
目录
二、图片转文本(image-to-text/image-text-to-text)
一、引言
pipeline(管道)是huggingface transformers库中一种极简方式使用大模型推理的抽象,将所有大模型分为音频(Audio)、计算机视觉(Computer vision)、自然语言处理(NLP)、多模态(Multimodal)等4大类,28小类任务(tasks)。共计覆盖32万个模型

今天介绍多模态的第四篇:图片转文本(image-to-text/image-text-to-text),在huggingface库内可以使用pipeline两行代码部署的图片转文本(image-to-text)模型有700个,因为2024年图片多模态大模型的兴起,在图片文本转文本(image-text-to-text)任务中,模型有5000+。关于图片文本转文本(image-text-to-text),之前写了很多篇,可以参考我之前的两篇文章:
【机器学习】GLM-4V:图片识别多模态大模型(MLLs)初探
【机器学习】阿里Qwen-VL:基于FastAPI私有化部署你的第一个AI多模态大模型
今天主要对如何使用pipeline两行代码部署的图片转文本(image-to-text)模型进行讲解。
二、图片转文本(image-to-text/image-text-to-text)
2.1 概述
图片转文本(image-to-text/image-text-to-text)模型从给定图像输出文本。图像字幕或光学字符识别可视为图像转文本的最常见应用。
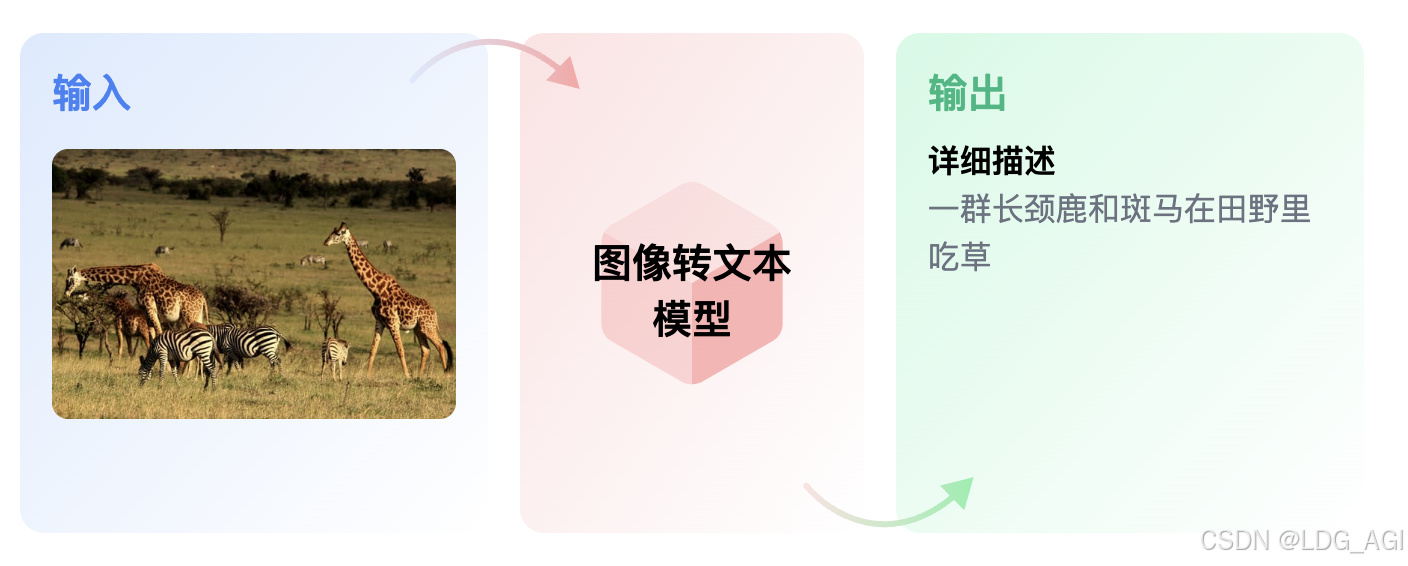
图片特征提取与文本生成在技术上主要有2个流派:
- ViT+GPT2:上一篇讲的是图片特征提取,主要讲到了Vision Transformer (ViT)方法,但ViT仅有encode结构,只能将图片转换为特征向量,无法进行文本生成,本篇进一步将ViT和GPT2融合,本质上是在ViT上新增一个decode结构,提供文本补全的功能。(Qwen-VL、GLM-4V)等均属于这个流派。
- CLIP+BLIP:同样的,另一个图片特征提取流派:对比学习CLIP也是仅有encode,无法进行文本生成,于是Salesforce团队研发了BLIP,在CLIP的基础上新增decode结构,具体论文见BLIP)。
为了保证技术连贯性,今天在上一篇ViT基础上,讲解ViT+GPT2。
2.2 nlpconnect/vit-gpt2
