一、概述
在众多降维算法中,PCA(Principal Component Analysis,主成分分析)历史悠久,被广泛应用于各个领域。使用PCA可以将相关的多变量数据以主成分简洁地表现出来。
PCA是一种用于减少数据中的变量的算法。它对变量之间存在相关性的数据很有效,是一种具有代表性的降维算法。降维是指在保留数据特征的前提下,以少量的变量表示有许多变量的数据,这有助于降低多变量数据分析的复杂度。比如在分析有100个变量的数据时,与其直接分析数据,不如使用5个变量表示数据,这样可以使后续分析比较容易。减少数据变量的方法有两种:一种是只选择重要的变量,不使用其余变量;另一种是基于原来的变量构造新的变量。PCA使用的是后一种方法。也就是说,PCA可以使用低维变量表示高维空间中的数据。这个低维的轴叫作主成分,以原来
的变量的线性和的形式组成。
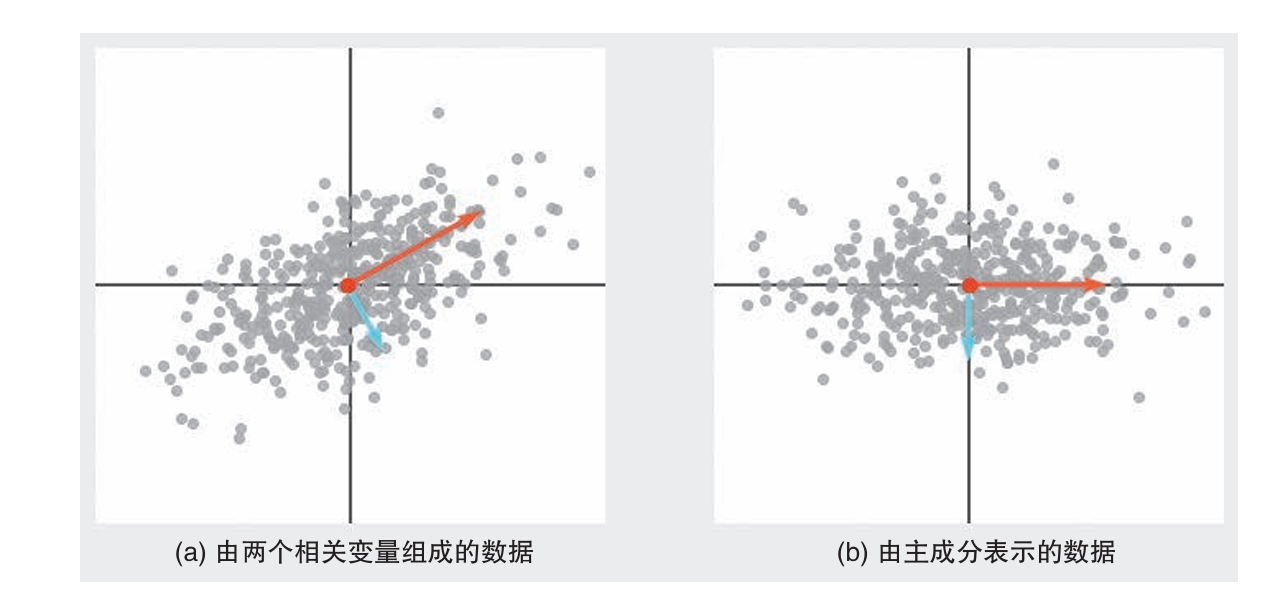
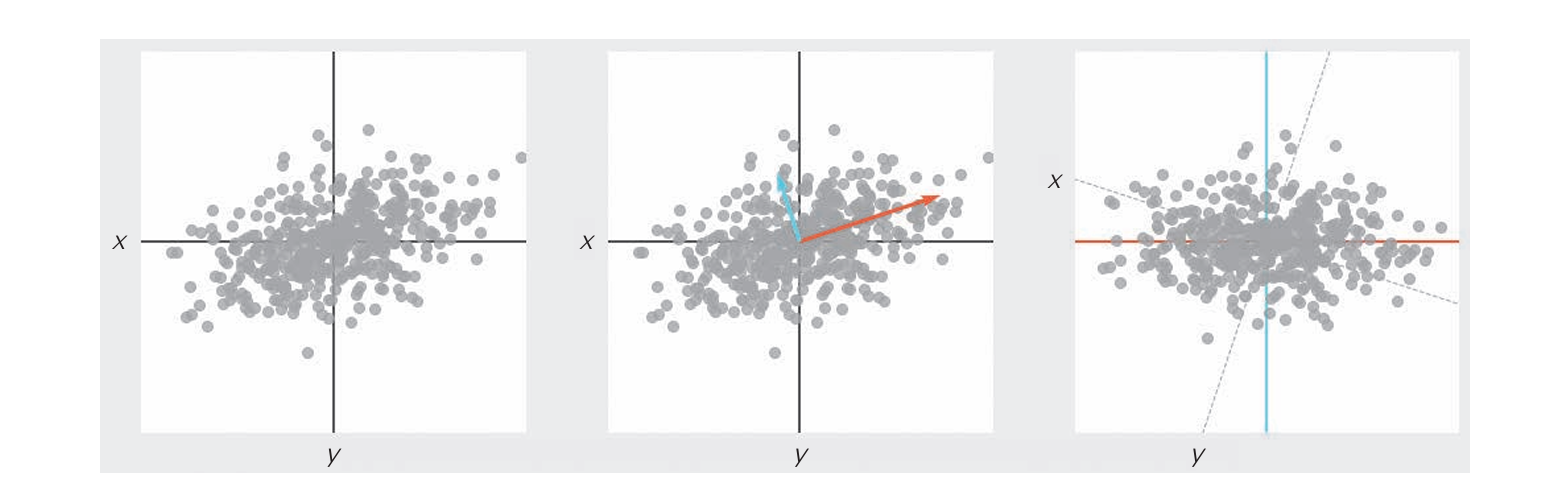
下面结合示意图来介绍PCA。PCA可发现对象数据的方向和重要度。对图a的散点图应用PCA,可以画出正交的两条线,线的方向表示数据的方向,长度表示重要度。方向由构成新变量时对象数据变量的权重决定,而重要度与变量的偏差有关。在每个数据点取相同值的变量并不重要,但是在每个数据点取不同值的变量能很好地体现数据整体的特点。
如图b是以这两条线为新轴对原始数据进行变换后得到的图形,变换后的数据称为主成分得分。按主成分轴的重要度的值从高到低排序,依次称它们为第一主成分、第二主成分。 从转换后的图来看,第一主成分方向的方差大,第二主成分方向的方差不大。通过PCA计算得到的第一主成分在方差最大的轴上,所以这个新的轴包含了更多的原始数据的特点。
