预料的错误。举个例子:
int main() {
int* p = (int*) malloc(4); // 开辟4字节大小的内存,并将内存地址赋值给指针p
*p = 10; // 将p指向的内存中的值设置为10
cout << *p << endl; 10
free(p); // 释放p所指向的内存
cout << *p << endl; // 输出随机的值,此时p为野指针
return 0;
}
这里我们让
p指向一个4字节的内存,并对其赋值,当我们将p释放,将其使用权还给操作系统后,继续使用p,p就成为了野指针,对野指针的使用会出现各种各样的问题,严重的话可能导致程序崩溃,因此,实际开发中,应该避免出现野指针。
(2)空指针
空指针是一种特殊的指针,它指向的是内存的0号地址,值为NULL(在C语言中,NULL本质是一个宏定义,值是0),将指针赋值为NULL的操作就是指针置空,当一个指针为空时,我们默认它没有指向任何变量的内存。
在指针初始化时,如果不能立即赋值那么可以将该指针置为空,或者在释放指针指向的内存后将指针置为空避免野指针的出现。C++更推荐使用nullptr来置空指针。
int main() {
int *p = NULL;
return 0;
}
c++则推荐使用nullptr,它提供了更好的类型安全性。
int main() {
// int* p = NULL;
int *p = nullptr;
return 0;
}
虽然说是推荐使用,但我觉得他都差不多,反正我是不用,因为懒打三个字符
5,指针的简单应用
接下来我们来举一个函数传参的经典例子来带各位更好的理解指针。
首先有以下代码,一个名为
change函数接收一个参数a,在函数中改变a的值。
void change(int a) {
a = 114514; //给a赋值114514
}
int main() {
int a = 5201314;
change(a); // 调用函数
cout << a << endl; // 5201314
return 0;
}
但是运行结果显示,虽然调用了
change函数,但是a的值并没有被改变,依旧是5201314。因为函数传参默认是值传递,change函数只是把主函数中的a的值拷贝到了自己的栈中,也就是说,change中的变量a只是主函数中变量a的一个副本。因此在change中给变量a赋值114514是不会影响主函数中的变量a的。讲人话就是:change函数里面的a和外面那个5201314的a不是一个a,change函数里边的那个是它的形参,只不过把他的形参赋值为了主函数里边面那个a,也就是说赋值114514那个a和外面那个a不是一个,所以输出的还是主函数定义的那个5201314
想要改变main中a的值,就需要使用使用指针
根据前面所说的内容我们知道指针存储的是内存地址,可以抽象(象:我犯什么事了?你天天拿皮鞭抽我呜呜呜)理解为指针指向的是变量的实际内存,可以通过解引用操作来获取所指向内存中存放的值。
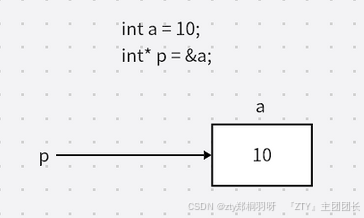
也就是说,可以把函数的参数改为指针,通过对指针解引用来改变实际内存中的值。代码如下:
void change(int* p) {
*p = 114514; //把指针解引用,直接改变内存中的值
}
int main() {
int a = 10;
int* p = &a;
change(p); // 调用函数,传入a的指针p
cout << a << endl; // 114514
return 0;
}
这里需要注意的是,在传入指针参数时依旧发生了拷贝,但是拷贝的是指针的值,也就是变量
a的地址,之后在解引用后修改值时,修改的便是实际指向的内存中的值,即实际a的值。
6,结构体与指针
关于结构体与指针要注意的是结构体指针的解引用。假设我们有如下结构体,并声明一个该结构体的指针:
struct Student {
int id;
char name[100];
double score;
};
int main() {
Student stu = {19, "test", 89.4};
Student* p = &stu;
return 0;
}
对于普通的结构体变量而言,要访问或修改结构体的成员变量可以通过.来实现,例如stu.id = 114514,但是指针就需要先解引用:
struct Student {
int id;
char name[100];
double score;
};
int main() {
Student stu = {19, "test", 89.4};
Student* p = &stu;
(*p).id = 114514;
cout << stu.id << endl; //114514
return 0;
}
但是(*p).id = 114514通过这样的方式来操作成员变量有点过于繁琐(可能对于某些人来说不是很繁琐,反正我懒)了,于是可以使用->来代替结构体指针访问成员变量:
struct Student {
int id;
char name[100];
double score;
};
int main() {
Student stu = {19, "test", 89.4};
Student* p = &stu;
// (*p).id = 114514;
p->id = 114514;
cout << stu.id << endl; // 114514
return 0;
}
相比*号解引用,这种方式则更加推荐,尤其是在面对链表一类的数据结构时,这种书写方式的优势尤为明显。(通过寄术来解决懒惰问题)
指针进阶
1,指针与数组
数组在C/C++中是一条连续的内存空间,存储着相同类型的多个数据。需要注意的是数组名,这里有一个误区,很多人认为数组名就是一个指针,然而这个说法并不正确。数组的数组名只是在一些情况下会被隐式转换成指向数组第一个元素的指针,因此大多数情况可以当作指针来进行使用,但数组名的本质并不是指针。但是为了方便读者理解,这里就暂时将数组名当作指针来看待。
什么你问为什么不继续?请你追更下一篇博客吧!
后记
作者:zty郑桐羽呀
联系方式:(不挂了,有事私信)
兄弟们给个赞呗
先 赞 后 看 养 成 习 惯