一、输入数据
飞桨使用张量(Tensor) 来表示神经网络中传递的数据,Tensor 可以理解为多维数组,类似于 Numpy 数组(ndarray) 的概念。与 Numpy 数组相比,Tensor 除了支持运行在 CPU 上,还支持运行在 GPU 及各种 AI 芯片上,以实现计算加速;此外,飞桨基于 Tensor,实现了深度学习所必须的反向传播功能和多种多样的组网算子,从而可更快捷地实现深度学习组网与训练等功能。
深度学习模型需要大量的数据来完成训练和评估,这些数据样本可能是图片(image)、文本(text)、语音(audio)等多种类型,而模型训练过程实际是数学计算过程,因此数据样本在送入模型前需要经过一系列处理,如转换数据格式、划分数据集、变换数据形状(shape)、制作数据迭代读取器以备分批训练等。
在飞桨框架中,可通过如下两个核心步骤完成数据集的定义与加载:
-
定义数据集:将磁盘中保存的原始图片、文字等样本和对应的标签映射到 Dataset,方便后续通过索引(index)读取数据,在 Dataset 中还可以进行一些数据变换、数据增广等预处理操作。在飞桨框架中推荐使用 paddle.io.Dataset 自定义数据集,另外在 paddle.vision.datasets 和 paddle.text 目录下飞桨内置了一些经典数据集方便直接调用。
-
迭代读取数据集:自动将数据集的样本进行分批(batch)、乱序(shuffle)等操作,方便训练时迭代读取,同时还支持多进程异步读取功能可加快数据读取速度。在飞桨框架中可使用 paddle.io.DataLoader 迭代读取数据集。
import numpy as np
import paddle
from paddle.nn import Layer
# 设置随机种子,以确保实验结果可复现
paddle.seed(42)
# 输入散点数据,包含特征和目标值
data = np.array([
[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2],
[-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],
[0.4, 34.0], [0.8, 62.3]
])
# 提取特征(自变量)和目标值(因变量),并调整形状
x_data = data[:, 0].reshape(-1, 1) # 提取第一列作为特征
y_data = data[:, 1].reshape(-1, 1) # 提取第二列作为目标值
# 将 NumPy 数组转换为 PaddlePaddle 的张量,设置数据类型为 float32
x_train = paddle.to_tensor(x_data, dtype=paddle.float32)
y_train = paddle.to_tensor(y_data, dtype=paddle.float32)
# 创建一个 TensorDataset,将特征和目标值组合在一起
dataset = paddle.io.dataloader.TensorDataset([x_train, y_train])
# 创建数据加载器,用于按批次加载数据,设置批次大小为 10,并随机打乱数据
dataloader = paddle.io.DataLoader(dataset, batch_size=10, shuffle=True) 二、定义前向模型
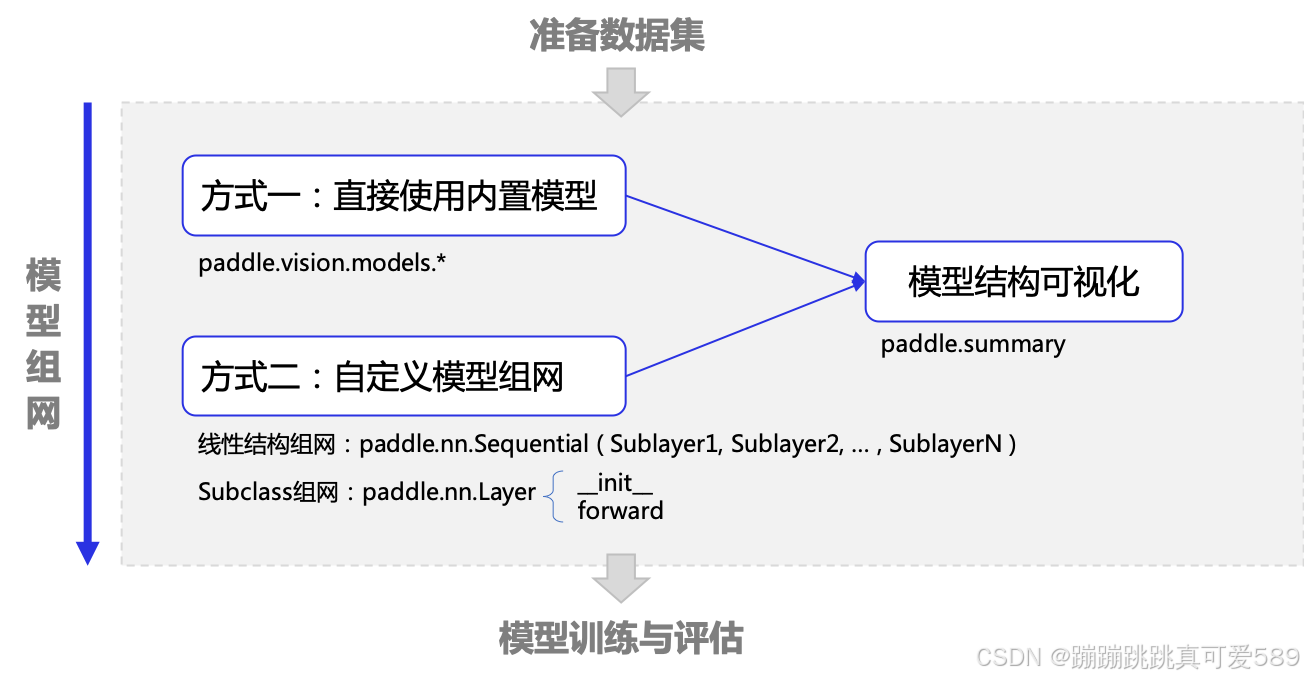
经典模型可以满足一些简单深度学习任务的需求,然后更多情况下,需要使用深度学习框架构建一个自己的神经网络,这时可以使用飞桨框架 paddle.nn 下的 API 构建网络,该目录下定义了丰富的神经网络层和相关函数 API,如卷积网络相关的 Conv1D、Conv2D、Conv3D,循环神经网络相关的 RNN、LSTM、GRU 等,方便组网调用,详细清单可在 API 文档 中查看。
飞桨提供继承类(class)的方式构建网络,并提供了几个基类,如:paddle.nn.Sequential、 paddle.nn.Layer 等,构建一个继承基类的子类,并在子类中添加层(layer,如卷积层、全连接层等)可实现网络的构建,不同基类对应不同的组网方式,本节介绍如下两种常用方法:
-
使用 paddle.nn.Sequential 组网:构建顺序的线性网络结构(如 LeNet、AlexNet 和 VGG)时,可以选择该方式。相比于 Layer 方式 ,Sequential 方式可以用更少的代码完成线性网络的构建。
-
使用 paddle.nn.Layer 组网(推荐):构建一些比较复杂的网络结构时,可以选择该方式。相比于 Sequential 方式,Layer 方式可以更灵活地组建各种网络结构。Sequential 方式搭建的网络也可以作为子网加入 Layer 方式的组网中。
2.1、方案一
model=paddle.nn.Linear(1,1)2.2、方案二
模型组网是深度学习任务中的重要一环,该环节定义了神经网络的层次结构、数据从输入到输出的计算过程(即前向计算)等。
飞桨框架提供了多种模型组网方式,本文介绍如下几种常见用法:
-
直接使用内置模型
-
使用 paddle.nn.Sequential 组网
-
使用 paddle.nn.Layer 组网
model=paddle.nn.Sequential(
paddle.nn.Linear(1,1)
)2.3、方案三(常用)
构建一些比较复杂的网络结构时,可以选择该方式,组网包括三个步骤:
-
创建一个继承自 paddle.nn.Layer 的类;
-
在类的构造函数
__init__中定义组网用到的神经网络层(layer); -
在类的前向计算函数
forward中使用定义好的 layer 执行前向计算。
class LinerModel(paddle.nn.Layer):
def __init__(self):
super().__init__()
self.liner=paddle.nn.Linear(1,1)
def forward(self,x):
x=self.liner(x)
return x
model=LinerModel()三、定义损失函数和优化器
criterion=paddle.nn.MSELoss()
optimizer=paddle.optimizer.SGD(learning_rate=0.01,parameters=model.parameters())
四、输出数据
4.1、基础api
for i in range(1,501):
total=0
for x,y in data:
y_hat=model(x.unsqueeze(1))
loss=criterion(y_hat.squeeze(1),y)
total+=loss
optimizer.clear_grad()
loss.backward()
optimizer.step()
avg_loss=total/len(data)
if i%10==0 or i==1:
print(i,avg_loss.item())1 2805.53271484375
10 1693.861572265625
20 979.18212890625
30 576.9484252929688
40 349.4954528808594
50 220.17758178710938
60 146.19935607910156
70 103.58463287353516
80 78.84718322753906
90 64.36637115478516
100 55.812904357910156
110 50.71232223510742
120 47.64075469970703
130 45.77250671386719
140 44.62482833862305
150 43.912940979003906
160 43.46727752685547
170 43.185848236083984
180 43.006675720214844
190 42.89180374145508
200 42.817623138427734
210 42.76947784423828
220 42.738067626953125
230 42.717491149902344
240 42.70396041870117
250 42.69502639770508
260 42.689109802246094
270 42.68519592285156
280 42.682586669921875
290 42.68085479736328
300 42.67970657348633
310 42.67892074584961
320 42.67841720581055
330 42.678077697753906
340 42.67784881591797
350 42.67768478393555
360 42.677574157714844
370 42.67751693725586
380 42.677459716796875
390 42.677433013916016
400 42.67741394042969
410 42.677406311035156
420 42.67739486694336
430 42.677391052246094
440 42.67737579345703
450 42.6773796081543
460 42.6773796081543
470 42.67737579345703
480 42.6773681640625
490 42.67737579345703
500 42.67736816406254.2、高层api
model=paddle.Model(model)
model.prepare(
optimizer=paddle.optimizer.SGD(learning_rate=0.01,parameters=model.parameters()),
loss=paddle.nn.MSELoss(),
metrics=paddle.metric.Accuracy()
)
model.fit(dataloader,epochs=500,verbose=1)Epoch 496/500
step 1/1 [==============================] - loss: 42.6774 - acc: 0.0000e+00 - 1ms/step
Epoch 497/500
step 1/1 [==============================] - loss: 42.6774 - acc: 0.0000e+00 - 1ms/step
Epoch 498/500
step 1/1 [==============================] - loss: 42.6774 - acc: 0.0000e+00 - 2ms/step
Epoch 499/500
step 1/1 [==============================] - loss: 42.6774 - acc: 0.0000e+00 - 999us/step
Epoch 500/500
step 1/1 [==============================] - loss: 42.6774 - acc: 0.0000e+00 - 2ms/step4.3、基础api完整代码
import numpy as np
import paddle
from paddle.nn import Layer
# 设置随机种子,以确保实验结果可复现
paddle.seed(42)
# 输入散点数据,包含特征和目标值
data = np.array([
[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2],
[-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],
[0.4, 34.0], [0.8, 62.3]
])
# 提取特征(自变量)和目标值(因变量)
x_data = data[:, 0] # 提取第一列作为特征
y_data = data[:, 1] # 提取第二列作为目标值
# 将 NumPy 数组转换为 PaddlePaddle 的张量,设置数据类型为 float32
x_train = paddle.to_tensor(x_data, dtype=paddle.float32)
y_train = paddle.to_tensor(y_data, dtype=paddle.float32)
# 创建 TensorDataset,将特征和目标值组合在一起
data = paddle.io.TensorDataset([x_train, y_train])
# 创建数据加载器,用于按批次加载数据,设置批次大小为 10,并随机打乱数据
data = paddle.io.DataLoader(dataset=data, batch_size=10, shuffle=True)
# 定义线性模型类
class LinerModel(Layer):
def __init__(self):
super().__init__()
self.liner = paddle.nn.Linear(1, 1) # 创建一个线性层,输入和输出尺寸均为 1
def forward(self, x):
x = self.liner(x) # 前向传播,计算输出
return x
# 实例化线性模型
model = LinerModel()
# 设置损失函数为均方误差损失
criterion = paddle.nn.MSELoss()
# 设置优化器为随机梯度下降,学习率设为 0.01
optimizer = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
# 进行训练
for i in range(1, 501):
total = 0 # 初始化总损失
for x, y in data: # 遍历数据加载器中的每个批次
y_hat = model(x.unsqueeze(1)) # 前向传播,获取预测值
loss = criterion(y_hat.squeeze(1), y) # 计算损失
total += loss # 累加损失
optimizer.clear_grad() # 清空梯度
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
avg_loss = total / len(data) # 计算平均损失
# 每10步或第一步打印一次损失值
if i % 10 == 0 or i == 1:
print(i, avg_loss.item()) 4.4、高层api完整代码
import numpy as np
import paddle
from paddle.nn import Layer
# 设置随机种子,以确保实验结果可复现
paddle.seed(42)
# 输入散点数据,包含特征和目标值
data = np.array([
[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2],
[-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],
[0.4, 34.0], [0.8, 62.3]
])
# 提取特征(自变量)和目标值(因变量),并调整形状
x_data = data[:, 0].reshape(-1, 1) # 提取第一列作为特征并调整为二维数组
y_data = data[:, 1].reshape(-1, 1) # 提取第二列作为目标值并调整为二维数组
# 将 NumPy 数组转换为 PaddlePaddle 的张量,设置数据类型为 float32
x_train = paddle.to_tensor(x_data, dtype=paddle.float32)
y_train = paddle.to_tensor(y_data, dtype=paddle.float32)
# 创建 TensorDataset,将特征和目标值组合在一起
dataset = paddle.io.dataloader.TensorDataset([x_train, y_train])
# 创建数据加载器,用于按批次加载数据,设置批次大小为 10,并随机打乱数据
dataloader = paddle.io.DataLoader(dataset, batch_size=10, shuffle=True)
# 定义线性模型类
class LinerModel(Layer):
def __init__(self):
super().__init__()
self.liner = paddle.nn.Linear(1, 1) # 创建一个线性层,输入和输出尺寸均为 1
def forward(self, x):
x = self.liner(x) # 前向传播,计算输出
return x
# 实例化线性模型
model = LinerModel()
# 将线性模型包装成 Paddle 的 Model 类
model = paddle.Model(model)
# 准备模型,包括优化器、损失函数和评估指标
model.prepare(
optimizer=paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters()), # 设置随机梯度下降优化器
loss=paddle.nn.MSELoss(), # 设置损失函数为均方误差损失
metrics=paddle.metric.Accuracy() # 设置评估指标为准确率(注意:在线性回归中,准确率的评估可能不太合适)
)
# 训练模型,指定数据加载器和训练的轮数,verbose=1 表示输出训练过程信息
model.fit(dataloader, epochs=500, verbose=1) 五、模型的保存与加载
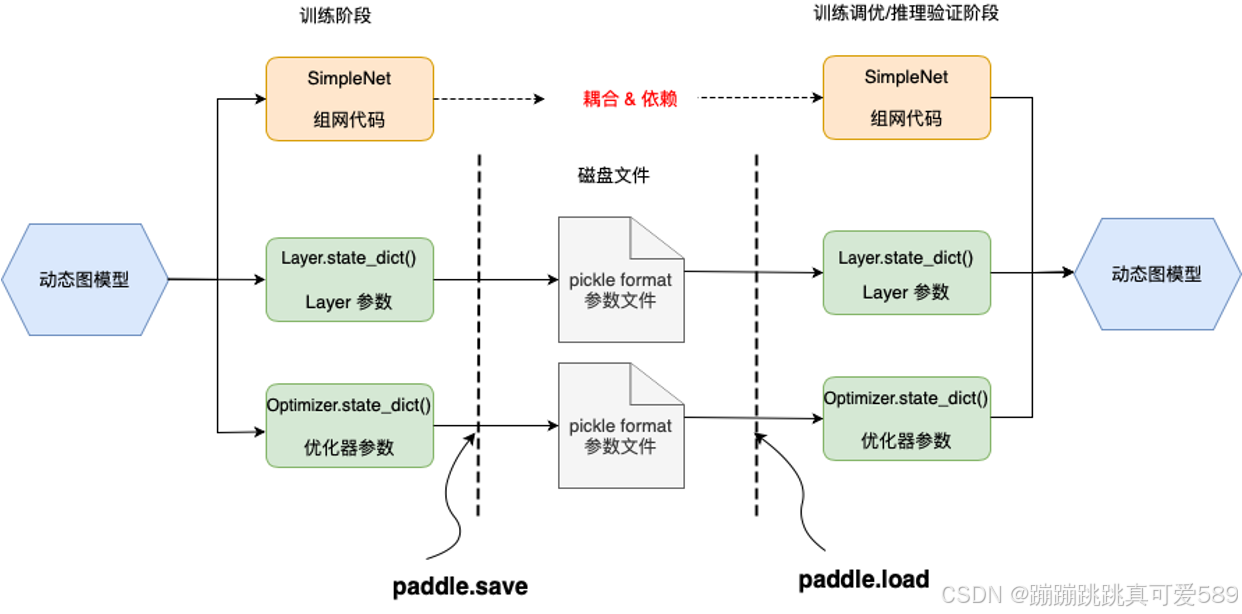
如下图所示,动态图模式下,模型结构指的是 Python 前端组网代码;模型参数主要指网络层 Layer.state_dict() 和优化器 Optimizer.state_dict()中存放的参数字典。state_dict()中存放了模型参数信息,包括所有可学习的和不可学习的参数(parameters 和 buffers),从网络层(Layer)和优化器(Optimizer)中获取,以字典形式存储,key 为参数名,value 为对应参数数据(Tensor)。
5.1、基础api保存
paddle.save:使用 paddle.save保存模型,实际是通过 Python pickle 模块来实现的,传入要保存的数据对象后,会在指定路径下生成一个 pickle 格式的磁盘文件。
另外,paddle.save还支持直接保存 Tensor 数据,或者含 Tensor 的 list/dict 嵌套结构。所以动态图模式下,可支持保存和加载的内容包括:
-
网络层参数:
Layer.state_dict() -
优化器参数:
Optimizer.state_dict() -
Tensor 数据 :(如创建的 Tensor 数据、网络层的 weight 数据等)
-
含 Tensor 的 list/dict 嵌套结构对象 (如保存 state_dict() 的嵌套结构对象:
obj = {'model': layer.state_dict(), 'opt': adam.state_dict(), 'epoch': 100})
import numpy as np
import paddle
from paddle.nn import Layer
# 设置随机种子,以确保实验结果可复现
paddle.seed(42)
# 输入散点数据,包含特征和目标值
data = np.array([
[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2],
[-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],
[0.4, 34.0], [0.8, 62.3]
])
# 提取特征(自变量)和目标值(因变量)
x_data = data[:, 0] # 提取第一列作为特征
y_data = data[:, 1] # 提取第二列作为目标值
# 将 NumPy 数组转换为 PaddlePaddle 的张量,设置数据类型为 float32
x_train = paddle.to_tensor(x_data, dtype=paddle.float32)
y_train = paddle.to_tensor(y_data, dtype=paddle.float32)
# 创建 TensorDataset,将特征和目标值组合在一起
data = paddle.io.TensorDataset([x_train, y_train])
# 创建数据加载器,用于按批次加载数据,设置批次大小为 10,并随机打乱数据
data = paddle.io.DataLoader(dataset=data, batch_size=10, shuffle=True)
# 定义线性模型类
class LinerModel(Layer):
def __init__(self):
super().__init__()
self.liner = paddle.nn.Linear(1, 1) # 创建一个线性层,输入和输出尺寸均为 1
def forward(self, x):
x = self.liner(x) # 前向传播,计算输出
return x
# 实例化线性模型
model = LinerModel()
# 设置损失函数为均方误差损失
criterion = paddle.nn.MSELoss()
# 设置优化器为随机梯度下降,学习率设为 0.01
optimizer = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
# 初始化一个字典用于保存最终的检查点信息
final_chechpoint = {}
# 进行训练
for i in range(1, 501):
total = 0 # 初始化总损失
for x, y in data: # 遍历数据加载器中的每个批次
y_hat = model(x.unsqueeze(1)) # 前向传播,获取预测值
loss = criterion(y_hat.squeeze(1), y) # 计算损失
total += loss # 累加损失
optimizer.clear_grad() # 清空梯度
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
avg_loss = total / len(data) # 计算平均损失
# 每10步或第一步打印一次损失值
if i % 10 == 0 or i == 1:
print(i, avg_loss.item())
# 保存最后的检查点信息
if i == 500:
final_chechpoint['epoch'] = i # 记录训练的轮数
final_chechpoint['loss'] = avg_loss # 记录最后的平均损失
# 保存模型参数
paddle.save(model.state_dict(), './jichu/model.pdparams')
# 保存优化器参数
paddle.save(optimizer.state_dict(), 'jichu/model.pdot')
# 保存检查点信息
paddle.save(final_chechpoint, './jichu/final_chechpoint.pkl') 5.2、基础api加载
paddle.load:加载时还需要之前的模型组网代码,并使用paddle.load传入保存的文件路径,即可重新将之前保存的数据从磁盘文件中载入。
import paddle
from paddle.nn import Layer
from paddle.io import DataLoader, TensorDataset
# 定义线性模型类
class LinerModel(Layer):
def __init__(self):
super().__init__()
self.liner = paddle.nn.Linear(1, 1) # 创建一个线性层,输入和输出尺寸均为 1
def forward(self, x):
x = self.liner(x) # 前向传播,计算输出
return x
# 实例化线性模型
model = LinerModel()
# 设置损失函数为均方误差损失
criterion = paddle.nn.MSELoss()
# 设置优化器为随机梯度下降,学习率设为 0.01
optimizer = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
# 加载模型和优化器的保存状态
model_state_dict = paddle.load('./jichu/model.pdparams') # 加载模型参数
optimizer_state_dict = paddle.load('./jichu/model.pdot') # 加载优化器参数
final_checkpoint = paddle.load('./jichu/final_chechpoint.pkl') # 加载最后的检查点信息
# 将加载的参数设置到模型中
model.set_state_dict(model_state_dict)
# 将模型设置为验证模式,以禁用 dropout 等层
model.eval()
# 创建测试数据张量
data = paddle.to_tensor([1.5], dtype=paddle.float32) # 测试输入数据
data = TensorDataset([data]) # 将测试数据放入 TensorDataset 中
# 创建数据加载器以便于批次处理
dataloader_test = DataLoader(data)
# 遍历测试数据加载器,进行预测
for i in dataloader_test:
pred = model(i[0]) # 使用模型进行预测
print(pred) # 输出预测结果 5.3、高层api保存
使用高层 API,需预先将模型定义为 paddle.Model 实例,后续的训练、模型保存/加载、预测等功能都需要该实例来调用各 API。模型的保存和加载使用 paddle.Model.save 和 paddle.Model.load 这一对,它们的底层实现与基础 API 类似。
import numpy as np
import paddle
from paddle.nn import Layer
# 设置随机种子,以确保实验结果可复现
paddle.seed(42)
# 输入散点数据,包含特征和目标值
data = np.array([
[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2],
[-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],
[0.4, 34.0], [0.8, 62.3]
])
# 提取特征(自变量)和目标值(因变量),并调整形状
x_data = data[:, 0].reshape(-1, 1) # 提取第一列作为特征并调整为二维数组
y_data = data[:, 1].reshape(-1, 1) # 提取第二列作为目标值并调整为二维数组
# 将 NumPy 数组转换为 PaddlePaddle 的张量,设置数据类型为 float32
x_train = paddle.to_tensor(x_data, dtype=paddle.float32)
y_train = paddle.to_tensor(y_data, dtype=paddle.float32)
# 创建 TensorDataset,将特征和目标值组合在一起
dataset = paddle.io.dataloader.TensorDataset([x_train, y_train])
# 创建数据加载器,用于按批次加载数据,设置批次大小为 10,并随机打乱数据
dataloader = paddle.io.DataLoader(dataset, batch_size=10, shuffle=True)
# 定义线性模型类
class LinerModel(Layer):
def __init__(self):
super().__init__()
self.liner = paddle.nn.Linear(1, 1) # 创建一个线性层,输入和输出尺寸均为 1
def forward(self, x):
x = self.liner(x) # 前向传播,计算输出
return x
# 实例化线性模型
model = LinerModel()
# 将线性模型包装成 Paddle 的 Model 类
model = paddle.Model(model)
# 准备模型,包括优化器、损失函数和评估指标
model.prepare(
optimizer=paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters()), # 设置随机梯度下降优化器
loss=paddle.nn.MSELoss(), # 设置损失函数为均方误差损失
metrics=paddle.metric.Accuracy() # 设置评估指标为准确率(注意:在线性回归中,准确率的评估可能不太合适)
)
# 1. 训练模型,指定数据加载器和训练的轮数,verbose=1 表示输出训练过程信息,
# save_dir 指定模型保存路径,save_freq 设置每多少轮保存一次
model.fit(dataloader, epochs=500, verbose=1, save_dir='./gaocengapi', save_freq=10)
# 2. 使用 paddle.Model 的 save 方法保存整个模型,包括结构及参数
model.save('./gaocengapi2/model')
# 3. 保存推断模型,但不保存优化器状态
model.save('./gaocengapi2/infer_model', False) 5.4、高层api加载
import paddle
from paddle.nn import Layer
from paddle.io import DataLoader, TensorDataset
# 定义线性模型类
class LinerModel(Layer):
def __init__(self):
super().__init__()
self.liner = paddle.nn.Linear(1, 1) # 创建一个线性层,输入和输出尺寸均为 1
def forward(self, x):
x = self.liner(x) # 前向传播,计算输出
return x
# 实例化线性模型
model = LinerModel()
# 将线性模型包装成 Paddle 的 Model 类
model = paddle.Model(model)
# 准备模型,包括优化器、损失函数和评估指标
model.prepare(
optimizer=paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters()), # 设置随机梯度下降优化器
loss=paddle.nn.MSELoss(), # 设置损失函数为均方误差损失
metrics=paddle.metric.Accuracy() # 设置评估指标为准确率(注意:在线性回归中,准确率的评估可能不太合适)
)
# 加载训练好的模型状态
model.load('./gaocengapi/final') # 从指定路径加载模型参数和结构
# 创建测试数据张量,包含多个输入数据用于评估
data = paddle.to_tensor([[1.5], [82.]], dtype=paddle.float32)
dataset = TensorDataset(data) # 将测试数据放入 TensorDataset 中
# 创建数据加载器以便于批次处理
dataloader_eval = DataLoader(dataset, batch_size=1)
# 使用模型对加载的数据进行评估
eval_predict = model.evaluate(dataloader_eval, verbose=1) # 评估并打印结果
print(eval_predict) # 打印评估结果
# 创建单个测试数据张量,用于模型预测
data = paddle.to_tensor([[1.5]], dtype=paddle.float32)
dataset = TensorDataset(data) # 将测试数据放入 TensorDataset 中
# 使用模型进行预测
pre_result = model.predict(dataset) # 进行预测
print(pre_result) # 打印预测结果 飞桨框架同时支持动态图和静态图,优先推荐使用动态图训练,兼容支持静态图。
如果用于训练调优场景,动态图和静态图均使用
paddle.save和paddle.load保存和加载模型参数,或者在高层 API 训练场景下使用paddle.Model.save和paddle.Model.load。如果用于推理部署场景,动态图模型需先转为静态图模型再保存,使用
paddle.jit.save和paddle.jit.load保存和加载模型结构和参数;静态图模型直接使用paddle.static.save_inference_model和paddle.static.load_inference_model保存和加载模型结构和参数。
六、模型网络可视化
6.1、summary
通过 paddle.summary 可清晰地查看神经网络层次结构、每一层的输入数据和输出数据的形状(Shape)、模型的参数量(Params)等信息,方便可视化地了解模型结构、分析数据计算和传递过程。
import paddle
from paddle.nn import Layer
# 定义线性模型类
class LinerModel(Layer):
def __init__(self):
super().__init__()
self.liner = paddle.nn.Linear(1, 1) # 创建一个线性层,输入和输出尺寸均为 1
def forward(self, x):
x = self.liner(x) # 前向传播,计算输出
return x
# 实例化线性模型
model = LinerModel()
# 从指定路径加载模型参数
model_state_dict = paddle.load('./jichu/model.pdparams') # 加载保存的模型状态字典
# 将加载的模型参数设置到模型中
model.set_state_dict(model_state_dict)
# 打印模型的摘要信息,包括模型结构和参数数量等
print(paddle.summary(model, (1,))) # 输入的形状为 (1,),表示单个特征的输入 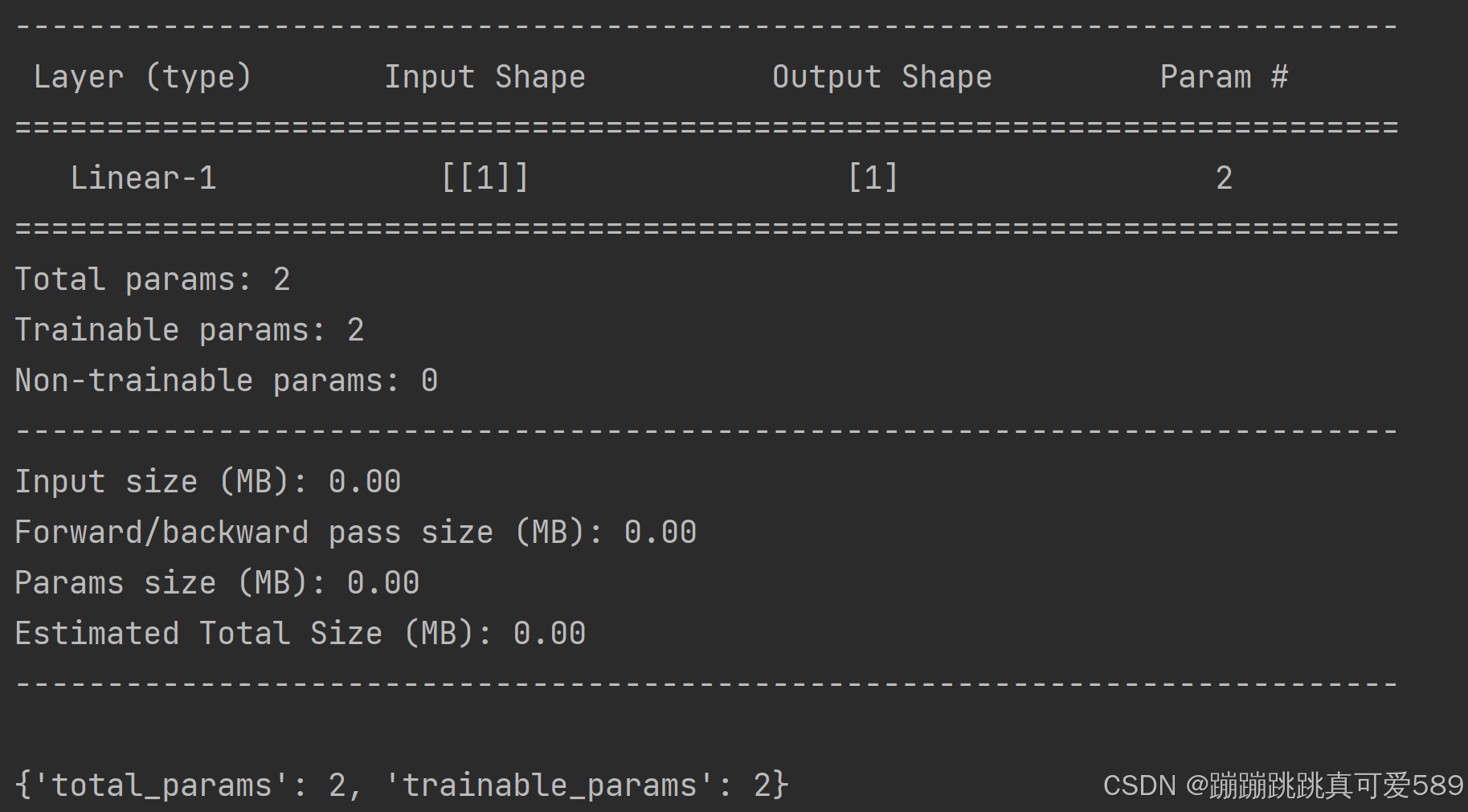
6.2、 netron
6.3、 visualdl
visualdl --logdir ./runs/mnist_experiment --model ./runs/mnist_experiment/model.pdmodel --host 0.0.0.0 --port 8040
--logdir:与使用 LogWriter 时指定的参数相同。
--model:(可选)为保存的网络模型结构文件。
--host:指定服务的 IP 地址。
--port:指定服务的端口地址。
在命令行中输入上述命令启动服务后,可以在浏览器中输入 http://localhost:8040 (也可以查看 ip 地址,将 localhost 换成 ip)进行查看。
安装
pip install visualdl -i https://pypi.tuna.tsinghua.edu.cn/simple/
import numpy as np
import paddle
from paddle.nn import Layer
from visualdl import LogWriter
# 设置随机种子,以确保实验结果可复现
paddle.seed(42)
# 输入散点数据,包含特征和目标值
data = np.array([
[-0.5, 7.7], [1.8, 98.5], [0.9, 57.8], [0.4, 39.2],
[-1.4, -15.7], [-1.4, -37.3], [-1.8, -49.1], [1.5, 75.6],
[0.4, 34.0], [0.8, 62.3]
])
# 提取特征(自变量)和目标值(因变量)
x_data = data[:, 0] # 提取第一列作为特征值
y_data = data[:, 1] # 提取第二列作为目标值
# 将数据转换为 PaddlePaddle 的张量格式,并设置数据类型为 float32
x_train = paddle.to_tensor(x_data, dtype=paddle.float32)
y_train = paddle.to_tensor(y_data, dtype=paddle.float32)
# 创建 TensorDataset,将特征和目标值组合在一起
data = paddle.io.TensorDataset([x_train, y_train])
# 创建数据加载器,用于按批次加载数据,设置批次大小为 10,并随机打乱数据
data = paddle.io.DataLoader(dataset=data, batch_size=10, shuffle=True)
# 定义线性模型类
class LinerModel(Layer):
def __init__(self):
super().__init__()
self.liner = paddle.nn.Linear(1, 1) # 创建一个线性层,输入和输出尺寸均为 1
def forward(self, x):
x = self.liner(x) # 前向传播,计算输出
return x
# 实例化线性模型
model = LinerModel()
# 设置损失函数为均方误差损失
criterion = paddle.nn.MSELoss()
# 设置优化器为随机梯度下降,学习率设为 0.01
optimizer = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())
# 初始化 VisualDL 的日志记录器
log = LogWriter(logdir='logs') # 指定日志保存目录
for i in range(1, 501):
total = 0 # 初始化总损失
for x, y in data: # 遍历数据加载器中的每个批次
y_hat = model(x.unsqueeze(1)) # 前向传播,获取预测值
loss = criterion(y_hat.squeeze(1), y) # 计算损失
total += loss # 累加损失
optimizer.clear_grad() # 清空梯度
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
avg_loss = total / len(data) # 计算平均损失
# 记录平均损失到日志,step 参数通常应该是第 i 轮而非固定为 500
log.add_scalar('train_loss', value=avg_loss, step=i)
# 每10步或第一步打印一次损失值
if i % 10 == 0 or i == 1:
print(i, avg_loss.item())
# 保存模型为 JIT 格式,定义输入规范以便后续推理
paddle.jit.save(model, './logs/model', [paddle.static.InputSpec([1,])])
# 记录超参数和指标到日志
log.add_hparams(hparams_dict={'lr': 0.01, 'batch_size': 10, 'opt': 'SGD'},
metrics_list=['train_loss']) # 记录训练损失 生成
D:\Anaconda3\envs\python381\python.exe C:\Users\xxxxxx\AppData\Roaming\Python\Python38\Scripts\visualdl.exe --logdir=D:\xxxxxx\xxxxxx\logs --model=D:\xxxxxx\xxxxxx\logs\model.pdmodel --host 0.0.0.0 --port 8040D:\Anaconda3\envs\python381\python.exe 该版本python的位置
C:\Users\xxxxxx\xxxxx\Python\Python38\Scripts\visualdl.exe visualdl.exe 文件位置
--logdir=D:\xxxxxx\xxxxxx\logs 模型所在的文件夹的位置
--model=D:\xxxxxx\xxxxxx\logs\model.pdmodel 模型所在的位置
--host 0.0.0.0 --port 8040 ip地址和端口号
