前言:来一个官方一点的介绍:MinerU是一个一站式、开源、高质量的数据提取工具,支持多种功能,如提取 PDF、markdown 等格式的内容。
MinerU可以用来做什么?
现在很多公司和个人都喜欢借助例如 MaxKB、Dify、AnythingLLM等开源平台搭建私有化知识库平台。但是私有文档很多是PDF文件,RAG索引对PDF文件的处理效果有限,特别是如果还有图片内容,识别解析度准确度会更低。所以需要使用更适合的文档类型来提高识别的准确度,例如markdown文件等。
下面是直接安装客户端的版本(备注:客户端版本会使用在线网络)。
下载minerU,客户端版本下载地址:
https://mineru.net/
安装完成以后,可以直接上传文件进行解析。注意,这儿上传的文件,会被传输到远程的线上默认环境进行解析。
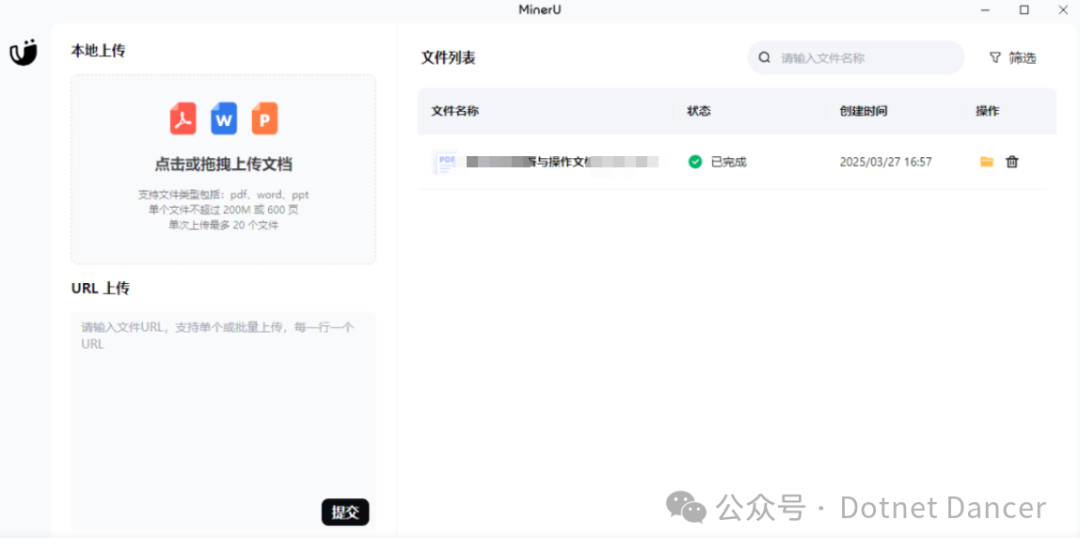
解析成功以后,本地会有输出的解析目录,如下所示。假如你用MaxKB的情况下,需要把images和full.md一起打包成zip压缩包丢给它。