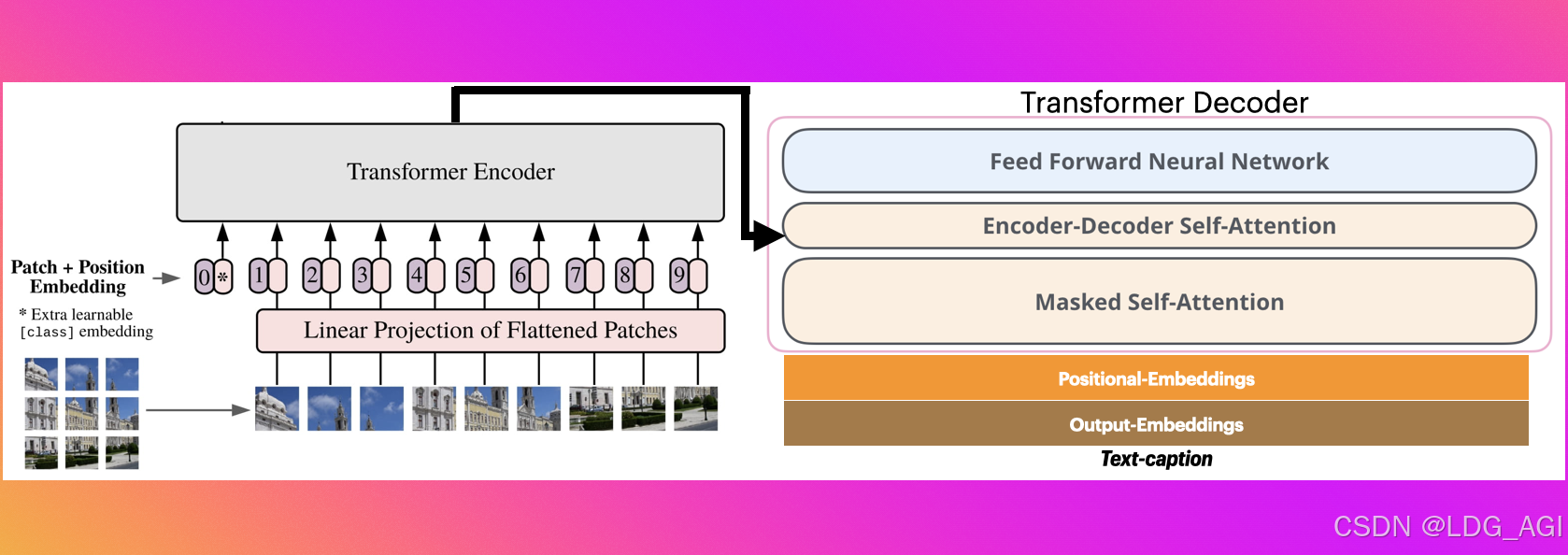
ViT部分:首先将图片切分成大小相等的块序列(分辨率为16*16),对每个图片块进行线性嵌入添加位置信息,通过喂入一个标准的transformer encoder结构进行特征交叉。
GPT部分:将文本token向量化后,经过embedding层、Masked Self-Attention层,在Encoder-Decoder Self-Attention层与ViT的Transformer Encoder输出相连接。
这样ViT与GPT可以进行联合学习,完成图片到文本的转换。
2.3 pipeline参数
2.3.1 pipeline对象实例化参数
- model(PreTrainedModel或TFPreTrainedModel)— 管道将使用其进行预测的模型。 对于 PyTorch,这需要从PreTrainedModel继承;对于 TensorFlow,这需要从TFPreTrainedModel继承。
- tokenizer ( PreTrainedTokenizer ) — 管道将使用其对模型的数据进行编码的 tokenizer。此对象继承自 PreTrainedTokenizer。
- image_processor ( BaseImageProcessor ) — 管道将使用的图像处理器来为模型编码数据。此对象继承自 BaseImageProcessor。
- modelcard(
str或ModelCard,可选) — 属于此管道模型的模型卡。- framework(
str,可选)— 要使用的框架,"pt"适用于 PyTorch 或"tf"TensorFlow。必须安装指定的框架。如果未指定框架,则默认为当前安装的框架。如果未指定框架且安装了两个框架,则默认为 的框架
model,如果未提供模型,则默认为 PyTorch。- task(
str,默认为"")— 管道的任务标识符。- num_workers(
int,可选,默认为 8)— 当管道将使用DataLoader(传递数据集时,在 Pytorch 模型的 GPU 上)时,要使用的工作者数量。- batch_size(
int,可选,默认为 1)— 当管道将使用DataLoader(传递数据集时,在 Pytorch 模型的 GPU 上)时,要使用的批次的大小,对于推理来说,这并不总是有益的,请阅读使用管道进行批处理。- args_parser(ArgumentHandler,可选) - 引用负责解析提供的管道参数的对象。
- device(
int,可选,默认为 -1)— CPU/GPU 支持的设备序号。将其设置为 -1 将利用 CPU,设置为正数将在关联的 CUDA 设备 ID 上运行模型。您可以传递本机torch.device或str太- torch_dtype(
str或torch.dtype,可选) - 直接发送model_kwargs(只是一种更简单的快捷方式)以使用此模型的可用精度(torch.float16,,torch.bfloat16...或"auto")- binary_output(
bool,可选,默认为False)——标志指示管道的输出是否应以序列化格式(即 pickle)或原始输出数据(例如文本)进行。
2.3.2 pipeline对象使用参数
- inputs(
str、或List[str])——管道处理三种类型的图像:PIL.ImageList[PIL.Image]
- 包含指向图像的 HTTP(s) 链接的字符串
- 包含图像本地路径的字符串
- 直接在 PIL 中加载的图像
该管道可以接受单个图像或一批图像。
- max_new_tokens(
int,可选)— 生成的最大令牌数量。默认情况下将使用generate默认值。- generate_kwargs(
Dict,可选)——传递它以将所有这些参数直接发送到generate允许完全控制此函数。
2.4 pipeline实战
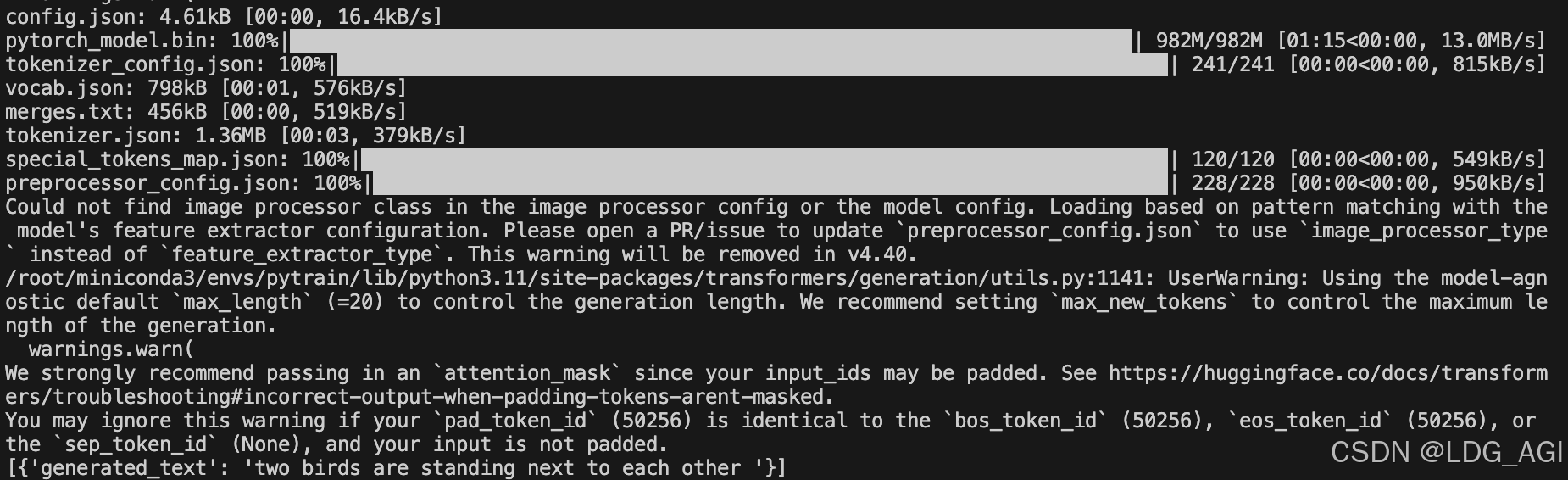
基于pipeline的图片转文本(image-to-text)任务,采用nlpconnect/vit-gpt2-image-captioning进行图片转文本,代码如下:

import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
from transformers import pipeline
image_to_text = pipeline("image-to-text", model="nlpconnect/vit-gpt2-image-captioning")
output=image_to_text("./parrots.png")
print(output)
执行后,自动下载模型文件并进行识别:
2.5 模型排名
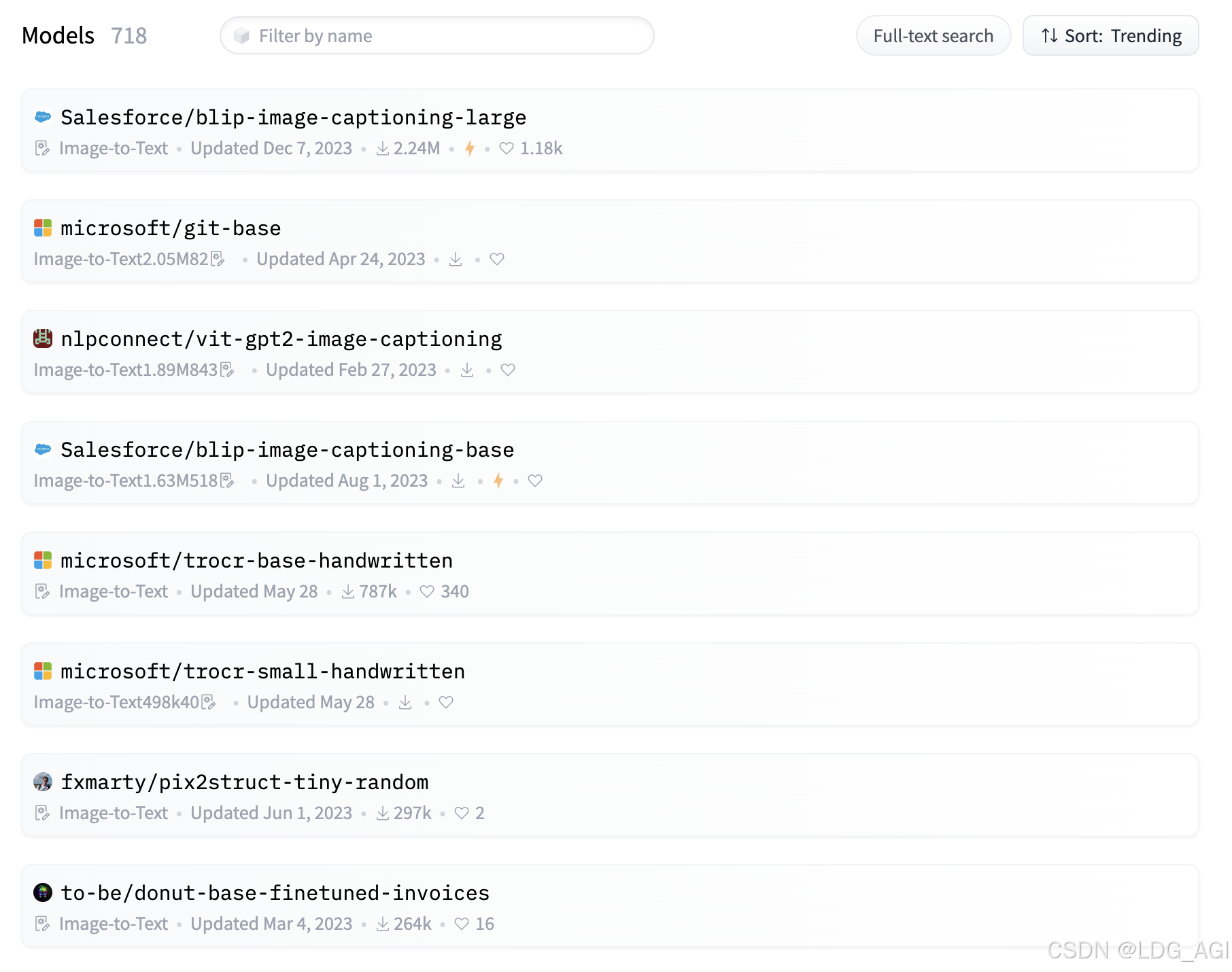
