鸣人:我已成影,待你成 "王"

Hello,大家好,这篇博客我们就来为大家讲解一下C++中STL中的vector类,这个vector类听起来感觉很陌生,但是如果我给它换一个名字,叫顺序表,大家是不是就不陌生了,对的,它虽然说是叫vector类,但是它的底层实际上实现的就是顺序表。
温馨提示:如果大家还没有接触过顺序表的话,大家可以去看一下我前面写的那个关于顺序表的博客,大家可以先去学习一下,再来看我们的这个vector相关的知识。链接如下:
目录
2.1.1.1 explicit vector (const allocator_type& alloc = allocator_type())函数
2.1.1.2 vector(size_type n, const allocator_type& alloc = allocator_type())函数
2.1.1.4 vector (const vector& x)函数
2.3.1.1 iterator insert (iterator position, const value_type& val)函数
2.3.2.1 iterator erase (iterator position)函数
2.3.2.2 iterator erase (iterator first, iterator last)函数
2.4 vector不支持operator<<和operator>>重载
4.vector的底层实现以及在使用过程中容易出现的各种注意事项
4.2 void reserve(szie_type n);函数的模拟实现
4.3 void print();(这个函数并不是库中的函数,是我们自己实现的打印函数)
前情提要
STL简介:STL是C++标准库的重要组成部分,不仅仅是一个可重用的组件库,而且还是一个包罗数据结构与算法的软件框架,简单来说,它主要就是一个数据结构与算法的库。因此,我们这里的这个讲解vector类也就是说是去相应的库中去学习相关的成员函数以及它其中的成员变量,总而言之,学习STL主要就是学习相关的库,既然如此,我在这里为大家推荐一个英语的相关网站,希望对大家在学习STL时能够有所帮助。
C/C++相关函数查询官网:Reference - C++ Reference
1 简单介绍

vector这个类就是属于STL的一部分,vector在这里是一个类类型的模板,简单来说,vector就是我们之前所学过的顺序表这个数据结构。
2 vector的使用:
2.1 Member functions(基本功能)
2.1.1 Constructer(构造函数)
(构造函数的重载有很多,我们在这里只介绍几个比较重要的函数接口)
2.1.1.1 explicit vector (const allocator_type& alloc = allocator_type())函数
explicit vector (const allocator_type& alloc = allocator_type());//默认构造函数,并且初始化为元素类型的默认构造。这个函数是无参构造函数,也就是我们平时所说的默认构造函数(不需要传参的构造函数),这里初始化为元素类型的默认构造。
2.1.1.2 vector(size_type n, const allocator_type& alloc = allocator_type())函数
vector (size_type n, const allocator_type& alloc = allocator_type());这个函数的作用是用n个alloc值去进行构造函数初始化操作,这个函数的第二个参数是初始化的那个值,我们的这个vector是一个模板,我们这个vector类模板中所存放的元素不一定是内置类型,还有可能是自定义类型,比如说string类型,就是vector的每一个空间存放的元素都是string类型的对象,因此我们这里使用一个缺省值,而这个缺省值就是这个vector类型中所存放的元素的默认构造对象,如果我们不传初始化的值的话,那么我们这里就会使用当前元素类型的默认构造去进行初始化操作(如果我们vector中存放的元素是string类型的话,我们若用这个构造函数进行初始化操作的话,如果我们只传一个参数的话,那么编译器这里在进行创建vector类型的对象的时候,会用n个string类的默认构造函数所产生的对象去进行初始化操作)。
说到这里的话,我们可能就会有的小伙伴会问到那如果vector类类型中的对象存放的是int类型的元素,也可以使用这个构造函数进行初始化操作吗?其实是可以的,C++中内置类型其实也是有默认构造函数的,这个我们先在这里了解一下,后续我们会细细地进行讲解的。
2.1.1.3 vector (InputIterator first, InputIterator last,const allocator_type& alloc = allocator_type())函数
template <class InputIterator>
vector (InputIterator first, InputIterator last,const allocator_type&alloc=allocator_type());这个函数的作用是用迭代器区间去进行构造初始化操作(迭代器的使用和我们前一篇博客中的迭代器的使用是相同的)。(我们这里先暂时只了解这个函数的用法,暂时先不要去了解这个构造函数地最后一个参数了)
2.1.1.4 vector (const vector& x)函数
vector (const vector& x);这个函数就是拷贝构造函数,也就是用一个vector类型的对象给另一个vector类型的类初始化(注意:在调用这个函数进行初始化操作时,要注意两个vector模板中存放的元素类型一定要相同才可以,否则,无法完成我们这里想要的操作)。
#include<iostream>
#include<vector>
#include<list>
using namespace std;
int main()
{
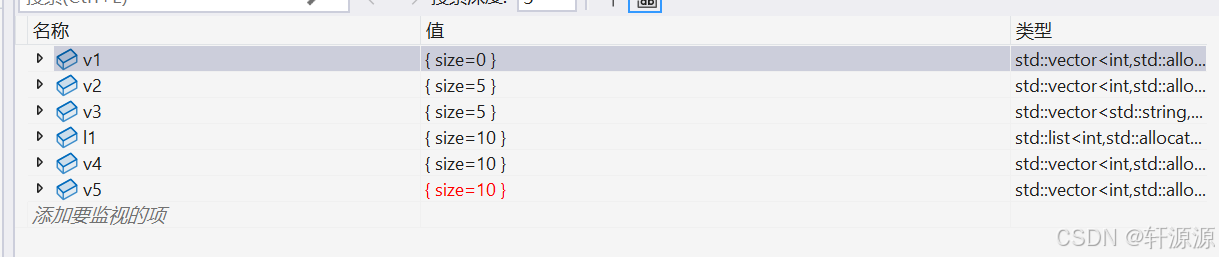
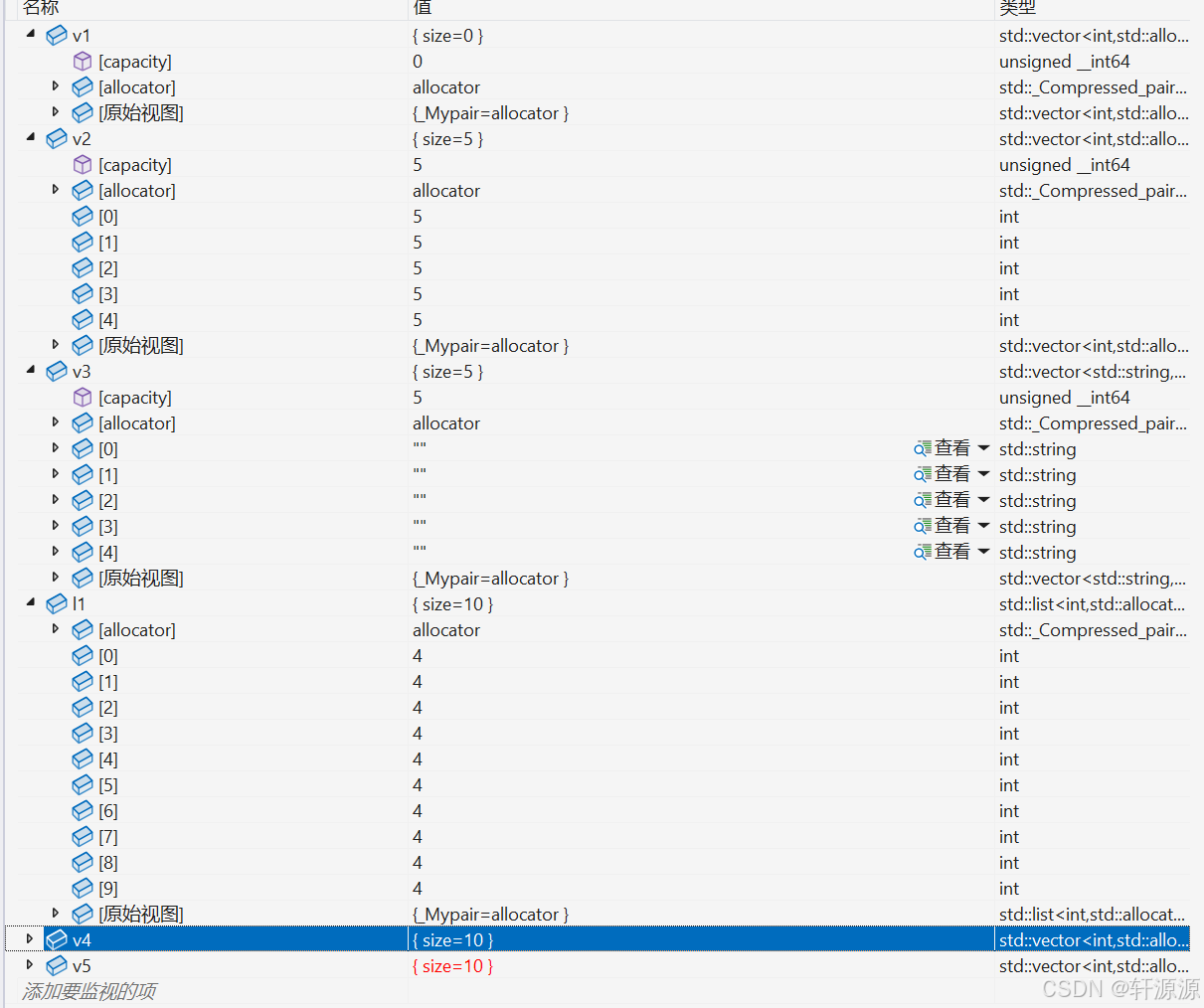
//由于vector在这里是不支持<<操作符的,因此,我们这里就无法将vector类类型的对象打印出来看了,所以我们在这里将其用图片的形式来呈现出来给大家看。
