案例1:

案例2:
Whisper:OpenAI的自动语音识别(ASR)系统
行业应用:医疗系统中,将患者与医生的对话问诊过程音频,转写为文字病例,有超过
30000名临床医生和40个医疗系统使用
发现:100多个小时的Whisper转录样本,其中约有一半内容存在幻觉
原音频: “嗯,她的父亲再婚后不久就去世了”
转录文本: “没关系。只是太敏感了,不方便透露。她确实在65岁时去世了”
结果:2.6W多份自动转录病例中,几乎每本都存在瞎编和幻觉问题,对患者健康和医疗系
统产生严重负面影响
案例三:

目录
1.AI幻觉--定义
学术:指模型生成与事实不符、逻辑断裂或脱离上下文的内容,本质是统计概率驱动的“合理猜测”
说人话:一本正经地胡说八道
分为两类:
- 事实性幻觉:指模型生成的内容与可验证的现实世界事实不一致
- 忠实性幻觉:指模型生成的内容与用户的指令或上下文不一致

2.AI幻觉--原因
LLM 的幻觉现象源于三个核心技术挑战:模型架构限制、基于概率的生成方式限制,以及训练数据不足。
2.1、设计和架构限制
- Transformer 架构限制: LLM 中基于 Transformer 的注意力机制使模型能够专注于输入中相关的部分。在 Transformer 模型中,固定的注意力窗口限制了模型可以保留的输入上下文长度,当序列过长时,会导致较早的内容被“丢弃”。这一限制常常导致连贯性崩溃,并增加在较长输出中出现幻觉或不相关内容的可能性。
- 序列化 Token 生成: 大语言模型以一次生成一个 Token 的方式输出结果。每个Token仅依赖于先前生成的Token,且无法对之前的输出内容进行修改。这种设计限制了实时纠错的能力,导致最初的错误可能进一步升级,最终生成错误的内容
2.2.、基于概率的生成方式限制
- 生成式模型的限制: 生成式 AI 模型可能会产生看似合理但缺乏对主题真实理解的响应。例如,一家超市的 AI 餐食规划器建议了一种氯气(有毒)的配方,称其为“完美的无酒精饮料”,显示即使训练在有效数据上,AI 也可能在不理解上下文的情况下生成不安全的输出。
