文章目录
本文主要是基于开源的COT数据集,验证deepseek-r1的微调可行性,使用的是unsloth框架,unsloth目前不支持多卡并行训练,只适合简单的测试和验证,如果需要多卡训练,可以试试LLaMA-Factory和ColossAI
unsloth安装
git地址:https://github.com/unslothai/unsloth
安装参考:https://docs.unsloth.ai/get-started/installing-±updating
经过几种尝试后,我选用的是conda的方式安装:
安装conda参考:https://blog.csdn.net/qq_28513801/article/details/140866786
创建unsloth_env虚拟环境:
conda create --name unsloth_env \
python=3.11 \
pytorch-cuda=12.1 \
pytorch cudatoolkit xformers -c pytorch -c nvidia -c xformers \
-y
激活unsloth_env:
conda activate unsloth_env
安装unsloth:
pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
安装相关依赖:
pip install --no-deps trl peft accelerate bitsandbytes
Jupyter中使用虚拟环境
安装ipykernel
ipykernel是一个用于在 Jupyter 中运行 Python 内核的包。你需要在目标 Conda 环境中安装它。

先保证激活目标 Conda 环境,在终端中运行以下命令:
conda activate unsloth_env
使用conda安装ipykernel
conda install ipykernel
会自动下载安装很多依赖,最后选y:
将 Conda 环境添加到 Jupyter
安装<font style="color:rgba(0, 0, 0, 0.85);">ipykernel</font>后,你需要将当前 Conda 环境注册到 Jupyter 中,以便 Jupyter 可以识别并使用它。运行以下命令将环境添加到 Jupyter:
python -m ipykernel install --user --name=myenv