vector<int> v1;//默认构造,默认初始化为0(int类型默认初始化的时候是默认初始化为0的)。
vector<int> v2(5, 5);//用5个5来进行初始化操作。
vector<string> v3(5);//这个我们依旧调用的是2.1.2中的那个默认构造函数,只不过不同的是我们的参数个数不同,上面那个是用5这个元素进行默认构造,而我们这个没有指定那个元素进行默认构造,因此,这个是使用缺省值去进行构造的,而我们这个v3中存放的元素的类型是string类,所以存放到v3中的元素是string类的默认构造的对象。
list<int> l1(10, 4);//这个是list类模板,大家现在可能还不太了解,这个我们在下一篇博客上会讲解,所以我们这里先回用就可以了,我们现在只需要知道这也是一个和vector类似的容器就看可以了。
list<int>::iterator it1 = l1.begin();
list<int>::iterator it2 = l1.end();
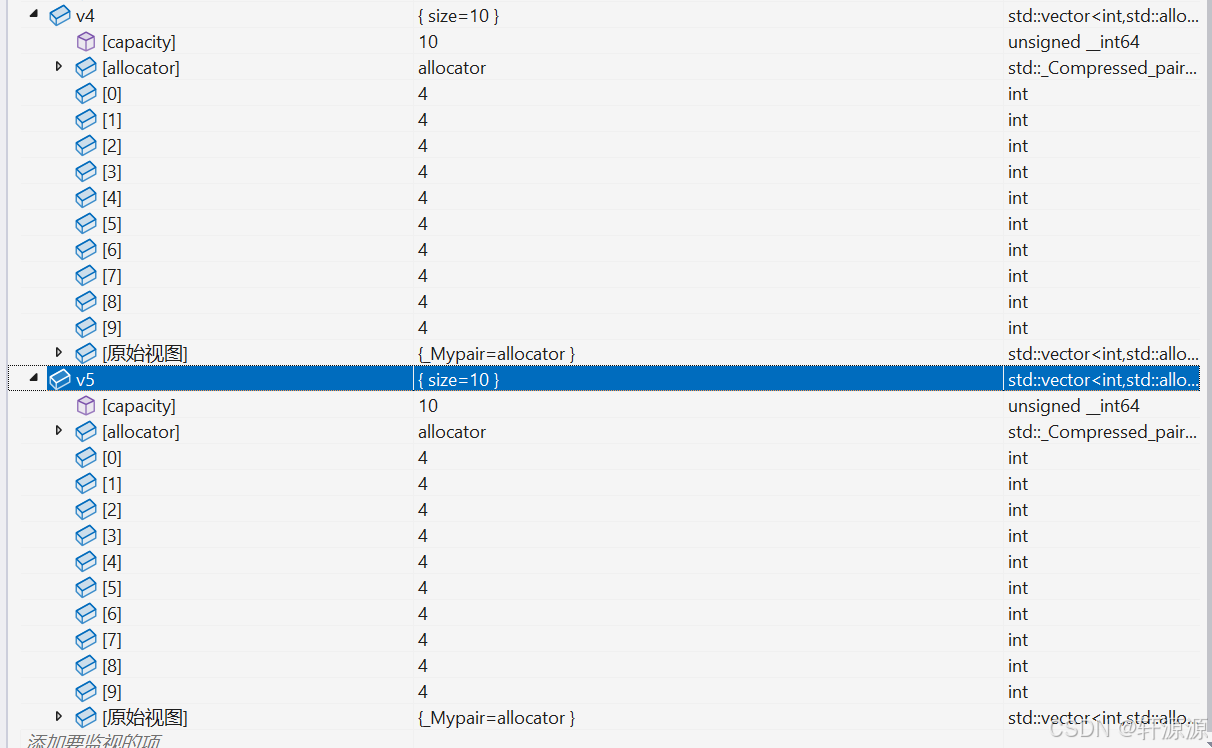
vector<int> v4(it1, it2);//用[it1,it2)这个迭代器区间的数值去对v4进行初始化操作。
vector<int> v5(v4);//拷贝构造函数。
return 0;
}
2.1.2 destructor(析构函数)

编译器在程序结束的时候会自动去调用析构函数,因此这里不需要我们去了解。
2.1.3 operator=(赋值重载函数)

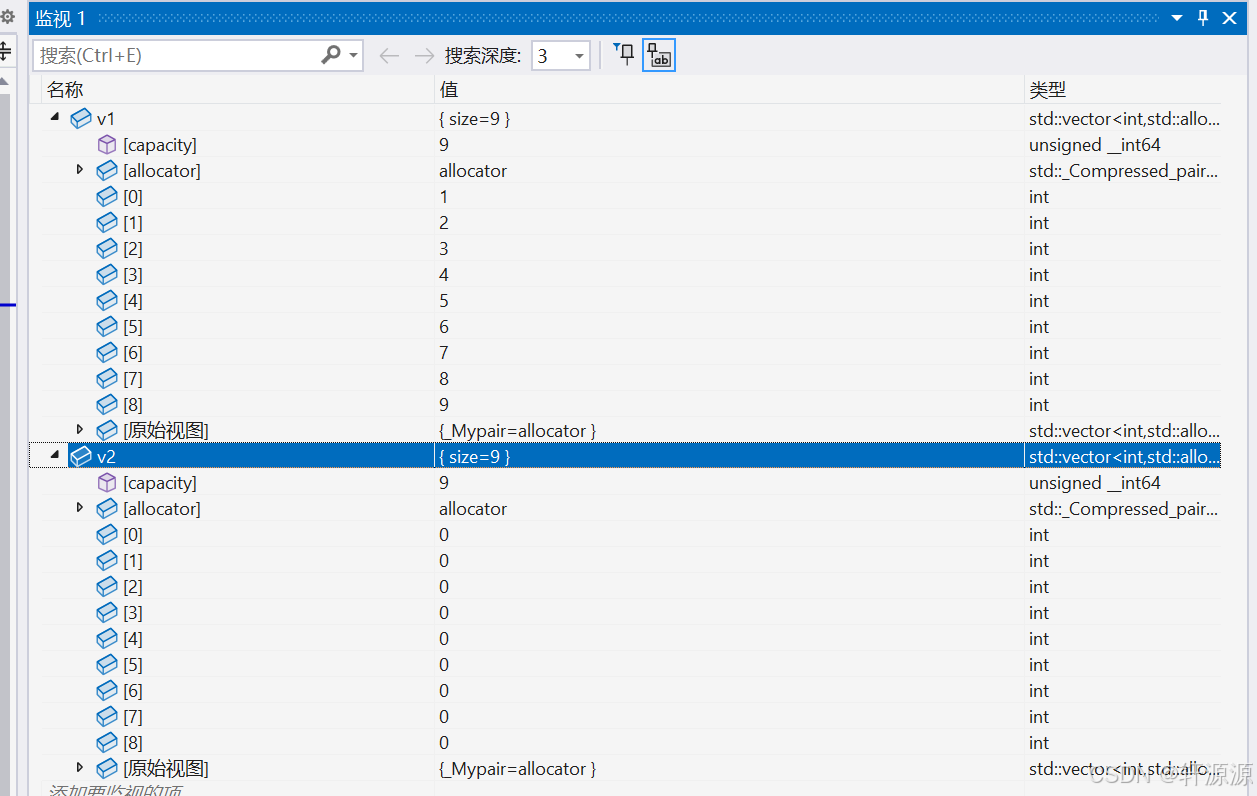
将一个vector类类型的对象中所存储的元素赋值给另外一个已经存在的vector类类型的对象。
2.2 Capacity(空间容量)
(我们这里只讲几个比较重要的函数接口,其余我们没有讲的接口的作用和我们前一篇中所讲的相同的接口的作用基本是相同的,所以我们除了我下面所讲的这几个函数接口以外的接口,大家如果有哪个函数接口不会的话,可以参照我们前一篇所讲的那个函数接口。)
2.2.1 reserve()函数接口

这个函数的作用就是开创n个空间,而这里之所以要写一个这个函数,是因为我们在后面难免会多次开创空间,这样的话会使得编译器的效率会得到下降,为了避免这种情况,如果我们能够提前知道最终的空间的大小的话,我们是不是就可以提前一步开创好足够的空间,避免效率下降这个问题,鉴于此处,所以才有了这个函数接口。
2.2.2 resize()函数接口

这个函数的功能就是将数据个数给扩大到n个,并进行初始化操作,多出的空间用val进行初始化操作。
OK,我们根据reserve函数的功能,这里有3种情况需要我们去进行分析:假如说,我有一个vector类类型的对象的空间(capacity)有20个空间,这20个空间中只有10个元素,v1对象中的内容如下图所示:

2.2.2.1 n=5
当n=5时,也就是将数据的个数从10个缩小为5个,这种情况n<size,此时数据只会保留前n个,这里指的是保留前5个元素,删除其余的数据,这种情况下是不会进行缩容操作的,也就是说它的容量是不会变的。
2.2.2.2 n=15
当n=15时,也就是说是将数据的个数从10个增加到15个,这种情况下n>size&&n<capacity,系统是不会进行扩容操作的,它会往后再数5个空间,对这5个空间均进行初始化操作,用val对其进行初始化(如果我们不传val的话,系统就会自动用无参构造函数构造一个对象对这5个空间进行初始化操作)
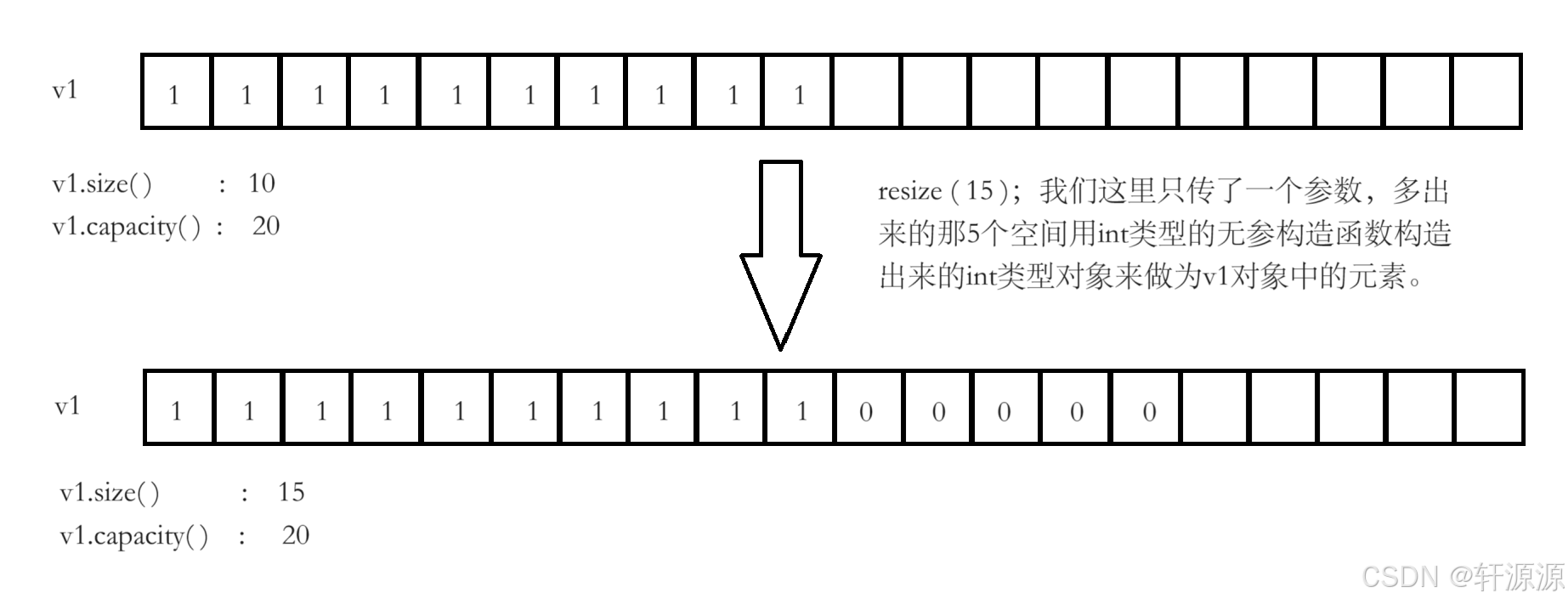
(我们这里可以把int类型当成是一个类,他也是有默认构造函数的,它默认初始化为0,我们后面会讲到,大家先不要着急)
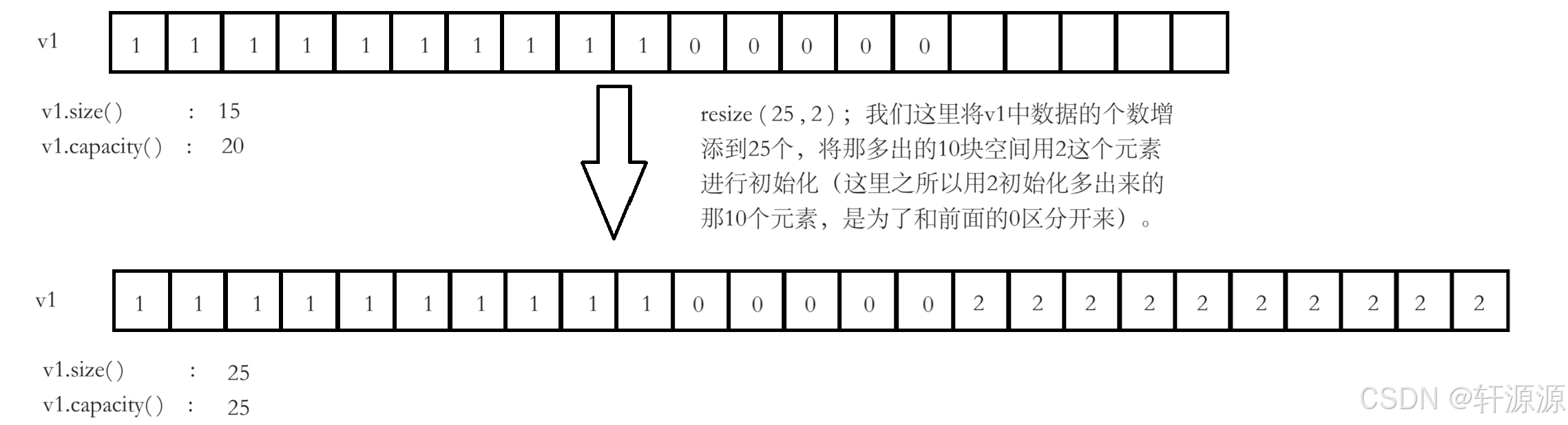
2.2.2.3 n=25
当n=25时,也就是将数据的个数从15个增长到25个(这里我们紧接着上面n=15那种情况),这种情况下n>capacity,空间不够的话,系统就会自动进行扩容操作去开创空间,将v1对象中的空间最少开到25个,对于这多出的10个数据同样用val进行初始化。
#include<iostream>
#include<vector>
using namespace std;
int main()
{
vector<int> v1({ 1,2,3,4,5,6,7,8,9 });
cout << v1.capacity() << endl;//9;输出v1对象的空间大小。
v1.resize(15, 10);//将v1中的元素数量扩大到15个,并将多出的6个空间均赋初始值为10。
cout << v1.capacity() << endl;//15;
for (auto ch : v1)
{
cout << ch << " ";
}//1 2 3 4 5 6 7 8 9 10 10 10 10 10 10;
return 0;
}2.3 Modifiers(调节,修改,插入)
(我们这里只讲intsert这个函数接口,其余我们没有讲的接口的作用和我们前一篇中所讲的相同的接口的作用基本是相同的,所以我们除了我下面所讲的这几个函数接口以外的接口,大家如果有哪个函数接口不会的话,可以参照我们前一篇所讲的那个函数接口。)
2.3.1 insert()函数接口
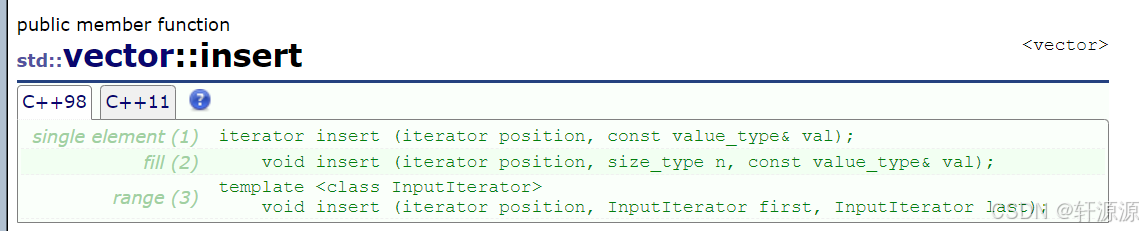
insert这个函数的作用就是在pos迭代器指向的这个位置处插入一个值val,通过我们上面那的那幅图可知,vector类中的insert函数它只支持迭代器访问(这个函数许多的重载,我们这里只讲其中的一个,其余的我们参考这个就可以了)。
2.3.1.1 iterator insert (iterator position, const value_type& val)函数
这个函数的作用是在迭代器position所指向的这个位置上插入一个val值(value_type是当前这个vector类类型的对象中所存储的元素的类型)。
2.3.2 erase()函数接口

2.3.2.1 iterator erase (iterator position)函数
这个函数的作用是删除position迭代器指向的位置上的元素。
