文章目录
一、 引言
在经济、金融、运营、气象等领域,时间序列数据无处不在。时间序列分析与预测旨在从历史数据中提取趋势、季节性、周期性以及随机波动等信息,构建结构化的预测模型,从而为企业决策、风险控制和战略规划提供可靠依据。
本文将详细介绍以下内容:
- 时序数据基础与组件分解:如何分析趋势、季节性、周期性与随机波动,以及如何利用移动平均、指数平滑与分解方法提取数据结构。
- 预测模型与评估:构建回归趋势模型与 ARIMA 模型,结合自相关性信息提升预测精度,并通过分割数据、对比基准模型与误差指标进行模型验证。
通过理论解析、详细代码示例和个人实践经验分享,希望您能从本文中获得系统而深入的时间序列分析与预测的知识。
二、 时序数据基础与组件分解
时序数据具有时间依赖性,其主要组件包括趋势、季节性、周期性和随机波动。正确分解这些组件不仅有助于理解数据内在结构,也为后续建模打下基础。
2.1 时序数据基本概念
- 趋势(Trend):长期向上的或向下的变化趋势。
- 季节性(Seasonality):固定时间周期内的规律性波动,如季度、月度或周周期。
- 周期性(Cyclicity):数据中反映经济周期等长期波动,但周期长度不固定。
- 随机波动(Noise):数据中无法预测的随机变化部分。
2.2 数据平滑与移动平均
移动平均(Moving Average) 是最简单的平滑方法,通过对相邻数据求均值来消除随机波动,从而更清晰地捕捉趋势。
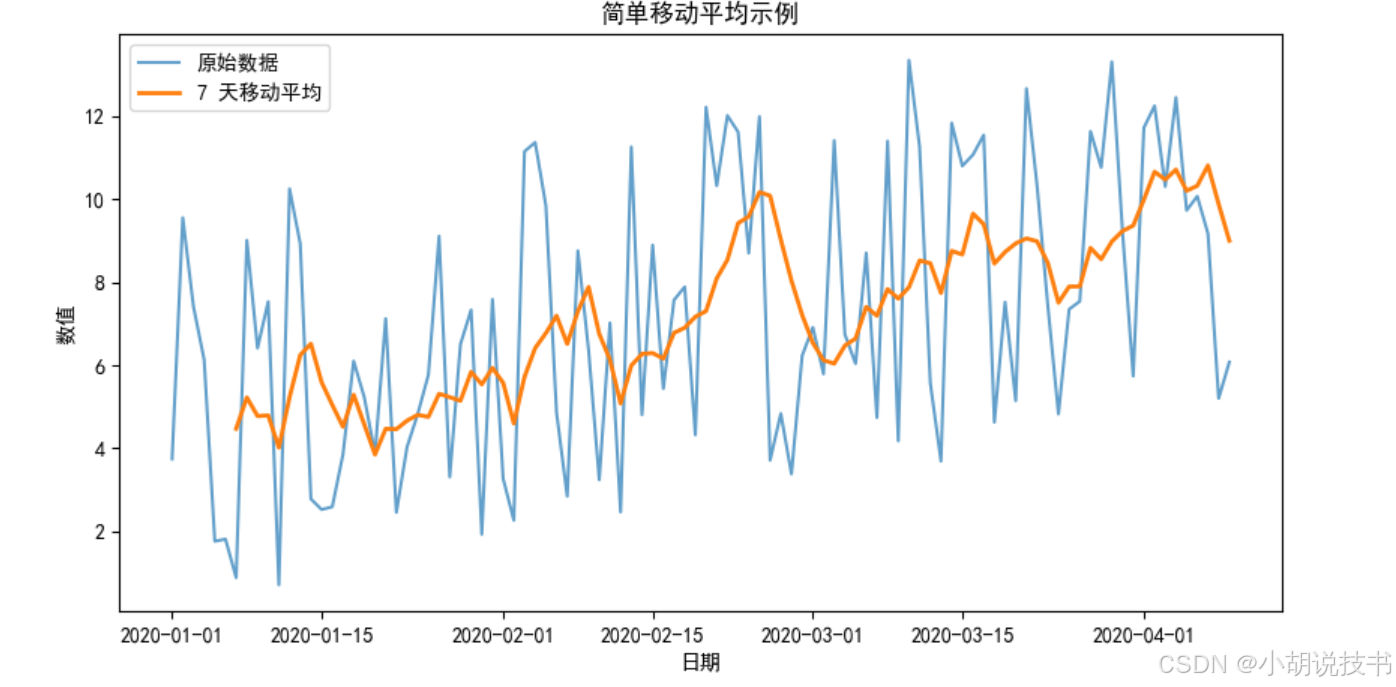
实践示例:简单移动平均
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 模拟生成时间序列数据
np.random.seed(42)
dates = pd.date_range(start='2020-01-01', periods=100, freq='D')