举个例子,例如我使用MaxKB做知识库,把打包好的zip压缩包上传为知识库。
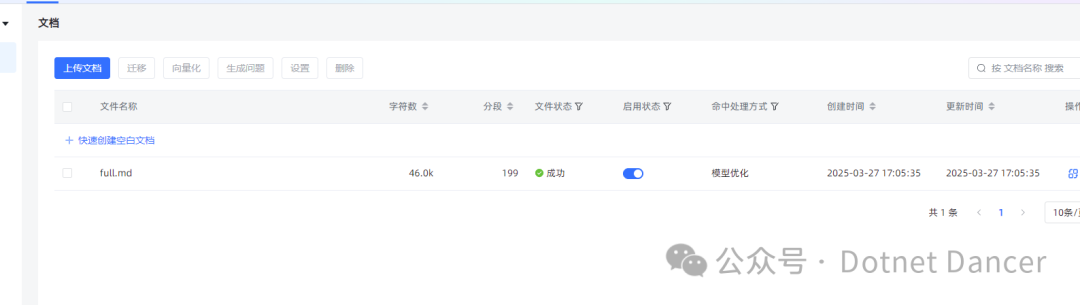
过程此处省略,直接看最终的测试效果,可以自动匹配相关内容,以及关联的图片输出。
但是使用客户端的minerU,毕竟文档会被上传到云端,如果遇到私密的文档,还可能存在消息泄露的隐患。所以需要本地化部署minerU来解决这个问题,毕竟本地才最安全。接下来开始本地化部署操作教程。
以下内容教程,基于Windows系统进行操作。
本地安装minerU之前,需要确保你的电脑上已经安装有Conda环境,如果有显卡资源(8G显存起步),还需要提前安装好Cuda环境、显卡驱动等。这部分安装我就不多描述了,此处默认大家已经安装。
使用conda命令,创建虚拟环境。此处指定python为3.10版本。
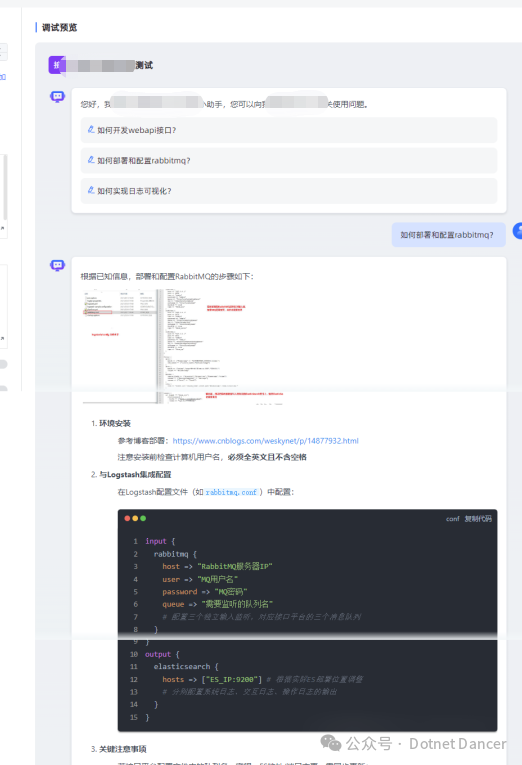
