基于MATLAB的并行计算、多核优化技术实战
在MATLAB中,随着计算机硬件性能的提升,如何有效地利用多核CPU以及并行计算的技术成为了一个重要的研究课题。本文将介绍MATLAB中的并行计算工具箱以及如何通过代码优化,充分发挥多核处理器的性能。我们将深入探讨并行计算的原理、常见应用场景以及优化技巧,并通过实际的代码示例帮助读者掌握MATLAB在并行计算中的应用。
1. MATLAB中的并行计算工具箱概述
MATLAB提供了并行计算工具箱(Parallel Computing Toolbox),它允许用户在多核处理器、集群、GPU等环境下进行高效的计算。利用这些工具,用户可以显著加速计算密集型任务,例如大规模的矩阵运算、数据处理、图像处理等。
1.1 并行计算的基本概念
并行计算是指将一个复杂的计算任务分解成若干个独立的子任务,然后在多个计算单元(如处理器核心)上同时执行。通过并行计算,可以减少计算时间,尤其是在处理大规模数据时,能够显著提高效率。
MATLAB的并行计算工具箱提供了以下几种常用的方法来实现并行计算:
- parfor循环:一种并行化的for循环,它将迭代分配到多个工作线程中进行并行计算。
- spmd(Single Program Multiple Data):允许在不同的工作线程中执行相同的程序,但每个线程处理不同的数据。
- parallel.pool对象:管理并行计算任务的工作池(worker pool)。
1.2 配置并行计算环境
在MATLAB中,使用并行计算工具箱之前,需要先配置并行环境。通常,MATLAB会自动识别并使用系统的多核处理器,但用户也可以手动配置工作池的大小和计算资源。
% 启动并行池,设置工作池大小
parpool('local', 4); % 4个工作线程
在启动并行池后,可以使用并行计算的命令进行高效计算。
2. 使用parfor实现并行循环
parfor是MATLAB中最常用的并行计算方法之一,它可以将for循环的迭代分配到多个工作线程中,从而加速计算过程。
2.1 parfor的基本用法
与普通的for循环不同,parfor要求循环的每次迭代是独立的,没有数据依赖。这样每个迭代可以在不同的工作线程中并行执行。
下面是一个简单的parfor示例:
% 定义一个大规模的矩阵
N = 1e7;
A = zeros(1, N);
% 使用parfor进行并行计算
parfor i = 1:N
A(i) = sin(i) * cos(i); % 计算每个元素的值
end
在这个例子中,parfor将矩阵A的每个元素的计算任务分配给不同的计算核心,充分利用多核CPU的优势。
2.2 parfor性能提升
通过比较传统的for循环和parfor循环的执行时间,可以明显看出并行计算的优势:
% 测试普通for循环的执行时间
tic;
for i = 1:N
A(i) = sin(i) * cos(i);
end
toc;
% 测试parfor循环的执行时间
tic;
parfor i = 1:N
A(i) = sin(i) * cos(i);
end
toc;
通常情况下,当任务具有高度的并行性且没有依赖关系时,parfor能够提供显著的性能提升。
3. 使用spmd进行分布式计算
spmd(Single Program Multiple Data)是一种更为灵活的并行计算方式,它允许多个工作线程执行相同的程序,但每个线程处理不同的数据。在spmd中,所有工作线程共享相同的代码,但是它们可以访问不同的数据块。
3.1 spmd的基本用法
% 使用spmd进行分布式计算
spmd
% 获取当前工作线程的ID
workerID = labindex;
% 每个线程处理不同的数据
disp(['Worker ', num2str(workerID), ' is processing.']);
end
在此示例中,spmd会启动多个工作线程(每个线程都有一个唯一的labindex),每个线程独立执行程序并处理不同的数据块。
3.2 分布式数据处理
在实际应用中,spmd常用于大数据的分布式处理。例如,在计算一个大规模矩阵的特征值时,数据可以分布到不同的工作线程中进行并行计算。
N = 1e5; % 矩阵的规模
A = rand(N, N); % 创建大规模矩阵
spmd
% 每个工作线程处理矩阵的一部分
localData = A(labindex:N/numlabs:N, :);
localSum = sum(localData, 1);
disp(['Worker ', num2str(labindex), ' computed partial sum.']);
end
在这个例子中,矩阵A被分割成多个子矩阵,每个工作线程计算自己负责部分的列和。