2.3.2.2 iterator erase (iterator first, iterator last)函数
这个函数的作用是删除[first,end)这一段迭代器区间所指向空间的元素。
#include<iostream>
#include<vector>
using namespace std;
int main()
{
vector<int> v1({ 1,2,3,4,5,6,7,8,9 });
for (auto ch : v1)
{
cout << ch << " ";
}//1 2 3 4 5 6 7 8 9
cout << endl;
vector<int>::iterator it1 = v1.begin();//我们这里it迭代器指向的是v1对象的第一个元素的位置。
v1.insert(it1, 10);//在v1的首位置上插入10这个元素。
for (auto ch: v1)
{
cout << ch << " ";
}//10 1 2 3 4 5 6 7 8 9;插入成功。
cout << endl;
vector<int>::iterator it2 = v1.begin() + 3;
v1.erase(it2);//删除迭代器it2指向的那个位置的元素。
for (auto ch : v1)
{
cout << ch << " ";
}//10 1 2 4 5 6 7 8 9
cout << endl;
vector<int>::iterator it3 = v1.begin()+1;
vector<int>::iterator it4 = v1.begin()+5;
v1.erase(it3, it4);//删除区间为[it3,it4)这个迭代器去区间中的所有的元素。
for (auto ch : v1)
{
cout << ch << " ";
}//10 6 7 8 9
return 0;
}2.4 vector不支持operator<<和operator>>重载
在vector类中,编译器其实并不支持输入输出操作,这个vector相较于string来说,最大的区别就是vector输入输出不固定,而string的输入输出其实是固定的(vector的输入输出之所以不固定是因为vector中的各个元素之间没有固定的关系,有时候我们想输出某一个值,某一段区间,极少数的时候才可能会输出所有的元素,也就是具体输出什么我们这里是不确定的),但是我们可以通过其他的一些方式去实现这里的输入输出操作。但是不支持输入输出不代表它不可以输出元素,我们可以通过下买你的方式去实现输出元素的操作。
#include<iostream>
#include<vector>
using namespace std;
int main()
{
vector<int> v1({1,2,3,4,5,6,7,8,9});
for (auto ch : v1)//范围for去遍历v1。
{
cout << ch << " ";
}//1 2 3 4 5 6 7 8 9
cout << endl;
vector<int>::iterator it1 = v1.begin();
vector<int>::iterator it2 = v1.end();
while (it1 != it2)//通过迭代器区间去进行遍历v1。
{
cout << *it1 << " ";
++it1;
}//1 2 3 4 5 6 7 8 9
return 0;
}2.5 Element access(元素访问)
(我们这里只讲operator[ ]这个函数接口,其余我们没有讲的接口的作用和我们前一篇中所讲的相同的接口的作用基本是相同的,所以我们除了我下面所讲的这几个函数接口以外的接口,大家如果有哪个函数接口不会的话,可以参照我们前一篇所讲的那个函数接口。)

这个函数的作用是随机访问某一个元素,当然也可以修改某一个元素。
#include<iostream>
#include<vector>
using namespace std;
int main()
{
vector<int> v1(10, 1);
vector<vector<int>> v2(5, v1);
v2[2][3] = 8;//将v2对象中下标为(2,3)的这个位置上的元素修改为8。
for (size_t i = 0; i < v2.size(); i++)
{
for (size_t j = 0; j < v1.size(); j++)
{
cout << v2[i][j] << " ";
}
cout << endl;
}// 1 1 1 1 1 1 1 1 1 1
// 1 1 1 1 1 1 1 1 1 1
// 1 1 1 8 1 1 1 1 1 1
// 1 1 1 1 1 1 1 1 1 1
// 1 1 1 1 1 1 1 1 1 1
return 0;
}3 vector的应用
我们这里讲的这个vector实际上是一个类模板,编译器可以自动地去为不同的类型去生成我们所需要的vector类类型地对象,vector类类型的对象它里面所存放的元素的类型不仅仅可以是内置类型的,也可以是我们自己定义的自定义类型,具体解析请看以下的代码:
vector<int> v1(10, 1);//创建了10个int类型大小的空间,并将这10个空间全部初始化为1(我们这里暂时不考虑它的底层结构)。
vector<string> v2(1, "xxxx");//创建了1个string类型大小的空间,并将这个空间初始化为"xxxx"。 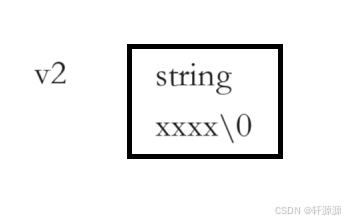
vector<vector<int>> v3(5, v1);//ok,通过我们之前所讲的那样,我们在这里可以得知,vector其实也属于是自定义类型,因此,我们vector也可以嵌套一个vector,这样写就相当于是开创了一个二维数组的空间。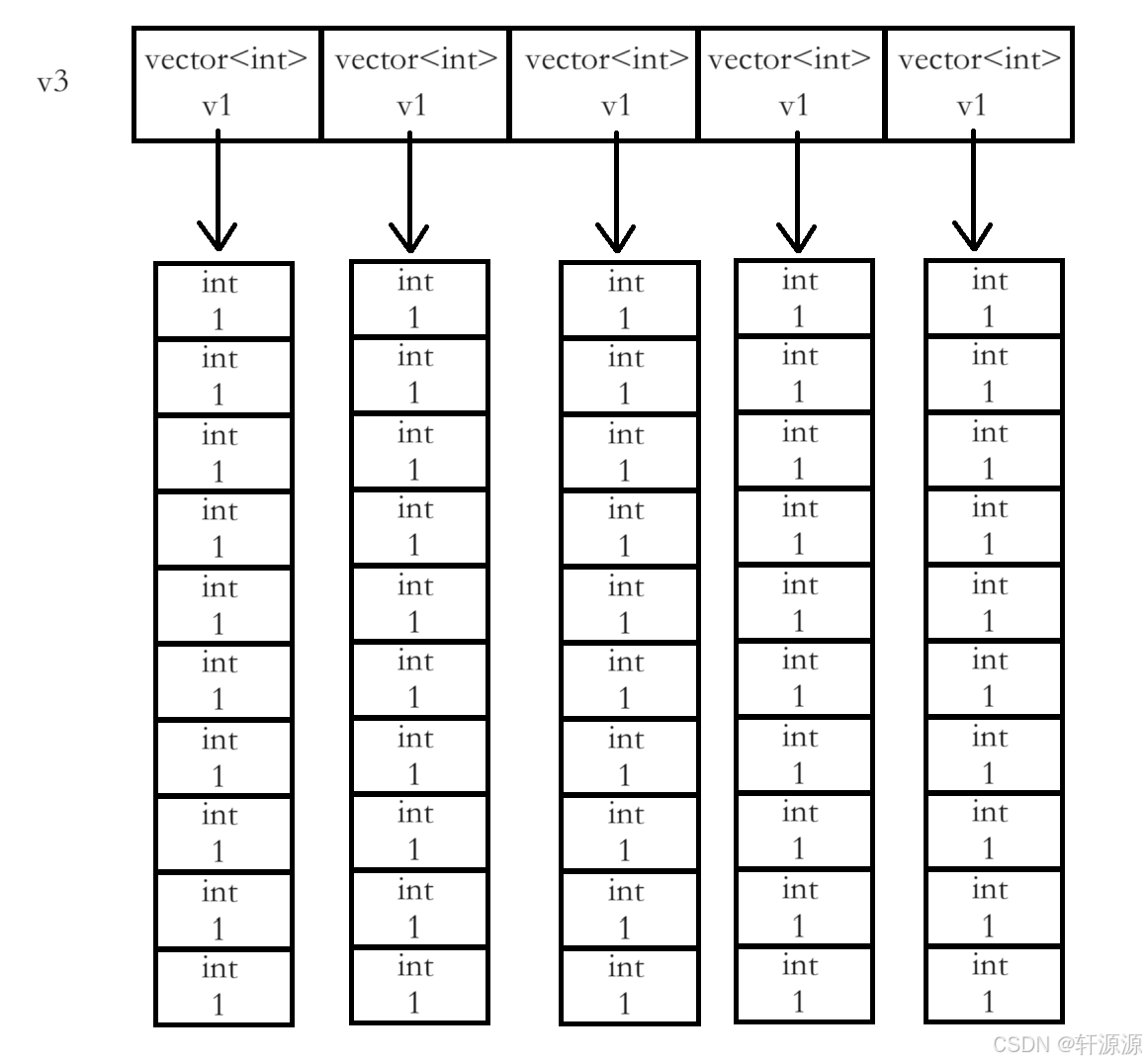
解析如下所示:vector<vector<int>> v3(5, v1);我们首先看第一个vector,我们创建了一个类型为vector<int>的vector类类型的对象,总共开创了5个vector<int>类型大小的空间,这5个空间均用v1对象进行初始化操作,再看第2个vector,这个vector是int类型的vector类类型的对象,换句话说,就是v1又指向了开创的10个空间,这10个空间都被初始化为1。
