import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.optim as optim
import warnings
warnings.filterwarnings("ignore")
features = pd.read_csv('F:/cv/4.第四章 深度学习框架PyTorch/第二,三章:神经网络实战分类与回归任务/神经网络实战分类与回归任务/temps.csv')
#看看数据长什么样子
features.head()
print('数据维度:', features.shape)
# 处理时间数据
import datetime
# 分别得到年,月,日
years = features['year']
months = features['month']
days = features['day']
# datetime格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
dates[:5]
# 准备画图
# 指定默认风格
plt.style.use('fivethirtyeight')
# 设置布局
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize = (10,10))
fig.autofmt_xdate(rotation = 45)
# 标签值
ax1.plot(dates, features['actual'])
ax1.set_xlabel(''); ax1.set_ylabel('Temperature'); ax1.set_title('Max Temp')
# 昨天
ax2.plot(dates, features['temp_1'])
ax2.set_xlabel(''); ax2.set_ylabel('Temperature'); ax2.set_title('Previous Max Temp')
# 前天
ax3.plot(dates, features['temp_2'])
ax3.set_xlabel('Date'); ax3.set_ylabel('Temperature'); ax3.set_title('Two Days Prior Max Temp')
# 我的逗逼朋友
ax4.plot(dates, features['friend'])
ax4.set_xlabel('Date'); ax4.set_ylabel('Temperature'); ax4.set_title('Friend Estimate')
plt.tight_layout(pad=2)
# 显示图形
plt.show()
# 独热编码
features = pd.get_dummies(features)
features.head(5)
# 标签
labels = np.array(features['actual'])
# 在特征中去掉标签
features= features.drop('actual', axis = 1)
# 名字单独保存一下,以备后患
feature_list = list(features.columns)
# 转换成合适的格式
features = np.array(features)
features.shape
from sklearn import preprocessing
input_features = preprocessing.StandardScaler().fit_transform(features)
input_features[0]
x = torch.tensor(input_features, dtype = float)
y = torch.tensor(labels, dtype = float)
# 权重参数初始化
weights = torch.randn((14, 128), dtype = float, requires_grad = True)
biases = torch.randn(128, dtype = float, requires_grad = True)
weights2 = torch.randn((128, 1), dtype = float, requires_grad = True)
biases2 = torch.randn(1, dtype = float, requires_grad = True)
learning_rate = 0.001
losses = []
for i in range(1000):
# 计算隐层
hidden = x.mm(weights) + biases
# 加入激活函数
hidden = torch.relu(hidden)
# 预测结果
predictions = hidden.mm(weights2) + biases2
# 通计算损失
loss = torch.mean((predictions - y) ** 2)
losses.append(loss.data.numpy())
# 打印损失值
if i % 100 == 0:
print('loss:', loss)
#返向传播计算
loss.backward()
#更新参数
weights.data.add_(- learning_rate * weights.grad.data)
biases.data.add_(- learning_rate * biases.grad.data)
weights2.data.add_(- learning_rate * weights2.grad.data)
biases2.data.add_(- learning_rate * biases2.grad.data)
# 每次迭代都得记得清空
weights.grad.data.zero_()
biases.grad.data.zero_()
weights2.grad.data.zero_()
biases2.grad.data.zero_()
input_size = input_features.shape[1]
hidden_size = 128
output_size = 1
batch_size = 16
my_nn = torch.nn.Sequential(
torch.nn.Linear(input_size, hidden_size),
torch.nn.Sigmoid(),
torch.nn.Linear(hidden_size, output_size),
)
cost = torch.nn.MSELoss(reduction='mean')
optimizer = torch.optim.Adam(my_nn.parameters(), lr = 0.001)
