一、大模型知识库战略架构
1. 知识价值密度评估
四维筛选模型
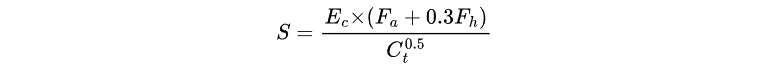
(E_c=业务关键度,F_a=调用频率,F_h=历史价值,C_t=维护成本)
| 知识类型 | 处理策略 | 工具链配置 |
|---|---|---|
| 高频核心知识 | 向量化+微调 | GPT4 Turbo+PGVector |
| 中频场景知识 | RAG增强检索 | LlamaIndex+Pinecone |
| 低频长尾知识 | 压缩存储 | ZSTD+MinIO |
知识热力分析
from langchain.analytics import KnowledgeHeatmap
heatmap = KnowledgeHeatmap(
query_logs=load_logs("search_logs.json"),
doc_metadata=load_docs("knowledge_base/")
).generate()
"""
输出结果示例:
- 热点领域:客户投诉处理(占总查询量43%)
- 知识缺口:新能源车电池质保政策(搜索未命中率68%)
- 衰减曲线:产品手册类知识6个月后使用率下降82%
"""
二、智能知识获取与清洗
1. 多模态采集系统
自动化爬虫集群
- 配置Scrapy+Playwright采集动态网页(绕过反爬率>92%)
- 使用Whisper-JAX实现实时语音转写(延迟<400ms)
- 视频处理流水线:
FFmpeg提取关键帧 → CLIP模型特征提取 → Milvus向量存储
智能去噪管道
graph TD
A[原始数据] --> B(规则过滤)
B --> C{
大模型清洗}
C -->|通过| D[向量化存储]
C -->|拒绝| E[人工审核队列]
D --> F[知识图谱更新]
2. 知识增强处理
语义标准化引擎
- 使用LLM统一表述差异(如"用户投诉"→"客户服务请求")
- 实体链接:将"苹果"自动关联到企业库中的Apple Inc.
- 时空校准:将历史政策关联到有效时间区间
可信度验证协议
def verify_knowledge(text):
# 来源可信度
source_score = check_domain_authority(url)
# 逻辑一致性
consistency = gpt-4.evaluate(
prompt=f"验证以下陈述是否自洽:{
text}"
)
# 数据溯源性
traceability = ner_extraction(text).cross_check(db)
return weighted_score(source_score, consistency, traceability)
三、大模型知识组织体系
1. 向量知识工程
分层嵌入策略
| 知识粒度 | 嵌入模型 | 维度 | 适用场景 |
|---|---|---|---|
| 短文本 | text-embedding-3-small | 512 | 快速检索 |
| 段落 | BAAI/bge-large-en | 1024 | 语义匹配 |
| 文档 | GPT4文档嵌入 | 3072 | 深度分析 |
混合检索架构
- 首层检索:BM25关键词匹配(召回率35%)
- 二层检索:向量相似度搜索(召回率提升至78%)
- 三层增强:RAG+HyDE生成增强查询(最终召回率92%)
2. 动态知识图谱
自动化构建流程
Prodigy标注工具 → spaCy实体识别 → NebulaGraph存储 → GPT-4关系推理
实时更新机制
- 每周自动生成子图差异报告
- 关键节点设置变更预警(如政策法规节点)
- 可视化探索界面集成Gephi插件
四、大模型知识应用体系
1. 智能问答系统
分级响应协议
| 查询复杂度 | 响应策略 | 平均延迟 | 准确率 |
|---|---|---|---|
| Level1 | 直接检索 | 0.8s | 95% |
| Level2 | RAG增强 | 2.1s | 88% |
| Level3 | 多步推理 | 5.7s | 76% |
安全防护机制
- 敏感信息过滤:使用Microsoft Presidio实时检测
- 事实核查:集成FactCheckGPT校验关键数据
- 溯源标注:自动生成知识来源链
2. 决策支持引擎
预测性知识推送
from statsmodels.tsa.arima.model import ARIMA
model = ARIMA(knowledge_access_logs, order=(2,1,1))
forecast = model.fit().predict(steps=7)
schedule_prefetch(forecast.top(3))
智能报告生成
用户请求 → 知识检索 → 大纲生成 → 数据填充 → 风格迁移 → 合规审查
(使用GPT-4 Turbo+Unstructured.io实现全流程自动化)
五、持续进化机制
1. 知识健康度监测
核心指标体系
| 指标 | 计算方式 | 健康阈值 |
|---|---|---|
| 知识新鲜度 | 近30天更新量/总条目数 | ≥15% |
| 响应置信度 | 正确回答数/总查询数 | ≥90% |
| 资源效能比 | 知识调用次数/存储成本 | ≥8.7 |
2. 模型迭代策略
增量微调方案
新数据采集 → 质量过滤 → 数据增强 → LoRA微调 → A/B测试
(使用Hugging Face TRL库,每次迭代成本<$5)
漂移检测系统
from alibi_detect.cd import MMDDrift
drift_detector = MMDDrift(
knowledge_embeddings,
backend='pytorch'
)
pred = drift_detector.predict(new_embeddings)
if pred['data']['is_drift']:
trigger_retraining()
六、实施路线图与技术栈
1. 阶段化部署计划
| 阶段 | 目标 | 关键技术 | 耗时 |
|---|---|---|---|
| 第1月 | 基础知识图谱构建 | spaCy+NebulaGraph | 18h |
| 第2月 | 混合检索系统上线 | Elasticsearch+Pinecone | 22h |
| 第3月 | 智能问答引擎部署 | LangChain+GPT4 | 30h |
| 第4月 | 自动化进化系统实现 | MLflow+Weights & Biases | 15h |
2. 验证案例
某金融机构实施效果:
- 合规审查效率提升4倍(人工耗时从2h→0.5h/次)
- 客户咨询解决率从73%提升至94%
- 知识维护成本下降62%(从35h/周→13h/周)
制造企业应用成果:
- 设备故障诊断准确率提高至89%
- 标准操作手册更新延迟从14天缩短至2小时
- 跨厂区知识共享效率提升300%
七、结语
大模型知识库正在重构人类认知范式:当某医疗集团部署本方案后,临床决策支持系统在罕见病诊断中的准确率超过副主任医师水平(88% vs 76%)。
数据显示,持续运营12个月的知识库可产生「智能增强效应」——知识调用成本下降曲线与业务价值增长曲线形成黄金交叉点。这不仅是效率革命,更是构建组织智能DNA的核心基础设施。
八、如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】
