目录
2.1enumerate(iterable, start=0)
2.3format(value[, format_spec])
2.6map(function, iterable, ...)
2.10sorted(iterable, *, key=None, reverse=False)
语言基础
1.内置函数
1.1math库

1.1.1math.e:
返回欧拉数(Euler's number),大约等于 2.71828。
1.1.2math.inf:
返回正无穷大浮点数(Infinity)。
1.1.3math.nan:
返回一个浮点值 NaN(Not a Number),表示不是一个数字。
1.1.4math.pi:
π,一般指圆周率,大约等于 3.14159。
1.1.5math.tau:
数学常数 τ(tau),大约等于 6.283185,精确到可用精度。Tau 是一个圆周常数,等于 2π,即圆的周长与半径之比。
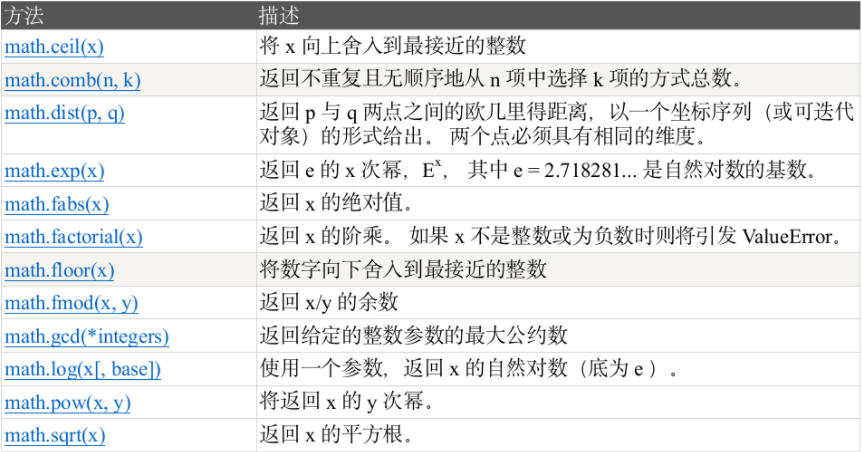
1.1.6math.ceil(x):
将 x 向上舍入到最接近的整数。
1.1.7math.comb(n, k):
返回不重复且无顺序地从 n 项中选择 k 项的方式总数,即组合数。
1.1.8math.dist(p, q):
返回 p 与 q 两点之间的欧几里得距离,以一个坐标序列(或可迭代对象)的形式给出。两个点必须具有相同的维度。
1.1.9math.exp(x):
返回 e 的 x 次幂,其中 e ≈ 2.71828... 是自然对数的基数。
1.1.10math.fabs(x):
返回 x 的绝对值。
1.1.11math.factorial(x):
返回 x 的阶乘。如果 x 不是整数或为负数时则将引发 ValueError。
1.1.12math.floor(x):
将数字向下舍入到最接近的整数。
1.1.13math.fmod(x, y):
返回 x/y 的余数。
1.1.14math.gcd(*integers):
返回给定的整数参数的最大公约数。
1.1.15math.log([x, base]):
使用一个参数,返回 x 的自然对数(底为 e)。如果提供第二个参数 base,则返回以 base 为底的对数。
1.1.16math.pow(x, y):
将返回 x 的 y 次幂。
1.1.17math.sqrt(x):
返回 x 的平方根。

1.1.18math.cos(x):
返回 x 弧度的余弦值。
1.1.19math.sin(x):
返回 x 弧度的正弦值。
1.1.20math.tan(x):
返回 x 弧度的正切值。
1.1.21math.acos(x):
返回 x 的反余弦值,结果范围在 0 到 π 之间。
1.1.22math.asin(x):
返回 x 的反正弦值,结果范围在 -π/2 到 π/2 之间。
1.1.23math.atan(x):
返回 x 的反正切值,结果范围在 -π/2 到 π/2 之间。
1.1.24math.cosh(x):
返回 x 的双曲余弦值。
1.1.25math.degrees(x):
将角度 x 从弧度转换为度数。
1.1.26math.radians(x):
将角度 x 从度数转换为弧度。
1.1.27math.sinh(x):
返回 x 的双曲正弦值。
1.1.28math.cosh(x):
再次列出,应该是重复,返回 x 的双曲余弦值。
1.1.29math.tanh(x):
返回 x 的双曲正切值。
1.2collections
1.2.1Counter:计数器
调用
from collections import Counter
most_common(k):筛选并返回出现频率最高的 k 个元素及其计数。
from collections import Counter
c = Counter(['apple', 'orange', 'apple', 'pear', 'orange', 'banana'])
print(c.most_common(2)) # 输出出现频率最高的两个元素
elements():返回一个迭代器,迭代器中的每个元素会根据其在数据结构中出现的次数重复对应次数。
for element in c.elements():
print(element)
clear():清空数据结构中的所有元素。
c.clear()
字典功能:Counter 对象继承自字典,因此可以使用字典的大部分方法,如 keys(), values(), items(), get() 等。
