数据查询
数据查询是数据库的核心操作,是使用频率最高的操作。SQL提供了SELECT语句进行数据库的查询,该语句具有灵活的使用方式和丰富的功能。
SELECT语句的基本语法如下:
SELECT * |<列名|列表达式> [,<列名! 列表达式>]......
FROM <表名或视图名>[,<表名或视图名>]......
[ WHERE <条件表达式> ]
GROUP BY <分组列名1][,<分组列名2>]......
[ ORDER BY <排序列名1[ ASC| DESC]> [,<排序列名2 [ASC | DESC]>]...];
在语法中,[]表示该部分是可选的,<>表示该部分是必有的,注意在写具体命令时[]和<>不能写。
整个语句的执行过程如下。
(1)读取FROM子句中的表,视图的数据,如果是多个表或视图,执行笛卡尔儿积操作。
(2)选择满足WHERE子句中给出的条件表达式的记录。
(3)按GROUP BY子句中指定列的值对记录进行分组,同时提取满足HAVING子句中组条件表达式的那些组。
(4)按SELECT子句中给出的列名或列表达式求值输出。
(5)ORDER BY子句对输出的记录进行排序,按ASC升序排列或按DESC降序排列。SELECT语句既可以完成简单的单表在询,也可以完成复杂的连接查询和嵌套查询。
1. SELECT子句的规定
SELECT子句用于描述输出值的列名或表达式,其形式如下:
SELECT[ ALL I DISTINCT] *[ <列名或列名表达式序列>
(1)DISTINCT选项表示输出无重复结果的记录;ALL选项是默认的,表示输出凯记录:包括重复记录。
(2)关表示选取表中所有的字段。
1. SELECT子句的规定
SELECT子句用于描述输出值的列名或表达式,其形式如下:
SELECT[ ALL I DISTINCT] *[ <列名或列名表达式序列>
【注】
(1)DISTINCT选项表示输出无重复结果的记录;ALL选项是默认的,表示输出所有记录,包括重复记录。
(2) * 表示选取表中所有的字段。
我们先在company建议三个表,分别是 dept,emp和salgrade
具体如下
CREATE DATABASE company;
USE company;
CREATE TABLE dept
(
deotno DECIMAL(2,0) NOT NULL PRIMARY KEY,
dname VARCHAR(14) ,
loc VARCHAR(13)
);
INSERT INTO dept VALUES(10,'ACCOUNTING','NEW YORK');
INSERT INTO dept VALUES(20,'RESEARCH','DALLAS');
INSERT INTO dept VALUES(30,'SALES','CHICAGO');
INSERT INTO dept VALUES(40,'OPERATIONS','BOSTON');
CREATE TABLE emp
(
emono DECIMAL(4,0) NOT NULL PRIMARY KEY,
ename VARCHAR(10),
job VARCHAR(9),
mor DECIMAL(4,0),
hiredate DATE,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deotno DECIMAL(2,0)
);
INSERT INTO emp VALUE (7369,'SMITH','CLERK','7902','1980-12-17',800,NULL,20);
INSERT INTO emp VALUE (7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30);
INSERT INTO emp value(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30);
INSERT INTO emp values(7566,'JONES','MANAGER',7839,'1981-04-02',2975,NULL,20);
INSERT INTO emp VALUE(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30);
INSERT INTO emp VALUE(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,NULL,30);
INSERT INTO emp VALUE(7782,'CLARK','MANAGER',7839,'1981-06-09',2450,NULL,10);
INSERT INTO emp VALUE(7788,'SCOTT','ANALYST',7566,'1987-04-19',3000,NULL,20);
INSERT INTO emp VALUE(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10);
INSERT INTO emp VALUE(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,NULL,30);
INSERT INTO emp VALUE(7876,'ADAMS','CLERK',7788,'1987-05-28',1100,NULL,20);
INSERT INTO emp VALUE(7900,'JAMES','CLERK',7698,'1981-12-03',950,NULL,30);
INSERT INTO emp VALUE(7902,'FORD','ANALYST',7566,'1981-12-03',3000,NULL,20);
INSERT INTO emp VALUE(7934,'MILLER','CLERK',7782,'1982-01-23',1300,NULL,10);
CREATE TABLE salgrade
(
orade DECIMAL(10,0) ,
losal DECIMAL(10,0),
hisal DECIMAL(10,0)
);
INSERT INTO salgrade VALUE (1,700,1200);
INSERT INTO salgrade VALUE (2,1201,1400);
INSERT INTO salgrade VALUE (3,1401,2000);
INSERT INTO salgrade VALUE (4,2001,3000);
INSERT INTO salgrade VALUE (5,3001,9999);
(1)查询表的全部数据
【例1-1】
SELECT * FROM dept;
DESC dept; 
DESC emp; 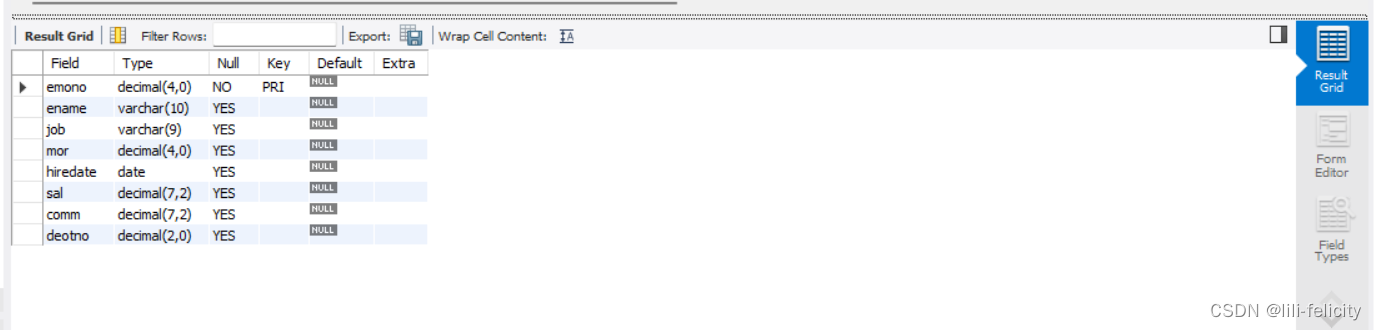
SELECT * FROM emp; 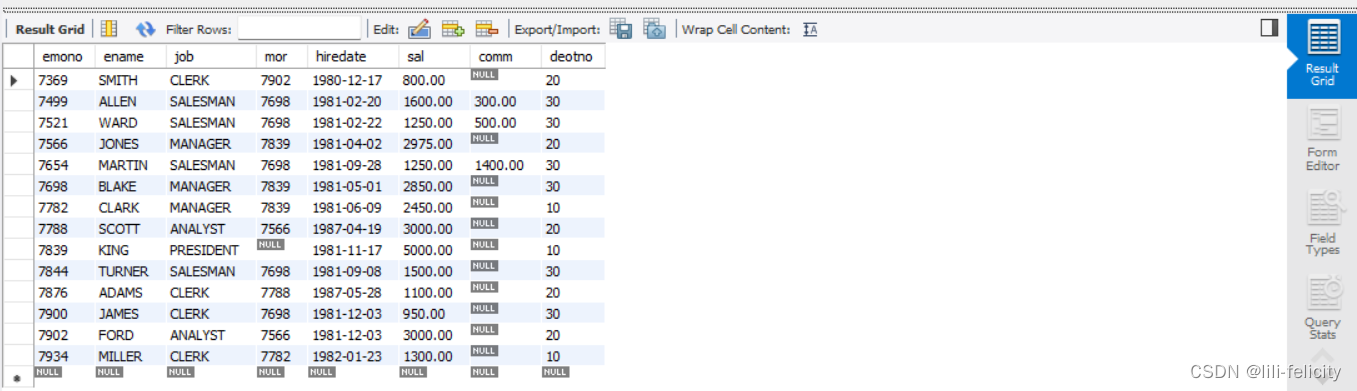
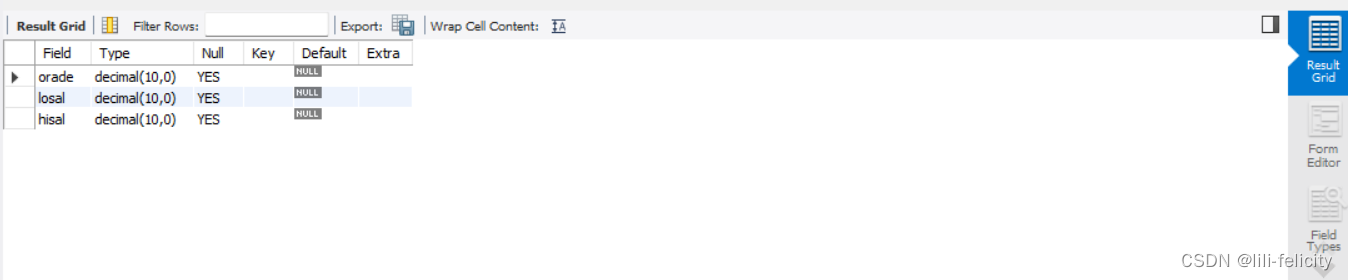
DESC salgrade;
SELECT * FROM salgrade;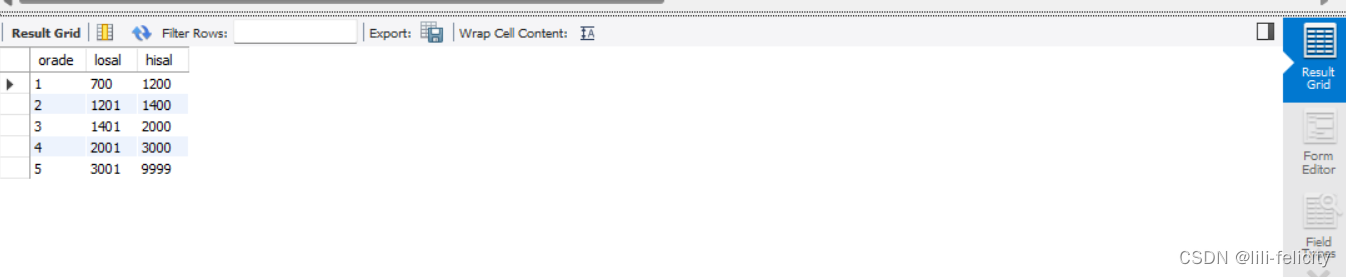
(2)查询指定的列
【例1-2】查询dept 表的部门编号deptno和部门名称dname
SELECT deotno,dname FROM dept;
(3)去掉重复行
【例1-3】查询雇员表emp中各部门的职务信息
SELECT deotno,job FROM emp; 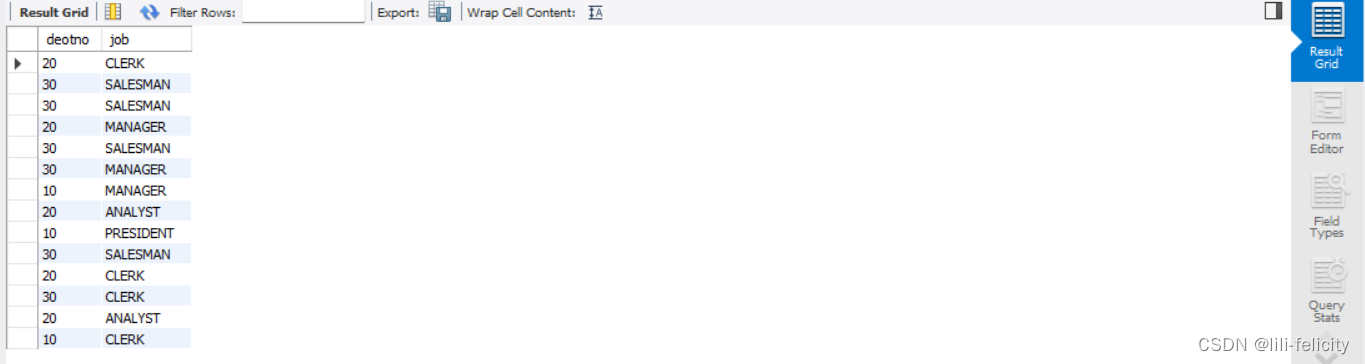
【例1-4】查询上面结果中有重复的行值出现,需要去掉重复的记录
SELECT DISTINCT DEOTNO,job FROM emp; 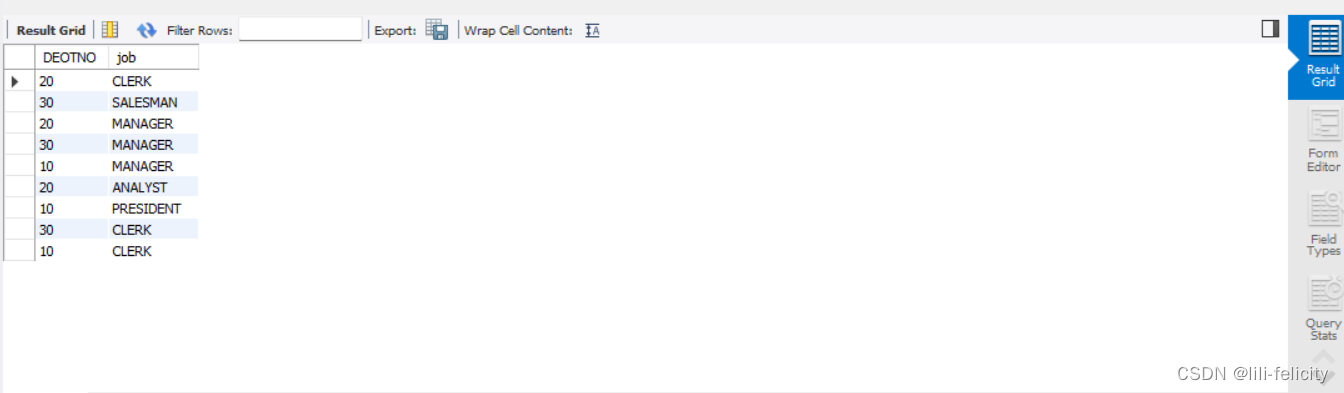
2.为列起别名的操作
在显示选择查询的结果时,第1行(即表头)中显示的是各个输出字段的名称。为了便于阅读,也可指定更容易理解的列名来取代原来的字段名。设置别名的格式如下:
原宇段名[AS]列别名
【例1-5】在 emp表中查询每个员工的emono、ename、hiredate,输出的列名为雇员编号、雇员姓名、雇佣日期。
SELECT emono AS 雇员编号,ename AS 雇员姓名,hiredate AS 雇佣日期 FROM emp;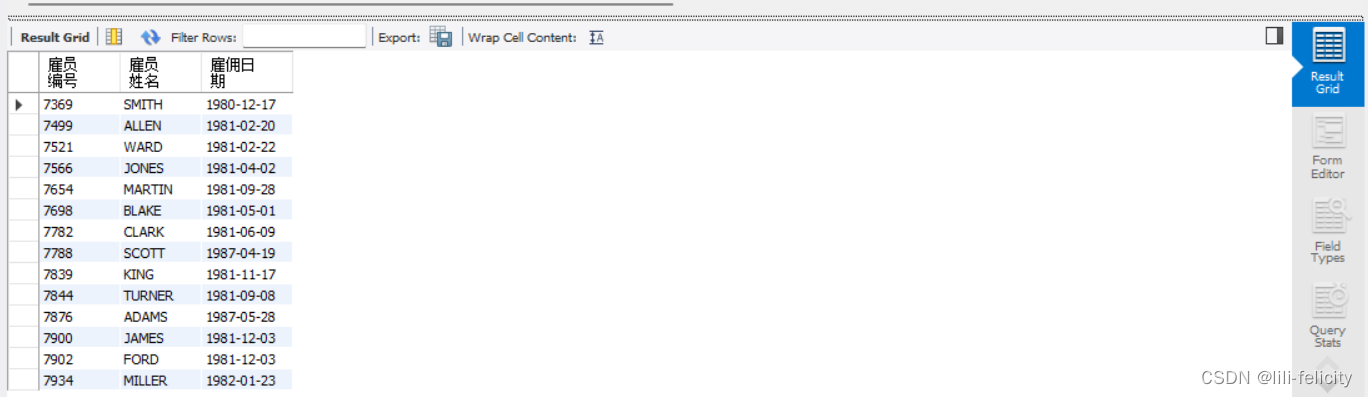
3.使用WHERE子句指定查询条件
WHERE子句后的行条件表达式可以由各种运算符组合而成,常用的比较运算符如表1-3常用的比较运算符
| 运算符名称 | 符号及格式 | 说 明 |
| 算术比较判断 |
θ代表的符号有<、<=、>、>=、< >或!=、= |
比较两个表达式的值 |
| 逻辑比较判断 | <比较表达式1>θ<比较表达式2>θ代表的符号按其优先级由高到低的顺序为NOT、AND、OR | 两个比较表达式进行非、与、或的运算 |
| 之间判断 | <表达式> [NOT] BETWEEN<值1> AND<值2> | 搜索(不)在给定范围内的数据 |
| 字符串模糊判断 | <字符串> [NOT] LIKE <匹配模式> | 查找(不)包含给定模式的值 |
| 空值判断 | <表达式> IS [NOT]NULL | 判断某值是否为空值 |
| 之内判断 | <表达式> [NOT] IN(<集合>) | 判断表达式的值是否在集合内 |
(1)比较判断
【例1-6】查询SMITH的雇佣日期
SELECT ename,hiredate FROM emp WHERE ename='SMITH';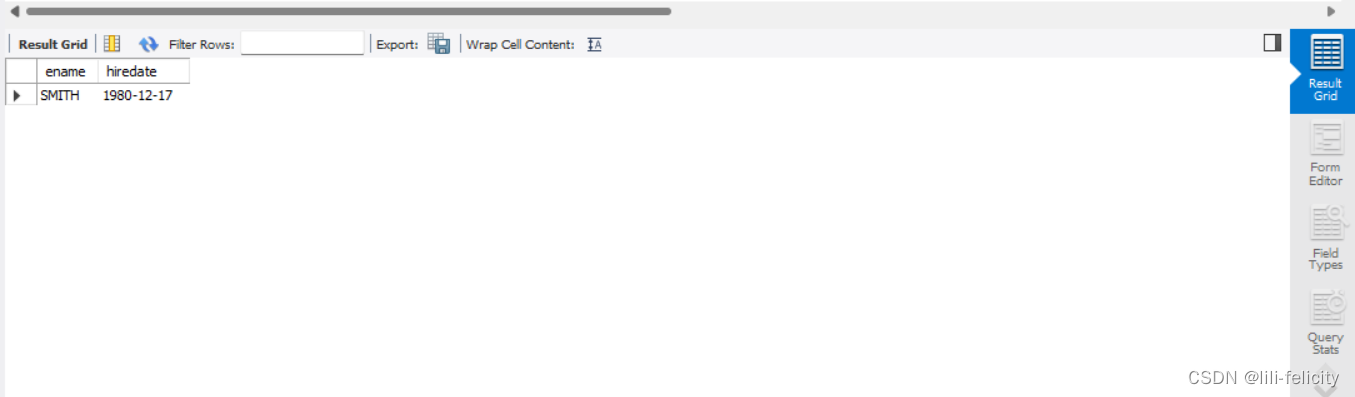
【例1-7】查询emp表在部门10工作的、工资高于1000岗位是CLERK的所有雇员的姓名、工资、岗位的信息。
SELECT ename,job,sal FROM emp
WHERE deotno=10 AND(sal>1000 OR job='CLERK');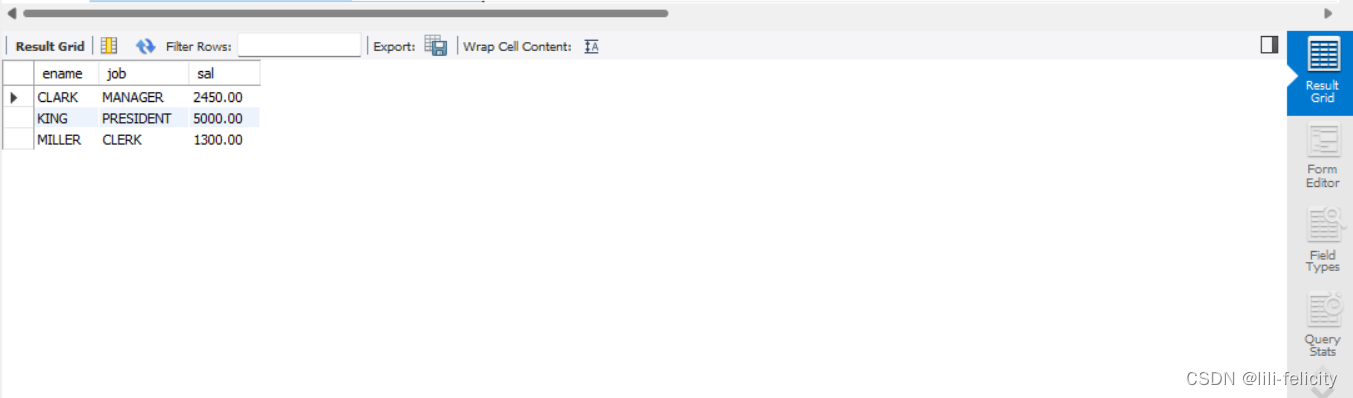
(2)之内判断
用BETWEEN...AND来确定一个连续的范围,要求BETWEEN后面指定小值,AND后面指定大值。
例如:,sal BETWEEN 1000 AND 2000,相当于sal>= 1000 AND sal<= 2000 JjT .
【例1-8】查询emp表中工资为2500~3000,1981年聘用的所有雇员的姓名、工资、聘用日期信息。
SELECT ename,sal,hiredate FROM emp
WHERE sal BETWEEN 2500 AND 3000
AND hiredate BETWEEN '1981-01-01'AND '1981-12-31'; 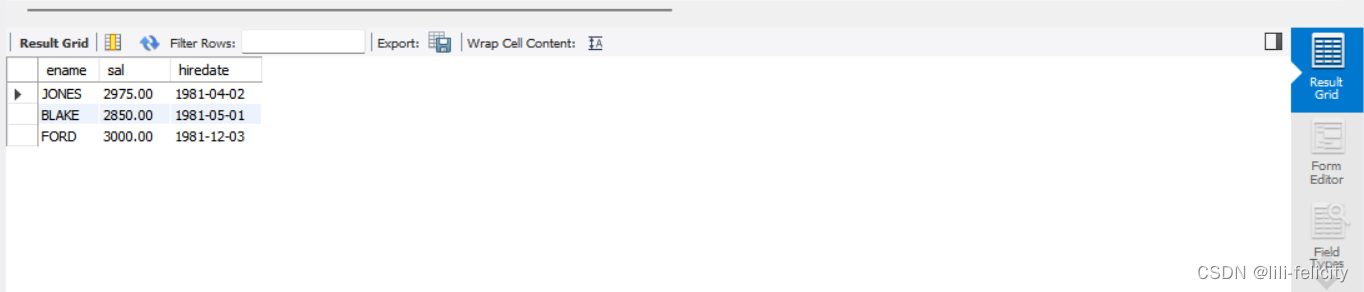
(3)字符串的模糊查询
使用LIKE运算符进行字符串模糊匹配查询,格式如下:
[NOT]LIKE '匹配字符串'
在匹配字符串中使用通配符“%”和“_”。“%"用于表示0个或任意多个字符,“_”表示任意一个字符。
【例1-9】查询emp表中的所有姓名以K开头或姓名的第二个字母为C的员工的姓名、部门号和工资信息
SELECT ename,deotno,sal FROM emp
WHERE ename LIKE 'K%' OR ename LIKE '_C%';(4)空值判断
【例1-10】查询EMP表中1981年聘用没有补助的员工的姓名和职位信息
SELECT ename,job FROM emp
WHERE hiredate BETWEEN '1981-01-01' AND '1981-12-31'
AND COMM IS NULL;(5)之内判断
可以使用IN实现数值之内的判断,例如sal IN (2000, 3000),它相当于sal= 2000 OR sal= 3000的表达式。
【例1-11】查询emp表中部门20和30中的岗位是CLERK的所有雇员的部门号、姓名、工资信息。
SELECT deotno,ename,sal FROM emp
WHERE deotno IN(20,30)
AND job='CLERK';4.使用ORDERBY子句对查询结果排序
在使用ORDER BY子句对查询结果进行排序时要注意以下两点。
(1)当SELECT语句中同时包含多个子句时,例如WHERE GROUP BY、HAVING、ORDER BY子句,ORDER BY子句必须是最后一个子句。
(2)可以使用列的别名、列的位置进行排序。
【例1-12】以部门号的降序 、姓名的升序查询emp表中工资为2000~ 3000元的员工的部门号、姓名、工资和补助信息。
SELECT deotno,ename,sal,comm FROM emp
WHERE sal BETWEEN 2000 AND 3000
ORDER BY deotno DESC,ename;【例1-13】使用列的别名,列的位置进行排序,改写【例1-12】
SELECT deotno AS '部门编号',ename,sal,comm FROM emp
WHERE sal BETWEEN 2000 AND 3000
ORDER BY '部门编号' DESC,2;2.分组查询
数据分组是通过在SELECT语句中加人GROUP BY子句完成的。通常用聚合函效对每个组中的数据进行汇总、统计,用HAVING子句来限定查询结果集中只显示分组后的、其聚合函数的值满足指定条件的那些组
1.聚合函数
聚合函数也称为分组函数,作用于查询出的数据组,并返回一个汇总 、统计结果。常用的聚合函数如表2-1所示。
| 函数 |
说明 |
| COUNT(* ) COUNT(<列名>) |
计算记录的个数 对一列中的值计算个数 |
| AVG(<列名>) | 求某一列值的平均值 |
| MAX(<列名>) | 求某一列值的最大值 |
| MIN(<列名>) | 求某一列值的最小值 |
| SUM(<列名>) |
求某一列值的总和 |
在使用聚合函数时需要注意以下两点。
(1)聚合函数只能出现在所查询的列、ORDER BY子句、HAVING子句中,不能出现在WHERE子句GROUP BY子句中。
(2)除了COUNT(*)以外,其他聚合函数(包括COUNT(<列名>))都忽略对列值为NULL的统计。
【例1-14】统计deotno 为30的部门的平均工资,总补助款、总人数、补助人数、最高工资和最低工资
SELECT emono,sal,comm FROM emp WHERE deotno =30;下面这些数据是聚合函数处理的结果
SELECT AVG(sal) AS 平均工资 ,SUM(comm) 总补助款,
COUNT(*)AS 总人数,COUNT(comm)补助人数,
MAX(sal) AS 最高工资, MIN(sal) 最低工资
FROM emp WHERE deotno=30;2.使用GROUP BY子句
(1)按单列分组
【例1-15】查询emp表中的每个部门的平均工资和最高工资,并按部门编号升序排序
SELECT deotno,AVG(sal) 平均工资,MAX(sal) 最高工资 FROM emp
GROUP BY deotno
ORDER BY deotno;(2)多列分组
【例1-16】查询emp表中每个部门,每种岗位的平均工资和最高工资
SELECT deotno,job,AVG(sal) 平均工资,MAX(sal) 最高工资 FROM emp
GROUP BY deotno,job
ORDER BY deotno;3.使用HAVING子句
【例1-17】 查询部门编号在30以下的各个部门的部门编号、平均工资,要求只显示平均工资大于或等于2000的信息
SELECT deotno, AVG(sal) 平均工资 FROM emp
WHERE deotno <30
GROUP BY deotno
HAVING AVG(sal)>=2000;3.子查询
子查询是指嵌人在其他SQL语句中的一个查询。在子查询中还可以继续嵌套子查询。使用子查询,可以用一系列简单的查询构成复杂的查询,从而增强SQL语句的功能。子查询的执行步骤如下。
(1)首先取外层查询中表的第1个记录,根据它与内层查询相关的列值进行内层查询的处理(例如WHERE子句的处理),若处理结果为真,则取此记录放人结果集。
(2)然后取外层表的下一个记录进行内层查询的处理。
(3)重复这一过程,直到外层查询中表的全部记录处理完为止。
1.返回单值的子查询
单值子查询向外层查询只返回一个值。
【例1-18】查询与SCOTT工作岗位相同的员工的员工编号,姓名,工资和岗位信息
SELECT emono,ename,sal,job FROM emp
WHERE job=(SELECT job FROM emp WHERE ename='SCOTT');【例1-19】查询工资大于平均工资而且与SCOTT工作岗位相同的员工信息
SELECT emono,ename,sal,job FROM emp
WHERE job=(SELECT job FROM emp WHERE ename='SCOTT')
AND SAL>(SELECT AVG(sal) FROM emp);2.返回多值的子查询
多值子查询可以向外层查询返回多个值。在WHERE子句中使用多值子查询时必须使用多值比较运算符,例如[NOT] IN、[NOT] EXISTS.ANY、AlL,其中ALLANY必须与比较运算符结合使用。
(1)使用IN操作符的多值子查询
比较运算符IN的含义为子查询返回列表中的任何一一个。IN操作符比较子查询返回列表中的每一个值,并且显示任何相等的数据行。
【例1-20】查询工资为所任岗位最高的员工的员工编号、姓名、岗位和工资信息,不包含岗位为CLERK和PRESIDENT的员工。
SELECT emono, ename, job, sal FROM emp
WHERE sal IN (SELECT MAX( sal) FROM emp GROUP BY job)
AND job<>'CLERK' AND job<> 'PRESIDENT';(2)使用ALL操作符的多值子查询
ALL操作符比较子查询返回表中的每一个值。< ALL为小于最小值,> ALL为大于最大值
【例1-21】查询高于部门20的所有雇员工资的雇员信息。
SELECT ename,sal,job FROM emp
WHERE sal>all(SELECT sal FROM emp WHERE deotno=20); 这个命令相当于
SELECT ename, sal, job FROM emp
WHERE sal>(SELECT MAX(sal)FROM emp WHERE deotno= 20);(3)使用ANY操作符的多值子查询
ANY操作符比较子查询返回列表中的每一个值。< ANY为小于最大的,> ANY为大于最小的。
【例1-22】查询高于部门10的任何雇员工资的信息。
SELECT ename, sal, job FROM emp
WHERE sal > ANY(SELECT sal FROM emp WHERE deotno= 10);这个命令相当于
SELECT ename, sal, job FROM emp
WHERE sal>(SELECT MIN(sal) FROM emp WHERE deotno= 10);(4)使用EXISTS操作符的多行查询
EXISTS操作符比较子查询返回列表中的每一行。在使用EXISTS时应注意外层查询的WHERE子句格式为WHERE EXISTS; 在内层子查询中必须有WHERE子句,给出外层查询和内层子查询所使用表的连接条件。
【例1-23】查询工作 在NEW YORK的雇员的姓名、部门编号、工资和岗位信息。
SELECT ename, deotno,sal,job FROM emp
where deotno IN
( SELECT deotno FROM dept
WHERE loc= 'NEW YORK');4.合并查询结果
当两个SELECT在询结果的结构完全-致时,可以对这两个查询执行合并运算,运算符为UNION。
UNION的语法格式如下:
SELECT 语句1
UNION [ALL]
SELECT 语句2;
UNION在连接数据表的查询结果时,结果中会删除重复的行,所有返回的行都是唯一的。在使用UNION ALL时,结果中不会删除重复行。
【例1-23】合并查询结果示例。
SELECT emono, ename, deotno, job FROM emp WHERE job= 'MANAGER'
UNION
SELECT emono, ename, deotno, job FROM emp WHERE deotno= 10;SELECT emono, ename, deotno, job FROM emp WHERE job= 'MANAGER'
UNION ALL
SELECT emono, ename, deotno, job FROM emp WHERE deotno= 10;【例1-24】 对合并后的查询结果排序
SELECT emono, ename, deotno, job FROM emp WHERE job = 'MANAGER'UNION
SELECT emono, ename, deotno, job FROM emp WHERE deotno= 10
ORDER BY deotno;【 注意】在ORDERBY之后要排序的列名一定是来自第1个表中的列名,第1个表中的列名如果设置了别名,在ORDER BY后面也要写成别名。
SELECT emono, ename,deotno AS 部门编号,job FROM emp WHERE job= 'MANAGER'
UNION
SELECT emono, ename, deotno,job FROM emp WHERE deotno= 10
ORDER BY 部门编号;感谢您阅读这篇关于MySQL数据查询的文章。如果您对深入挖掘数据潜力感兴趣,下一篇博文将带您进入数据维护的新世界。