LLM入门课#05 人类反馈强化学习是啥
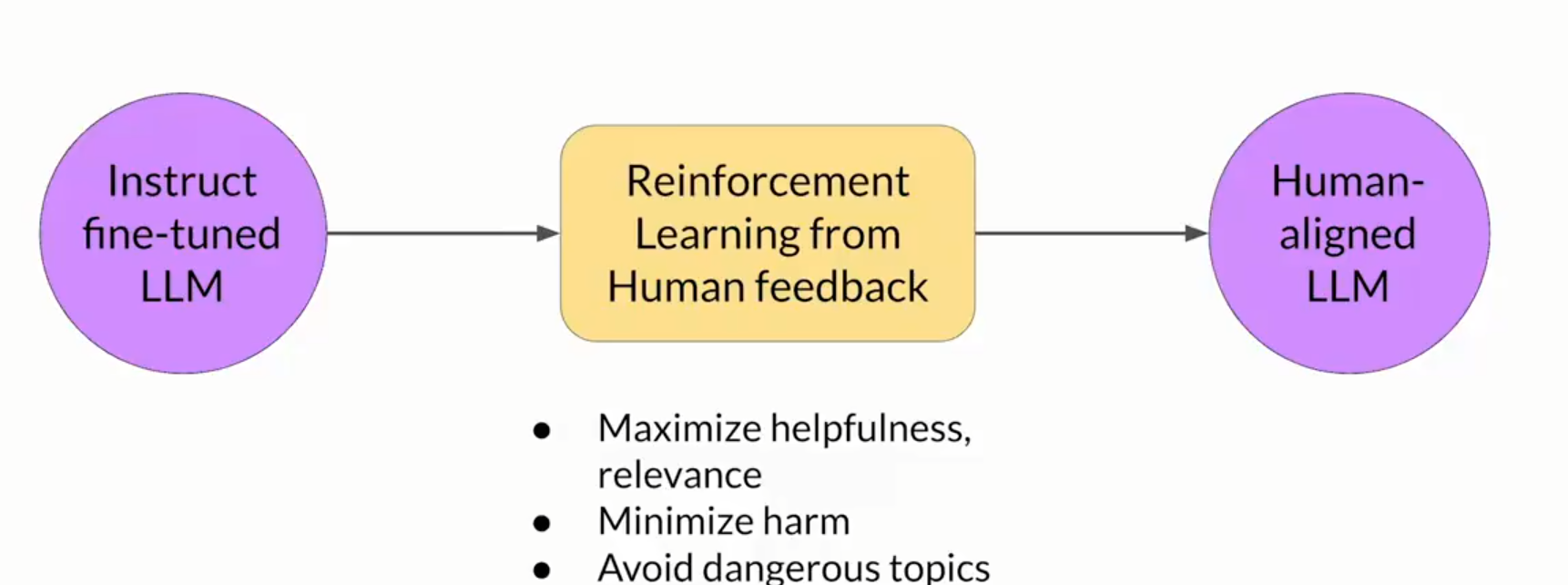
大模型虽然已经呈现出了强大的能力,但是如果不添加管制的话,会导致模型生成一些没有用的或者有害的内容,比如如果你问他如何去黑入别人的wifi,他也会提供给你一个有效的方案。这对吗,这明显是不对的,机器人应该和谐地融入到我们的社会中才可以。
所以,这个时候,RLHF这个技术就出来了,通过这个技术,你可以帮助你的模型更加具有人性化,对不好的答案进行抑制,对好的答案直接加大火力。可以说是强化学习的魅力时刻了。
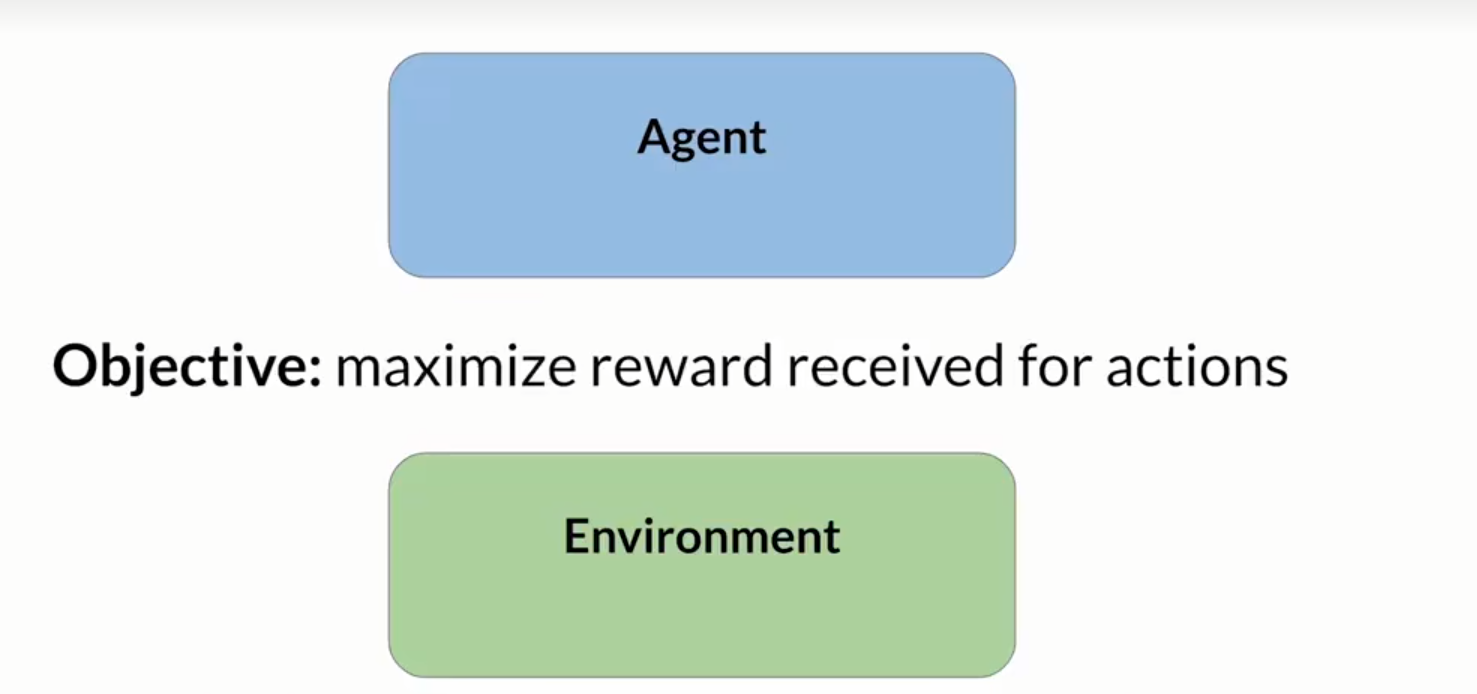
