24年12月来自上海AI实验室、北大和香港中文大学的论文“Predictive Inverse Dynamics Models Are Scalable Learners For Robotic Manipulation”。
目前,在机器人操作中学习可扩展策略的努力主要分为两类:一类侧重于“动作”,涉及从大量的机器人数据中克隆行为;另一类强调“视觉”,通过使用大规模视觉数据集预训练表示或生成模型(也称为世界模型)来增强模型泛化。本文提出一种端到端范式,该范式使用以机器人预测视觉状态为条件的逆动力学模型来预测动作,称为预测逆动力学模型 (PIDM)。通过闭合视觉和动作之间的循环,端到端 PIDM 可以成为更好的可扩展动作学习者。在实践中,用 Transformers 来处理视觉状态和动作,并将模型命名为 Seer。它最初在 DROID 等大规模机器人数据集上进行预训练,并且可以通过少量微调数据适应真实世界场景。得益于大规模端到端训练以及视觉与动作之间的协同作用,Seer 在模拟和真实世界实验中的表现均显著优于之前的方法。它在 LIBERO-LONG 基准上实现 13% 的改进,在 CALVIN ABC-D 上实现 21% 的改进,在真实世界任务中实现 43% 的改进。值得注意的是,Seer 在 CALVIN ABC-D 基准上创造不俗成绩,平均长度达到 4.28,并且在真实世界场景中对新目标、光照条件和高强度干扰下的环境,表现出优异的泛化能力。
PIDM 和 Seer 如图所示:(a)从大规模机器人数据进行端到端的简单行为克隆,或(b)使用解耦的视觉预测和逆动力学模型来设定目标和指导动作, (c)端到端 PIDM,即 Seer 模型。
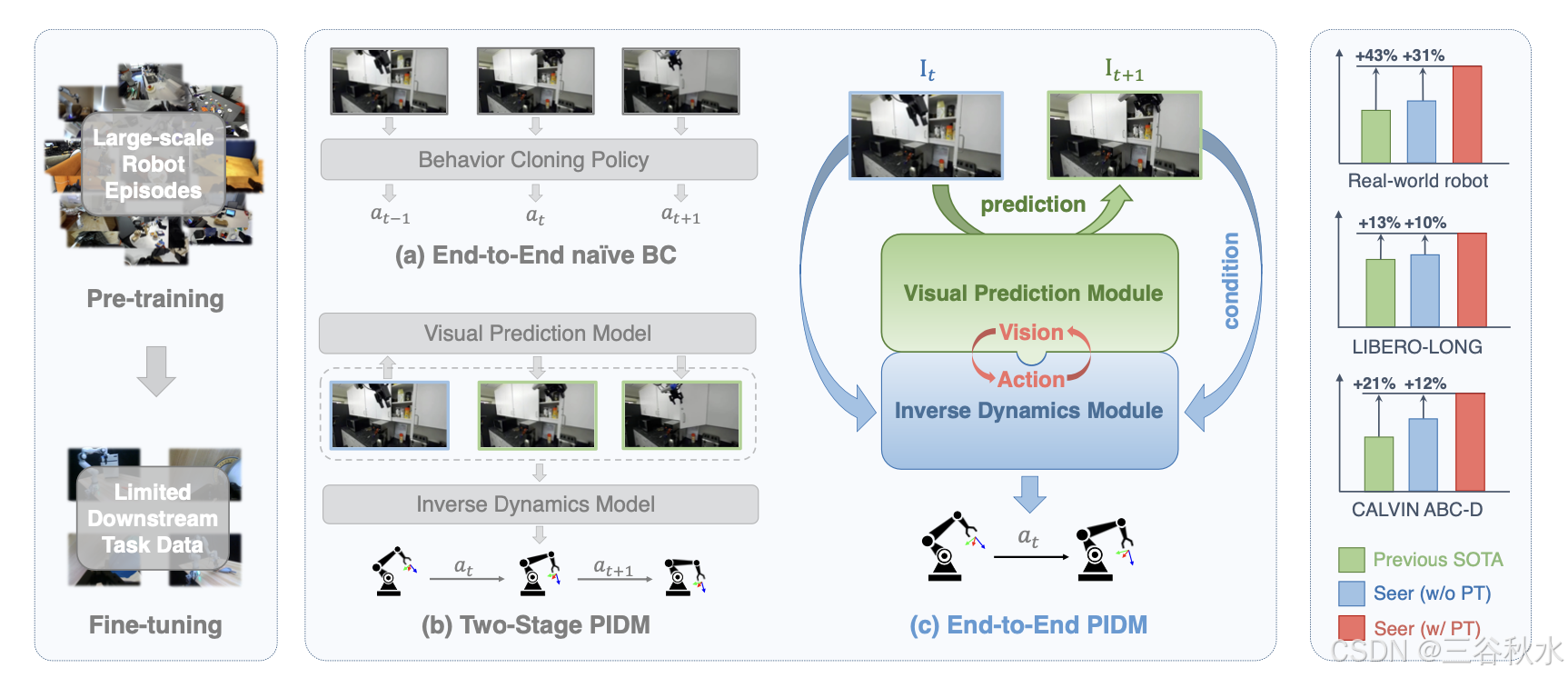