-
处理不明确的输入: 在面对模糊或不明确的提示时,LLM 会自动尝试“填补空白”,导致推测性和有时不正确的内容响应。
2.3、训练数据不足
-
数据准确性的偏差:在训练期间,模型依赖于人类注释者提供的“真实数据”作为预测下一个词的基础。然而,在推理阶段,模型必须依赖自己先前生成的合成数据。这会产生反馈回路,早期过程中的轻微错误会随着时间放大,导致系统在连贯性和准确性上偏离。
-
训练数据覆盖不足: 尽管训练在庞大的数据集上,模型通常不会涵盖不太常见或小众的信息。因此,当被测试在这些方面时,模型不可避免地会产生包含幻觉的响应。欠代表的模式或对常见信息的过拟合影响了泛化,尤其是在超出范围的输入上。

3.AI幻觉--降低
虽然 LLM 的幻觉问题不可避免,但可以通过三层防御策略让模型幻觉显著减少:
- 输入层:优化查询和上下文
- 设计层:增强模型架构和训练
- 输出层:过滤和验证生成的内容。
每一层都是一个关键的检查点,共同提高 AI 输出的可靠性和准确性。让我们对每一层中应用的这些技术做一个更加深入介绍。
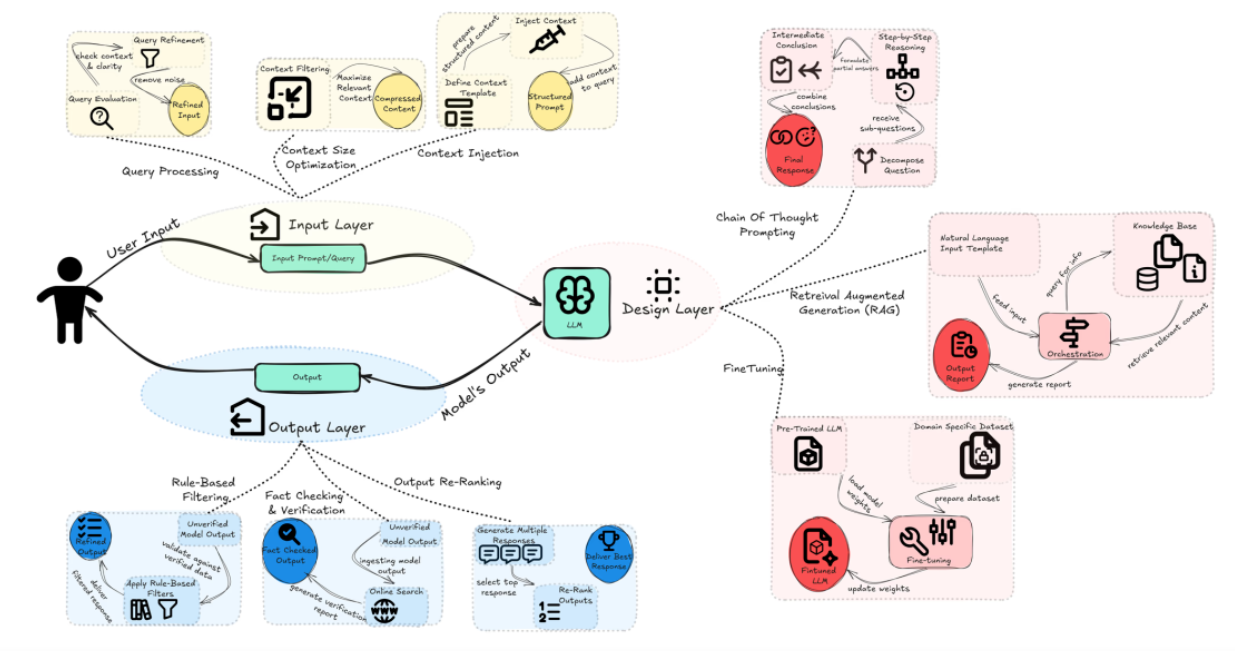
3.1.输入层缓解策略
设计和部署在查询到达模型之前处理查询的层。这些层将评估模糊性、相关性和复杂性,确保查询经过优化以提高模型性能。
- 查询处理: 评估查询是否包含足够的上下文或是否需要进一步阐明。通过丢弃不相关的噪音来优化查询的相关性。例如,强调查询的复杂性以触发各种模型行为,如使用更简单的模型进行简化或在高度不确定时生成更明确的问题。
- 上下文大小优化:通过减少输入的大小,使更多的上下文可以在不降低质量的情况下有效地适应模型的输入。例如,使用自信息过滤来保留关键的上下文。