conda create -n mineru python=3.10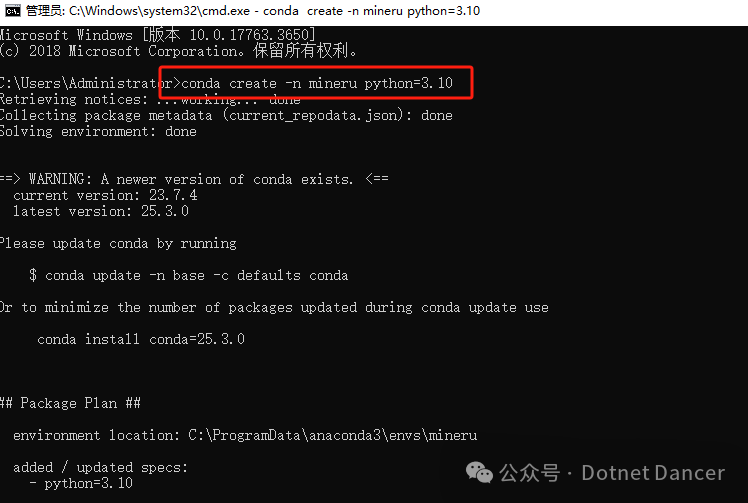
创建成功以后,激活conda环境。
conda activate mineru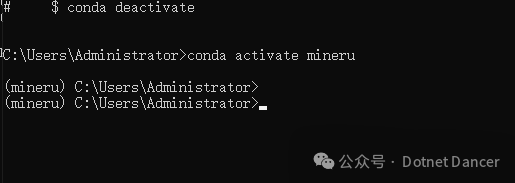
安装magic-pdf环境,主要解析工具是这个。如果本身不怕墙的,阿里云镜像后缀可以不需要。
pip install -U magic-pdf[full] --extra-index-url https://wheels.myhloli.com -i https://mirrors.aliyun.com/pypi/simple安装完成以后,使用以下命令可以进行查看当前安装成功的版本。
magic-pdf --version
安装成功以后,还要继续安装 modelscope环境:
pip install modelscope
接下来,咱们在本地克隆一份minerU项目下来,后面会使用到:
git clone https://gitee.com/myhloli/MinerU.git
这conda环境下,目录定位到minerU项目的脚本文件夹路径下:
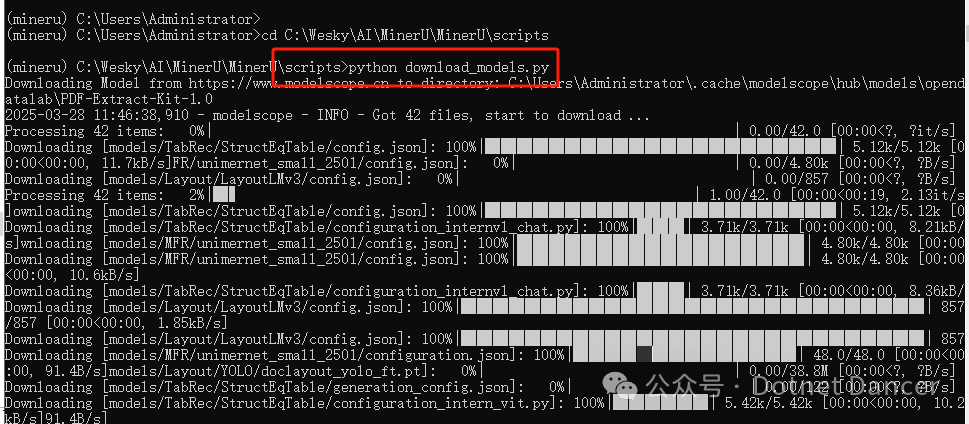
执行里面的download_models.py脚本,会自动开始下载有关模型文件
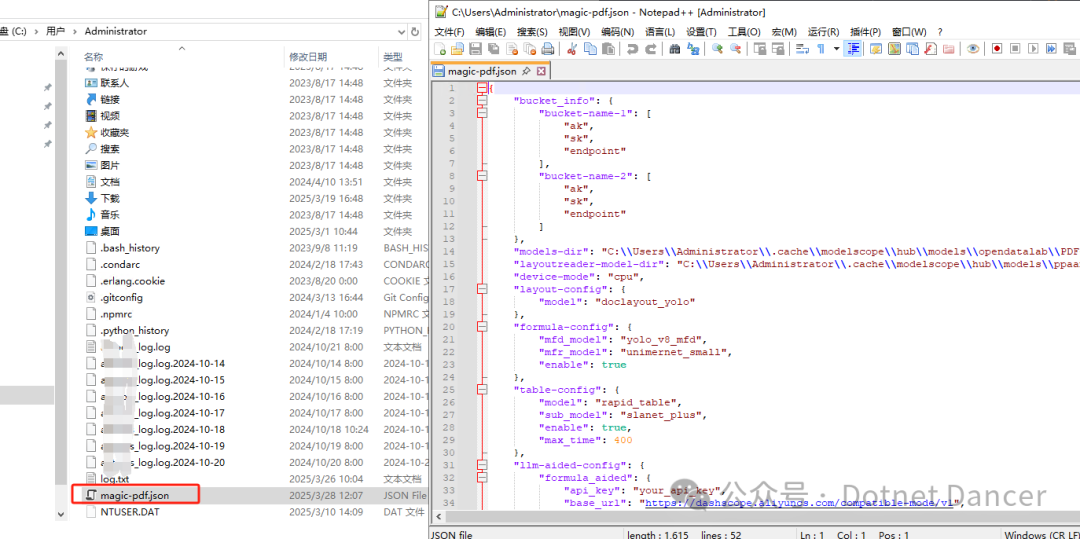
下载完成以后,会自动配置好配置文件,配置文件位于你自己电脑上的 C:\Users\用户名 路径下
接着定位到项目的demo路径下,可以看到里面有测试使用的三个pdf文件
先使用CPU执行一下,看下解析度测试效果,输出到当前路径下的output目录下
magic-pdf -p small_ocr.pdf -o ./output
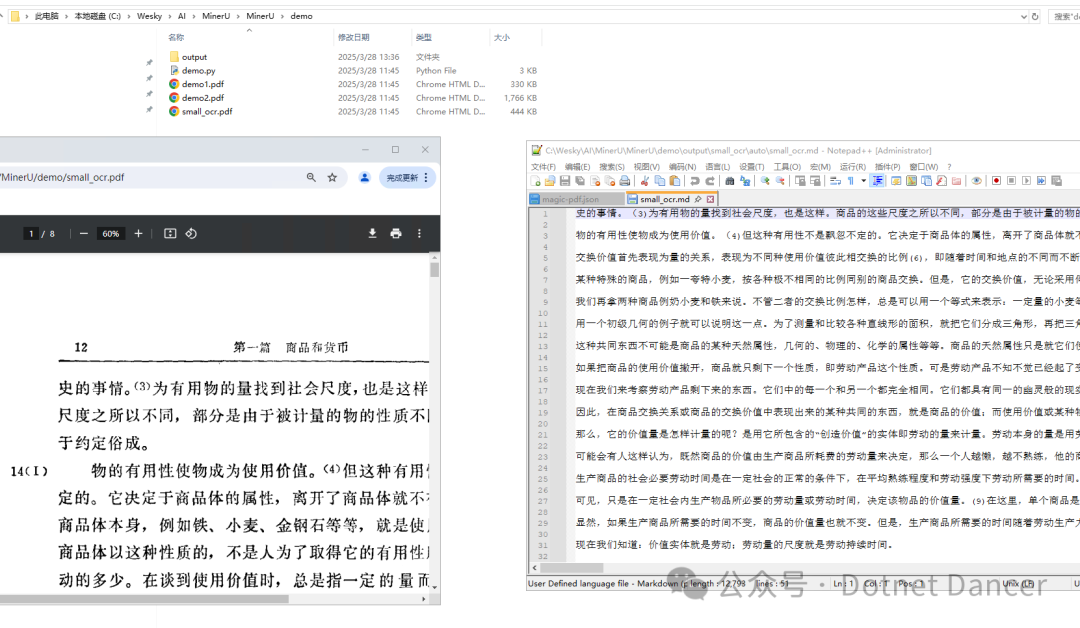
执行以后,可以看到输出了md文件,以及其他一些杂项。打开MD文件和原始的PDF文件数据进行比对看效果,初步看起来识别是成功的。