给定一个包含各种操作演示的大规模数据集 D_1 = {(l, o_t, s_t, a_t)T_i}N_1 和一个较小的下游数据集 D_2 = {(l, o_t, s_t, a_t)T_j}N_2(其中 N_1 >> N_2),目标是通过对 D_1 进行有效的预训练,然后对 D_2 进行微调,来提高下游任务的性能。每个轨迹 {(l, o_t, s_t, a_t)^T} 提供时间步长 t、语言指令 l、从手-上-眼和基-上-眼获得的 RGB 图像 o_t、机器人状态 s_t 和机器人动作 a_t,其中包括手臂动作 a_arm(6D 姿势)和夹持器动作 a_gripper(打开或关闭)。值得注意的是,当前大量的预训练机器人数据可能包含不完整的语言注释 l 和与任务无关的动作 a_t,例如环境中的随机探索 (Mees,2022)。
然而,由于特定的设计选择,本文提出的 Seer 可以有效地处理这种情况。
视觉:条件视觉预见。一个关键的见解是,信息丰富的未来状态可以指导行动。因此,提出条件视觉预见 f_fore,以有效地预测未来的视觉表现。Seer 将语言指令或机器人状态形式的目标 g 与历史观察 h_t 作为输入,并预测时间步骤 t + n 的 RGB 图像,用 oˆ_t+n 表示。
历史观测值 h_t 包括过去 m 个时间步内的 RGB 图像 o_t−m+1:t 和机器人状态 s_t−m+1:t。由于 RGB 图像中包含的信息丰富、数量众多且易于获取,选择它们作为未来的代表。按照 (He et al., 2022),损失函数 L_fore 计算像素级的均方误差 (MSE)。
动作:逆动态预测。给定两个按时间顺序排列的观测值 o_t 和 o_t+1,逆动态预测估计中间动作 aˆ_t。在这里,扩展逆动态 f_inv 以预测给定目标 g、历史观测值 h_t 和 o_t+n 的动作序列 aˆ_t:t+n−1。具体来说,用潜空间中的预测表示 ˆo^l_t+n 替换真值 o_t+n。