--user:表示将内核安装到用户目录,这样只有当前用户可以使用该内核。--name=myenv:指定内核的名称,你可以根据需要自定义名称,通常使用 Conda 环境的名称。

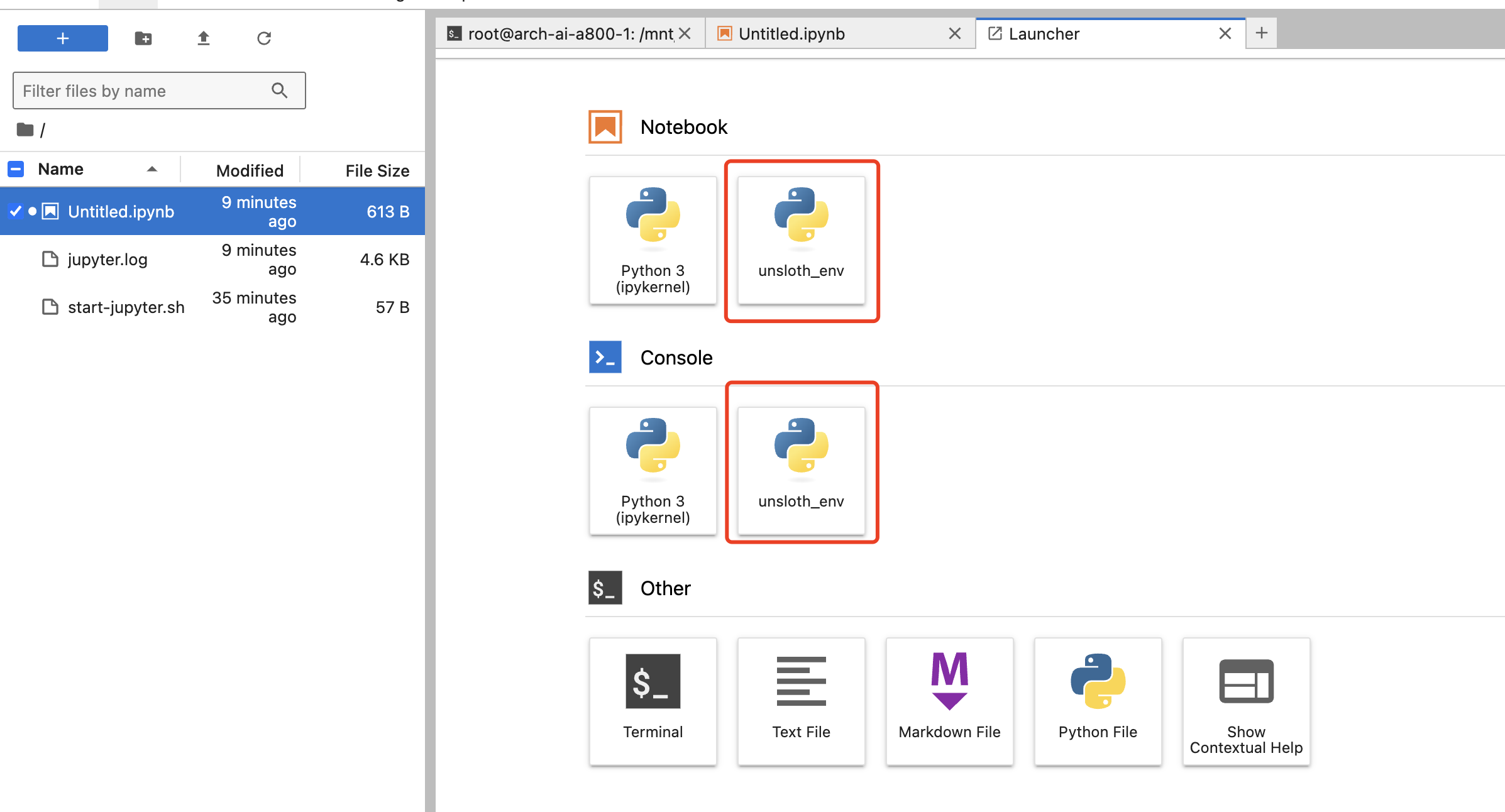
重启Jupyter
重启后,在Jupyter新建页面,可以看到对应的环境
检查一下是否可以使用该环境中的包:
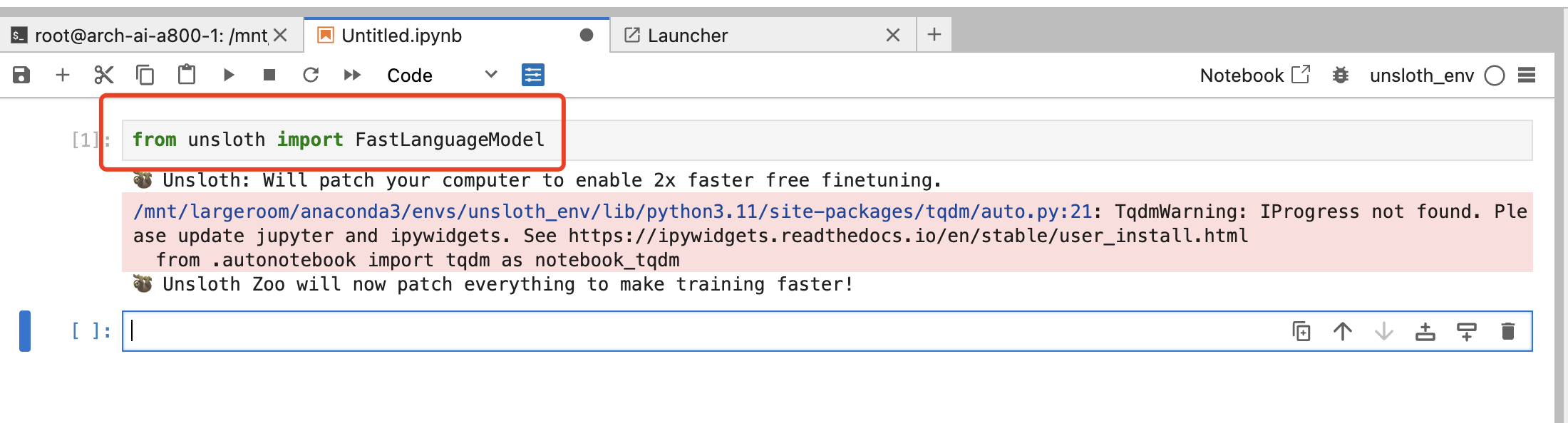
可以正常使用。
使用unsloth推理
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
load_in_4bit = False
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "/mnt/largeroom/llm/model/DeepSeek-R1-Distill-Qwen-1.5B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
FastLanguageModel.for_inference(model)
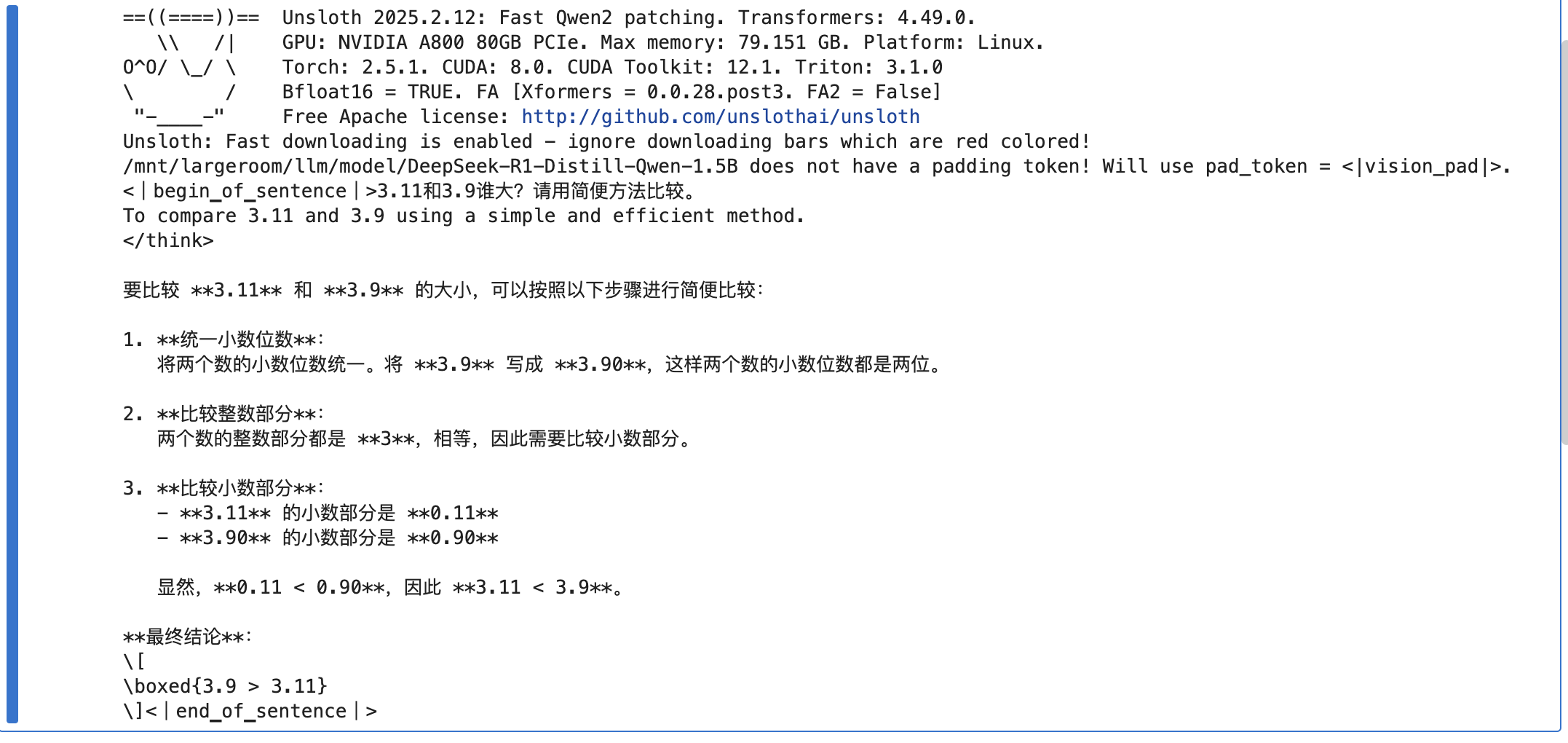
question = "3.11和3.9谁大?"