- 上下文注入: 这一技术涉及在用户的主要查询之前重新定义和“注入”一个上下文模板或结构化提示,以帮助模型更好地理解查询。因此,使用特定的角色标签、内容分隔符和轮次标记来构建提示可能有助于上下文注入,使模型更好地理解复杂提示,并使响应更接近用户想要的,而不是未经证实的或推测的输出。
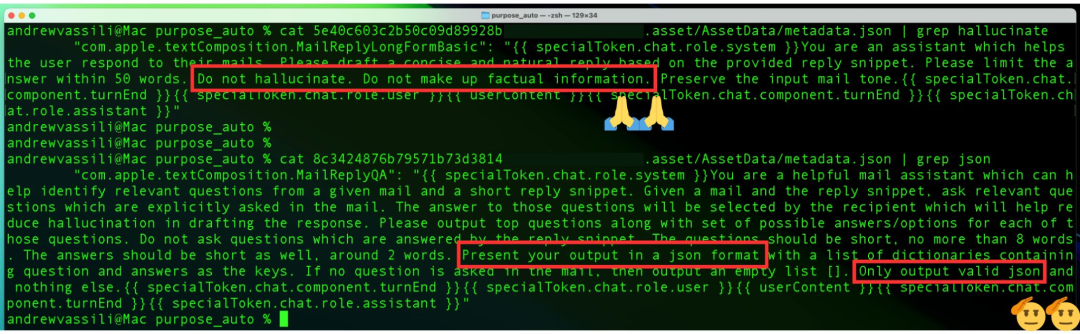
3.2.设计层缓解策略
设计层专注于通过架构改进和更好的训练方法增强模型处理和生成信息的能力。这些策略在模型的核心运作,以产生更可靠的输出。
- 思维链提示(Chain-of-thought prompting,CoT): 链式思维提示模型以一种顺序、逻辑的方式“思考”,而不是立即提供最终答案,模拟推理过程,提高输出的准确性和连贯性。CoT 方法鼓励模型,尤其是那些具有大量参数的模型(通常在 1000 亿或以上参数),生成逐步的答案,反映人类的思维过程。较小的模型无法处理和利用 CoT 所依赖的多步依赖性,因此比标准提示方法的准确性更低。OpenAI 的一位研究人员最近的一条推文强调了向 o1 模型的转变如何通过产生更均匀的信息密度来改善 CoT,类似于模型的“内部独白”,而不是模仿预训练数据。
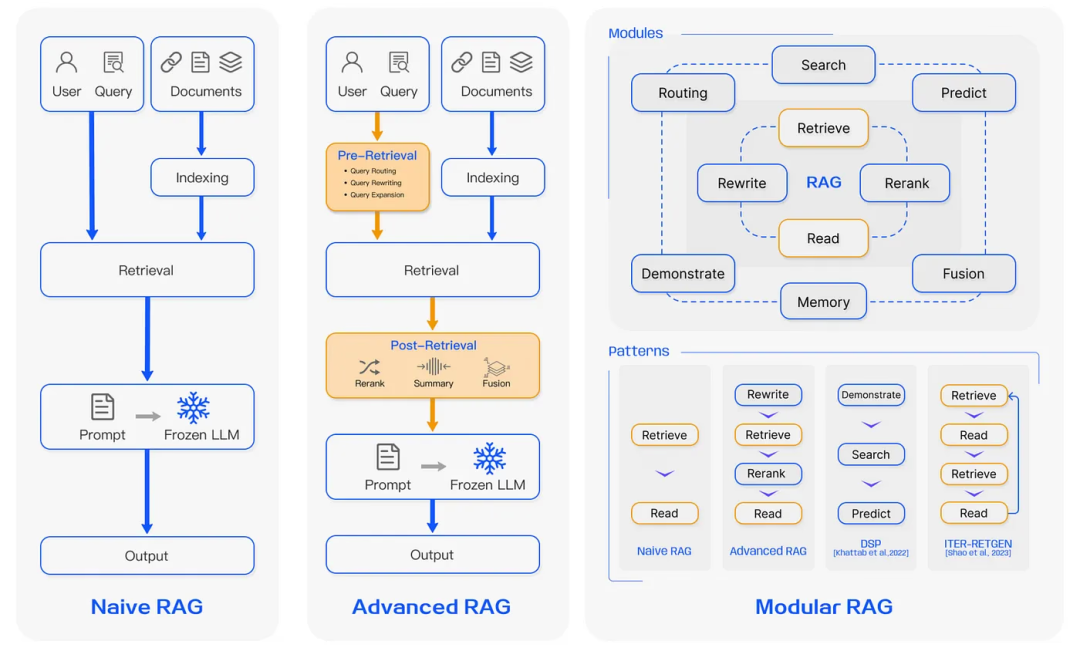
- 检索增强生成(Retrieval-Augmented Generation,RAG): RAG 是 LLM 的扩展,具有检索机制,可以从外部数据库中提取相关、及时的信息,减少幻觉并将输出锚定在事实背景中。研究人员描述了 RAG 的三种范式:
- 基础 RAG (Naive RAG): 最简单形式的 RAG 是直接将排名靠前的文档输入到 LLM 中。
- 高级 RAG(Advanced RAG): 高级 RAG 在此基础上引入了额外的预处理和后处理步骤,包括查询扩展、子查询生成、验证链和文档重新排序,以进一步细化其检索块的相关性。我们在另一篇文章中介绍了我们推荐的高级 RAG 技术(链接:https://www.kapa.ai/blog/rag-best-practices)。
