一、大模型生成过程
首先,我们看看大模型生成过程中每一步是怎么进行的。由于现有大模型基本都是Decoder-only架构,可以按照以下流程进行理解:

<Begin>是一个起始符,用于标记句子的开头。当模型的输入只有<Begin>的时候,模型输出概率最大的词I,表示在模型看来,以I作为句子的实际开头是合理的;当模型的输入变成<Begin>和I的时候,模型预测出下一个词大概率是have。依此类推,整个生成过程就是把模型预测出的词拼接到输入的句子中去,组成新的输入句子后,再让模型预测这个新输入句子的下一个词汇是什么。
到这里,我们会发现一个问题,随着输入句子的长度越来越长,Decoder模块需要计算的内容越来越多,预测新的词的速度应该是越来越慢才对,为什么我们实际体验中的大模型输出都很流畅,甚至有的平均输出达到几百token/s?
二、Decoder模块
回顾一下Decoder模块的结构:

紫色部分的归一化和黄色部分的前向传播属于标准的神经网络层都有的结构,这里不做讨论。Transformers架构中最复杂也最容易搞混的是其中的注意力部分,即图中的红色区域。原始Decoder模块共由12层注意力层进行堆叠,前一层的输出作为下一层的输入,因此,我们可以简化成只有一层注意力层进行分析。
每次输入一个新词,都会由橙色区域把该词变成一个固定维度的向量化表示,这个向量化表示包含了语义信息和位置信息,比如把I变成如下向量化表示:
"I" → [0.2, -0.5, 1.3, ..., 0.7]
接下来,该向量会与3个矩阵(WQ、WK、WV)分别相乘,得到新的3个向量,分别叫做q、k、v。这3个矩阵是在训练过程中不断调整的参数,是学习目标之一。至于为什么是这3个矩阵,这里先不管,只要记得这个计算过程就行了。注意力计算公式如下:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax( \frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