4.vector的底层实现以及在使用过程中容易出现的各种注意事项
4.1 vector类的成员变量
我们这里既然要实现vector类的底层逻辑,我们就首先要知道vector类的成员变量是什么,我们通过代码可以知道vector类中有3个成员变量,并且这3个成员变量均为迭代器(我们这里的迭代器实际上就是T*,在定义中:typedef value_type* iterator;就是改了一个名字而已,这种定义的方式是我们在这里的定义,这里我们将这个vector迭代器弄成char*类型的指针,其实这种定义是错误的,迭代器的底层其实是用类封装了一个指针,并不完全是指针,这个大家可以打开vector的头文件去看一下,我们这里之所以这么讲解,完全是因为方便大家去了解和使用,因为迭代器的使用和指针基本上没有什么两样,因此我们才选择这样去定义的)
template<class T>
class vector
{
typedef T* iterator;//定义一个迭代器,我们这里将vector中的迭代器弄做是char*类型,实际上底层并不是这么实现的,我们这里之所以这么定义完全是因为方便并且好理解。
iterator _start;//指向元素开始的位置。
iterator _finish;//指向元素结束的下一个位置。
iterator _end_of_storage;//指向空间结束的下一个位置。
}; 4.2 void reserve(szie_type n);函数的模拟实现
4.2 void reserve(szie_type n);函数的模拟实现
在我们开始写模拟实现之前我们先来了解一下reserve这个函数的功能,这个函数的主要作用就是开创新空间,也就是我们平时所说的扩容操作,用new开创一块连续的空间,再将原来的那块空间(也就是要进行扩容的那块空间)中的数据内容全部拷贝到这块刚刚新开创的空间中,再对其它的成员变量重新赋值即可,代码如下所示:
template<class T>
class vector
{
typedef T* iterator;
typedef const T* const_iterator;
public:
void reserve(int n)
{
T* tmp = new T[n];//开创空间。
memcpy(tmp, _start, size() * szieof(T));//拷贝数据,将原数组中的数据全部都拷贝到刚刚创建的这个tmp数组空间中。
delete[] _start;//再删除原来存放数据的那个数组空间。
_finish = tmp + size();//通过我们之前的讲解可知,_finish指针是指向元素结束下一个的位置,我们通过size()函数可以求出数组空间中的元素个数,tmp再加上元素个数就相当于是找到了元素结束的下一个位置,因此,让_finish指向这个位置就可以了。
_start = tmp;//通过我们之前的讲解可知,_start指针是指向存放数据的数组空间的首元素的位置,tmp数组是空间进行扩大操作之后的那块空间。
_end_of_storage = tmp + n;//通过我们之前的讲解我们可知,_end_of_storage是指向空间结束的下一个位置,我们这个reserve函数的目的是实现扩容操作,扩容结束后存放数据的空间大小就是n,因此,tmp再加上扩容之后空间的个数就相当于是找到了元素结束的下一个位置,那么,让_end_of_storage指向这个位置就可以了。
}
private:
iterator _start;
iterator _finish;
iterator _end_of_storage;
};这里我们需要注意两个事情:(1).当前我们完成上述操作的时候,其实有很多的同学会认为到这里其实就已经结束了,但是这里还有一个坑需要我们去注意一下,就是上面第13行和第14行的代码其实是不可以进行交换的,也就是说,这两行代码的顺序我们是不允许在这里交换的,否则的话,编译器会编译失效,解释如下(我们假如将这两行代码交换一下):

我们先让_start指针指向tmp所指向的位置,然后再让tmp+size() 的位置,这里会出现一个问题,就是size(),这个函数它是返回_finish-_start(也就是空间中元素的个数),那么这样的话,这句代码就相当于是_finish=_start(就是tmp)+_finish-_start,也就是说,执行完这句代码后,_finish还是指向空指针,这个问题实际上指的就是新旧空间的问题,_start指向的是新空间,而_finish指向的还是原来的旧空间,在这种情况下,旧空间-新空间就会出现问题。
(2).接下来我来给大家说一个我在这里所产生的一个问题,希望会对大家有所帮助,就是我们是在reserve这个函数的内部开创的一块空间,那么,当我们出这个函数的时候,按照道理,会销毁掉在这个reserve函数中所开创的空间,那么,为什么在上面的这个函数中我们却不用担心这个问题呢?这就是因为只有类的对象在生命周期结束的时候才自动调析构函数 指针是内置类型 你只有delete 指针 才调用析构函数,因此,这里我们不需要担心。一个函数在结束时销毁的是这个栈中所开创的空间大小,而tmp所指向的那块空间是在堆上开创的,因此,我们完全不用担心,用下图来更加形象地为大家解释一下:
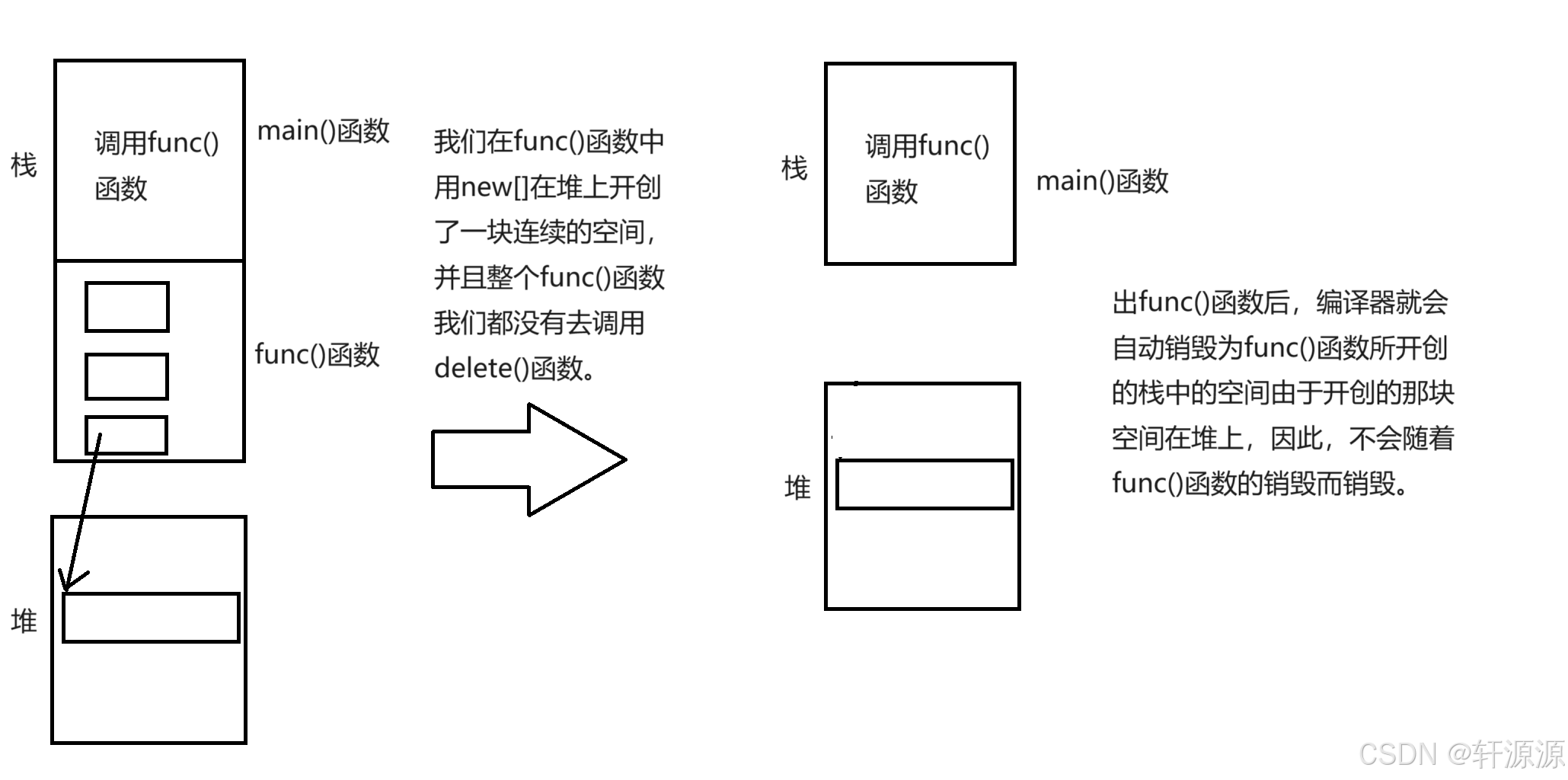
4.3 void print();(这个函数并不是库中的函数,是我们自己实现的打印函数)
接下来我们来实现vector类类型的对象的打印函数,在实现这个打印函数之前,我们首先要知道在vector类中是没有重载"<<"和">>"操作符的,也就是说,这个打印的函数,它并不是成员函数,它需要我们单独在类外去实现,由于vector类是一个类模板,因此这个打印函数也必须写成模板的形式,为了适应多种类型的打印操作,代码如下所示:
template <class K>
void print_vector(const vector<K>& v)
{
//对于我们在这里接下来要进行的操作,我们是需要去遍历存放数据的那个数组的,这里我们使用迭代器去实现遍历的这一操作。