如果本地有显卡资源,显存大于8GB的用户,可以安装cuda版本pytorch有关环境进行操作。先安装指定cuda版本的pytorch有关环境:
pip install --force-reinstall torch==2.3.1 torchvision==0.18.1 --index-url https://download.pytorch.org/whl/cu118
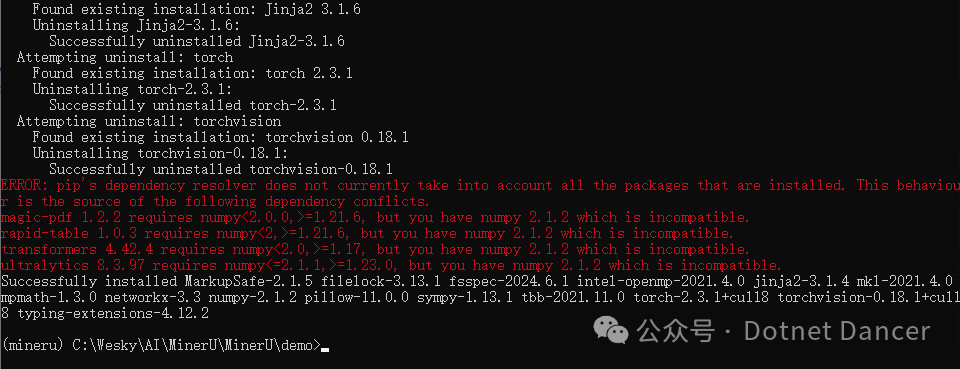
我在安装期间报错了,看提示内容,是依赖的numpy包环境版本冲突。
上numpy库进行查看numpy的所有版本,找到一个不冲突进行代替,找到1.2x版本最新的是1.26.4,那咱们就用这个版本来代替吧。

直接安装1.26.4版本pip install numpy==1.26.4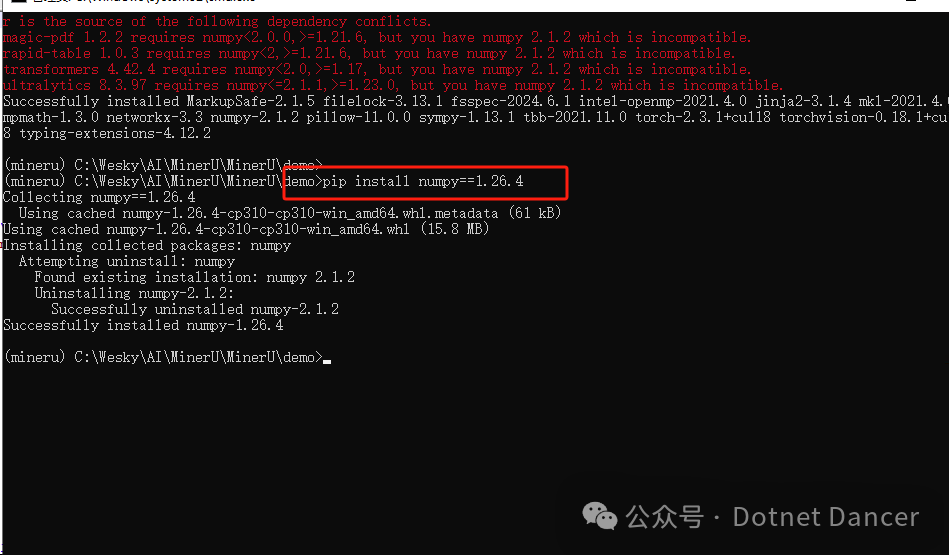
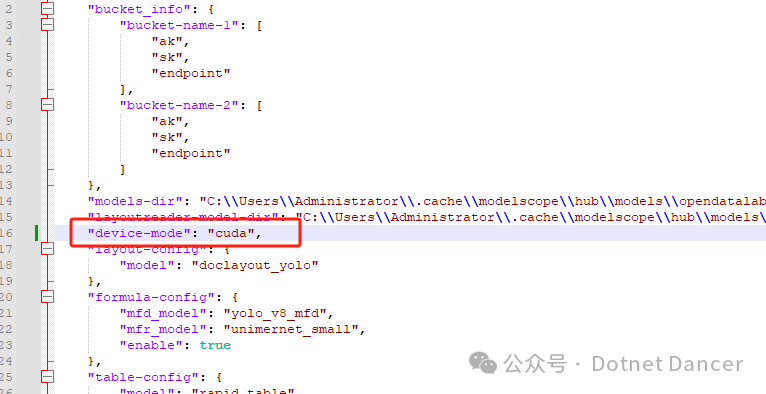
