0 前言
当我们有着数千上万本证券研究报告,即使使用标题关键字搜索,依旧存在着不少对应的研报,此时只能一本一本地去阅读去筛选,十分消耗脑力,那么能不能使用大模型来代替我们的操作,让它给出相对完整的答案并给出引用,我们直接看这些引用的文章来获取细节即可。
本文首先概述了 RAG 的原理与优势,同时面向个人应用对主流的开源 RAG 产品进行选择,然后介绍基于深度文档解析的 RagFlow 知识库产品与如何在 Mac M1 进行源码部署,最后对 RAG 系统的缺点和近期流行的长文本模型进行简短的探讨。
一、RAG 的原理与优势
RAG 系统(Retrieval-Augmented Generation system)是一种自然语言处理技术,这种方法区别于原生大语言模型,它通过外挂知识库来协助大模型解决一些问题,不仅提高了回答的准确性和一致性,同时还能避免敏感信息被大模型直接学习而出现信息泄露风险。
它结合了搜索引擎和原生大模型的优点,工作流程类似于传统搜索引擎的两阶段模式,分为语义检索和召回生成两大过程,首先,系统根据用户的提问转换为 embedding 从向量数据库中检索出语义相似信息,然后配合大模型,通过喂入检索召回的 top-k 个文本信息与相应提示词来生成归纳回答。
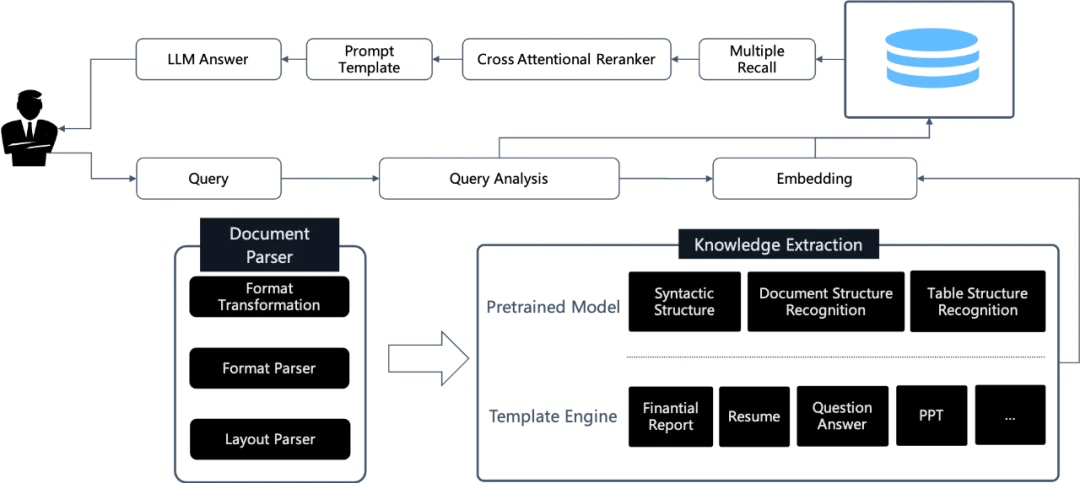
其中,检索系统能提供具体、相关的事实和数据,而生成模型则能够灵活地构建回答,并融入更广泛的语境和信息。这种结合使得 RAG 系统在处理复杂的查询和生成信息丰富的回答方面非常有效,被广泛应用于需要高质量文本生成和信息查询的场景,如智能客服、问答系统和内容生成等领域。
RAG 技术的相较于原生的大模型,具有如下几种天然的优势:
-
减轻幻觉问题:RAG 通过检索外部信息来辅助大模型回答问题,能显著减少生成信息不准确的问题,增加回答的可追溯性与解释性。
-
保护数据隐私:RAG 可以将知识库作为外部组件来管理企业或机构的私有数据,进而避免数据在微调阶段被模型学习后以不可控的方式泄露。
-
信息的实时性:RAG 允许从外部数据源实时检索信息并添加至知识库,使得系统回复可以获取当前最新的、领域特定的知识,解决知识时效性问题。
-
搭建的性价比:RAG 通过外挂业务知识库即可使大模型得到当前业务的知识拓展,无需进行高成本的模型微调优化操作。
可见,RAG 系统对于个人搭建本地私有化金融知识库来说,是一个性价比最好的解决方案。
二、RAG 开源系统选择
如果你是一个资深程序爱好者,你可能在想该如何搭建出对应的 RAG 系统,这里我也提前进行了调查。简单来说,RAG 系统主要由 RAG引擎、前端页面、向量数据库、语言大模型和外部搜索引擎这五块部件组成,因此我们只要确定每个部件的开发工具就可以自行构建,下面认为合理的组合:
- RAG引擎:langchain
- 前端页面:chainlit
- 向量数据库:elasticsearch
- 语言大模型:qwen2
- 外部搜索引擎:searxng
langchain 是一个为自然语言模型应用到构建提供诸多功能接口的框架;chainlit 是用于快速开发和部署对话系统的开源工具;elasticsearch 是一个支持全文搜索和分析的分布式向量数据库,qwen2 是阿里巴巴开源的国产大模型,经过调研,它是中文、日文和金融综合能力最高的开源模型;searxng 是能够整合多个搜索引擎结果的元搜索引擎。
那么有人问,我没有精力去搭建一个系统,那怎么办?别担心,我也调研了现在比较主流的开源 RAG 系统,它们都是端到端的产品,开箱即用。目前有:
- AnythingLLM
- RagFlow
- open-webui
- QAnything
- FastGPT
- MaxKB
- Langchain-Chatchat
这些开源系统都有着各自的特点,我虽然都进行了体验,但由于篇幅就不一一列举了,简单来说,AnythingLLM 可以配合 LMStuido 完成应用程序的配合使用,只需下载无需编程知识;open-webui 是小M最喜欢的界面,使用体验也是最好的,但是文本解析依旧有短板;FastGPT 具有许多友好的接口设置,方便用户将应用部署到诸如微信等其余平台提供功能服务。
这里还有一个待解决的问题,那就是上述系统只是提供了 RAG 使用环境,对于大模型的选择是需要用户自行确定的,这里主要有模型厂家的收费接口和本地部署大模型权重两种选择。
一般而言,对于大多数人,如果没有使用大模型权重进行任务开发的需求的话,建议使用收费接口即可,因为随着国内私募幻方旗下的 DeepSeek 开始打起价格战,国内模型厂家的收费接口也开始更加低廉,大约每百万的 tokens 只是收费三四块人民币。同时使用接口,也无需担忧硬件限制导致的模型文本生成的质量和效率问题。
如果确实有本地构建任务开发的需求,比如想使用大模型来进行每日新闻情感极性分析,以辅助中低频交易中给出合理的交易信号。此时如果采用收费接口的方法,可能会由于大量的文本传输而导致成本费用上升,此时便需要进行本地大模型权重的部署。
考虑这篇文章主要面向个人计算机的场景,这里也提供一点本地部署大模型的建议。如果硬件存在约束,可以首先使用 ollama.cpp 将大模型权重进行轻量化,根据配置甚至可以减少一两倍的内存空间。当然一般而言,开源厂家一般也会提供多个量化版本的模型权重,直接用 ollama 进行下载即可。
三、RagFlow 介绍与源码部署