//当我们在使用迭代器实现时,要注意一个东西,v是const类型的,因此在调用begin()和end()等迭代器时,它就只能调用const类型的。这里为了节省时间,就没有写用const修饰的这两个迭代器的实现方式,我们这里知道具体是这么的一回事就可以了。我们这里默认下面所有调用的begin()和end()都是调用由const修饰的。
//既然要使用迭代器,那么首先我们得要得到迭代器
//vector<K>::const_iterator it = v.begin();//按照我们平时的迭代器的写法来看的话,我们前面的代码时正确的,但是实际上却是错误的,不应该这样写,如果我们这样写的话,编译器会报错,C++规定:不能到没有实例化的类模板里面去取东西,编译器不能区分这里的const_iterator是模板还是静态成员变量,也就是说,编译器规定不能到类模板里面去取东西,如果大家这里理解不了的话将这个东西记住就好了。
//但是我们这里就必须要用到迭代器,我们此时只需要在最前面加上一个typename关键字就可以了。
typename vector<K>::const_iterator it = v.begin();//这句代码的意思就是说,const_iterator是一个类型,那么相反的,不加typename的话,就说明const_iterator是一个静态成员变量。
vector<K>::_start = nullptr;//这样写是正确的。
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;//这是其中的一种打印写法。
for (auto ch : v)
{
cout << ch << " ";
}//这是另一种打印的写法。
}4.4 迭代器失效
(1).类似于野指针的问题:这个问题就相当于是我们前面所说的那个新旧空间的问题,我们这里通过insert函数再来回顾一下这个问题,代码如下所示:
template<class T>
class vector
{
public:
typedef T* iterator;
void insert(iterator pos, const T& x)
{
//我们这里要实现的操作是插入操作,既然要实现插入操作,那么我们首先就要先判断一下是否有空间等着我们去进行插入操作,因此,我们就要先判断一下是否还有多余的空间。
if (_finish == _end_of_shorage)
{
size_t len = pos - _start;//求出pos的位置相对于_start在数组中的第几个位置上。
reserve(capacity == 0 ? 4 : _capacity() * 2);//如果这个数组中原空间为0的话,我们的这个插入元素的操作就相当于是开创一块空间,我们一般是开创4个空间的大小,如果原空间数不为0的话,那么,我们开创的空间的个数是原数组空间个数的2倍。
pos = _start + len;//让pos指向新开创的这个空间并与_start之间相差len个数据。
}
iterator end = _finish - 1;//将从pos位置开始到end位置上的元素全部都往后移动一位。
while (end != pos)
{
*(end + 1) = *end;
--end;
}
++_finish;//插入了一个元素,_finish往后移动一位。
}
private:
iterator _start = nullptr;
iterator _finish = nullptr;
iterator _end_of_shorage = nullptr;
};OK,以上就是我们实现插入元素的代码了,但是,还没结束,如果我们有认真的朋友的话,就会看出上述代码有一个致命性的错误,它是由_finish==_end_of_shorage这个情况引起的,如果我们在这种情况下我们去插入一个元素的话,编译器就会报错,通过下图我们来展示一下:
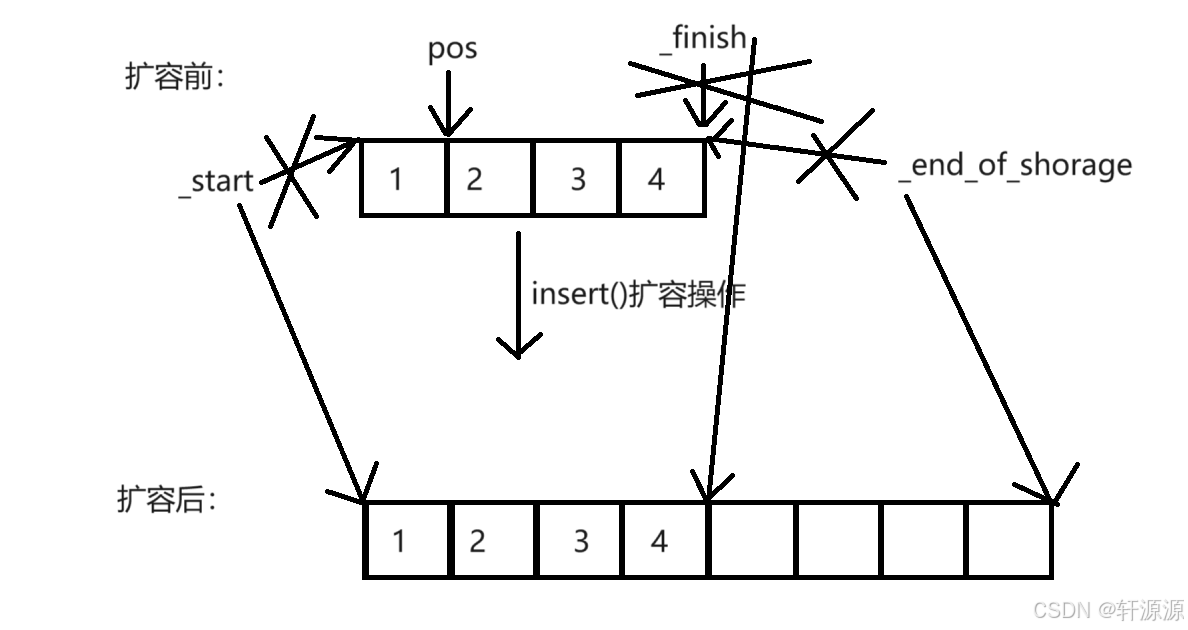
扩容之后,pos还指向的是原来的那块空间的位置,但是我们在经过reserve函数过后,原来的那块空间就被是释放了,因此pos是指向为空,也就是说,如果我们不在经过reserve这个函数过后对pos进行重新指向的话,那么,编译器可能会造成死循环的问题,对于这种情况所引发的问题,我们称之为是迭代器的失效(pos是迭代器)。
这种问题主要是由空间进行扩容操作时引起的,因此,需要在扩容这一操作上作文章,将上述代码中的第8~11行替换成下面这几行:
if (_finish == _end_of_shorage)
{
size_t len = pos - _start;//求出pos的位置相对于_start在数组中的第几个位置上。
reserve(capacity == 0 ? 4 : _capacity() * 2);//如果这个数组中原空间为0的话,我们的这个插入元素的操作就相当于是开创一块空间,我们一般是开创4个空间的大小,如果原空间数不为0的话,那么,我们开创的空间的个数是原数组空间个数的2倍。
pos = _start + len;//让pos指向新开创的这个空间并与_start之间相差len个数据。
}(2).insert以后,pos就失效了,不要再访问了。
1>.不扩容的情况下,在插入之后再去访问的话,意义就变了,借助前面这一章的所有代码,我们来看一下:
int main()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
int x = 2;
auto p = find(v.begin(), v.end(), x);//这里我们去调用库里面的find()函数,库里面的这个find()函数它可以用于所有的容器,它会根据传过来的这个迭代器,从这两个迭代器所控制的空间中去找x,若找到,则返回相应位置的迭代器,反之,则返回传过来的那个end()迭代器,这里我们先来了解一下find函数的用法,这里我们要求会用就行。
//我们接下来实现一下在2这个元素的位置的前面去插入一个40这个元素,然后我们将2这个元素再乘一个10。
if (p != v.end())
{
v.insert(p, 40);
(*p) *= 10;
}
vector<int>::iterator it = v.begin();
while (it != v.end())
{
cout << *it << " ";
++it;
}
return 0;