data_values = np.random.rand(100) * 10 + np.linspace(0, 5, 100) # 趋势 + 随机噪声
ts = pd.Series(data_values, index=dates)
# 计算简单移动平均(窗口大小 7 天)
moving_avg = ts.rolling(window=7).mean()
# 绘制原始数据与移动平均
plt.figure(figsize=(10, 5))
plt.plot(ts, label='原始数据', alpha=0.7)
plt.plot(moving_avg, label='7 天移动平均', linewidth=2)
plt.title("简单移动平均示例")
plt.xlabel("日期")
plt.ylabel("数值")
plt.legend()
plt.show()
解析:
- 使用 Pandas 的
rolling()方法计算 7 天简单移动平均,有效平滑数据噪音,凸显趋势。
2.3 指数平滑
指数平滑(Exponential Smoothing) 采用指数加权的方式,赋予最近数据更高权重,常用于短期预测。
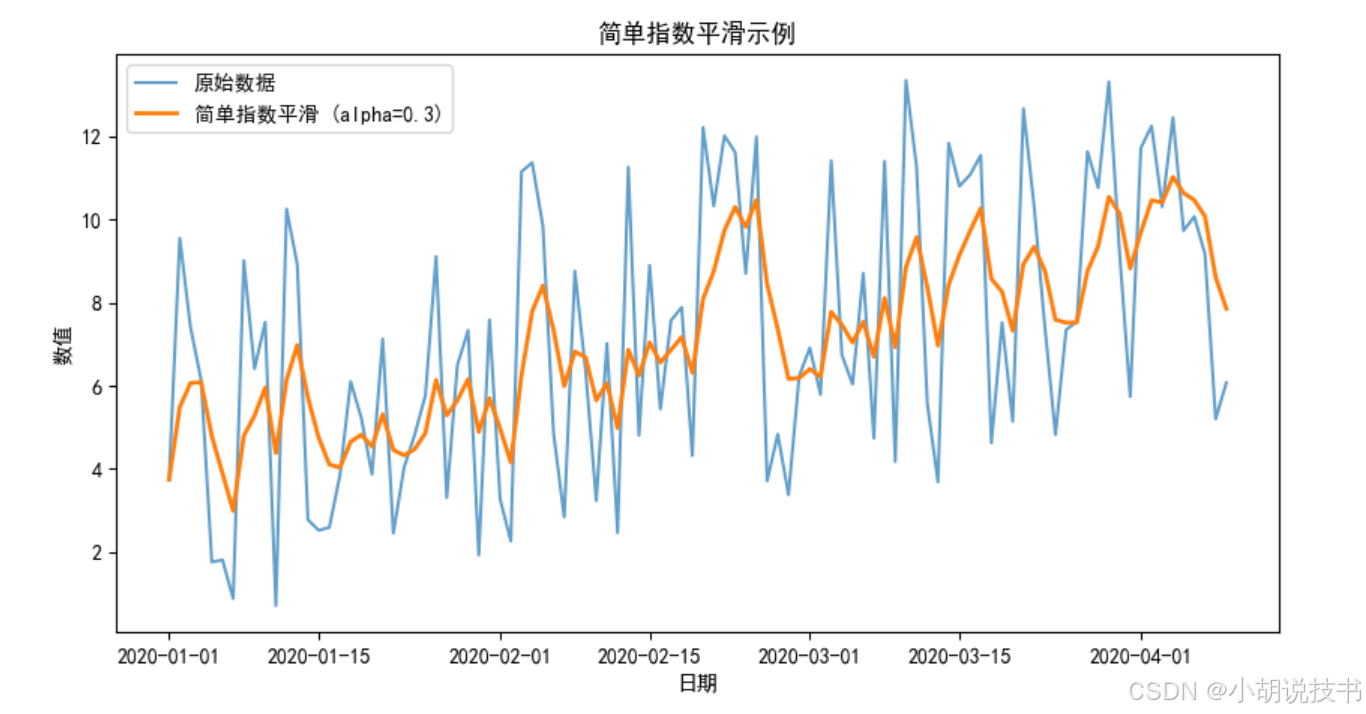
简单指数平滑(SES)
# 简单指数平滑:alpha 为平滑因子,范围 0-1
alpha = 0.3
ses = ts.ewm(alpha=alpha, adjust=False).mean()
plt.figure(figsize=(10, 5))
plt.plot(ts, label='原始数据', alpha=0.7)
plt.plot(ses, label=f"简单指数平滑 (alpha={
alpha})", linewidth=2)
plt.title("简单指数平滑示例")
plt.xlabel("日期")
plt.ylabel("数值")
plt.legend()
