StoryDiffusion 是由南开大学与字节跳动的联合研究小组共同研发的一项突破性的图像与视频合成技术。它通过融合先进的自我注意力机制与语义运动预测技术,实现了在文本驱动下生成具有一致主题的图像和视频,为视觉叙事开辟了新的纪元。

其核心创新在于一致性自注意力机制与语义运动预测器(的双技术融合:
-
一致性自注意力:通过将多个文本提示(至少3个)批量输入模型,建立跨图像的关联性,确保角色外观、服饰等特征在长序列中稳定不变。例如,生成漫画时,角色在不同场景中的发型、服装细节可保持统一。
-
语义运动预测器:将图像编码至语义空间,预测动作轨迹,实现平滑的视频过渡。例如,从“角色奔跑”到“跳跃”的动态过程,无需逐帧调整即可生成连贯动画514。该技术兼容 SD1.5 和 SDXL 模型框架,支持热插拔,开发者可灵活适配现有工具链。
接下来就为大家奉上详细的 StoryDiffusion 本地部署教程,手把手教你如何将模型部署到你的项目中,轻松享受高性能AI带来的便利。

本地部署
基础环境最低要求说明:
(在部署完成进行对话时一张卡回答得很慢,建议使用两张)
| 环境名称 |
版本信息 1 |
| Ubuntu |
22.04 LTS |
| Cuda |
V11.8 |
| Python |
3.12 |
| NVIDIA Corporation |
RTX 4090 |
(1)基础环境
查看系统是否有 Miniconda3 的虚拟环境
conda -V如果输入命令没有显示Conda版本号,则需要安装。

(2)更新系统命令
输入下列命令将系统更新及系统下载
apt-get update && apt-get install ffmpeg libsm6 libxext6 -y
(3)创建虚拟环境
创建名称为“StoryDiffusion”的虚拟环境并激活
conda create --name storydiffusion python=3.12 -y
conda activate storydiffusion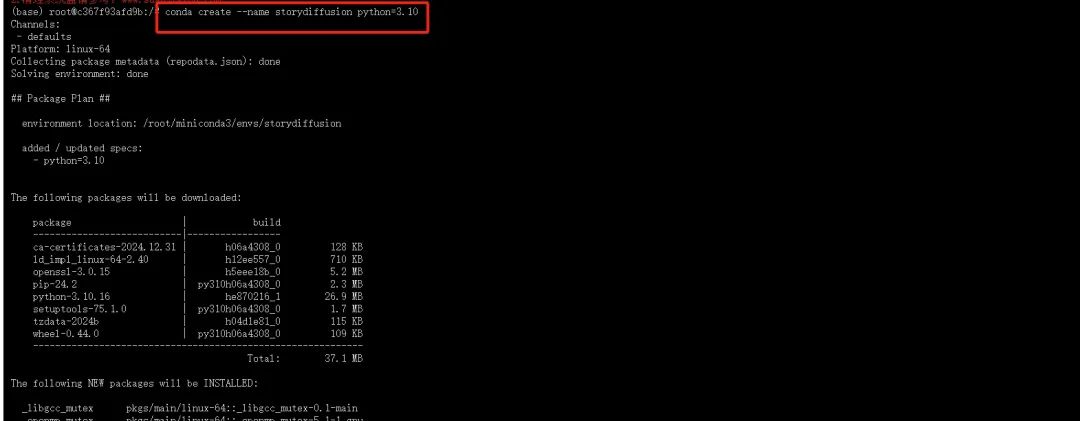