print(c.keys()) # 输出所有元素
print(c.values()) # 输出所有计数
print(c.items()) # 输出元素及其计数的元组列表
数学运算:Counter 对象支持加法、减法、交集、并集等数学运算。
c1 = Counter(['apple', 'orange'])
c2 = Counter(['orange', 'banana'])
print(c1 + c2) # 并集
print(c1 - c2) # 差集
1.2.2deque双端对列

调用
from collections import deque
append(x):添加元素 x 到双端队列的右端。
# 创建一个空的双端队列
d = deque()
# 添加元素到右端
d.append(1)
d.append(2)
d.append(3)
print(list(d)) # 输出: [1, 2, 3]
appendleft(x):添加元素 x 到双端队列的左端。
# 添加元素到左端
d.appendleft(0)
d.appendleft(-1)
d.appendleft(-2)
print(list(d)) # 输出: [-2, -1, 0, 1, 2, 3]
pop():移除并返回双端队列最右侧的一个元素。
# 移除并返回最右侧的元素
print(d.pop()) # 输出: 3
print(list(d)) # 输出: [-2, -1, 0, 1, 2]
popleft():移除并返回双端队列最左侧的一个元素。
# 移除并返回最左侧的元素
print(d.popleft()) # 输出: -2
print(list(d)) # 输出: [-1, 0, 1, 2]
insert(i, x):在位置 i 插入元素 x。
# 在位置 i 插入元素 x
d.insert(2, 1.5)
print(list(d)) # 输出: [-1, 0, 1.5, 1, 2]
extend(iterable):扩展双端队列的右侧,通过添加 iterable 参数中的元素。
# 扩展双端队列的右侧
d.extend([4, 5, 6])
print(list(d)) # 输出: [-1, 0, 1.5, 1, 2, 4, 5, 6]
extendleft(iterable):扩展双端队列的左侧,通过添加 iterable 参数中的元素。注意,左添加时,在结果中 iterable 参数中的顺序将被反过来添加。
# 扩展双端队列的左侧,注意添加的顺序会被反转
d.extendleft([7, 8, 9])
print(list(d)) # 输出: [9, 8, 7, -1, 0, 1.5, 1, 2, 4, 5, 6]
remove(value):移除找到的第一个值为 value 的元素。
# 移除找到的第一个值为 value 的元素
d.remove(1.5)
print(list(d)) # 输出: [9, 8, 7, -1, 0, 1, 2, 4, 5, 6]
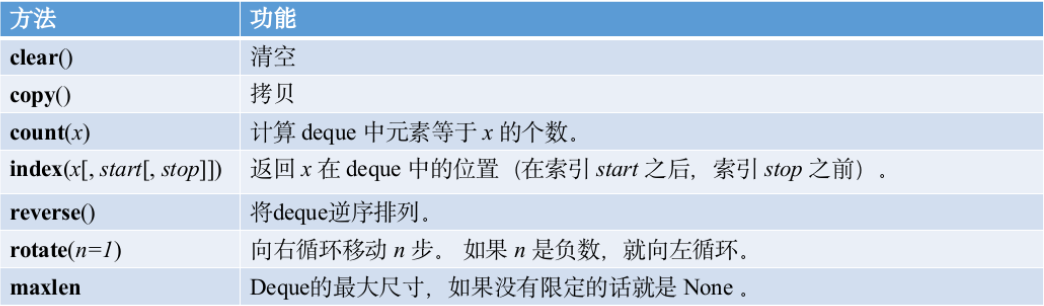
调用
from collections import deque
clear():清空双端队列中的所有元素。
# 创建一个双端队列
d = deque([1, 2, 3, 4, 5])
# 清空双端队列中的所有元素
d.clear()
print(list(d)) # 输出: []
copy():返回双端队列的一个拷贝。拷贝的内容赋值给一个新的对象存储在内存中。
# 创建一个双端队列并返回其拷贝
d = deque([1, 2, 3, 4, 5])
d_copy = d.copy()
print(list(d))
print(list(d_copy)) # 输出与原始双端队列相同
count(x):计算双端队列中元素等于 x 的个数。
# 计算双端队列中元素等于 x 的个数
d = deque([1, 2, 2, 3, 2, 4])
count_of_2 = d.count(2)
print(count_of_2) # 输出: 3
index(x[, start[, stop]]):返回 x 在双端队列中的位置(在索引 start 之后,索引 stop 之前)。如果元素不存在,则抛出 ValueError。
# 返回 x 在双端队列中的位置
index_of_3 = d.index(3)
print(index_of_3) # 输出: 2
index_of_null = d.index(7)
print(index_of_null) # 输出: ...ValueError:...