最大化数据方差是PCA降维的核心思想,通过选择数据分布最分散的方向作为主成分,保留原始数据的主要信息
二、算法说明
PCA采用以下步骤来寻找主成分
1. 计算协方差矩阵。
2. 对协方差矩阵求解特征值问题,求出特征向量和特征值。
3. 以数据表示各主成分方向。
特征值问题是指对n维方形矩阵A,寻找使得Ax*x =λx的λ和x的问题。求解协方差矩阵的特征值问题在数学上等同于寻找使方差最大化的正交轴的问题。
让我们观察一下式Ax*x =λx。左边是一个矩阵和向量的乘积。举个具体的例子,将下面的向量x1、x2与矩阵A相乘。
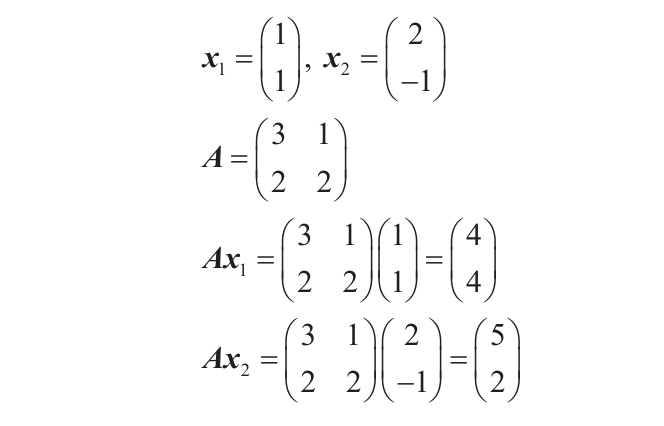
与矩阵相乘后,x1、x2分别变换为(4, 4)和(5, 2),如下图所示。像这个例子一样,矩阵可以变换向量的大小和方向,但有的向量并不能通过这种变换改变方向,这样的向量叫作A的特征向量。这时向量的大小在该变换下缩放的比例叫作特征值。
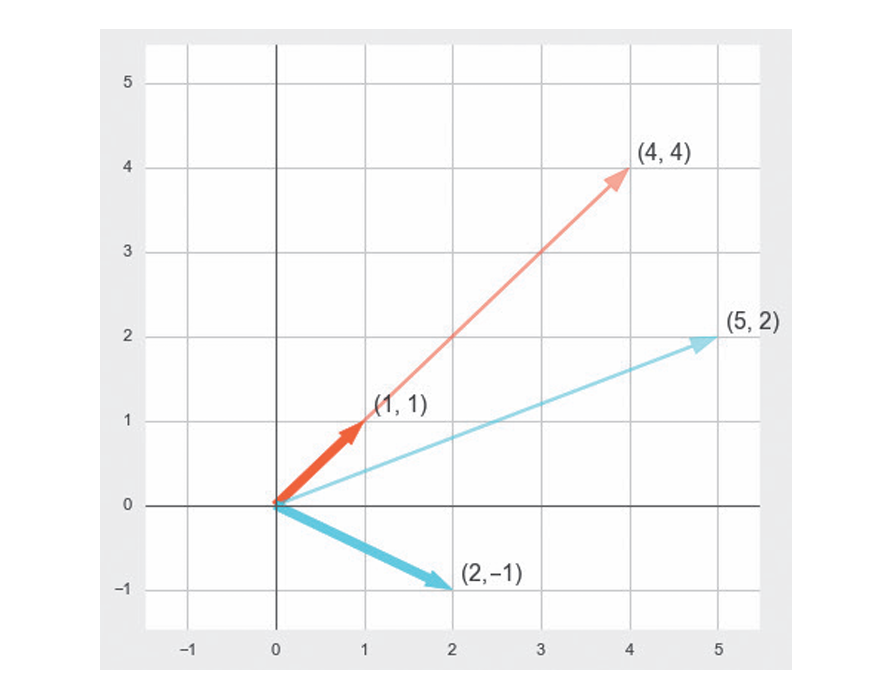
从图中看,以红线表示的变换后的向量(4, 4)与原向量在一条直线上。这就意味着乘以矩阵A的变换与乘以常数4的变换是一样的。在PCA中,矩阵A就是协方差矩阵。PCA对协方差矩阵求解特征值问题,并计算出特征值和特征向量的几种组合。这时按特征值大小排序的特征向量分别对应于第一主成分、第二主成分……照此类推。“概述”部分介绍的方向和重要度与特征值问题的特征向量和特征值相关。如果我们使用针对每个主成分计算出的特征值除以特征值的总和,就能够以百分比来表示主成分的重要度,这个比例叫作贡献率,它表示每个主成分对数据的解释能力。从第一主成分开始依次相加,得到的贡献率叫作累计贡献率。
