架构
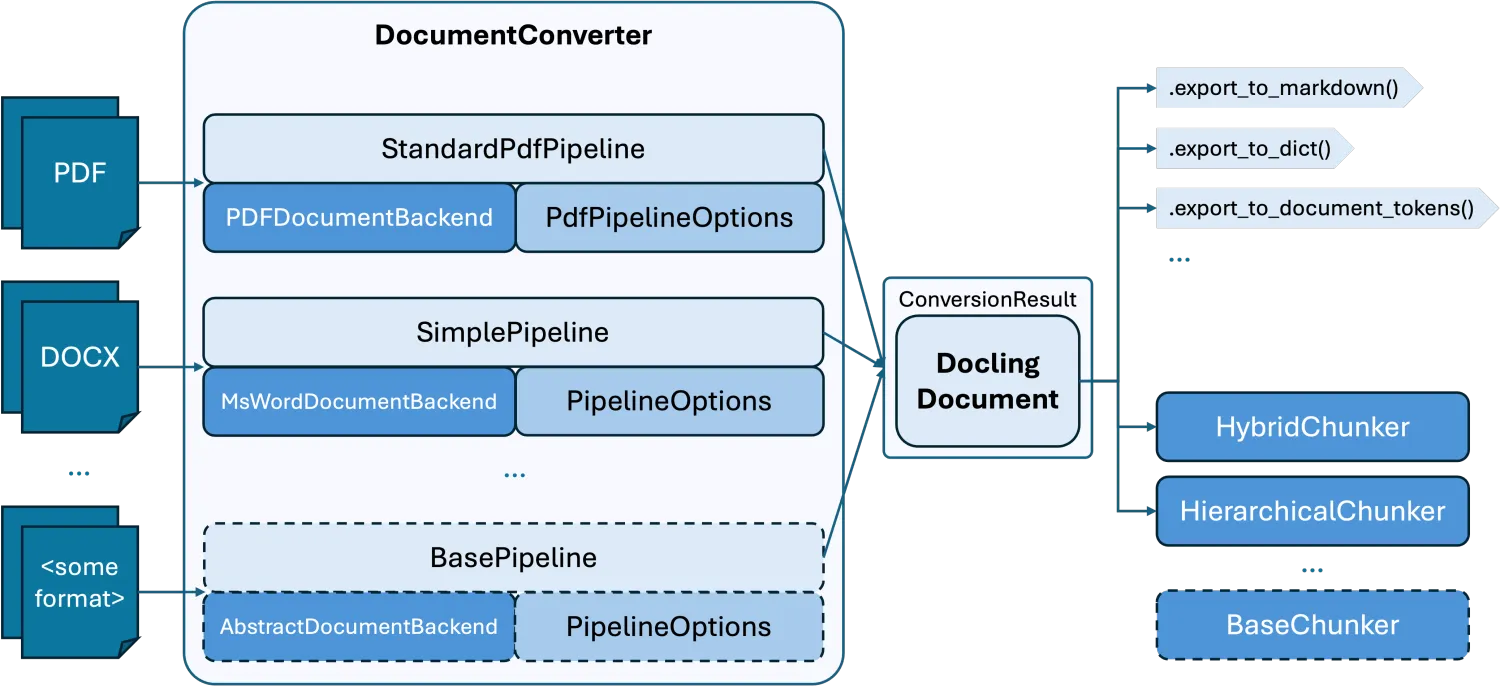
对于每种文档格式,Docling会自动识别应该调用哪一种Pipeline进行解析处理,并且解析后可以导出不同的数据格式,如Markdown、字典等,甚至还能进一步进行分块处理。
特性
● 支持解析多种文档格式,包括 PDF、DOCX、XLSX、HTML、图片等。
● PDF理解功能,涵盖页面布局、阅读顺序、表格结构、代码、公式等。
● 提出DoclingDocument结构用于统一表示不同的文档格式。
● 支持多种导出格式,包括 Markdown、HTML和JSON。
● 支持私有化部署,以保证数据安全性。
● 具有广泛的OCR支持功能,可以根据实际需要按需配置,适用于扫描的 PDF 和图片。
安装步骤
安装
通过pip安装docling
pip install docling
通过docling提供的命令行工具离线下载模型
docling-tools models download
处理
from docling.document_converter import DocumentConverter
# 参数可以是本地PDF路径或者URL链接
source = "https://arxiv.org/pdf/2408.09869"
converter = DocumentConverter()
result = converter.convert(source)
print(result.document.export_to_markdown())
如果是首次使用或者没有离线下载过模型,会自动进行下载
命令行使用
# 参数可以是本地PDF路径或者URL链接
docling https://arxiv.org/pdf/2206.01062
切分
from docling.document_converter import DocumentConverter
from docling.chunking import HybridChunker
conv_res = DocumentConverter().convert("https://arxiv.org/pdf/2206.01062")
doc = conv_res.document
chunker = HybridChunker(tokenizer="BAAI/bge-small-en-v1.5") # set tokenizer as needed
chunk_iter = chunker.chunk(doc)
切分后的块是一个json数据,不仅含有原始的文本,还保留其他的元信息,如位置和标签等。
print(list(chunk_iter)[11])
# {
# "text": "In this paper, we present the DocLayNet dataset. [...]",
# "meta": {
# "doc_items": [{
# "self_ref": "#/texts/28",
# "label": "text",
# "prov": [{
# "page_no": 2,
# "bbox": {"l": 53.29, "t": 287.14, "r": 295.56, "b": 212.37, ...},
# }], ...,
# }, ...],
# "headings": ["1 INTRODUCTION"],
# }
文档表征格式
Docling提出了一种统一的文档表示格式,称为 DoclingDocument,在docling_core.types.doc中进行了定义。它是一个 Pydantic 数据类型,分为两大类:内容项和内容结构。可以表达文档的多种常见特征,如文本、表格、图片等。
内容项包括:
● 文本(texts):包含所有具有文本表示的项,如段落、标题、方程等。
● 表格(tables):包含所有表格。
● 图片(pictures):包含所有图片。
● 键值项(key_value_items):包含所有的键值对。
内容结构包括:
● 主体(body):文档主体的根节点,以树结构组织。
● 内容(furniture):非主体内容的根节点,如页眉、页脚。
● 分组(groups):作为其他内容项的容器,如列表、章节。
# 查看转换后的文本
doc.texts
# 查看转换后的表格
doc.tables
# 查看转换后的图片
doc.pictures
# 查看主体
doc.body
# 查看分组
doc.groups
其他功能
Docling允许通过额外的步骤丰富文档转换流程,例如处理代码块、图片等特定文档组件,包括:
● 代码理解
● 公式理解
● 图片分类
● 图片描述
代码理解
对文档中找到的代码块使用高级解析
# ...其余代码一致...
pipeline_options = PdfPipelineOptions()
pipeline_options.do_code_enrichment = True
# ...其余代码一致...
公式理解
将分析文档中的方程公式并提取它们的LaTeX表示
# ...其余代码一致...
pipeline_options = PdfPipelineOptions()
pipeline_options.do_formula_enrichment = True
# ...其余代码一致...
图片分类
使用DocumentFigureClassifier模型对文档中的PictureItem元素进行分类,该模型专门用于理解文档中图片的类别,例如不同的图表类型、流程图、Logo、签名等。
# ...其余代码一致...
pipeline_options = PdfPipelineOptions()
pipeline_options.generate_picture_images = True
pipeline_options.images_scale = 2
pipeline_options.do_picture_classification = True
# ...其余代码一致...
图片描述
使用视觉语言模型为图片添加注释
# ...其余代码一致...
pipeline_options = PdfPipelineOptions()
pipeline_options.do_picture_description = True
# ...其余代码一致...
使用体验
- 安装过程简单,基本没遇到环境配置的问题
- 提供了一个统一的Pipeline,支持对多种文档进行处理
- 解析结构中具备元信息,无需额外进行处理
- 支持解析之后的块切分,与Langchain等框架可以结合使用
- 内置OCR性能有限,中文开源OCR模型需要自行支持