plt.show()
Holt-Winters 指数平滑
当数据存在趋势和季节性时,可使用 Holt 或 Holt-Winters 方法。
from statsmodels.tsa.holtwinters import ExponentialSmoothing
# 假设数据存在趋势和季节性(模拟数据)
ts_hw = ts + 2 * np.sin(np.linspace(0, 2*np.pi, 100))
model = ExponentialSmoothing(ts_hw, trend='add', seasonal='add', seasonal_periods=7)
hw_fit = model.fit()
plt.figure(figsize=(10, 5))
plt.plot(ts_hw, label='原始数据', alpha=0.7)
plt.plot(hw_fit.fittedvalues, label="Holt-Winters 拟合", linewidth=2)
plt.title("Holt-Winters 指数平滑示例")
plt.xlabel("日期")
plt.ylabel("数值")
plt.legend()
plt.show()
解析:
- Holt-Winters 方法同时考虑趋势和季节性,适合具有周期性波动的数据。

2.4 时序分解
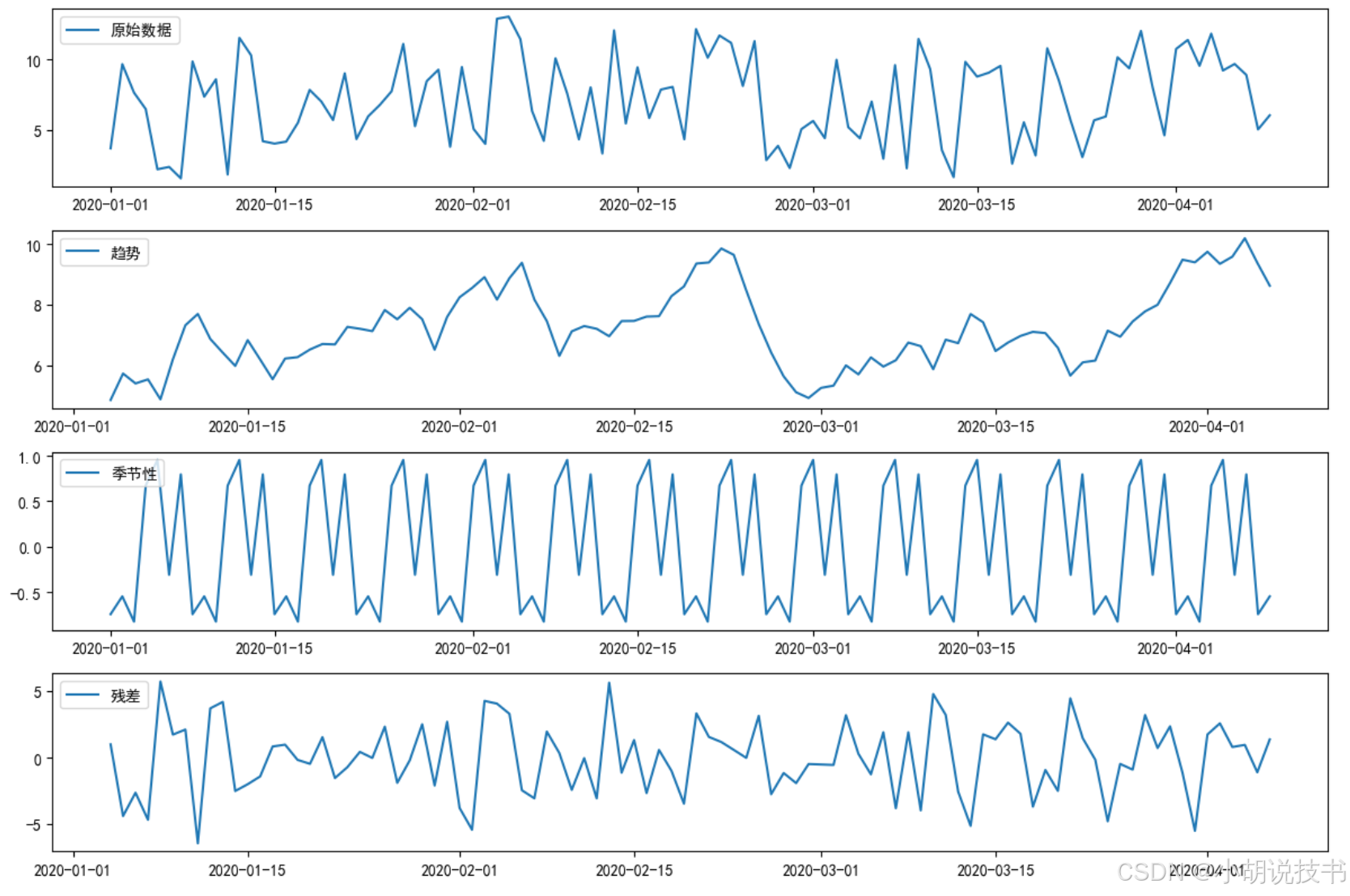
时间序列分解将数据分为趋势、季节性和残差部分,帮助深入理解数据结构。
实践示例:使用 statsmodels 进行分解
from statsmodels.tsa.seasonal import seasonal_decompose
# 对 ts_hw 进行加法分解
decomposition = seasonal_decompose(ts_hw, model='additive', period=7)
