目录
此章节主要讲解函数的进阶用法和文件主要有:函数多返回值、函数多种传参方式、匿名函数、文件的编码、文件的读取、文件的写入、文件的追加。
一.函数多个返回值
问:如果一个函数如些两个return(如下所示),程序如何执行?

答:只执行了第一个return,原因是因为return可以退出当前函数导致return下方的代码不执行。
由上述案例我们引出可以多个返回值的函数。
函数多返回值的格式如下:

注:
(1)按照返回值的顺序,写对应顺序的多个变量接收即可
(2)交量之间用逗号隔开
(3)支持不同类型的数据return
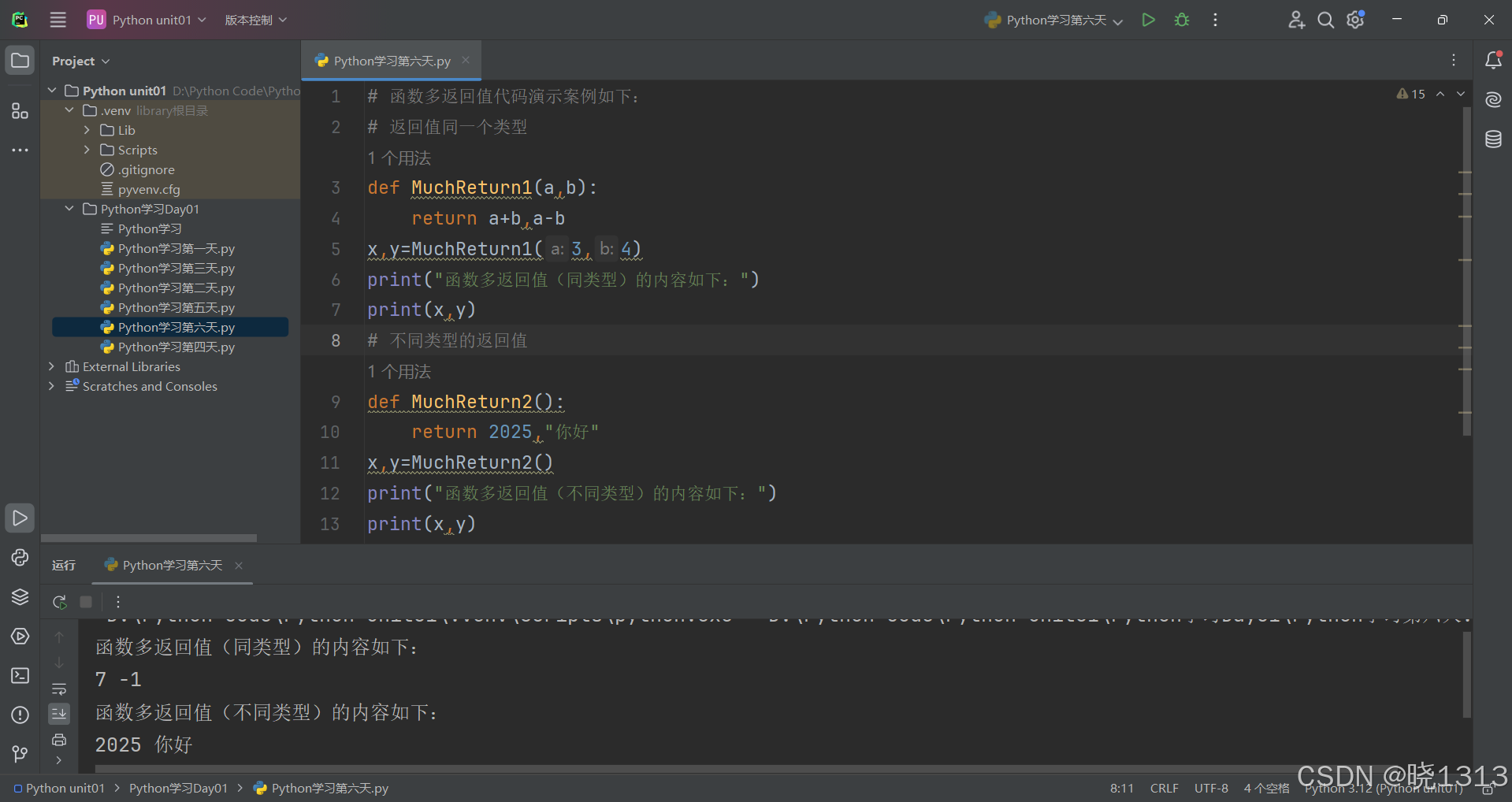
多函数返回值代码演示案例如下:
二.函数多种传参方式
函数多种常见的传参方式一共是4种分别为:位置参数、关键字参数、不定长参数、缺省参数
1.位置参数
位置参数:调用函数时根据函数定义的参数位置来传递参数