}当我们开始运行的时候,我们会发现编译器居然在这个地方报错了(第12行的原因),是因为编译器内部设置了不允许在insert之后去访问迭代器,因此,编译器在这里会报错,既让这样的话,我就来直接告诉大家结果吧:1 400 2,OK,我们发现这个结果却和我们想要的结果不一样,是因为在2这个元素的前面插入一个元素之后,相应的2这个元素就要往后面移动一位,将40这个元素插入到2原来的那个位置上去,而p这个指针还指向原来的2那个位置,因此,就达不到我们想要的那个效果。
2>.接下来,我们来看一下扩容的这一情况,在执行insert这一操作时,如果时靠扩容操作完成的,那么此时去访问元素时非常危险的:
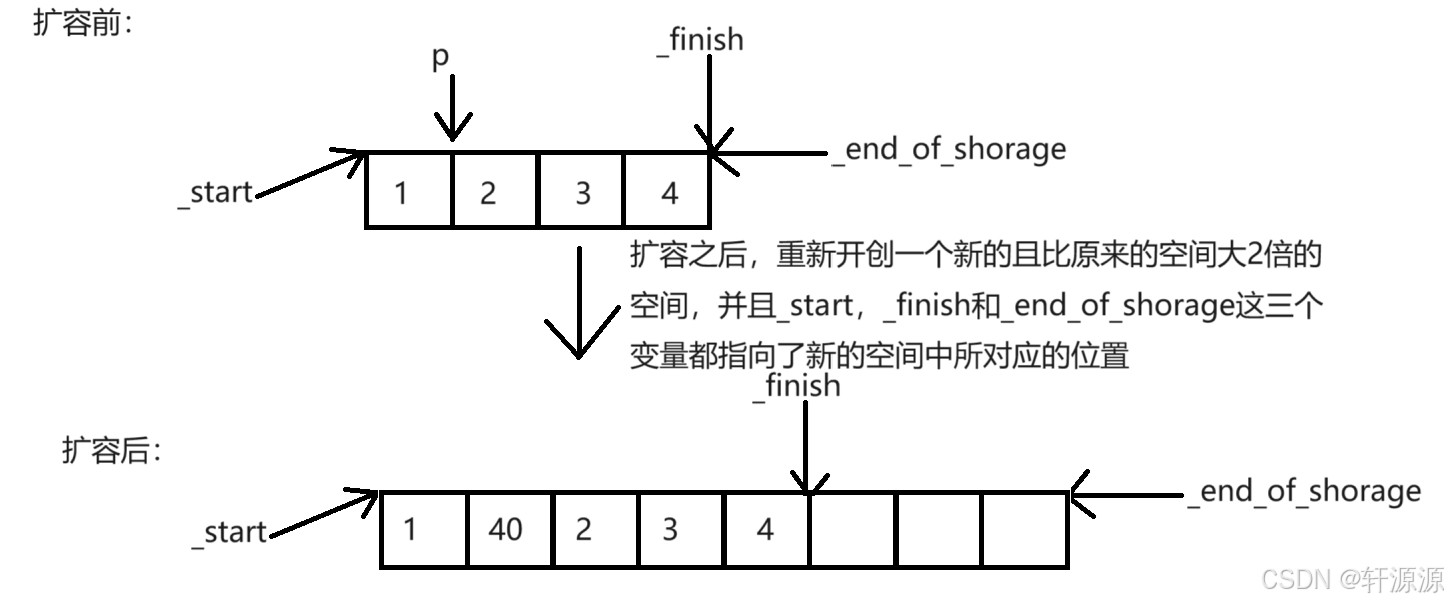
通过上面的这幅图我们可以得知,遇到这种需要我们去扩容的情况时,就会出现和前面一样的新旧空间的问题,在进行insert这一插入元素的操作后,p这个迭代器它指向的还是旧空间,此时若对其进行访问操作的话就会很危险,结合我们前面所了解的知识,有的同学可能就会说在reserve中不是对这个问题进行处理了吗?是的,确实是处理了针对这个问题,但是是对传过去的形参进行了处理,形参改变不会影响实参;对形参引用也不行(insert(iterator& pos,const T& x)),有权限放大的问题;使用const修饰pos迭代器其实也不行(insert(const iterator& pos,const T& x)),这样无法解决在扩容时出现的那个新旧空间的问题。
如果我们在某种特殊情况下必须要去访问的话,其实也可以被访问,只需要重新去定义一下p的位置即可,在vector的库中,insert有多个函数重载,其中一个函数重载:iterator insert (const_iterator position, const value_type& val);这个函数会返回插入元素位置的迭代器,以前面的例子为例:我想让在插入40这个元素之后再将2这个元素乘以10变成20,代码如下:
int main()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
int x = 2;
auto p = find(v.begin(), v.end(), x);//这里我们去调用库里面的find()函数,库里面的这个find()函数它可以用于所有的容器,它会根据传过来的这个迭代器,从这两个迭代器所控制的空间中去找x,若找到,则返回相应位置的迭代器,反之,则返回传过来的那个end()迭代器,这里我们先来了解一下find函数的用法,这里我们要求会用就行。
//我们接下来实现一下在2这个元素的位置的前面去插入一个40这个元素,然后我们将2这个元素再乘一个10。
if (p != v.end())
{
p = v.insert(p, 40);
(*(p+1)) *= 10;
}
vector<int>::iterator it = v.begin();
while (it != v.end())
{
cout << *it << " ";
++it;
}//1 40 20 3 4
return 0;
}综上所述,我们知道insert之后会出现某一种问题,由此观之,我们普遍认为在实现insert函数之后,我们就认为pos迭代器失效了,我们也就不会再去访问了。
(3).erase之后,pos也失效了,就不要再访问了。
为了有一个更好的效果,我们这里首先来模拟实现一下erase函数:
template<class T>
class vector
{
public:
typedef T* iterator;//我们这里将元素的类型的指针typedef成迭代器,这里只是为了方便才这么做的,实际上vector库的底层的迭代器的实现是将其用类封装起来的,我们这里知道一下就好了。
void erase(iterator pos)
{
assert(pos >= _start);
assert(pos <= _finish);//我们首先要保证pos是有效的。
iterator it = pos + 1;//erase函数的功能是删除pos迭代器所指向位置的那个元素,因此要将这个元素以后的所有元素均向前挪动。由此得知,it迭代器应该指向pos这个位置的下一个位置
while (it != end())
{
*(it - 1) = *it;
}
--_finish;
}
private:
iterator _start = nullptr;
iterator _finish = nullptr;
iterator _end_of_shorage = nullptr;
};以上的操作就是我们模拟实现的vector类中的erase函数的操作。接下来,我们通过"删除所有的偶数"这个例子来解析一下这里的原因,代码如下所示:
int main()
{
vector<int> v;
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
{
v.erase(it);
}
++it;
}
return 0;
}//删除所有的偶数,我们是将那个偶数删除之后就++it,我们来看一下是否能够完成我们想要的结果。1>.当v对象中存放的元素是1,2,3,4,5时,当运行程序时,我们会发现程序可以完美的运行下来,并且输出结果是1,3,5。
2>.当v对象中存放的元素是1,3,4,4,5时,当运行程序时,我们会发现程序也可以运行下来,但是,结果是1,3,4,5,并没有达到我们想要的结果,那么,我们现在就来看一下原因:
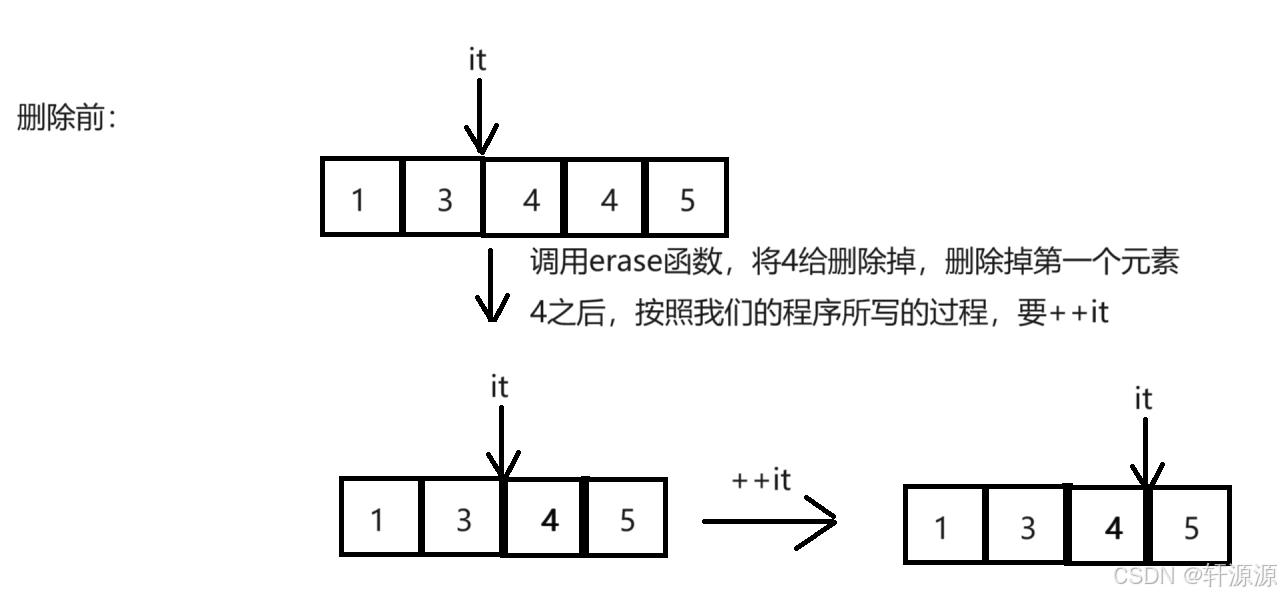
由上副图我们可以得知,++it之后,跳过了第2个元素4,从而使得结果没有达到我们想要的效果。
3>.当v对象中存放的元素是1,2,3,4时,当程序运行时,编译器会崩溃,是段错误,原因如下:
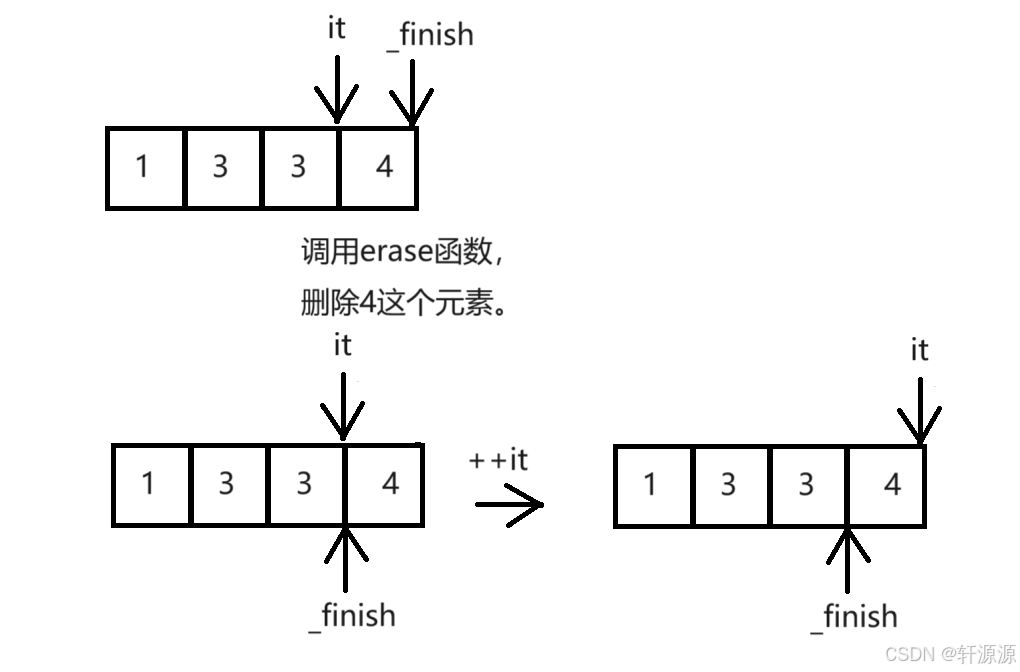
由于这一轮while循环结束时,it!=_finish因此会加入下一轮循环,此时it其实都已经越界了。*it是一个随机值,如果为偶数,则又一次调用erase函数,由于it>_finish被assert断言检查出来了,因此会报错,若*it一直为奇数的话,就会一直循环走下去。