trend = decomposition.trend
seasonal = decomposition.seasonal
residual = decomposition.resid
plt.figure(figsize=(12, 8))
plt.subplot(411)
plt.plot(ts_hw, label='原始数据')
plt.legend(loc='upper left')
plt.subplot(412)
plt.plot(trend, label='趋势')
plt.legend(loc='upper left')
plt.subplot(413)
plt.plot(seasonal, label='季节性')
plt.legend(loc='upper left')
plt.subplot(414)
plt.plot(residual, label='残差')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()
解析:
- 使用
seasonal_decompose()将时序数据拆分成趋势、季节性和残差部分,为后续预测和建模提供依据。
三、 预测模型与评估
在掌握了时序数据的平滑和分解方法后,接下来我们构建预测模型,并使用合理的评估指标对模型性能进行量化。
3.1 回归趋势模型
回归趋势模型通过拟合线性或多项式函数来捕捉数据的长期趋势,适用于预测长期走势。
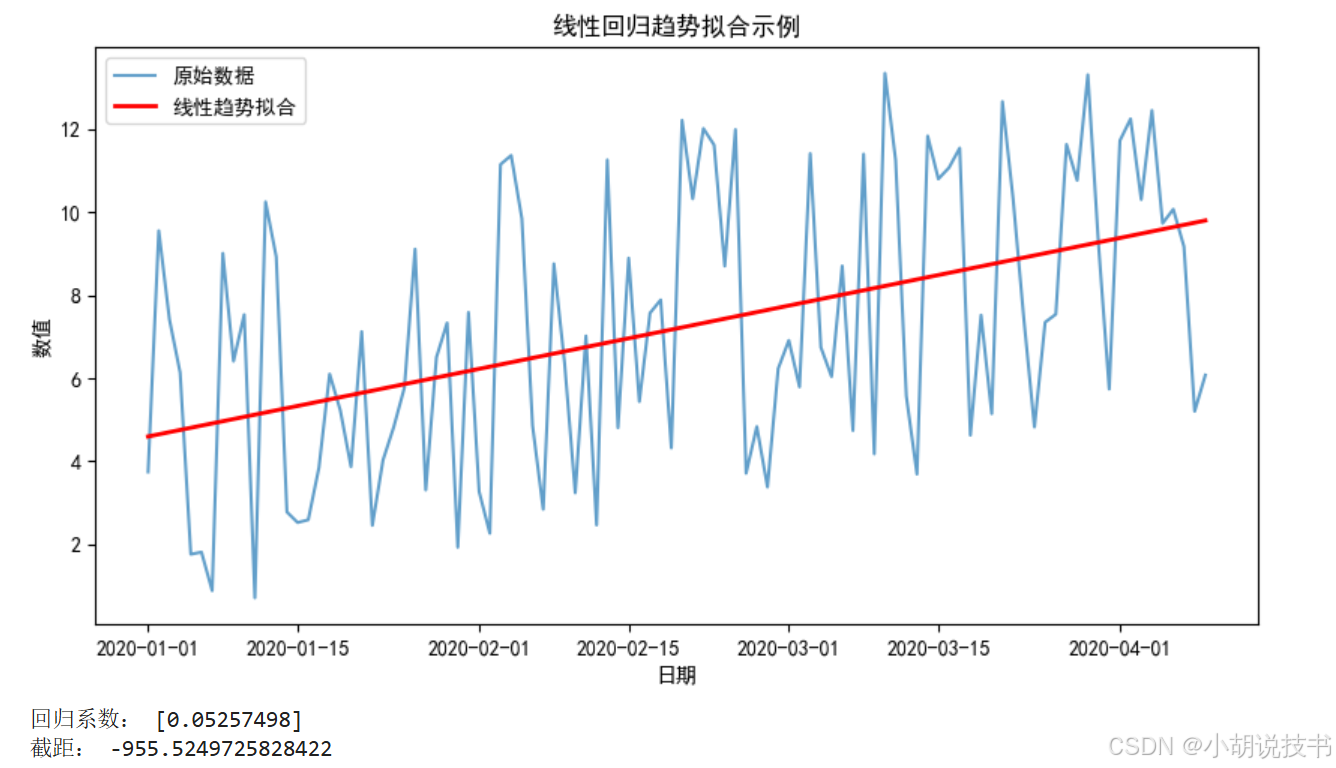
实践示例:线性回归拟合趋势
from sklearn.linear_model import LinearRegression
import matplotlib.dates as mdates
# 将日期转换为数值型特征
ts_numeric = np.array(mdates.date2num(ts.index)).reshape(-1, 1)