对于个人搭建 RAG 系统,更推荐大多数人直接使用端到端的开源产品,毕竟大家都有自己的事情,如果有一个现成且效果还好的成品,也没必要一定要自行开发,这里我介绍 RagFlow 。
RAGFlow 是一款完整的 RAG 解决方案,允许用户上传和管理各种文档(PDF、Word、PPT、Excel、TXT)。通过重新研发的智能文档理解系统,RAGFlow 自动识别文档布局(标题、段落、图片、表格等)并对表格内容进行详细解析。它提供行业和岗位定制化模板,适应会计、HR、科研等不同需求,并且支持用户查看和校对解析结果,确保数据从垃圾输入垃圾输出(Garbage In Garbage Out)转变为优质输入优质输出(Quality In Quality Out)。
此外,RAGFlow 强调文档处理的可视化和可解释性,允许用户查看文档解析结果并定位到原文,提高答案的准确性和可追溯性。RAGFlow 也通过提供原文引用链接和详细的处理结果展示,帮助用户高效管理和利用文档数据,显著减少生成信息不准确的风险,满足各行业的文档管理需求。
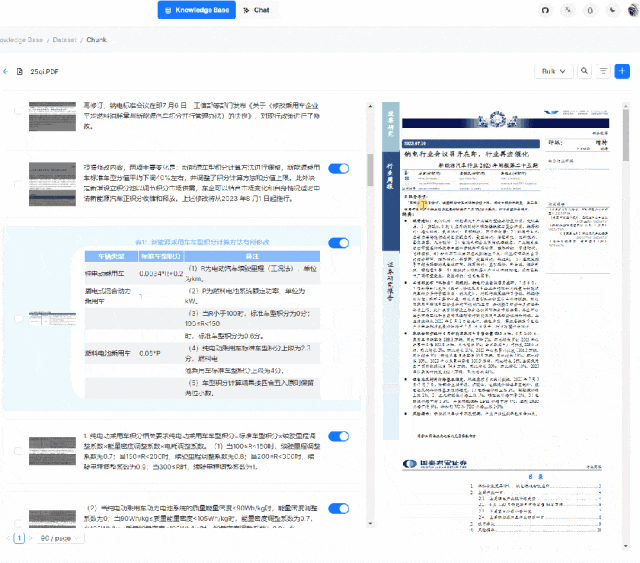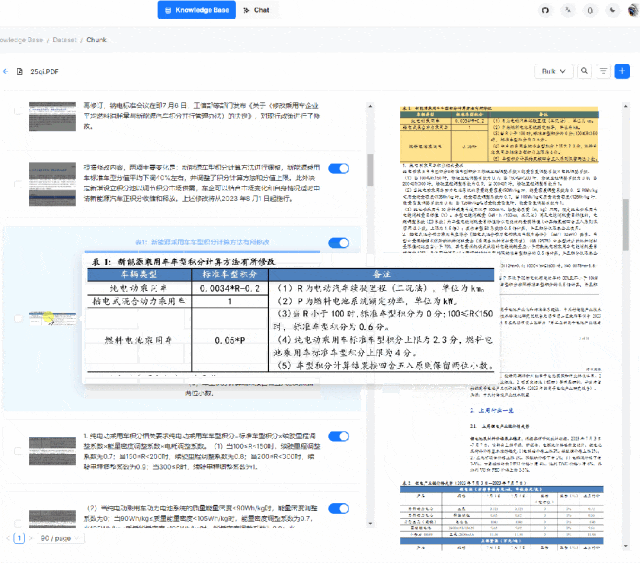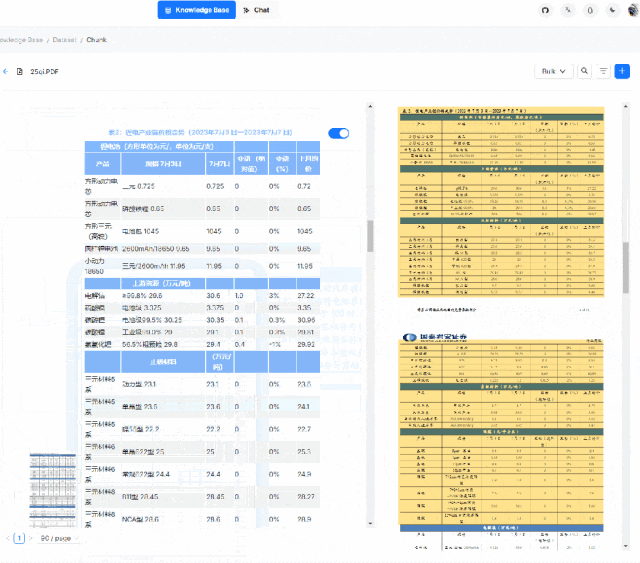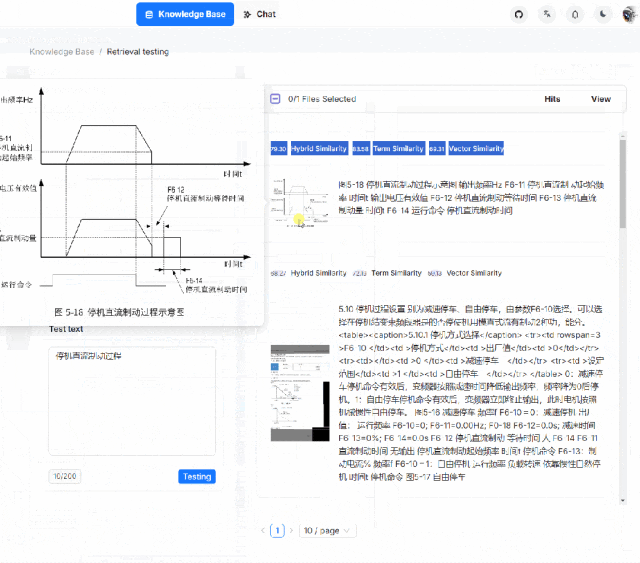
目前 RagFlow 提供两种方法,分别是使用开源社区提供的 RagFlow 镜像,本地下载即可启动使用,另一种是使用开源社区提供的源代码进行编译运行。两种方法都有使用过,第一种方法是最方便的,但由于只能使用 CPU 处理,在文本深度解析的过程中往往会出现时间耗费较长的现象,这也是为什么小木这里给出源码部署的原因。
由于 RagFlow 主要是支持 Linux,而小木使用的是 Mac M1 ,在本地部署的时候还是花了不少时间,这里也感谢官方给予的帮助,这里就为 Mac M1 提供整理好的步骤分享给大家, Linux 的话官方文档已经足够详细。
- 创建并激活 Anaconda 虚拟环境
$ conda create -n ragflow python=3.11.0
$ conda activate ragflow
- 克隆仓库,安装对应 python 依赖包
$ git clone https://github.com/infiniflow/ragflow.git
$ cd ragflow/
$ pip install -r requirements_arm.txt
- 拷贝入口脚本并配置环境变量
$ cp docker/entrypoint.sh .