注意:传递的参数和定义的参数的顺序及个数必须一致
2.关键字参数
关键字参数:函数调用时通过“键=值”形式传递参数,
作用:可以让函数更加清晰、容易使用,同时也清除了参数的顺序需求

注意:函数调用时,如果有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序
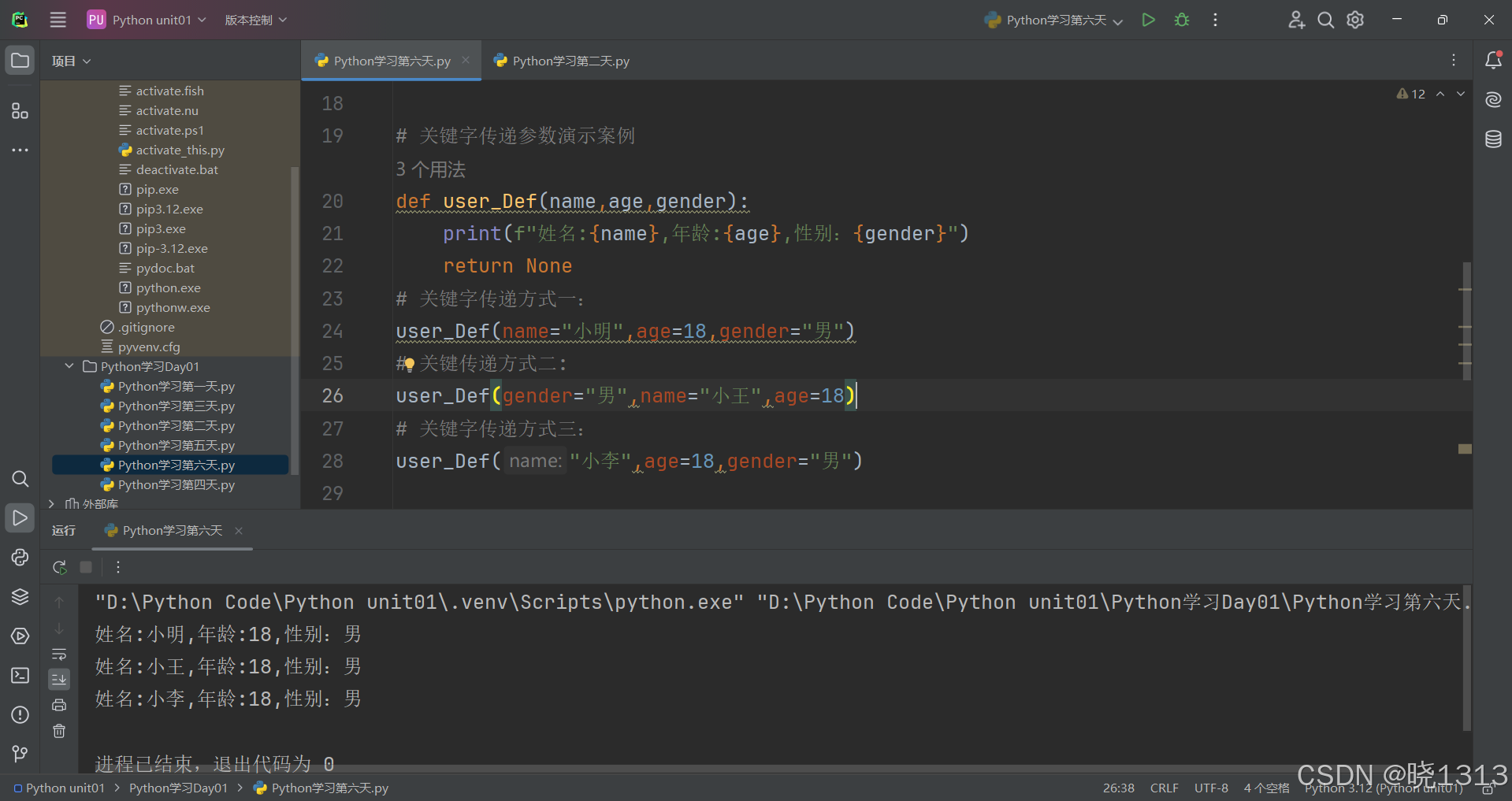
关键字参数演示代码如下:
3.缺省参数
缺省参数:缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值(注意:所有位置参数必须出现在默认参数前,包括函数定义和调用)
作用:当调用函数时没有传递参数,就会使用默认是用缺省参数对应的值。