(4)下载模型
输入下列命令下载StoryDiffusion模型同时进入项目中
git clone https://gitclone.com/github.com/FudanDISC/DISC-LawLLM.git
cd StoryDiffusion
输入下列命令:
pip install -r requirements.txt建议使用这行命令,提升下载速度:
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple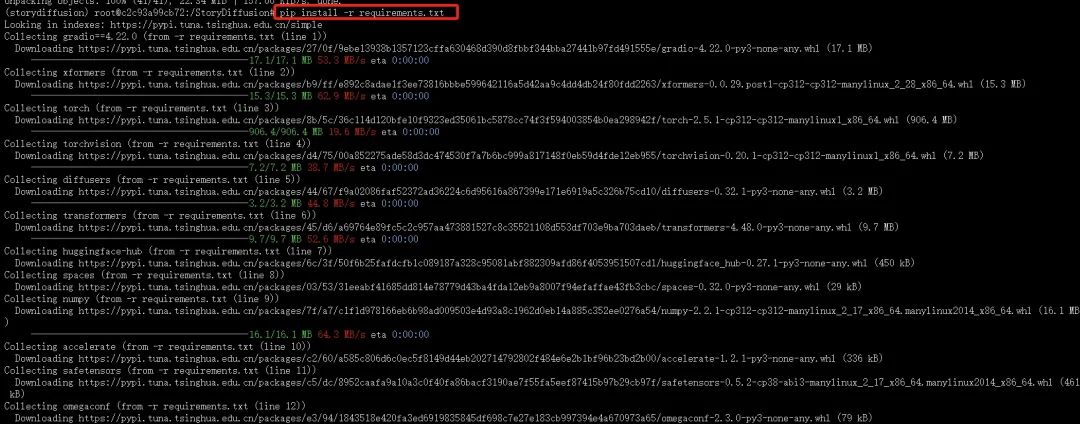
直到“Successfully”出现,下载才结束:
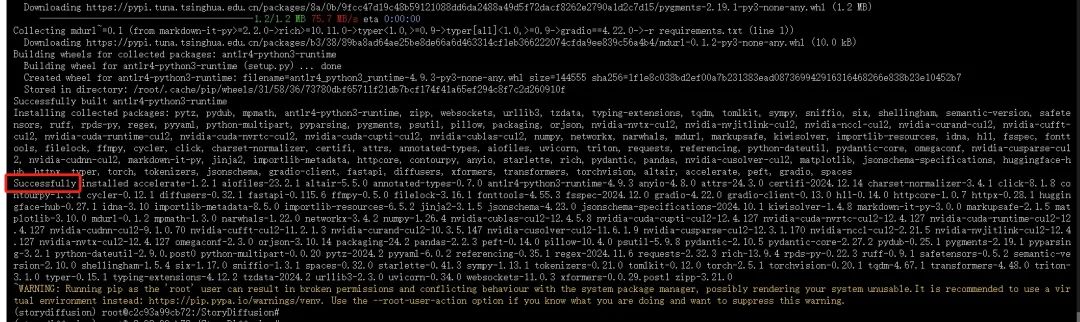
(5)网页演示
在本地运行graio应用程序,使用下列命令运行项目呈现模型的成功界面
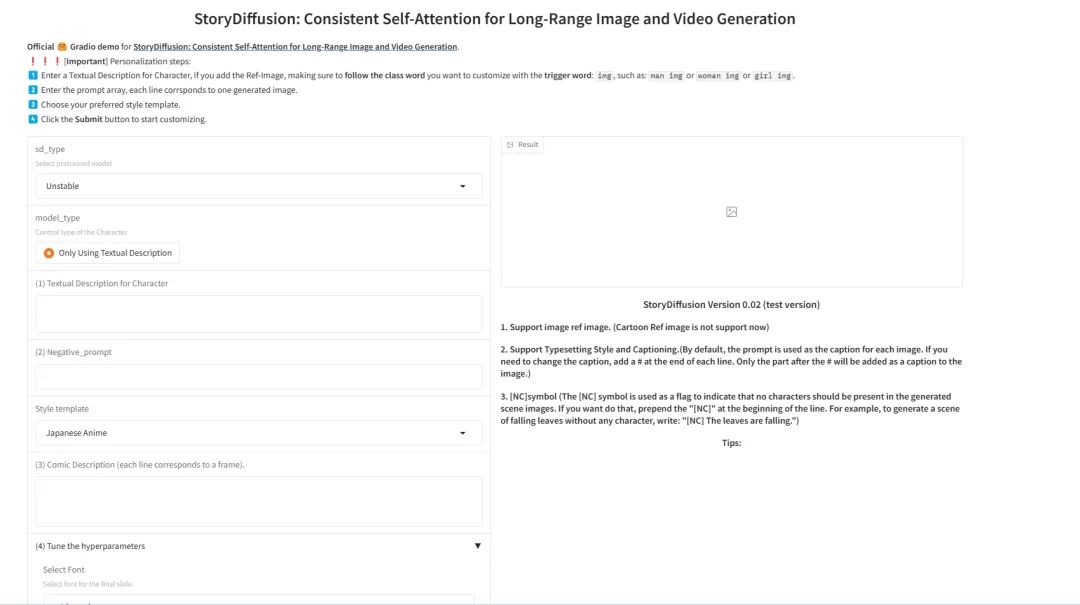
以上就是 StoryDiffusion 的两种使用教程。希望能够帮助到大家,欢迎在评论区交流提问哦~