损失函数 L_inv 包括手臂动作损失 L_arm(平滑L1损失)和夹持器动作损失 L_gripper(二元交叉熵)。
视觉与动作之间的闭环。Seer 通过训练有效地将条件视觉预见与逆动力学预测相结合,从而充分利用机器人数据中的视觉和动作信息。具体来说,f_fore 结合明确的目标 g 和历史观察 h_t 来预测未来的 RGB 图像 oˆ_t+n。潜表示 ˆo^l_t+n(走向 oˆ_t+n)和 h_t 通过 f_inv 促进动作预测。由于 Seer 的模型设计,所有这些过程都以端到端的方式执行。
与单步动作预测相比,预测多步动作可提供时间动作一致性和对空闲动作的鲁棒性 (Chi et al., 2023)。在推理过程中,可以丢弃第一步以外的动作,也可以应用时间集成技术来计算多步动作的加权平均值。
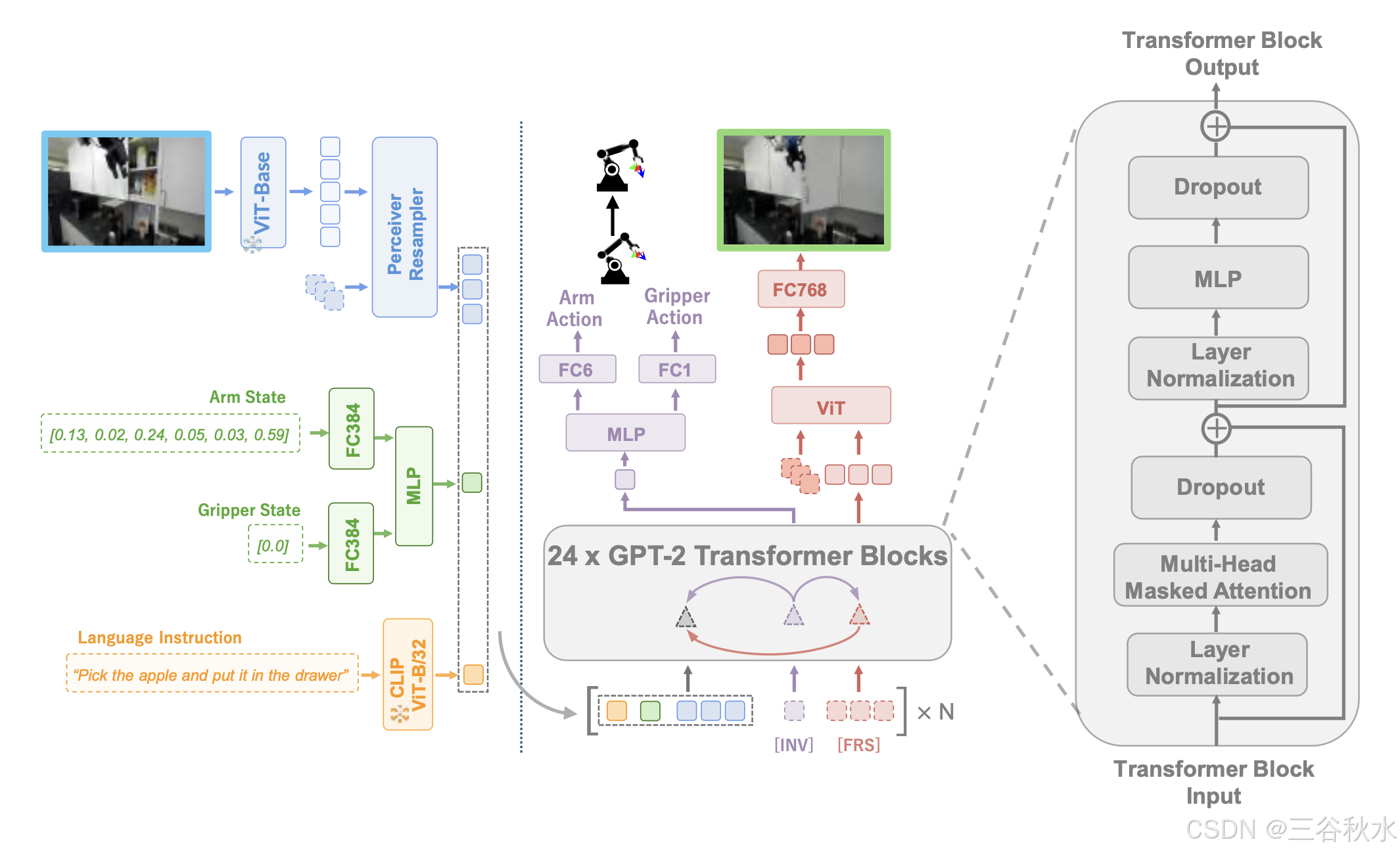
输入 token 化器。如图所示,该模型处理三种类型的输入:语言、图像和机器人状态。使用不同的编码器对每种模态进行相应的token化。对于语言输入,首先对文本进行token化,然后使用 CLIP 文本编码器 (Radford,2021) 获取文本嵌入,随后使用线性层将其投影到潜在空间中。对于图像输入,首先对图像进行修补并通过预训练的视觉Transformer (ViT) (He,2022) 生成视觉嵌入。由于 ViT 每幅图像产生数百个嵌入,给Transformer主干带来巨大的计算负担,并且许多视觉信息与操作任务无关,因此使用感知器重采样器 (Alayrac,2022) 来提取与任务相关的视觉特征并减少图像token的数量。对于机器人状态,使用多层感知器 (MLP) 将其编码为状态token。