在huggingface上,我们将图片转文本(image-to-text)模型按热度从高到低排序,总计700个模型,ViT-GPT2排名第三,CLIP的变体BLIP排名第一。
三、总结
本文对transformers之pipeline的图片转文本(image-to-text)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline使用文中的2行代码极简的使用多模态中的图片转文本(image-to-text)模型。
期待您的3连+关注,如何还有时间,欢迎阅读我的其他文章:
《Transformers-Pipeline概述》
【人工智能】Transformers之Pipeline(概述):30w+大模型极简应用
《Transformers-Pipeline 第一章:音频(Audio)篇》
【人工智能】Transformers之Pipeline(一):音频分类(audio-classification)
【人工智能】Transformers之Pipeline(二):自动语音识别(automatic-speech-recognition)
【人工智能】Transformers之Pipeline(三):文本转音频(text-to-audio/text-to-speech)
【人工智能】Transformers之Pipeline(四):零样本音频分类(zero-shot-audio-classification)
《Transformers-Pipeline 第二章:计算机视觉(CV)篇》
【人工智能】Transformers之Pipeline(五):深度估计(depth-estimation)
【人工智能】Transformers之Pipeline(六):图像分类(image-classification)
【人工智能】Transformers之Pipeline(七):图像分割(image-segmentation)
【人工智能】Transformers之Pipeline(八):图生图(image-to-image)
【人工智能】Transformers之Pipeline(九):物体检测(object-detection)
【人工智能】Transformers之Pipeline(十):视频分类(video-classification)
【人工智能】Transformers之Pipeline(十一):零样本图片分类(zero-shot-image-classification)