# 训练网络
losses = []
for i in range(1000):
batch_loss = []
# MINI-Batch方法来进行训练
for start in range(0, len(input_features), batch_size):
end = start + batch_size if start + batch_size < len(input_features) else len(input_features)
xx = torch.tensor(input_features[start:end], dtype = torch.float, requires_grad = True)
yy = torch.tensor(labels[start:end], dtype = torch.float, requires_grad = True)
prediction = my_nn(xx)
loss = cost(prediction, yy)
optimizer.zero_grad()
loss.backward(retain_graph=True)
optimizer.step()
batch_loss.append(loss.data.numpy())
# 打印损失
if i % 100==0:
losses.append(np.mean(batch_loss))
print(i, np.mean(batch_loss))
x = torch.tensor(input_features, dtype = torch.float)
predict = my_nn(x).data.numpy()
# 转换日期格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
# 创建一个表格来存日期和其对应的标签数值
true_data = pd.DataFrame(data = {'date': dates, 'actual': labels})
# 同理,再创建一个来存日期和其对应的模型预测值
months = features[:, feature_list.index('month')]
days = features[:, feature_list.index('day')]
years = features[:, feature_list.index('year')]
test_dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
test_dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in test_dates]
predictions_data = pd.DataFrame(data = {'date': test_dates, 'prediction': predict.reshape(-1)})
# 真实值
plt.plot(true_data['date'], true_data['actual'], 'b-', label = 'actual')
# 预测值
plt.plot(predictions_data['date'], predictions_data['prediction'], 'ro', label = 'prediction')
plt.xticks(rotation = 60);
plt.legend()
# 图名
plt.xlabel('Date'); plt.ylabel('Maximum Temperature (F)'); plt.title('Actual and Predicted Values');
plt.show()
详细解读
1
# 处理时间数据
import datetime
# 分别得到年,月,日
years = features['year']
months = features['month']
days = features['day']
# datetime格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]代码的主要功能是处理时间数据,将数据中的年、月、日信息合并成 datetime 对象。下面逐行解释:
导入模块
# 处理时间数据
import datetime
这行代码导入了 Python 标准库中的 datetime 模块,该模块提供了处理日期和时间的类和函数,后续用于创建和操作日期时间对象。
在 Python 中,datetime是一个内置模块,用于处理日期和时间相关的操作,提供了一系列类和方法来表示、操作和格式化日期和时间数据。datetime模块中常用的类主要有以下几个:
datetime.datetime类:表示日期和时间,包含年、月、日、时、分、秒和微秒等信息。可以通过它来创建日期时间对象,进行日期时间的计算、比较等操作。例如:
import datetime
# 创建一个datetime对象,表示当前日期和时间
now = datetime.datetime.now()
print(now)
# 创建一个指定日期和时间的datetime对象
specific_time = datetime.datetime(2024, 10, 1, 12, 30, 0)
print(specific_time)
datetime.date类:表示日期,只包含年、月、日信息。常用于处理与日期相关的操作,如获取当前日期、计算日期之间的差值等。例如:
import datetime
# 获取当前日期
today = datetime.date.today()
print(today)
# 创建一个指定日期的date对象
specific_date = datetime.date(2024, 10, 1)
print(specific_date)
datetime.time类:表示时间,包含时、分、秒和微秒信息。当只需要处理时间部分,不涉及日期时会用到这个类。例如:
import datetime
# 创建一个指定时间的time对象
specific_time = datetime.time(12, 30, 0)
print(specific_time)
datetime.timedelta类:表示时间间隔,用于计算两个日期或时间之间的差值,或者对日期时间进行加减操作。例如:
import datetime
# 创建一个时间间隔对象,表示1天
one_day = datetime.timedelta(days=1)
# 获取当前日期
today = datetime.date.today()
# 计算明天的日期
tomorrow = today + one_day
print(tomorrow)提取年、月、日信息
# 分别得到年,月,日
years = features['year']