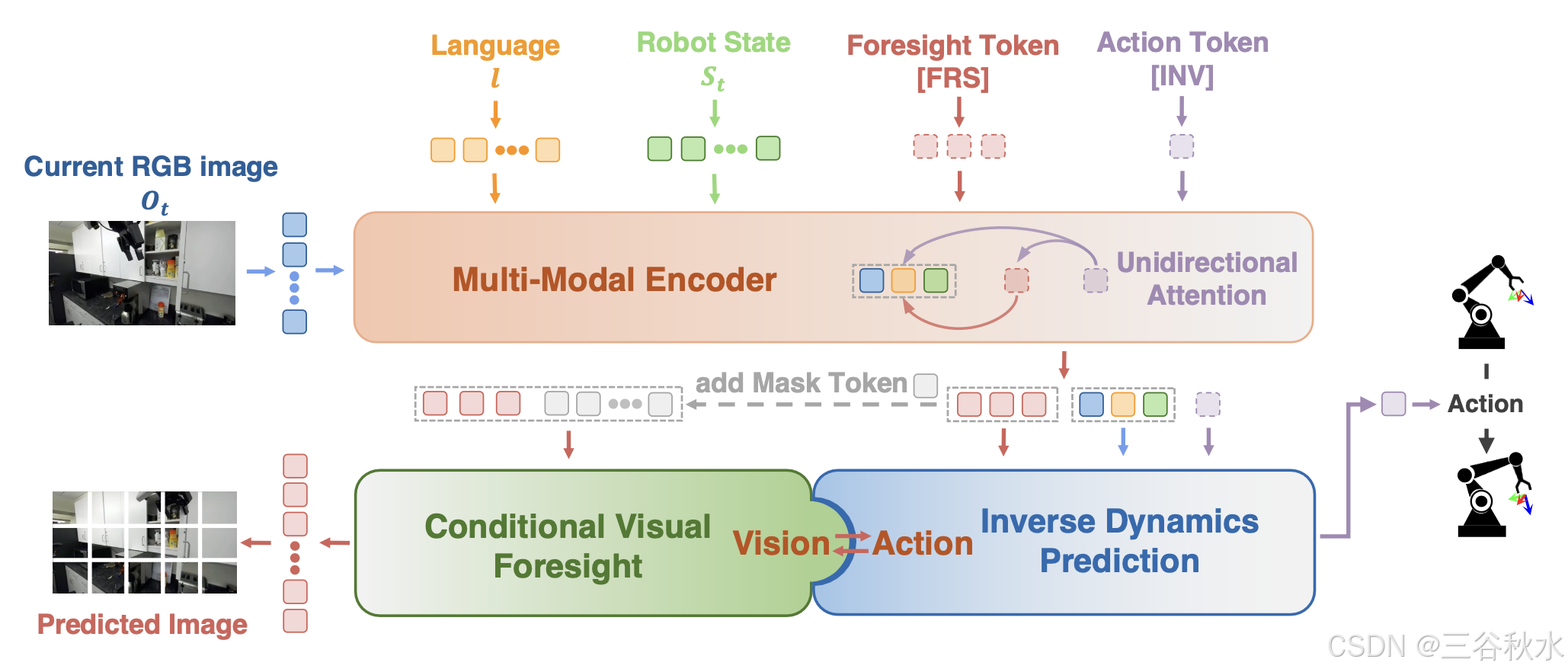
多模态编码器。模型中的多模态编码器基于 GPT-2 风格的Transformer架构。在将顺序的语言-图像-状态对输入到Transformer之前,读出token [INV] 和 [FRS] 附加到每个时间步。这些读出token关注来自不同模态的嵌入,用作条件视觉预见和逆动态预测的图像和动作潜变量。为了结合时间信息,还为每个时间步的token添加可学习的位置嵌入。
[FRS] token旨在促进条件视觉预见,对应于前面提到的 ˆo^l_t+n。它关注语言、历史图像和状态token。相反,[INV] token根据预测的视觉预见执行逆动态预测,关注输入token,以及至关重要的预见token [FRS]。Transformer 编码器中的这种特殊的单向注意掩码(如上图所示)带来两个好处。首先,这将有助于 [INV] token在多层网络中深度整合过去和未来的预测信息。其次,这通过潜空间中的融合实现端到端训练范式。
读出解码器。由多模态编码器编码后,由 [INV] 和 [FRS] 读出 token 生成的动作和图像潜信息,输入到读出解码器中以预测图像和动作。动作解码器利用 MLP 将动作潜信息转换为动作向量。对于图像解码,采用视觉 Transformer (ViT) 作为图像解码器,遵循 (He et al., 2022)。图像解码器将图像潜信息与掩码 tokens 一起作为输入。经过 ViT 处理后,每个掩码 token 对应的输出,代表图像的特定部分。
