介绍
将视觉能力与大型语言模型(LLMs)结合的多模态LLM(MLLM)正在通过多模态LLM革命性地改变计算机视觉领域。这些模型结合了文本和视觉输入,展示了在图像理解和推理方面的出色能力。虽然这些模型以前只能通过API访问,但最近的开源选项现在允许本地执行,使其在生产环境中更具吸引力。
在此教程中,我们将学习如何使用开源的Llama 3.2-Vision模型与图像进行聊天,你会对其OCR、图像理解和推理能力感到惊讶。所有代码都方便地提供在一个实用的Colab笔记本中。
如果你没有付费的Medium账户,你可以在这里免费阅读。
Llama 3.2-Vision
背景
Llama,即“大型语言模型元AI”,是Meta开发的一系列高级LLM。他们最新的Llama 3.2引入了先进的视觉能力。视觉变体有11B和90B参数两种大小,能够在边缘设备上进行推理。拥有高达128k令牌的上下文窗口和对高达1120x1120像素的高分辨率图像的支持,Llama 3.2可以处理复杂的视觉和文本信息。
架构
Llama系列模型是解码器仅有的Transformer模型。Llama 3.2-Vision基于预训练的纯文本Llama 3.1模型构建。它采用标准的密集自回归Transformer架构,与前代Llama和Llama 2相比,没有显著偏离。
为了支持视觉任务,Llama 3.2使用预训练的视觉编码器(ViT-H/14)提取图像表示向量,并通过视觉适配器将这些表示集成到冻结的语言模型中。适配器由一系列交叉注意力层组成,这些层使模型能够专注于处理文本时与之对应的图像特定部分[1]。
适配器是在文本图像对上进行训练的,以将图像表示与语言表示对齐。在适配器训练期间,更新图像编码器的参数,而语言模型参数保持冻结,以保留现有的语言能力。
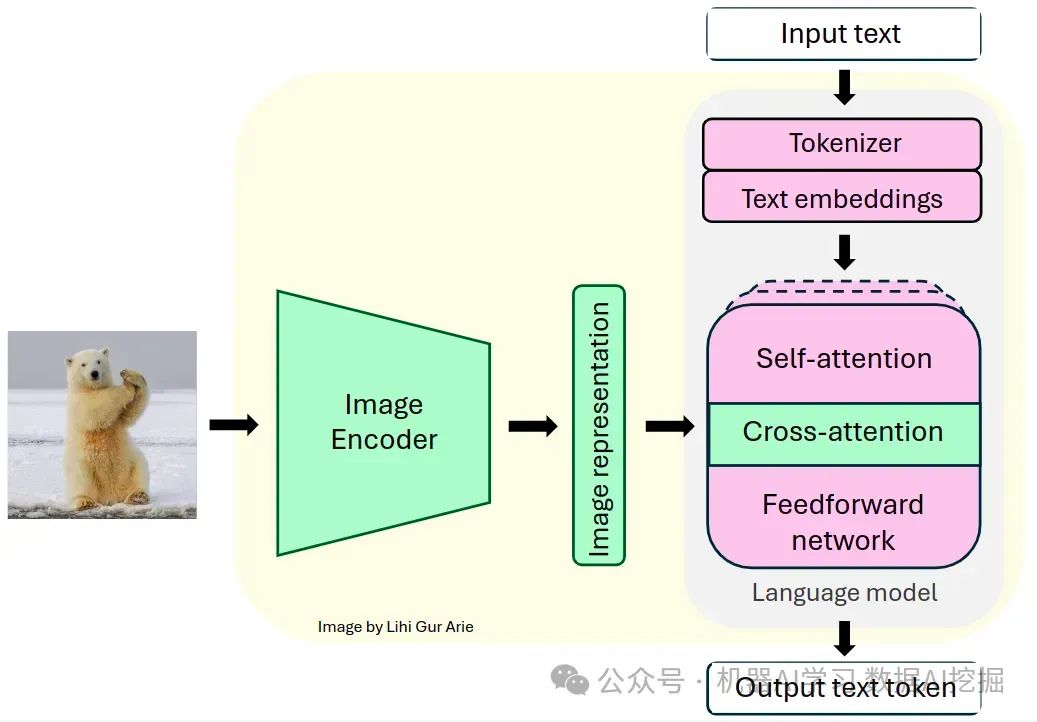
此设计使Llama 3.2在多模态任务中表现出色,同时保持其仅文本任务的强大性能。该模型在需要同时理解和处理图像与语言的任务中展示了出色的能力,并允许用户与其视觉输入进行交互式沟通。
开始编码!
在了解了Llama 3.2的架构后,我们可以深入实际的实现。但在开始之前,我们需要做一些准备工作。
准备工作
在Google Colab上运行Llama 3.2—Vision 11B之前,我们需要做一些准备工作:
GPU设置:
推荐使用至少配备22GB显存的高端GPU以实现高效的推理[2]。
对于Google Colab用户:导航至‘运行时’ > ‘更改运行时类型’ > ‘A100 GPU’。请注意,高端GPU可能无法免费提供给Colab用户。
2. 模型权限:
在此处申请访问Llama 3.2模型。
3. Hugging Face设置:
如果您还没有Hugging Face账户,请在此处创建一个。
如果您还没有,从您的Hugging Face账户中生成访问令牌,在此处。
对于Google Colab用户,在google Colab Secrets中将Hugging Face令牌设置为名为‘HF_TOKEN’的密钥环境变量。
4. 安装所需的库。
加载模型
在完成环境设置并获得必要的权限后,我们将使用Hugging Face Transformers库来实例化模型及其相关处理器。处理器负责为模型准备输入并格式化其输出。
model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto")
processor = AutoProcessor.from_pretrained(model_id)
预期对话模板
对话模板通过存储“用户”(我们)和“助理”(AI模型)之间的交流历史来保持上下文。对话历史被组织成一个名为消息的字典列表,其中每个字典代表一次对话回合,包括用户和模型的响应。用户的回合可以包含图文或纯文本输入,{“type”: “image”} 表示图像输入。
例如,在几次对话迭代后,消息列表可能如下所示:
messages = [
{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": prompt1}]},
{"role": "assistant", "content": [{"type": "text", "text": generated_texts1}]},
{"role": "user", "content": [{"type": "text", "text": prompt2}]},
{"role": "assistant", "content": [{"type": "text", "text": generated_texts2}]},
{"role": "user", "content": [{"type": "text", "text": prompt3}]},
{"role": "assistant", "content": [{"type": "text", "text": generated_texts3}]}
]
此消息列表随后会被传递给 apply_chat_template() 方法,以将对话转换为模型期望的单个可分词字符串格式。
主函数
在此教程中,我提供了一个 chat_with_mllm 函数,该函数可与 Llama 3.2 MLLM 实现动态对话。此函数负责图像加载、对图像和文本输入进行预处理、生成模型响应,并管理对话历史记录以支持聊天模式交互。
def chat_with_mllm (model, processor, prompt, images_path=[],do_sample=False, temperature=0.1, show_image=False, max_new_tokens=512, messages=[], images=[]):
# Ensure list:
if not isinstance(images_path, list):
images_path = [images_path]
# Load images
if len (images)==0 and len (images_path)>0:
for image_path in tqdm (images_path):
image = load_image(image_path)
images.append (image)
if show_image:
display ( image )
# If starting a new conversation about an image
if len (messages)==0:
messages = [{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": prompt}]}]
# If continuing conversation on the image
else:
messages.append ({"role": "user", "content": [{"type": "text", "text": prompt}]})
# process input data
text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(images=images, text=text, return_tensors="pt", ).to(model.device)
# Generate response
generation_args = {"max_new_tokens": max_new_tokens, "do_sample": True}
if do_sample:
generation_args["temperature"] = temperature
generate_ids = model.generate(**inputs,**generation_args)
generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:-1]
generated_texts = processor.decode(generate_ids[0], clean_up_tokenization_spaces=False)
# Append the model's response to the conversation history
messages.append ({"role": "assistant", "content": [ {"type": "text", "text": generated_texts}]})
return generated_texts, messages, images
与Llama对话
蝴蝶图像示例
在我们的第一个例子中,我们将与Llama 3.2讨论一张蝴蝶破茧而出的图片。由于Llama 3.2-Vision在使用图像时不支持系统提示,我们将直接在用户提示中添加指令来引导模型的响应。通过设置do_sample=True和temperature=0.2,我们可以在保持响应连贯性的同时启用轻微的随机性。对于固定答案,你可以将do_sample设置为False。消息参数(包含对话历史)最初为空,就像图像参数一样。
instructions = "Respond concisely in one sentence."
prompt = instructions + "Describe the image."
response, messages,images= chat_with_mllm ( model, processor, prompt,
images_path=[img_path],
do_sample=True,
temperature=0.2,
show_image=True,
messages=[],
images=[])
# Output: "The image depicts a butterfly emerging from its chrysalis,
# with a row of chrysalises hanging from a branch above it."
如下所示,输出准确且简洁,证明了模型有效地理解了图像。
对于下一个聊天迭代,我们将传递一个新的提示,连同聊天历史(消息)和图像文件(图片)一并提供。新的提示旨在评估Llama 3.2的推理能力:
prompt = instructions + "What would happen to the chrysalis in the near future?"
response, messages, images= chat_with_mllm ( model, processor, prompt,
images_path=[img_path,],
do_sample=True,
temperature=0.2,
show_image=False,
messages=messages,
images=images)
# Output: "The chrysalis will eventually hatch into a butterfly."
我们在提供的Colab笔记本中继续了这次聊天,并获得了以下对话:
对话突出了模型的画面理解能力,通过准确描述场景来展现这一点。它还通过逻辑地连接信息,来正确推断出蚕茧会发生什么,并解释为什么有些是棕色而有些是绿色,从而展示了其推理能力。
- 梗图示例
在此示例中,我将向模型展示我自己创建的一个梗图,以评估Llama的OCR能力,并确定它是否理解了我的幽默感。
instructions = "You are a computer vision engineer with sense of humor."
prompt = instructions + "Can you explain this meme to me?"
response, messages,images= chat_with_mllm ( model, processor, prompt,
images_path=[img_path,],
do_sample=True,
temperature=0.5,
show_image=True,
messages=[],
images=[])
这是输入的梗图:

以下是模型的响应:

正如我们所见,该模型展示了出色的OCR能力,并理解了图像中文字的含义。至于它的幽默感——你觉得它懂了吗?你懂了吗?也许我也该提高一下自己的幽默感!
结语
在本教程中,我们学习了如何本地构建Llama 3.2-Vision模型,并管理对话历史以增强类似聊天的交互,提升用户体验。我们探讨了Llama 3.2的零样本能力,并对其场景理解、推理和OCR技能印象深刻。
可以将高级技术应用于Llama 3.2,例如在独特数据上进行微调,或使用检索增强生成(RAG)来验证预测并减少幻觉现象。
总的来说,本教程为快速发展的多模态大语言模型领域及其在各种应用中的强大能力提供了见解。
最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】