注意:
函数调用时,如果为缺省参数传值则修改默认参数值,否则使用这个默认值
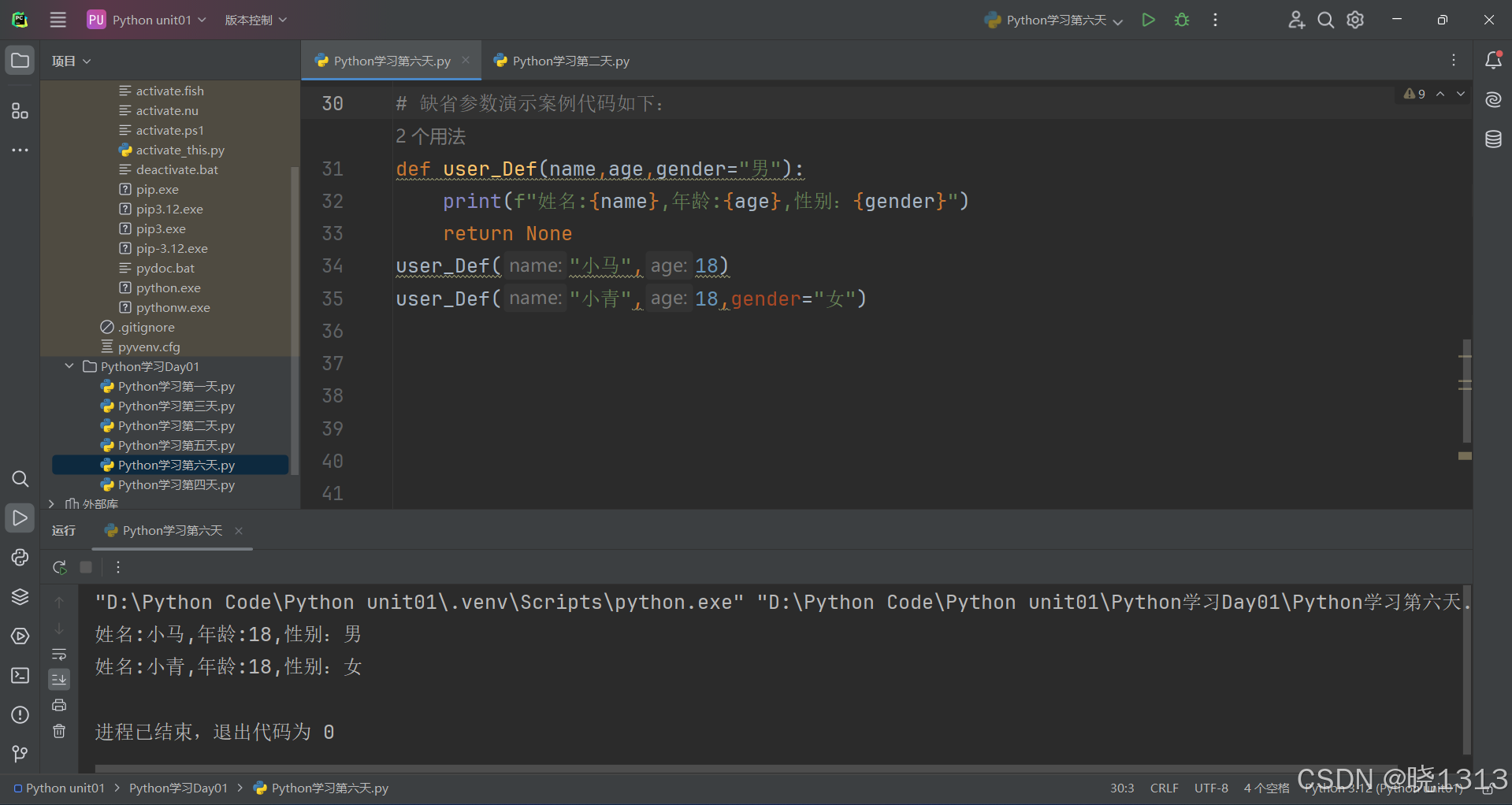
缺省参数演示代码如下:
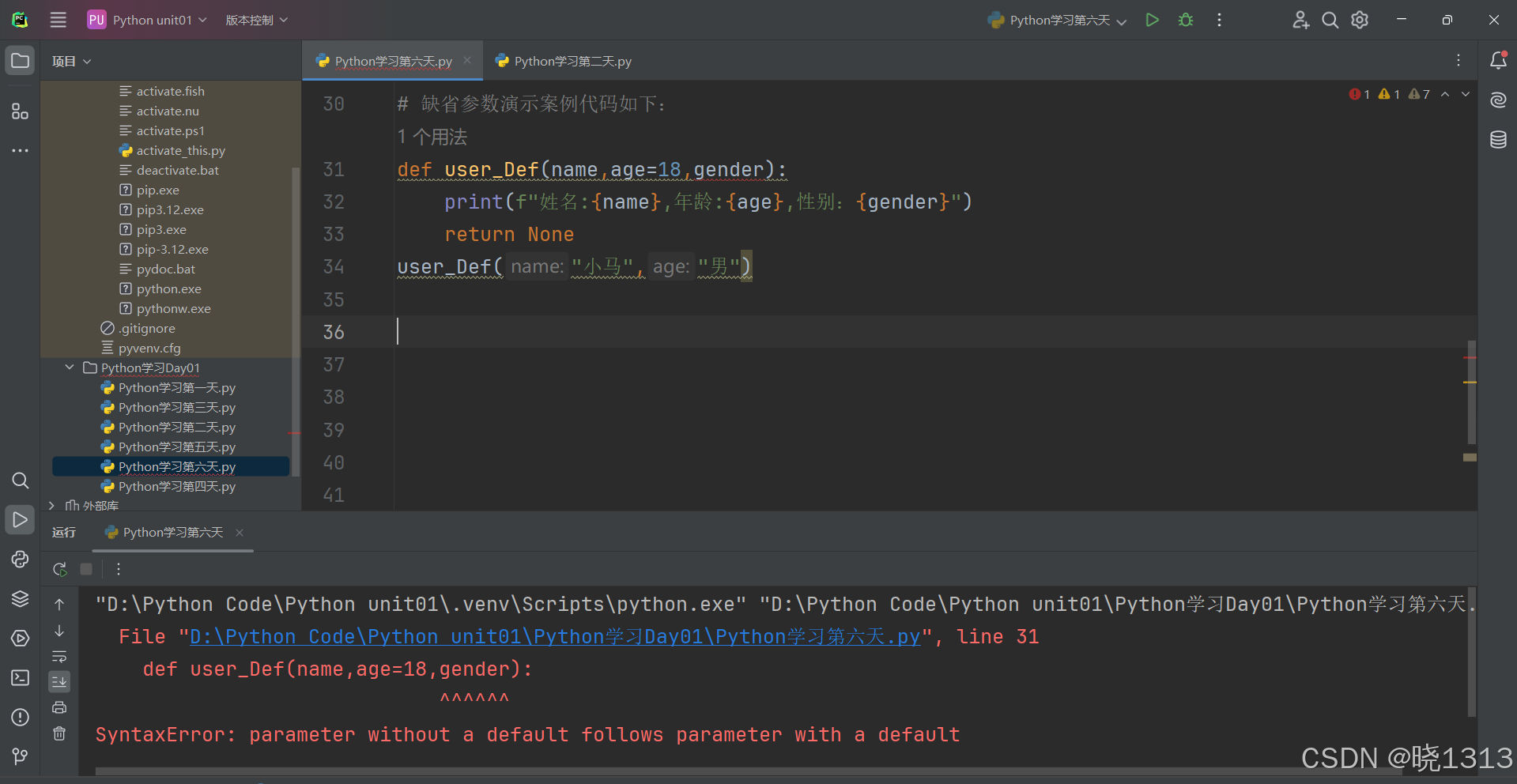
注:设置缺省参数必须是,末尾的位置开始设置,如果不是末尾设置则会报错。
4.不定长参数
不定长参数:不定长参数也叫可变参数,用于不确定调用的时候会传递多少个参数(不传参也可以)的场景.
作用:当调用函数时不确定参数个数时,可以使用不定长参数
不定长参数的类型:
- 位置传递
- 键字传递
(1)不定长参数——位置传递

