一、RagFlow简介
RagFlow是一个基于对文档深入理解的开源 RAG(检索增强生成)引擎。它的作用是可以让用户创建自有知识库,根据设定的参数对知识库中的文件进行切块处理,用户向大模型提问时,RAGFlow先查找自有知识库中的切块内容,接着把查找到的知识库数据输入到对话大模型中再生成答案输出。
它能凭借引用知识库中各种复杂格式的数据为后盾,为用户提供真实可信的答案。RAGFlow的技术原理涵盖了文档理解、检索增强、生成模型、注意力机制等,特别强调了深度文档理解技术,能够从复杂格式的非结构化数据中提取关键信息.
二、RagFlow本地部署(不使用docker)
部署需要的环境:
| 环境 | 版本号 |
|---|---|
| python | >=3.10 |
| pytorch | >=2.0 |
| mysql | =8.0 |
| elasticsearch | >=8.7.1 |
| ubtuntu | 22.4.0 |
1.MySQL安装
1.1更新软件包列表
sudo apt update
1.2安装 MySQL 服务器
# 查看可使用的安装包
sudo apt search mysql-server
# 安装指定版本8.0
sudo apt install -y mysql-server-8.0
1.3启动 MySQL 服务
#启动MySQL
sudo service mysql start
#设置开机自启动
sudo service mysql enable
#检查MySQL状态
sudo service mysql status
启动MySQL时若出现图片中最后一行的内容可以运行以下命令
sudo usermod -d /var/lib/mysql mysql

1.4设置密码和权限
# 登录mysql,在默认安装时如果没有让我们设置密码,则直接回车就能登录成功。
sudo mysql -uroot -p