lr_model = LinearRegression()
lr_model.fit(ts_numeric, ts)
# 预测趋势
trend_pred = lr_model.predict(ts_numeric)
plt.figure(figsize=(10, 5))
plt.plot(ts.index, ts, label='原始数据', alpha=0.7)
plt.plot(ts.index, trend_pred, label='线性趋势拟合', color='red', linewidth=2)
plt.title("线性回归趋势拟合示例")
plt.xlabel("日期")
plt.ylabel("数值")
plt.legend()
plt.show()
print("回归系数:", lr_model.coef_)
print("截距:", lr_model.intercept_)
解析:
- 通过将日期转换为数值,利用线性回归拟合时序数据,获得趋势部分,有助于短期预测和长期趋势分析。
3.2 ARIMA 模型
ARIMA(自回归积分移动平均)模型结合了自回归、差分与移动平均成分,是时间序列预测中常用的模型之一。
ARIMA 模型原理
- AR(自回归):利用过去的观测值预测当前值。
- I(差分):对数据进行差分以使时间序列平稳。
- MA(移动平均):利用过去的预测误差来修正当前预测。
实践示例:构建 ARIMA 模型
import warnings
warnings.filterwarnings("ignore")
from statsmodels.tsa.arima.model import ARIMA
# 假设 ts_hw 为已平稳的时间序列数据(或经过差分处理)
# 这里直接使用 ts_hw 作为示例
model_arima = ARIMA(ts_hw, order=(2, 1, 2)) # (p,d,q) 参数示例