训练。训练目标、条件视觉预见和逆动力学预测在预训练和微调之间保持一致。值得注意的是,这两个阶段之间存在两个模型配置的关键差异。首先,在机器人预训练数据集中,缺少语言指令的情况很常见。在这种情况下,在预训练期间,未来时间步 t + n + 1 的机器人状态 token 充当目标。[FRS] 将关注它而不是语言 token,确保 [FRS] 获取明确的信息。其次,预训练数据可能包括随机或无意义的行为,例如环境探索。因此,[INV] 和 [FRS] token 不会关注先前的图像和机器人状态 token,以防止过拟合任何特定行为。
推理。在推理过程中,完整的语言指令 l、机器人状态 s 和图像观察 o 作为输入提供。[FRS] token 关注历史图像、状态和语言指令 token,以执行条件视觉预见,预测未来图像。反过来,[INV] token 关注输入 token 和另一个预见 [FRS] token,以执行逆动态预测,输出动作。
模型。在整个训练过程中,预训练的视觉和文本编码器保持冻结,总共包含 251M 个不可训练参数。其余组件完全可训练。Seer 的标准版拥有 65M 个可训练参数。此外,扩大参数大小并开发 Seer-Large 变型,其中包含 315M 个可训练参数。除非另有说明,否则提到的 Seer 是指具有 65M 个可训练参数的版本。
模拟实验如下。
在两个模拟基准 LIBERO-LONG(Liu,2024)、CALVIN ABC-D(Mees,2022)上进行实验。目标是回答:1)该方法在具有挑战性的模拟基准上表现如何?2)随着下游微调数据量的变化,流水线是否保持一致的有效性?3)Seer 中的训练目标是否有效?
真实实验如下。
在六项实际真实世界任务上评估 Seer,其中四项侧重于泛化,两项侧重于高精度和丰富联系。旨在回答:1)Seer 在实际真实世界任务中是否有效?2)预训练是否在强烈干扰下持续提高性能?