# 设置密码 mysql8.0
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '新密码';
# 设置密码 mysql5.7
set password=password('新密码');
# 配置IP 5.7
grant all pri
1.5创建ragflow数据库
#创建数据库
create database rag_flow;
#查看数据库是否创建成功
show databases;
下面的可以不执行
注意:配置8.0版本参考:我这里通过这种方式没有实现所有IP都能访问;我是通过直接修改配置文件才实现的,MySQL8.0版本把配置文件 my.cnf 拆分成mysql.cnf 和mysqld.cnf,我们需要修改的是mysqld.cnf文件:
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
修改 bind-address,保存后重启MySQL即可。
bind-address= 0.0.0.0
重启MySQL重新加载一下配置:
sudo systemctl restart mysql
2.安装elasticsearch
2.1安装前的准备
#创建文件夹
mkdir elastic
#创建普通用户
useradd elastic
#设置用户密码
passwd elastic
#将文件指定给elastic用户
chown -R elastic /elastic
2.2安装
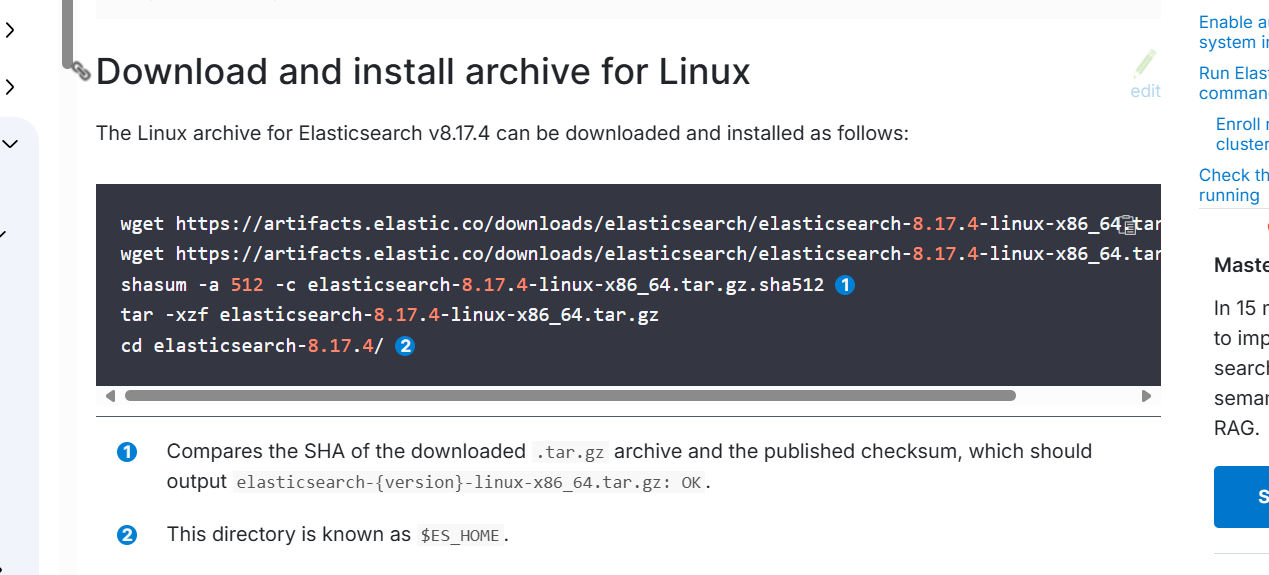
进入网址Install Elasticsearch from archive on Linux or MacOS | Elasticsearch Guide [8.17] | Elastic,根据图片中的内容安装elasticsearch