months = features['month']
days = features['day']
这里假设 features 是一个 pandas 的 DataFrame 或者类似字典结构的对象。代码从 features 中提取 'year'、'month' 和 'day' 这三列的数据,分别赋值给 years、months 和 days 变量。
生成日期字符串列表
# datetime格式
dates = [str(int(year)) + '-' + str(int(month)) + '-' + str(int(day)) for year, month, day in zip(years, months, days)]
这是一个列表推导式,zip(years, months, days) 将 years、months 和 days 这三个可迭代对象中的元素一一对应组合。对于每一组年、月、日,先将其转换为整数,再转换为字符串,并用 - 连接成一个日期字符串,最终生成一个包含所有日期字符串的列表 dates。
转换为 datetime 对象列表
dates = [datetime.datetime.strptime(date, '%Y-%m-%d') for date in dates]
这也是一个列表推导式,datetime.datetime.strptime() 是 datetime 模块中的方法,用于将字符串按照指定的格式解析为 datetime 对象。'%Y-%m-%d' 是日期字符串的格式,其中 %Y 表示四位数的年份,%m 表示两位数的月份,%d 表示两位数的日期。最终将 dates 列表中的每个日期字符串都转换为 datetime 对象。
提高可读性和性能的建议
- 可读性:可以添加更多注释说明每一步的作用,尤其是列表推导式部分。也可以将复杂的列表推导式拆分成多个步骤,使代码更易读。
- 性能:如果
features是pandas的DataFrame,可以使用pandas自带的to_datetime方法,它在处理大量数据时性能更好。示例如下:
import pandas as pd
# 假设 features 是 pandas DataFrame
features['date'] = pd.to_datetime(features[['year', 'month', 'day']])
dates = features['date'].tolist()2
dates[:5]代码 dates[:5] 运用了 Python 列表(或者其他支持切片操作的序列类型,像元组、numpy 数组、pandas 的 Series 等)的切片功能。下面详细解释:
代码功能
dates是一个变量名,它应该代表一个序列对象,例如列表、元组等。结合前面的代码,dates大概率是一个包含datetime对象的列表,这些对象代表了一系列日期。[:5]是切片操作符。切片操作允许你从一个序列中提取出一部分元素。冒号:是切片的标志,[:5]表示从序列的起始位置(索引为 0)开始,一直取到索引为 4 的元素(索引从 0 开始计数,所以取前 5 个元素)。
示例
假设 dates 列表内容如下:
import datetime
dates = [
datetime.datetime(2023, 1, 1),
datetime.datetime(2023, 1, 2),
datetime.datetime(2023, 1, 3),
datetime.datetime(2023, 1, 4),
datetime.datetime(2023, 1, 5),
datetime.datetime(2023, 1, 6)
]
print(dates[:5])
输出结果会是 dates 列表的前 5 个元素:
[datetime.datetime(2023, 1, 1, 0, 0), datetime.datetime(2023, 1, 2, 0, 0), datetime.datetime(2023, 1, 3, 0, 0), datetime.datetime(2023, 1, 4, 0, 0), datetime.datetime(2023, 1, 5, 0, 0)]
dates[:5] 代码的作用是从 dates 序列里提取前 5 个元素,通常用于查看序列开头的部分数据,快速了解数据的结构和内容。
# 准备画图
# 指定默认风格
plt.style.use('fivethirtyeight')
# 设置布局
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize = (10,10))
fig.autofmt_xdate(rotation = 45)
# 标签值
ax1.plot(dates, features['actual'])
ax1.set_xlabel(''); ax1.set_ylabel('Temperature'); ax1.set_title('Max Temp')
# 昨天
ax2.plot(dates, features['temp_1'])
ax2.set_xlabel(''); ax2.set_ylabel('Temperature'); ax2.set_title('Previous Max Temp')
# 前天
ax3.plot(dates, features['temp_2'])
ax3.set_xlabel('Date'); ax3.set_ylabel('Temperature'); ax3.set_title('Two Days Prior Max Temp')
# 我的逗逼朋友
ax4.plot(dates, features['friend'])
ax4.set_xlabel('Date'); ax4.set_ylabel('Temperature'); ax4.set_title('Friend Estimate')
plt.tight_layout(pad=2)3
代码的主要功能是使用 matplotlib 库绘制一个包含四个子图的图表,用于展示不同气温相关数据随时间的变化情况。下面逐行解释代码中较复杂或新手不易理解的部分:
1. 绘图风格设置
# 指定默认风格
plt.style.use('fivethirtyeight')
plt.style.use()是matplotlib里用于设置绘图风格的函数。'fivethirtyeight'是一种预定义的绘图风格,它模仿了 FiveThirtyEight 网站文章里图表的样式,包含特定的颜色、线条样式和字体等。
2. 子图创建与布局设置
# 设置布局
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize = (10,10))
