各位观众老爷大家好!三连入场,神清气爽!请大家多多点赞关注!今天为大家带来一篇最新的工作,是阿里通义Lab开源的LHM项目,该项目旨在从单张图像生成可驱动的3D人体模型。而LHM模型采用3DGS表示,利用大规模重建模型的优势,高效推断高保真度的3D虚拟形象。其中的多模态Body-Head Transformer架构能显著提升了对脸部和衣物细节的还原能力。基于Pytorch实现。

此方法能够在几秒钟内通过单次前馈传递重建出一个可进行动画操作的人体虚拟形象。最终生成的模型支持实时渲染以及姿势控制的动画效果。
论文地址: https://arxiv.org/abs/2503.10625
项目地址:LHM
1.Abstruct
从单张图像中重建出可进行动画操作的 3D 人体是一个具有挑战性的问题,这是因为在分离几何形状、外观和变形方面存在不确定性。近期在 3D 人体重建领域的进展主要集中在静态人体建模上,并且依赖使用合成的 3D 扫描数据进行训练,这限制了它们的泛化能力。
相反,基于优化的视频方法能实现更高的保真度,但需要可控的采集条件以及计算量庞大的优化处理过程。受用于高效静态重建的大型重建模型出现的启发,作者提出了 LHM(大型可动画人体重建模型),以便在前馈过程中推断出以 3D 高斯溅射形式表示的高保真虚拟化身。并且此模型利用多模态变换器架构,借助注意力机制有效地对人体位置特征和图像特征进行编码,从而能够细致地保留衣物的几何形状和纹理。
为了进一步提高面部身份的保留效果和精细细节的恢复能力,还提出了一种头部特征金字塔编码方案,用于聚合头部区域的多尺度特征。大量实验表明, LHM 模型能够在几秒钟内生成逼真的可动画人体模型,且无需对面部和手部进行后处理,在重建精度和泛化能力方面均优于现有方法。
2. Introduction
从单张图像创建可进行动画操作的 3D 人体虚拟形象对于沉浸式增强现实(AR)/ 虚拟现实(VR)应用至关重要,但由于几何形状、外观和变形等方面存在相互关联的不确定性,这一任务仍然极具挑战性。
最近,基于扩散的人体视频动画方法已显示出能够生成逼真的人体视频的能力。然而,这些方法在极端姿势下常常会出现视角不一致的问题,并且在进行视频采样时需要较长的推理时间。在 3D 可动画人体重建方面,早期的方法依赖于参数化模型来为动画提供强大的人体先验知识,但在捕捉宽松衣物的精细几何形状以及高保真的面部细节方面存在困难,这限制了它们的表现力。尽管近年来基于学习的 3D 方法在静态着装人体重建方面取得了显著进展,但大多数现有方法要么无法生成可动画的人体模型,要么缺乏对自然场景图像的泛化能力。由于缺乏合适的模型架构以及用于学习的大规模 3D 绑定人体数据集,从单张图像进行可泛化的 3D 可动画人体重建这一问题仍未得到充分解决。
大型重建模型(LRM)表明,使用大规模 3D 数据进行训练的可扩展的 Transformer 模型能够学习到可用于单张图像 3D 物体重建的泛化先验知识。要将这一成功拓展到可动画的人体重建领域,面临着独特的挑战,需要解决两个关键问题:(1)设计一种有效的架构,将 3D 人体表示与动画能力相结合;(2)克服高质量 3D 绑定人体训练数据稀缺的问题。(LRM详细信息请参考:https://arxiv.org/pdf/2311.04400)
而LHM(大型可动画人体模型),是一种可扩展的前馈 Transformer 模型,能够在几秒钟内从单张图像中生成可进行动画操作的 3D 人体虚拟形象。考虑到其能够进行实时的照片级真实感渲染,作者将人体虚拟形象表示为高斯溅射形式。此方法将单张图像作为输入,并直接在规范空间中把标准人体预测为一组 3D 高斯分布。为了实现动画效果,此方法从一组从 SMPL-X 模板网格中采样得到的表面点开始,将这些点用作几何锚点来进行预测3D Gaussian properties。(SMPL-X信息: Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed AA Osman, Dimitrios Tzionas, and Michael J Black. Expressive body capture: 3d hands, face, and body from a single image. In CVPR, 2019. 2, 3)