4. 使用GPU加速计算
除了使用多核CPU进行并行计算,MATLAB还支持通过GPU进行加速。利用gpuArray对象,用户可以将数据传输到GPU并在GPU上进行高效计算。
4.1 将数据移至GPU
% 将数据从CPU移到GPU
A = rand(1e6, 1);
gpuA = gpuArray(A);
% 在GPU上进行运算
gpuB = sin(gpuA) .* cos(gpuA);
在这个例子中,数据A被传输到GPU上,并在GPU上进行计算。GPU的并行计算能力大大加速了这些操作,特别是在大规模数据处理时,效果非常显著。
4.2 使用parallel.gpu进行并行计算
MATLAB还提供了parallel.gpu工具箱,支持GPU上的并行计算。使用parfor和GPU结合,可以进一步提升性能。
parpool('local', 4); % 启动CPU并行池
gpuDevice(1); % 使用第1个GPU
parfor i = 1:100
% 将计算任务发送到GPU
gpuData = gpuArray(rand(1000, 1000));
result = fft(gpuData);
end
5. 优化并行计算性能
虽然MATLAB提供了并行计算工具箱,合理地优化代码以减少计算开销和内存瓶颈也是至关重要的。以下是一些常见的性能优化技巧:
- 减少数据传输:在进行并行计算时,频繁的数据传输会影响性能。尽量将数据集中到最少的节点中进行计算。
- 最小化通信开销:在分布式计算中,避免频繁的工作线程间通信是提升性能的关键。
- 内存管理:使用合适的内存分配策略,避免过度使用内存或频繁的内存分配操作。
5.1 内存优化
% 使用single类型数据来减少内存占用
A = single(rand(1e7, 1));
6. 高效管理并行任务
在MATLAB中进行并行计算时,除了利用并行工具箱中的基本方法外,还可以通过高效管理任务,进一步提升计算效率。合理分配计算资源、优化任务调度等手段,对于大规模计算任务的加速至关重要。
6.1 使用parfeval进行异步计算
parfeval函数允许用户将计算任务提交给工作池并返回一个异步操作的句柄。这样,用户可以在等待任务完成时执行其他操作,极大地提升计算效率,特别是在处理多个独立任务时。
% 创建并行池
parpool('local', 4);
% 异步提交任务
futures = cell(1, 5);
for i = 1:5
futures{
i} = parfeval(@(x) x^2, 1, i); % 求每个i的平方
end
% 等待所有任务完成并获取结果
results = cell(1, 5);
for i = 1:5
[idx, result] = fetchNext(futures); % 获取下一个完成的任务结果
results{
idx} = result;
end
disp(results); % 输出所有计算结果
在这个例子中,parfeval允许我们并行执行五个独立的任务,并且在所有任务完成之前,我们可以继续执行其他操作。通过fetchNext函数,用户可以逐一获取完成的结果。
6.2 动态任务调度
当并行计算任务的规模或任务数量不均匀时,动态任务调度可以有效地减少计算资源的浪费。在MATLAB中,可以使用distributed任务或通过自定义调度策略来分配计算负载。
% 创建并行池
parpool('local', 4);
% 创建任务队列
tasks = repmat({
@taskFunction}, 1, 10); % 假设有10个任务
% 使用parfeval提交任务到池中
futures = cell(1, numel(tasks));
for i = 1:numel(tasks)
futures{
i} = parfeval(tasks{
i}, 1); % 每个任务返回一个结果
end
% 等待并获取结果
results = cell(1, numel(tasks));
for i = 1:numel(tasks)
[idx, result] = fetchNext(futures);
results{
idx} = result;
end
通过这种动态调度方式,我们能根据任务的完成情况和计算需求,动态分配计算资源,避免资源的空闲或过度使用。
6.3 自定义负载均衡
对于一些特定的任务,如处理极大规模的数据集,MATLAB的负载均衡功能可以帮助自动分配计算资源。然而,当任务特性较为复杂时,用户可以手动调整计算负载。自定义负载均衡策略有助于优化并行任务的执行。
% 假设有一个大的矩阵,想要按列进行处理
A = rand(1e6, 100);
% 手动分割任务
numTasks = 4; % 4个任务
colsPerTask = size(A, 2) / numTasks;
% 将每个任务分配给不同的工作线程
parfor t = 1:numTasks
colRange = (t-1)*colsPerTask + 1 : t*colsPerTask;
result = sum(A(:, colRange), 1); % 对每个任务的列进行求和
end
在这个示例中,任务被手动划分为四个子任务,每个子任务计算矩阵的不同列。通过自定义划分策略,可以实现任务的均匀分配,确保计算资源的合理利用。
7. 内存优化与并行计算
在并行计算中,内存的管理尤为关键。尤其是在进行大数据计算时,内存瓶颈可能会显著影响计算性能。MATLAB为用户提供了多种内存优化方法,使得在并行计算过程中能够最大化地利用内存资源。
7.1 使用内存映射文件
内存映射文件是一种通过将大文件直接映射到内存来避免将整个文件读入内存的方法。这对于处理大数据集尤其重要,可以节省大量内存开销并提高计算速度。
% 创建一个大数据集并将其保存为文件
A = rand(1e8, 1);
save('bigdata.mat', 'A');
% 使用内存映射文件读取大数据
m = matfile('bigdata.mat', 'Writable', false);
A = m.A; % 直接访问内存中的数据
通过内存映射文件,MATLAB能够直接在硬盘与内存之间交换数据,减少了加载整个数据集的内存需求,从而提高了大数据处理的效率。
7.2 精细控制内存分配
在并行计算中,避免频繁的内存分配和释放对于性能至关重要。可以通过预先分配内存并按需填充数据来避免不必要的内存重分配。
% 预先分配内存空间
A = zeros(1e7, 1);
% 使用并行计算填充数据
parfor i = 1:1e7
A(i) = sin(i); % 对每个元素赋值
end
通过预分配内存空间,避免了在每次循环时重新分配内存,能够有效减少内存管理的开销。
7.3 避免内存复制
在并行计算中,避免对大型数据集进行不必要的复制是提高效率的一个重要环节。使用MATLAB的gpuArray和distributed对象可以在多个工作线程之间共享数据,减少内存复制的需求。
% 使用gpuArray来避免内存复制
A = rand(1e6, 1);
gpuA = gpuArray(A); % 将数据移到GPU
% 在GPU上执行并行计算
parfor i = 1:10
gpuResult = fft(gpuA); % 在GPU上计算FFT
end
通过这种方式,数据只会在GPU上保持一份副本,从而避免了多个工作线程之间的数据复制。
8. 多核计算中的负载分配策略
在多核计算中,合理的负载分配策略对于提高计算效率至关重要。根据计算任务的特性和计算资源的配置,选择合适的负载分配策略能够显著减少计算时间。
8.1 均衡负载
对于大部分计算密集型的任务,最常见的负载分配策略是均衡负载,即将计算任务均匀地分配到各个核心上。通过这种方式,避免了某些核心空闲而其他核心繁忙的情况。
8.2 按需分配
对于某些任务,可能存在部分计算需求较大的情况。在这种情况下,按需分配策略能够根据每个计算任务的复杂度和计算需求,动态调整每个核心的负载。这种策略可以显著提高效率,特别是在任务不均匀时。
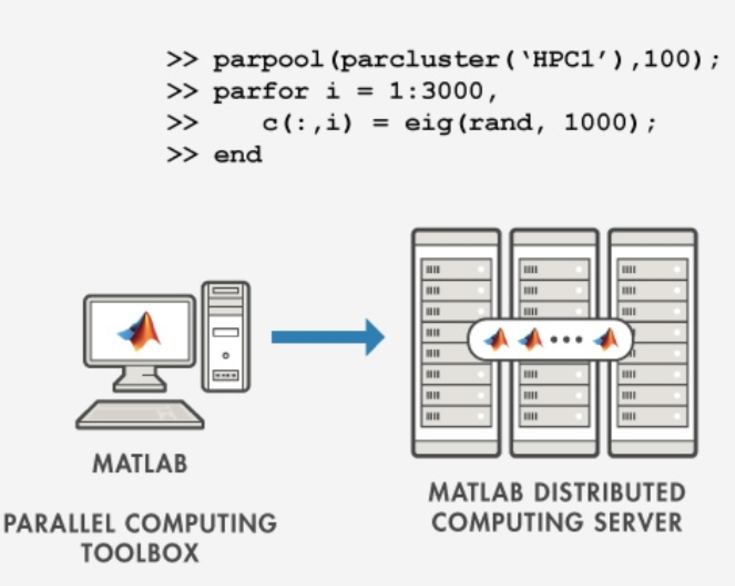
9. 在集群环境中的并行计算
在大规模集群环境中,MATLAB的并行计算工具箱同样能够充分发挥作用。通过在多个计算节点上分配任务,能够处理超大规模的数据集,极大地提高计算性能。
9.1 使用MATLAB Distributed Computing Server
MATLAB Distributed Computing Server(MDCS)是MATLAB的一个扩展,用于在集群或云环境中分配计算任务。通过MDCS,用户可以将计算任务分配到多个计算节点上,完成更大规模的数据处理。
% 配置MDCS并启动计算任务
parpool('myCluster', 16); % 在16个节点上进行并行计算
% 提交任务
spmd
data = labindex * rand(1000); % 每个节点生成一个数据块
result = sum(data); % 计算每个节点的和
end
在集群环境中,MDCS能够让MATLAB将任务分配到多个节点上进行处理,极大地提升计算能力和效率。
通过这些高级并行计算技巧和负载管理策略,MATLAB能够高效地处理大规模数据并充分利用多核、集群和GPU等计算资源。在实际应用中,用户应根据任务的特点,选择适合的并行计算方法和优化策略,以获得最佳的计算性能。