LLAMA-Factory,在经历了几个的坑之后,终于训练了完成了一次模型
(调通了??)
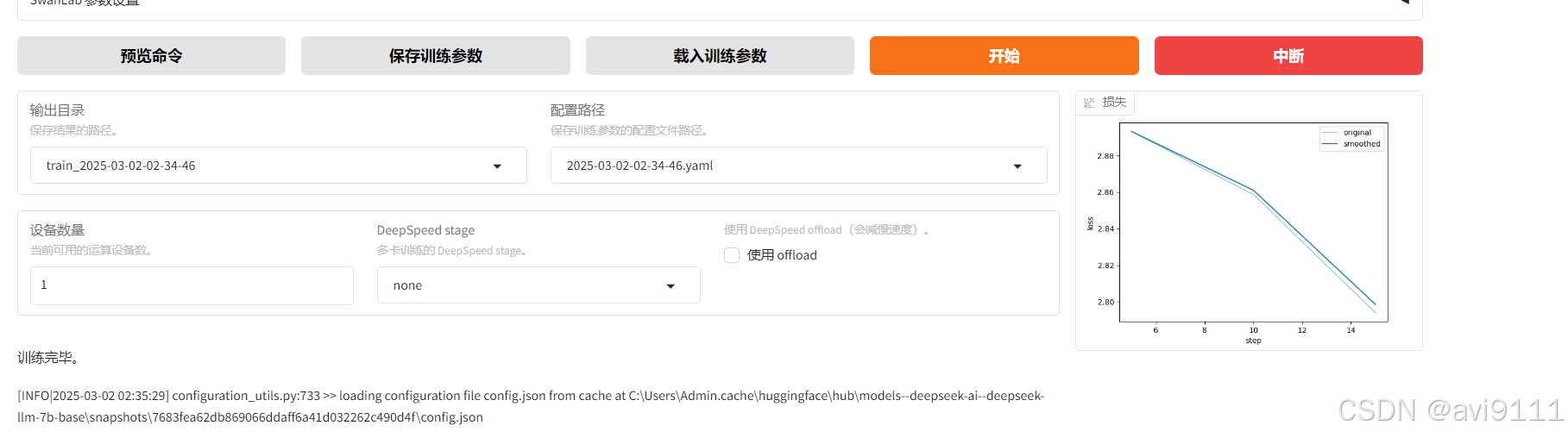
不过下个文章才详细解析每个坑
这里先用Ollama 测试一下模型的调用
cmd.exe只要输入这行命令即可,会下载4.5Gb的 blob文件
> ollama.exe run deepseek-r1:7b
(但因为之前的llama-factory的模型怎么用?)
《之后会补上吧》

Ollama 默认情况下会安装在 Windows 系统的 C 盘,但可以通过以下方式灵活调整安装路径和模型存储位置:
一、自定义安装路径 247
-
通过命令行指定安装目录
-
下载安装包
OllamaSetup.exe后,在安装包所在目录打开命令提示符(CMD)或 PowerShell。 -
输入命令指定目标路径(例如安装到 D 盘):
bash
复制
OllamaSetup.exe /DIR="D:\Ollama"
-
执行后,安装程序会将 Ollama 安装到指定目录,避免占用 C 盘空间。
-
-
验证安装路径
-
安装完成后,打开命令提示符输入
ollama --version,若显示版本号则安装成功313。
-
二、修改模型存储路径 246
-
设置环境变量
-
默认模型存储路径为
C:\Users\<用户名>\.ollama\models,可通过添加系统环境变量OLLAMA_MODELS修改存储位置:-
变量名:
OLLAMA_MODELS -
变量值:新路径(如
E:\Ollama\models)。
-
-
验证设置:在 CMD 中执行
echo %OLLAMA_MODELS%,确认路径显示正确10。
-
-
迁移已有模型文件
-
若已下载模型在默认路径,可手动将
C:\Users\<用户名>\.ollama\models文件夹复制到新路径,并删除原路径下的文件611。
-
三、已安装到 C 盘的迁移方法 46
-
移动安装目录
-
将
C:\Users\<用户名>\AppData\Local\Programs\Ollama整个文件夹复制到其他盘(如D:\Program\Ollama)。 -
修改系统环境变量
Path,将原路径替换为新路径(如D:\Program\Ollama)。 -
重启系统或重新运行 Ollama.exe 以生效。
-
-
更新模型路径
-
同步更新
OLLAMA_MODELS环境变量,指向新存储位置,并迁移模型文件(步骤同上)。
-
四、常见问题与注意事项
-
安装后命令无法识别
-
确保 Ollama 的安装路径已添加到系统环境变量
Path中313。
-
-
端口占用或网络访问限制
-
若需局域网访问,可设置
OLLAMA_HOST=0.0.0.0并开放防火墙端口(默认11434)13。
-
-
CUDA 加速支持
-
若需 GPU 加速,需提前安装 NVIDIA 驱动、CUDA Toolkit 和 cuDNN,确保硬件兼容性28。
-
LLAMA-Factory转ollama

以下是使用Ollama调用LLaMA-Factory训练后的模型的完整流程,结合具体步骤和环境配置要求:
一、模型训练与导出
-
使用LLaMA-Factory完成模型微调
-
在LLaMA-Factory的Web界面中选择基座模型(如Llama3-8B、Qwen2.5-7B等),加载自定义数据集(需符合Alpaca或ShareGPT格式),配置微调参数(如LoRA、学习率、训练轮数等),启动训练71112。
-
训练完成后,模型检查点默认保存在
saves目录下(如saves/Qwen2.5-7B-Instruct/lora/train_xxx)411。
-
-
导出全精度模型或LoRA适配器
-
若使用LoRA微调,需将适配器与基座模型合并。通过执行
llamafactory-cli export命令合并生成全精度模型文件(格式为.safetensors或.bin)611。 -
示例命令:
llamafactory-cli export examples/merge_lora/qwen_lora_sft.yaml
-
二、模型格式转换
-
安装llama.cpp工具
-
从GitHub克隆llama.cpp仓库,安装Python依赖:
git clone https://github.com/ggerganov/llama.cpp cd llama.cpp pip install -r requirements/requirements-convert_lora_to_gguf.txt ```:cite[3]:cite[5]
-
-
转换为GGUF格式
-
使用