此方法的网络架构受到了最先进的图像生成模型 SD3 所引入的multimodal transformer(MM transformer)模块的启发,该模块旨在对文本和图像标记之间的交互进行建模。作者对 MM transformer进行了调整,使其适用于当前任务,以便通过注意力操作有效地对人体三维点特征和二维图像特征进行编码,从而能够细致地保留衣物的几何形状和纹理。为了解决面部身份保留的问题,进一步引入了一种头部特征金字塔编码(HFPE)方案,该方案聚合了来自头部区域的多尺度视觉特征,显著提高了这些在感知上较为敏感区域的细节恢复能力。
在训练过程中,为了借助大规模数据提升这个transformer的性能,作者使用 SMPL-X 参数将预测得到的规范高斯分布变换到各种不同的姿势,并通过结合渲染损失和正则化方法进行优化。这种自监督策略使得我们能够从易于获取的视频数据中学习到具有泛化能力的人体先验知识,而无需依赖稀缺的 3D 扫描数据。(在一个大规模视频数据集上进行训练,且无需带绑定的 3D 数据,在真实世界图像上取得了领先的性能表现,在泛化能力和动画一致性方面超越了现有的方法)
3.Related Work
3.1. Single-Image Human Reconstruction(单张图像的 3D 人体重建)
单张图像的 3D 人体重建的早期方法主要依赖于SMPL 这样的参数化人体模型,来预测裸体或着装对象的几何偏移量 。由于这些方法基于刚性的网格表示,它们常常难以捕捉多样的服装风格。随后的进展利用隐式函数对复杂的几何形状进行建模,在处理精细的表面细节时提供了更大的灵活性,且不受分辨率的限制。生成式框架,例如扩散模型和生成对抗网络(GANs),已被用于根据输入图像合成细节丰富的 3D 人体模型。一些研究人员也探索了使用基于分数蒸馏采样(SDS)损失从扩散模型中提炼出生成虚拟形象的方法。然而,这些方法往往比较耗时。
最近,大型重建模型(LRMs)已被引入,以实现具有泛化能力的前馈式物体重建 ,显著加快了推理速度。人体大型重建模型(Human-LRM)采用前馈式transformer对三平面神经辐射场(triplane-NeRF)表示进行解码,以实现多视图渲染,随后进行基于扩散的 3D 重建。人体高斯溅射模型(Human-Splat)首先利用视频扩散生成多视图图像,然后应用潜在重建transformer来预测以 3D 高斯溅射(3DGS)形式表示的人体虚拟形象。PSHuman 利用多视图扩散结合身份扩散来提高面部重建质量。与这些专注于静态人体重建的方法不同,LHM方法能够生成逼真的、可进行动画操作的人体虚拟形象,从而实现高质量的动态渲染和交互。
3.2. Animatable Human Generation(可动画人体模型的生成)
创建可动画的虚拟形象已经从参数模型驱动的方法发展到将隐式曲面和人体先验知识相结合的混合方法,用于着装人体建模 。基于视频的技术通过利用来自单目或多视图序列的时间线索,进一步提高了重建的一致性。文本生成三维模型(text-to-3D)方法的兴起,使得通过一个漫长的优化过程 ,能够根据文本提示生成虚拟形象。
在 3D 可动画人体重建领域,“角色生成(CharacterGen)” 已经探索了利用扩散模型进行标准视角合成以及基于transformer的形状重建,来生成卡通风格的虚拟形象。AniGS采用了一种视频扩散模型来生成多视图的标准图像,随后通过四维高斯溅射(4DGS)优化来实现一致的三维生成效果。“通用可动画人体模型(GAS)” 采用了一种可泛化的人体神经辐射场(NeRF)在标准空间中重建对象,然后利用视频扩散进行优化。最近,“IDOL” 引入了一种前馈transformer模型来解码 UV 空间中的高斯属性图,并且需要进行后处理来优化面部和手部细节。与这些方法不同,作者提出了一种高效且富有表现力的多模态人体transformer,它能够直接回归出三维人体的高斯表示,而无需依赖 UV 表示,也不需要对手部和面部进行后处理来优化细节。
