线性回归是一种用于建模和分析关系的线性方法。在简单线性回归中,我们考虑一个 自变量和一个因变量之间的关系,用一条直线进行建模。而在多元线性回归中,我们 可以使用多个自变量来建模,因此我们需要拟合的不再是一个简单的直线,而是在高 维空间上的一个超平面。每个样本的因变量(y)在多元线性回归中依赖于多个自变 量(x),这样的关系可以用一个超平面来表示,这个超平面被称为回归平面。因 此,在多元线性回归中,我们试图找到一个最适合数据的超平面,以最小化实际观测 值与模型预测值之间的差异。
一、数据集介绍
本例使用了一个Abalone(Datasets - UCI Machine Learning Repository)数据集, 其中包含关于鲍鱼的信息。数据以data形式保存在dataset文件夹中,其中 abalone.data是数据,abalone.names是本案例数据的英文解释。以下是数据集的 中文解释:
数据集地址
通过物理测量预测鲍鱼的年龄。鲍鱼的年龄是通过将壳切开锥体,染色,然后通过显微镜计算年轮的数量来确定的——这是一项无聊且耗时的任务。其他更容易获得的测量值用于预测年龄。可能需要更多信息,例如天气模式和位置(因此食物供应)才能解决问题。 从原始数据中删除了具有缺失值的示例(大多数示例缺少预测值),并且连续值的范围已缩放以用于 ANN(通过除以 200)。
| 变量名称 | 角色 | 类型 | 描述 | 单位 | 缺失值 |
|---|---|---|---|---|---|
| 性别 | 特征 | 分类 | M、F 和 I(婴儿) | 不 | |
| 长度 | 特征 | 连续的 | 最长的外壳测量 | 毫米 | 不 |
| 直径 | 特征 | 连续的 | 垂直于长度 | 毫米 | 不 |
| 高度 | 特征 | 连续的 | 带壳肉 | 毫米 | 不 |
| 总重Whole_weight | 特征 | 连续的 | 整只鲍鱼 | 克 | 不 |
| 剥离重量Shucked_weight | 特征 | 连续的 | 肉的重量 | 克 | 不 |
| 内脏重量Viscera_weight | 特征 | 连续的 | 肠道重量(出血后) | 克 | 不 |
| 壳重Shell_weight | 特征 | 连续的 | 干燥后 | 克 | 不 |
| 环 | 目标 | 整数 | +1.5 以年为单位给出年龄 | 不 |
给定的是属性名称、属性类型、度量单位和简要描述。
环数是要预测的值:作为连续值或作为分类问题。
二、读取数据集
数据展示

读取数据
import pandas as pd
columns = ['性别', '长度', '直径', '高度', '总重', '剥离重量', '内脏重量', '壳重', '环']
df = pd.read_csv('abalone.data', names=columns, sep=',') 三、数据处理
对离散数据进行one-hot处理
df=pd.get_dummies(df,columns=['性别'])确定自变量(x)和因变量(y)
X=df.drop(columns=['环'])
y=df['环']划分数据集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2,random_state=42)标准化
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
scaler.fit(X_train)
X_train_scaler=scaler.transform(X_train)
X_test_scaler=scaler.transform(X_test)转化为pytorch张量
import torch
X_train_tensor=torch.tensor(X_train_scaler,dtype=torch.float32)
y_train_tensor=torch.tensor(y_train.values,dtype=torch.float32).reshape(-1,1)
X_test_tensor=torch.tensor(X_test_scaler,dtype=torch.float32)
y_test_tensor=torch.tensor(y_test.values,dtype=torch.float32).reshape(-1,1)四、模型训练
定义线性回归模型 ( LinearRegressionModel)
from torch.nn import Module
import torch.nn as nn
class LineModel(Module):
def __init__(self,input):
super().__init__()
self.liner=nn.Linear(input,1)
def forward(self,x):
return self.liner(x)
实例化模型
model=LineModel(X_train_tensor.shape[1])定义损失函数和优化器
使用均方误差损失 ( MSELoss) 作为损失函数,Adam 优 化器作为优化器,学习率为 0.1。
crizerion=nn.MSELoss()
optimier=torch.optim.Adam(lr=0.01,params=model.parameters())模型训练
for i in range(1,10001):
model.train()
optimier.zero_grad()
y_hat=model(X_train_tensor)
loss=crizerion(y_hat,y_train_tensor)
loss.backward()
optimier.step()
if i%1000==0 or i==1:
print(i,loss.item())五、模型评估
设置为评估模式
model.eval()进行前向传播,并计算测 试集的损失
with torch.no_grad():
y_predit=model(X_test_tensor)
y_predit_loss=crizerion(y_predit,y_test_tensor)实际值和模型预测值之间的关系
from matplotlib import pyplot as plt
y_predit=y_predit.numpy()
y_test=y_test_tensor.numpy()
plt.figure(0)
plt.scatter(y_test, y_predit, color='blue')
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], linestyle='--', color='red',linewidth=2)
plt.xlabel('Actual Values')
plt.ylabel('Predicted Values')
plt.title('Regression Results')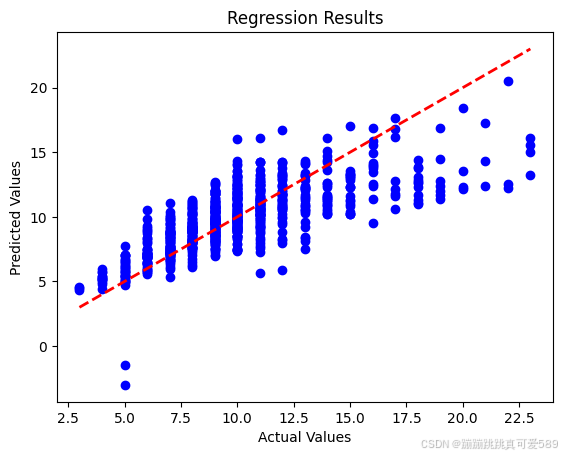
六、完整代码
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import torch
from torch.nn import Module
import torch.nn as nn
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 定义鸸鹋数据集的列名
columns = ['性别', '长度', '直径', '高度', '总重', '剥离重量', '内脏重量', '壳重', '环']
# 使用指定的列名加载数据集
df = pd.read_csv('abalone.data', names=columns, sep=',')
# 对‘性别’列进行独热编码
df = pd.get_dummies(df, columns=['性别'])
# 将特征(X)与目标变量(y)分开
X = df.drop(columns=['环']) # 特征: 除了 '环' 的所有列
y = df['环'] # 目标变量: '环'
# 将数据集拆分为训练集和测试集(80/20分割)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 对特征进行标准化(均值为零,方差为一)
scaler = StandardScaler()
scaler.fit(X_train) # 在训练数据上拟合标准化器
X_train_scaler = scaler.transform(X_train) # 标准化训练数据
X_test_scaler = scaler.transform(X_test) # 标准化测试数据
# 将标准化后的数据转换为PyTorch张量
X_train_tensor = torch.tensor(X_train_scaler, dtype=torch.float32)
# 确保形状为(n_samples, 1)以适应模型的输出
y_train_tensor = torch.tensor(y_train.values, dtype=torch.float32).reshape(-1, 1)
X_test_tensor = torch.tensor(X_test_scaler, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test.values, dtype=torch.float32).reshape(-1, 1)
# 定义线性回归模型类
class LineModel(Module):
def __init__(self, input):
super().__init__()
self.liner = nn.Linear(input, 1) # 定义一个线性层
def forward(self, x):
return self.liner(x) # 前向传播通过模型
# 初始化模型
model = LineModel(X_train_tensor.shape[1]) # 输入大小为特征的数量
# 定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差损失
optimizer = torch.optim.Adam(lr=0.01, params=model.parameters()) # Adam优化器
# 训练循环
for i in range(1, 10001): # 训练10000个周期
model.train() # 设置模型为训练模式
optimizer.zero_grad() # 清除之前的梯度
y_hat = model(X_train_tensor) # 正向传播: 计算预测值
loss = criterion(y_hat, y_train_tensor) # 计算损失
loss.backward() # 反向传播: 计算梯度
optimizer.step() # 更新权重
# 每1000步或第一次迭代时打印损失
if i % 1000 == 0 or i == 1:
print(i, loss.item())
# 模型评估模式,不计算梯度
model.eval()
with torch.no_grad():
y_predit = model(X_test_tensor) # 在测试集上进行预测
y_predit_loss = criterion(y_predit, y_test_tensor) # 计算预测损失
# 将预测值和实际值转换为NumPy数组以进行绘图
y_predit = y_predit.numpy()
y_test = y_test_tensor.numpy()
# 绘制实际值与预测值的散点图
plt.figure(0)
plt.scatter(y_test, y_predit, color='blue') # 实际值与预测值的散点图
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], linestyle='--', color='red', linewidth=2) # 对角线(y=x)
plt.xlabel('实际值') # x轴标签
plt.ylabel('预测值') # y轴标签
plt.title('回归结果') # 图表标题
plt.show() # 显示图表 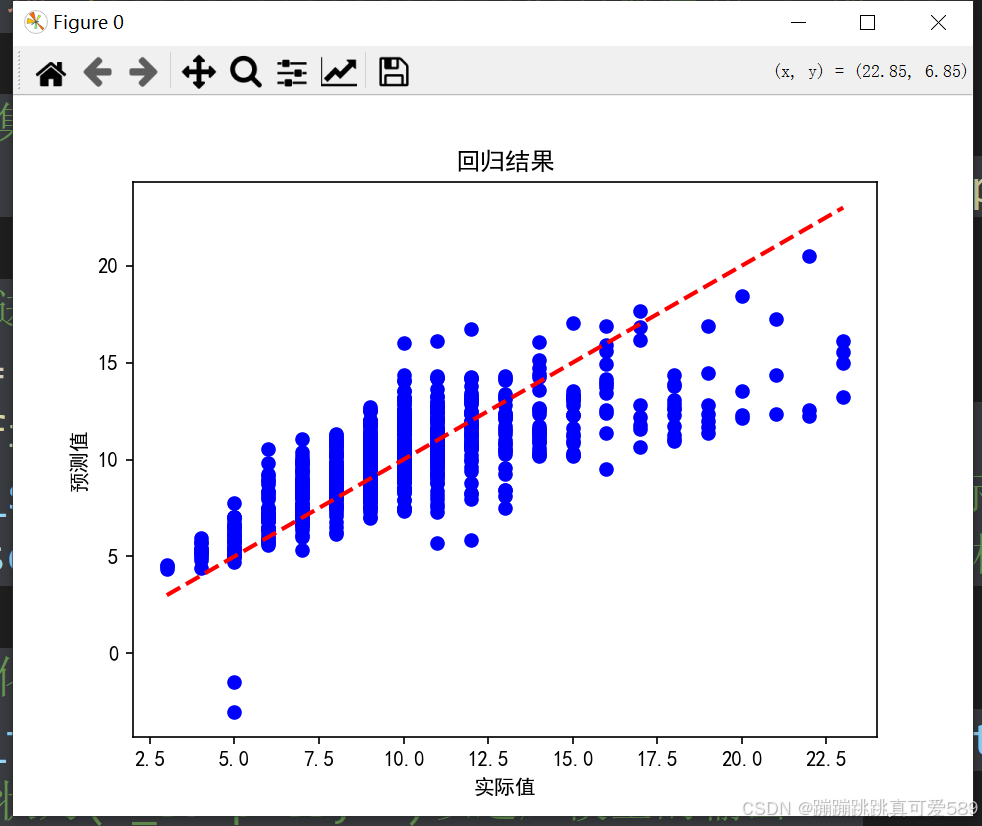
七、设计思路
-
数据加载与预处理:
首先加载鸸鹋数据集,并为数据集指定列名。这是为了方便后续的数据处理和分析。对“性别”这一分类变量进行独热编码,以将其转换为数值型数据,以便模型可以处理。
-
特征与目标变量分离:
将数据集分为特征(X)和目标变量(y)。特征包含所有用于训练的输入数据,而“环”则是我们希望预测的输出。
-
数据集划分:
将数据随机分为训练集和测试集,通常80%的数据用于训练模型,20%的数据用于测试模型的性能。这种划分方式有助于评估模型在未见数据上的表现。
-
数据标准化:
对特征进行标准化处理,使其均值为0,方差为1。这一步骤确保模型在学习时不会因为特征的不同规模而受到影响。
-
转换为PyTorch张量:
将标准化后的数据转换为PyTorch张量,以便能够使用PyTorch进行模型的训练和预测。张量是PyTorch处理数据的基本格式。
-
定义线性回归模型:
创建一个线性回归模型类,里面定义了一个线性层。这一层将输入特征与输出目标变量之间的关系通过线性方程表示。
-
设置损失函数和优化器:
选择均方误差(MSE)作为损失函数,用于衡量模型预测值与真实值之间的差距。同时使用Adam优化器来更新模型的参数,以最小化损失。
-
模型训练:
在一个循环中进行多次训练迭代。在每次迭代中,先进行前向传播计算预测值,然后计算损失,再进行反向传播更新模型参数。通过打印损失值来监控训练过程。
-
评估模型:
在训练完成后,使用测试集来评估模型的预测能力。同样计算模型在测试集上的损失,以了解模型的泛化性能。
-
可视化结果:
使用散点图来展示模型的预测值与实际值之间的关系。通过可视化可以直观地检验模型的预测效果,并通过对角线(y=x)来判断预测的准确性。