说到人类反馈强化学习,我们先来说一下正常的强化学习。强化学习指的是,智能体在环境中采取行动,以达到最大化某种累积奖励的目标,从而学习做出与特定目标相关的决策,强调的是模型和环境的交互。
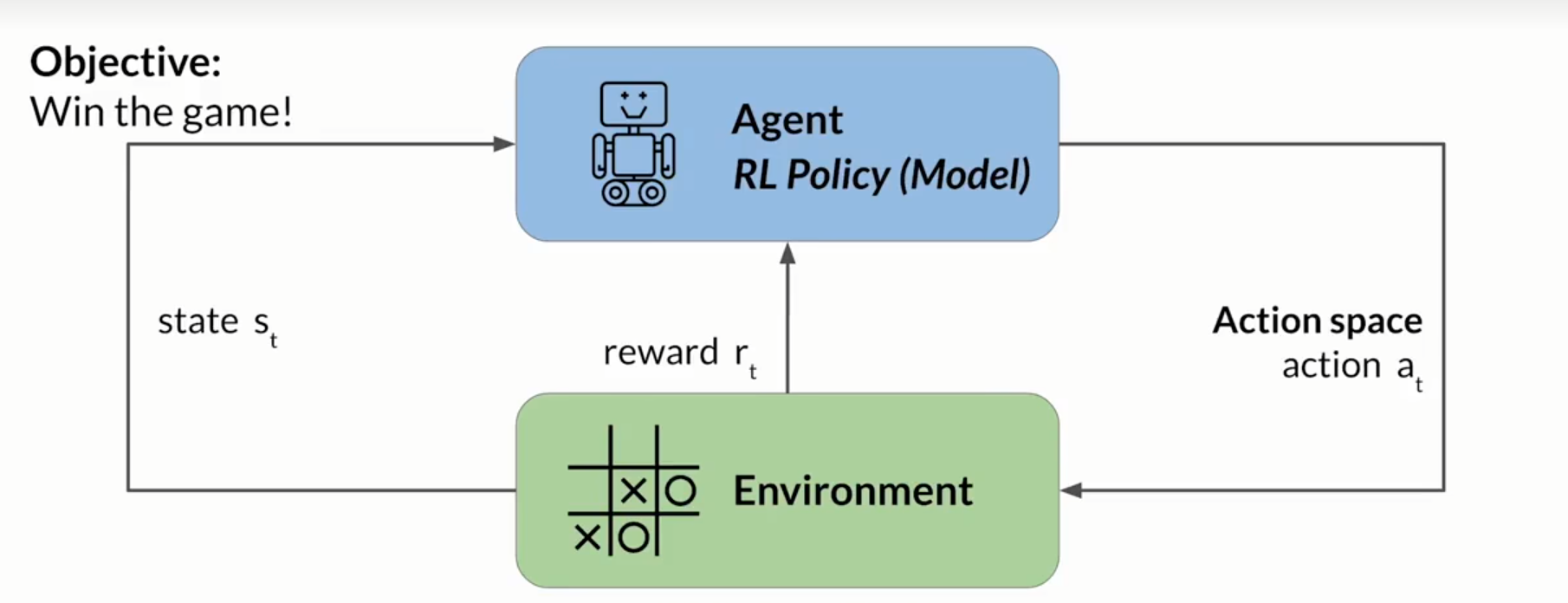
强化学习最典型的是训练你的模型去玩#游戏,下面是一个过程。
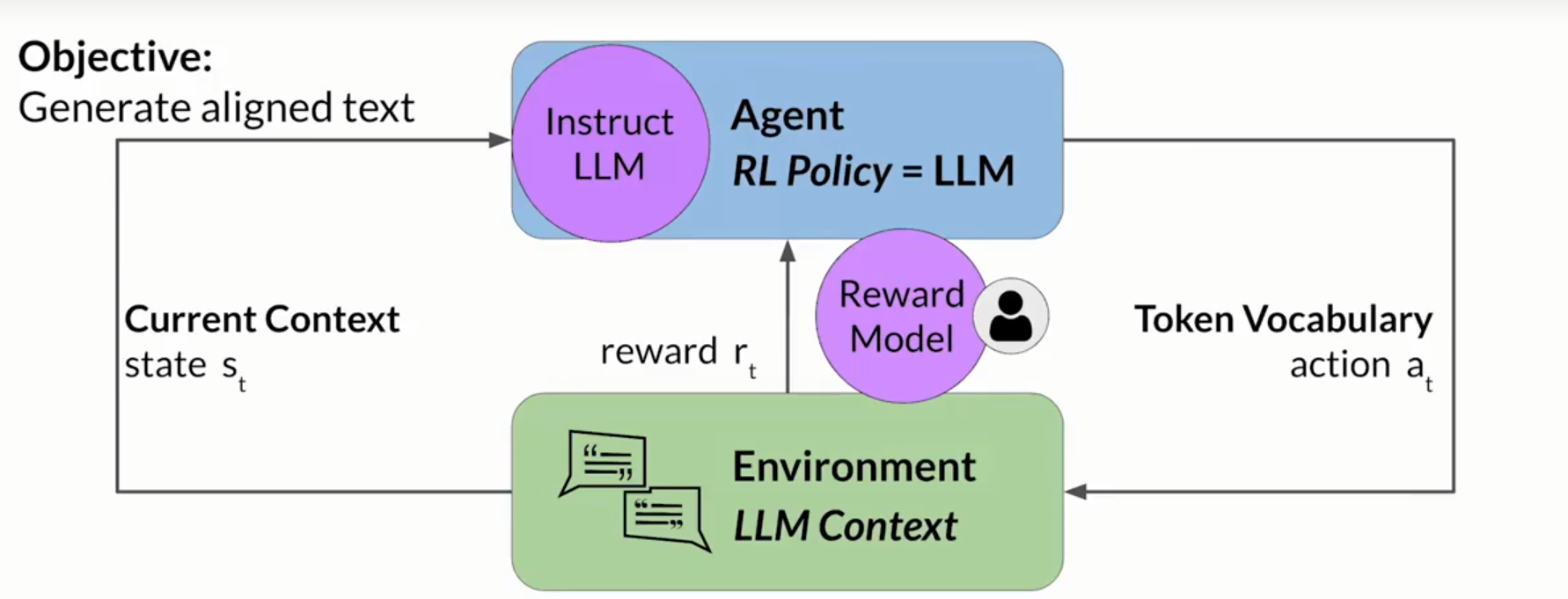
同理,将这个过程借鉴到大语言模型上面,我们可以得到这样的一个结果。其中agent是你的llm模型,环境来自于用户指定的任务,状态则是当前的上下文,动作则是通过token的池子给出一个合理的输出,reward则是用来判断模型当前的输出是否和用户希望的输出是一致的,是有毒的还是无毒的。但是,如果你用人工的话那就比较昂贵了,所以这个时候,你使用reward model,简单理解,他可以是一个文本分类的模型,主要是识别出你当前输出的内容是和谐的,还是不和谐的。如果是和谐的内容,就奖励模型,奖励模型就是最大化对应token的概率,如果是不和谐的内容,就惩罚模型,惩罚模型就是奖励对应token的概率。
在医学病理图像生成的任务中, 我们也可以通过奖励模型来定义什么模型是一个好的模型,而什么模型是一个不好的模型,通过这个方式,也可以让我们的模型生成一个更好的病理图像报告的内容,实在是太棒了!