前言:零基础学Python:Python从0到100最新最全教程。 想做这件事情很久了,这次我更新了自己所写过的所有博客,汇集成了Python从0到100,共一百节课,帮助大家一个月时间里从零基础到学习Python基础语法、Python爬虫、Web开发、 计算机视觉、机器学习、神经网络以及人工智能相关知识,成为学业升学和工作就业的先行者!
【优惠信息】 • 新专栏订阅前500名享9.9元优惠 • 订阅量破500后价格上涨至19.9元 • 订阅本专栏可免费加入粉丝福利群,享受:
- 所有问题解答
-专属福利领取欢迎大家订阅专栏:零基础学Python:Python从0到100最新最全教程!

一、问题背景
- 单图像超分辨率(SISR)是计算机视觉和图像处理领域中的经典问题,目标是从输入的低分辨率图像重建高分辨率图像。
- 深度学习方法在SISR中取得了显著成果,但大多数方法通过构建更复杂的网络来提高性能,这需要大量的计算资源,限制了超分辨率技术的实际应用。
二、方法概述:
本文提出了一种名为RNET(Residual Network with Efficient Transformer)的网络,该网络结合了三种有效的设计元素:
1. 使用蓝图可分离卷积代替传统卷积,减少计算负担。
2. 提出局部特征提取的残差连接结构,简化特征聚合,加速推理。
3. 将空间注意和通道注意机制被整合到我们的模型中。
注意力机制通过让模型关注图像关键区域提升了识别精度,而轻量级残差网络通过减少参数和计算量,实现了在低资源消耗下的优秀性能。 结合注意力机制与轻量级残差网络,既能让模型能够更高效地关注输入数据中的关键信息,提升模型处理复杂模式的能力,还通过减少参数和计算复杂度,保持了模型的轻量级特性,达到在有限资源下同时保持高效率和高性能的目标。
三、相关工作
-
基于CNN的图像超分辨率:
- SRCNN:Dong等人首次将深度卷积神经网络应用于图像超分辨率任务,使用三层卷积神经网络来映射低分辨率(LR)和高分辨率(HR)图像之间的相关性。
- VDSR:Kim等人提出了一个19层的卷积神经网络来实现SISR。
- EDSR:Lim等人修改了SRResNet,构建了一个更深更宽的残差网络,具有大量的可学习参数,显著提高了SR性能。
- 其他方法:包括增加网络深度、使用残差连接、探索不同网络框架(如循环神经网络、图神经网络、生成对抗网络)等。
-
高效的超分辨率方法:
- DRCN和DRRN:通过引入递归层来共享参数,减少计算量。
- LapSRN:结合了传统的图像算法和深度学习,使用拉普拉斯金字塔实现实时重建。
- MemNet:使用门控机制连接深度特征和浅层信息。
- IDN和IMDN:通过组卷积和特征融合,以及基于IDN的信息蒸馏策略,逐步提取层次化特征,提高模型效率。
-
视觉变换器(Vision Transformer):
- 变换器在自然语言处理领域的成功也吸引了计算机视觉领域的关注,核心思想是自注意力机制,捕捉序列元素间的长期信息。