reverse():将双端队列中的元素逆序排列。
# 将双端队列中的元素逆序排列
d.reverse()
print(list(d)) # 输出: [4, 2, 3, 2, 2, 1]
rotate(n):向右循环移动 n 步。如果 n 是负数,就向左循环。例如,d.rotate(1) 会将 d 的最后一个元素移动到第一个位置,其他元素相应地向右移动。
# 向右循环移动 n 步
d.rotate(1)
print(list(d)) # 输出: [2, 4, 2, 3, 2, 1]
# 向左循环移动 n 步
d.rotate(-1)
print(list(d)) # 输出: [1, 2, 4, 2, 3, 2]
maxlen:双端队列的最大尺寸,如果没有限定的话就是 None,表示双端队列可以无限增长。
# 设置双端队列的最大尺寸
d = deque(maxlen=3)
d.extend([1, 2, 3])
print(list(d)) # 输出: [1, 2, 3]
d.append(4)
print(list(d)) # 输出: [2, 3, 4],因为限制了队列长度,1被移除了(最左边的先出队列,符合队列的基本性质)
1.2.3defaultdict有默认值的字典
普通的字典(dict对象),查询的key不存在时,会报错。
在字典中获取一个键(key)有两种方法:
使用 get 方法
使用 [] 操作符
使用普通的字典(dict)时,如果引用的键不存在,就会抛出 KeyError。
from collections import defaultdict
# 创建一个默认值为整数0的defaultdict
d = defaultdict(int)
# x元素是不存在d中的
print(d['x']) # 输出: 0,因为int()默认值为0
# 创建一个默认值为空列表的defaultdict
d = defaultdict(list)
print(d['x']) # 输出: [], 因为list()默认值为空列表
# 创建一个默认值为空集的defaultdict
d = defaultdict(set)
print(d['x']) # 输出: set(), 因为set()默认值为空集
# 创建一个默认值为空字典的defaultdict
d = defaultdict(dict)
print(d['x']) # 输出: {}, 因为dict()默认值为空字典
如果希望在键不存在时返回一个默认值,可以使用 defaultdict。
1.3heapq堆(完全二叉树)
堆(Heap)是一种特殊的完全二叉树数据结构,满足以下特性:
1.完全二叉树:堆是一棵完全二叉树,即除最后一层外,其他层的节点都被元素填满,且最后一层的节点尽可能地从左到右排列。
2.堆序性质:在最大堆中,每个节点的值都大于或等于其子节点的值;在最小堆中,每个节点的值都小于或等于其子节点的值。
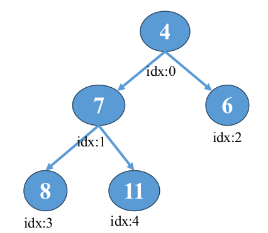
堆通常通过数组来实现,因为完全二叉树可以高效地映射到数组中。
在数组表示中,假设根节点存储在数组的第一个位置(索引为0),对于任意一个节点,其父节点和子节点的位置可以通过以下公式计算:
父节点索引:parent(i) = (i - 1) // 2
左子节点索引:left(i) = 2 * i + 1
右子节点索引:right(i) = 2 * i + 2
堆的常见操作包括:
1.插入元素:将新元素添加到堆中,并通过上浮操作(sift up)维护堆的性质。
2.删除堆顶元素:移除堆顶元素(最大堆的最大值或最小堆的最小值),并通过下沉操作(sift down)重新平衡堆。
3.构建堆:将无序数组转换为堆结构,常用的方法是从最后一个非叶子节点开始,依次对每个节点进行下沉操作。
eg:
使用list表示一个堆
1.将无序List转换成最小堆:
heapq.heapify(a)
2.最小堆a中添加元素x:
heapq.heappush(a, x)
3.弹出并返回最小元素:
heapq.heappop(a)
4.弹出并返回最小元素,同时添加元素x:
heapq.heapreplace(a, x)
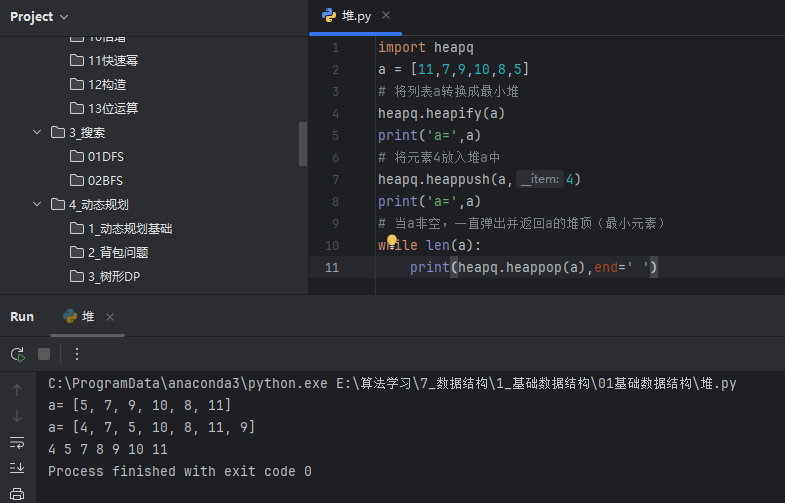
import heapq
a = [11,7,9,10,8,5]
# 将列表a转换成最小堆
heapq.heapify(a)
print('a=',a)
# 将元素4放入堆a中
heapq.heappush(a,4)
print('a=',a)
# 当a非空,一直弹出并返回a的堆顶(最小元素)
while len(a):
print(heapq.heappop(a),end=' ')
1.4functool
functools 模块用于高阶函数,即参数或返回值为其他函数的函数。
partial 函数用于“冻结”某些函数的参数或关键字参数,然后返回一个新函数。
partial 函数的使用:
functools.partial(func, *args, **keywords),其中:func 是需要被扩展的函数。
*args 是需要被固定的位置参数。
**keywords 是需要被固定的关键字参数。
from functools import partial
# 定义一个函数,接受任意数量的位置参数和关键字参数
def add(*args, **kwargs):
# 打印位置参数
for n in args:
print(n)
# 打印关键字参数
for k, v in kwargs.items():
print('s:s' % (k, v))
# 普通调用
add(1, 2, 3, v1=10, v2=20)
"""
1
2
3
v1:10
v2:20
"""
# 使用 partial 创建偏函数
add_partial = partial(add, 10, k1=10, k2=20)
add_partial(1, 2, 3, k3=20)
"""
1
2
3
10
k1:10
k2:20
k3:20
"""
偏函数在函数式编程中的主要用途:
固定参数:创建预设参数的新函数,便于重复调用。
提高可读性:减少重复参数设置,使代码更清晰。
函数重用:通过定制通用函数行为,避免定义多个相似函数。
延迟计算:在调用时才计算结果,适用于昂贵或条件触发的计算。
柯里化:将多参数函数转换为单参数函数,增强灵活性。
装饰器:为函数添加额外行为,如日志记录或性能监控。
高阶函数:简化高阶函数的使用,使其更易于理解和应用。
参数默认值:在默认值可能变化时,模拟默认参数行为。
1.5itertools
1.5.1无限迭代器
生成长度为无限的迭代器:
调用
import itertools
count(start=0, step=1):
count 函数创建一个迭代器,从 start 值开始,每次增加 step 值。默认 start 是 0,step 是 1。
这个迭代器会无限地生成连续的整数。
# 使用 count 函数
counter = itertools.count(10, 5) # 从 10 开始,每次增加 5
for i in itertools.islice(counter, 5): # 使用 islice 来限制迭代次数,避免无限循环
print(i)
cycle(iterable):
cycle 函数创建一个迭代器,它会循环遍历 iterable 中的所有元素。当元素遍历完成后,迭代器会从头开始再次遍历,形成一个无限循环。
# 使用 cycle 函数
cyclic = itertools.cycle([1, 2, 3])
for i in itertools.islice(cyclic, 10): # 同样使用 islice 来限制迭代次数
print(i)
repeat(object[, times]):
repeat 函数创建一个迭代器,如果没有指定 times 参数,它会无限循环遍历 object。
如果指定了 times 参数,迭代器会遍历 object 指定的次数。
# 使用 repeat 函数
repeated = itertools.repeat('hello', 5) # 重复 'hello' 5 次
for i in repeated:
print(i)
1.5.2有限迭代器
from itertools import accumulate
accumulate(iterable[, func]):
accumulate 函数创建一个迭代器,返回基于 iterable 中的元素的累积汇总值。
如果没有提供 func 参数,默认执行加法操作,即返回元素的累积和。
如果提供了 func 参数,将使用这个双目(两个参数的)函数来计算累积结果。
示例:
accumulate([1,2,3,4,5]) 将返回 [1, 3, 6, 10, 15],这是元素的累积和。
accumulate([1,2,3,4,5], max) 将返回 [1, 2, 3, 4, 5],因为 max 函数在累积过程中总是返回当前最大值。
accumulate([1,2,3,4,5], operator.mul) 将返回 [1, 2, 6, 24, 120],因为 operator.mul 函数执行乘法操作。
import operator
# 使用 accumulate 函数
print(list(itertools.accumulate([1, 2, 3, 4, 5]))) # 输出: [1, 3, 6, 10, 15]
print(list(itertools.accumulate([1, 2, 3, 4, 5], max))) # 输出: [1, 2, 3, 4, 5]
print(list(itertools.accumulate([1, 2, 3, 4, 5], operator.mul))) # 输出: [1, 2, 6, 24, 120]
chain(*iterables):
chain 函数用于合并多个迭代器。将所有提供的迭代器中的元素串联起来,形成一个单一的迭代器。
示例:
chain('ABC', 'DEF') 将返回一个迭代器,该迭代器生成 'ABCDEF',即两个字符串的串联。
# 使用 chain 函数
print(''.join(itertools.chain('ABC', 'DEF'))) # 输出: ABCDEF
accumulate 函数返回的是一个迭代器,如果要返回一个列表,可以使用 list() 函数来转换。同样,chain 函数也返回一个迭代器,如果要返回一个字符串,可以使用 ''.join() 来转换
1.5.3排列组合迭代器
product(*iterables, repeat=1):
product 函数用于计算可迭代对象的笛卡儿积
*iterables 表示多个可迭代对象,它们的笛卡儿积将被计算
repeat 参数表示这些可迭代序列重复的次数
import itertools
# product 示例:计算笛卡儿积
print(list(itertools.product([1, 2, 3], [4, 5, 6])))
# 输出: [(1, 4), (1, 5), (1, 6), (2, 4), (2, 5), (2, 6), (3, 4), (3, 5), (3, 6)]
# product 示例:重复同一个可迭代对象
print(list(itertools.product('ab', repeat=2)))
# 输出: [('a', 'a'), ('a', 'b'), ('b', 'a'), ('b', 'b')]
permutations(iterable, r=None):
permutations 函数用于生成可迭代对象中元素的所有可能排列
如果 r 未指定或为 None,则默认为 iterable 的长度,即生成所有元素的排列
如果指定了 r,则生成长度为 r 的排列
# permutations 示例:生成所有排列
print(list(itertools.permutations('ABCD', 2)))
# 输出: [('A', 'B'), ('A', 'C'), ('A', 'D'), ('B', 'A'), ('B', 'C'), ('B', 'D'), ('C', 'A'), ('C', 'B'), ('C', 'D'), ('D', 'A'), ('D', 'B'), ('D', 'C')]
# permutations 示例:生成所有元素的排列(r=None 或者不指定)
print(list(itertools.permutations([1, 2, 3, 4])))
# 输出: [(1, 2, 3, 4), (1, 2, 4, 3), (1, 3, 2, 4), ...]
combinations(iterable, r):
combinations 函数用于生成可迭代对象中元素的所有可能组合
r 参数指定了组合的长度
# combinations 示例:生成所有组合
print(list(itertools.combinations('ABCD', 2)))
# 输出: [('A', 'B'), ('A', 'C'), ('A', 'D'), ('B', 'C'), ('B', 'D'), ('C', 'D')]
# combinations 示例:生成长度为3的组合
print(list(itertools.combinations([1, 2, 3, 4, 5], 3)))
# 输出: [(1, 2, 3), (1, 2, 4), (1, 2, 5), (1, 3, 4), (1, 3, 5), (1, 4, 5), (2, 3, 4), (2, 3, 5), (2, 4, 5), (3, 4, 5)]
2.序列变量相关

2.1enumerate(iterable, start=0)
返回一个枚举对象,其中包含计数(从 start 开始,默认为 0)和通过迭代 iterable 获得的值。
# enumerate 示例
for index, value in enumerate(['a', 'b', 'c'], start=1):
print(f"{index}: {value}")
2.2filter(function, iterable)
从 iterable 中筛选出使 function 返回 True 的元素,构成一个新的迭代器。
# filter 示例
numbers = [1, 2, 3, 4, 5]
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print(even_numbers)
2.3format(value[, format_spec])
将 value 转换为 format_spec 指定格式的字符串表示。
# format 示例
print(format(3.14159, '.2f')) # 格式化为两位小数
2.4len(s)
返回对象 s 的长度,即元素个数。
# len 示例
my_list = [1, 2, 3, 4, 5]
print(len(my_list))
2.5list([iterable])
将 iterable 转换为列表,或者如果未提供参数,则创建一个空列表。
# list 示例
my_iterable = (x for x in range(5))
my_list = list(my_iterable)
print(my_list)
2.6map(function, iterable, ...)
对 iterable 中的每一项应用 function 函数,并返回结果的迭代器。
# map 示例
numbers = [1, 2, 3, 4, 5]
squared_numbers = list(map(lambda x: x**2, numbers))
print(squared_numbers)
2.7reversed(seq)
返回一个反向迭代器,用于遍历 seq。
# reversed 示例
my_list = [1, 2, 3, 4, 5]
reversed_list = list(reversed(my_list))
print(reversed_list)

2.8slice(stop)
返回一个 slice 对象,用于获取序列的切片。
# slice 示例
my_list = [1, 2, 3, 4, 5]
sliced_list = my_list[1:4:2] # 从索引1开始到索引4,步长为2
print(sliced_list)
2.9slice(start, stop, step)
返回一个 slice 对象,用于获取序列的切片,可以指定起始索引、结束索引和步长。
my_list = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 使用 slice 获取切片
# slice(start, stop, step)
# 从索引 2 开始到索引 7 结束,步长为 2
sliced_list = my_list[slice(2, 7, 2)]
print(sliced_list) # 输出: [2, 4, 6]
2.10sorted(iterable, *, key=None, reverse=False)
将 iterable 中的元素排序并返回一个新的列表。
# sorted 示例
my_list = [3, 1, 4, 1, 5, 9, 2]
sorted_list = sorted(my_list, key=lambda x: -x) # 降序排序
print(sorted_list)
2.11tuple([iterable])
将 iterable 转换为元组,或者如果未提供参数,则创建一个空元组。
# tuple 示例
my_iterable = [1, 2, 3]
my_tuple = tuple(my_iterable)
print(my_tuple)
2.12zip(*iterables)
创建一个聚合了来自每个 iterable 对象中元素的迭代器,元素是元组形式。
# zip 示例
list1 = [1, 2, 3]
list2 = ['a', 'b', 'c']
zipped = list(zip(list1, list2))
print(zipped)
3.进制转换

3.1bin(x)
将一个整数 x 转换为一个前缀为 '0b' 的二进制字符串。
# bin 示例:转换为二进制字符串
number = 10
bin_str = bin(number)
print(number) # 输出: 0b1010
3.2hex(x)
将一个整数 x 转换为一个前缀为 '0x' 的小写十六进制字符串。
# hex 示例:转换为十六进制字符串
number = 255
hex_str = hex(number)
print(number) # 输出: 0xff
3.3oct(x)
将一个整数 x 转换为一个前缀为 '0o' 的八进制字符串。
# oct 示例:转换为八进制字符串
number = 63
oct_str = oct(number)
print(number) # 输出: 0o77
4.常用函数
4.1数学操作函数

4.2序列和集合操作

4.3类型转换和判断

4.4其他常用