convert_lora_to_gguf.py脚本将合并后的模型转换为Ollama支持的GGUF格式:python convert_lora_to_gguf.py --base "基座模型路径" "微调模型路径" --outfile "输出路径/模型名.gguf"例如:
python convert_lora_to_gguf.py --base "models/Qwen2.5-7B-Instruct" "saves/Qwen2.5-7B-Instruct/lora/train_xxx" --outfile "output/my_model.gguf" ```:cite[1]:cite[5]:cite[9]
-
-
量化(可选)
-
使用
ollama/quantize工具对GGUF模型进行量化(如q4_0、q5_K等),减小模型体积:docker run --rm -v /path/to/model:/repo ollama/quantize -q q4_0 /repo ```:cite[5]
-
三、创建Ollama Modelfile
-
编写Modelfile
-
在模型目录下创建
Modelfile,指定基础模型、适配器路径、模板和参数。示例:FROM qwen2.5:7b # 基座模型名称 ADAPTER ./my_model.gguf # 转换后的GGUF文件路径 TEMPLATE """{ { if .System }}<|im_start|>system { { .System }}<|im_end|> { { end }}{ { if .Prompt }}<|im_start|>user { { .Prompt }}<|im_end|> { { end }}<|im_start|>assistant """ PARAMETER temperature 0.7 PARAMETER stop "<|im_end|>" ```:cite[5]:cite[8]
-
四、导入并运行模型
-
创建Ollama模型
-
执行命令导入自定义模型:
ollama create my_model -f ./Modelfile成功后会显示
Successfully created model 'my_model'46。
-
-
启动模型对话
-
运行模型进行测试:
ollama run my_model输入问题验证输出是否符合微调目标412。
-
五、常见问题与优化
-
CUDA加速支持
-
若需GPU加速,确保已安装NVIDIA驱动、CUDA Toolkit和cuDNN,并在转换时指定
--outtype f16或f32以启用浮点计算35。
-
-
模型路径与权限
-
若Ollama无法识别模型文件,检查环境变量
OLLAMA_MODELS是否指向正确目录,并确保文件权限开放46。
-
-
量化与性能平衡
-
量化等级越高(如q8_0),模型精度损失越小但体积更大;q4_0适合低显存设备但可能影响生成质量67。
-
总结
通过LLaMA-Factory微调模型后,需通过格式转换生成GGUF文件并编写Modelfile配置,最终通过Ollama导入运行。关键步骤包括:模型合并→格式转换→Modelfile定义→Ollama部署。若需进一步优化,可结合量化技术或调整微调参数提升效果。更多细节可参考LLaMA-Factory和Ollama的官方文档711。
OLLAMA run的几个模型命令
| ollama run deepseek-r1:7b | |
| ollama run huihui_ai/deepseek-41-abliterated:32b | 32b还是挺卡的 |
GPU加速尝试
Windows Subsystem for Linux (WSL, Ubuntu) 最新安装教程(2024.11 更新)-CSDN博客
一文教你在windows上实现ollama+open webui、外网访问本地模型、ollama使用GPU加速_ollama gpu-CSDN博客
WSL Update Failed - #7 by brianivander - Docker Desktop - Docker Community Forums
https://stackoverflow.com/questions/78879806/docker-desktop-wsl-update-failed
参考学习视频
https://www.youtube.com/watch?v=L1QkuWK4U9g&t=572s
https://www.youtube.com/watch?v=LPmI-Ok5fUc
其他,再找到的一些资料
LlamaFactory Lora 合并大模型,GGUF 转换与 Ollama 部署Open_WebUI全流程_llama factory lora权重合并 转gguf-CSDN博客