arima_result = model_arima.fit()
# 打印模型摘要
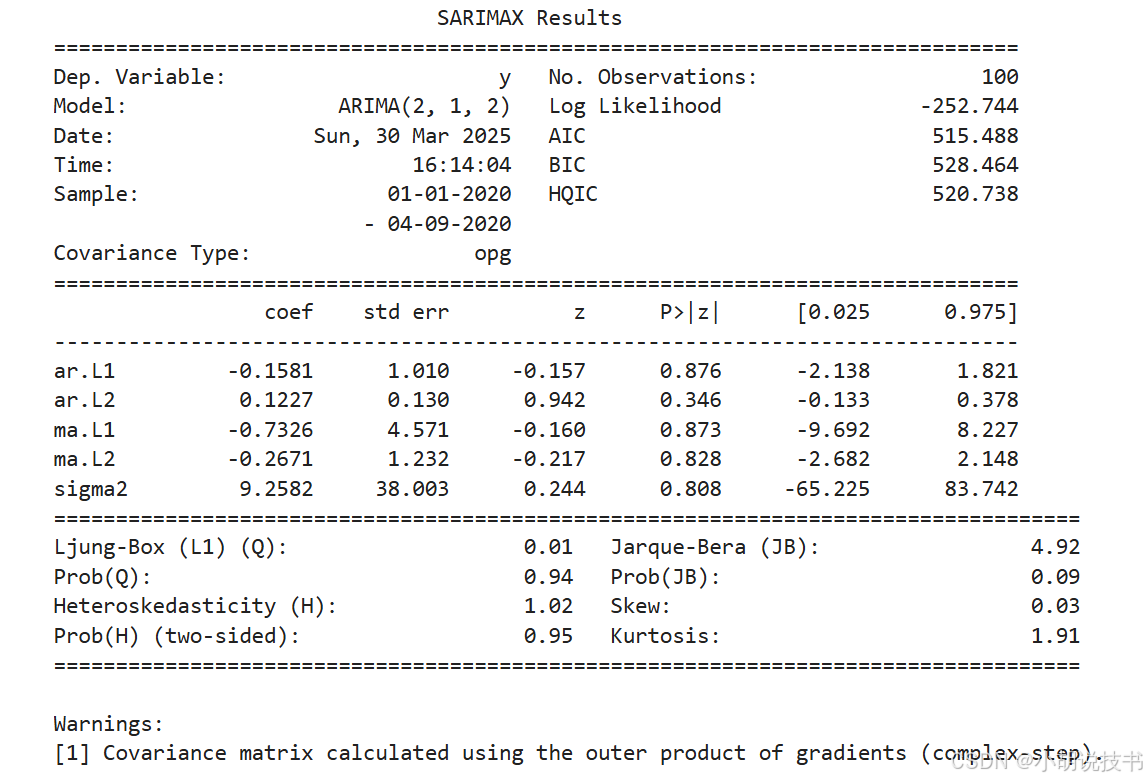
print(arima_result.summary())
# 预测未来 14 天
forecast = arima_result.forecast(steps=14)
plt.figure(figsize=(10, 5))
plt.plot(ts_hw.index, ts_hw, label='历史数据')
plt.plot(forecast.index, forecast, label='预测数据', color='red')
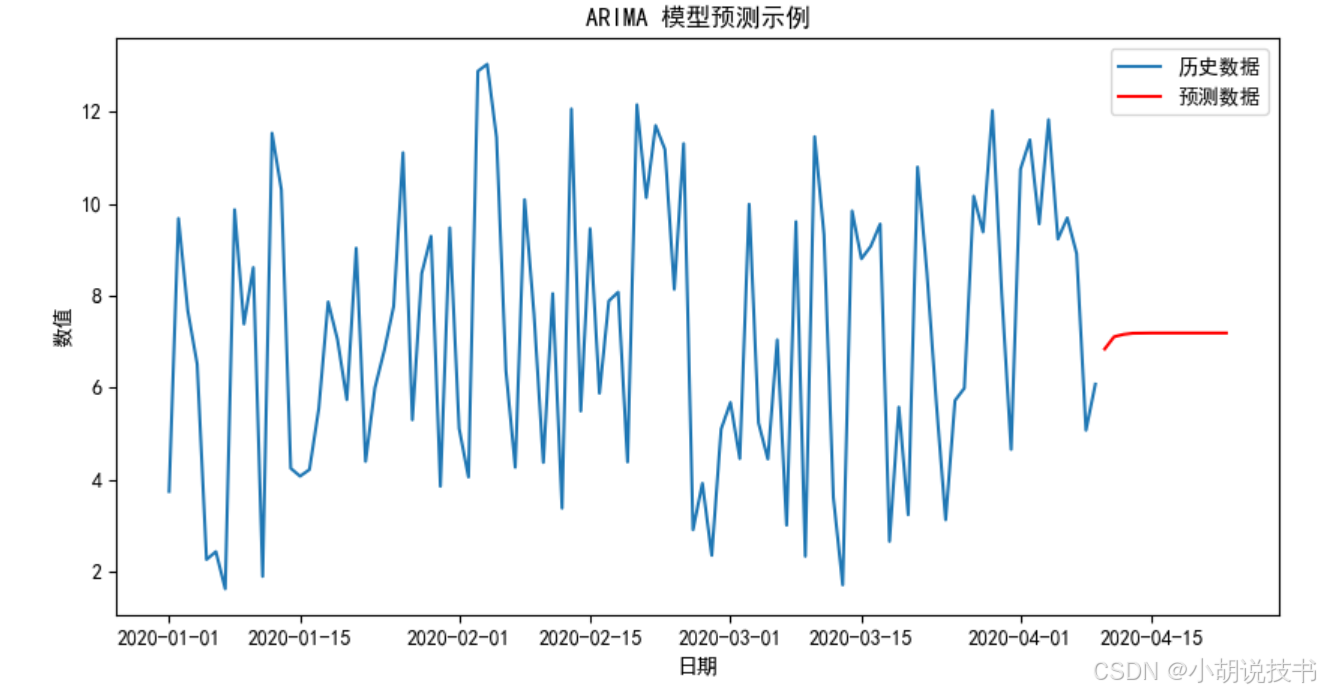
plt.title("ARIMA 模型预测示例")
plt.xlabel("日期")
plt.ylabel("数值")
plt.legend()
plt.show()
解析:
- ARIMA 模型中的参数
(p, d, q)分别代表自回归阶数、差分阶数和移动平均阶数,需要通过自相关图(ACF)与偏自相关图(PACF)确定。 - 模型摘要提供了参数统计检验和模型拟合指标,为进一步调优提供依据。
3.3 模型验证与评估指标
对于时间序列预测,模型验证和评估至关重要。常用的评估方法包括数据分割、对比基准方法(朴素预测)以及多种误差指标。
数据分割与基准模型
- 数据分割:将数据划分为训练集、验证集和测试集,确保模型在未见数据上具有良好表现。
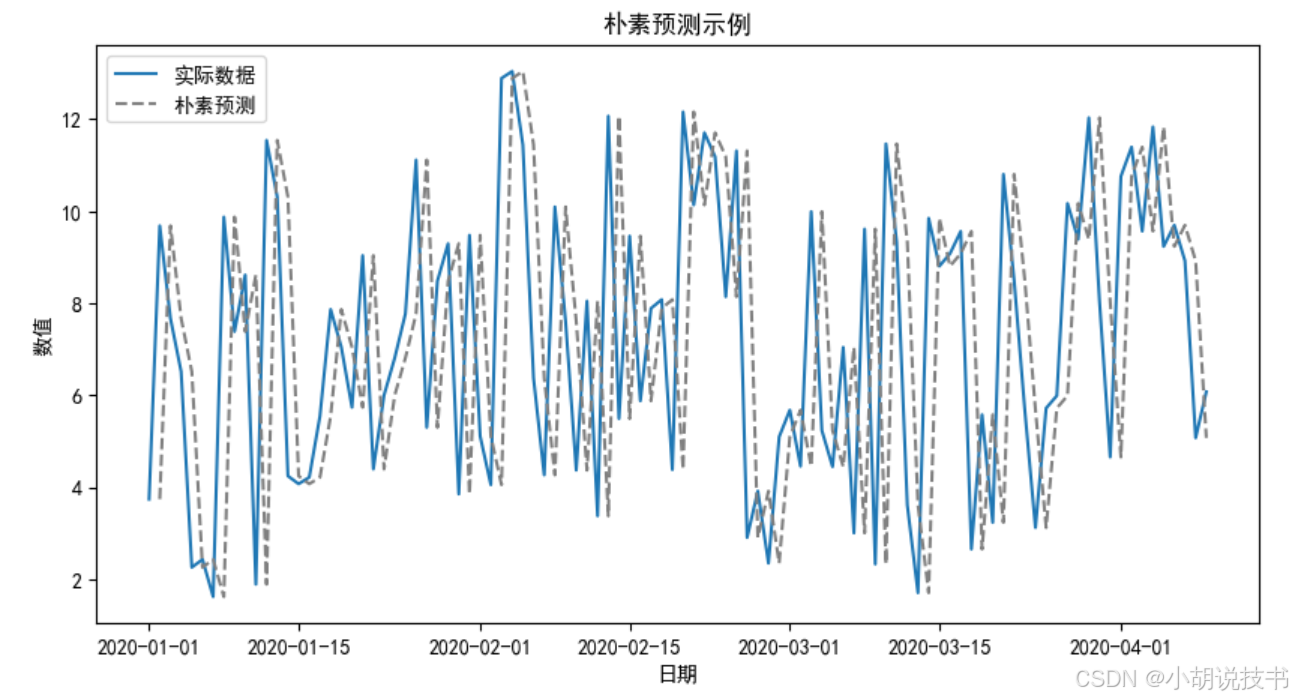
- 朴素预测:使用上一时刻数据作为预测值,作为基准模型比较 ARIMA 或其他复杂模型的改进效果。
实践示例:朴素预测对比
# 构造朴素预测模型(使用上一期的值作为预测)
naive_forecast = ts_hw.shift(1)
plt.figure(figsize=(10, 5))