fig.autofmt_xdate(rotation = 45)
plt.subplots()函数用于创建一个包含多个子图的图表。nrows=2和ncols=2表明要创建一个 2 行 2 列的子图布局,总共 4 个子图。figsize = (10,10)则指定了整个图表的大小为宽 10 英寸、高 10 英寸。fig.autofmt_xdate(rotation = 45)会自动调整 x 轴日期标签的格式,并且将日期标签旋转 45 度,这样可以避免标签之间相互重叠。
3. 子图绘制与设置
# 标签值
ax1.plot(dates, features['actual'])
ax1.set_xlabel(''); ax1.set_ylabel('Temperature'); ax1.set_title('Max Temp')
ax1.plot(dates, features['actual']):ax1代表第一个子图的坐标轴对象,plot()方法用于在该子图上绘制折线图。dates是 x 轴的数据(通常是日期),features['actual']是 y 轴的数据(实际气温值)。ax1.set_xlabel('')、ax1.set_ylabel('Temperature')和ax1.set_title('Max Temp')分别用于设置子图的 x 轴标签(这里为空)、y 轴标签和标题。
4. 自动调整子图间距
plt.tight_layout(pad=2)
plt.tight_layout()函数会自动调整子图之间的间距,避免子图之间的内容相互重叠。pad=2指定了子图与图表边缘之间的间距为 2 个字体大小。
提高可读性和性能建议
- 可读性:
- 可以将子图的创建和设置封装成函数,减少代码重复。
- 为
dates和features变量添加注释,说明其数据来源和含义。
- 性能:当前代码主要是绘图操作,性能瓶颈通常不在于代码逻辑,而在于数据量。如果数据量非常大,可以考虑对数据进行采样后再绘图。
输出
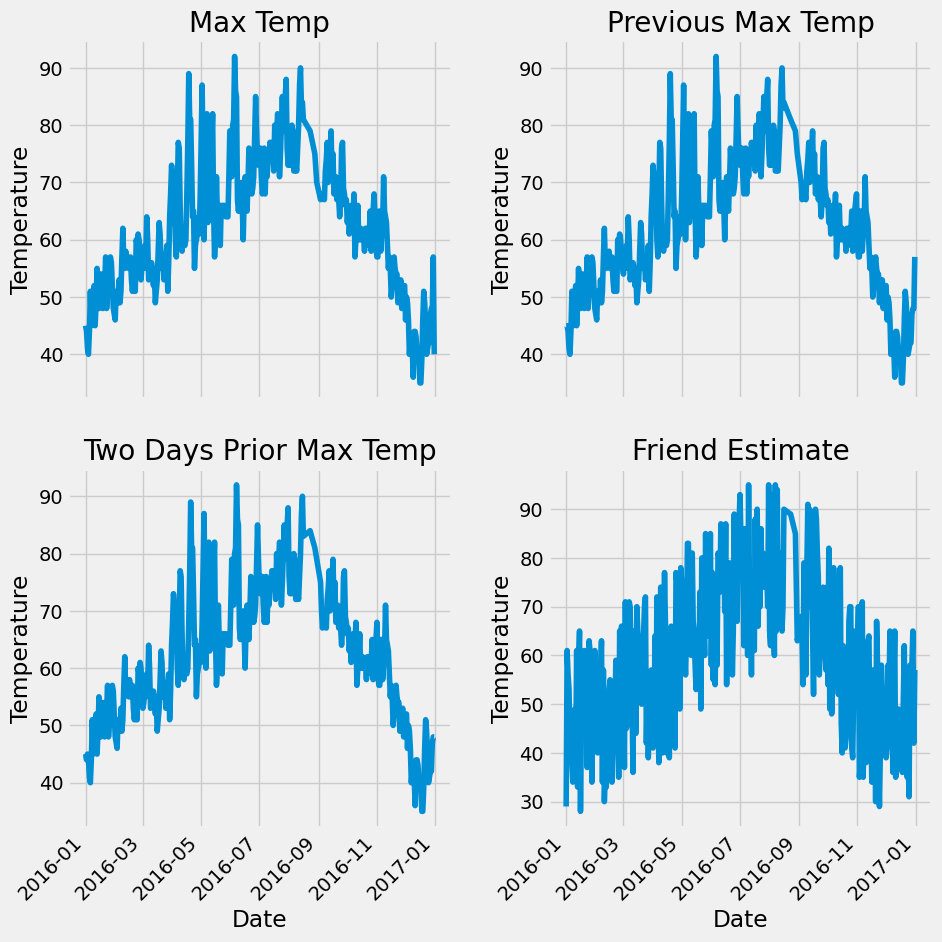
4
# 独热编码
features = pd.get_dummies(features)
features.head(5)代码主要完成了两个操作:对数据进行独热编码和查看编码后数据的前 5 行。下面详细解释每一行代码:
1. 独热编码操作
# 独热编码
features = pd.get_dummies(features)
- 注释:
# 独热编码表明这行代码的作用是对数据进行独热编码处理。 - 函数:
pd.get_dummies()是pandas库中的一个函数,用于将分类变量转换为独热编码(One-Hot Encoding)的形式。独热编码是一种将分类变量转换为二进制列的方法,每一列代表一个类别,当某个样本属于该类别时,对应列的值为 1,否则为 0。 - 变量:
features通常是一个pandas的DataFrame对象,包含了需要进行编码的分类特征。这行代码将features中的分类列进行独热编码,并将结果重新赋值给features变量。
独热编码(One - Hot Encoding)是一种常用的数据编码方式,主要用于将分类数据转换为机器可处理的数字形式。以下是其详细介绍:
原理
- 对于具有n个不同类别的分类变量,独热编码会创建一个长度为n的二进制向量来表示每个类别。在这个向量中,只有对应类别位置的元素为1,其余元素均为0。例如,对于 “颜色” 这个分类变量,有红、绿、蓝三种颜色,那么 “红色” 可以表示为[1,0,0],“绿色” 表示为[0,1,0],“蓝色” 表示为[0,0,1]。
作用
- 便于模型处理:许多机器学习和深度学习模型无法直接处理分类数据,需要将其转换为数字形式。独热编码提供了一种简单有效的方式,将分类数据转换为模型能够理解和处理的数值向量,有助于模型更好地学习和捕捉数据中的模式。
- 避免类别间的虚假排序:在一些编码方式中,可能会给类别赋予数字序号,这可能会导致模型认为类别之间存在某种顺序关系。而独热编码不会引入这种虚假的顺序信息,每个类别都是独立且平等的,能够更准确地反映数据的本质特征。
优缺点
- 优点:编码方式简单直接,能够清晰地表示类别信息,易于理解和实现。并且可以将离散的分类特征扩展到欧式空间,使得不同特征之间具有相同的度量标准,便于模型进行计算和比较。
- 缺点:当分类变量的类别数量较多时,独热编码会导致数据维度大幅增加,从而增加模型的计算量和存储空间。例如,对于一个有1000个不同类别的变量,独热编码后每个样本都将变成一个1000维的向量。这种维度灾难可能会导致模型训练速度变慢,甚至出现过拟合现象。
独热编码在数据预处理中是一种非常有用的技术,但在使用时需要根据具体情况权衡其优缺点,特别是在处理高维分类数据时,可能需要结合其他降维方法来优化数据表示。
2. 查看编码后数据的前 5 行
features.head(5)
- 函数:
head()是pandas的DataFrame对象的一个方法,用于返回DataFrame的前几行数据。默认情况下,head()会返回前 5 行,但这里显式指定了参数5,确保返回前 5 行数据。 - 作用:这行代码的作用是查看经过独热编码处理后的
features数据的前 5 行,方便开发者快速了解编码后的数据结构和内容。
提高可读性和性能的建议
- 可读性:可以在
features.head(5)这行代码后添加注释,说明其作用是查看编码后数据的前 5 行,增强代码的可读性。 - 性能:
pd.get_dummies()在处理大规模数据时可能会占用较多内存,因为它会为每个分类变量的每个类别创建一个新的列。如果数据量非常大,可以考虑使用更高效的编码方法,如scikit-learn中的OneHotEncoder,它支持稀疏矩阵输出,可以减少内存占用。
5
# 标签
labels = np.array(features['actual'])
# 在特征中去掉标签
features= features.drop('actual', axis = 1)
# 名字单独保存一下,以备后患
feature_list = list(features.columns)
# 转换成合适的格式
features = np.array(features)代码主要完成了机器学习数据预处理中的几个关键步骤:从特征数据里分离出标签、移除特征数据中的标签列、保存特征名称列表以及将特征数据转换为 numpy 数组。下面逐行解释:
1. 提取标签数据
# 标签
labels = np.array(features['actual'])
- 注释表明这行代码的目的是提取标签数据。
features通常是一个pandas的DataFrame对象,包含了特征和标签数据。features['actual']从features中选取名为'actual'的列,这一列数据被视为标签数据。np.array()函数将pandas的Series对象转换为numpy数组,方便后续在机器学习模型中使用。最终,labels变量存储了所有的标签数据。