注意:
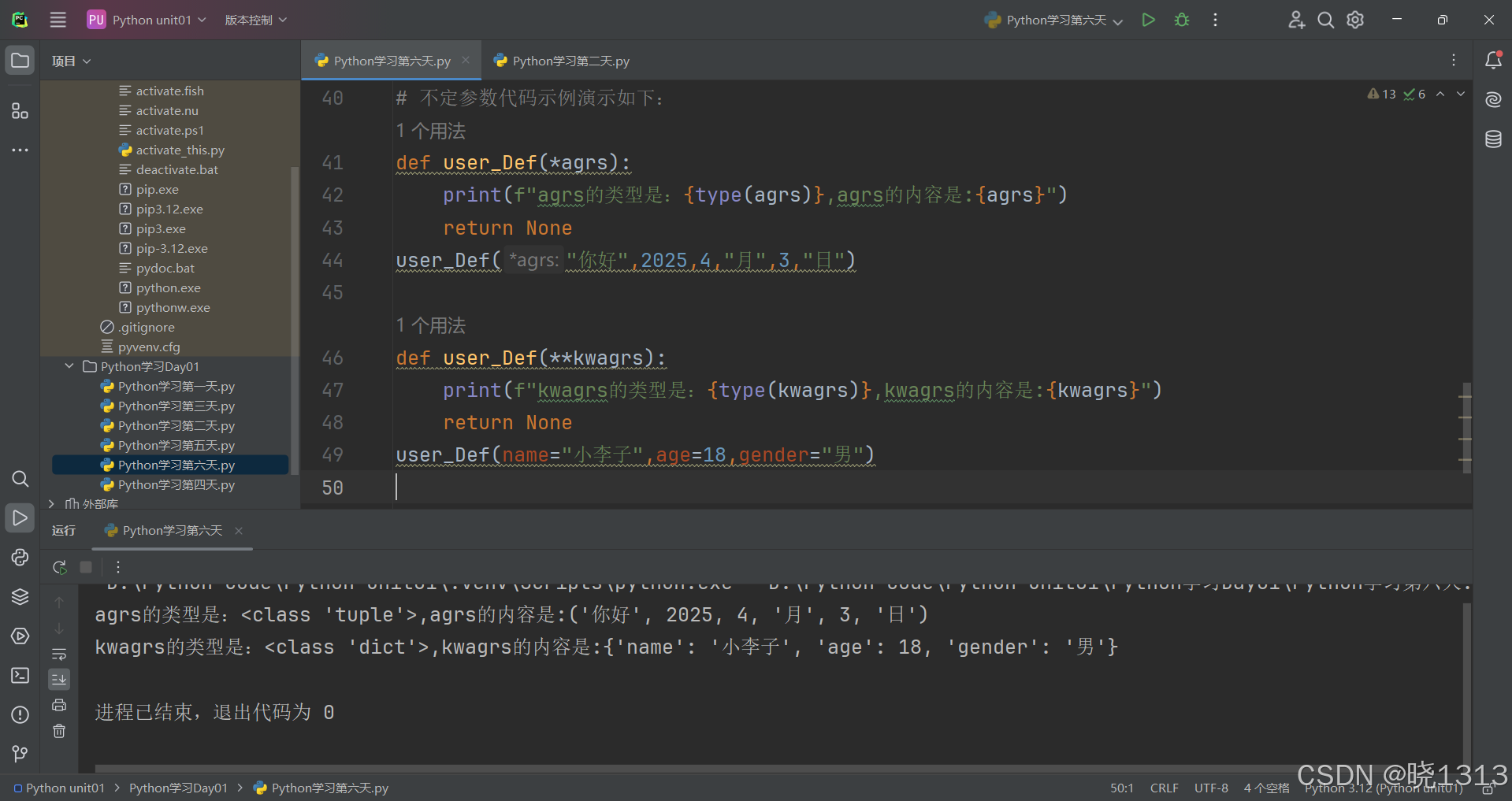
传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型,这就是位置传递
(2)不定长参数——关键字传递