综合以上三种情况而言,再调用erase函数之后再去访问的话容易出错,因此C++规定erase函数之后就不要再去访问了。但是若我们非要在erase之后去访问的话,其实也有方法,只需要更新一下这个失效的迭代器it的值就可以了。将上面的while循环中的代码改成下面的内容就可以了:
while (it != v.end())
{
if (*it % 2 == 0)
{
it = v.erase(it);
}
else
{
++it;
}
}(5).模拟实现resize()函数:
直接上代码:
template<class T>
class vector
{
public:
typedef T* iterator;//为了方便。
void resize(size_t n, T val = T())//后面我们会讲解一下这个T()的,我们在这里要实现一下resize函数,首先我们先了解一下resize函数,这个函数的作用是将数据个数从原来的个数扩大到n个,并对其进行初始化,初始化值是value,好的。那么,根据我们所讲述过的知识来看,resize函数的实现,它分为三种情况(前面有讲过,可以到前面去看相关的知识。由于某种原因,这里就不一一区分了,我们直接开始)
{
if (n < size())//size()这个函数它返回的是数据的个数n小于size()的,这种情况就说明这里要实现的是减少数据的操作,既然如此,那么就直接重新定义一下_finish的位置即可。
{
_finish = _start + n;
}
else//其余的两种情况就将均为n>size()的情况了。
{
reserve(n);//这里我们先来看一下剩余的两种情况,一种情况是size()<n,并且n>capacity(),这种情况我们是需要进行扩容操作的,而另一种情况则是size()<n<capacity()这种情况,其实是不需要我们进行扩容的,但是如果非要进行扩容操作的话,其实也是可以的,因此我们这里就不再分情况考虑了,需不需要进行扩容操作了
while (_finish < _start + n)//我们这里既然要扩大数据,就足以说明要扩大的数据比原来的数据个数多,而_finish迭代器就指向的是原来数据结束的下一个位置,因此我们从_finish位置开始往后一一赋值,直到数据的位个数达到n就说明成功了
{
*_finish = val;
++_finish;
}
}
}
private:
iterator _start = nullptr;
iterator _finish = nullptr;
iterator _end_of_shorage = nullptr;
};接下来我们这里再看一个比较重要的知识点,就是前面代码中的T(),val是一个形参,我们这里想要给这个T类型的对象(val)一个缺省值。由于val是T类型的对象,这个T可以是vector,可以是string,这些自定义类型,当然也可以是int,double这样的内置类型,我们这里使用一个匿名对象来作为val的缺省值,但是这样的话就会新产生一个问题,匿名对象只仅限于类类型的对象,而T还有可能是内置类型。为了兼容向这种地方的这个场景,c++为内置类型设计了构造函数,这样的话就相当于是有了模板,当然也有析构函数,只不过对于内置类型而言,什么都不用做,例:
int main()
{
int i = int();//默认初始化为0,类似于匿名对象。调用赋值构造
int j = int(1);//初始化为1。
int k(2);//初始化为2。
return 0;
}5.关于vector的其他知识
(1).在我们这里的vector类类型的模板中,也就是在我们的类中,如果我们写了构造函数的话,编译器是不会再为我们自动生成默认构造函数的,C++11过后,我们可以在拥有构造函数的情况下让编译器强制生成默认构造函数。注:拷贝构造函数也属于是构造函数。
template<class T>
class vector
{
public:
vector<T>() = default;//在后面加上一个default关键字,意思就是说,可以强制生成默认构造,在其他的类中也同样适用。
vector<T>(const vector<T>& v)//拷贝构造,通过我们前面所学的知识可知,一个类中只要有构造函数,那么编译器就不会再生成默认构造函数了,是需要我们自己写构造函数的,我们这里写一个拷贝构造是为了凸显出这个特点。
{
reserve(v.size());//开空间
for (auto& ch : v)
{
push_back(ch);
}
}
private:
//由于某种原因,我们这里就不写了,大家知道就好了。
};
int main()
{
vector<int> v;//编译器在这里没有报错,就说明编译器在编译的时候强制生成了一个默认构造函数。
return 0;
}(2).在我们这里vector类模板中,我们在写类型时,可以不用写后面的那个<T>,只写一个vector就可以代表类型,出了类之后就不可以这样写了。
template<class T>
class vector//我们这里将所有的vector<T>全部替换成vector,用来验证我们的这个结论。
{
public:
vector() = default;
vector(const vector& v)
{
reserve(v.size());
for (auto& ch : v)
{
push_back(ch);
}
}
private:
//由于某种原因,我们这里就不写了,大家知道就好了。
};
int main()
{
vector<int> v;
vector<int> v1(v);//将v中的数据全部拷贝给v1,编译器在这里没有报错,就说明运行成功了,这里没有问题。
return 0;
}(3).紧接着,我们来讲一个相对比较重要的知识点,就是类模板中的成员函数,还可以继续是函数模板,我们这里在代码里面对其做进一步的解释说明:
template<class T>
class vector
{
public:
template<class inputiterator>
vector(inputiterator first, inputiterator last)//我们这里通过模拟实现一个vector库中的构造函数的重载,就是用迭代器区间初始化的那个重载函数。
{
while (first != last)
{
push_back(*first);
++first;
}
}
private:
//...