4. Method
在展示技术细节之前,我们先来看一张论文中方法的总览图:
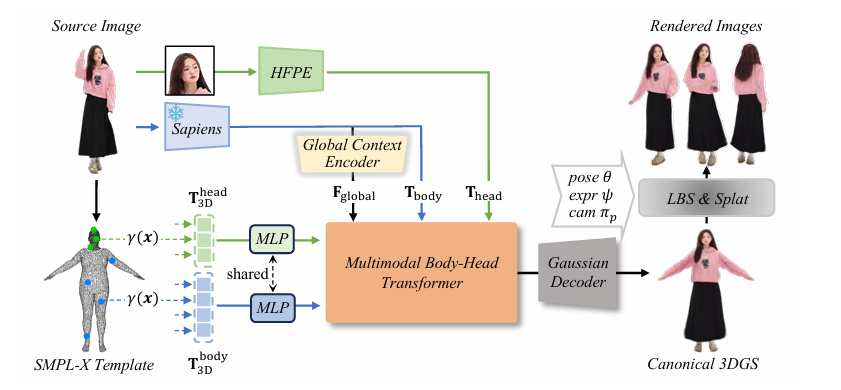
从这张图中我们不难得到LHM的pipeline:从输入的可爱小姐姐的图像中提取人体和头部的图像标记,然后利用Multimodal Body-Head Transformer(MBHT)将三维几何人体标记与图像标记进行融合,在基于注意力机制的融合过程之后,几何人体标记被解码为高斯参数。
4.1.Geometric and Image Feature Encoding(几何特征与图像特征编码)
几何标记源自于 SMPL-X 表面点,对人体的结构先验信息进行编码。人体图像标记是从预训练的vision transformer中提取的,对纹理和外观进行编码。头部标记专门通过多尺度特征提取过程来捕捉高频的面部细节。
4.1.1.Human Geometric Feature Encoding(人体几何特征编码)
利用 SMPL-X 的人体先验知识,通过有策略地对规范的pose mesh进行采样,初始化3D query points。每个点都要经过位置编码 ,随后通过多层感知器(MLP)进行投影,以便与transformer的标记通道维度相匹配:
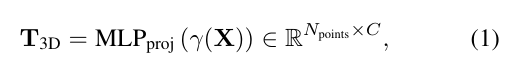
其中γ: 对空间坐标应用L频率的正弦编码,并且C是标记维度。
4.1.2.Body Image Tokenization(人体图像标记化)
基于在以人为中心的数据集上预训练的 large-scale vision transformers,将图像像素转换为与transformer兼容的token。具体来说,通过使用在 1000 万张人体图像上预训练的冻结的 Sapiens-1B 编码器,来提取语义人体特征。
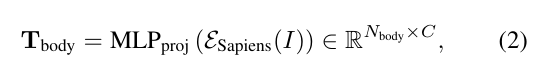
其中Nbody表示人体标记的数量。
4.1.3.Head Feature Pyramid Tokenization (头部特征金字塔标记化)
然而,由于在输入图像中人类头部仅占据较小区域,并且在编码器中会进行空间下采样,关键的面部细节常常会丢失。为缓解这一问题,作者提出了头部特征金字塔编码(HFPE)方法,它聚合来自 DINOv2的多尺度特征{Edino}:
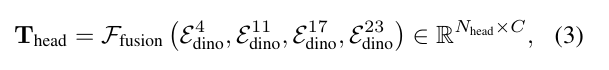
4.2. Multimodal Body-Head Transformer(多模态身体 - 头部变换器)
4.2.1.Global Context Feature(全局上下文特征)
全局上下文标记用于注意力模块的调制。为了捕获用于注意力调制的全局上下文信息,以身体标记作为输入,经过最大池化和两个多层感知器(MLP)层来提取全局上下文嵌入:
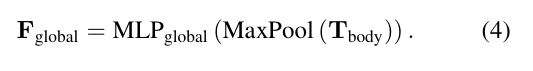
4.2.2.Multimodal Body-Head Transformer Block(多模态身体 - 头部变换器模块)
下面先给出原文中的模块示意图:
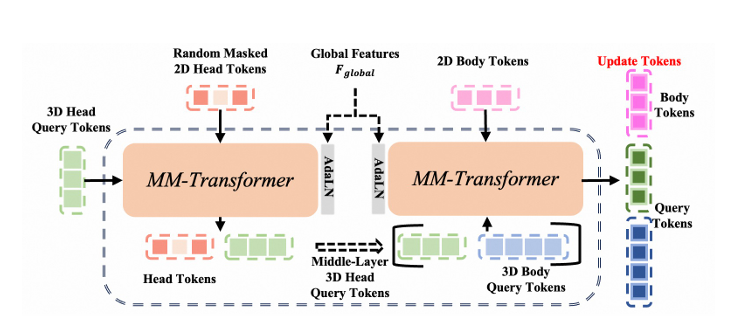
此模型架构的核心设计是多模态身体 - 头部变换器模块(MBHT 模块),它有效地融合了三维几何标记与身体和头部的图像特征。具体而言,全局上下文特征、图像标记和查询点标记会同时输入到 MBHT 模块中。为了增强对头部和身体特定特征的学习,三维头部点标记会先与头部图像特征融合,然后再与三维身体点标记连接,进而与身体图像特征进行交互:

4.2.3.Head Token Shrinkage Regularization(头部标记收缩正则化)