- ViT:首次用变换器替代卷积操作,将2D图像块展平为向量并输入变换器。
- SwinIR:引入了Swin Transformer到SISR中,展示了变换器在超分辨率任务中的潜力。
- DPT:引入了一种新的自注意力机制,考虑全局空间角度关系。
-
RNET提出的创新点:
- BSConv:蓝图可分离卷积,改进了深度可分离卷积,通过更好地利用内核内部的相关性来减少冗余。
- HFEB:混合特征提取块,结合了局部特征提取、空间注意力和通道注意力机制。
- ET模块:高效变换器模块,包括MBTA和GBFN,减少了计算压力,同时保留了全局特征提取能力。
这些工作和方法为RNET的提出提供了理论和技术基础,同时也展示了SISR领域内研究的多样性和深度。RNET通过结合这些现有技术和自身的创新设计,旨在实现更高效、更轻量的图像超分辨率处理。
四、模型分析
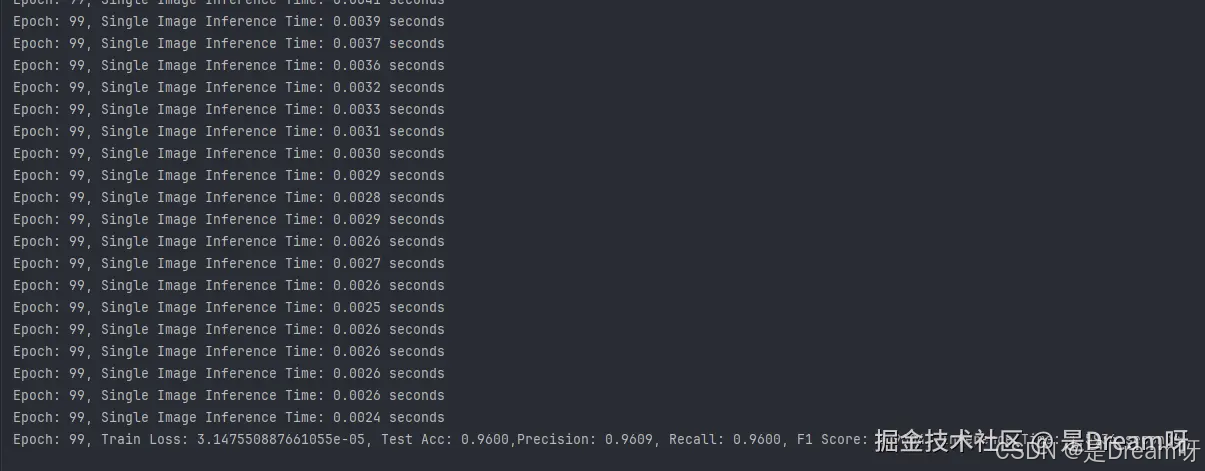
1. 网络结构:
RNET由三个主要部分组成:浅层特征提取模块、深层特征提取模块和图像重建模块。
- 浅层特征提取模块:使用BSConv获取浅层特征。
- 深层特征提取模块:由多个直接连接的混合特征提取块(HFEB)组成。
- 图像重建模块:使用3×3标准卷积和像素重排上采样融合特征,恢复到HR尺寸。
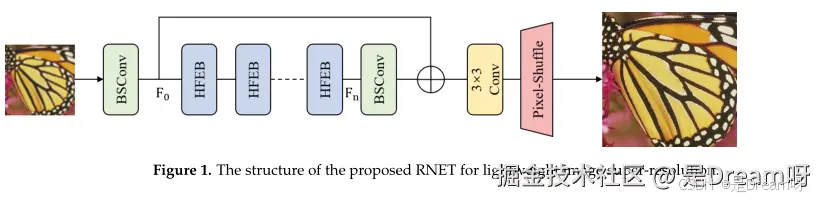
2. 混合特征提取块(HFEB):
HFEB包含三个主要部分:局部特征提取模块、混合注意力机制和高效变换器,使用BSConv代替传统的卷积,大大减少了计算量。此外使用局部残余连接代替可分离的蒸馏结构,局部残差结构可以在保持模型能力的同时显著减少推理时间:
- 局部特征提取模块:使用堆叠的BSConv和LeakyRelu层提取局部特征。
- 混合注意力机制:包括增强空间注意力(ESA)和对比感知通道注意力(CCA)。
- 高效变换器(ET)模块:包括多BSConv头转置注意力(MBTA)和门控BSConv前馈网络(GBFN)。
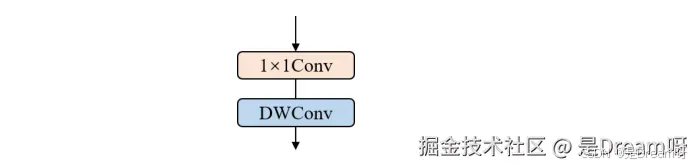
BSConv:BSConv将标准卷积分解为点对点1×1卷积和深度卷积,减少计算负担。
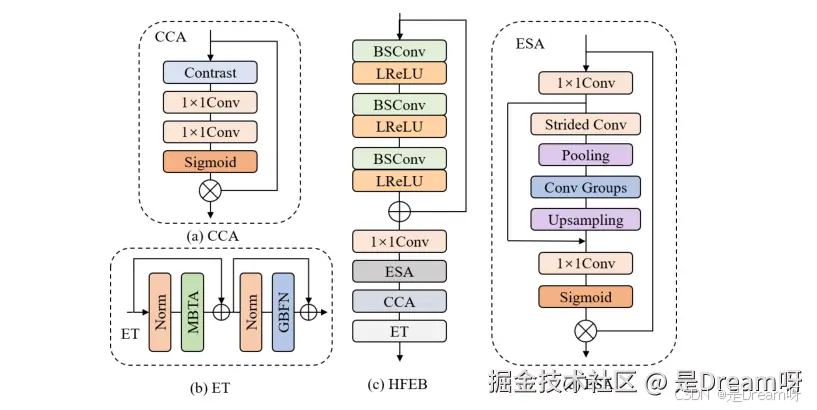
ESA和CCA:
ESA使用1×1卷积减少输入通道,并通过步长卷积和步长最大池化减少空间大小,CCA采用标准差和均值的和代替全局池化,增强图像细节和纹理结构信息:

高效变换器(ET):
包括MBTA和GBFN,MBTA通过跨通道自注意力减少计算开销,GBFN通过门控机制和BSConv学习局部信息。
五、实验步骤
- 数据集和评价指标:
使用DIV2K数据集的800张图像进行训练,使用Set5、Set14、BSD100、Urban100和Manga109数据集进行测试。评价指标包括平均峰值信噪比(PSNR)和结构相似性(SSIM)。
- 训练细节:
模型在RGB通道上训练,通过随机翻转图像增强训练数据。HFEB的数量设置为8,通道数设置为48。使用Adam优化器,初始学习率设置为5×10^-4,使用余弦衰减策略。在模型优化方面使用均方误差(MAE)损失函数进行优化。
六、实验结果
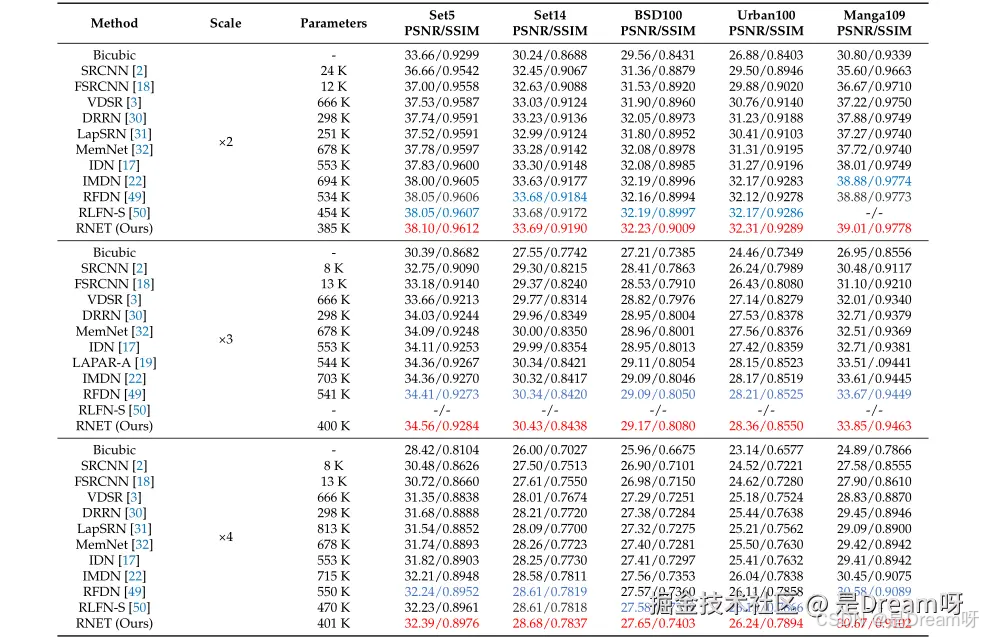
- 定量结果:
RNET在所有测试集上均实现了最佳性能,特别是在纹理细节增强方面。与现有高效SR方法相比,RNET在参数数量上减少了70K,性能最佳。
- 可视化结果:
与其他方法相比,RNET能够重建更清晰的图像细节,具有更高的视觉质量。
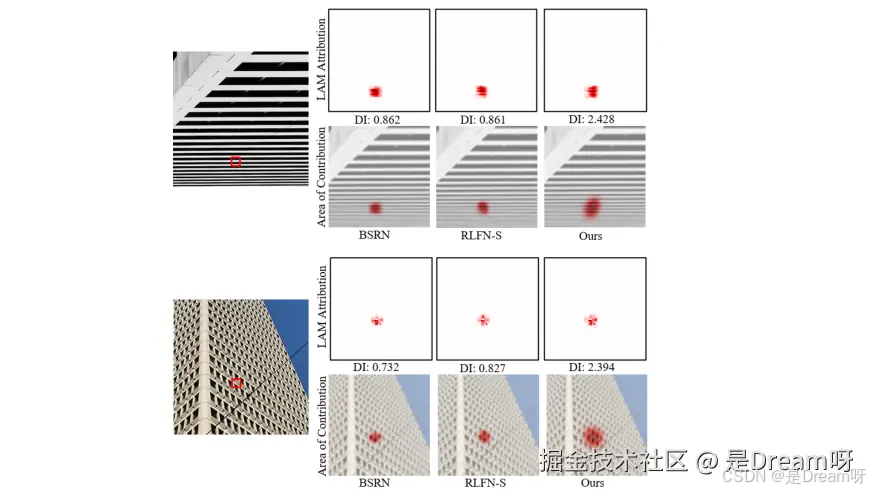
- 局部归因图(LAM)结果:
RNET在SR图像重建中利用了最广泛的像素范围,达到了最高的扩散指数(DI)值。
- 计算成本和模型复杂性分析:
RNET在参数数量、FLOPs和激活数量上均表现出较低的计算复杂性,同时保持了较高的性能。
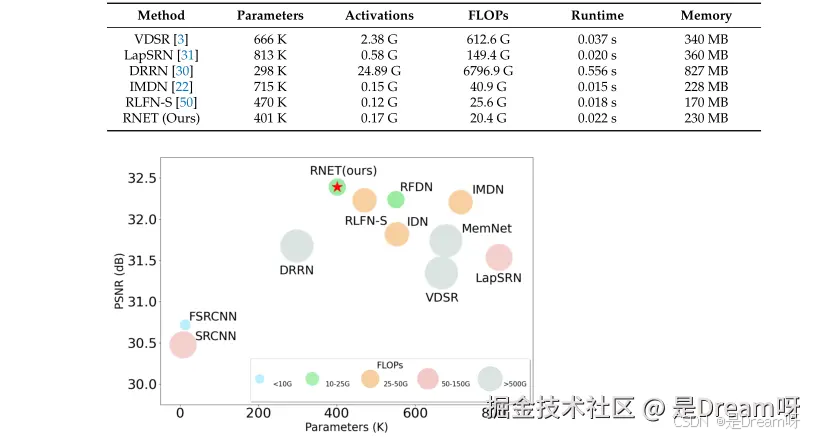
RNET在Set5数据集上的表现优于ESRT,并且与SwinIR的性能相似,但参数和FLOPs数量最少。通过一系列消融实验,验证了网络深度、宽度、ET模块的有效性以及激活函数的选择对模型性能的影响。
七、结论
RNET在轻量级单图像超分辨率任务中实现了性能与模型参数之间的良好平衡。通过局部残差连接结构和BSConv,显著提高了推理速度并减少了参数数量。
结合注意力机制与轻量级残差网络,既能让模型能够更高效地关注输入数据中的关键信息,提升模型处理复杂模式的能力,还通过减少参数和计算复杂度,保持了模型的轻量级特性,达到在有限资源下同时保持高效率和高性能的目标。
八、Attention与ResNet融合网络复现
1.通道注意力模块:
通过一个全连接层(att_fc)来学习通道间的权重,输入数据首先通过AdaptiveAvgPool2d在模态轴上进行平均池化,然后转换维度,并通过全连接层来获取注意力权重。将原始特征图与注意力权重相乘,实现通道的加权:
class ChannelAttentionModule(nn.Module):
def __init__(self, inchannel):
super().__init__()
self.att_fc = nn.Sequential(
nn.Linear(inchannel, inchannel // 4),
nn.ReLU(),
nn.Linear(inchannel // 4, inchannel),
nn.Sigmoid()
)
def forward(self, x):
'''
x.shape: [b, c, series, modal]
'''
# 传感数据特殊性,固定模态轴,只在时序轴上做GAP或者GMP
att = nn.AdaptiveAvgPool2d((1, x.size(-1)))(x) # [b, c, series, modal] -> [b, c, 1, modal]