inputs = tokenizer([question], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
max_new_tokens=1024,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0])
模型训练
加载模型
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
load_in_4bit = False
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "/mnt/largeroom/llm/model/DeepSeek-R1-Distill-Qwen-1.5B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,# 可选值为:True/load_in_4bit、False
)
数据集准备
数据集模版
train_prompt_style = """下面是一条描述任务的指令,与提供进一步上下文的输入配对。写一个适当完成请求的响应。在回答之前,仔细思考问题,并创建一个循序渐进的思路链,以确保逻辑和准确的回答。
### Instruction:
您是一位医学专家,在临床推理、诊断和治疗计划方面拥有先进的知识。请回答以下医学问题。
### Question:
{}
### Response:
<think>
{}
</think>
{}"""
下载数据集
from modelscope.msdatasets import MsDataset
ds = MsDataset.load('FreedomIntelligence/medical-o1-reasoning-SFT', subset_name='zh', split='train[0:100]')
查看数据集
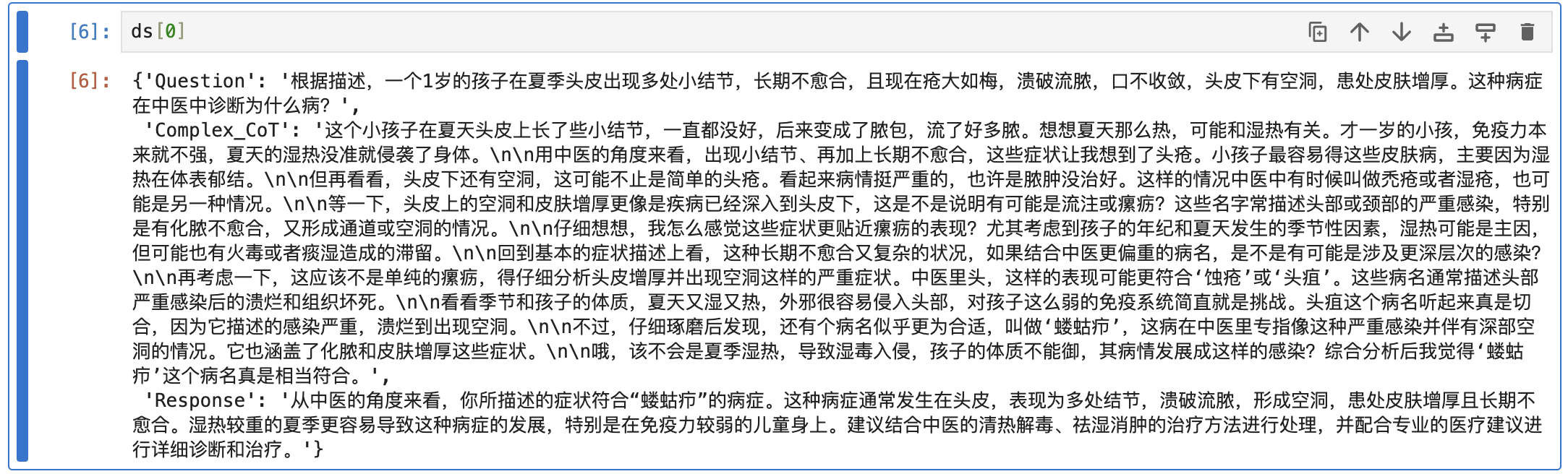
数据清洗
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}
ds = ds.map(formatting_prompts_func, batched = True,)
查看清洗后的数据集
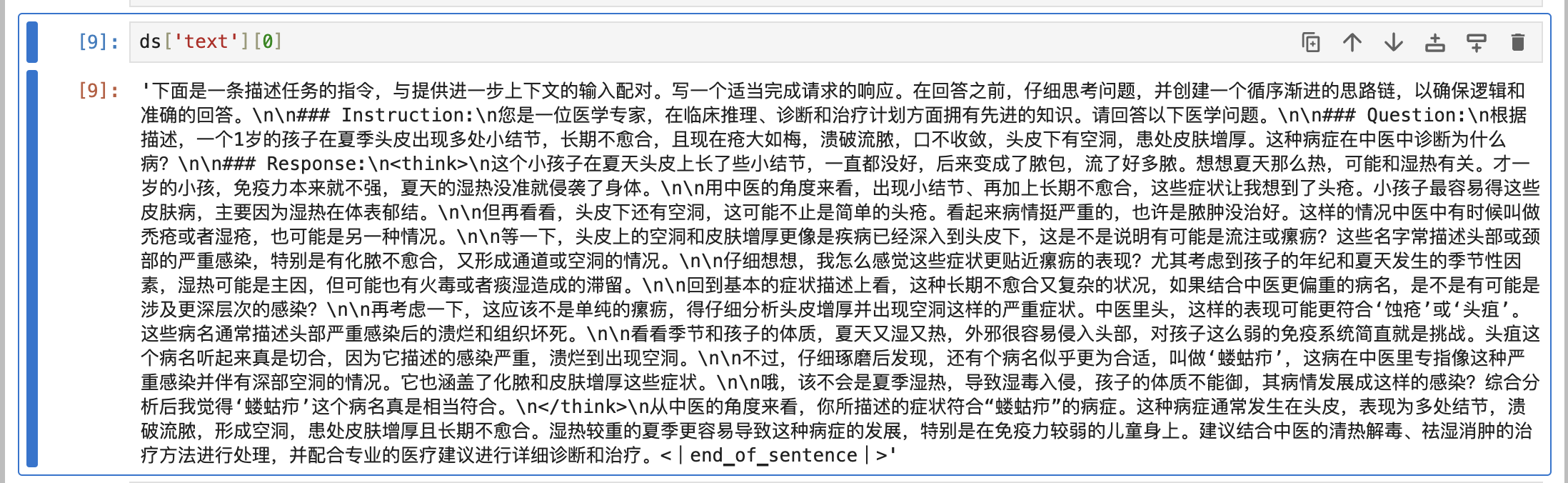
微调模型
登录Weight&Biases(可选)
import wandb
wandb.login(key="xxxxxx")
将模型转为高效微调模式
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407,
use_rslora=False,
loftq_config=None,
)
设置训练参数
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=ds,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=8,
## 训练参数配置
args=TrainingArguments(
# 批处理相关
per_device_train_batch_size=4, # 每个设备(GPU)的训练批次大小