2.3启动elasticsearch
#进入bin目录
cd /elastic/elasticsearch-8.7.1/bin
#进入普通用户
su elastic
#启动elasticsearch
./elasticsearch
注意初次启动过程中可能会出现没有权限的错误,只需要给具体的文件夹权限即可
注意不要随便修改配置文件
启动成功之后再浏览器输入下面的网址并出现于图片内容相似的结果即为成功
网址:http://localhost:9200
结果:
3.安装redis
3.1更新软件列表
sudo apt update
sudo apt upgrade
3.2使用 apt 安装 Redis
sudo apt install redis-server
3.3启动redis
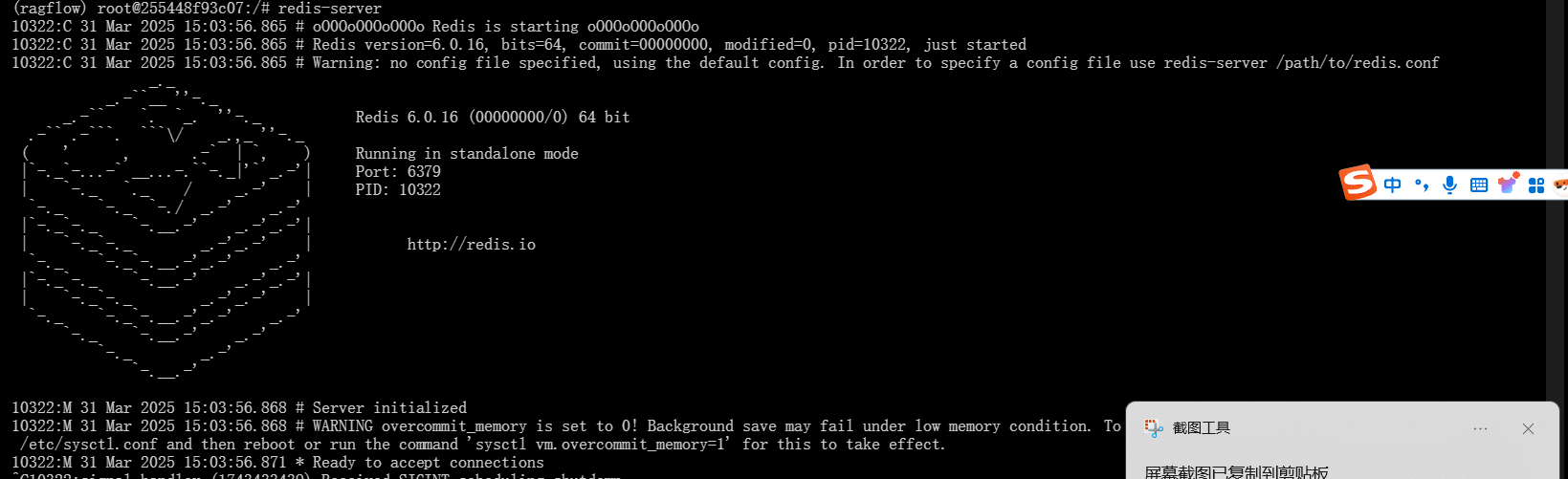
redis-server
出现下面的内容即为启动成功
3.4测试 Redis 是否正常工作
redis-cli --version
4.ragflow部署
4.1创建虚拟环境
#创建虚拟环境
conda create -n ragflow python==3.12
#激活虚拟环境
conda activate ragflow
#更换匹配下载源
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple
4.2安装pytorch
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu124
4.3克隆ragflow仓库
#github
git clone https://github.com/infiniflow/ragflow.git
4.4下载相应的依赖