实验表明,MBHT 模块中的注意力机制严重依赖头部区域的特征,这限制了它有效学习身体部位特征的能力。为了解决这种不平衡问题,作者从掩码自编码器(MAE)中获得灵感,在训练期间随机掩码输入裁剪图像中的头部区域。
具体来说,以 0% 到 50% 的比例对头部标记进行空间掩码,鼓励模型通过增强对身体上下文的利用来进行补偿。这种正则化策略在保持头部重建保真度的同时,提高了身体部位的自注意力能力。
4.2.4.3DGS Parameter Prediction(3DGS 参数预测)
经过个 MBHT 模块后,一个 MLP 头部会预测 3DGS 参数:
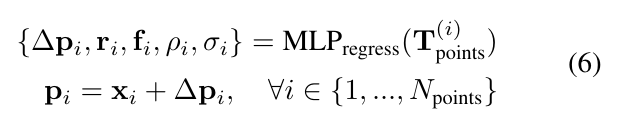
其中Δpi∈R3表示相对于规范 SMPL - X 的残差位置偏移。
4.3. Loss Function
训练的目标是将来自真实场景视频序列的光度监督与规范空间中的正则化约束相结合。完整的优化框架能够在无需真实 3D 监督的情况下学习可动画化的虚拟形象。
4.3.1. View Space Supervision(视图空间监督)
给定预测的 3D 高斯溅射(3DGS)参数χ=(p,r,f,ρ,σ),首先使用Linear Blend Skinning(LBS)将规范的虚拟人模型变换到目标视图空间。然后,在目标相机参数下,通过可微的溅射操作渲染变换后的高斯基元,生成 RGB 图像
和阿尔法掩模
。为了更好地模拟衣物变形,作者采用了diffused voxel skinning技术。
视图一致性监督在视图空间中包含三个组成部分:
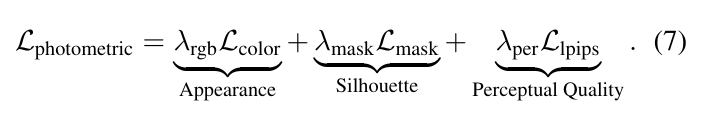
损失权重用于平衡重建的各个方面:用于直接颜色监督的λrgb=1.0,用于几何对齐的λmask=0.5,以及用于保留高频细节的λper=1.0。
4.3.2. Canonical Space Regularization(规范空间正则化)
虽然光度损失在目标视图空间中提供了有效的监督,但由于单目重建的缺点,规范表示仍然约束不足。这种限制表现为在将虚拟形象变形到新姿势时出现变形伪影。为了解决这一根本性挑战,引入两个互补的正则化项,以在规范空间中强制实现几何一致性。
Gaussian Shape Regularization(高斯形状正则化):应用spherical as possible loss 来惩罚高斯基元中过度的各向异性:
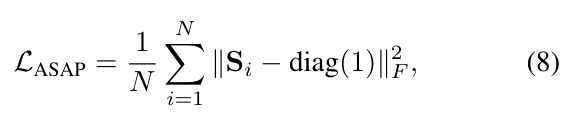
Positional Anchoring(位置锚定):为了保持身体表面的合理性,加入as close as possible loss,通过hinged distance constraint,促使高斯位置接近其由 SMPL-X 初始化的位置:
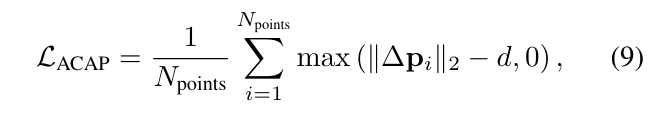
其中d在实践中表示根据经验确定的阈值(5.25 cm),它允许进行局部调整,同时防止出现严重的漂移。
4.3.3.Summary
联合规范正则化的操作如下:
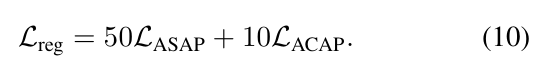
复合训练目标将光度保真度保持与几何正则化相结合,公式如下:
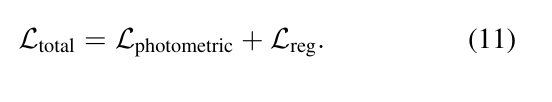

该图是在 DeepFashion 数据集和真实场景图像上的单视图重建对比。LHM 在外观保真度和纹理清晰度上表现更优,在面部细节和服装褶皱方面尤为明显。
5.Limitations and Future Work
方法的一个局限性在于,现实世界的视频数据集通常存在视角分布偏差,对不常见姿势和极端角度的覆盖有限。这种不平衡会影响模型对新视角的泛化能力。在未来的工作中,应该开发改进的训练策略,并整理一个更加多样化和全面的数据集,以增强模型的稳健性。
天下没有不散的宴席,今天的读书笔记又到此结束了,更多实验细节请参阅原文。