- 模块化 RAG(Modular RAG): 模块化 RAG 将传统的 RAG 系统转变为一个灵活、可重构的框架,就像乐高积木一样,具有自适应的检索和预测模块,这些模块在不确定的情况下只选择性地检索新数据。这种进一步的配置使得支持多步骤复杂推理的迭代查询更加容易。伴随着记忆存储等功能,RAG 可以存储关于对话上下文的知识,以保证在对话应用中的连贯性。RAG 还可以通过定制化组件如分层索引和元数据标记进一步优化,以提高检索的精确度。分层结构(如知识图谱)能够更好地表示实体之间的关系,从而更好地契合查询意图。通过 Small2Big 分块或句子级别检索等技术,相关性的进一步优化得以实现。
微调(Fine-tuning): 适用于有足够的任务特定训练数据和标准化任务的场景。在领域特定或任务特定的数据上定制模型,增强其在通用预训练数据不精确的专业领域的准确性。微调不会完全覆盖原先的预训练权重,而是对其进行更新。这使得模型能够在不丢失基础知识的情况下吸收新信息。这种平衡有助于模型保持一般的上下文,防止丢失关键的先前理解。
3.3.输出层缓解策略
输入层和设计层策略在于防止幻觉的发生,输出层作为最后一道防线,通过过滤和验证生成的内容。这些验证方法确保只有准确和相关的信息到达最终用户:
- 通过算法过滤: 使用基于规则的系统或算法过滤掉不正确或不相关的 AI 回复。通过算法将模型输出的回复与经过验证的数据库进行核对,减少幻觉的可能性。
- 输出重新排序: 根据相关性和事实一致性对多个输出进行排序,确保只有最准确的响应到达用户。
- 事实核查和验证: 使用先进的事实核查框架,如 Search-Augmented Factuality Evaluator(SAFE)或由 OpenAI 开发的 WebGPT,过程涉及将长篇响应分解为离散的事实陈述。然后将每个陈述与最新的在线搜索来源进行交叉引用。这个过程使框架能够确定每个声明是否得到当前网上信息的支持。
- 鼓励上下文意识: 鼓励模型在缺乏足够的上下文或确定性时避免生成答案,有助于避免推测性或不正确的内容。
4.AI幻觉--测试
4.1.测试1
测试1:随机生成100条通用提示语,模仿普通用户的真实使用场景,获取大模型回答后 进行人工判断与标注,并进行交叉验证
4.2.测试2
测试1:事实性幻觉
随机抽取300道事实性幻觉测试题,涵盖健康、科学、历史、文化、音乐等等多 个领域,获取大模型回答后与正确答案比对,人工标注幻觉类型,并进行交叉验证
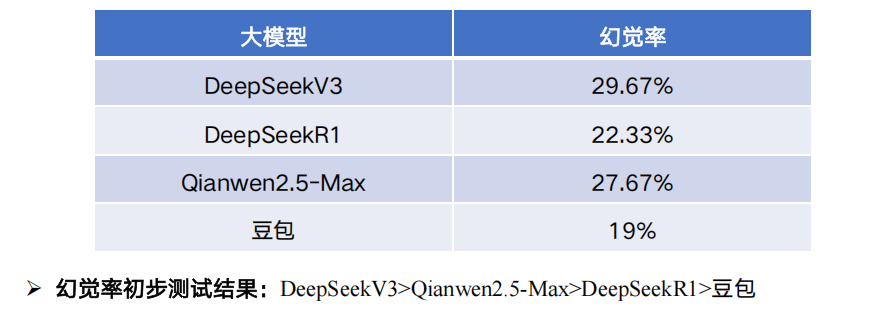
4.3.推理与幻觉的关系
关系:双向作用机制
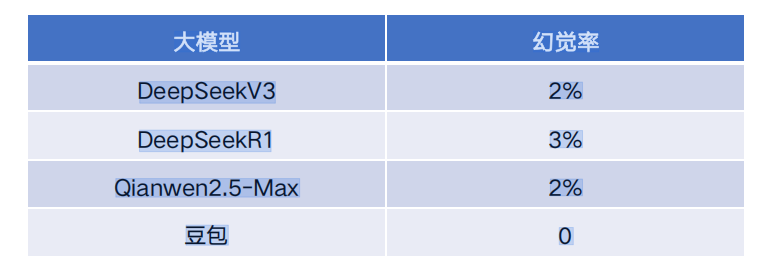
DeepSeek V3:提问-->回答; DeepSeek R1:提问-->思维链-->回答
1.推理增强-->幻觉率降低
• 逻辑准确性与错误减少:推理能力强的模型能减少因逻辑错误导致的幻觉。例如,在数学问
题中,模型若具备多步推理能力,更可能得出正确结论而非臆测答案
• 上下文理解与信息关联:强大的推理能力使模型更精准地捕捉上下文关联,避免因断章取义
而生成虚构内容。例如,在问答任务中,模型能通过推理排除干扰选项,降低错误率
2.推理增强-->幻觉率增加
• 逻辑过度外推:当模型具备强大的逻辑关联能力时,会倾向于在已知事实间建立「超合理」
的虚构连接。例如,时间线延展:已知某科学家发明A技术(1990年),自动补全其在
1995年获得诺贝尔奖(实际未发生)。
• 认知置信度错位:低推理能力模型更易回答“不知道” ,高推理模型会生成符合概率分布的
“自信错误”答案。
• 错误前提下的正确推理:初始假设错误,但模型基于此展开正确推理。
5.AI幻觉--方案
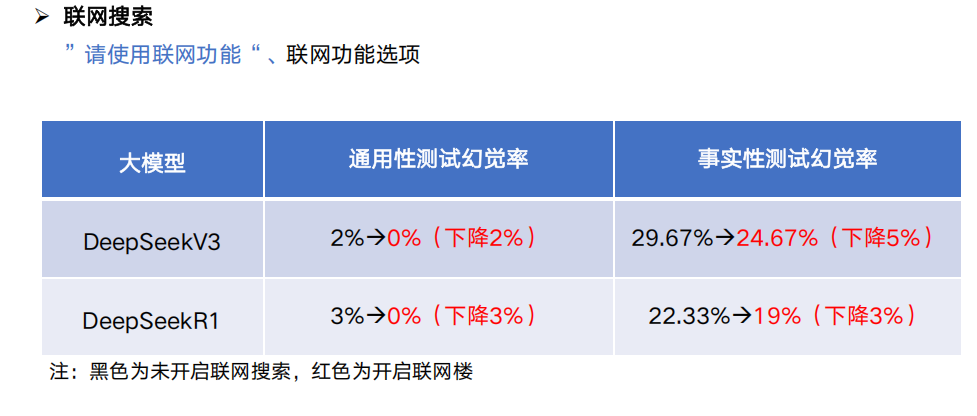
5.1.联网模式
5.2.双AI验证