在magic-pdf的配置文件内,找到device-mode属性,把默认大模式是cpu改为cuda
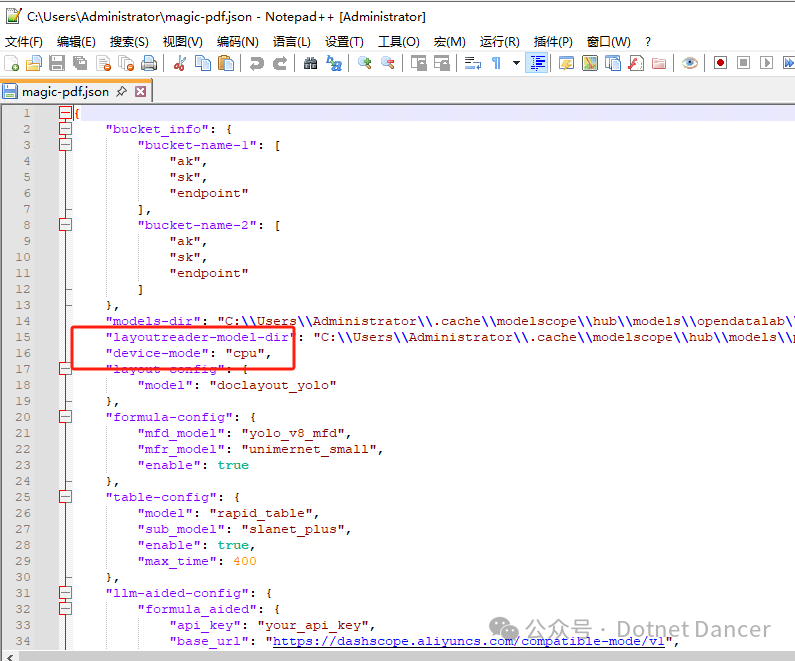
改为cuda
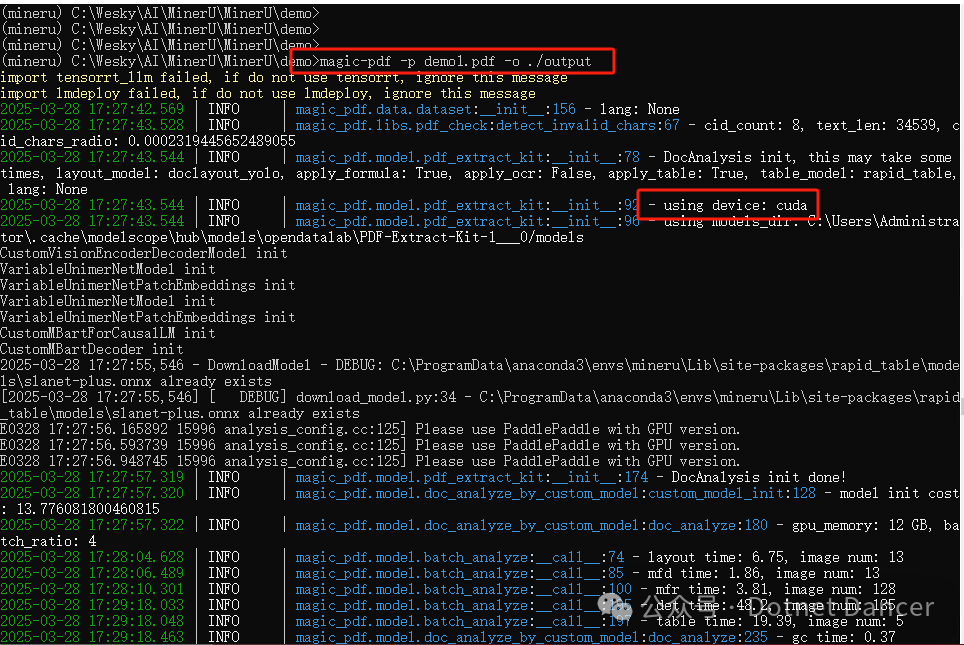
修改完毕,直接运行,这次换一个带有图片的demo1.pdf,执行期间也可以看到输出日志,选择了cuda(显卡资源)来执行。
经过短暂的运行以后,跑完以后在指定输出的output文件夹下面,可以看到PDF文件被解析成功了,输出量md文件类型,并且里面的图片也被对应处理,放到了images文件夹下。
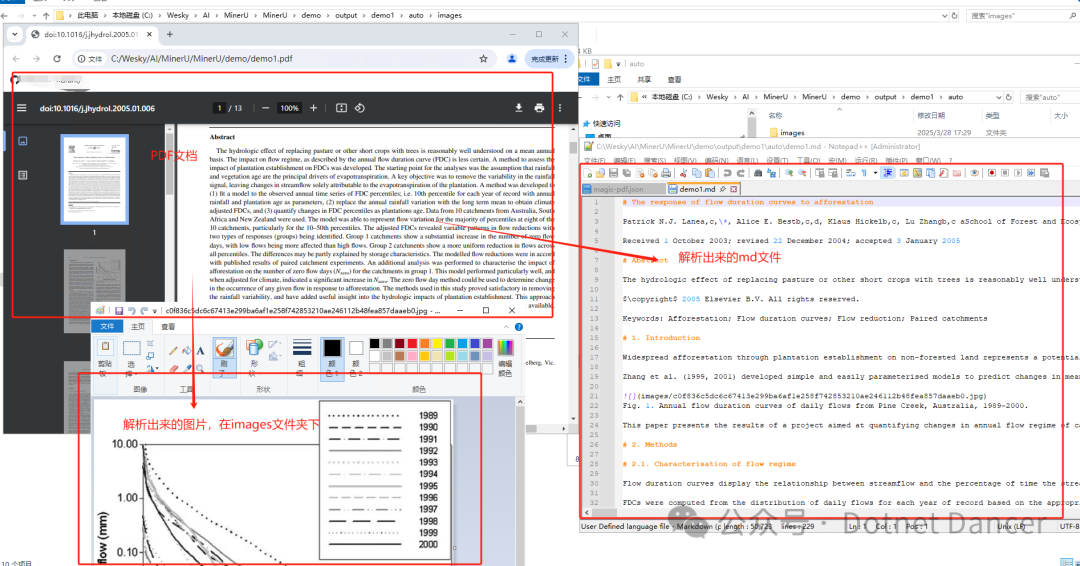
至此,一切准备就绪,接下来就可以对自己的PDF文档进行处理啦!
以上就是minerU本地安装配置的全部过程。没了。
如果本文章对你有帮助,欢迎点赞转发或留言,也欢迎扫码快捷关注我的公众号 Dotnet Dancer:
