3月6日凌晨,阿里通义千问团队投下一颗技术炸弹——开源推理模型 QwQ-32B 横空出世。
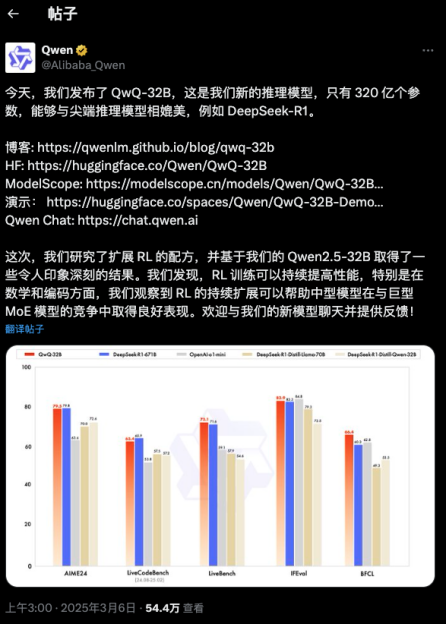
QwQ-32B 有多厉害呢?这款仅有320亿参数的模型,在数学、代码、通用能力等核心场景里,已经几乎跟满血版DeepSeek-R1(6710亿参数)不相上下了。
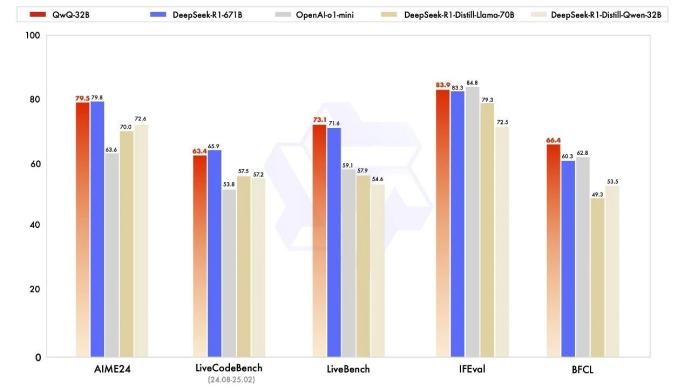
更令人惊叹的是通用场景测试——在包含工具调用、多轮对话的 IFEval 评测中,QwQ-32B 综合得分竟比 DeepSeek-R1 高出15%。
这一突破颠覆了“参数规模决定性能上限”的传统认知,更以“消费级硬件可部署”的极致性价比,为AI行业开辟了一条“小模型撬动大价值”的全新路径。
320亿参数的技术革命——阿里精妙的训练策略
QwQ-32B 的惊人表现,核心在于其创新的两阶段强化学习框架。
第一阶段,研发团队摒弃传统奖励模型的模糊评价体系,直接对数学推导、代码执行等任务进行答案正确性验证——比如让模型生成的代码实际运行并比对结果,如同给学生布置完作业后当场批改。
这种“真刀真枪”的训练方式,使得模型在专业领域迅速形成类人思维习惯,例如精准计算复杂调休日期、秒解LeetCode困难级算法题。进入第二阶段后,模型又在保持专业优势的基础上,通过规则验证器和通用奖励模型拓展综合能力,最终实现“专精特新”与“博采众长”的完美平衡。
当行业还在比拼千亿参数集群时,阿里用320亿参数完成了对巨头的弯道超车。
在硬件配置方面,QwQ-32B 仅需4张消费级 RTX 4090 即可流畅运行,部署成本骤降至十分之一。
这种“平民化”特性配合 Apache 2.0 开源协议,意味着中小企业甚至个人开发者都能在本地环境构建私有化 AI 服务——无论是金融风控系统的实时决策,还是智能工厂的产线优化,QwEN-32B都能以极低门槛输出专业级推理能力。阿里同步开放的 Hugging Face、ModelScope 平台支持,更让开发者无需重复造轮子,一键下载即可融入现有技术生态。
“以小博大”的技术起义,正在重塑AI竞争格局
QwQ-32B 的诞生不仅是算法的胜利,更标志着行业从“暴力堆参数”向“智能密度提升”的战略转向。
对于开源社区而言,它证明了中等规模模型完全可以通过训练策略优化比肩顶级闭源产品,极大提振了独立开发者的信心;对企业用户来说,这款兼具高性能与高安全性的模型,将成为金融、医疗、政务等敏感场景的破局利器。
而阿里三年3800亿重注AI基建的战略,也通过这次开源释放出明确信号:未来的AI竞赛,不再是资源垄断者的独角戏,而是技术巧思与生态开放的协同进化。
阿里这波开源,正如网友说的那样:“等于给每个程序员配了个年薪百万的AI工程师!”
大家有什么看法呢?欢迎在评论区留言讨论~