2. 从特征数据中移除标签列
# 在特征中去掉标签
features= features.drop('actual', axis = 1)
- 注释说明这行代码的作用是从特征数据里移除标签列。
features.drop('actual', axis = 1)是pandas的DataFrame对象的drop方法,用于删除指定的列。'actual'是要删除的列名,axis = 1表示按列删除。删除操作后,features只包含特征数据。
3. 保存特征名称列表
# 名字单独保存一下,以备后患
feature_list = list(features.columns)
- 注释解释了保存特征名称列表的目的,可能在后续的特征分析、模型解释等环节会用到。
features.columns返回features这个DataFrame的所有列名,list()函数将这些列名转换为 Python 列表,存储在feature_list变量中。
4. 将特征数据转换为 numpy 数组
# 转换成合适的格式
features = np.array(features)
- 注释表明这行代码的作用是将特征数据转换为合适的格式。
np.array()函数将pandas的DataFrame对象features转换为numpy数组,方便后续在机器学习模型中使用。
提高可读性和性能的建议
- 可读性:代码已有基本注释,可以进一步说明
features和labels在机器学习流程中的作用,让代码更易理解。 - 性能:对于大规模数据,
pandas和numpy的转换可能会有一定性能开销。如果数据量很大,可以考虑直接使用numpy进行数据处理,减少数据格式转换。
6
from sklearn import preprocessing
input_features = preprocessing.StandardScaler().fit_transform(features)代码主要使用 scikit-learn 库中的 preprocessing 模块对特征数据进行标准化处理,下面详细解释每一部分:
1. 导入 preprocessing 模块
from sklearn import preprocessing
这行代码从 scikit-learn 库中导入 preprocessing 模块。scikit-learn 是一个强大的机器学习库,而 preprocessing 模块提供了多种数据预处理功能,例如数据标准化、归一化、编码等。
2. 数据标准化处理
input_features = preprocessing.StandardScaler().fit_transform(features)
这行代码包含了两个主要步骤:
创建 StandardScaler 对象
preprocessing.StandardScaler() 创建了一个 StandardScaler 类的实例。StandardScaler 是用于数据标准化的类,其标准化的原理是将数据转换为均值为 0,标准差为 1 的标准正态分布。公式: ,其中,(x) 是原始数据,(
) 是数据的均值,(
) 是数据的标准差,(z) 是标准化后的数据。
拟合数据并进行转换
fit_transform(features) 方法完成了两个操作:
fit:计算输入数据features的均值和标准差,这些统计量会被存储在StandardScaler实例中,用于后续的转换操作。transform:使用计算得到的均值和标准差对输入数据features进行标准化处理,将处理后的数据赋值给input_features。
总结
这段代码的目的是对输入的特征数据 features 进行标准化处理,使得处理后的数据具有零均值和单位方差,有助于提高某些机器学习算法(如线性回归、神经网络等)的性能和收敛速度。
提高可读性和性能的建议
- 可读性:可以添加注释说明数据标准化的目的和
StandardScaler的作用,让代码更易理解。 - 性能:如果数据量非常大,可以考虑使用
partial_fit方法分批计算均值和标准差,减少内存占用。
7
x = torch.tensor(input_features, dtype = float)
y = torch.tensor(labels, dtype = float)
# 权重参数初始化
weights = torch.randn((14, 128), dtype = float, requires_grad = True)
biases = torch.randn(128, dtype = float, requires_grad = True)
weights2 = torch.randn((128, 1), dtype = float, requires_grad = True)
biases2 = torch.randn(1, dtype = float, requires_grad = True)
learning_rate = 0.001
losses = []
for i in range(1000):
# 计算隐层
hidden = x.mm(weights) + biases
# 加入激活函数
hidden = torch.relu(hidden)
# 预测结果
predictions = hidden.mm(weights2) + biases2
# 通计算损失
loss = torch.mean((predictions - y) ** 2)
losses.append(loss.data.numpy())
# 打印损失值
if i % 100 == 0:
print('loss:', loss)
#返向传播计算
loss.backward()
#更新参数
weights.data.add_(- learning_rate * weights.grad.data)
biases.data.add_(- learning_rate * biases.grad.data)
weights2.data.add_(- learning_rate * weights2.grad.data)
biases2.data.add_(- learning_rate * biases2.grad.data)
# 每次迭代都得记得清空
weights.grad.data.zero_()
biases.grad.data.zero_()
weights2.grad.data.zero_()
biases2.grad.data.zero_()
代码使用 PyTorch 构建了一个简单的两层神经网络来进行气温预测,下面逐部分解释代码:
1. 数据转换为 PyTorch 张量
x = torch.tensor(input_features, dtype = float)
y = torch.tensor(labels, dtype = float)
input_features是经过预处理的特征数据,labels是对应的真实标签数据。torch.tensor()函数将input_features和labels转换为 PyTorch 张量,dtype = float指定张量的数据类型为浮点型。
2. 初始化权重和偏置
weights = torch.randn((14, 128), dtype = float, requires_grad = True)
biases = torch.randn(128, dtype = float, requires_grad = True)
weights2 = torch.randn((128, 1), dtype = float, requires_grad = True)
biases2 = torch.randn(1, dtype = float, requires_grad = True)
torch.randn()函数用于生成服从标准正态分布的随机数。weights是输入层到隐藏层的权重矩阵,形状为(14, 128),表示输入有 14 个特征,隐藏层有 128 个神经元。biases是隐藏层的偏置向量,长度为 128。weights2是隐藏层到输出层的权重矩阵,形状为(128, 1),表示输出层有 1 个神经元。biases2是输出层的偏置向量,长度为 1。requires_grad = True表示这些张量需要计算梯度,以便后续进行反向传播更新参数。
3. 设置学习率和初始化损失列表
learning_rate = 0.001
losses = []
learning_rate是学习率,控制每次参数更新的步长。losses是一个空列表,用于存储每次迭代的损失值。
4. 训练循环
for i in range(1000):
- 代码将进行 1000 次迭代训练模型。
5. 前向传播
# 计算隐层
hidden = x.mm(weights) + biases
# 加入激活函数
hidden = torch.relu(hidden)
# 预测结果
predictions = hidden.mm(weights2) + biases2
x.mm(weights)进行矩阵乘法,计算输入层到隐藏层的线性组合,然后加上偏置biases得到隐藏层的输出。torch.relu()是激活函数,将隐藏层的输出进行非线性变换。hidden.mm(weights2) + biases2计算隐藏层到输出层的线性组合,得到最终的预测结果predictions。
6. 计算损失
# 通计算损失
loss = torch.mean((predictions - y) ** 2)
losses.append(loss.data.numpy())
- 使用均方误差(MSE)作为损失函数,计算预测值
predictions与真实标签y之间的误差平方的平均值。 loss.data.numpy()将损失值转换为 NumPy 数组,并添加到losses列表中。
7. 打印损失值
# 打印损失值
if i % 100 == 0:
print('loss:', loss)
- 每 100 次迭代打印一次当前的损失值,方便观察模型的训练过程。
8. 反向传播
#返向传播计算
loss.backward()
loss.backward()调用 PyTorch 的自动求导机制,计算损失函数关于所有需要梯度的张量(即weights、biases、weights2和biases2)的梯度。
9. 更新参数
#更新参数
weights.data.add_(- learning_rate * weights.grad.data)
biases.data.add_(- learning_rate * biases.grad.data)
weights2.data.add_(- learning_rate * weights2.grad.data)
biases2.data.add_(- learning_rate * biases2.grad.data)
- 使用梯度下降法更新参数,
weights.grad.data是weights的梯度,- learning_rate * weights.grad.data表示参数更新的步长。 .add_()是 PyTorch 的原地操作函数,直接在原张量上进行更新。
10. 梯度清零
# 每次迭代都得记得清空
weights.grad.data.zero_()
biases.grad.data.zero_()
weights2.grad.data.zero_()
biases2.grad.data.zero_()
- 每次迭代结束后,需要将梯度清零,避免梯度累积影响下一次迭代的参数更新。
.zero_()是原地操作函数,将梯度张量的值全部置为 0。
提高可读性和性能的建议
- 可读性:可以将网络结构封装成
torch.nn.Module的子类,将前向传播逻辑封装在forward方法中,这样代码结构会更清晰。 - 性能:可以使用 PyTorch 提供的优化器(如
torch.optim.SGD)来更新参数,避免手动更新参数的繁琐过程。同时,使用 GPU 进行训练可以显著提高训练速度。
算法框架
算法的神经网络结构见资源绑定
8 更简单的构建网络模型
input_size = input_features.shape[1]
hidden_size = 128
output_size = 1
batch_size = 16
my_nn = torch.nn.Sequential(
torch.nn.Linear(input_size, hidden_size),
torch.nn.Sigmoid(),
torch.nn.Linear(hidden_size, output_size),
)
cost = torch.nn.MSELoss(reduction='mean')
optimizer = torch.optim.Adam(my_nn.parameters(), lr = 0.001)代码主要完成了一个简单神经网络的定义、损失函数的选择以及优化器的配置,下面详细解释每一部分:
1. 确定网络参数
input_size = input_features.shape[1]
hidden_size = 128
output_size = 1
batch_size = 16
input_size = input_features.shape[1]:input_features应该是一个二维数组(如numpy数组或torch.Tensor),shape[1]表示取其第二维的大小,也就是输入特征的数量,将其赋值给input_size,作为神经网络输入层的神经元数量。hidden_size = 128:定义隐藏层的神经元数量为 128。output_size = 1:定义输出层的神经元数量为 1,通常用于回归任务中输出一个预测值。batch_size = 16:定义训练时每次处理的样本数量为 16,但此变量在当前代码中未被使用。
2. 定义神经网络
my_nn = torch.nn.Sequential(
torch.nn.Linear(input_size, hidden_size),
torch.nn.Sigmoid(),
torch.nn.Linear(hidden_size, output_size),
)
torch.nn.Sequential:这是一个容器类,用于按顺序堆叠神经网络的各层。torch.nn.Linear(input_size, hidden_size):创建一个全连接层,输入维度为input_size,输出维度为hidden_size,会自动初始化权重和偏置。torch.nn.Sigmoid():添加一个 Sigmoid 激活函数,将隐藏层的输出进行非线性变换,将值映射到(0, 1)区间。torch.nn.Linear(hidden_size, output_size):创建另一个全连接层,将隐藏层的输出映射到输出层,输出维度为output_size。
3. 选择损失函数
cost = torch.nn.MSELoss(reduction='mean')
torch.nn.MSELoss:均方误差损失函数,常用于回归任务。它计算预测值和真实值之间误差的平方的平均值。reduction='mean':指定损失的计算方式为求平均值,即对所有样本的损失求平均。
4. 选择优化器
optimizer = torch.optim.Adam(my_nn.parameters(), lr = 0.001)
torch.optim.Adam:Adam 优化器,是一种自适应学习率的优化算法,结合了 AdaGrad 和 RMSProp 的优点。my_nn.parameters():传入神经网络的所有可训练参数,让优化器知道需要更新哪些参数。lr = 0.001:设置学习率为 0.001,控制每次参数更新的步长。
提高可读性和性能建议
- 可读性:可以为每一步操作添加详细注释,解释代码的功能和目的。也可以将神经网络的定义封装成一个类,继承
torch.nn.Module,这样结构会更清晰。 - 性能:Sigmoid 函数在输入值较大或较小时容易出现梯度消失问题,可以考虑使用 ReLU 等其他激活函数。
9
# 训练网络
losses = []
for i in range(1000):
batch_loss = []
# MINI-Batch方法来进行训练
for start in range(0, len(input_features), batch_size):
end = start + batch_size if start + batch_size < len(input_features) else len(input_features)
xx = torch.tensor(input_features[start:end], dtype = torch.float, requires_grad = True)
yy = torch.tensor(labels[start:end], dtype = torch.float, requires_grad = True)
prediction = my_nn(xx)
loss = cost(prediction, yy)
optimizer.zero_grad()
loss.backward(retain_graph=True)
optimizer.step()
batch_loss.append(loss.data.numpy())
# 打印损失
if i % 100==0:
losses.append(np.mean(batch_loss))
print(i, np.mean(batch_loss))代码的核心功能是使用 MINI - Batch 方法训练一个 PyTorch 神经网络,并记录和打印训练过程中的损失值。以下是逐行详细解释:
初始化损失列表
# 训练网络
losses = []
创建一个空列表 losses,用于存储每 100 次迭代的平均损失值,方便后续分析训练过程中的损失变化。
外层迭代循环
for i in range(1000):
batch_loss = []
for i in range(1000):设定训练的总迭代次数为 1000 次。batch_loss = []:每次迭代开始时,创建一个空列表batch_loss,用于存储当前迭代中每个小批量的损失值。
MINI - Batch 训练循环
# MINI-Batch方法来进行训练
for start in range(0, len(input_features), batch_size):
end = start + batch_size if start + batch_size < len(input_features) else len(input_features)
for start in range(0, len(input_features), batch_size):使用range函数生成一系列起始索引,以batch_size为步长,遍历整个输入特征数据集。end = start + batch_size if start + batch_size < len(input_features) else len(input_features):确定每个小批量数据的结束索引,确保最后一个小批量不会超出数据集的范围。
数据转换为张量
xx = torch.tensor(input_features[start:end], dtype = torch.float, requires_grad = True)
yy = torch.tensor(labels[start:end], dtype = torch.float, requires_grad = True)
xx和yy分别将当前小批量的输入特征和标签数据转换为torch.Tensor类型,数据类型为torch.float,并设置requires_grad = True以允许在反向传播时计算梯度。不过对于标签数据,通常不需要计算梯度,可将yy的requires_grad设置为False。
前向传播
prediction = my_nn(xx)
调用之前定义好的神经网络 my_nn,对当前小批量的输入数据 xx 进行前向传播,得到预测结果 prediction。
计算损失
loss = cost(prediction, yy)
使用之前定义好的损失函数 cost 计算预测结果 prediction 与真实标签 yy 之间的损失值。
梯度清零
optimizer.zero_grad()
调用优化器的 zero_grad() 方法,将神经网络中所有可训练参数的梯度清零。因为 PyTorch 会累积梯度,所以在每次反向传播之前需要手动清零。
反向传播
loss.backward(retain_graph=True)
调用 loss.backward() 方法进行反向传播,计算损失函数关于神经网络中所有可训练参数的梯度。retain_graph=True 表示保留计算图,一般在多次反向传播共享计算图时使用,但在这个场景下通常不需要,可移除该参数。
参数更新
optimizer.step()
调用优化器的 step() 方法,根据计算得到的梯度更新神经网络的可训练参数。
记录小批量损失
batch_loss.append(loss.data.numpy())
将当前小批量的损失值转换为 NumPy 数组,并添加到 batch_loss 列表中。
打印和记录平均损失
# 打印损失
if i % 100==0:
losses.append(np.mean(batch_loss))
print(i, np.mean(batch_loss))
if i % 100==0::每 100 次迭代执行一次以下操作。losses.append(np.mean(batch_loss)):计算当前迭代中所有小批量损失值的平均值,并添加到losses列表中。print(i, np.mean(batch_loss)):打印当前迭代次数和平均损失值,方便观察训练过程。
优化建议
- 对于标签数据
yy,将requires_grad设置为False,避免不必要的梯度计算。 - 移除
loss.backward()中的retain_graph=True参数,减少内存消耗。
10
# 真实值
plt.plot(true_data['date'], true_data['actual'], 'b-', label = 'actual')
# 预测值
plt.plot(predictions_data['date'], predictions_data['prediction'], 'ro', label = 'prediction')
plt.xticks(rotation = 60);
plt.legend()
# 图名
plt.xlabel('Date'); plt.ylabel('Maximum Temperature (F)'); plt.title('Actual and Predicted Values');代码使用 matplotlib 库绘制图表,用于对比真实值和预测值随日期的变化情况。下面逐行解释:
1. 绘制真实值曲线
# 真实值
plt.plot(true_data['date'], true_data['actual'], 'b-', label = 'actual')
plt.plot()是matplotlib.pyplot模块里用于绘制折线图的函数。true_data['date']作为 x 轴数据,代表日期,true_data是一个pandas的DataFrame对象。true_data['actual']作为 y 轴数据,代表真实的最高温度值。'b-'是格式字符串,b表示蓝色(blue),-表示绘制实线。label = 'actual'为这条曲线设置图例标签,后续调用plt.legend()时会显示该标签。
2. 绘制预测值散点图
# 预测值
plt.plot(predictions_data['date'], predictions_data['prediction'], 'ro', label = 'prediction')
- 同样使用
plt.plot()函数,predictions_data['date']作为 x 轴数据,predictions_data['prediction']作为 y 轴数据,predictions_data也是一个pandas的DataFrame对象。 'ro'是格式字符串,r表示红色(red),o表示绘制圆形散点。label = 'prediction'为这些散点设置图例标签。
3. 旋转 x 轴刻度标签
plt.xticks(rotation = 60);
plt.xticks()函数用于设置 x 轴刻度的属性。rotation = 60表示将 x 轴刻度标签(日期)逆时针旋转 60 度,这样在日期较多时可以避免标签之间相互重叠。
4. 显示图例
plt.legend()
plt.legend()函数用于在图表中显示图例,图例包含前面为曲线和散点设置的标签('actual'和'prediction'),方便用户区分不同的数据系列。
5. 设置图表标题和坐标轴标签
plt.xlabel('Date'); plt.ylabel('Maximum Temperature (F)'); plt.title('Actual and Predicted Values');
plt.xlabel('Date'):为 x 轴设置标签,标签内容为'Date',表明 x 轴代表日期。plt.ylabel('Maximum Temperature (F)'):为 y 轴设置标签,标签内容为'Maximum Temperature (F)',表明 y 轴代表华氏最高温度。plt.title('Actual and Predicted Values'):为图表设置标题,标题内容为'Actual and Predicted Values',表明图表展示的是真实值和预测值的对比。
输出
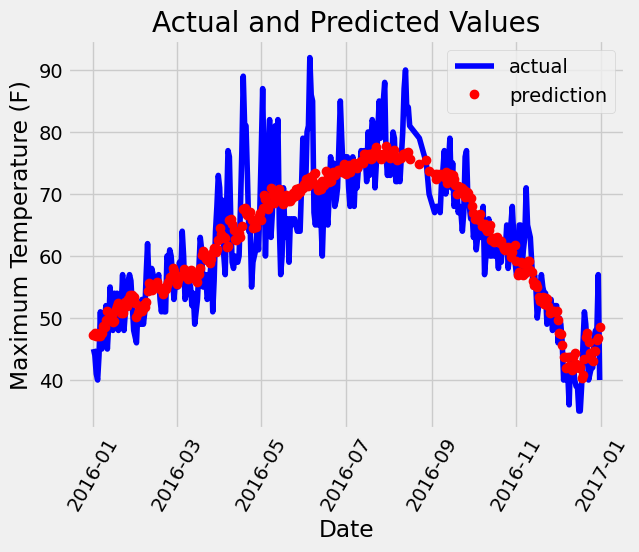
总结
这段代码实现了一个基于 PyTorch 的神经网络回归模型,用于预测温度,具体功能如下:
- 数据读取与预处理:从 CSV 文件中读取温度相关数据,将日期数据处理为
datetime格式,对分类特征进行独热编码,将特征和标签分别提取出来,并对特征进行标准化处理,转换为 PyTorch 的张量格式1。 - 模型构建与训练(手动实现):手动初始化神经网络的权重和偏置,定义学习率和损失列表。通过循环进行 1000 次迭代训练,在每次迭代中,计算隐层输出和预测结果,使用均方误差损失函数计算损失,进行反向传播更新权重和偏置,并在每次迭代后清空梯度。
- 模型构建与训练(使用
nn.Sequential):使用torch.nn.Sequential构建包含线性层和激活函数的神经网络模型,定义均方误差损失函数和 Adam 优化器。通过循环进行 1000 次迭代训练,采用 Mini - Batch 方法,每次从数据中选取一个小批量数据进行训练,计算损失、反向传播和更新参数1。 - 模型预测与结果可视化:使用训练好的模型对全部数据进行预测,将预测结果和真实值分别整理成 DataFrame 格式,绘制折线图对比实际温度和预测温度,直观展示模型的预测效果。