由于不使用docker启动且官方文档没有requirements.txt文件不能批量下载,本人已经制作了文档,可在下方的网盘中免费下载
「requirements (1).txt」来自UC网盘分享
https://drive.uc.cn/s/4ed9293e7cbe4?public=1
pip install -r requirements.txt
4.5启动ragflow-server(后端)
注意在启动ragflow-server时要先启动MySQL,elasticsearch,redis
修改配置文件
#用vim修改配置文件
vim /ragflow/conf/service_conf.yaml
根据自己的信息修改框中的内容

运行/ragflow/api/ragflow_server.py时最好将其复制到/ragflow下,因为有极大概率会报错
#进入ragflow
cd /ragflow
#将/ragflow/api/ragflow_server.py复制到ragflow中
cp -r /ragflow/api/ragflow_server.py /ragflow
#运行ragflow_server.py
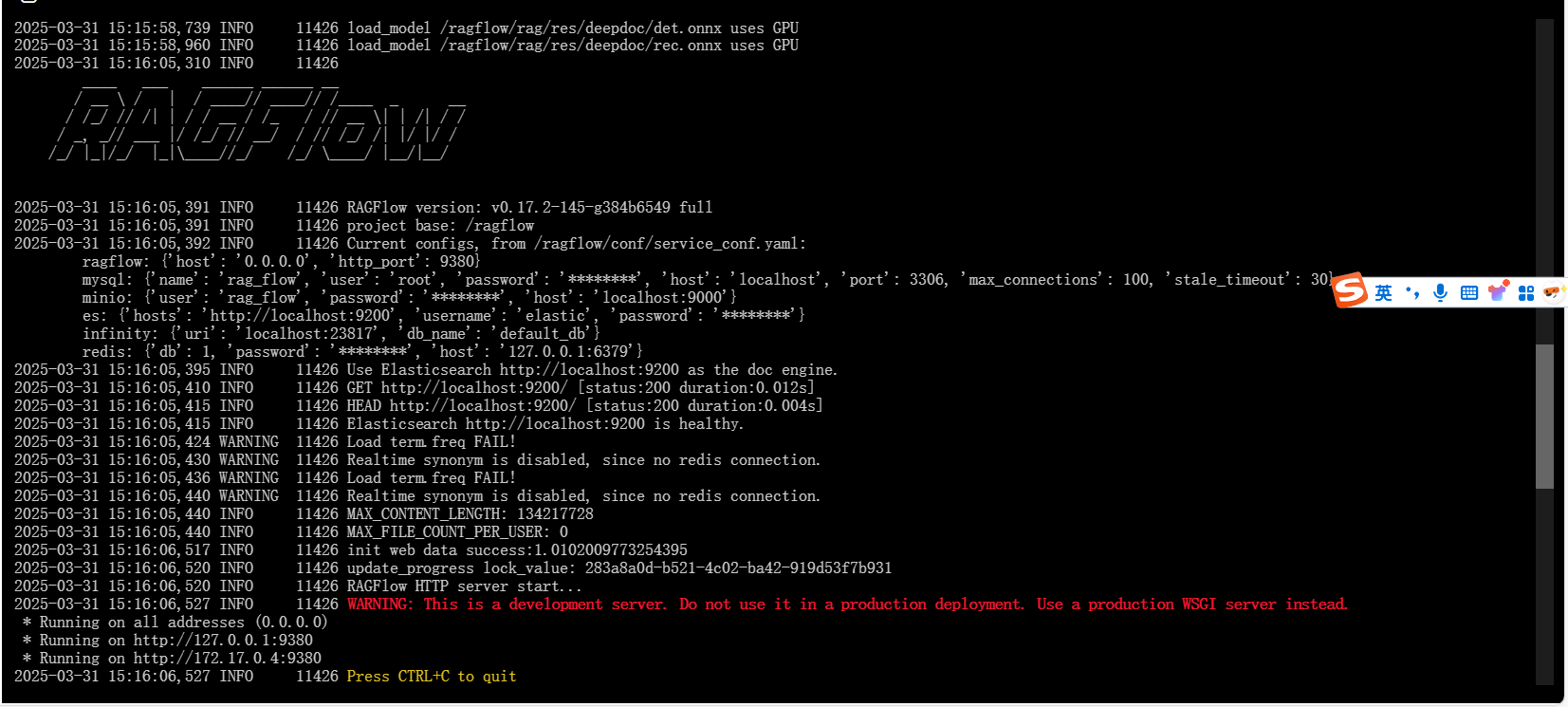
python ragflow_server.py
**成功启动结果如图
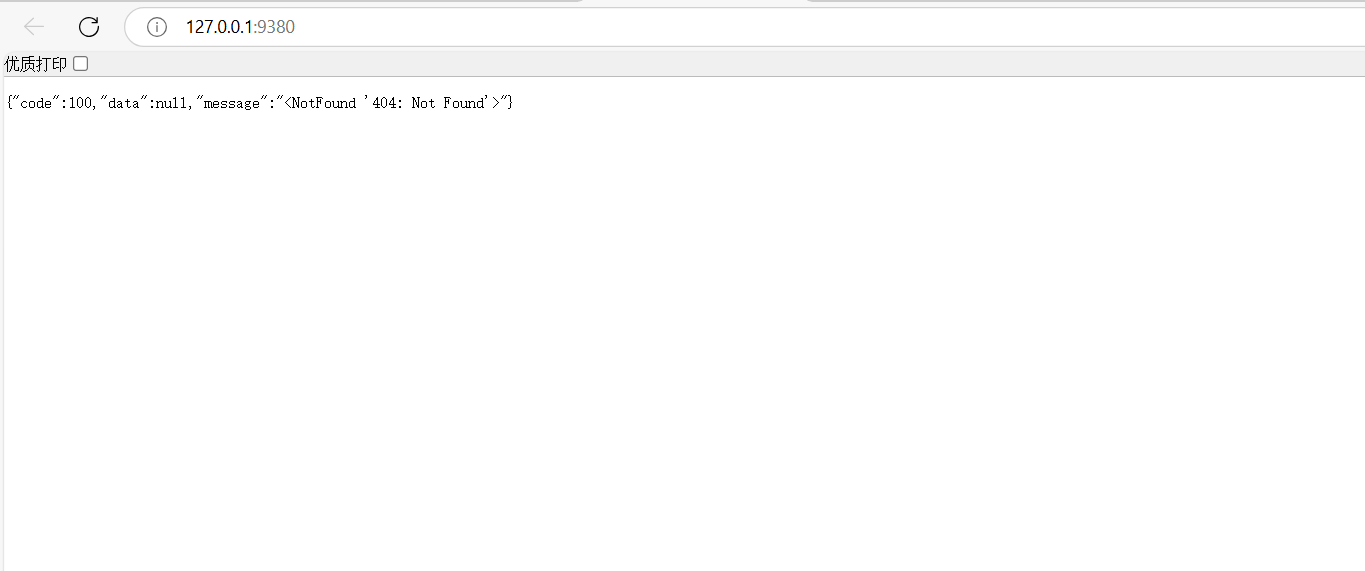
**
注意下面为本人运行过程中所出现的错误,希望对你有所帮助
1.在用批量安装依赖后需要再安装infinity-sdk,因为批量下载时会冲突所以需要单独安装
pip install infinity-sdk==0.6.0.dev3
2.若出现下面的图片中的错误可以进入下面的网址中下载相应的包,并放进相应的位置
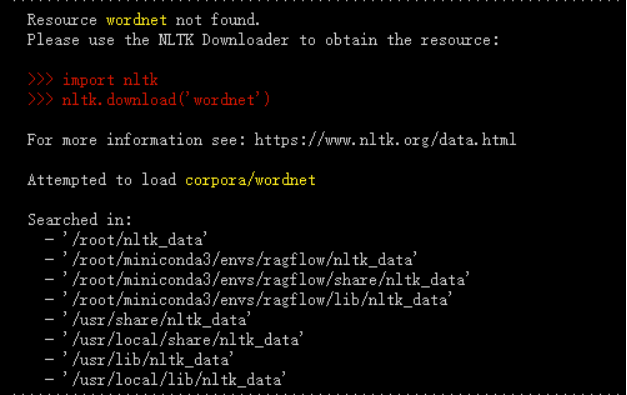
https://github.com/nltk/nltk_data/blob/gh-pages/packages
/root/nltk_data/tokenizers/
/root/nltk_data/corpora/
3.#出现此错误
![]()
将/root/miniconda3/envs/ragflow/lib/python3.12/site-packages/azure/storage/filedatalake/文件夹下的_models.py中的18行修改为如图所示

4.#出现图片中的错误,运行下面的命令
pip install google-search-results
![]()
5.#若出现下面图片中的错误,可运行下面的命令
sudo apt update && sudo apt install -y unixodbc unixodbc-dev
![]()
5.ragflow的web启动(源启动)
5.1nodejs的安装
#更新软件包的索引
sudo apt update
#运行将为 Node.js 20 包配置 APT 存储库的脚本。
curl -fsSL https://deb.nodesource.com/setup_20.x | sudo -E bash -
#运行run后面的命令
apt-get install nsolid -y
#验证安装是否成功
node -v
npm -v

安装成功的样式
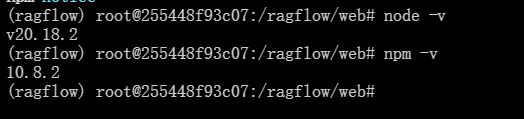
5.2启动web
#进入web文件
cd /ragflow/web
#安装前端依赖项
npm install
#启动前端服务
npm run dev
成功启动的截图
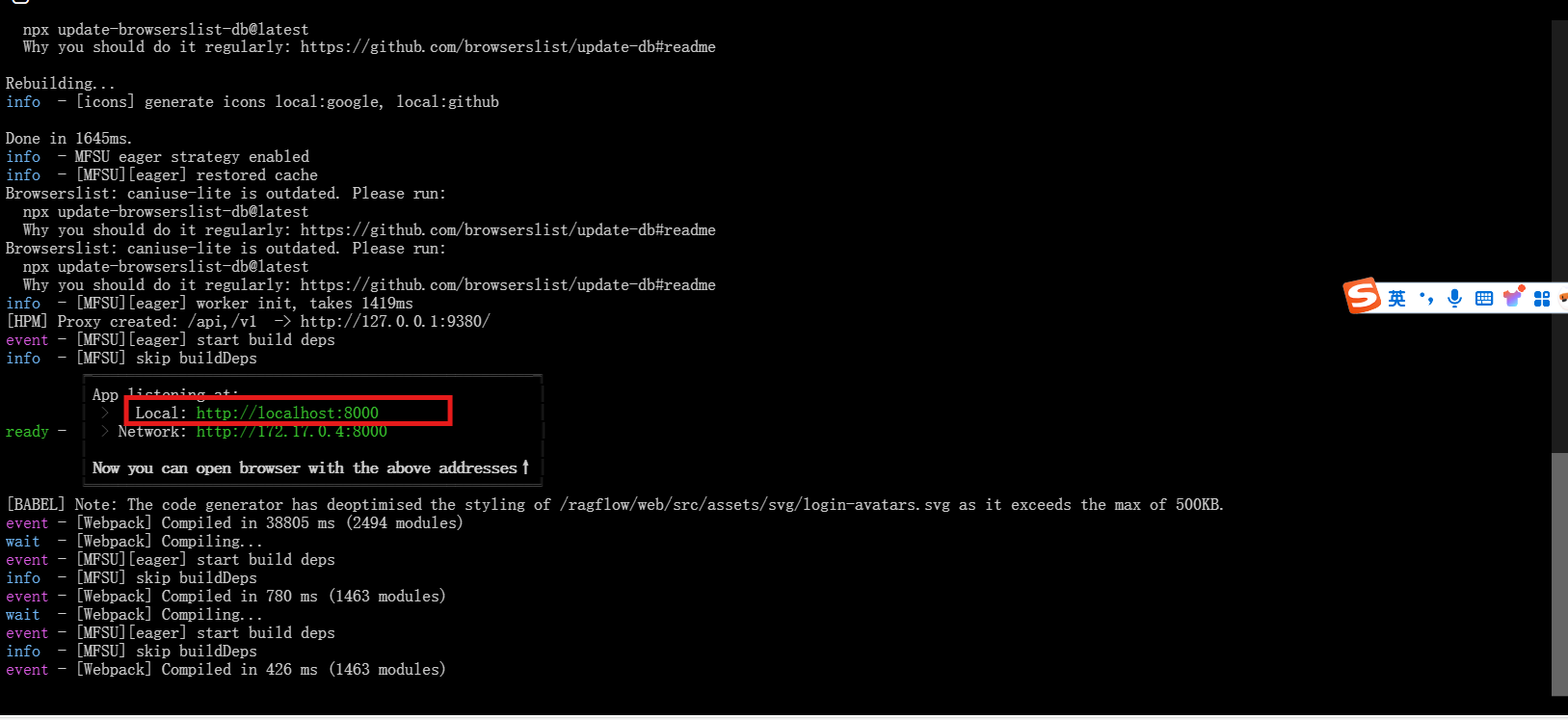
点击红框中的网址即可进入web端(由于网络原因可能进入网页的速度较慢)如图