$ vi entrypoint.sh
PY=命令 which python 的返回值
export PYTHONPATH=命令 pwd 的返回值
export HF_ENDPOINT=https://hf-mirror.com export MACOS=TRUE
4. 使用 docker 启动第三方基础服务
$ cd docker
$ vi docker-compose-base.yml
将 mysql/image 修改成 mariadb:10.5.8
$ docker compose -f docker-compose-base.yml up -d
- 检查 /conf/service_conf.yaml 配置文件
将 ragflow/host 修改成 127.0.0.1
将 mysql/host 修改成 ‘127.0.0.1’
将 minio/host 修改成 ‘127.0.0.1:9000’
将 es/hosts 修改成 ‘http://127.0.0.1:9200’
将 redis/hosts 修改成 ‘127.0.0.1:6379’
- 启动 ragflow 后端服务
$ chmod +x ./entrypoint.sh
$ bash ./entrypoint.sh
- 启动 ragflow 前端服务
$ cd web
$ npm install --registry=https://registry.npmmirror.com --force
$ vim .umirc.ts
将 proxy.target 修改成 http://127.0.0.1:9380
$ npm run dev
- 安装 ragflow 前端服务器 nginx
$ cd web
$ npm install --registry=https://registry.npmmirror.com --force
$ umi build
$ mkdir /Users/xxx/ragflow
$ mkdir /Users/xxx/ragflow/web
$ sudo ln -s /Users/xxx/ragflow /ragflow
$ cp -r dist /ragflow/web
$ brew install nginx
- 拷贝配置文件并启动 ragflow 前端服务
vim ../docker/nginx/proxy.conf
将 error_log 修改成 /opt/homebrew/var/log/nginx/error.log notice;
将 pid 修改成 /opt/homebrew/var/run/nginx.pid;
将 include 修改成 /opt/homebrew/etc/nginx/mime.types;
将 access_log 修改成 /opt/homebrew/var/log/nginx/access.log
将 include 修改成 /opt/homebrew/etc/nginx/ragflow.conf;
vim ../docker/nginx/ragflow.conf
将 proxy_pass 修改成 http://127.0.0.1:9380;
$ cp ../docker/nginx/proxy.conf /opt/homebrew/etc/nginx
$ cp ../docker/nginx/nginx.conf /opt/homebrew/etc/nginx
$ cp ../docker/nginx/ragflow.conf /opt/homebrew/etc/nginx/conf.d
$ sudo nginx -s reload
xxx 表示自己的账户目录名称。
如果显示没有 conf.d,则杀死先行 ragflow 前端所有进程,再次执行 nginx -s reload。
四、总结
尽管 RAG 系统可以显著提高语言模型的事实准确性,但它们并不是对抗错误信息的万能药。正如前文所讲的,RAG 系统分为语义检索和召回生成两大过程,然而语义检索的效果也直接影响了大模型的生成效果,这往往要求了更加强力的 embedding 模型来增强语义表征,同时由于 RAG 不是直接对文件进行总结,而是进行拆分后再进行召回,因此生成也存在诸多影响因素,如召回阶段检索到的知识片段可能存在缺失,使用的 top k 限制和相似度匹配机制也可能导致检索过程不够完美。
随着月之暗面推出长文本大模型 kimi 后,用户可以很方便地上传几十篇 PDF,大模型可以根据这些文件进行回答问题,并且还可以识别复杂图表里的内容。但是对于普通中小企业而言,搭建一个低成本高可靠的私有化知识库,系统搭建过程中大模型所需的 tokens 依旧需要着重考量。
五、最后分享(全套大模型学习资料)
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】