plt.plot(ts_hw.index, ts_hw, label='实际数据')
plt.plot(naive_forecast.index, naive_forecast, label='朴素预测', color='gray', linestyle='--')
plt.title("朴素预测示例")
plt.xlabel("日期")
plt.ylabel("数值")
plt.legend()
plt.show()
评估指标
- 均方误差(MSE)、均方根误差(RMSE):衡量预测值与实际值差异的平方平均及其平方根。
- 平均绝对误差(MAE):平均绝对误差,受异常值影响较小。
- 平均绝对百分比误差(MAPE):以百分比衡量误差,更直观。
- R²(决定系数):评估模型解释目标变量方差的比例。
实践示例:误差指标计算
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 计算 ARIMA 模型预测与实际数据之间的误差(这里假设有测试集 ts_test)
# 为演示,我们使用 ts_hw 的后一部分作为测试集
split_index = int(len(ts_hw) * 0.8)
ts_train, ts_test = ts_hw[:split_index], ts_hw[split_index:]
model_arima = ARIMA(ts_train, order=(2, 1, 2))
arima_result = model_arima.fit()
forecast = arima_result.forecast(steps=len(ts_test))
mse = mean_squared_error(ts_test, forecast)
mae = mean_absolute_error(ts_test, forecast)
r2 = r2_score(ts_test, forecast)