att = att.permute(0, 3, 1, 2).squeeze(-1) # [b, c, 1, modal] -> [b, modal, c]
att = self.att_fc(att) # [b, modal, c]
att = att.permute(0, 2, 1).unsqueeze(-2) # [b, modal, c] -> [b, c, modal] -> [b, c, 1, modal]
out = x * att
return out
2.空间注意力模块:
输入数据先在通道维度上进行平均,然后通过卷积层和激活函数得到空间注意力权重,再来将原始特征图与空间注意力权重相乘,实现空间特征的加权:
class SpatialAttentionModule(nn.Module):
def __init__(self):
super().__init__()
self.att_fc = nn.Sequential(
nn.Conv2d(1, 1, (3, 1), (1, 1), (1, 0)), # 传感数据特殊性,固定模态轴,只在时序轴上进行空间注意力
nn.Sigmoid()
)
def forward(self, x):
'''
x.shape: [b, c, series, modal]
'''
att = torch.mean(x, dim=1, keepdim=True) # [b, c, series, modal] -> [b, 1, series, modal]
att = self.att_fc(att) # [b, 1, series, modal]
out = x * att
return out
3.ResNetWithAttention:
使用残差块来构建网络,在所有残差层之后,添加通道注意力和空间注意力模块:
class ResidualBlock(nn.Module):
def __init__(self, inchannel, outchannel, stride):
super().__init__()
self.block = nn.Sequential(
nn.Conv2d(inchannel, outchannel, (3, 1), (stride, 1), (1, 0)),
nn.BatchNorm2d(outchannel),
nn.ReLU(),
nn.Conv2d(outchannel, outchannel, 1, 1, 0),
nn.BatchNorm2d(outchannel)
)
self.short = nn.Sequential()
if (inchannel != outchannel or stride != 1):
self.short = nn.Sequential(
nn.Conv2d(inchannel, outchannel, (3, 1), (stride, 1), (1, 0)),
nn.BatchNorm2d(outchannel)
)
def forward(self, x):