gradient_accumulation_steps=8,# 梯度累积步数,用于模拟更大的批次大小
# 训练步数和预热
warmup_steps=5,# 学习率预热步数,逐步增加学习率
max_steps=60,# 最大训练步数
learning_rate=2e-4,
fp16=not is_bfloat16_supported(), # 如果不支持 bfloat16,则使用 float16
bf16=is_bfloat16_supported(),# 如果支持则使用 bfloat16,通常在新型 GPU 上性能更好
logging_steps=10,# 每10步记录一次日志
optim="adamw_8bit", # 使用8位精度的 AdamW 优化器
weight_decay=0.01,# 权重衰减率,用于防止过拟合
lr_scheduler_type="linear",# 学习率调度器类型,使用线性衰减
seed=3407,# 随机种子,确保实验可重复性
output_dir="outputs", # 模型和检查点的输出目录
),
)
开始训练
trainer_stats = trainer.train()
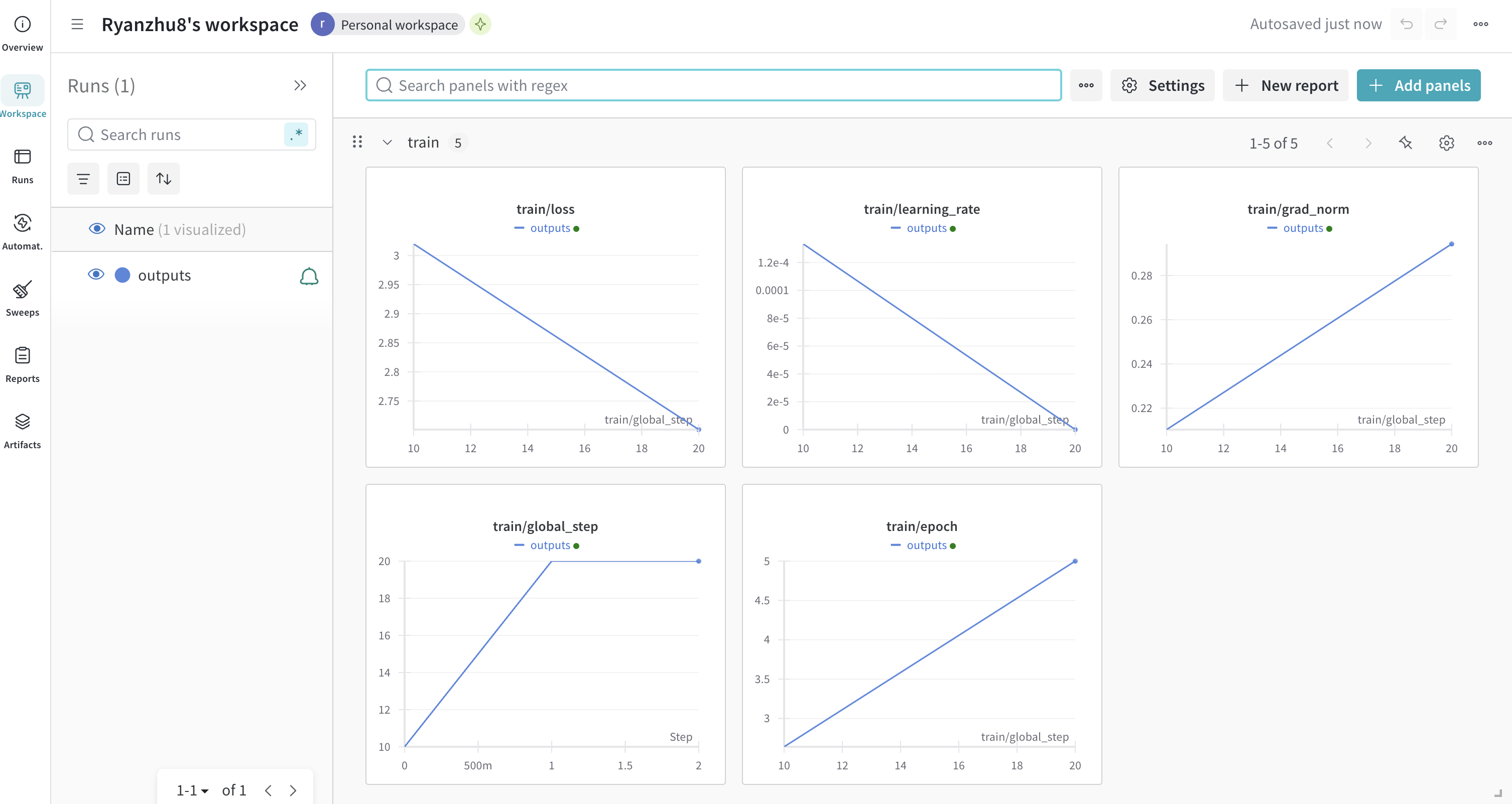
wandb中的各项指标
效果对比
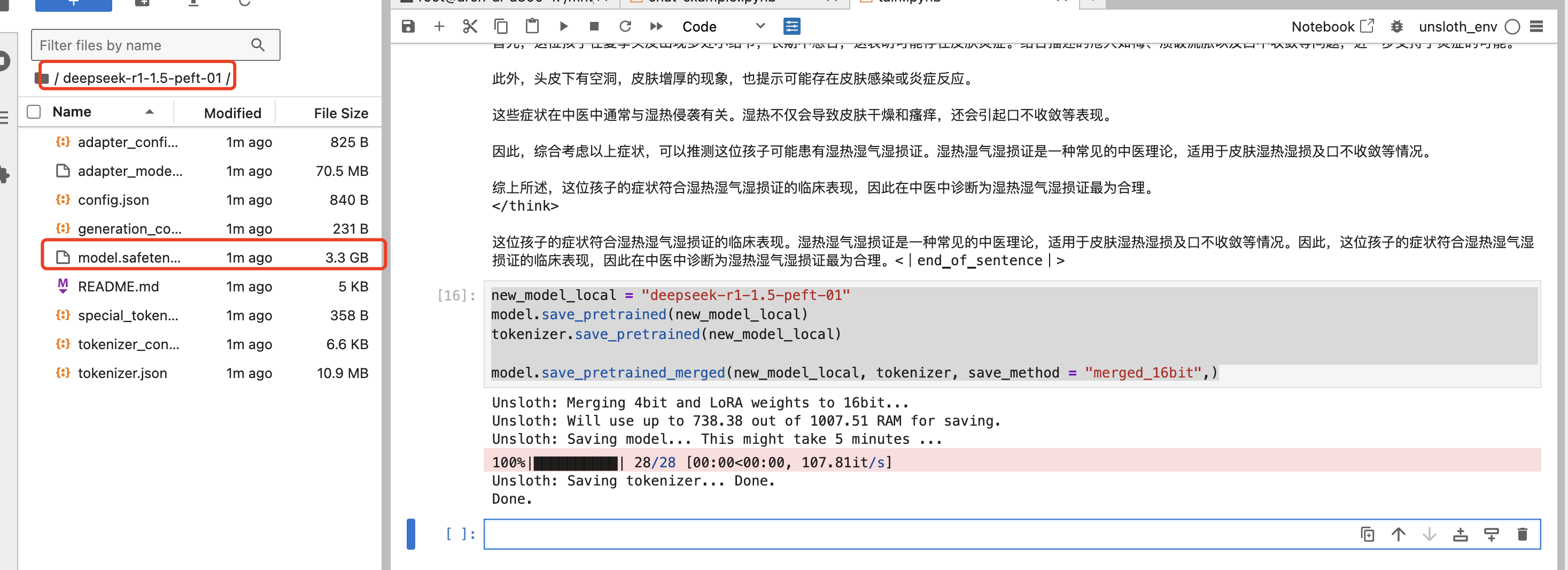
注意,unsloth在微调结束后,会自动更新模型权重(在缓存中),因此无需手动合并模型权重即可直接调用微调后的模型,重启Jupyter或者重启kernel就不行了,需要合并模型。
问题:根据描述,一个1岁的孩子在夏季头皮出现多处小结节,长期不愈合,且现在疮大如梅,溃破流脓,口不收敛,头皮下有空洞,患处皮肤增厚。这种病症在中医中诊断为什么病?
原模型回答:

训练后的模型回答:

可以看出来回答效果有改善,微调之后的模型,需要使用训练时指定的模板:
prompt_style = """下面是一条描述任务的指令,与提供进一步上下文的输入配对。写一个适当完成请求的响应。在回答之前,仔细思考问题,并创建一个循序渐进的思路链,以确保逻辑和准确的回答。
### Instruction:
您是一位医学专家,在临床推理、诊断和治疗计划方面拥有先进的知识。请回答以下医学问题。
### Question:
{}
### Response:
<think>
{}"""
FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style.format("根据描述,一个1岁的孩子在夏季头皮出现多处小结节,长期不愈合,且现在疮大如梅,溃破流脓,口不收敛,头皮下有空洞,患处皮肤增厚。这种病症在中医中诊断为什么病?", "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
模型合并
微调之后的权重在此:
执行下面的代码合并
new_model_local = "deepseek-r1-1.5-peft-01"
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
model.save_pretrained_merged(new_model_local, tokenizer, save_method = "merged_16bit",)