还有,根据前面描述,Decoder-only架构的大模型生成过程就是不断把模型预测出的词拼接到输入的句子中去,组成新的输入句子后,再让模型预测这个新输入句子的下一个词汇是什么。因此,Decoder-only定义了一种称为掩码注意力的机制,即每个词只能看到当前词与所有的历史词,计算注意力的时候也只能利用这些信息计算,不能用未来词计算注意力。
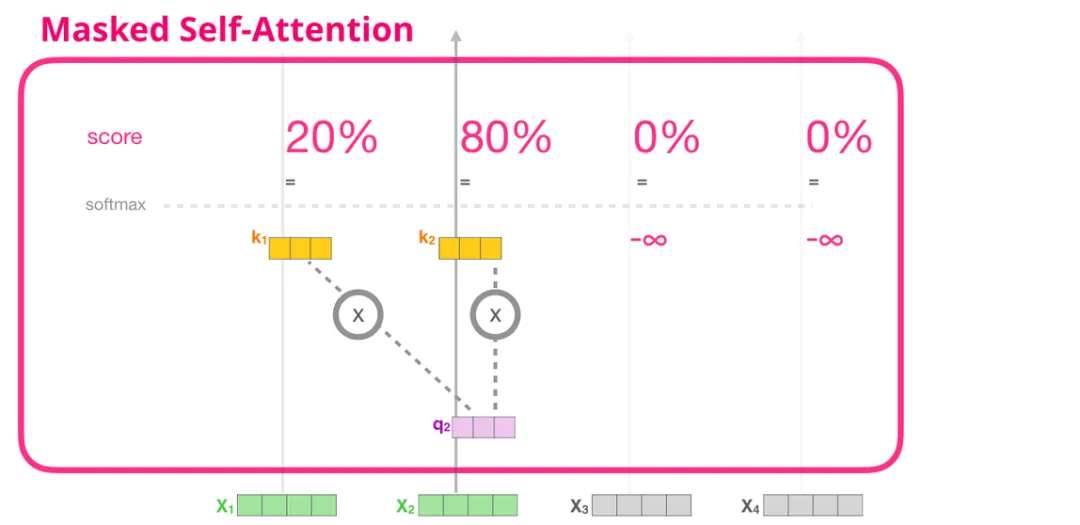
三、注意力计算过程
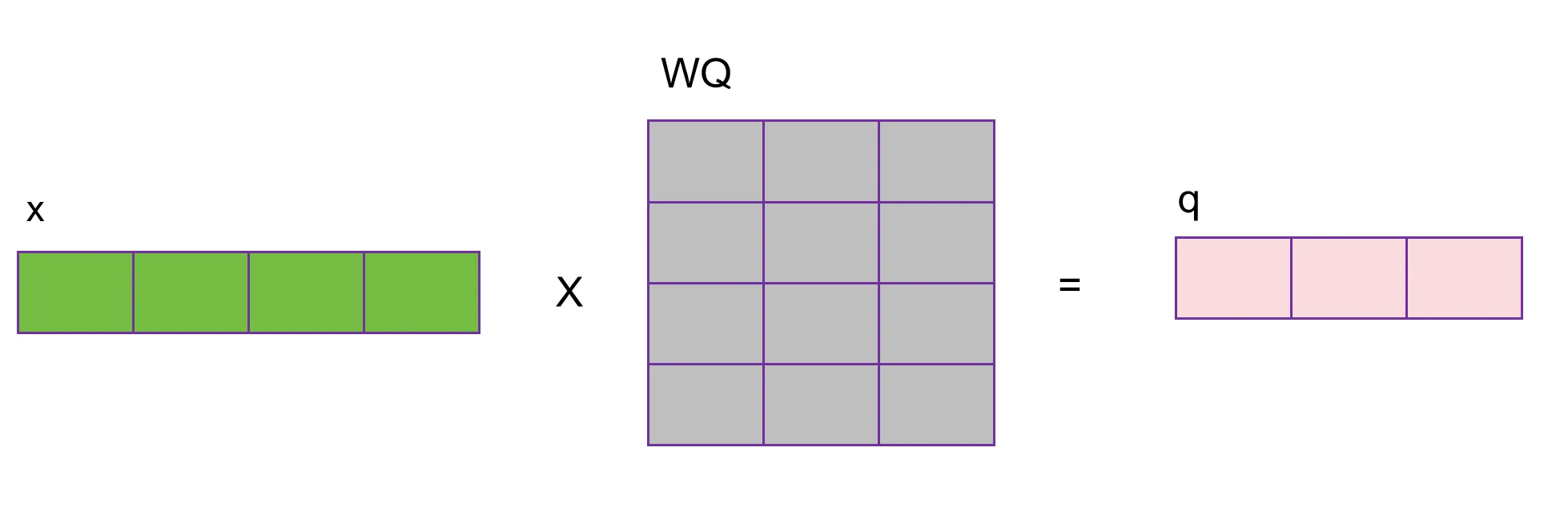
对于某个单词的向量,与WQ相乘后,得到向量表示q:
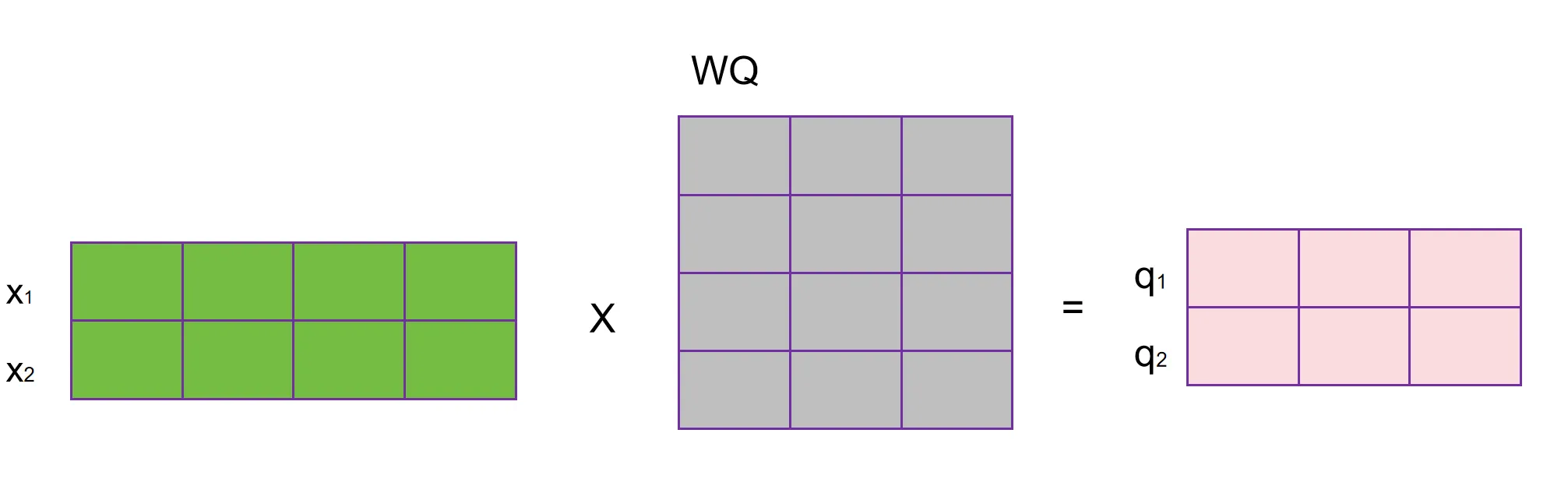
对于有多个输入的,比如现在句子的输入长度是2个词,则可以用矩阵来表示:
同样的,与WQ相乘类似,我们可以把x和WK和WV分别相乘,同样可以得到k和v向量,这里省略这部分图。
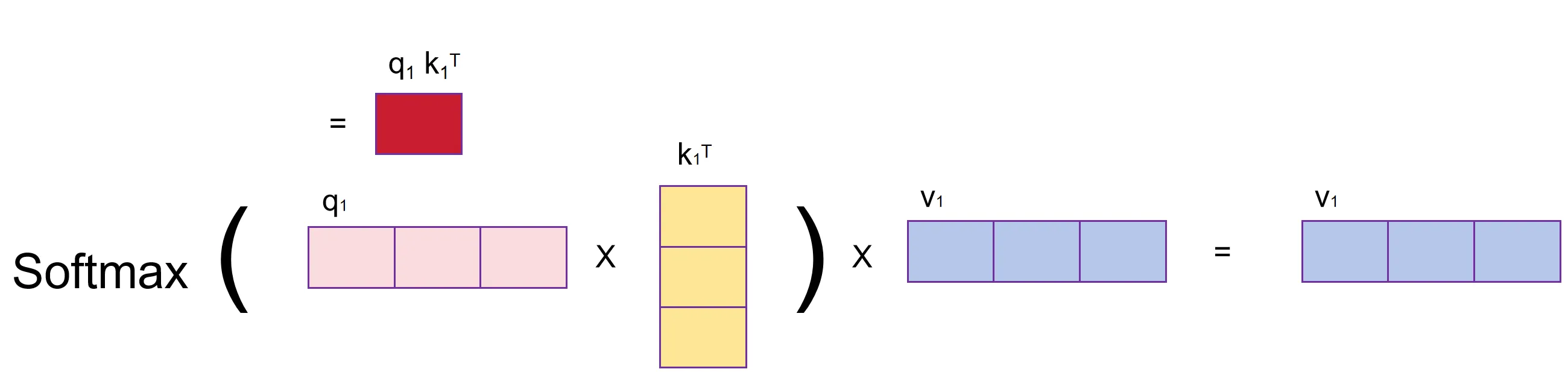
q 1 k 1 T {q_1} {k_1}^T q1k1T的结果是一个标量,而标量的Softmax结果为1,所以最终该向量在注意力的作用下,结果依旧还是 v 1 v_1 v1