【人工智能】Transformers之Pipeline(十二):零样本物体检测(zero-shot-object-detection)
《Transformers-Pipeline 第三章:自然语言处理(NLP)篇》
【人工智能】Transformers之Pipeline(十三):填充蒙版(fill-mask)
【人工智能】Transformers之Pipeline(十四):问答(question-answering)
【人工智能】Transformers之Pipeline(十五):总结(summarization)
【人工智能】Transformers之Pipeline(十六):表格问答(table-question-answering)
【人工智能】Transformers之Pipeline(十七):文本分类(text-classification)
【人工智能】Transformers之Pipeline(十八):文本生成(text-generation)
【人工智能】Transformers之Pipeline(十九):文生文(text2text-generation)
【人工智能】Transformers之Pipeline(二十):令牌分类(token-classification)
【人工智能】Transformers之Pipeline(二十一):翻译(translation)
【人工智能】Transformers之Pipeline(二十二):零样本文本分类(zero-shot-classification)
《Transformers-Pipeline 第四章:多模态(Multimodal)篇》
【人工智能】Transformers之Pipeline(二十三):文档问答(document-question-answering)
【人工智能】Transformers之Pipeline(二十四):特征抽取(feature-extraction)
【人工智能】Transformers之Pipeline(二十五):图片特征抽取(image-feature-extraction)
【人工智能】Transformers之Pipeline(二十六):图片转文本(image-to-text)
【人工智能】Transformers之Pipeline(二十七):掩码生成(mask-generation)
【人工智能】Transformers之Pipeline(二十八):视觉问答(visual-question-answering)