print("均方误差 (MSE):", mse)
print("平均绝对误差 (MAE):", mae)
print("决定系数 (R²):", r2)
解析:
- 这些指标能够量化模型的预测精度,帮助我们在选择模型时进行权衡。
- 对比 ARIMA 与朴素预测的指标,可以直观评估模型改进效果。

四、 总结与展望
-
全面方法论:
- 时间序列分析是一项系统工程,涉及数据平滑、分解、模型构建及评估。
- 交叉验证、验证曲线和学习曲线在监督学习中同样适用于时序模型调优。
-
自动化与持续监控:
- 建议构建自动化的模型调优管道,将时间序列预测模型与数据治理平台结合,实时监控数据变化和模型表现。
- 随着业务数据和市场环境的不断变化,模型需要持续更新和再训练。
-
技术前沿:
- 未来,深度学习方法(如 LSTM、Transformer)在时间序列预测中的应用将进一步提升预测准确性,特别是在处理复杂非线性和多变量时序数据上。
- 结合传统方法与新兴算法,将形成更为强大的混合模型,为企业决策提供更稳健的支持。
-
个人观点:
- 在实际应用中,我认为模型评估必须结合业务场景。例如,在零售预测中,节假日、促销活动等因素会对销售数据产生突变,模型评估指标应充分反映这些实际情况。
- 同时,参数调优不是一次性的工作,而是一个迭代的过程,需要不断根据数据反馈调整策略,从而不断提升模型性能。
本文系统阐述了时间序列分析与预测的核心技术,从数据平滑、组件分解到回归趋势与 ARIMA 模型构建,再到模型验证和评估指标选择,形成了一个全面而科学的流程。在实际应用中,数据挖掘工程师应根据具体业务背景、数据特性以及外部环境,不断调整模型参数并进行持续监控。
希望本文能够为您在时间序列预测项目中提供全面的理论指导与实践示例,并激发您对更深层次模型优化的探索。欢迎在 Jupyter Notebook 中尝试所有代码示例,并根据业务需求进行扩展和改进。