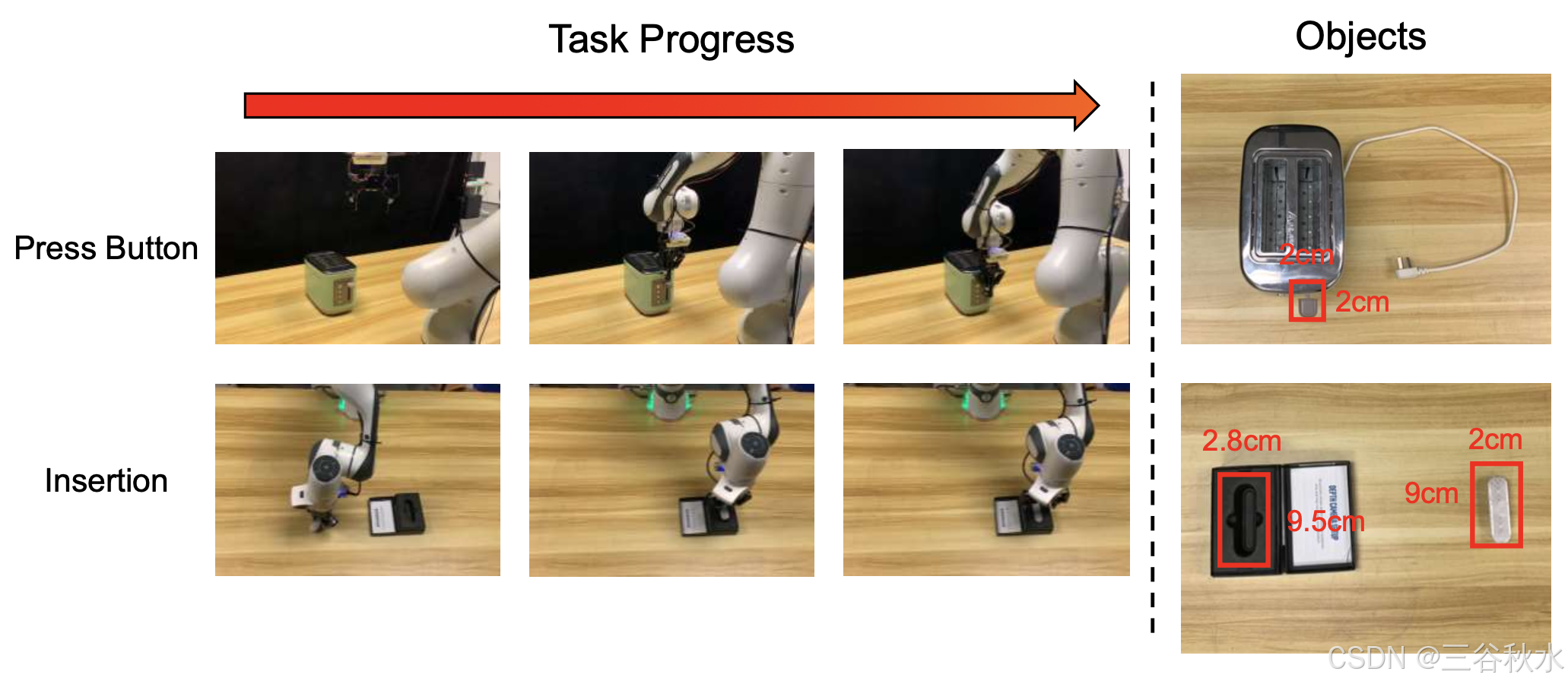
对配备 Robotiq-2f-85 夹持器的 Franka Research 3 机器人进行六项任务评估,使用两个 RealSense D435i 摄像头,配置为 Eye-on-Hand 和 Eye-on-Base 进行视觉输入。如图显示四个以泛化为中心的任务:

下图显示两个高精度、接触丰富的任务:
如图所示,Seer 由以下模块组成:图像编码器、感知器重采样器、机器人状态编码器、语言编码器、Transformer主干、动作解码器和图像解码器。