三、示例代码
下面是对scikit-learn内置的鸢尾花数据使用PCA的示例代码,用于将4个特征变量变换为2 个主成分。
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
data = load_iris()
n_components = 2 # 将减少后的维度设置为2
model = PCA(n_components=n_components)
model = model.fit(data.data)
print(model.transform(data.data)) # 变换后的数据
四、详细说明
主成分的选择方法
PCA可以将原始数据中的变量表示为新的轴的主成分。这些主成分按照贡献率大小排序,分别为第一主成分、第二主成分……照此类推。这时通过计算累计贡献率,我们可以知道使用到第几个主成分为止可以包含原始数据多少比例的信息。
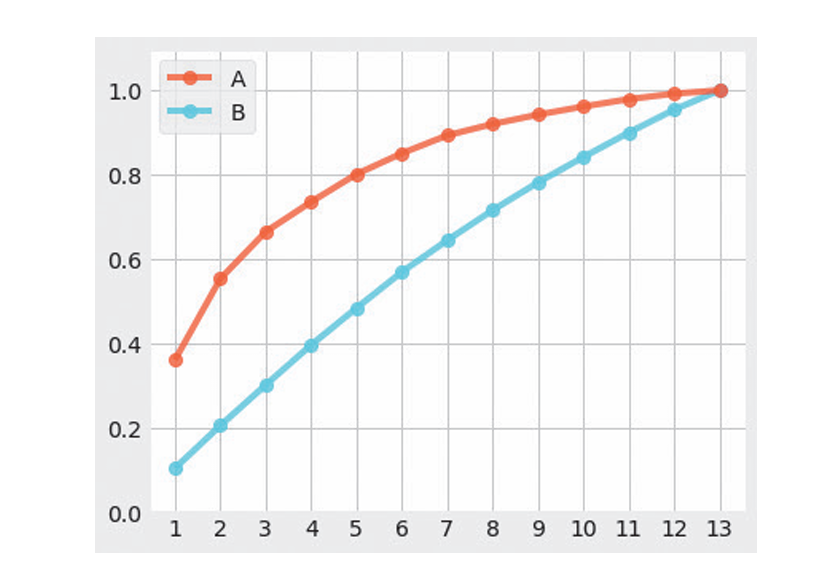
下图中的横轴为主成分,纵轴为累计贡献率,其中A为变量之间存在相关性的数据的PCA结果。这时的累计贡献率分别为0.36、0.55、0.67、0.74、0.80……当根据累计贡献率选取主成分时,我们可以像“累计贡献率在0.7以上→4个主成分”“ 累计贡献率在0.8以上→5个主成分”这样,根据基准值决定主成分的数量。而B是对变量之间没有相关性的数据进行PCA的结果,从图中可以看出,各个主成分的贡献率几乎相同。可以说这样的数据不适合用PCA进行降维,需要考虑其他方法。
主成分在各个数据集上的累计贡献率: