DeepSeek已经火起来了,准备部署一个单机版的蒸馏模型玩一玩。由于一直在玩业余软件无线电,所以顺带用一个最简单的问题考一考它。整个过程在CSDN的C知道、讯飞星火上搜索并完成配置。
文章目录
1. 安装ollama
Ollama是一个与人工智能相关的软件平台,旨在简化大型语言模型(LLMs)和其他机器学习模型的部署和服务。通过Ollama,开发人员可以更容易地将这些复杂的模型集成到自己的应用程序中,从而提供诸如自然语言处理、图像识别等高级功能。
在计算机领域里,Ollama提供了几个关键特性以帮助用户更好地利用AI能力:
- 本地化:让用户能够在个人电脑或者服务器上直接运行强大的AI模型,无需依赖远程服务。
- API接口:包括HTTP API以及兼容OpenAI标准的API端点,方便开发者快速接入现有的工作流。
- 图形界面:带有直观易用的UI组件,使得非技术人员也能轻松管理和测试不同的AI模型。
- 多模型支持:除了自家提供的Phi系列模型外,还集成了来自其他提供商的各种预训练模型,例如Xinference, Azure OpenAI等。
在windows下,直接下载ollama安装包即可,傻瓜式完成安装。
在Linux下,比如我的 manjaro,直接使用pamac安装:
pamac install ollama
安装后,运行:
ollama serve
即可启动服务。服务启动后,会出现一个羊驼图标在开始菜单右侧。


2. 自动安装并运行DeepSeek
首先,确定自己机器的配置。像我有64GB内存,一块8GB的GPU卡,则勉强可以运行 32B的蒸馏版。如果更小的配置,建议还是玩玩14或者1.5的版本(树莓派可用)。
#较好配置
ollama run deepseek-r1:32b
#一般配置
ollama run deepseek-r1:1.5b
等待一段时间后,模型进入提示符 >>>,即可对话。
$ ollama run deepseek-r1:1.5b
>>> 你好!请问您是谁?
<think>
我是DeepSeek-R1,一个由深度求索公司开发的智能助手,我会尽我所能为您提供帮助。
</think>
我是DeepSeek-R1,一个由深度求索公司开发的智能助手,我会尽我所能为您提供帮助。
>>> Send a message (/? for help)
3.安装配置网页端
虽然命令行方式就能对话,但是这不是我们想要的。我们希望大模型能够利用新的数据、阅读加工,并帮助我们获取信息。为此,根据需求不同,可以有两种方法。
方法1是直接在火狐或者Chrome里安装插件“Page Assist”,并允许其使用Baidu搜索,这样可以让DeepSeek变为上网助手,由助手搜索文章、加工后送给读者。
方法2是安装AnythingLLM,这个开箱即用的单机版GUI可以帮助你向量化自己本地的文件,特别适合看论文。比如上传一个论文,而后提问。
3.1 安装Page Assist
以火狐为例,在扩展管理器搜索 PageAssist,而后安装。
安装后,在配置菜单打开配置,允许百度搜索。
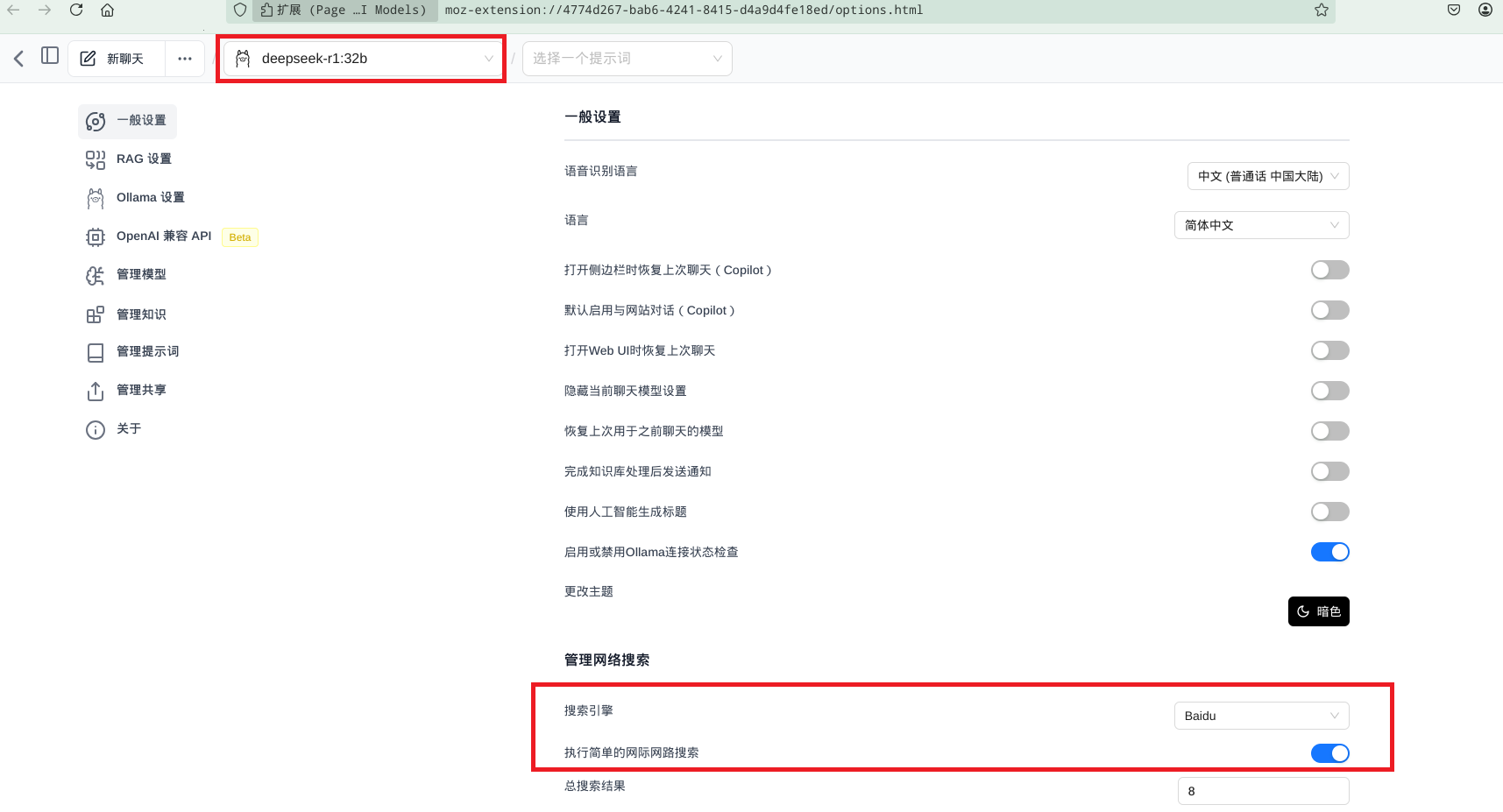
如果此刻ollama已经在serve状态,windows下任务栏有羊驼图标,即可开展对话。
3.2 安装AnythingLLM
假如我们本地有很多文档(比如准备发的paper,还有花钱买的万方的论文),又不想上传到网上去用现成的大模型来分析,则可以安装 AnythingLLM。这个框架可以在本地向量化文档,并对文档进行分析、理解。
在windows下,去官网下载安装包即可。在Linux下,直接执行在线安装:
curl -fsSL https://cdn.anythingllm.com/latest/installer.sh|sh
~/AnythingLLMDesktop/start
启动后,创建使用ollma的会话(工作区):
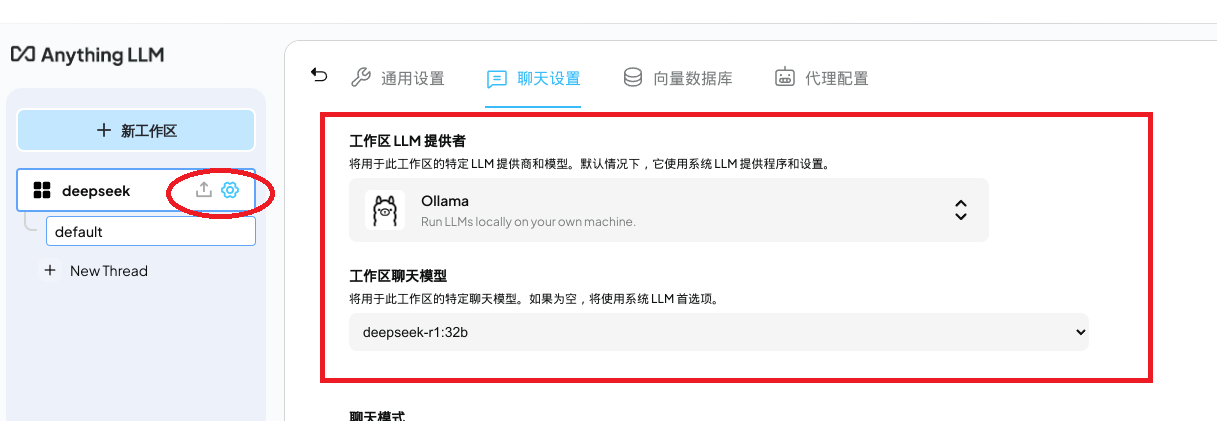
点击上传按钮,即可上传本地文章了。
4. 测试
4.1 在线搜素助手
在Page Assist里问问我自己的情况:
请搜索并阅读CSDN网站丁劲犇的文章,并评估他的技术水平。
回答:

4.2 资料助手
我们在anythingLLM里,上传一个PostgreSQL的PDF全文:
而后咨询它一个问题:
我有一个PostgreSQL的表格,里面有一个字段叫做"insert_time" , 是用作分区的键。 你的任务是通过一定的手段,在新的行插入时,自动检查insert_time的时间。如果时间超越了既有的分区范围,则自动创建分区。请给出解决方案。
32B大模型用了10分钟(注意在Anythingllm的设置里,设置模型永远不清理,把默认5分钟去掉,否则垃圾显卡首次会超时),给出了回答:
4.2.1 思考过程
嗯,用户的问题是关于PostgreSQL中如何实现动态分区。他们有一个表格,里面有一个叫做“insert_time”的字段,用来作为分区的键。现在,当插入新行的时候,需要检查这个时间是否超出了现有的分区范围,如果超过了,就自动创建新的分区。
首先,我得理解用户的场景。用户可能是在处理一个有大量数据插入的应用,比如日志系统或者电子商务平台,这些地方每天都有大量的数据生成,并且按照日期进行分区管理会比较方便。他们希望避免手动创建分区的麻烦,同时保持数据库的良好性能和可维护性。
接下来,我需要考虑如何实现这个自动分区的功能。PostgreSQL支持几种分区方法,包括范围分区、列表分区和哈希分区等。在这个场景中,使用范围分区是比较合适的,因为insert_time是一个时间类型,可以通过日期来划分分区。
然后,我想到可能有两种方式:一种是使用触发器,在插入数据时检查是否需要创建新分区;另一种是在应用层进行处理,比如在插入数据之前先检查分区是否存在,如果不存在就调用存储过程创建。这两种方法各有优缺点,触发器的方式完全在数据库内部完成,但可能会增加每次插入操作的开销;而应用层的方法则需要更多的代码维护,但也可能更灵活。
用户可能希望解决方案尽可能自动化,并且不影响现有系统的性能。因此,使用触发器可能是一个更好的选择,因为它能够自动处理分区创建的问题,无需修改现有的应用程序逻辑。
然后,我开始详细设计这个方案。首先,创建一个主表,用于存储所有数据,但实际的数据会分布在各个子分区中。为了实现范围分区,主表需要定义分区策略,比如按insert_time的年、月进行分区。接着,创建一个触发器,在插入或更新操作时被触发,检查当前insert_time是否超出了现有的分区范围。
为了实现这个检查,我需要编写一个函数,该函数会查询现有的分区信息,并确定新数据的时间是否落在已有的分区之外。如果需要创建新的分区,则根据时间生成相应的分区名称和条件,执行CREATE TABLE命令来创建新的分区。
此外,还需要考虑一些边界情况,比如分区的粒度(按年、月还是日),以及如何处理跨年的情况。例如,如果现有分区是按月份划分的,那么在每个月的第一天插入数据时,系统需要自动检查是否需要创建新的月份分区。
另一个需要注意的问题是性能。触发器会在每次插入操作后执行,这可能会增加一定的延迟。因此,可能需要优化触发器的逻辑,使其尽可能高效,或者考虑批量处理的方式,减少对单次插入的影响。
最后,我还需要验证这个方案的有效性。可以通过插入不同时间的数据,观察系统是否能够自动创建相应的分区,并且数据能够正确地分布到各个子分区中。此外,还应该测试在高并发情况下的性能表现,确保触发器不会成为瓶颈。
4.1.2 给出答案
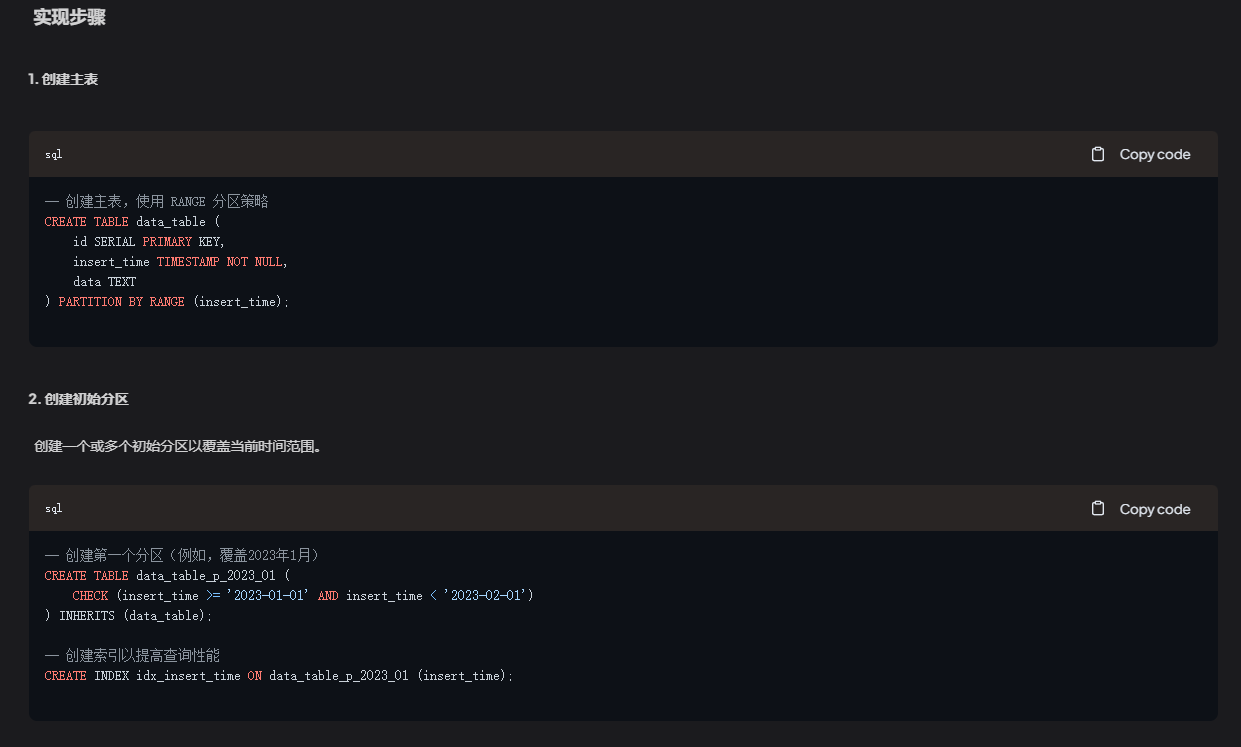
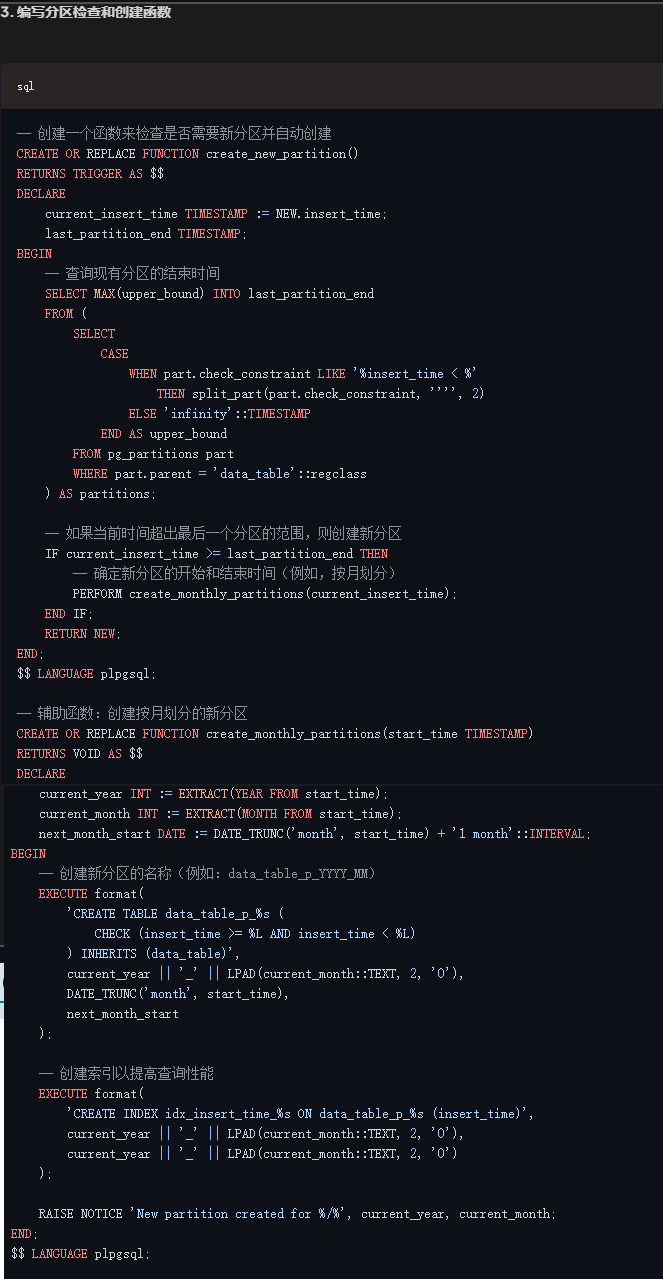
 可以看到,大模型能够基本理解英文版的 PostgreSQL A4.pdf的内容,并几乎正确地使用传统继承表的方法实现了分区的范例。
可以看到,大模型能够基本理解英文版的 PostgreSQL A4.pdf的内容,并几乎正确地使用传统继承表的方法实现了分区的范例。
但它混淆了新的partition by range语法,和继承表的传统做法,实际上是略有问题的。
5 在线满血版对比
可以看到,使用单机运行蒸馏后的大模型,是可以提高自己的工作效率的。但是,它对文献的理解比较浅显。
我们最后询问一下在线满血的deepSeek同样的问题:
5.1 询问结果
为了实现PostgreSQL中在插入新行时自动检测并创建所需分区的功能,可以按照以下步骤操作:
5.1.1解决方案步骤
-
创建主表(Partitioned Table)
使用声明式分区,按insert_time字段的范围分区。CREATE TABLE main_table ( id SERIAL, data TEXT, insert_time TIMESTAMP NOT NULL ) PARTITION BY RANGE (insert_time); -
创建触发器函数
该函数负责动态创建新分区(如果不存在)。CREATE OR REPLACE FUNCTION create_partition_and_insert() RETURNS TRIGGER AS $$ DECLARE partition_name TEXT; start_date TIMESTAMP; end_date TIMESTAMP; BEGIN -- 按月分区,计算分区的起始和结束时间 start_date := date_trunc('month', NEW.insert_time); end_date := start_date + interval '1 month'; -- 生成分区名称(如main_table_2023_02) partition_name := 'main_table_' || to_char(start_date, 'YYYY_MM'); -- 动态创建分区(如果不存在) EXECUTE format( 'CREATE TABLE IF NOT EXISTS %I PARTITION OF main_table FOR VALUES FROM (%L) TO (%L)', partition_name, start_date, end_date ); RETURN NEW; END; $$ LANGUAGE plpgsql; -
创建BEFORE INSERT触发器
将触发器绑定到主表,在插入前自动执行函数。CREATE TRIGGER trg_main_table_partition BEFORE INSERT ON main_table FOR EACH ROW EXECUTE FUNCTION create_partition_and_insert();
5.1.2 方案说明
- 动态分区创建:每次插入数据时,触发器会根据
insert_time的值计算对应的月份分区范围。若分区不存在,则通过EXECUTE动态创建。 - 并发安全:使用
CREATE TABLE IF NOT EXISTS避免重复创建,确保并发插入时的安全性。 - 灵活调整:如需按其他时间间隔(如日或年)分区,只需修改
date_trunc和分区名称生成逻辑即可。
5.1.3 示例测试
插入一条新记录,触发分区创建:
INSERT INTO main_table (data, insert_time) VALUES ('test', '2023-03-15 14:30:00');
执行后,若main_table_2023_03分区不存在,将自动创建该分区,范围从2023-03-01到2023-04-01。
5.1.4 注意事项
- 权限:执行触发器的数据库用户需拥有
CREATE TABLE权限。 - 性能:频繁插入可能导致触发器轻微性能开销,建议监控并根据业务需求优化分区策略。
- 时区处理:若
insert_time为TIMESTAMPTZ类型,需在函数中显式处理时区转换,确保分区范围正确。
通过上述步骤,即可实现插入数据时自动检测并创建所需分区的功能,确保数据按时间高效组织。
5.2 附件:思考过程
117秒,叹为观止:
嗯,用户想要在PostgreSQL中实现一个自动创建分区的功能,当插入新行时检查insert_time是否超出已有的分区范围,如果是的话就自动创建新分区。首先,我需要回忆一下PostgreSQL的分区机制,特别是声明式分区,因为从版本10开始支持了声明式分区,可能更合适。
用户提到的insert_time作为分区键,应该是按范围分区的,比如按天、按月或者按年。假设用户可能使用的是时间范围分区,比如每个月一个分区。但具体分区策略可能需要根据用户的数据量和使用情况来定,不过这里用户没有具体说明,可能需要保持灵活。
接下来,问题是如何在插入数据时自动检测是否需要创建新分区。PostgreSQL本身没有内置的自动创建分区的功能,所以可能需要通过触发器或者规则来实现。当插入数据时,触发一个函数,检查当前行的insert_time是否在现有的某个分区中,如果不在,则创建新的分区。
首先,用户的分区表应该是已经存在的,并且设置好了分区策略。例如,主表是按月分区,每个分区对应一个月份。假设主表结构是这样的:
CREATE TABLE main_table (
id SERIAL,
data TEXT,
insert_time TIMESTAMP NOT NULL
) PARTITION BY RANGE (insert_time);
然后,已有的分区可能是这样的:
CREATE TABLE main_table_2023_01 PARTITION OF main_table
FOR VALUES FROM ('2023-01-01') TO ('2023-02-01');
接下来,当插入一个insert_time为'2023-02-15'的记录时,需要检查是否存在对应的分区,如果没有,则自动创建main_table_2023_02。
为了实现自动检测和创建,可以创建一个BEFORE INSERT触发器,当插入数据时,检查该行的insert_time是否属于现有某个分区的范围。如果不存在,则创建新的分区。
这里需要考虑几个问题:
1. 如何检查现有分区是否覆盖了插入的时间?
可能需要查询系统目录表pg_partitioned_table或者pg_inherits来获取所有分区表的信息,然后解析它们的范围约束,确定是否包含当前的insert_time。或者更直接的方式是尝试插入,如果失败则捕获异常并创建分区。但PostgreSQL的触发器无法在事务中自动重试,所以可能需要在触发器中处理。
不过,更可靠的方式可能是预先检查分区是否存在。例如,根据insert_time计算出对应的分区名称,然后检查该分区是否存在。如果不存在,则创建。
例如,如果按月份分区,可以将insert_time转换为对应的月份,然后生成分区表名如main_table_YYYY_MM。然后检查该表是否存在。如果不存在,则创建该分区。
但是这种方法依赖于分区的命名规则和范围的定义是否一致。比如,用户的分区可能不是按月的,或者命名方式不同,所以可能需要更通用的方法。
另一个方法是查询主表的所有分区,并检查是否存在覆盖该insert_time的分区。可以通过查询pg_inherits来获取所有分区表,然后对每个分区查询其约束条件,确定是否包含该时间值。这可能比较复杂,因为需要解析每个分区的CHECK约束中的范围条件。
或者,可以使用PostgreSQL的partition_bounds信息,不过可能需要更复杂的查询。
或者,可以尝试执行一条查询,查找是否存在分区可以包含该insert_time,例如:
SELECT COUNT(*) FROM main_table WHERE insert_time = NEW.insert_time;
但这可能不会有效,因为如果分区不存在,查询可能不会返回正确的结果。
另一种思路是,当插入数据时,如果发现没有对应的分区,触发器函数将捕获错误,然后创建分区并重新执行插入。但PostgreSQL的触发器函数是在同一事务中执行的,如果出现错误,整个事务会回滚。因此,可能需要使用异常处理来捕获错误,然后在触发器函数中创建分区,并重新尝试插入。
例如,在触发器函数中使用PL/pgSQL的EXCEPTION块来处理,当插入失败时,创建分区,然后再次插入。
但这种方法可能需要将插入操作包装在触发器函数中,而不是直接依赖原始INSERT语句。或者,在BEFORE INSERT触发器中,预先检查是否需要创建分区,如果不存在则创建,然后再允许插入。
具体步骤可能如下:
1. 创建一个BEFORE INSERT触发器,针对主表。
2. 在触发器函数中,获取NEW.insert_time的值。
3. 根据该值确定应该属于哪个分区范围,例如按月份。
4. 生成对应的分区表名,例如main_table_2023_02。
5. 检查该分区是否存在,如果不存在,则创建分区。
6. 然后允许插入操作继续。
这种方法的关键在于如何动态创建分区表。需要确保在触发器函数中有足够的权限来创建表,并且避免并发插入导致的问题,例如多个事务同时检测到分区不存在并尝试创建,可能会引发错误。
因此,在创建分区时,需要使用CREATE TABLE IF NOT EXISTS,或者在尝试创建时捕获重复表的错误。但PostgreSQL的CREATE TABLE IF NOT EXISTS会检查表名是否存在,而不管是否是分区,因此需要确保分区名称唯一,并且没有其他同名表存在。
另外,分区的定义需要正确设置范围约束,例如,对于按月分区,每个分区的FROM值是该月的第一天,TO值是下个月的第一天。
所以,在触发器函数中,需要根据NEW.insert_time计算出分区的起始和结束时间,然后生成相应的CREATE TABLE语句。
例如,对于时间'2023-02-15',对应的分区范围是FROM '2023-02-01' TO '2023-03-01',分区表名为main_table_2023_02。
创建分区的SQL语句可能是:
CREATE TABLE IF NOT EXISTS main_table_2023_02 PARTITION OF main_table
FOR VALUES FROM ('2023-02-01') TO ('2023-03-01');
这样,如果分区已存在,就不会重复创建。
但是,在并发情况下,多个插入操作可能同时检测到分区不存在,并尝试创建,但由于使用了IF NOT EXISTS,这应该不会有问题,除了可能的性能开销。
此外,分区的命名规则需要和触发器中的生成逻辑一致,否则可能导致错误。
现在,如何根据NEW.insert_time生成正确的分区名称和范围?
例如,将时间转换为该月的第一天作为起始,下个月的第一天作为结束。这可以通过date_trunc函数实现:
start_date := date_trunc('month', NEW.insert_time);
end_date := start_date + interval '1 month';
然后,分区名称可以是main_table_YYYY_MM,其中YYYY是年份,MM是月份。
在PL/pgSQL中,可以构造这样的字符串:
partition_name := 'main_table_' || to_char(start_date, 'YYYY_MM');
然后,构造动态SQL来创建分区:
EXECUTE format('CREATE TABLE IF NOT EXISTS %I PARTITION OF main_table FOR VALUES FROM (%L) TO (%L)', partition_name, start_date, end_date);
这样,每次插入时,触发器函数会检查对应的分区是否存在,如果不存在则创建。
这样处理之后,插入操作应该可以成功,因为分区已经存在。
但需要考虑时区的问题,如果insert_time是带时区的timestamp with time zone,则date_trunc可能会根据当前时区设置截断,可能需要显式处理时区。
不过用户提到的是insert_time字段,具体类型可能是timestamp或timestamptz,需要确保在计算时区时正确。
此外,还需要确保主表已经存在,并且触发器已经正确安装。
总结步骤:
1. 创建主表,使用PARTITION BY RANGE (insert_time)。
2. 创建一个BEFORE INSERT触发器,针对主表。
3. 在触发器函数中:
a. 获取NEW.insert_time的值。
b. 计算该时间对应的分区起始和结束时间。
c. 生成分区表名。
d. 使用动态SQL创建分区(如果不存在)。
4. 插入操作会自动路由到正确的分区。
需要注意的是,如果用户的分区策略不是按月,而是按其他时间间隔(比如按天或按年),则需要调整计算start_date和end_date的方法,以及分区名称的生成方式。
另外,如果用户已经存在某些分区,触发器函数中的创建逻辑应该不影响现有分区,只要范围正确。
潜在的问题包括:
- 并发插入时的竞争条件:多个事务同时插入导致多次尝试创建分区。但由于使用了CREATE TABLE IF NOT EXISTS,这应该没问题,除了可能多次尝试,但不会出错。
- 性能开销:每次插入都需要执行触发器函数,检查分区是否存在,可能会影响性能。特别是当插入频繁且每次都需要创建新分区时。但对于大多数场景,分区的创建是相对较少的事件,可能可以接受。
- 权限问题:触发器函数必须以具有创建表权限的用户身份运行,否则会失败。
- 分区范围的计算是否正确,特别是处理月末的情况。例如,当insert_time是某个月的最后一天时,date_trunc('month', '2023-02-28')会得到'2023-02-01',而结束时间是'2023-03-01',这样分区范围是正确的。
可能的优化是,在触发器中,先尝试插入,如果失败,捕获错误并创建分区。但PostgreSQL的触发器无法在插入失败后自动重试,因此必须在插入之前确保分区存在。
另一个方法是使用存储过程来封装插入操作,在插入前检查并创建分区。但用户希望自动处理,所以触发器更合适。
因此,最终的解决方案是创建一个BEFORE INSERT触发器,使用PL/pgSQL函数动态创建所需的分区。
现在,给出具体的SQL代码示例:
首先,创建主表:
CREATE TABLE main_table (
id SERIAL,
data TEXT,
insert_time TIMESTAMP NOT NULL
) PARTITION BY RANGE (insert_time);
然后,创建触发器函数:
CREATE OR REPLACE FUNCTION create_partition_and_insert()
RETURNS TRIGGER AS $$
DECLARE
partition_name TEXT;
start_date TIMESTAMP;
end_date TIMESTAMP;
BEGIN
-- 计算分区的时间范围(按月分区)
start_date := date_trunc('month', NEW.insert_time);
end_date := start_date + interval '1 month';
-- 生成分区名称,例如main_table_2023_02
partition_name := 'main_table_' || to_char(start_date, 'YYYY_MM');
-- 创建分区(如果不存在)
EXECUTE format(
'CREATE TABLE IF NOT EXISTS %I PARTITION OF main_table FOR VALUES FROM (%L) TO (%L)',
partition_name, start_date, end_date
);
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
然后,创建触发器:
CREATE TRIGGER trg_main_table_partition
BEFORE INSERT ON main_table
FOR EACH ROW EXECUTE FUNCTION create_partition_and_insert();
这样,每当插入新行时,触发器会自动检查对应的月份分区是否存在,不存在则创建。
需要注意的是,这个触发器会在每次插入时执行,可能会对性能有一定影响。可以考虑优化,比如缓存已存在的分区,但PL/pgSQL中每个语句都是独立的,可能无法有效缓存。或者,使用一年内预先创建分区的方式,但用户的需求是动态创建。
另外,如果用户的分区策略是按天,那么需要调整start_date和end_date的计算,例如:
start_date := date_trunc('day', NEW.insert_time);
end_date := start_date + interval '1 day';
同时,分区名称可以包含年月日,如main_table_2023_02_15。
另外,需要确保在创建分区时,范围是正确的,不会重叠或产生间隙。
最后,测试这个触发器,插入一个超出现有分区的时间,观察是否自动创建了新的分区。
6 总结
DeepSeek满血版的思考能力非常惊人,32b的中配版也可以很好的作为助手对本地数据进行初步的筛选和摘要。