};这是模拟实现的通过迭代器区间初始化的那个重载函数。
int main()
{
vector<int> v1;
v1.push_back(1);//push_back这个函数这里没有,我们默认是存在的。
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
print_container(v1);//1 2 3 4;print_container这个函数可以打印出任意类型中存储的值,我们这里没写,但是是存在的。
vector<int> v2(v1.begin(), v1.begin() + 3);//调用构造函数进行初始化操作。将v1对象中的前三个元素初始化给v2,此时构造函数的inputiterator就是vector<int>类型d的迭代器。
print_container(v2);//1 2 3
//这里我们写一个list<int>类类型的对象,这里我们学list,我们在这里先简单的提一下,这个list和vector的用法差不多,都是模板。
list<int> l1;
l1.push_back(10);
l1.push_back(20);
l1.push_back(30);
l1.push_back(40);
print_container(v1);//10 20 30 40
vector<int> v3(l1.begin(), l1.begin() + 3);//调用构造函数进行初始化操作。将l1对象中的前三个元素初始化给v3,此时构造函数的inputiterator就是list<int>类型的迭代器。
print_container(v2);//10 20 30
return 0;
}OK通过我们所写的代码,我们可以知道若将迭代器区间初始化这个函数写成模板的话,那么迭代器就可以不止局限于是vector<T>这个类型了,就可以是不同种类的迭代器类型,换句话说就是我们定义了一个vector类类型的对象,并对这个对象进行迭代器区间进行初始化操作,可以用任意容器的迭代器进行初始化操作,这一切都是由于我们将迭代器区间初始化的这个函数写成了模板,但要求是必须保证迭代器所指向的元素的类型和待初始化的对象中要存储的元素类型必须保持一致,或者通过强制类型转换可以转换成我们想要的类型才可以。由此可知,我们类模板中的成员函数,还可以继续是函数模板。
既然我们说到这里了,就再来给大家讲一个函数传值的问题,就是函数在进行传参的操作时,若此函数有多个函数重载的话,编译器会调用所有的函数重载中最合适的那个函数,用代码解释如下所示:
template<class inputiterator>
vector(inputiterator first, inputiterator last)//我们这里通过模拟实现一个vector库中的构造函数的重载,就是用迭代器区间初始化的那个重载函数。
{
while (first != last)
{
push_back(*first);
++first;
}
}
vector(size_t n, const T& val = T())
{
reserve(n);
for (size_t i = 0; i < n; i++)
{
push_back(val);
}
}以上是我们模拟实现的两个vector类类型的构造函数,我们现在来看一下:
int main()
{
vector<string> v1(3, "xxxxxx");
print_vector(v1);//xxxxxx xxxxxx xxxxxx;调用的是第一个构造函数。
vector<int> v2(10);
print_vector(v2);//0 0 0 0 0 0 0 0 0 0;调用的是第二个构造函数。
vector<int> v3(10, 1);
print_vector(v3);//编译器会报错,是因为对first解引用了。
return 0;
}调用v3时,编译器会报错,报错的原因是对int类型的变量进行了解引用操作,为什么呢?按照我们的意思来说,就是插入10个int类型的元素均为1的元素,可是并没有达到我们想要的效果。解析如下:编译器它在进行我们这里的传参操作时,会调用与实参最匹配的那个函数。换句话说,就是有现成的就调用现成的那个函数,没有的话就再说其他的,我们这里一个一个慢慢分析,若调用第一个构造函数的话,编译器会认为inputiterator是int类型,这样的话就是vector(int first,int last),若传第二个构造函数的话,编译器需要进行隐式类型转换,int需要转换为size_t类型,按照这样的对比来看的话,发现调用第一个构造函数比调用第二个构造函数要轻松的多,并且这两个构造函数均可以完成传值,且第一个构造函数是现成的,那么编译器它就会调用第一个构造函数,因此会报关于解引用first的错误。
(4).这里我们来探讨一下关于vector类类型的对象中所存储的元素类型的问题。众所周知,vector类类型的对象既可以存放内置类型的元素,也可以存放自定义类型的对象,比如说string类,我们这里分别就int(代表内置类型)和string(代表自定义类型)来分别看一下:
int main()
{
vector<int> v1;
v1.push_back(1);//push_back这个函数的内部其实也调用了reserve这个函数去实现的,因为这个函数是实现为差的操作,尾插有可能要进行扩容操作。通过我们前面所实现的reserve函数可知,当插入第五个元素的时候,编译器在这里就进行自动进行二倍扩容的操作,而我们这里就是要探究扩容后的空间问题,因此我们这里插入五个元素来看一看产生的问题都是什么。调用的reserve函数是调用我们前面实现的那个reserve函数。
v1.push_back(1);
v1.push_back(1);
v1.push_back(1);
v1.push_back(1);
print_container(v1);//1 1 1 1 1;编译器没有报错,就说明这里的内置类型,我们这里的空间扩容是没有问题的。好,那我们接下来就来看看自定义类型,这里以string类为例。
vector<string> v2;
v2.push_back("111111");
v2.push_back("111111");
v2.push_back("111111");
v2.push_back("111111");
v2.push_back("111111");
print_container(v2);//编译器会打印出一堆的乱码出来,为什么呢?
return 0;
}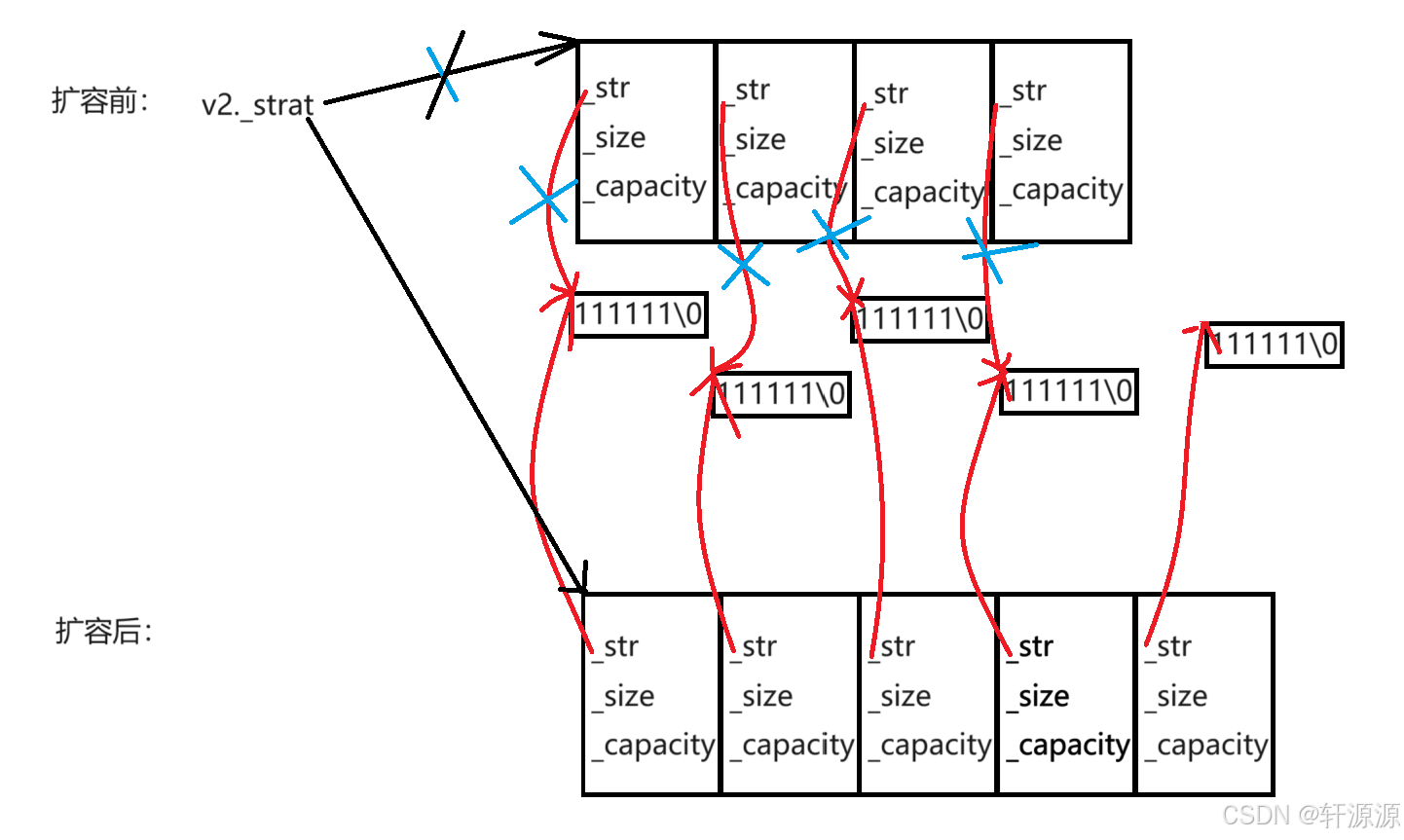 按照我们reserve函数中所实现的那样来看,将扩容后所需的空间开好之后,此时编译器就会调用memcpy函数将原来空间中的数据全部都一个字节一个字节的拷贝到刚刚开创的新空间中相应的位置上,由于memcpy它执行的是浅拷贝操作,那么就会造成原空间中存储的string类类型的对象和对应的新扩容的空间中存储的string类类型的对象指向的是同一块空间,按照程序按下来就会将原来的那块空间给释放掉,这样的话,新扩容的空间各中各个元素中的_str指针就会全部都变成野指针,此时再去访问的话就会出问题,因此我们这里需要把这个memcpy函数修改一下,用下面的这些代码的代码来替换掉memcpy函数所在的这一行代码。
按照我们reserve函数中所实现的那样来看,将扩容后所需的空间开好之后,此时编译器就会调用memcpy函数将原来空间中的数据全部都一个字节一个字节的拷贝到刚刚开创的新空间中相应的位置上,由于memcpy它执行的是浅拷贝操作,那么就会造成原空间中存储的string类类型的对象和对应的新扩容的空间中存储的string类类型的对象指向的是同一块空间,按照程序按下来就会将原来的那块空间给释放掉,这样的话,新扩容的空间各中各个元素中的_str指针就会全部都变成野指针,此时再去访问的话就会出问题,因此我们这里需要把这个memcpy函数修改一下,用下面的这些代码的代码来替换掉memcpy函数所在的这一行代码。
for (size_t i = 0; i < size(); i++)
{
tmp[i] = _start[i];//这里调用的是string的赋值构造函数。
}通过上面的解释,我么那接下来重新实现一下reserve函数:
template<class T>
class vector
{
typedef T* iterator;
typedef const T* const_iterator;
public:
void reserve(int n)
{
T* tmp = new T[n];//开创空间。
for (size_t i = 0; i < size(); i++)
{
tmp[i] = _start[i];//这里调用的是string的赋值构造函数。
}
delete[] _start;//再删除原来存放数据的那个数组空间。
_finish = tmp + size();//通过我们之前的讲解可知,_finish指针是指向元素结束下一个的位置,我们通过size()函数可以求出数组空间中的元素个数,tmp再加上元素个数就相当于是找到了元素结束的下一个位置,因此,让_finish指向这个位置就可以了。
_start = tmp;//通过我们之前的讲解可知,_start指针是指向存放数据的数组空间的首元素的位置,tmp数组是空间进行扩大操作之后的那块空间。
_end_of_storage = tmp + n;//通过我们之前的讲解我们可知,_end_of_storage是指向空间结束的下一个位置,我们这个reserve函数的目的是实现扩容操作,扩容结束后存放数据的空间大小就是n,因此,tmp再加上扩容之后空间的个数就相当于是找到了元素结束的下一个位置,那么,让_end_of_storage指向这个位置就可以了。
}
private:
iterator _start;
iterator _finish;
iterator _end_of_storage;
};补充:这里我们借助vector中的push_back这个函数接口来实现一下push_back这个函数:
void push_back(const T& x)
{
if (_finish == _end_of_shorage)
{
reserve(capacity() == 0 ? 4 : capacity() * 2);
}
*_finish = x;//这一步这里再着重强调一下,这一步的操作其实就是往vector类类型的对象中尾插一个元素x,这里注意一下,插入元素并不是直接插入x本身,而是调用拷贝构造函数,会调用x类型的拷贝构造,根据x创建一个对象将创写好的这个对象插入到_finish这个空间中。
++_finish;
}OK,今天我们就先讲到这里了,那么,我们下一篇再见,谢谢大家的支持!