out = self.block(x) + self.short(x)
return nn.ReLU()(out)
class ResNetWithAttention(nn.Module):
def __init__(self, train_shape, category):
super().__init__()
self.layer1 = self.make_layers(1, 64, 2, 1)
self.layer2 = self.make_layers(64, 128, 2, 1)
self.layer3 = self.make_layers(128, 256, 2, 1)
self.layer4 = self.make_layers(256, 512, 2, 1)
self.ada_pool = nn.AdaptiveAvgPool2d((1, train_shape[-1]))
self.fc = nn.Linear(512*train_shape[-1], category)
self.channel_attention = ChannelAttentionModule(512)
self.spatial_attention = SpatialAttentionModule()
def _make_layer(self, in_channels, out_channels, stride, blocks):
strides = [stride] + [1] * (blocks - 1)
layers = []
for stride in strides:
layers.append(ResidualBlock(in_channels, out_channels, stride))
in_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.channel_attention(x)
x = self.spatial_attention(x)
x = self.ada_pool(x)
x = x.view(x.size(0), -1) # Flatten the output
x = self.fc(x)
return x
def make_layers(self, inchannel, outchannel, stride, blocks):
layer = [ResidualBlock(inchannel, outchannel, stride)]
for i in range(1, blocks):
layer.append(ResidualBlock(outchannel, outchannel, 1))
return nn.Sequential(*layer)
九、ResNetWithAttention仿真实验
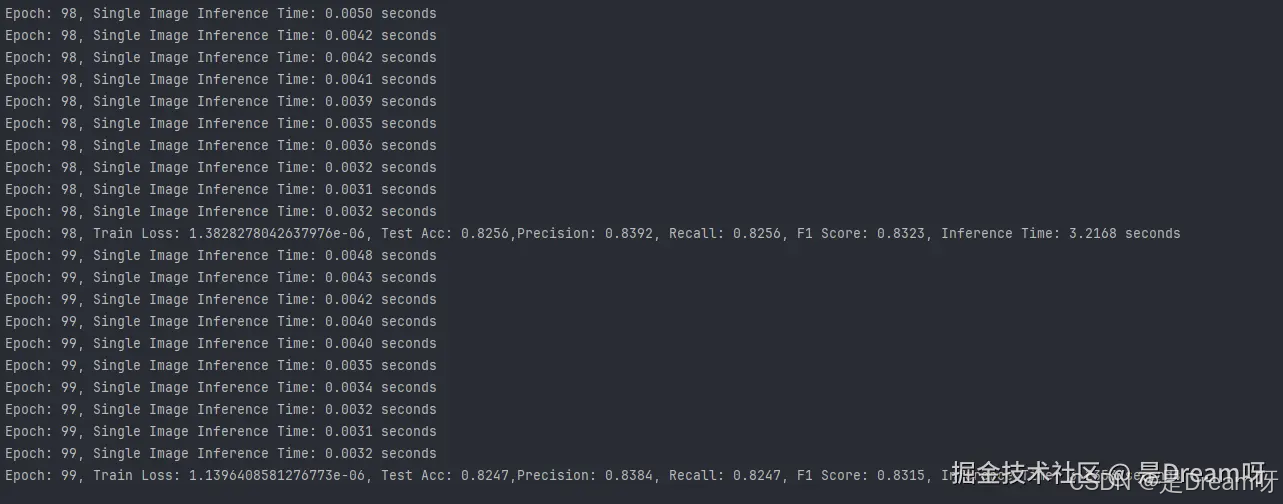
1.Opportunity数据集:
2.UCI HAR数据集: