一、前言
在上一次的教程里,教了大家如何搭建STM32MP157的开发环境,我们在Ubuntu18.04中部署好了环境并且完成了相关的配置。当然,搭建好开发环境只是学习STM32MP157的第一步。那么本次教程,就来带大家认识STM32MP157的启动流程并且教大家如何移植TF-A。当然,这里为什么要移植TF-A会留在后面再讲,这和STM32MP的启动流程有关,讲起来也比较复杂。所以,只能等启动流程介绍完了以后,再来解释TF-A。顺带一提,因为我购买的是正点原子的STM32MP157开发板,后面的教程也是基于这块开发板的。如果你准备好了,那就让我们开始吧!
二、谁适合本次教程
这里只是复述正点原子的建议,因为STM32MP157引入了TF-A这个概念,所以同时也引入了设备树的概念。但是,设备树是在Linux驱动开发中才会用到的,又但是,我们要学习Linux开发就是移植一个Linux,移植一个Linux又要涉及到移植TF-A。这样就像是形成了程序中的死锁一样。正点原子视频中给出的建议是,不建议没有Linux驱动开发基础的小伙伴来学习本次教程。至于原因嘛,当然就是上面那种情况。当然,就算没有Linux驱动开发基础也是可以跟着操作的。毫不避讳的说,我并没有Linux开发基础,但我还是决定跟着操作。一些修改设备树的地方我也不需要理解,等到学习完Linux驱动开发以后,再来看这次教程,我想我应该会有不一样的理解。
三、资料的准备
这里我就不像之前写环境搭建教程那样,为大家专门准备资料了,这一次我们就直接使用正点原子的资料,关于资料如何下载已经在环境搭建的教程中说得很清楚了,如果还有不知道如何下载资料的小伙伴请查看环境搭建教程中的资料准备部分:
STM32MP157环境搭建:[Linux]从零开始的STM32MP157交叉编译环境配置-CSDN博客
准备好资料以后,就让我们继续吧:
四、STM32MP157的启动流程
这里的讲解我们会结合正点原子的“【正点原子】STM32MP1嵌入式Linux驱动开发指南V2.1.pdf”文档教程,它被放在了正点原子资料目录下的“09、文档教程(非常重要)”文件夹中:
本次教程会和文档中的内容基本同步,如果有不理解的地方,还请大家查看正点原子的文档。
那我们现在就正式开始了解STM32MP157是如何启动的。
1.STM32MP157的启动模式
我们的STM32MP157已经不像传统的STM32微控制器那样,直接将程序下载到Flash中就可以直接运行。STM32MP1的代码被放在了外部的Flash中,比如我们常见的EMMC,NAND,SD卡等,都可以用来存放STM32MP157的程序。既然有这么多种的启动设备,那么,如果我们将多种存储设备都接到STM32MP1上时,它会选择哪个设备启动呢?这就是我们接下来要讲解的STM32MP157的启动模式。
在STM32MP157的程序起始位置,有一段128kb的空间,这一段空间用于存放ST自己写的代码。这些代码用户是不能修改的,它们用于确定从哪一个外部存储设备来启动代码。这128kb如图所示:
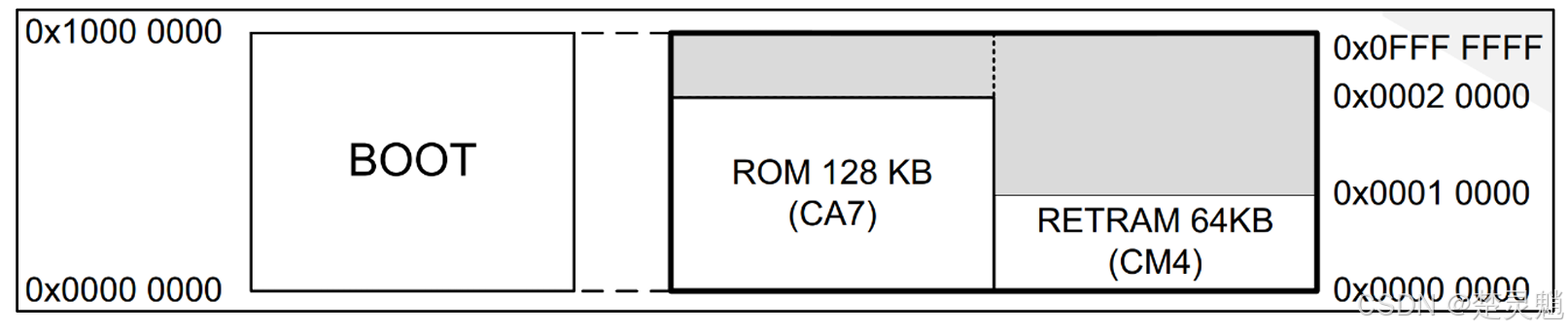
我们可以看到,这128k是属于我们芯片中的A7内核的,也就是当A7内核运行时才会运行这段代码。
当我们知道了STM32MP157的内部程序起始处有一段空间,它可以选择从哪个外部存储设备启动,那........具体是从哪个外部设备启动呢?这是用我们芯片上的BOOT引脚来决定的。STM32MP157上拥有三个BOOT引脚,分别是BOOT0,BOOT1,BOOT2。通过外部为这些BOOT引脚施加电平再搭配上刚才提到的内部128kb的代码,STM32MP157就能准确的选择从哪个Flash启动代码。下面我们来看看BOOT引脚的电平与启动设备的对照关系图:
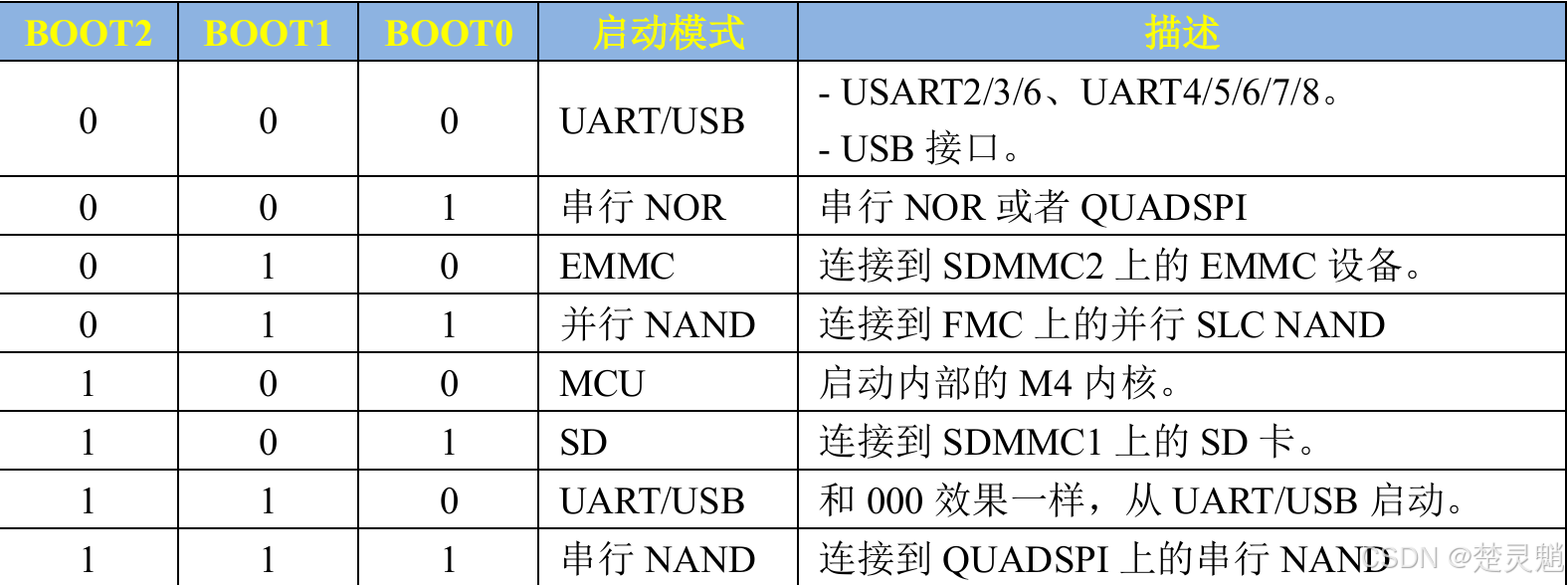
这里我们可以简单的看一下,按照图中所示,当我们的BOOT0为逻辑0,BOOT1为逻辑1,BOOT2为逻辑0时,我们的芯片就会选择从EMMC中读取代码。当BOOT0为逻辑1,BOOT1为逻辑0,BOOT2为逻辑1时我们的芯片就会从SD卡中读取代码。这里非常简单,也不做过多的讲解了。
但是现在我们还有一个问题,如何设置这些BOOT引脚的电平呢?其实很简单,正点原子在设计开发板时就已经考虑到了这个问题,让我们打开底板的原理图,它被放在了正点原子资料目录下的“02、开发板原理图”文件夹下,这里大家根据自己的底板版本选择原理图:
在原理图中,我们可以看到BOOT引脚被接到了这三个拨码开关上:

根据图中的描述,当我们将拨码拨到ON时,相当于引脚直接上拉到高电平。当我们将拨码拨到OFF时,引脚处于浮空或者是接地的状态,表示低电平。这里从正点原子的原理图中可以看出,当我们拨到OFF时,引脚会悬空,从而为引脚置低电平。在开发板上,拨码如图所示:

这里开发板上的拨码顺序从左到右依次为BOOT0,BOOT1,BOOT2,与表格中的BOOT顺序并不对应,大家根据实际情况进行调整。当然,拨码旁边的表格与拨码的顺序是对应的。大家可以按照拨码旁边的表格进行拨码。
在后面的正点原子的教程中,讲解了STM32MP157内部ROM代码启动的相应流程,这里的启动流程可以说是相当的复杂,就留给大家自行研究吧!毕竟我作为一位Linux新手,没有把握能够讲好。
2.安全启动的概念
当我们了解了STM32MP157是如何从外部存储设备中读取代码以后,我们现在来了解一下什么是安全启动。
首先我们要了解两个概念:
FSBL:全称为First stage boot loader,也就是第一阶段启动文件。
SSBL:全称为Second stage boot loader,也就是第二阶段启动文件。
当我们的STM32MP157选择了从哪个外部存储设备读取代码以后,就会进入安全启动六层,首先STM32MP157加载FSBL镜像,FSBL镜像就是ROM代码加载的第一个用户编写的可执行程序。我们常常会在FSBL镜像处存放TF-A镜像。这也是为什么我们一开始要教大家移植TF-A,因为这里要用到,并且是第一段用户代码就用到了。当然,这里不是简单的把我们编译好的bin文件放在FSBL区就没问题了,还需要为bin文件前面添加一个头部信息,否则内部ROM代码不知道如何处理这个bin 文件。
当我们的STM32MP157选择一种存储设备并且准备运行代码时,这些代码会在哪里运行呢?因为我们刚才只跑过了MP157内部的ROM代码。并没有初始化DDR,所以并不能使用。我们这里只能将FSBL代码放在MP157内部的SYSRAM中运行。在STM32MP157的内部一共有256kb的SYSRAM地址范围为0X2FFC0000~0X2FFFFFFF。ROM代码会将FSBL镜像拷贝到0X2FFC2400地址。但是FSBL的地址并不是0X2FFC2400。还记得我们一开始提到的FSBL的前面有一个256字节的头吗?所以我们FSBL的起始位置还要放在这个头之后即“0X2FFC2500”:

这里加100是因为256的十六进制为100。当我们编写A7的裸机程序时,链接地址就是“0X2FFC2500”。
顺带一提。boot上下文会保存到SYSRAM的前512 字节里面,boot上下文包含了boot信息,比如选定的boot设备,还有一些和安全启动鉴权有关 的服务。这也是为什么,ROM会将代码拷贝到0X2FFC2400而不是SYSRAM的起始地址。
此外,正点原子的文档中还介绍了串行启动,USB启动,OTG启动等,这里就不多说了。
3.从EMMC启动代码
我们现在来讲解一下STM32MP157是如何从EMMC中启动代码的。我们来看一下正点原子开发板上的EMMC的结构框图:

我们可以看到,这块芯片的起始位置,有两个boot分区,这是用来引导系统的。我们需要将FSBL的代码存放在此处。有两个boot分区我们选择一个存放就行,STM32MP157内部的ROM代码会去加载有效的那一个boot。这里boot1,boot2,RPMB分区的大小都是固定的,用户不能修改。ROM代码使用单bit模式来操作EMMC,默认情况下ROM代码使用连接到SDMMC2上的EMMC。从正点原子的核心板原理图上,我们也可以看出来,正点原子将EMMC接到了SDMMC2上:
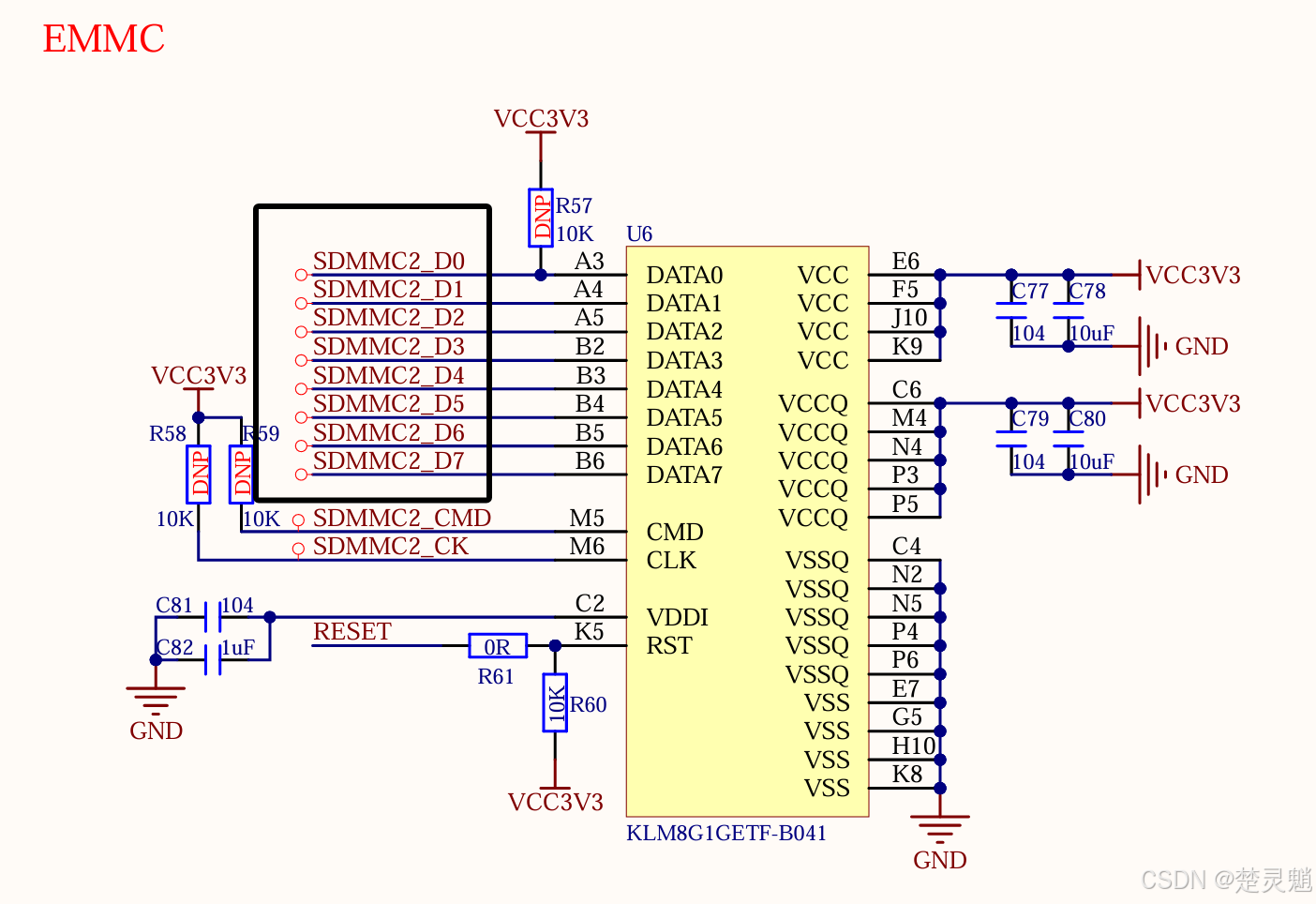
除了从EMMC启动外,正点原子还在文档中介绍了多种启动方式,大家自行查看即可。
4.STM32MP157FSBL中的头部信息
之前,我们提到了在FSBL中我们存放了TF-A,在TF-A的前面放了一段256字节的头部信息,这些头部信息用于描述了后面的代码如何运行以及一些鉴权信息。现在我们就来解析一下这个1头部信息看看里面存放了什么内容,首先就是一个大致的结构框图:

从表格中,我们可以看到,这个头部信息中包含了这么多的内容,下面我们可以根据下方的表格来查看这些内容的作用:
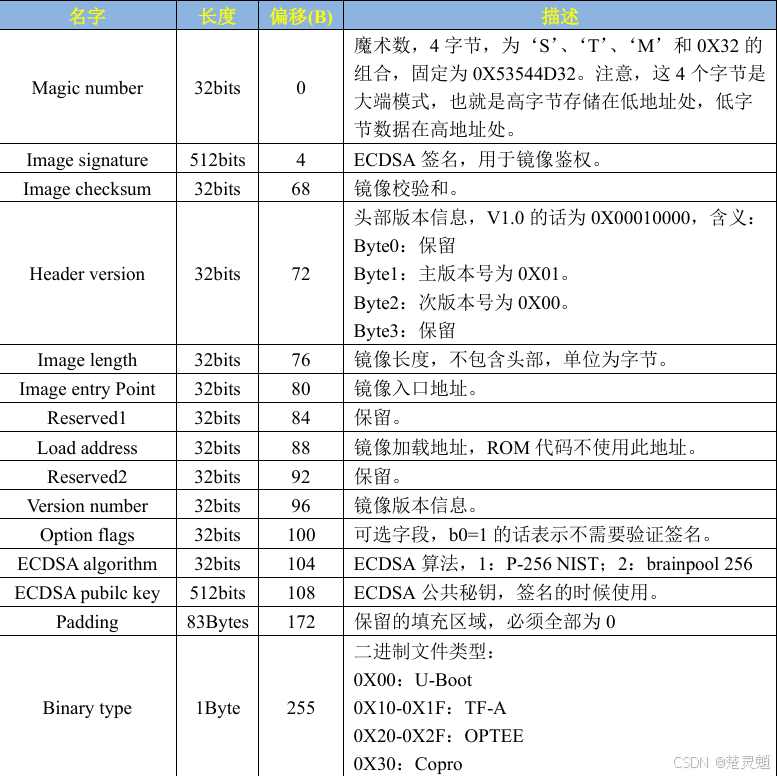
下面就来简单解释一下,名字当然不用多说,就是这一块数据的名字,长度表示这一块数据占用的长度,这里有的用bit为单位,有的用字节为单位。bit为单位要换算为字节的话需要除以8。就拿第一个“Magic number”来举例,它占用了32个bit,除以8也就是4个字节。也就是说这些数据占用了4个字节。然后是偏移地址,这里的偏移地址是相较于0地址的偏移。偏移的基础也是从0开始。
下面我们再来看看,头部存储的数据与真实的文件是否对应,这里我们需要安装一款名为“winhex”的软件,它用于查看二进制信息。它的安装包被放在了正点原子资料文件夹下的“03、软件”文件夹下:
这里软件的安装比较简单,大家自行安装即可。
安装好以后,我们将正点原子编译的TF-A拖进去即可。它被放在了正点原子资料文件夹下的“08、系统镜像\02、出厂系统镜像\01、STM32CubeProg烧录固件包\tf-a”文件夹下这里注意,这是一个名为“tf-a-stm32mp157d-atk-trusted.stm32”的文件:
我们将其拖入winhex以后,就能看到一堆十六进制的字符了。下面我们来解析一下,我们首先来看“Magic number”。这里要结合一下表格中的描述:


首先,它的偏移地址是0表示这段数据没有偏移就是从0地址开始存放的。然后再描述中,它有一个固定值,并且值为“0X53544D32”并且使用的大端模式进行存储,这里的大端模式就表示在存储时将高字节存放在低内存中。我们同样拿“0X53544D32”来举例。所谓的高字节就是高位字节。那么什么是高位呢?举个简单的例子,假如我们有一个数名为“114514”我们将其读作“十一万四千五百一十四”,这个数中,十一万肯定就是这个数的高位,最后面的14可定就是这个数的低位。嗯?你问我为什么?我也不知道,小学数学中就规定了,左边的是高位。换算成十六进制也一样,就像“0X53544D32”这个数,它的53就是高位,32就是它的最低位。我们了解了什么是高位,那么什么又是高字节放在低内存中呢?我们结合winhex的解析来看,既然“Magic number”没有偏移,那么我们就直接从文件的起始去找这个文件,我们可以看到这里的数据和表格中描述的完全吻合:

这里的内存,从左往右是依次增大的,最左边的内存地址为0的内存,然后向右边一个是地址为1的内存。以此类推。我们可以看到,内存的最低位也就是“0X00”的内存存放了53,而53又是“0X53544D32”的最高位,这就是所谓的高字节放在低内存中。下面我们再来看一个例子,这里我们使用“Header version”来举例:

可以看到它的偏移地址为72,也就是说,我们要找这段数据的话,需要去地址为72的地方去。这里我已经在winhex框出了这段数据的位置。它同样是32bit的,所以字节数是4:

在除了“Magic number”以外的数据中,都是采用小端模式进行数据存储的。所谓小端模式,就是将高字节存放在高内存中。这里只要学会了大端模式,理解小端模式也不是什么大问题。这里我们可以看看上面的数据这里我们的地址72,73,74,75对应的数据分别的00,00,01,00。根据小端模式的规则,高字节存放在高内存中,所以,这段数据的最高位就应该是75内存中的数据也就是00,其次是01,再就是00和00,我们将整段数据拼凑出来,就可以得到“00010000”这一段数了根据表格中的解析我们就可以得知,这里的版本号为01。
我们对STM32MP157FSBL的头部信息的讲解就到这里,正点原子对头部中的每一个数据块都进行了解析,大家可以自行查看。
5.STM32MP157 Linux的启动流程
说了上面那么多,最终我们要回到一个问题上,做上面的一切都是为了启动Linux,那,在STM32MP157上Linux究竟是如何启动的呢?
下面我们同样使用一张流程框图来解释Linux在MP157上是如何启动的:
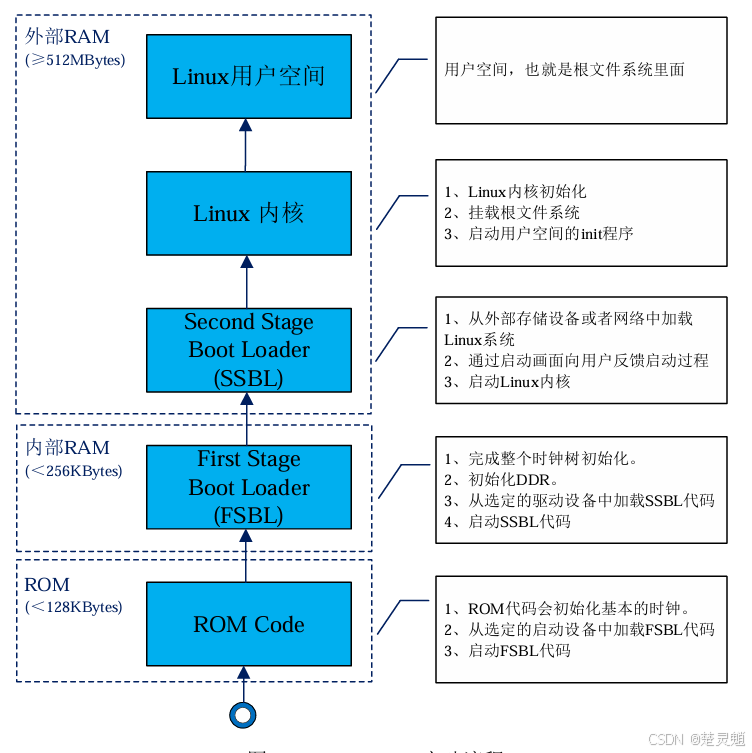
这张框图我们需要从下面往上看,首先,芯片上电时,会启动在STM32MP157内部ROM的代码,之前也提到了这段代码是用于选择从哪个外部存储设备中读取代码和启动FSBL的。当这段代码结束并且对FSBL进行鉴权以后,FSBL就启动了。在FSBL中会完成一些初始化并且鉴权与加载SSBL。在SSBL部分,我们往往会存放uboot等引导固件来启动Linux内核。当SSBL结束以后,我们的Linux就启动起来了。在Linux中会加载用户空间的init程序,最后启动用户空间,这样我们的Linux就启动完成并且可以供用户进行操作了。当然,上面的步骤听起来困难实则一点也不简单。Linux启动的细节远比上面描述的复杂得多。
五、TF-A的移植
之前也提到了在FSBL中我们需要加载一个名为TF-A的固件,TF-A是ARM推出用于芯片安全的软件。正点原子在此处也没有做过多的解释。所以我们这里也不进行研究,只讲解如何移植。下面就让我们一起来看看如何移植TF-A吧!
1.编译正点原子的TF-A代码
这里首先还是带大家找一下正点原子的TF-A代码存放的位置。它被放在了正点原子资料文件夹下的“01、程序源码\01、正点原子Linux出厂系统源码”文件夹下:
这里我们用FTP将其拷贝到Linux目录下,文件传输已经在环境搭建时讲了很多次了这里就不多赘述了。
这里还是建议大家在linux文件夹下新建一个文件夹来存放正点原子的“TF-A”源码:

源码拷贝过来以后,我们还需要安装一个名为“stm32wrapper4dbg”的工具,它会在TF-A源码被编译时调用到。
stm32wrapper4dbg的源码被存放到了正点原子资料目录下的“05、开发工具\02、ST官方开发工具”文件夹下:
我们同样用FTP将其上传到Ubuntu中,这里上传的位置大家自己决定即可:

我们使用下面的命令来解压“stm32wrapper4dbg”的源码:
unzip stm32wrapper4dbg-master.zip解压完成以后,就得到了一个名为“stm32wrapper4dbg-master”的文件夹:
我们进入这个文件夹,可以看到以下文件:

这里我们直接输入make并且回车:

看到有一行输出就说明编译已经完成了。没错这里就只有一行输出。随后,我们用下面的命令将编译完成的文件拷贝到指定目录,这个目录被添加到了环境变量中,可以让工具在随时随地被调用:
sudo cp stm32wrapper4dbg /usr/bin将文教拷贝到指定目录以后,我们输入下面的命令,如果出现如图所示的输出就表示这个工具已经安装完成了:
stm32wrapper4dbg -s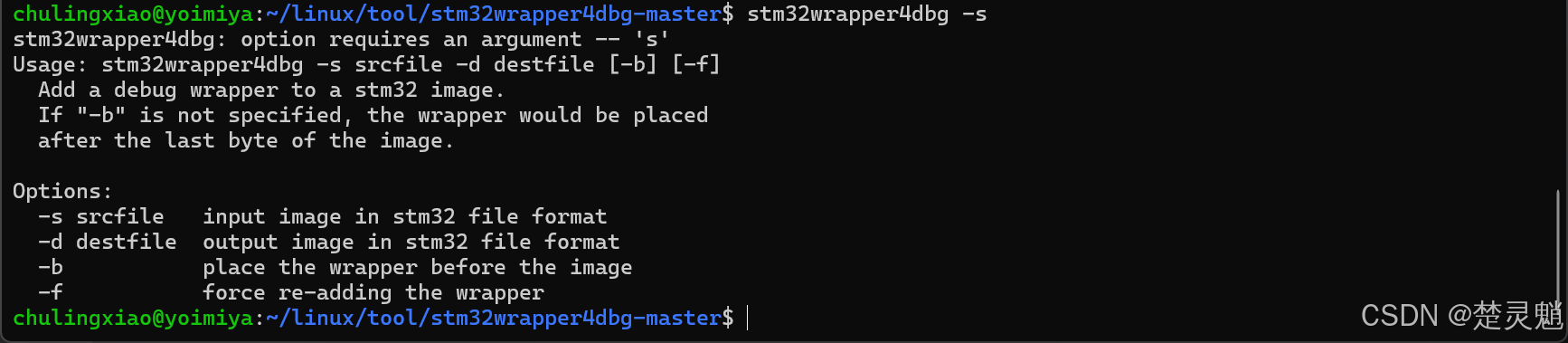
我们还需要安装一个设备树相关的工具,直接使用下面的命令:
sudo apt-get install device-tree-compiler当我们安装好上面的工具以后,就可以开始编译正点原子的TF-A源码了,我们使用下面的命令将正点原子的TF-A源码解压:
tat xvf tf-a-stm32mp-2.2.r1-gaa9f87c-v1.5.tar.bz2解压以后,我们得到了一个文件和文件夹:

这里的“Makefile.sdk”是用来指导编译的makefile文件,这里的“tf-a-stm32mp-2.2.r1”文件夹存放的是TF-A的源代码。我们首先要修改一下“Makefile.sdk”这个文件,使用下面的命令打开文件:
nano Makefile.sdk这里我们需要将“Makefile.sdk”文件中的“arm-ostl-linux-gnueabi-”修改为“arm-none-linux-gnueabihf-”,因为“arm-none-linux-gnueabihf-”才是我们一开始在环境配置中配置的编译器,修改完成以后,就如图所示:
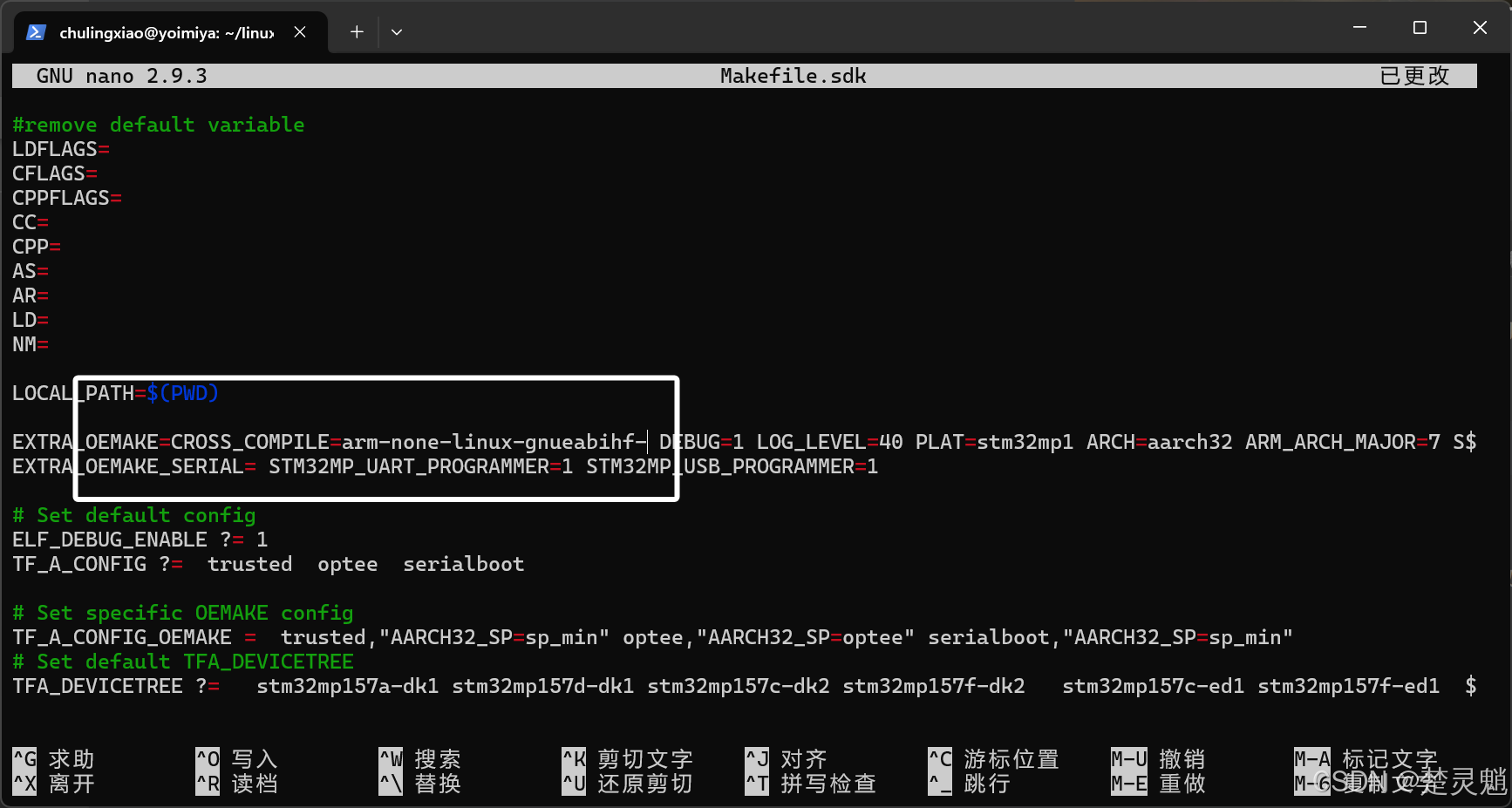
修改完文件以后,我们使用下面的命令切换到源码目录:
cd tf-a-stm32mp-2.2.r1/
随后,我们可以使用下面的命令对这些代码进行编译:
make -f ../Makefile.sdk all这里的-f表示自定义makefile文件,后面的all表示编译所有。如果想要编译快一点可以加一个-j的参数用来多线程编译,假如想使用12个CPU核心进行编译,只需要加上“-j12”即可这个大家就根据自己的情况来修改了。
没有出现别的什么错误的话,编译就完成了。如果出现错误,请首先查看Makefile.sdk有没有修改对,在终端中试一试自己的编译器有没有配置好,还要查看自己是否在源码目录下进行的编译,注意这里必须是源码目录。
编译好以后,在原本我们解压的目录下会多出一个"build"的文件夹,这个文件夹里面就是我们编译得到的文件:

我们进入这个build文件夹可以看到三个文件夹:

这里的optee是一个用于安全的系统的文件夹,serialboot很明显是和串口启动有关的文件夹,后面的TF-A的启动也需要使用serialboot来辅助。最后的trusted文件夹就是我们编译好的TF-A的二进制文件夹了,我们可以进去看看:

我们可以看到,这里有非常多的文件,每一个开发板都拥有“.ld”,“.map”,“.stm32”,“-trusted.stm32”这几种后缀的文件。这里我们主要会用到“-trusted.stm32”的文件。在这些开发板中,我们可以找到正点原子的开发板所对应的文件,是名为“tf-a-stm32mp157d-atk-trusted.stm32”的文件:
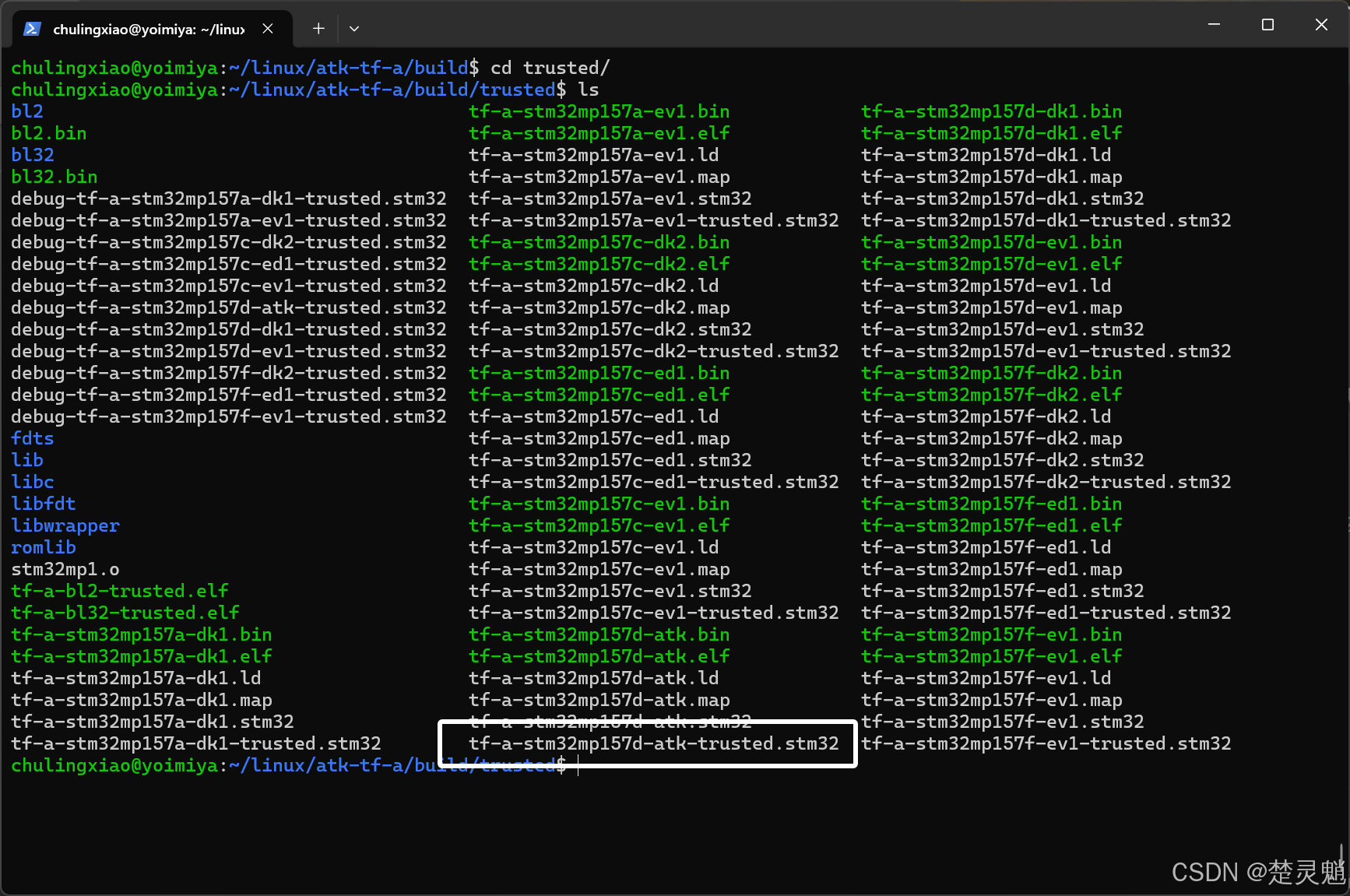
至此,我们编译正点原子官方代码就已经完成了。
2.烧录正点原子的TF-A固件
当我们编译好TF-A以后,可以烧录到开发板中测试一下,因为是正点原子官方的代码编译出来的TF-A固件所以说,直接烧录到开发板中是不会有任何问题的。在烧录之前,我们需要做一些准备,这里需要大家新建一个文件夹,建在什么地方都行,但是最好不要有中文路径,这里我为了方便就放在桌面了:

我们再使用FTP将我们编译好的“tf-a-stm32mp157d-atk-trusted.stm32”文件拷贝到我们创建的文件夹中:
当我们将TF-A的源码拷贝过来以后。我们还需要安装一个软件“STM32CubeProgrammer”,它的安装包被放在了正点原子资料目录下的“05、开发工具\02、ST官方开发工具”文件夹下:
这里的软件安装比较简单,大家自行安装即可。
安装好了以后,我们先不着急打开软件,还需要准备一些文件我们的TF-A才能被烧录。
这里我们打开正点原子资料目录下的“08、系统镜像\02、出厂系统镜像\01、STM32CubeProg烧录固件包”文件夹:
我们进入TF-A文件夹,将“tf-a-stm32mp157d-atk-serialboot.stm32”复制到一开始我们存放TF-A的文件夹中:
这里要注意的是,一定要用正点原子已经编译好的,如果将Ubuntu中自己编译的复制过来会出现奇怪的问题。
然后我们再回到上级目录,找到一个名为“uboot”的目录:
进入这个目录中,将这个目录的文件“u-boot.stm32”复制到我们创建的目录中:
这样,我们基础的文件就已经准备好了。有的小伙伴可能会疑惑,不是在移植TF-A吗?为什么还需要用到uboot?这个我们稍后会解释。而这里的“tf-a-stm32mp157d-atk-serialboot.stm32”文件是为了辅助TF-A烧录的。
下面我们还需要写一个“STM32CubeProgrammer”的脚本文件,这个文件会告诉“STM32CubeProgrammer”如何烧录代码。下面我们就来编写一下这个文件吧!在编写文件之前,我们还需要安装一个文本编辑软件——“Notepad++”,这也是为了我们更好的阅读脚本文件。小伙伴们可以前往“Notepad++开源地址”下载软件:
Notepad++开源主页:notepad-plus-plus/notepad-plus-plus: Notepad++ official repository
因为安装比较简单,所以这里就不过多讲述了。安装好以后,我们可以在我们刚才存放TF-A的文件夹中新建一个“tf-a.tsv”的文件:
这里大家应该能想到了,以tsv为后缀的文件,就是“STM32CubeProgrammer”的脚本文件。那么,这个文件应该怎么写呢?
我们可以打开一份正点原子已经写好的来作为参考,正点原子已经写好的文件被放在了正点原子资料目录下的“08、系统镜像\02、出厂系统镜像\01、STM32CubeProg烧录固件包\flashlayout”文件夹下:
我们可以看到,这里有sd卡和emmc两种版本的,因为我们使用的是emmc,所以直接打开emmc版的,我们右键,使用Notepad++打开:

打开以后,就能看到这样格式的文件了:
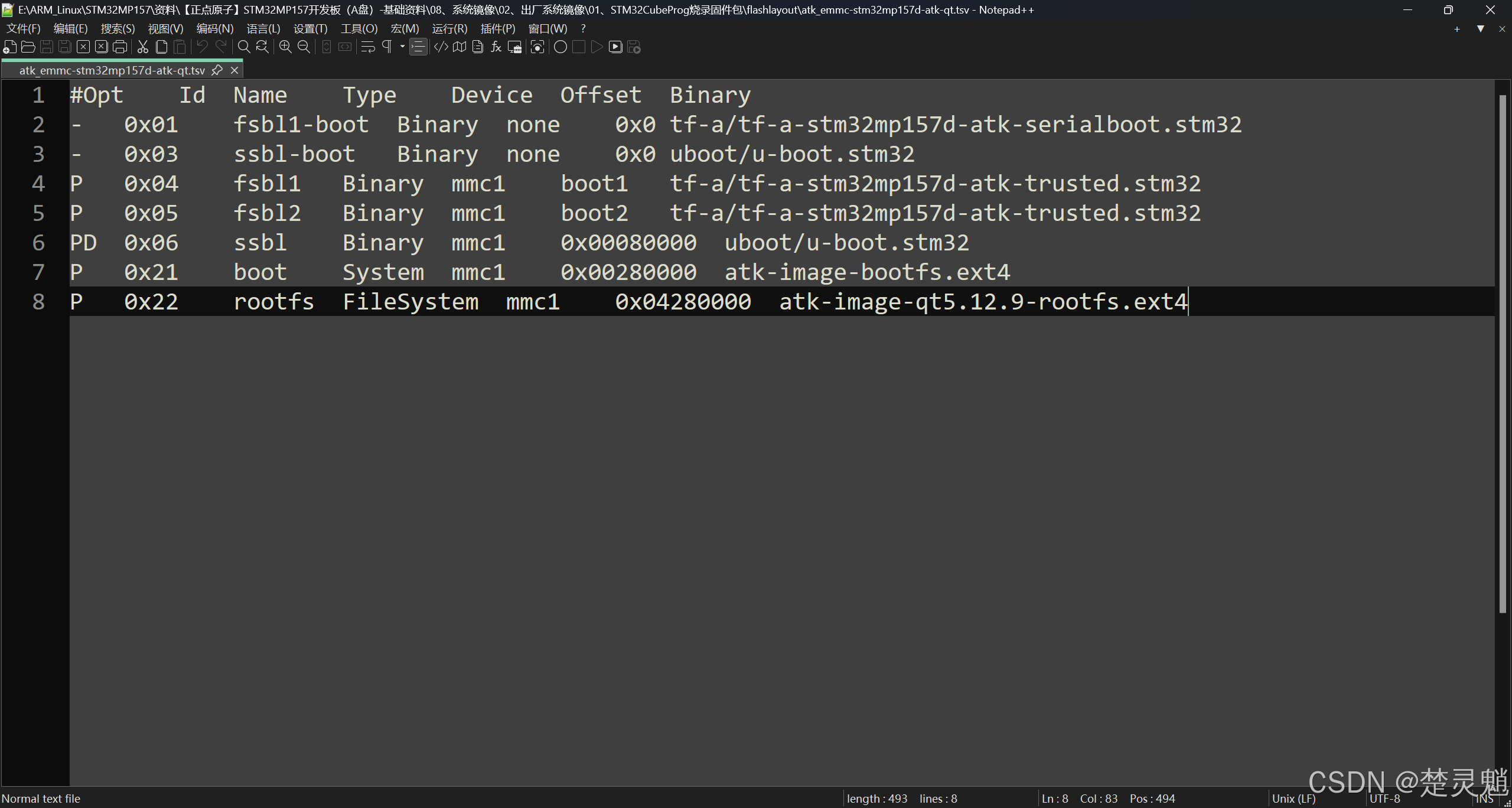
我们点击“视图”再点击“显示符号”然后选择“显示空格与制表符”:
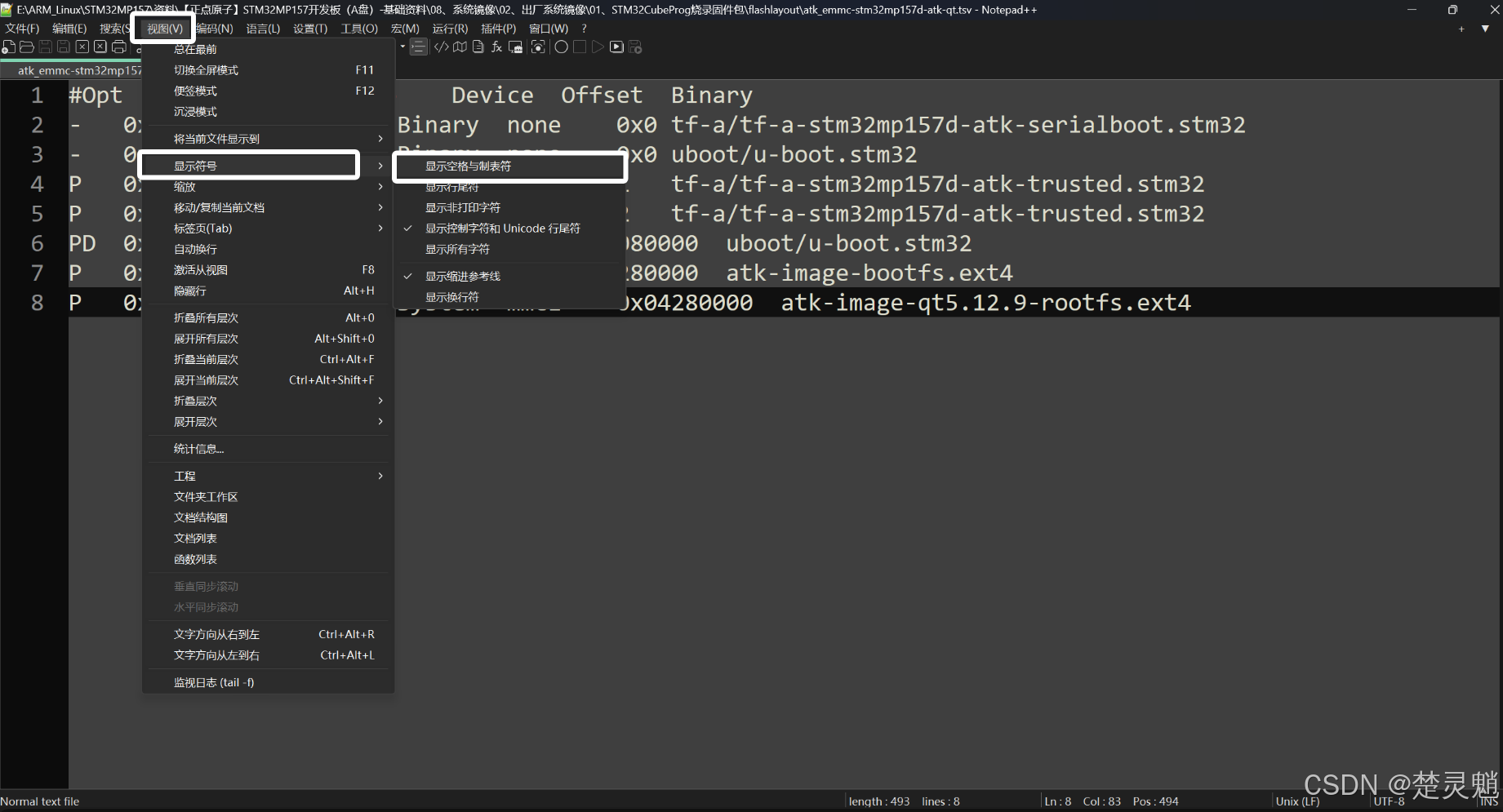
配置完这些以后,我们就能看到,我们的文字与文字之间多了许多的箭头:
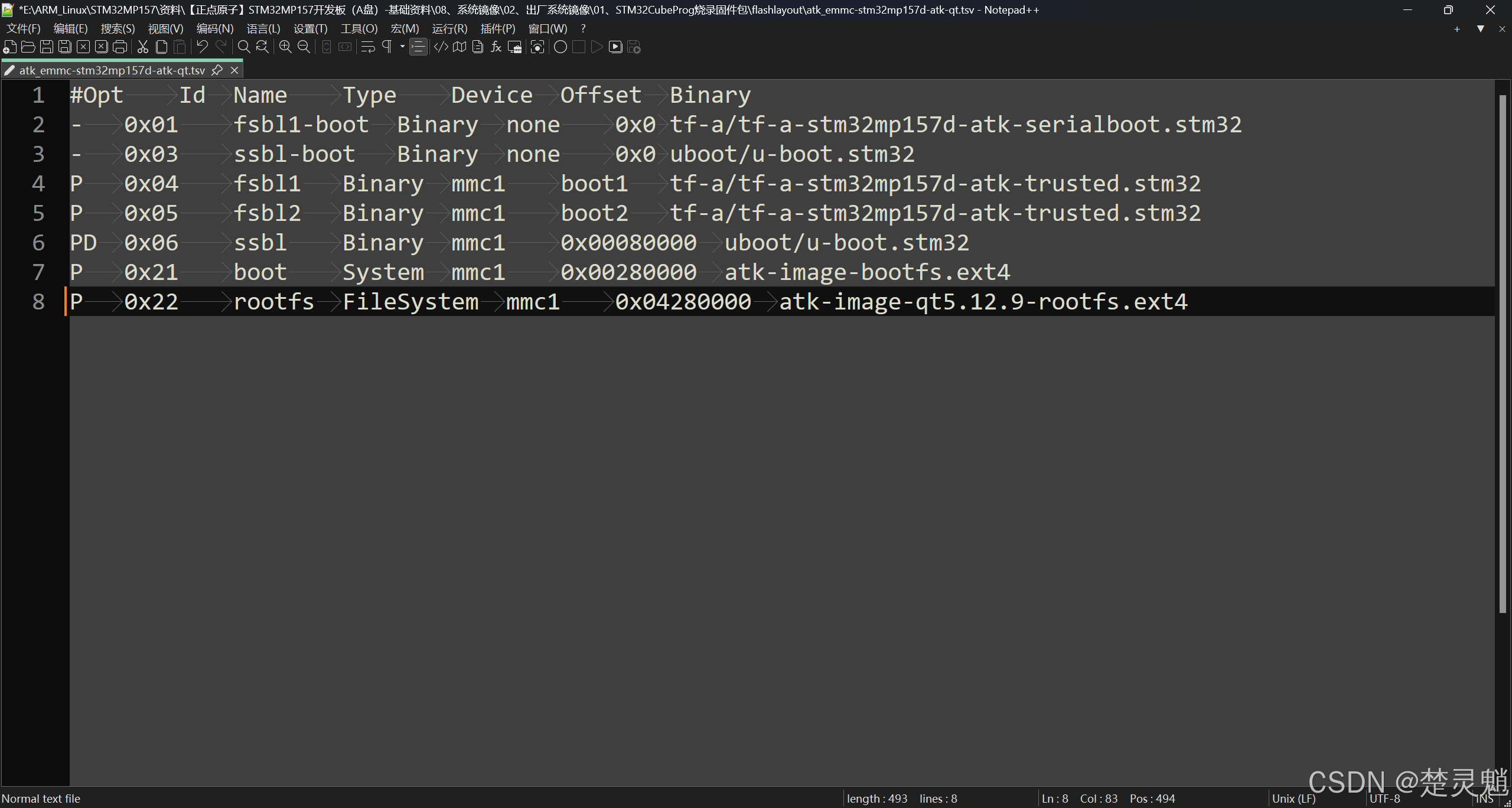
这些箭头就是制表符,我们按一下“TAB”键就能打出一个制表符。在“STM32CubeProgrammer”的脚本文件中,就是使用制表符来分隔字符与字符的。注意,这里说的是制表符,不是空格,如果STM32CubeProgrammer识别到空格就会报错。
下面我们来解析这个文件,为了方便解析,我们将文件中的格式整理一下,以便我们查看,顺带一提,因为是使用制表符来分隔字符,所以,不管中间有多少个制表符都可以,整理以后文件就变成了这样: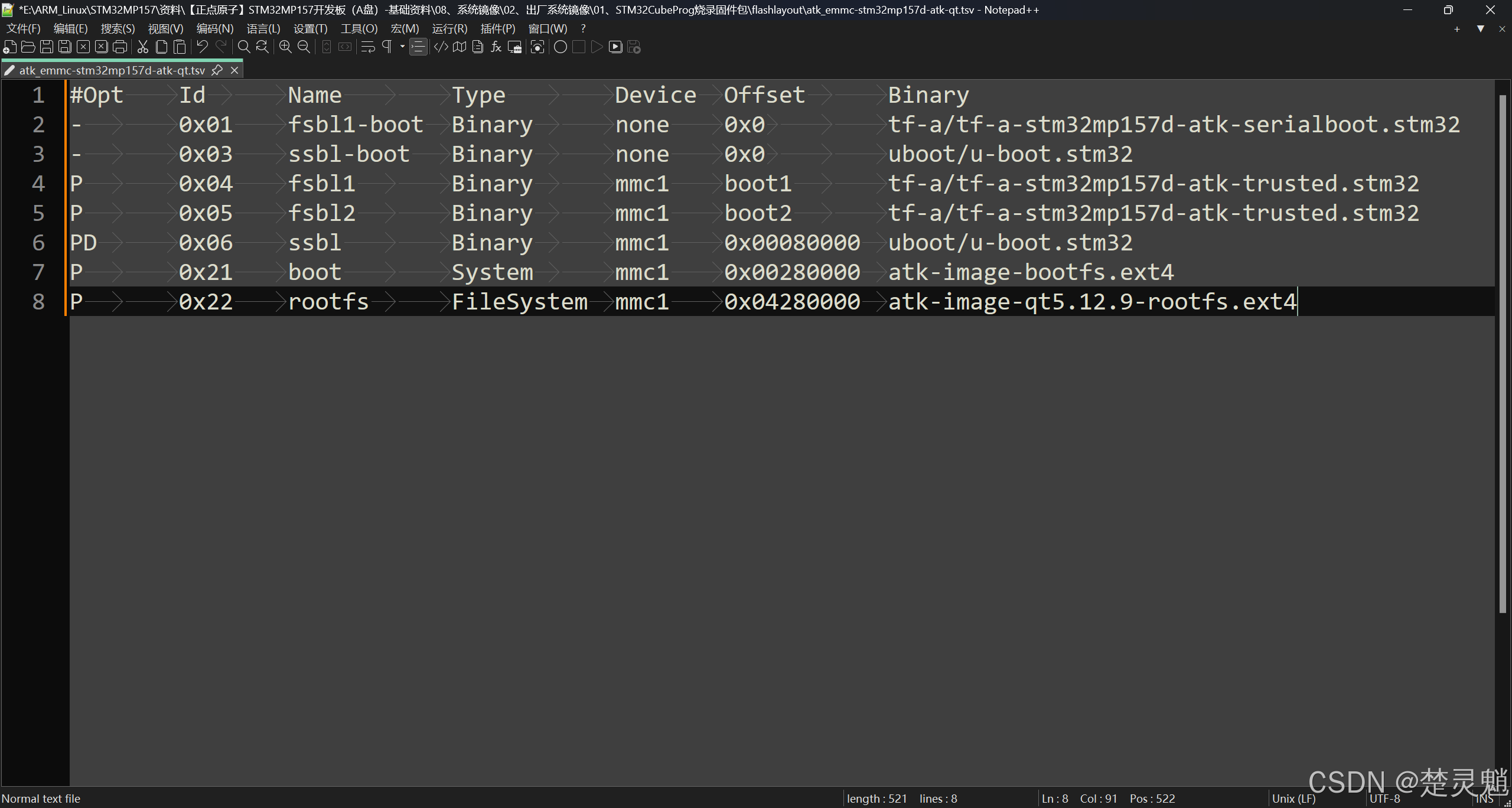
这样看起来是不是整齐多了,我们就可以很清楚的看到,这个文件一共有7列,这7列的含义分别如下:

这里需要注意,我们文件中,第一行开头有一个#号,表示这一行是一行注释,真正的文件从第二行开始,第一行的意义也是为了便于我们编写文件。这里对文件的解释在正点原子的资料中已经写得很详细了,这里就不多说了。我们主要解释一下为什么需要在一开始就加载uboot。我们可以看到第三行的id部分,这是和uboot有关的,这里的id为0x03表示将uboot加载到了RAM中运行。为什么要先将uboot加载到RAM中运行呢?因为STM32CubeProgrammer 本质是通过 uboot 来烧写系统的,也就是先把uboot加载到板子的 RAM 里面并运行,然后使用uboot来烧写系统。uboot 会请求需要烧写的二进制文件,然后将其烧写到指定的分区或者Falsh设备里面。明白了这些以后,我们就可以开始写脚本文件了。这里我们可以直接将正点原子的脚本文件复制到我们的文件中然后再进行一些修改,这里记得是复制到我们的文件中,而不是在正点原子原有的文件上进行修改。将正点原子的文件复制过来就是这样了:
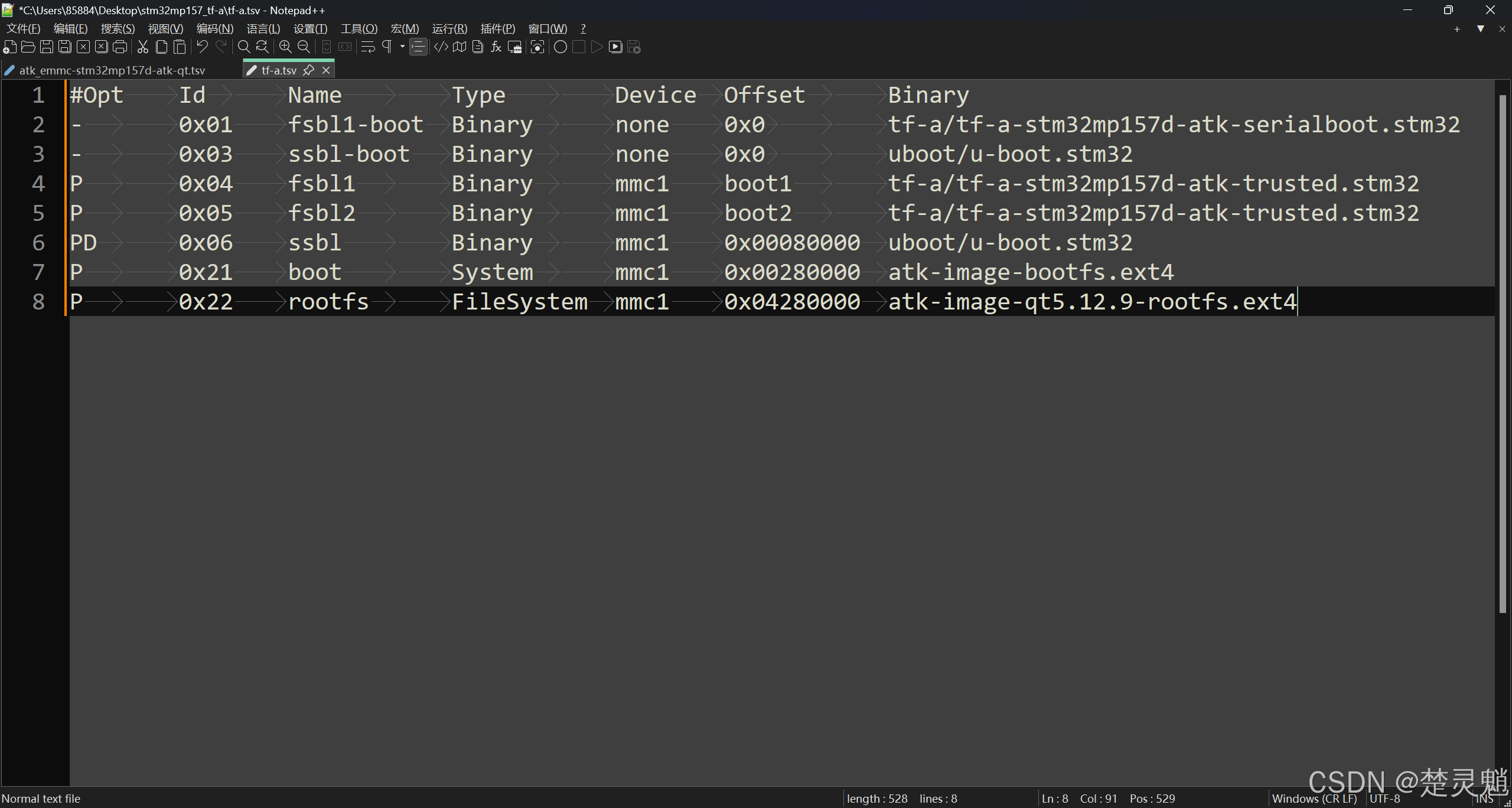
我们这里需要将最后三行删掉,因为我们只需要烧写TF-A,而从第6行开始,就是uboot和系统内核部分了,删掉以后,得到以下:

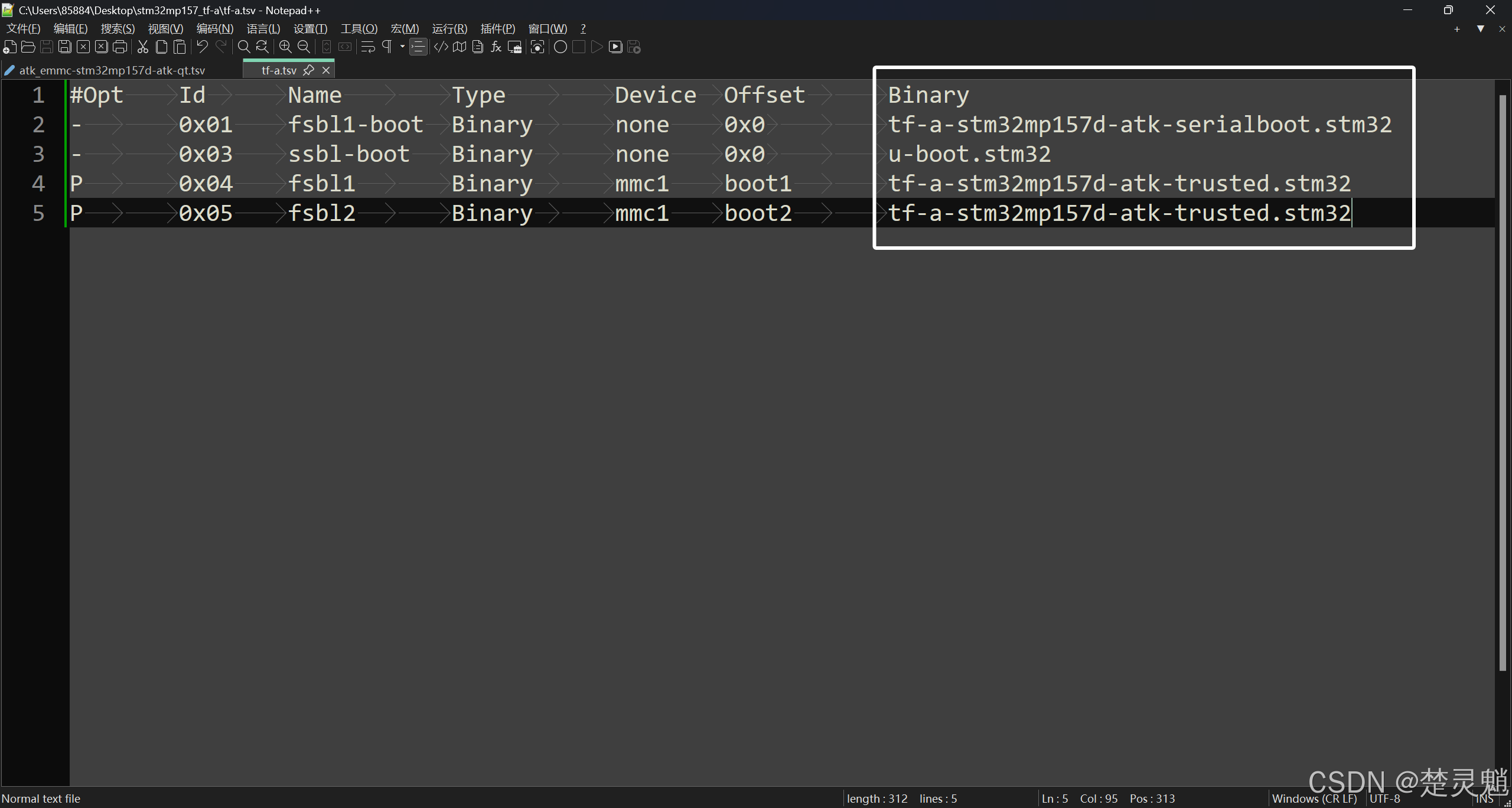
这里我们还需要修改一下每一行的Binary,因为我们的文件就在当前的文件夹中所以并不需要对路径进行特殊处理,修改完以后,就是这样了:
这样,我们的脚本文件就已经写好了,可以准备烧录了,我们打开STM32CubeProgrammer软件,并且将STM32MP157开发板的USB接口用数据线连接到电脑上,并且大家再为开发板选择一个供电,我这里因为只有一根USB线,我就选择使用12VDC口供电了链接好以后就如图:  然后,我们需要将拨码拨到000表示从USB启动:
然后,我们需要将拨码拨到000表示从USB启动:

然后我们在“STM32CubeProgrammer”中选择USB:
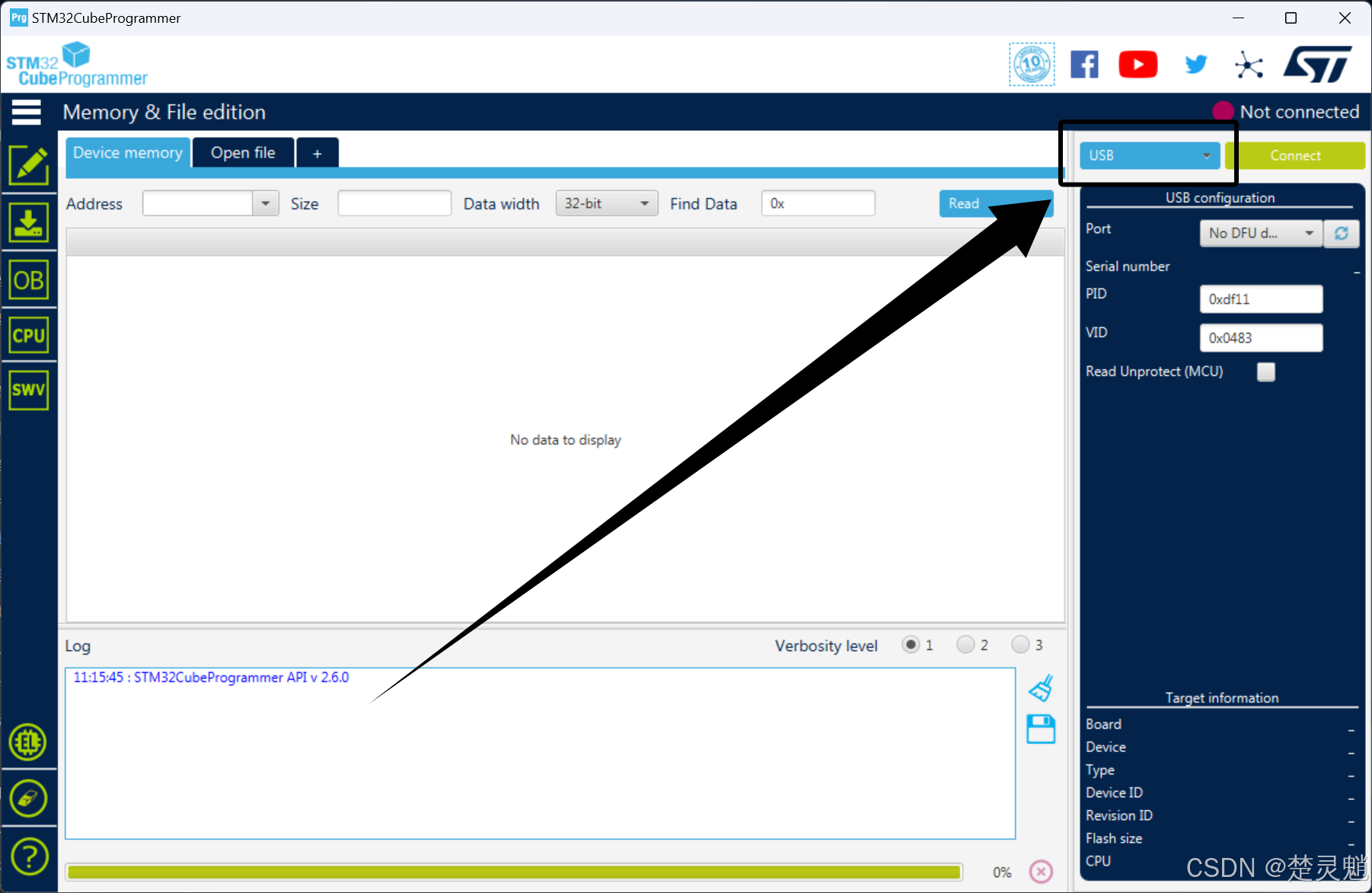
点击这里刷新可以刷新USB设备,如果识别不到USB设备可以考虑看看USB有没有正确连接,拨码是否被拨到000,检查以上以后还不行的话,可以先按下板子的复位键再刷新USB设备。USB设备识别到以后,会出现USB的ID号:
我们点击“Connect”连接到设备:
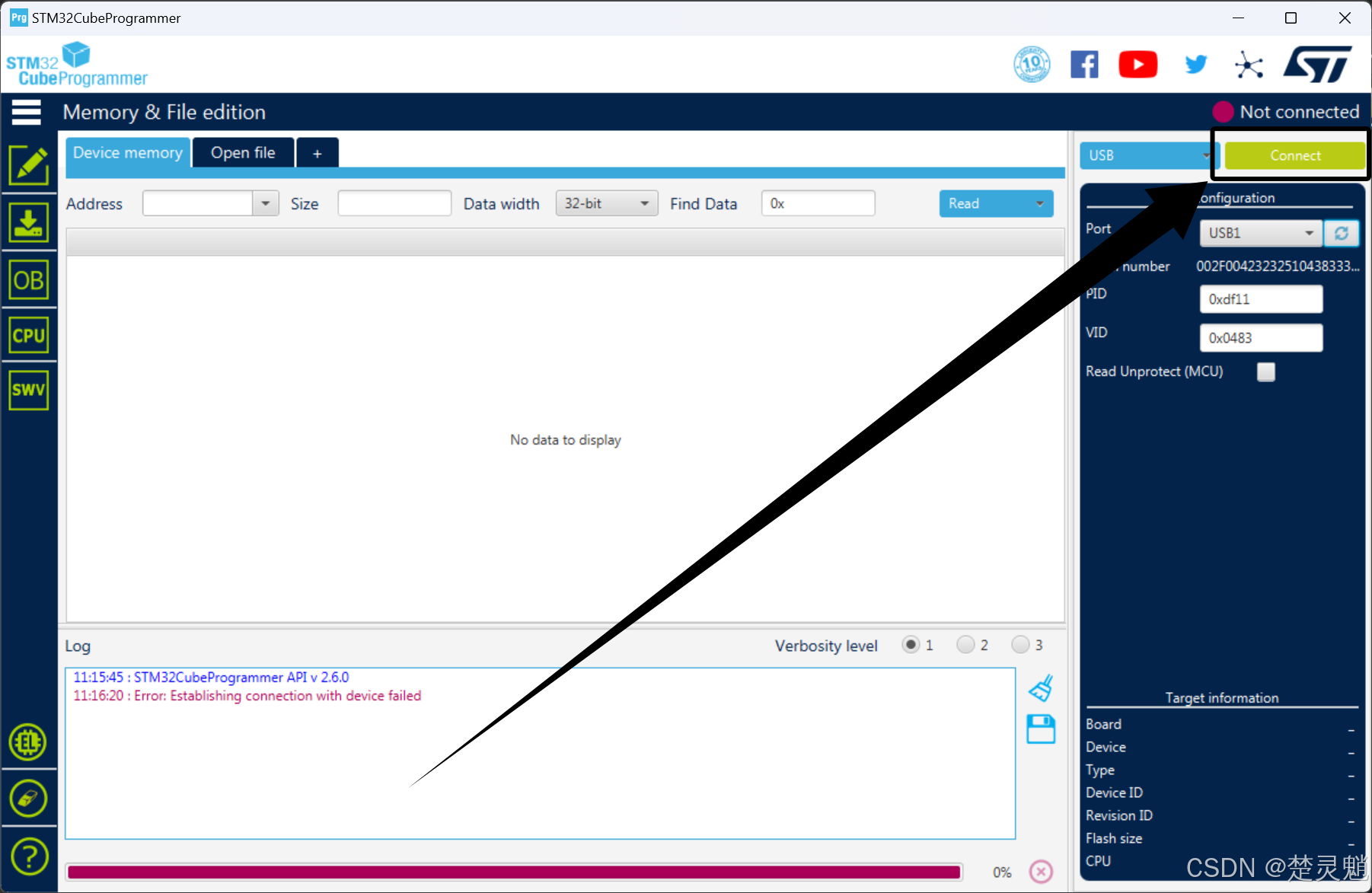
连接以后,我们就可以看到设备的分区了,下方的日志中,也可以看到连接的相关信息:
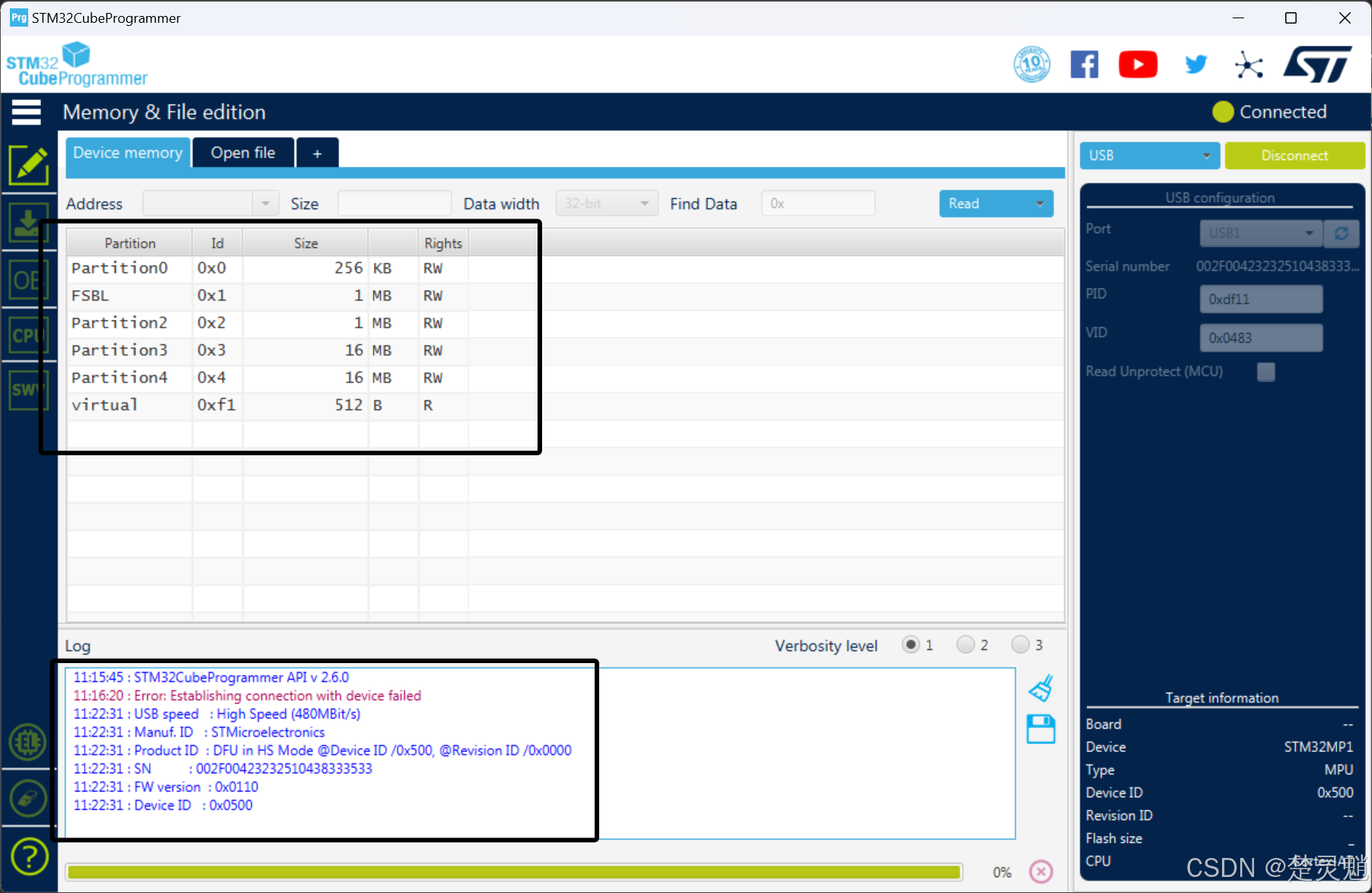
下面我们再点击“Open File”表示打开一个脚本文件:
我们将我们编写好的脚本文件加载进来,如图:

这里加载进来以后,我们再选择一下下方的路径,防止找不到文件,我们将路径选择到我们存放文件的目录即可:
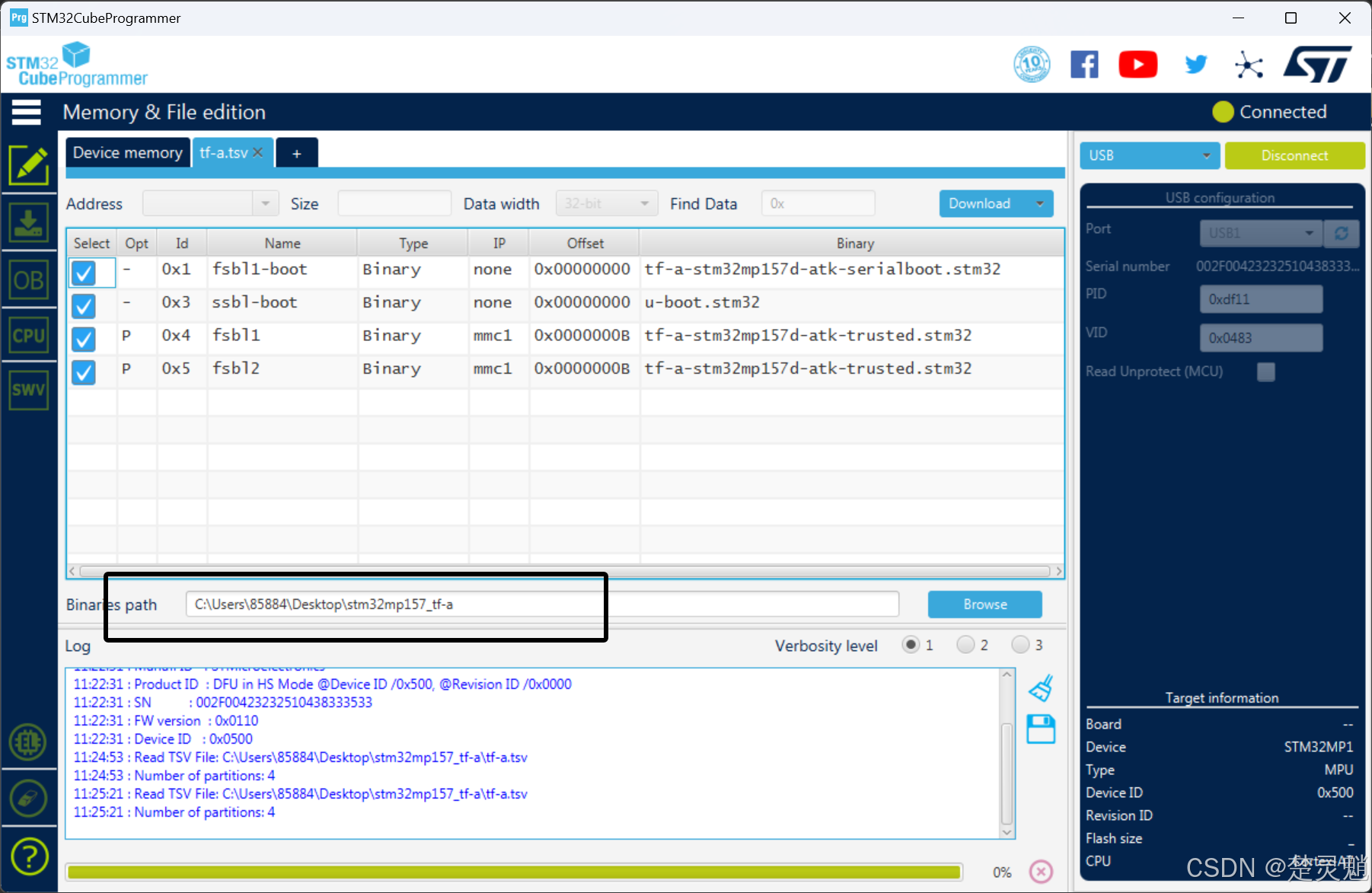
确定好这一切没有问题以后,我们就可以点击右上角的Download了:
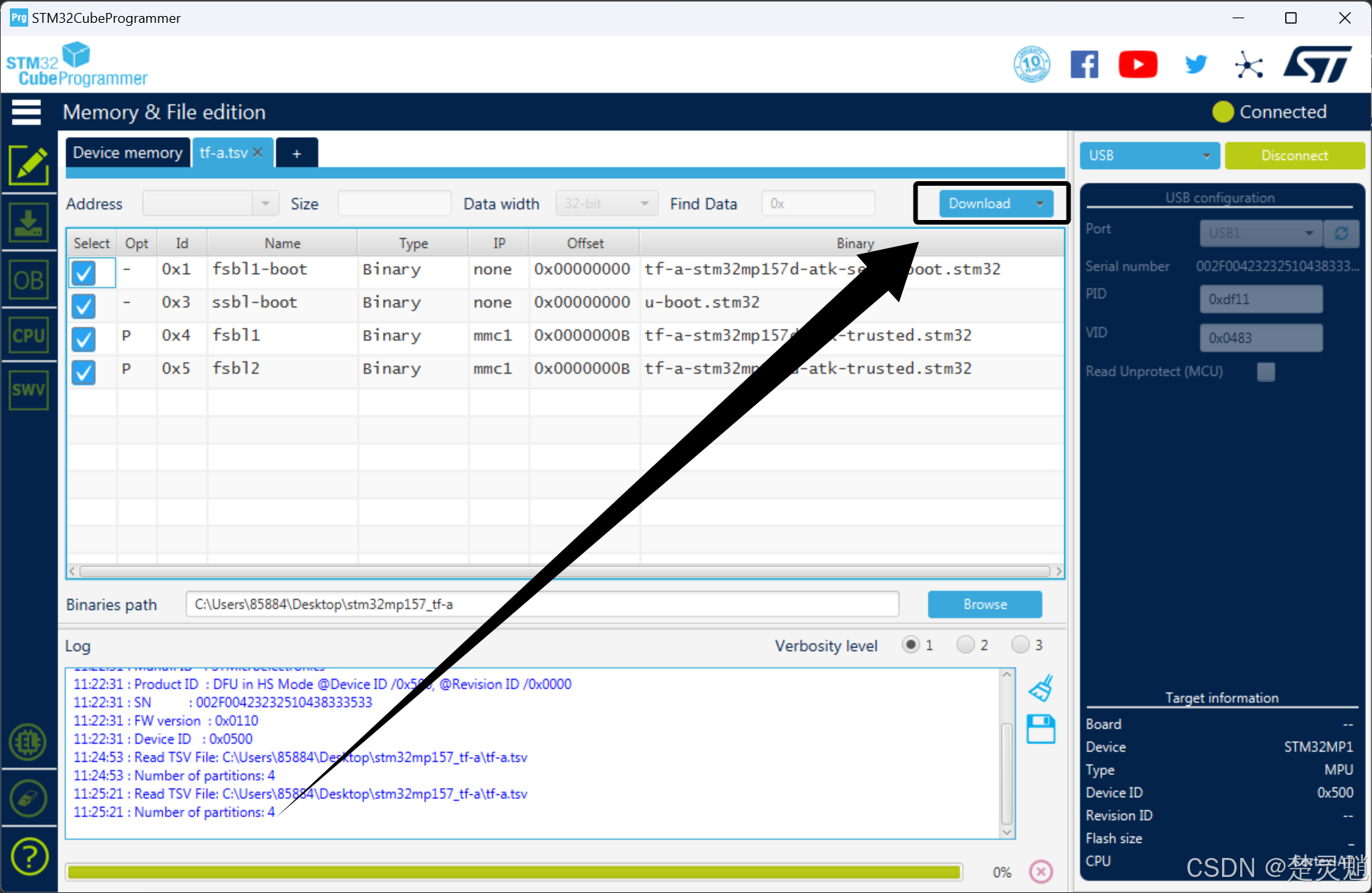
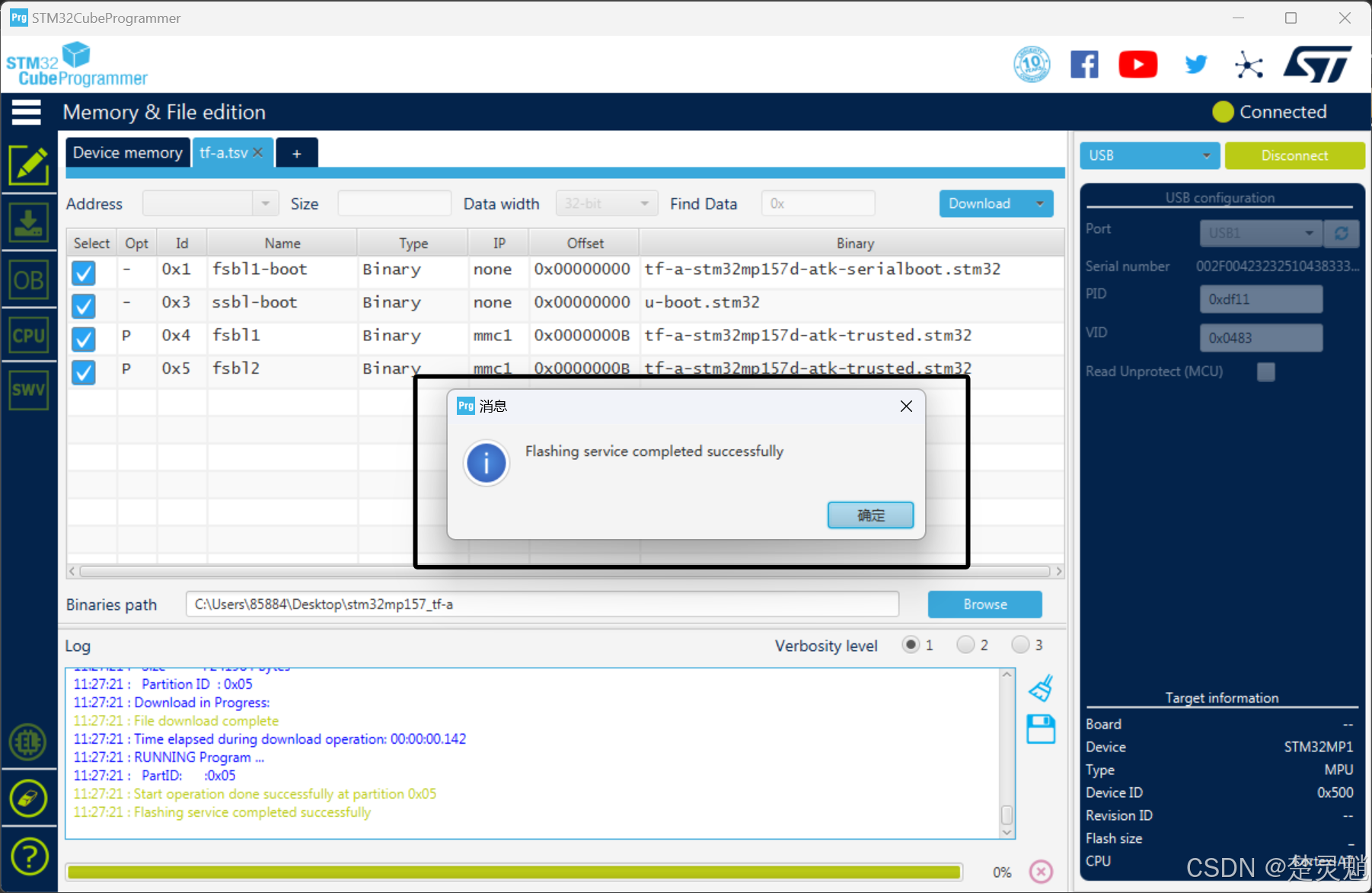
下载完以后,会出现一个这样的提示告诉我们已经下载完成了:
下面,我们需要使用一个串口终端的工具来查看我们的烧写是否成功,这里我使用的是“WindTerm”一款开源的串口工具,开源主页如下:
WindTerm开源主页:kingToolbox/WindTerm: A professional cross-platform SSH/Sftp/Shell/Telnet/Tmux/Serial terminal.
正点原子推荐的工具被放在了正点原子资料目录下的“03、软件”名为“MobaXterm”的软件:

这里软件安装大家自己安装即可,这些软件的安装步骤都不是特别的繁琐。
大家选择好自己喜欢的串口终端工具并打开,我下面会使用WindTerm进行演示,软件启动以后如图:

我们下面要将拨码拨到010表示从EMMC启动,并且将开发板的串口连接到电脑,如图:

随后,我们在串口终端的软件中配置串口波特率为115200,创建一个连接:
如果大家这里无法连接,甚至找不到串口,可以考虑看看CH340的驱动有没有正确安装。
然后,我们按下开发板的复位键,就能看到以下输出信息了:
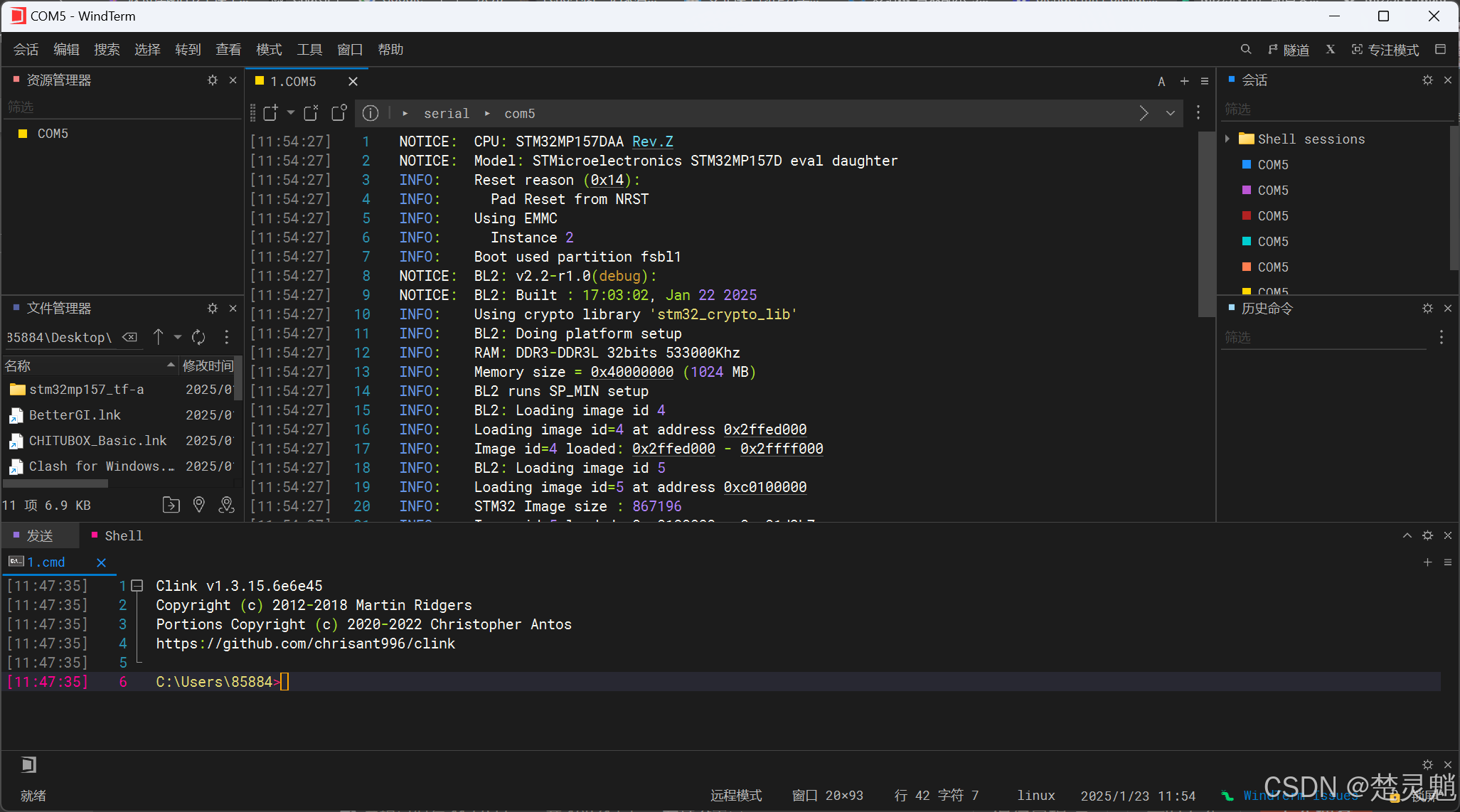
往下翻,我们可以看到,我们的uboot都已经启动起来了,因为我们的开发板中原本就有一套uboot我们改写的只是TF-A分区,所以uboot同样可以启动起来:
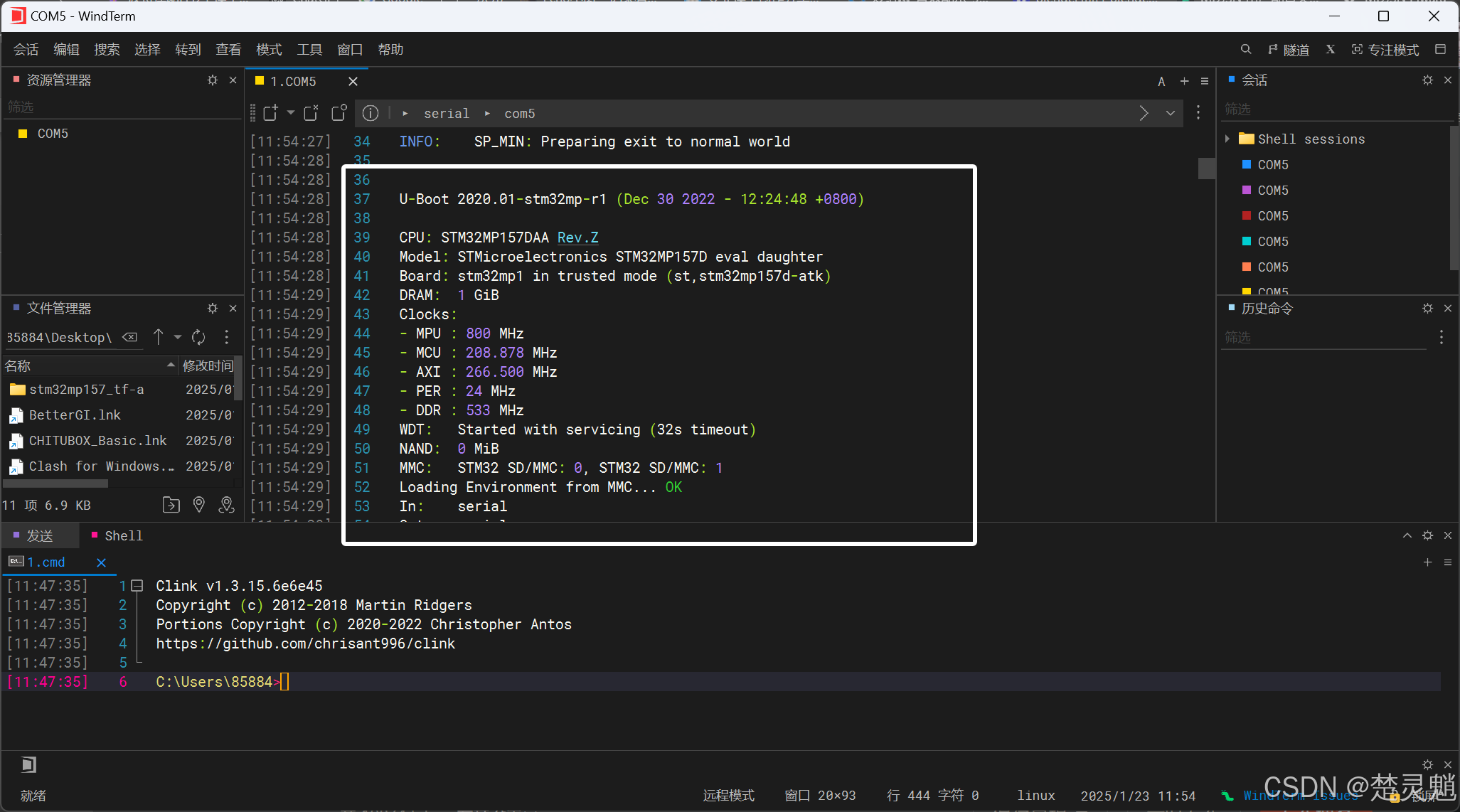
我们再次回到最开始的地方,TF-A在启动时,会告诉我们编译的时间:
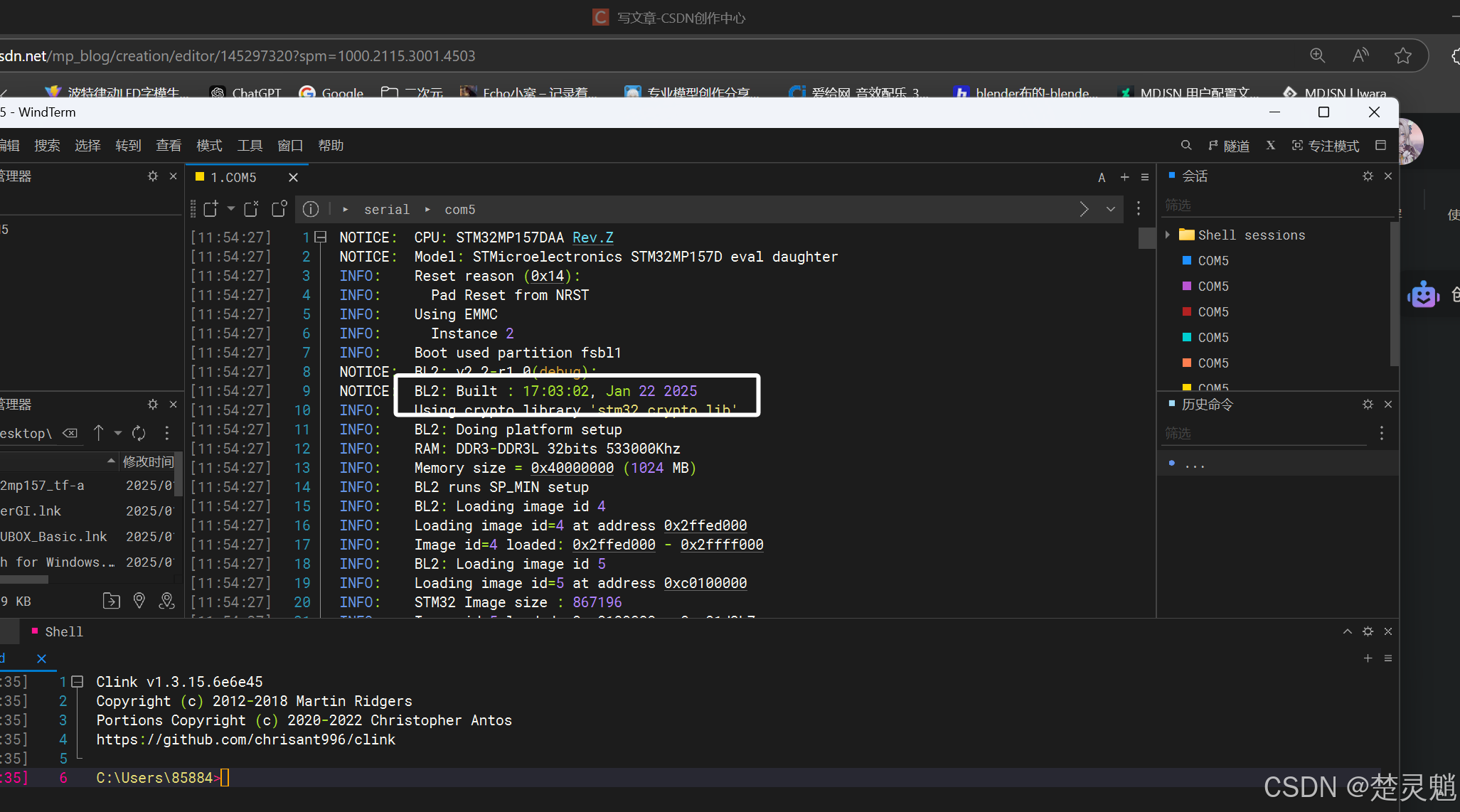
如果大家这里的编译时间没有改变,可以考虑再烧录一次或者清除原本编译内容重新编译。
至此,我们烧录正点原子官方的TF-A就已经完成了。这样一来,大家对编译和烧录的流程都有了大致的了解,我们后面再有编译或者烧写的部分就不会讲得这么细致了。
3.移植ST官方的TF-A
有的小伙伴可能会有疑问,我们已经可以直接使用正点原子编译好的TF-A,那干嘛还要自己移植呢?其实,在一开始ARM发布了自己TF-A,这个TF-A就是最纯正的。ST使用了ARM的内核制造了芯片,并且为TF-A打上补丁,这样TF-A就能适配自己芯片。当我们编译正点原子的TF-A时,我们可以看到除了正点原子的开发板以外还有一些别的开发板型号:
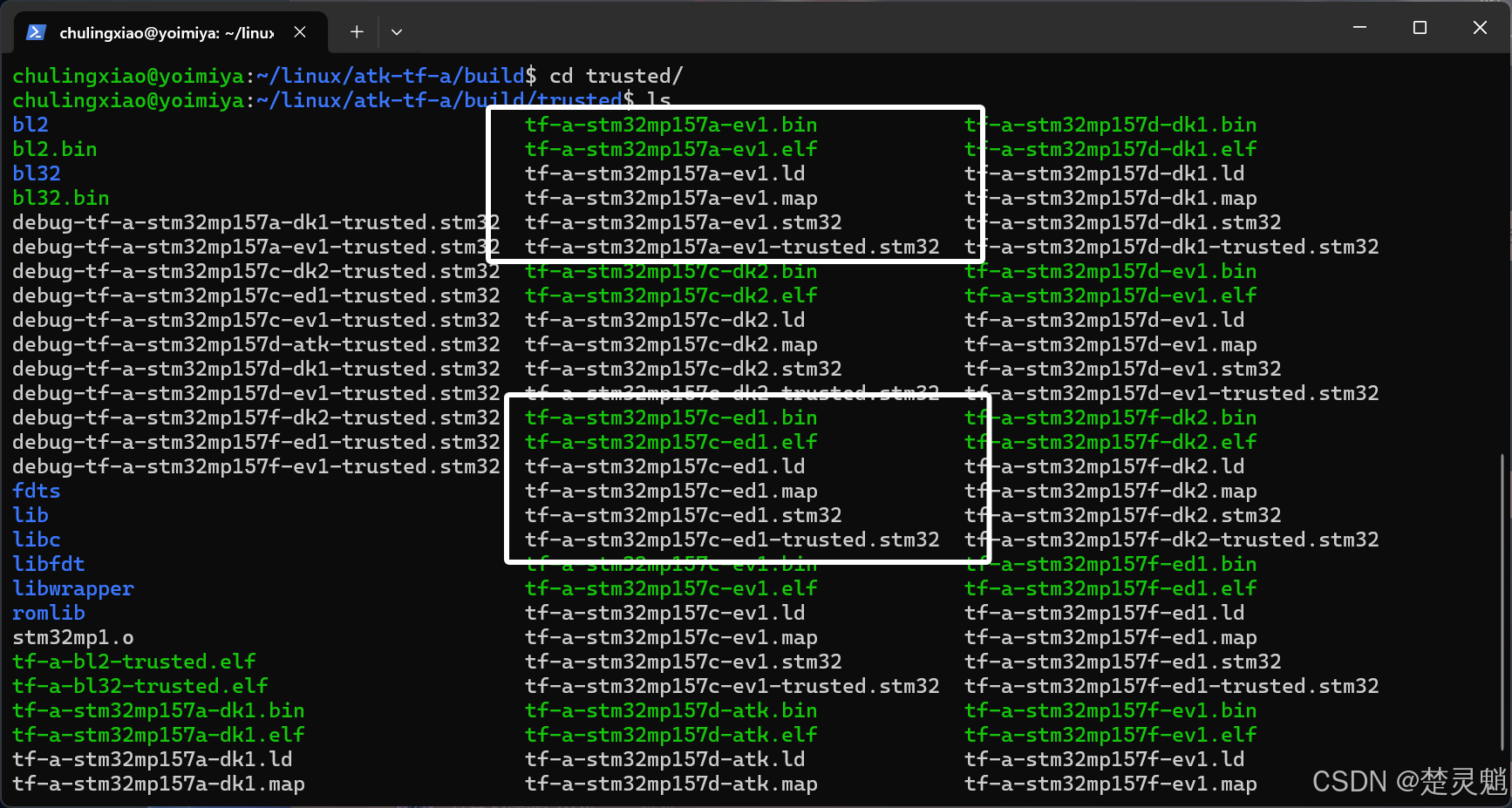
比如,图中被我框出来的ev1和ed1开发板。这些开发板是ST官方的开发板,ST设计出一款芯片以后,会设计一些开发板供开发者们参考并且为这些开发板移植相应的TF-A。在正点原子的代码中,已经将正点原子的开发板添加到了TF-A中,所以我们可以直接使用。如果说我们自己因为各种需要设计了一块开发板,它的外部硬件和正点原子的就会有些许不一样,我们就不能直接使用正点原子的TF-A,而是需要自己根据自己设计的开发板来移植TF-A。当然,因为我们现在只有正点原子的开发板,所以,我们只能在ST发布的原本的TF-A的基础上移植一份正点原子开发板的TF-A作为演示。
当然正点原子本身是非常不建议我们没有学习设备树就来学习移植TF-A,因为在移植的过程中会使用到设备树。但是如果你和我一样,只想感受一下移植的过程,那么就可以跟着我一起操作了。在移植之前正点原子对TF-A的代码目录进行了大量的讲解,现在在这里说起来未免有些过于复杂了,如果你想移植TF-A的话请跟着我操作吧!
我们这里首先将ST官方的TF-A代码放到我们的Ubuntu中,TF-A的源码被放在了正点原子资料目录下的“01、程序源码\05、ST官方原版Linux源码”目录下:
我们同样使用FTP服务将其传输到Linux中:

我们再使用下面的命令将这个源码包解压:
tar -xvf en.SOURCES-stm32mp1-openstlinux-5-4-dunfell-mp1-20-06-24.tar.xz解压以后得到如下文件夹:

这里我们进入“stm32mp1-openstlinux-5.4-dunfell-mp1-20-06-24”文件夹中的“sources/arm-ostl-linux-gnueabi”文件夹下可以看到以下文件夹。这些文件夹里面就是里面就是uboot、optee、tf-a、kernel 源码:

下面有一张这些文件夹对应源码的对照表:

这里用哪个文件已经很明显了那就是tf-a-stm32mp-2.2.r1-r0,tf-a-stm32mp-2.2.r1-r0 支持 ST 所有的 MP1 芯片,也支持各种启动方式,例如:EMMC、 NAND、NOR 、FLASH 等等。tf-a-stm32mp-2.2.r1-r0 里面包含了ST 自家所有的MP1评估板,正点原子的STM32MP157开发板参考了ST官方的STM32MP157C-EV1开发板,因此,后续的移植都是以STM32MP157C-EV1开发板为蓝本,在此基础上进行修改。
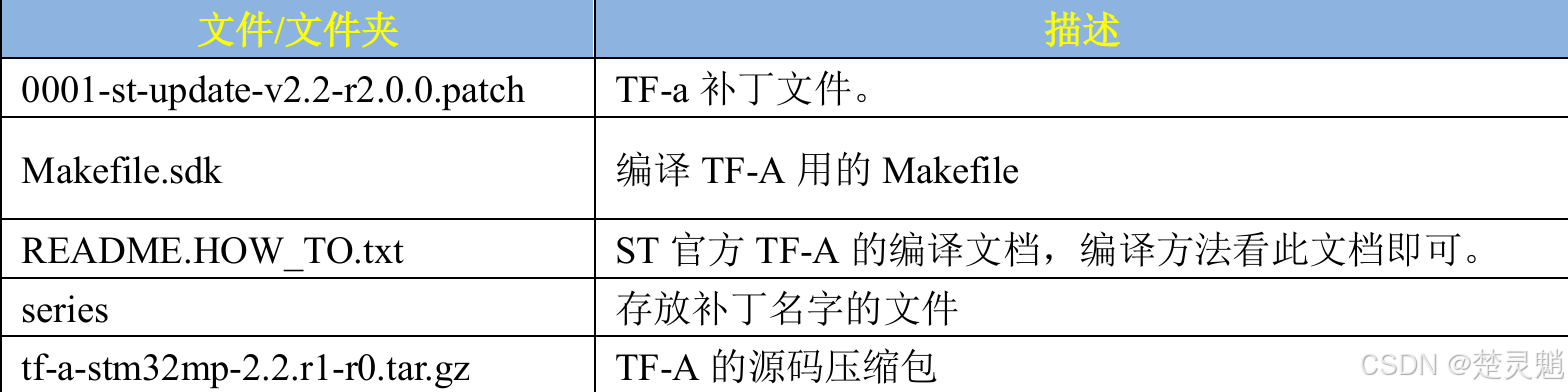
我们进入tf-a-stm32mp-2.2.r1-r0这个文件夹中,可以看到这样五个文件:

我们可以通过下方的表格来了解这几个文件的含义:
ST也是在ARM源码的基础上打了一个补丁,将自己的开发板加入到了TF-A中,我们现在就需要将patch这个补丁文件打入到TF-A的源码中,我们首先使用下面的命令将TF-A的源码解压:
tar -xvf tf-a-stm32mp-2.2.r1-r0.tar.gz我们这里进入解压以后的文件夹:

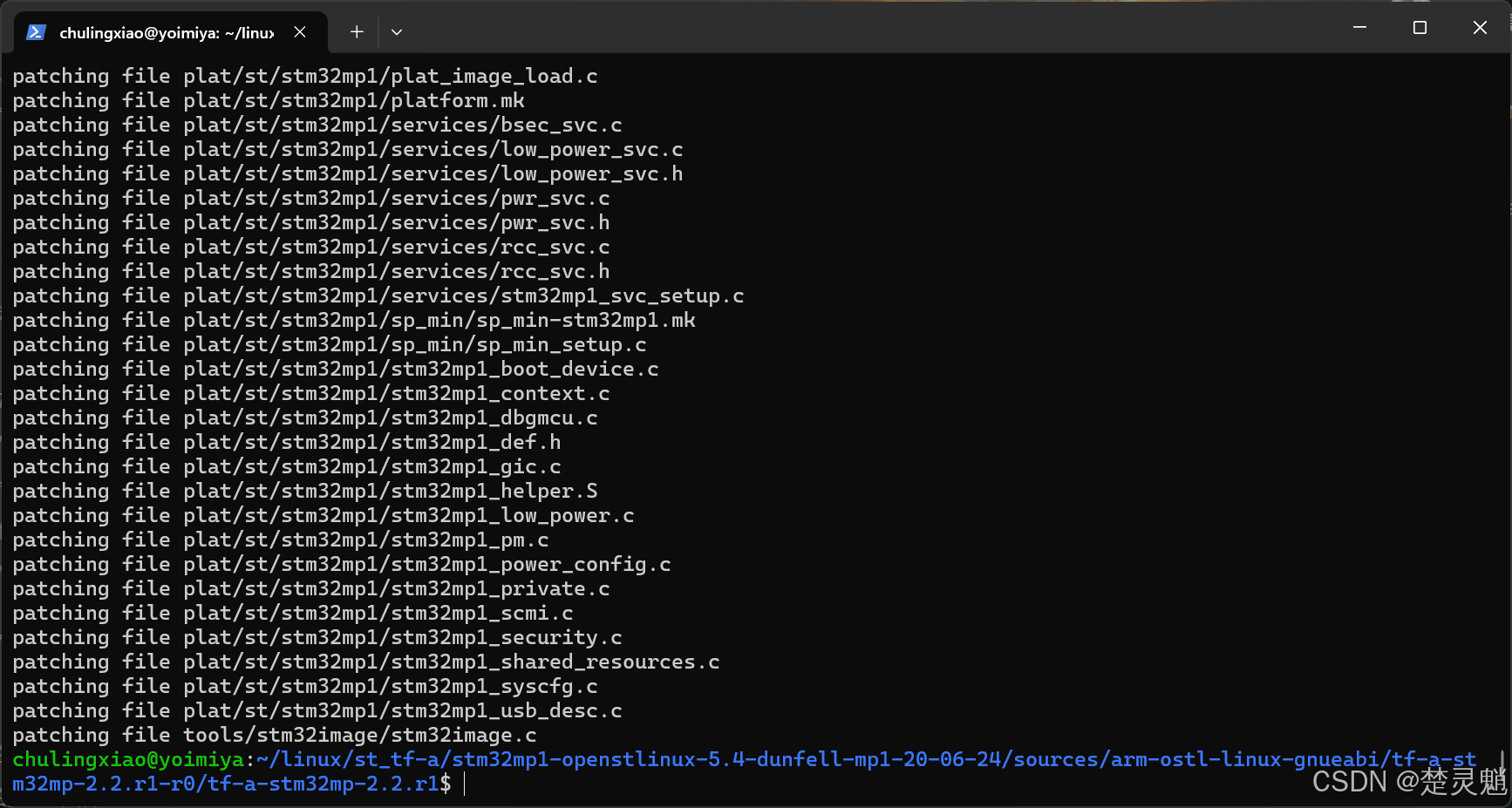
然后再使用下面的命令来打补丁,注意,这里打补丁一定要在源码目录下进行:
for p in `ls -1 ../*.patch`; do patch -p1 < $p; done 当你看到一堆东西跑过,补丁就完成了:
这里我使用下面的命令将打过补丁的TF-A源码移动到上面的目录中,防止路径太长了:

大家根据自己路径的情况移动文件即可。这里无关的文件就可以删掉了,当然也可以不删,这个看自己,这样看起来就清爽多了:

我们这个是已经打好补丁的TF-A的源码,我们尽量不在这个源码上修改,我们复制一份到自己新建的目录下,这里我新建了一个“my_tf-a”的目录,并且将其复制过去了:

我们现在来编译一下这个原本的代码,看看会不会有什么问题,我们进入“tf-a-stm32mp-2.2.r1-r0”目录,就能看到以下文件和文件夹:

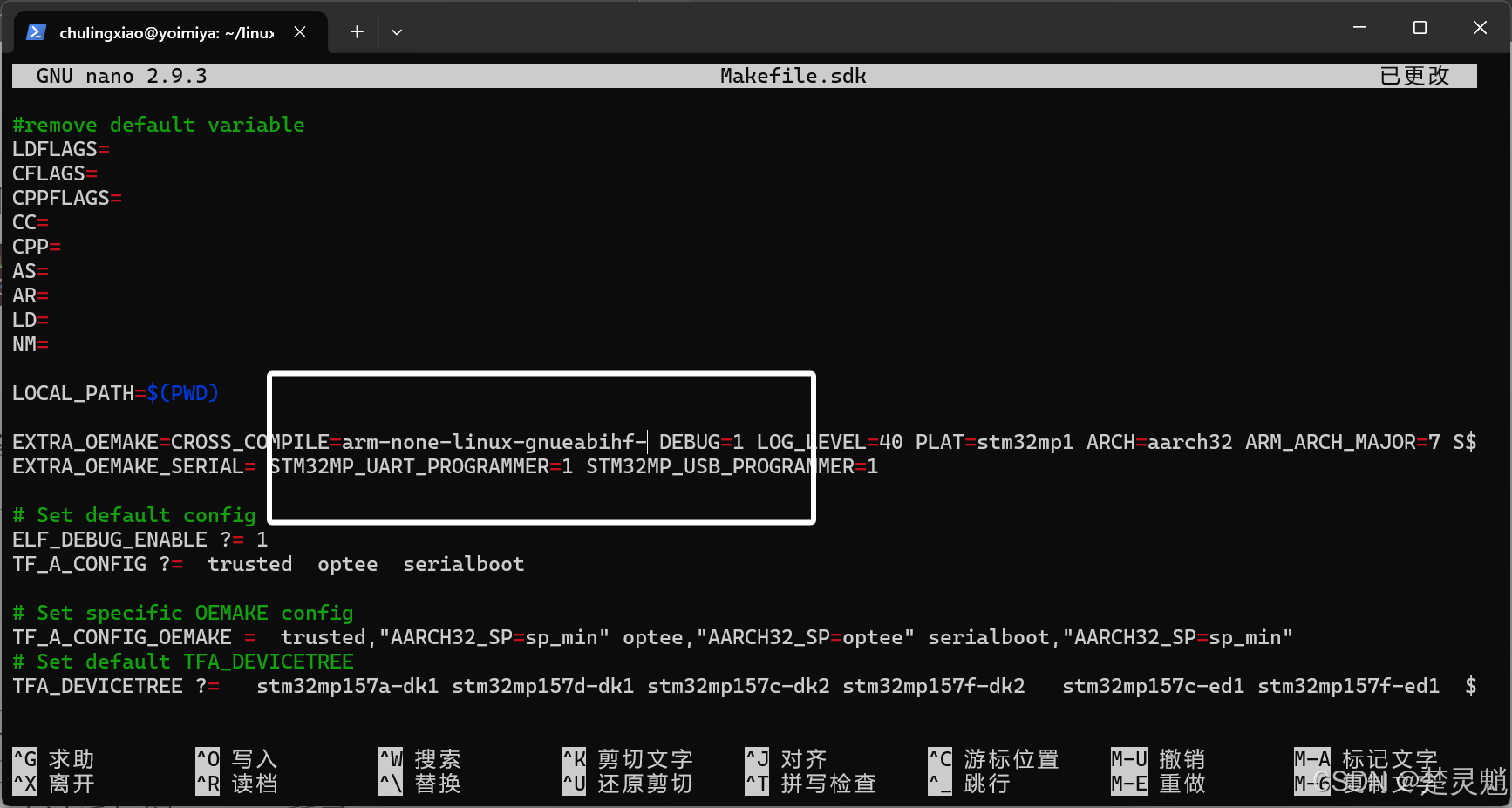
我们这里要编译就要像修改正点原子的代码那样,将“Makefile.sdk”里面的编译器修改为自己的,这一步很简单,就不多说了。修改完以后就是下面这样:
然后我们再用下面的命令切换到源码目录:
cd tf-a-stm32mp-2.2.r1/然后,我们再使用编译命令,来ST提供的编译TF-A的源代码:
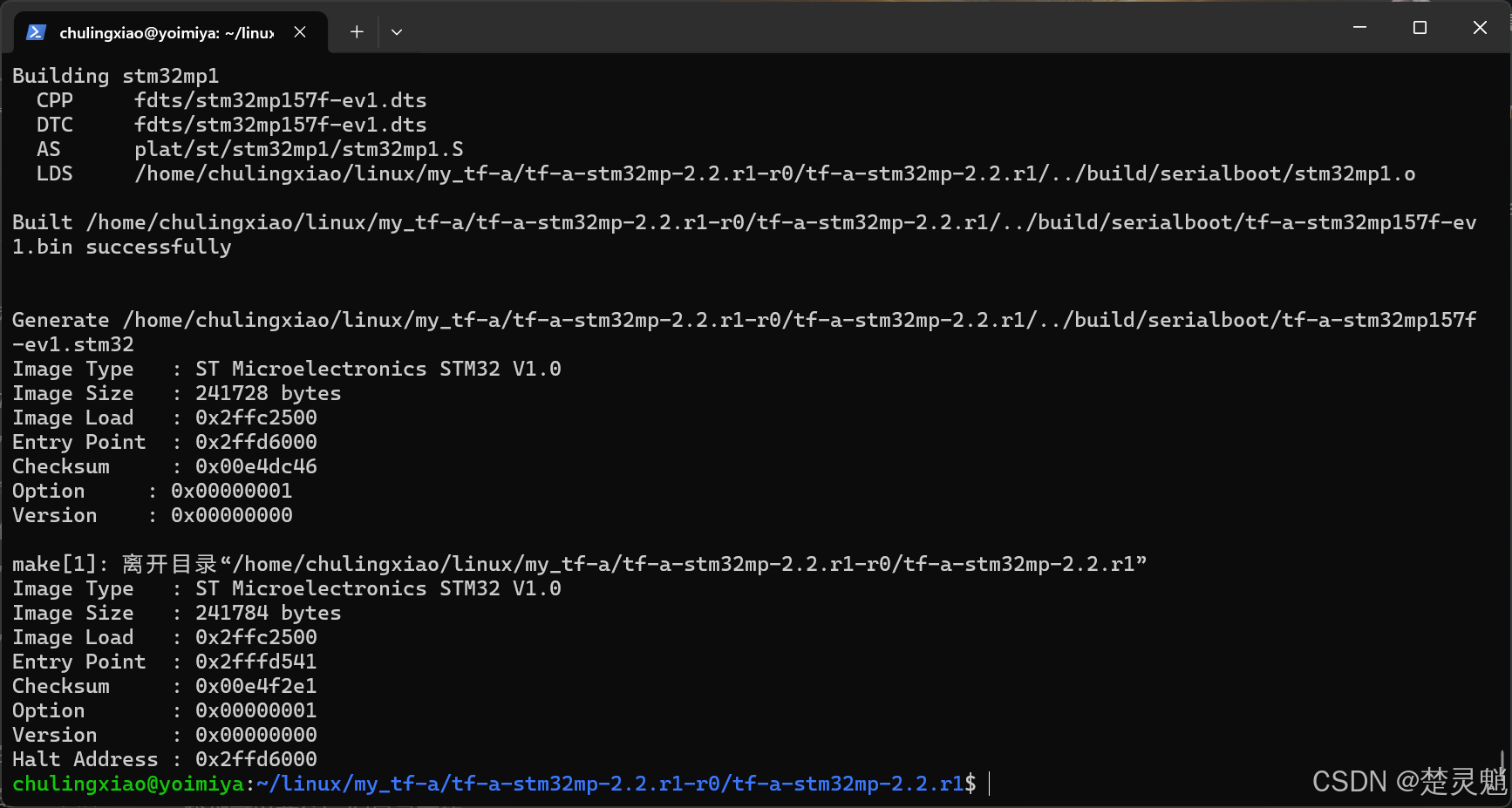
make -f ../Makefile.sdk all -j12这里的命令在编译正点原子的TF-A源码时已经解释过了,现在就不进行过多的讲解了。
编译完成应该是没有错误的:
我们可以前往build目录下的trusted目录看看,可以看到,这里是没有正点原子的开发板的,因为我们使用的是ST提供的TF-A源码,正点原子的开发板根本就没有被添加进来:
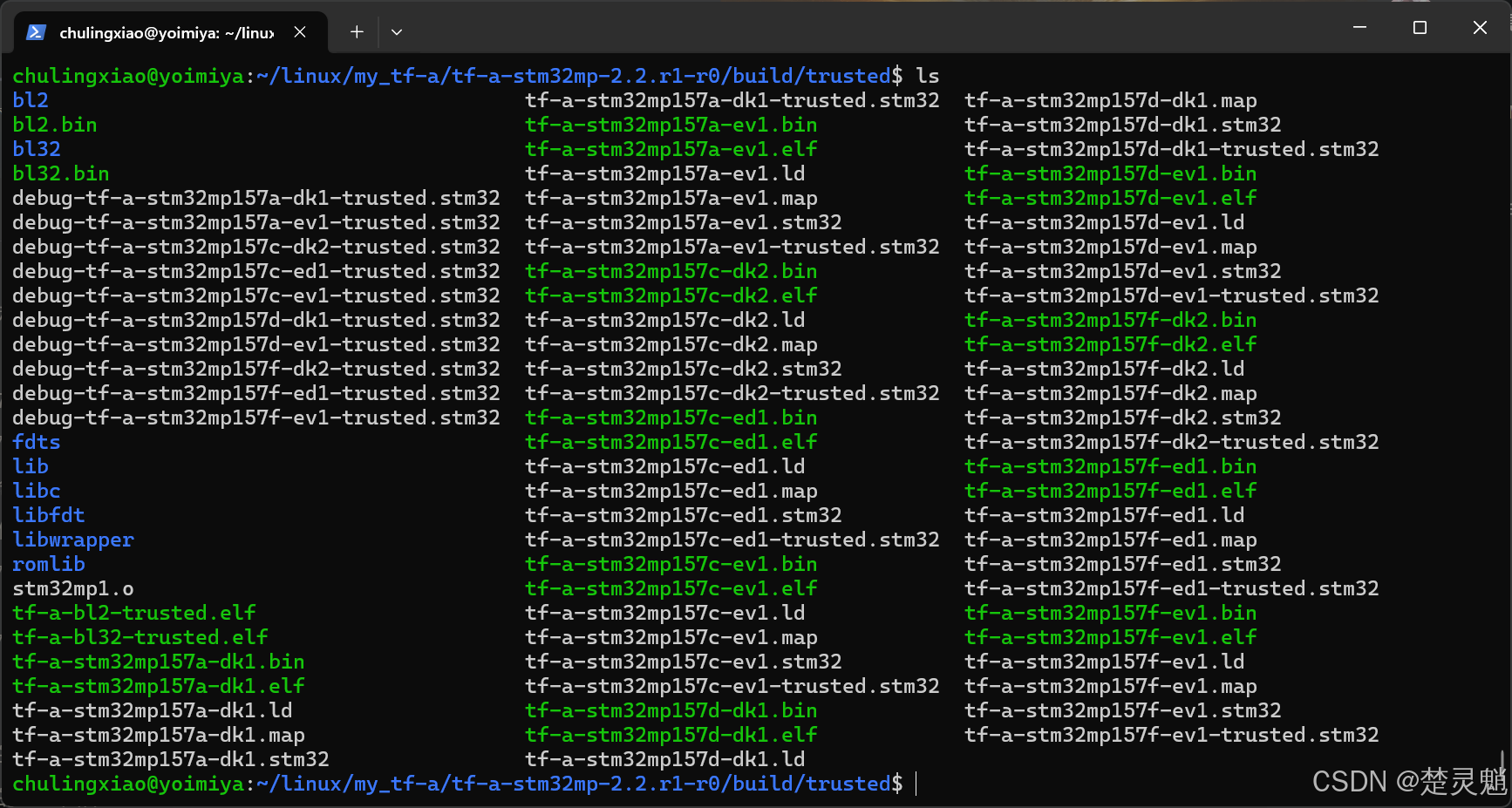
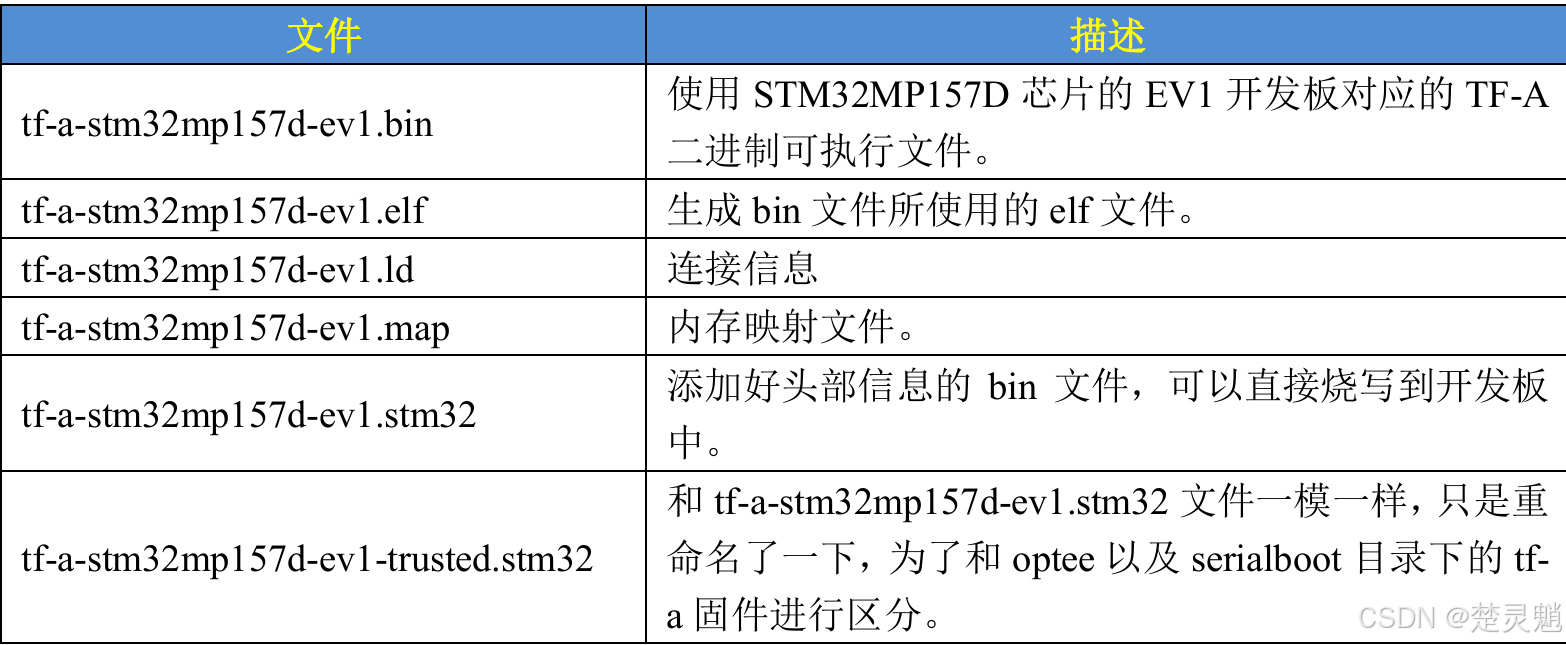
下面,我们来简单看一下,不同后缀的文件的含义是什么,这里就用ST官方的EV1开发板来举例:
下面我们就来将正点原子的开发板添加到TF-A的编译中。前面已经多次提到了正点原子的STM32MP157开发板是参考了了ST官方的EV1开发板,这样我们就可以将EV1开发板的一些代码和设备树作为蓝本了。我们去到源码目录下的fdts目录可以看到非常多的设备树文件:
这些dts和dtsi的文件都是设备树文件。下面我们只需要复制一些关键的文件拿来修改就行了因为正点原子的板子是使用的EV1的原理图,我们这里可以直接用EV1的设备树来改,这里如果你不了解设备树,那么跟着我操作就行,我们使用下面的命令复制设备树并且改为自己开发板的名字,这样就得到了一个自己开发板的文件:
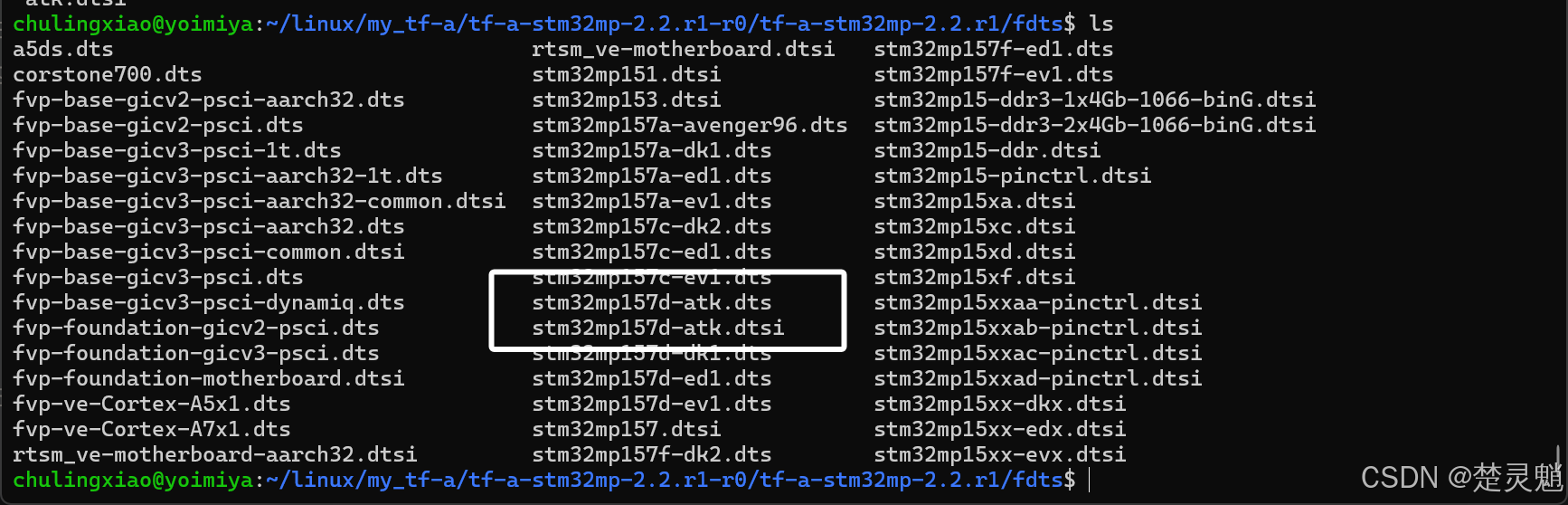
cp stm32mp157d-ed1.dts stm32mp157d-atk.dts 然后我们还需要另一个文件来复制,同样使用下面的命令:
cp stm32mp15xx-edx.dtsi stm32mp157d-atk.dtsi 这样我们就通过复制得到了“stm32mp157d-atk.dts”和“stm32mp157d-atk.dtsi”两个文件:
这里我们可以使用vscode打开my_tf-a整个文件夹这样更便于我们修改文件:
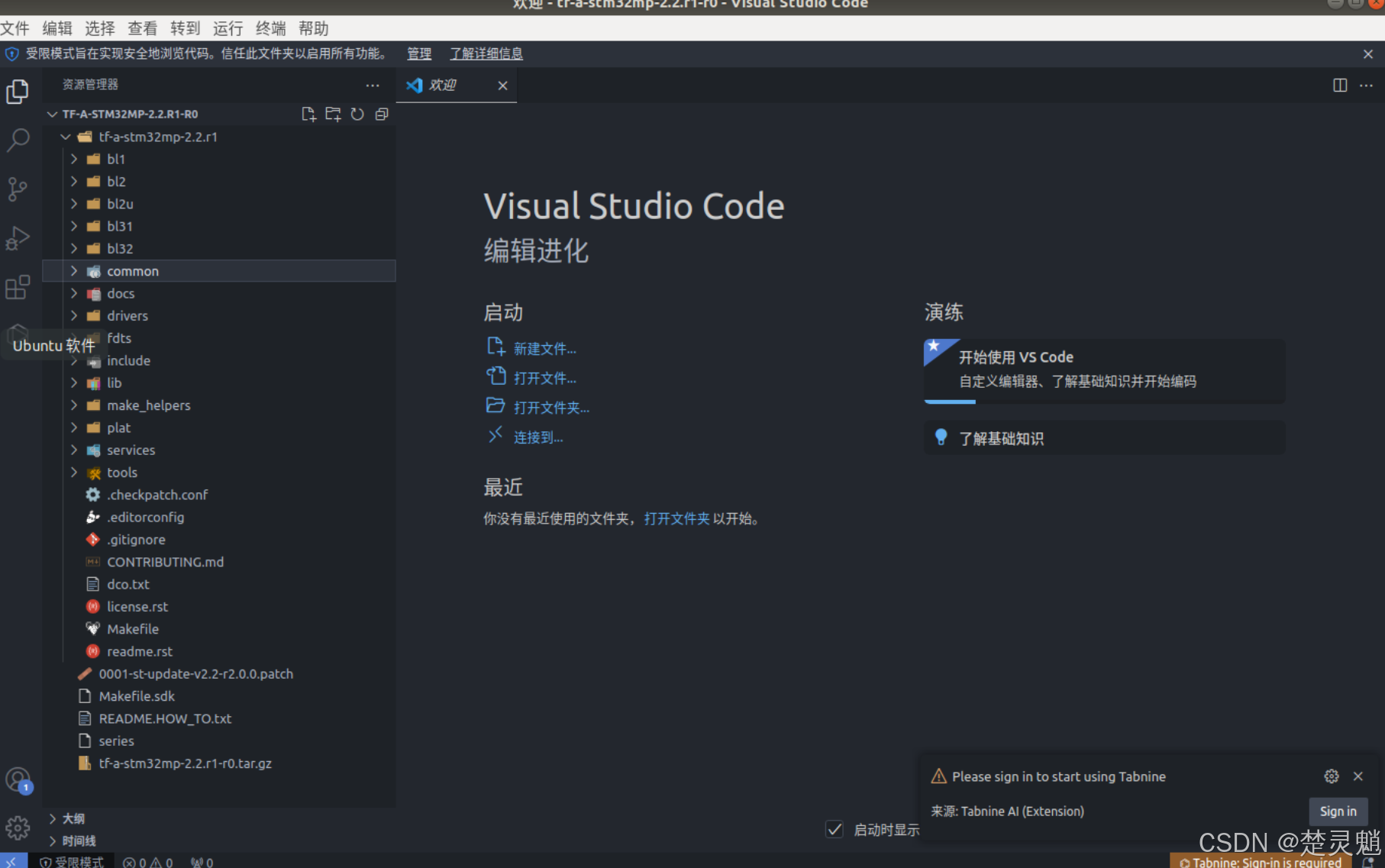
我们打开stm32mp157d-atk.dts文件,将第12行的#include "stm32mp15xx-edx.dtsi"改为#include "stm32mp157d-atk.dtsi”,修改完以后如图所示
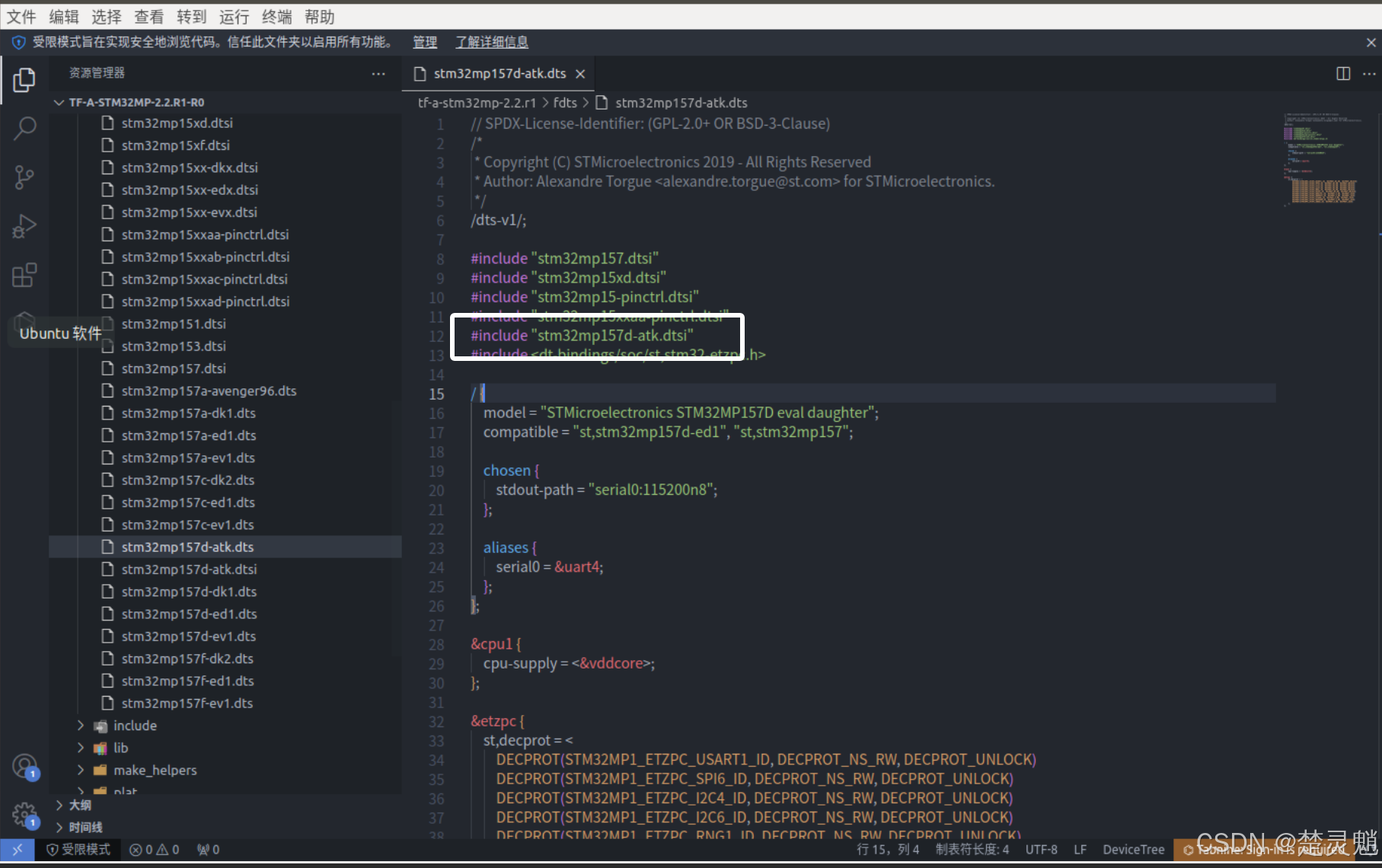
修改完以后使用“Ctrl+S”保存。
下面我们可以来编译一下,但是在编译之前,需要将我们的开发板添加到编译队列中,不然我们就只是添加了设备树,编译器根本就不知道要编译我们的开发板,我们来到Makefile.sdk中找到TFA_DEVICETREE在它的后面添加我们的开发板即可,添加如下字段:
stm32mp157d-atk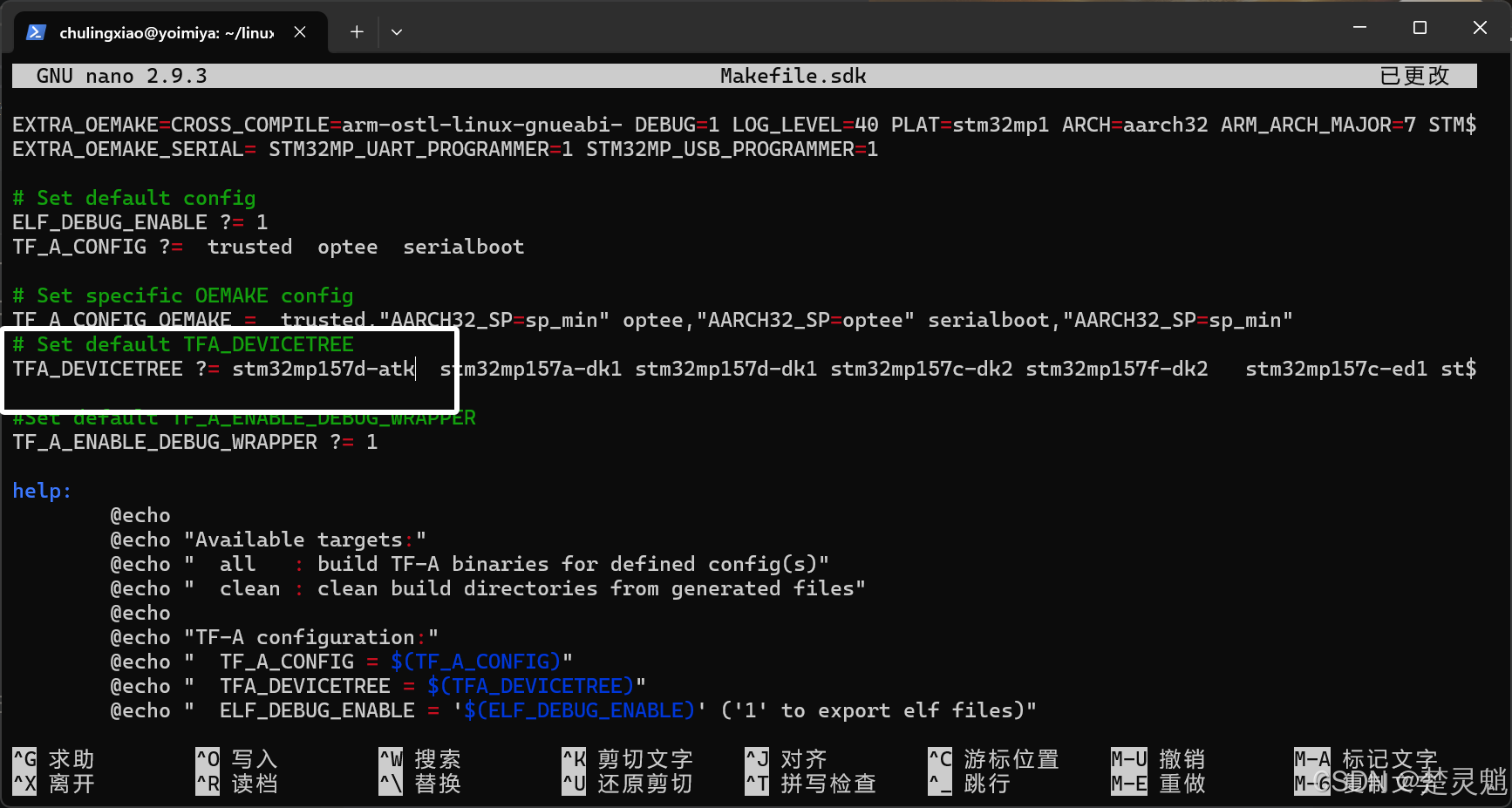
修改完以后我们就可以开始编译了,还是使用以前的命令来编译即可,我这里已经编译完成了,如果你和我上面的操作一样是不会有错误的:
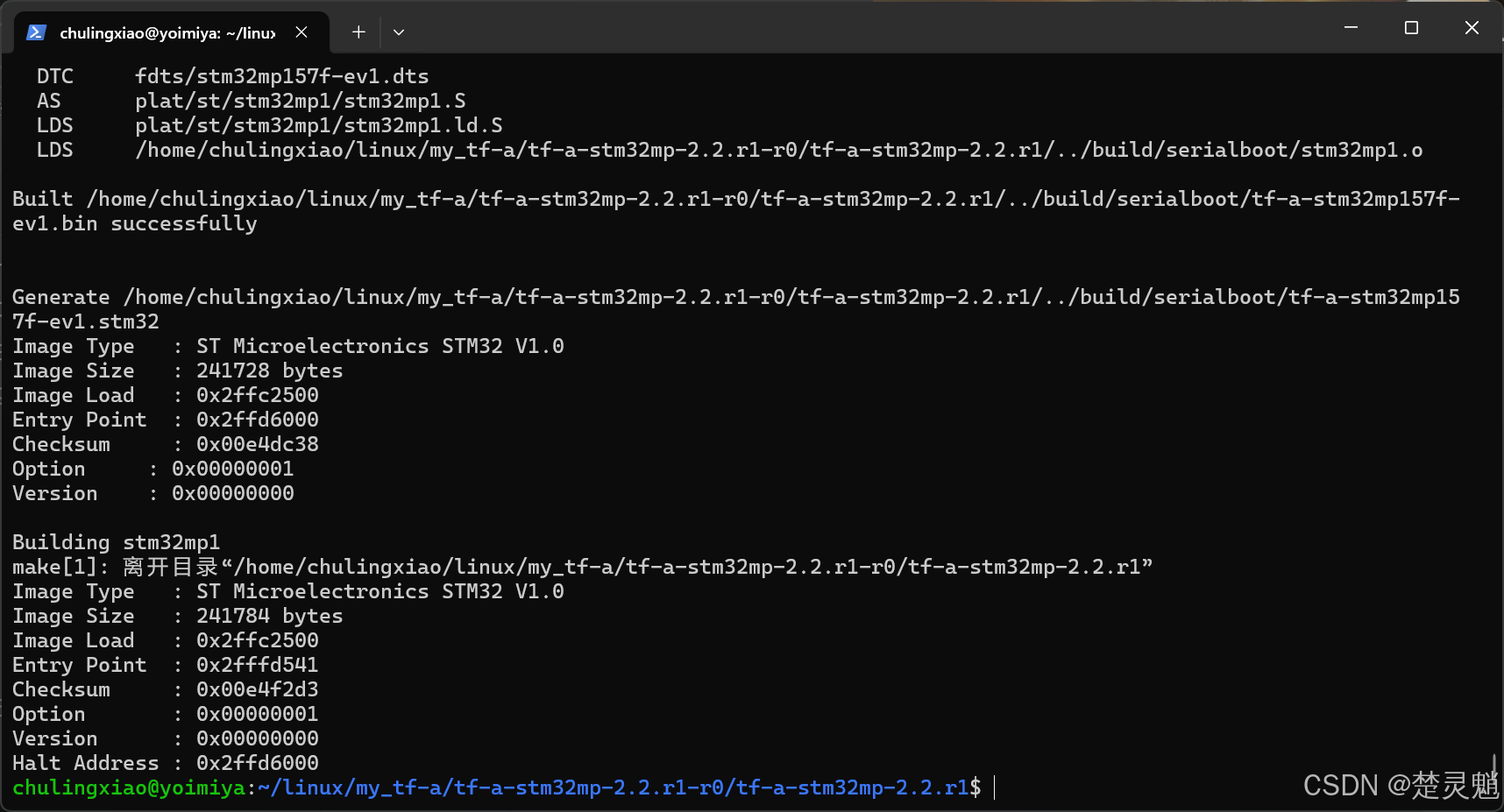
我们再次回到TF-A已经编译完成的目录中,可以发现,这里已经有我们的开发板了:
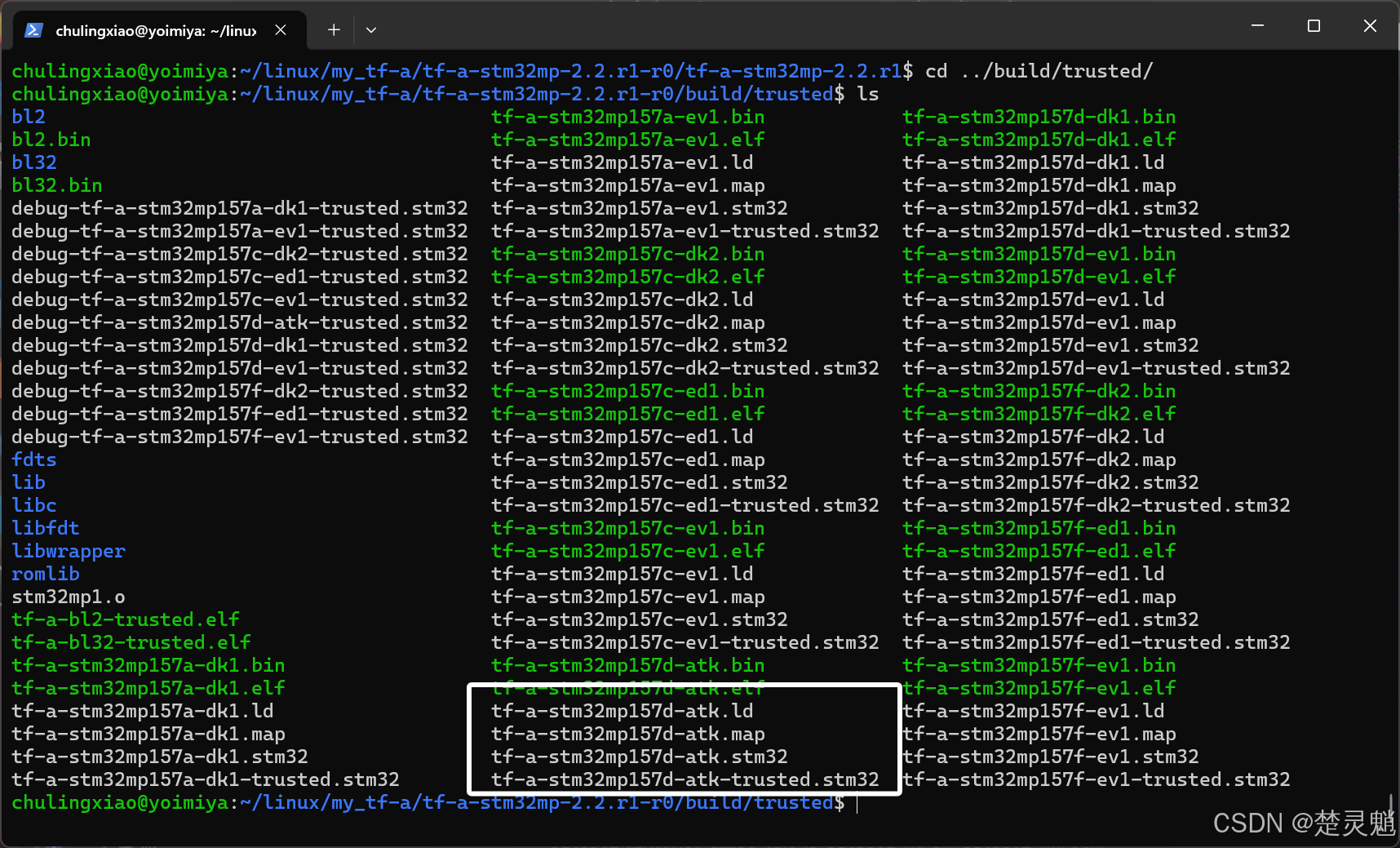
但是也不要着急烧录,这里我们都是复制EV1开发板的设备树,烧入进去也会有问题的。我们还需要对设备树进行一些修改。当然后面的一切都建立在前面的步骤没有报错的前提下。
我们同样使用vscode打开“stm32mp157d-atk.dtsi”文件:

下面我们开始修改,这里首先找到“&i2c4”:
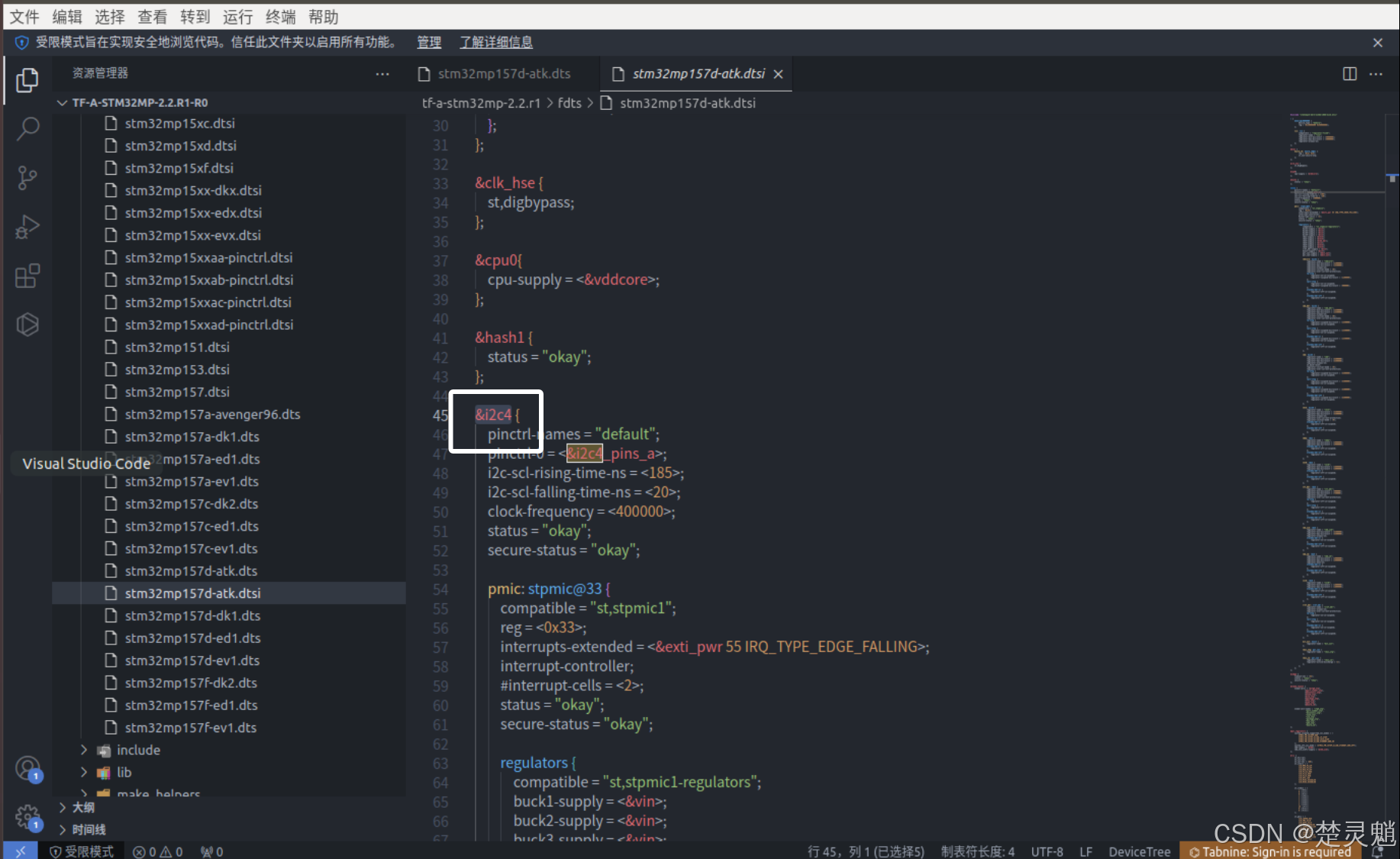
我们需要将“i2c4”下的“pmic:”下的代码全部删掉,注意不要删到“i2c4的括号了”,删除完"i2c4"的内容就变得非常简单了,如图:
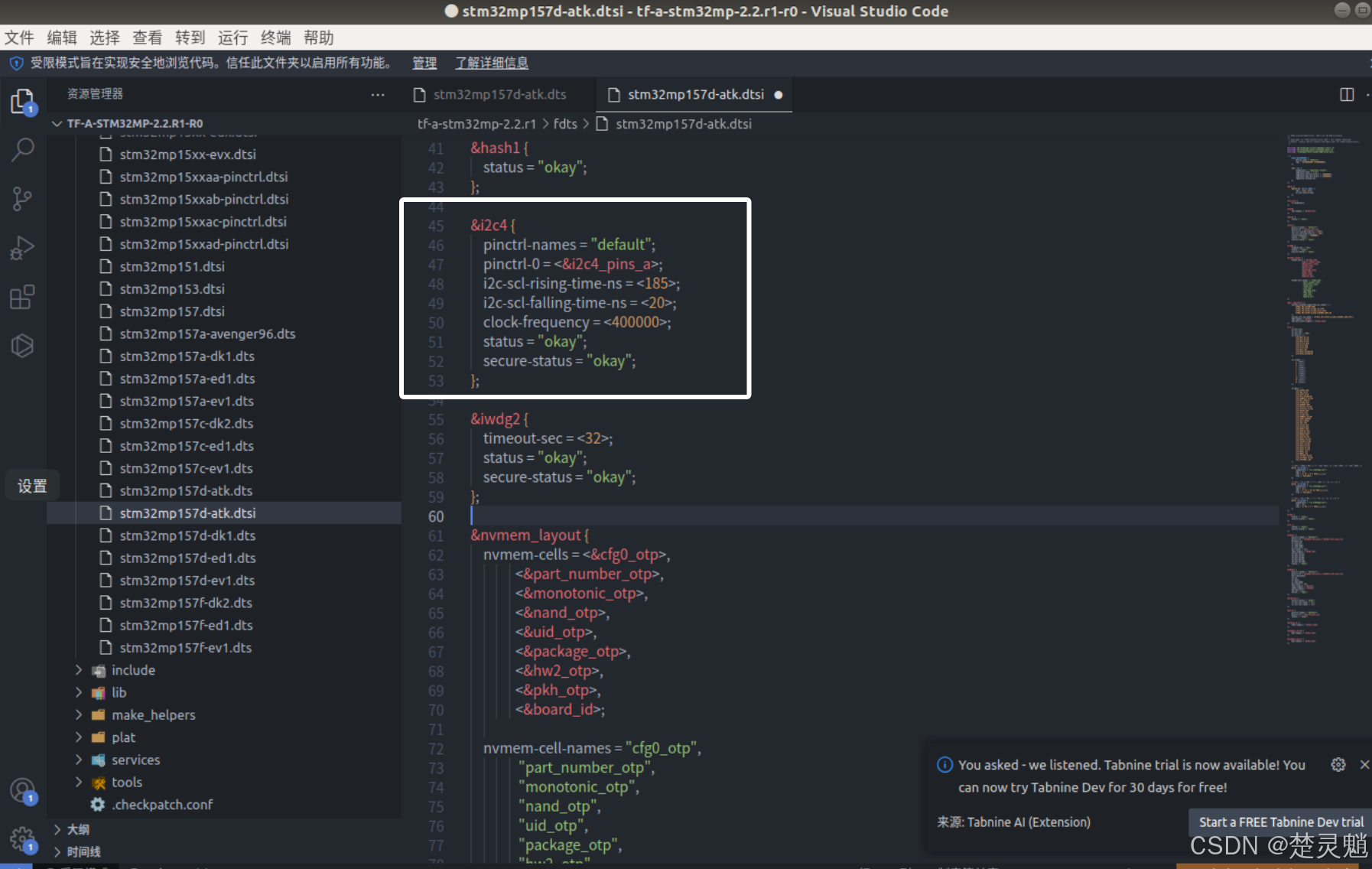
然后我们还要修改vin部分,这里我们可以看到vin部分有这些内容:
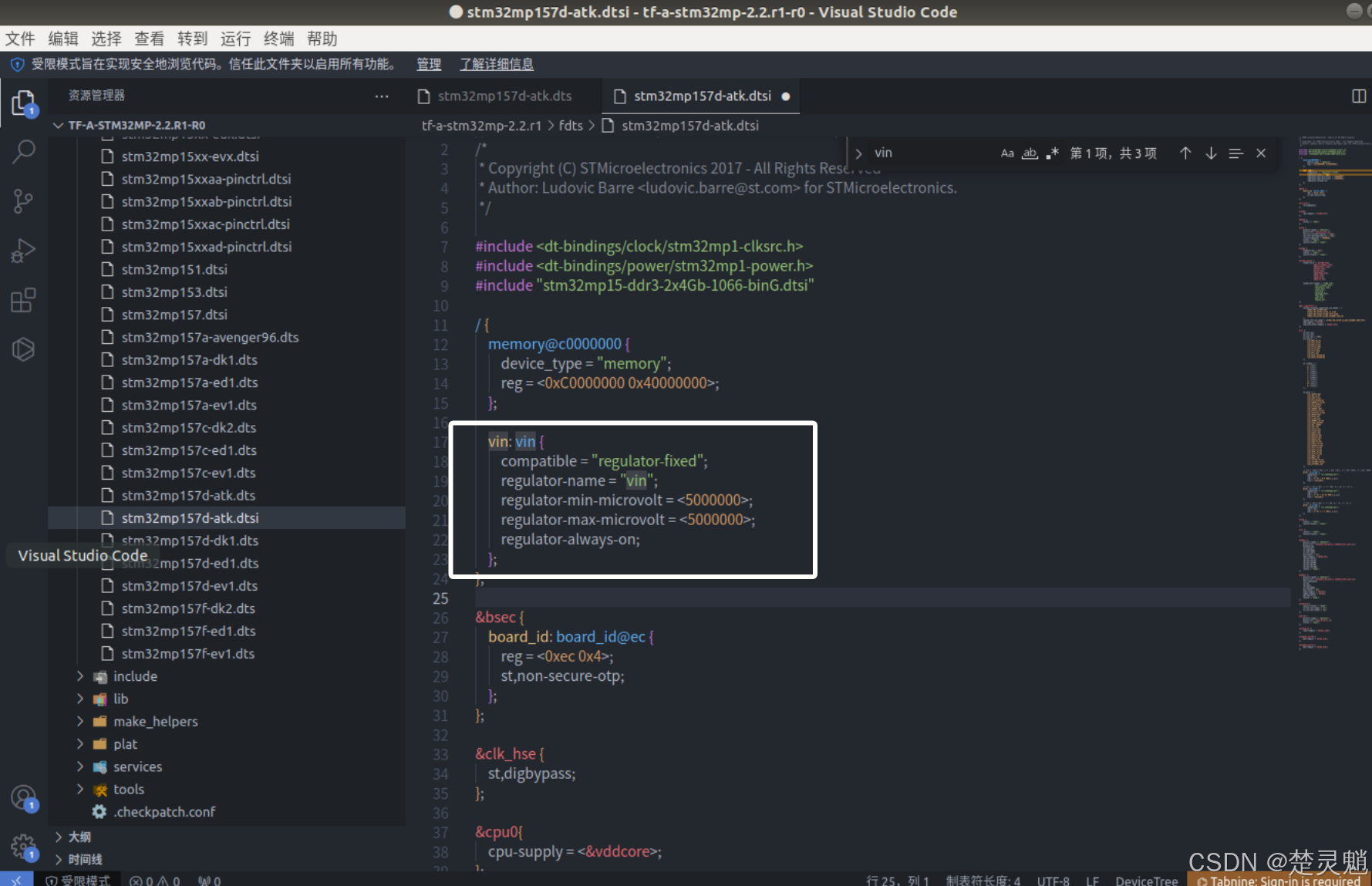
我们将这些内容全部删掉。是的,将vin所以内容全部删掉。删掉以后我们将下面的内容复制到vin原本的位置上:
vddcore: regulator-vddcore {
compatible = "regulator-fixed";
regulator-name = "vddcore";
regulator-min-microvolt = <1200000>;
regulator-max-microvolt = <1350000>;
regulator-off-in-suspend;
regulator-always-on;
};
v3v3: regulator-3p3v {
compatible = "regulator-fixed";
regulator-name = "v3v3";
regulator-min-microvolt = <3300000>;
regulator-max-microvolt = <3300000>;
regulator-off-in-suspend;
regulator-always-on;
};
vdd: regulator-vdd {
compatible = "regulator-fixed";
regulator-name = "vdd";
regulator-min-microvolt = <3300000>;
regulator-max-microvolt = <3300000>;
regulator-off-in-suspend;
regulator-always-on;
};
vdd_usb: regulator-vdd-usb {
compatible = "regulator-fixed";
regulator-name = "vdd_usb";
regulator-min-microvolt = <3300000>;
regulator-max-microvolt = <3300000>;
regulator-off-in-suspend;
regulator-always-on;
}; 修改完以后就如图所示了:

下面我们再找到“sdmmc1”和“sdmmc2”处:
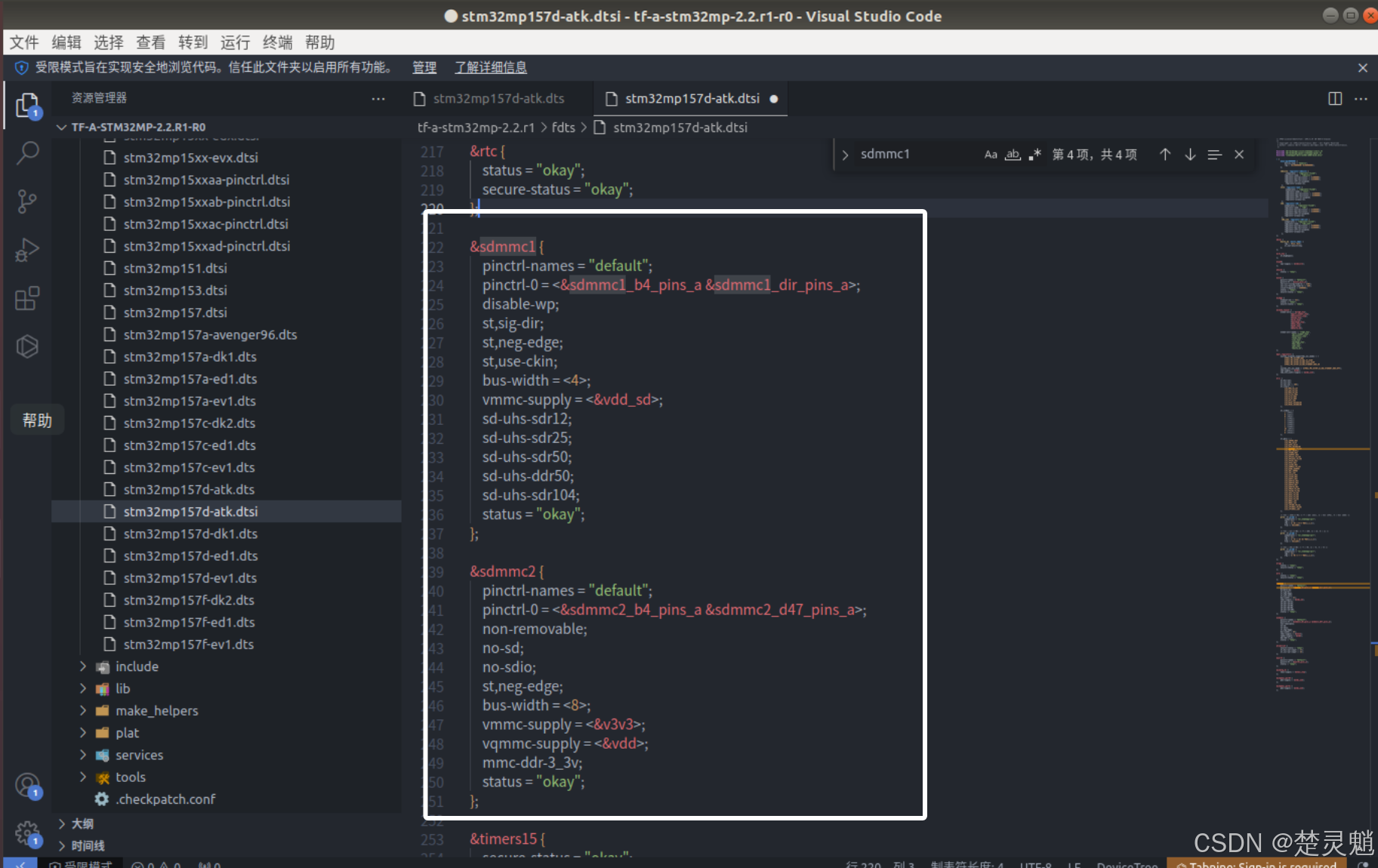
我们将其修改为以下的内容:
&sdmmc1 {
pinctrl-names = "default";
pinctrl-0 = <&sdmmc1_b4_pins_a &sdmmc1_dir_pins_a>;
st,neg-edge;
broken-cd;
bus-width = <4>;
vmmc-supply = <&v3v3>;
status = "okay";
};
&sdmmc2 {
pinctrl-names = "default";
pinctrl-0 = <&sdmmc2_b4_pins_a &sdmmc2_d47_pins_a>;
non-removable;
st,neg-edge;
bus-width = <8>;
vmmc-supply = <&v3v3>;
vqmmc-supply = <&v3v3>;
status = "okay";
};修改完以后,如图:
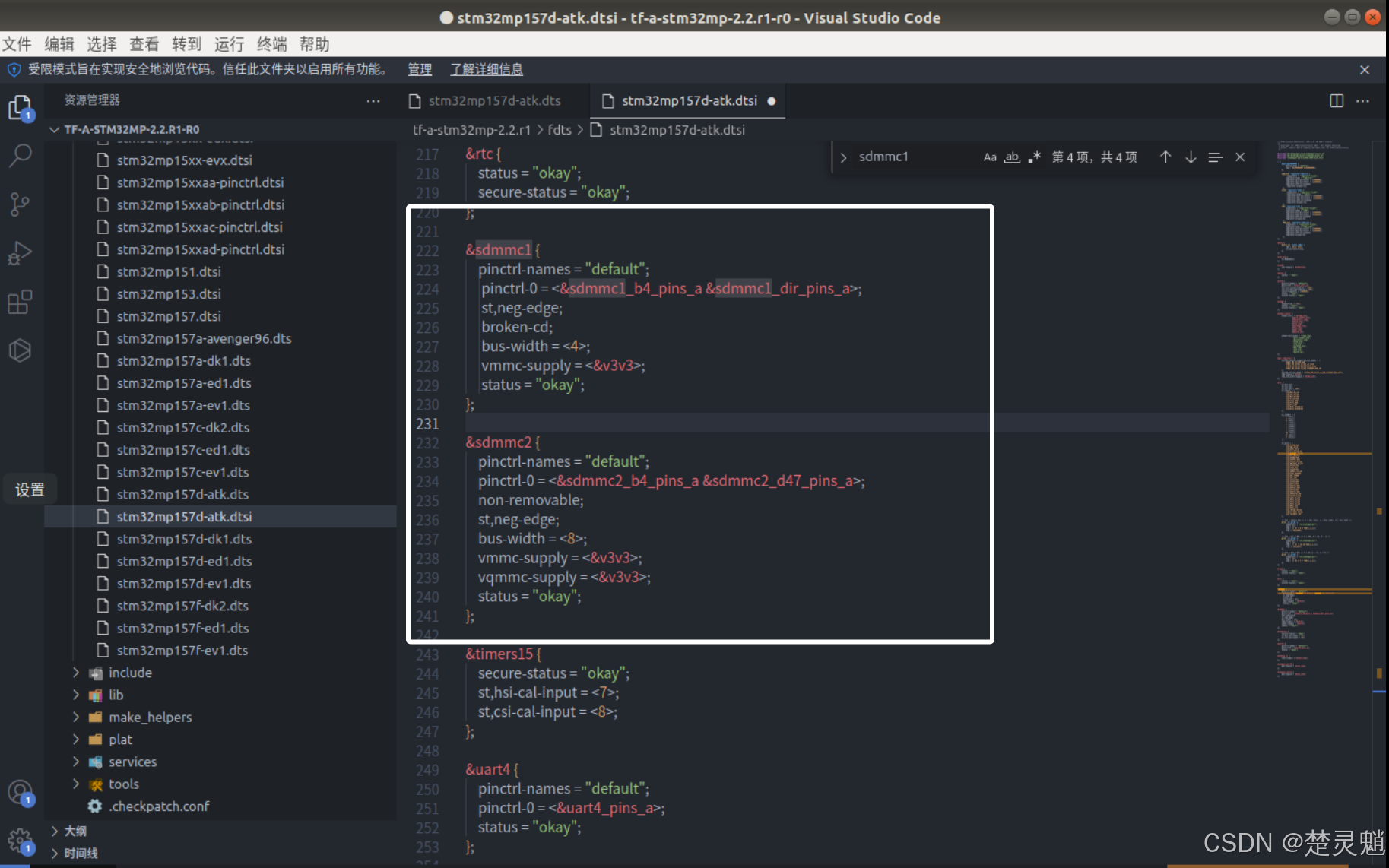
然后我们还要修改一下“usbotg_hs”处:

我们将其修改为以下内容:
&usbotg_hs {
phys = <&usbphyc_port1 0>;
phy-names = "usb2-phy";
usb-role-switch;
status = "okay";
};修改完以后如图所示:
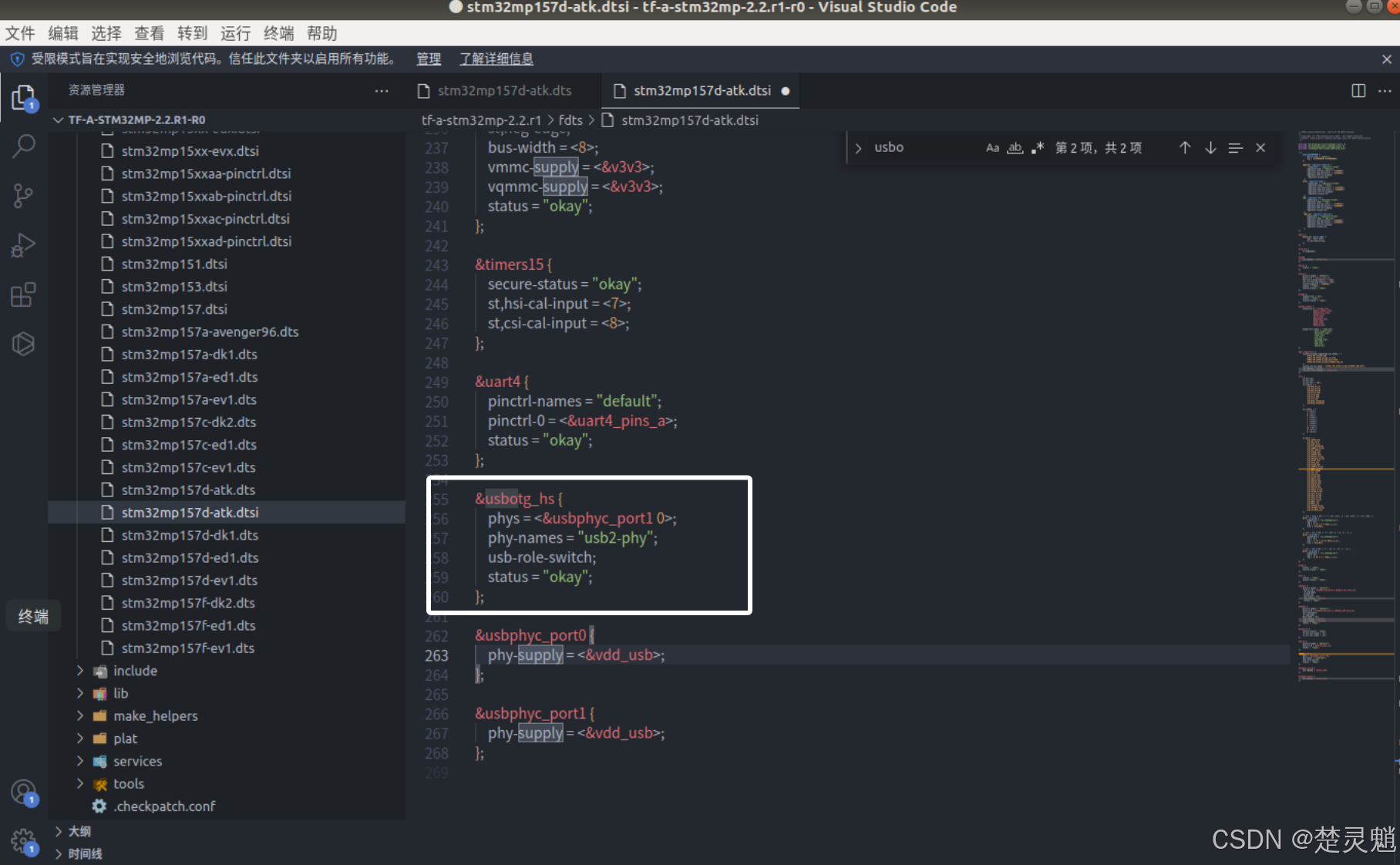
然后我们需要在“usbotg_hs”处的下面添加如下内容:
&usbphyc {
status = "okay";
};添加完以后如图所示:
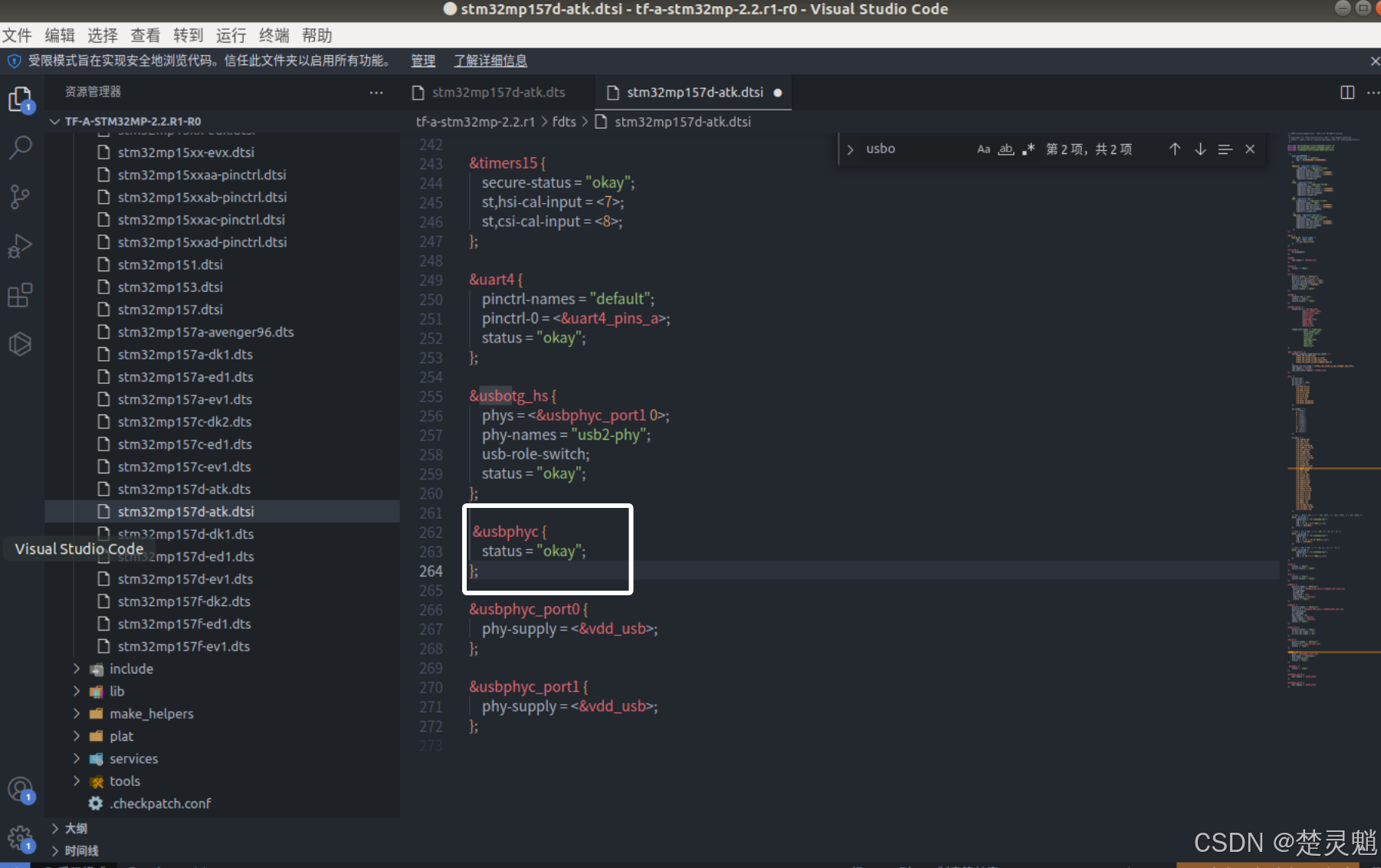
至此,我们所有的文件都已经处理完毕,这里大家记得按“Ctrl+S”保存一下编辑的内容。然后我们就可以回原本的文件夹中进行编译了。
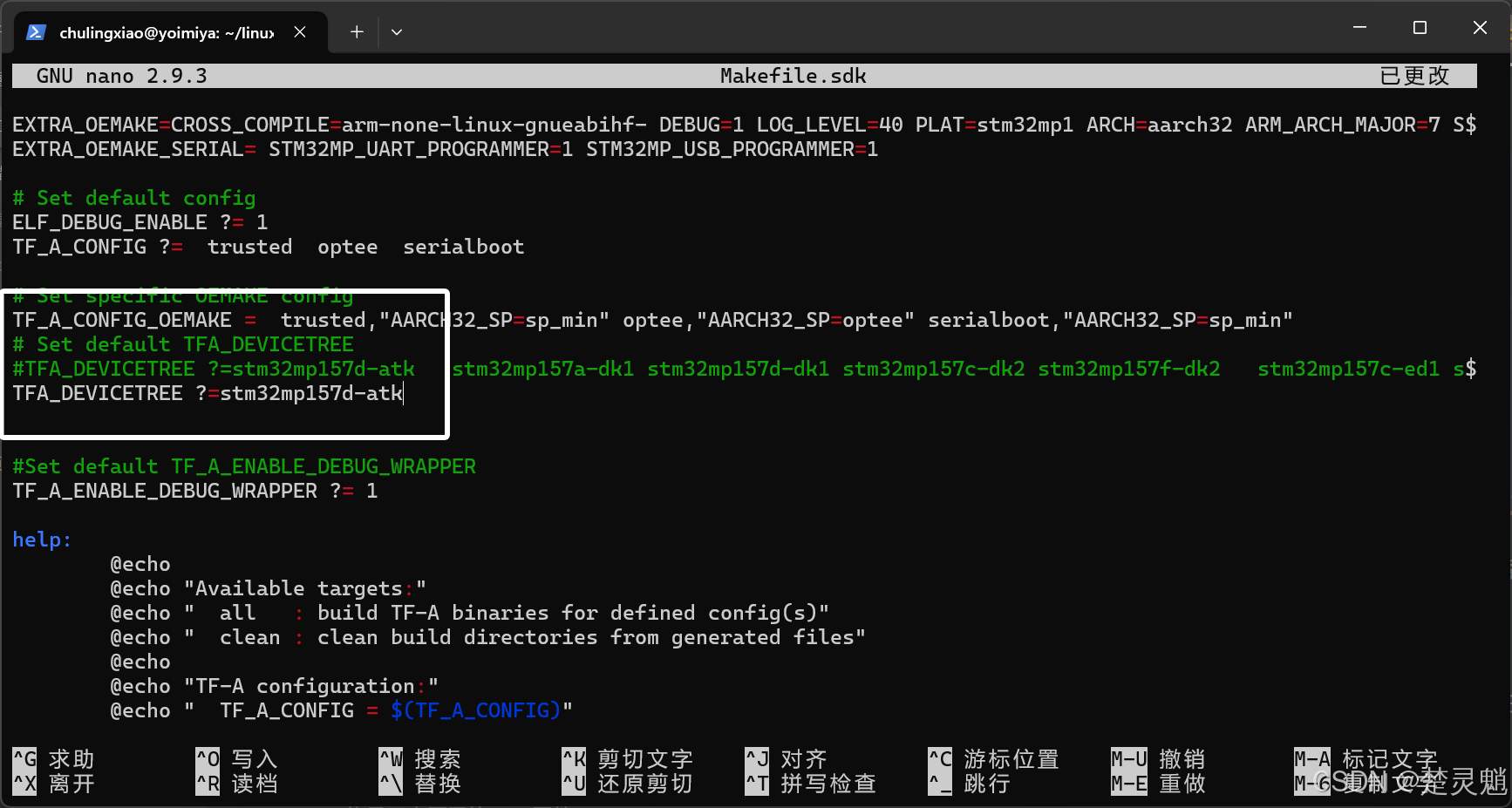
这里我们修改一下“Makefile.sdk”让编译时只编译我们的开发板,我们这里将原本的TFA_DEVICETREE 这一行都用#注释掉,然后写一行新的TFA_DEVICETREE 并且在后面只跟一个我们的开发板,修改完以后就如图所示:
然后我们可以将之前产生的build文件夹删掉。使用下面的命令:
rm -rf ./build/然后我们进入源码文件夹使用下面的命令进行编译:
make -f ../Makefile.sdk all这里就不要加多线程编译了,可能会出现错误。
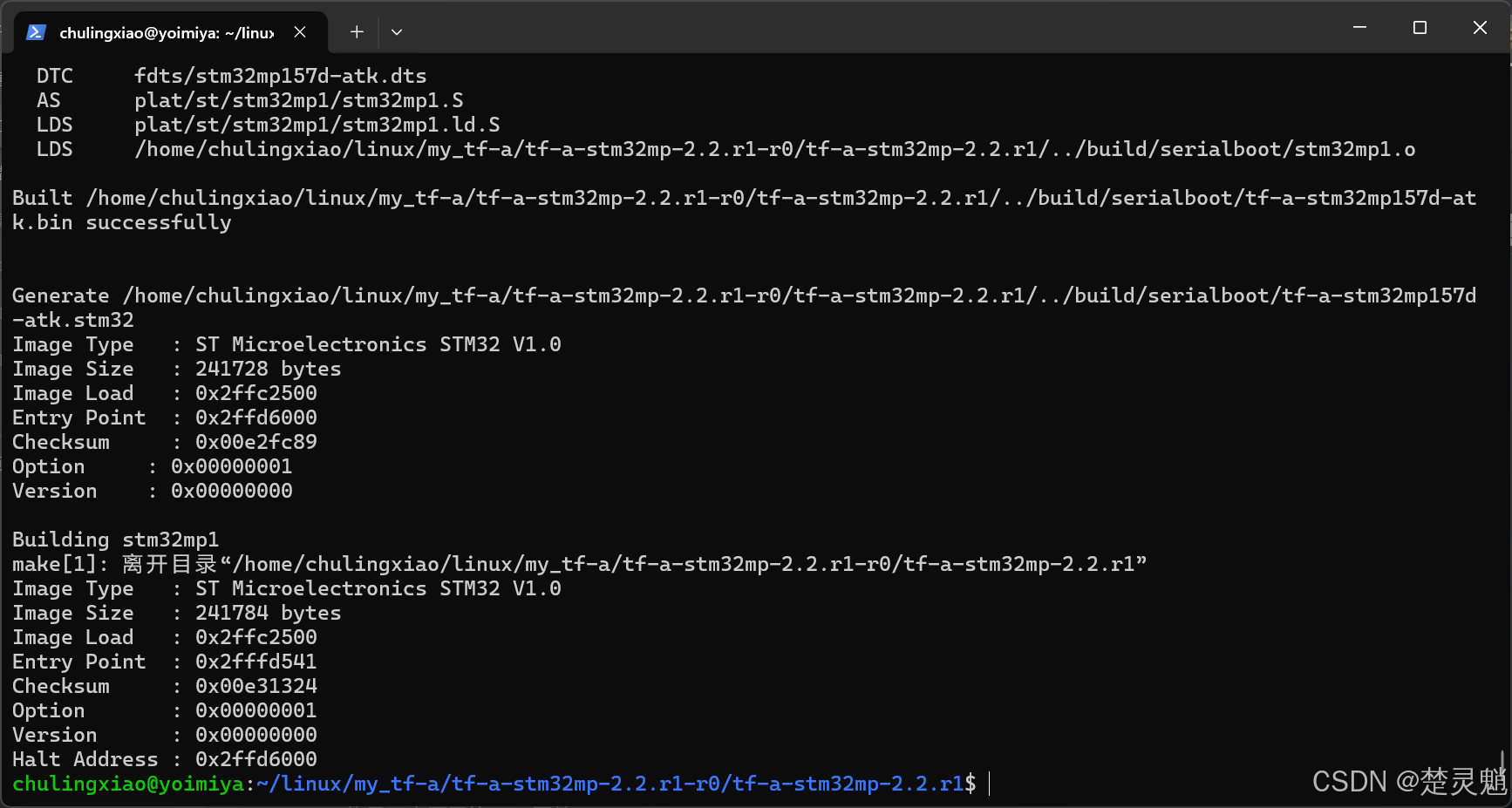
我这里已经编译完成了,按道理说,如果是跟着我操作的话,是不会有错误的:
这里我们再次进入build目录下的“trusted”目录下就可以看到我们编译的文件了:

因为这里只编译了我们的开发板所以文件少了许多。
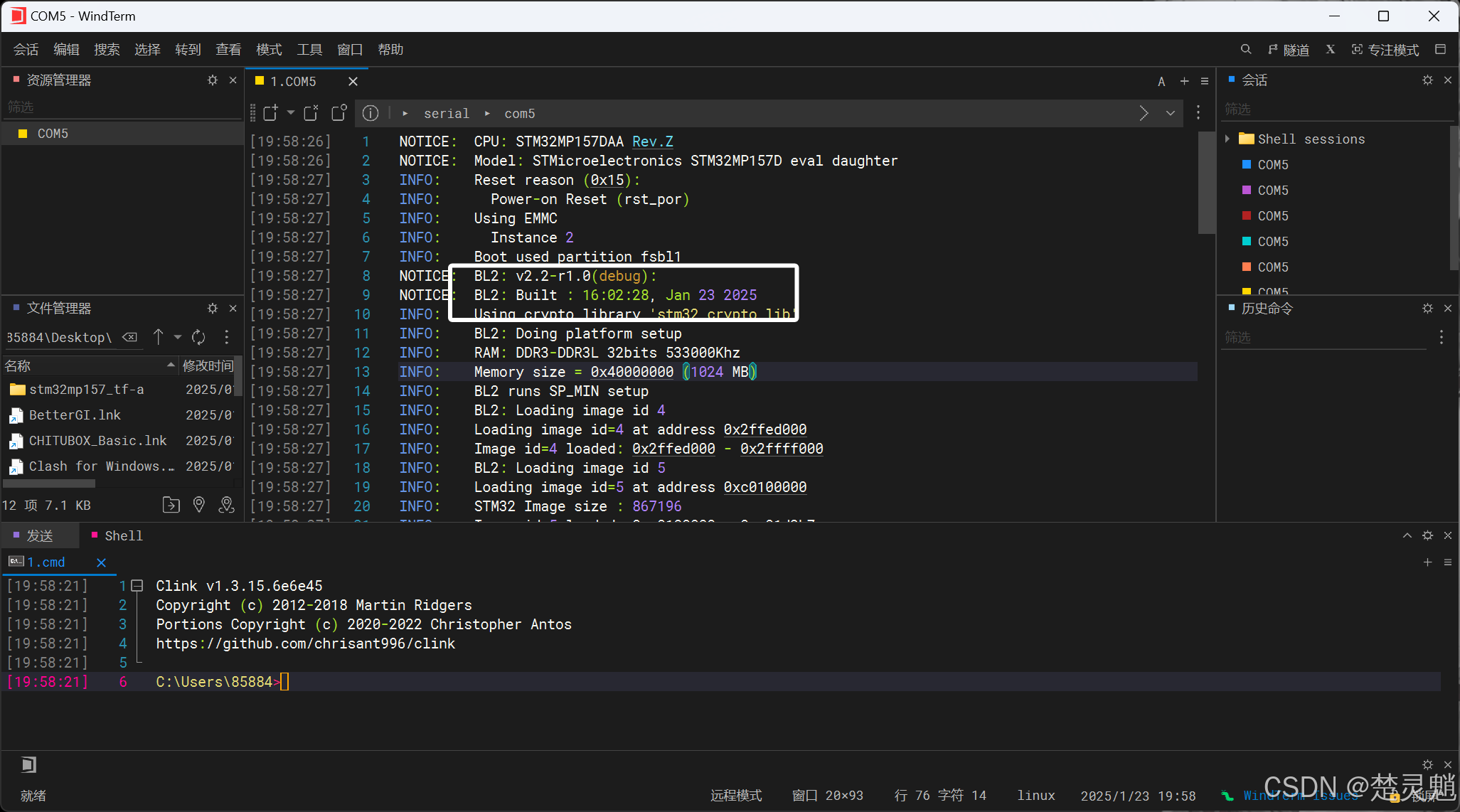
然后大家可以按照之前烧录的方法将这个自己移植编译的TF-A烧录到开发板中测试一下,可以看到我们这里已经移植成功并且TF-A已经启动了:
至此,我们自己移植TF-A并且烧录就已经完成了。
六、结语
本次教程中,我们带大家了解了STM32MP1的启动流程,了解了什么是TF-A,并且我们也自己亲自移植了TF-A并且让它跑了起来,总的来说,内容还是比较多的。那么最后,感谢大家的观看!