注意:
参数是“键=值”形式的形式的情况下,所有的“键=值”都会被kwargs接受,同时会根据“键=值”组成字典.
不定长参数代码演示如下:
总结:
1.掌握位置参数
根据参数位置来传递参数
2.掌握关键字参数
通过“键=值”形式传递参数,可以不限参数顺序
可以和位置参数混用,位置参数需在前
3.掌握缺省参数
(1)不传递参数值时会使用默认的参数值
(2)默认值的参数必须定义在最后
4.掌握不定长参数
(1)位置不定长传递以*号标记一个形式参数,以元组的形式接受参数,形式参数一般命名为args
(2)关键字不定长传递以**号标记一个形式参数,以字典的形式接受参数,形式参数一般命名为kwargs
三.匿名函数
此小节分为:函数作为参数传递、Lambda匿名函数
(1)函数作为参数传递
在前面的函数学习中,我们一直使用的函数,都是接受数据作为参数传入:
- 数字
- 字符串
- 字典、列表、元组等
其实,我们学习的函数本身,也可以作为参数传入另一个函数内。
函数作为参数传递如下代码所示:

函数compute,作为参数,传入了test func函数中使用。
- test func需要一个函数作为参数传入,这个函数需要接收2个数字进行计算,计算逻辑由这个被传入函数决定
- compute函数接收2个数字对其进行计算,compute函数作为参数,传递给了test func函数使用
- 最终,在test func函数内部,由传入的compute函数,完成了对数字的计算操作
所以,这是一种,计算逻辑的传递,而非数据的传递。
就像上述代码那样,不仅仅是相加,相见、相除、等任何逻辑都可以自行定义并作为函数传入。
(2)lambda匿名函数
函数的定义中
- def关键字,可以定义带有名称的函数
- lambda关键字,可以定义匿名函数(无名称)
有名称的函数,可以基于名称重复使用。
无名称的匿名函数,只可临时使用一次。
匿名函数的定义语法如下:
![]()
- lambda 是关键字,表示定义匿名函数
- 传入参数表示匿名函数的形式参数,如:x,y表示接收2个形式参数
- 函数体,就是函数的执行逻辑,要注意:只能写一行,无法写多行代码
如下图代码,我们可以:
通过del关键字,定义一个函数,并传入,如下图:

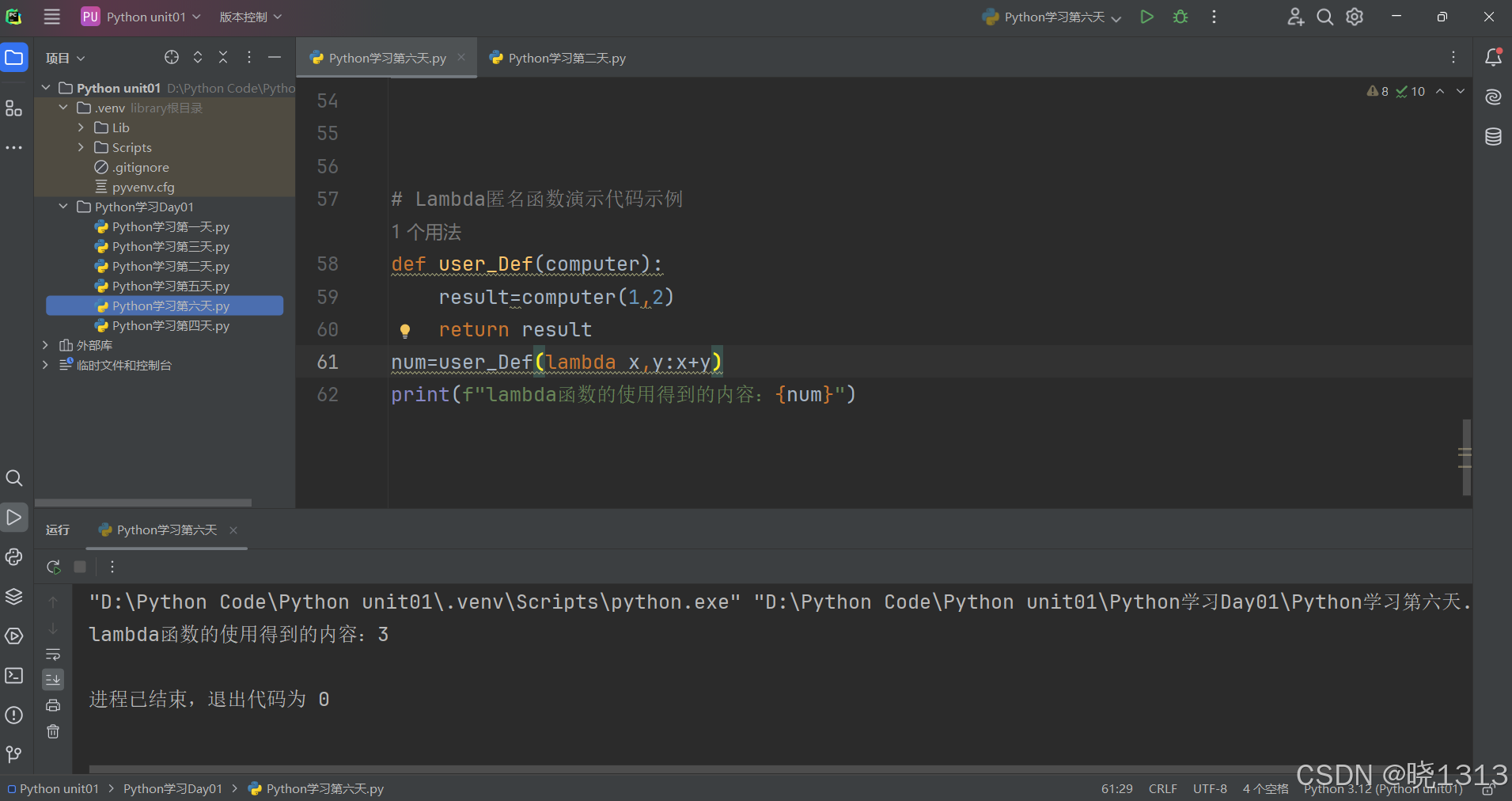
也可以通过lambda关键字,传入一个一次性使用的lambda匿名函数

使用def和使用lambda,定义的函数功能完全一致,只是lambda关键字定义的函数是匿名的,无法二次使用
lambda匿名函数的演示代码如下:
总结:
匿名函数使用“lambda”关键字进行定义
匿名函数的定义语法:![]()
匿名函数的注意事项:
- 匿名函数用于临时构建一个函数,只用一次的场景
- 匿名函数的定义中,函数体只能写一行代码,如果函数体要写多行代码,不可用lambda匿名函数,应使用def定义带名函数
四.文件
此章节主要讲解Python对于文件的操作。主要是:文件的编码、文件的读取、文件的写入、文件的追加。
(1)文件的编码
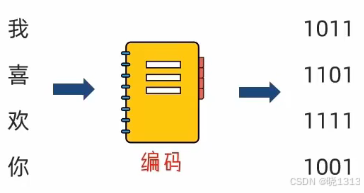
思考:计算机只能识别:0和1,那么我们丰富的文本文件是如何被计算机识别,并存储在硬盘中呢?
答案:使用编码技术(密码本)将内容翻译成0和1存入。
编码技术即:翻译的规则,记录了如何将内容翻译成二进制,以及如何将二进制翻译回可识别内容。
计算机中有许多可用编码:
- UTF-8
- GBK
- Big5
- 等
不同编码,将内容翻译成二进制也是不同的。
注:
编码有许多,所以要使用正确的编码,才能对文件进行正确的读写操作呢。

如上,如果你给喜欢的女孩发送文件,使用编码A进行编码(内容转二进制)女孩使用编码B打开文件进行解码(二进制反转回内容),这样会存在一些差异和错误。
查看文件编码的方法
我们可以使用Windows系统自带的记事本,打开文件后,即可看出文件的编码是什么:

从上图用记事本看的话在,在右下角有一个UTF-8代表文件所使用的格式。
UTF-8是目前全球通用的编码格式
除非有特殊需求,否则,一律以UTF-8格式进行文件编码即可。
总结:
1.什么是编码?
(1)编码就是一种规则集合,记录了内容和二进制间进行相互转换的逻辑。
(2)编码有许多中,我们最常用的是UTF-8编码
2.为什么需要使用编码?
(1)计算机只认识0和1,所以需要将内容翻译成0和1才能保存在计算机中。
(2)同时也需要编码,将计算机保存的0和1,反向翻译回可以识别的内容。
五.文件的读取
文件的概念:内存中存放的数据在计算机关机后就会消失。要长久保存数据,就要使用硬盘、光盘、U盘等设备。为了便于数据的管理和检索,引入了“文件”的概念。
一篇文章、一段视频、一个可执行程序,都可以被保存为一个文件,并赋予一个文件名。操作系统以文件为单位管理磁
盘中的数据。一般来说,文件可分为文本文件、视频文件、音频文件、图像文件、可执行文件等多种类别。
日常对文件的操作主要包含:打开、关闭、读、写等操作
Python中对文件的操作步骤:
(1)打开文件
(2)读写文件
(3)关闭文件
注意:可以只打开和关闭文件,不进行任何读写
1.open()打开函数
在Python,使用open函数,可以打开一个已经存在的文件或者创建一个新文件,语法如下:

示例代码:

注意:此时的`f` 是 `open `函数的文件对象,对象是Python中一种特殊的数据类型,拥有属性和方法,可以使用对象.属性或对象.方法对其进行访问,后续面向对象课程会给大家进行详细的介绍。
mode常用的三种基础访问模式

读操作相关方法
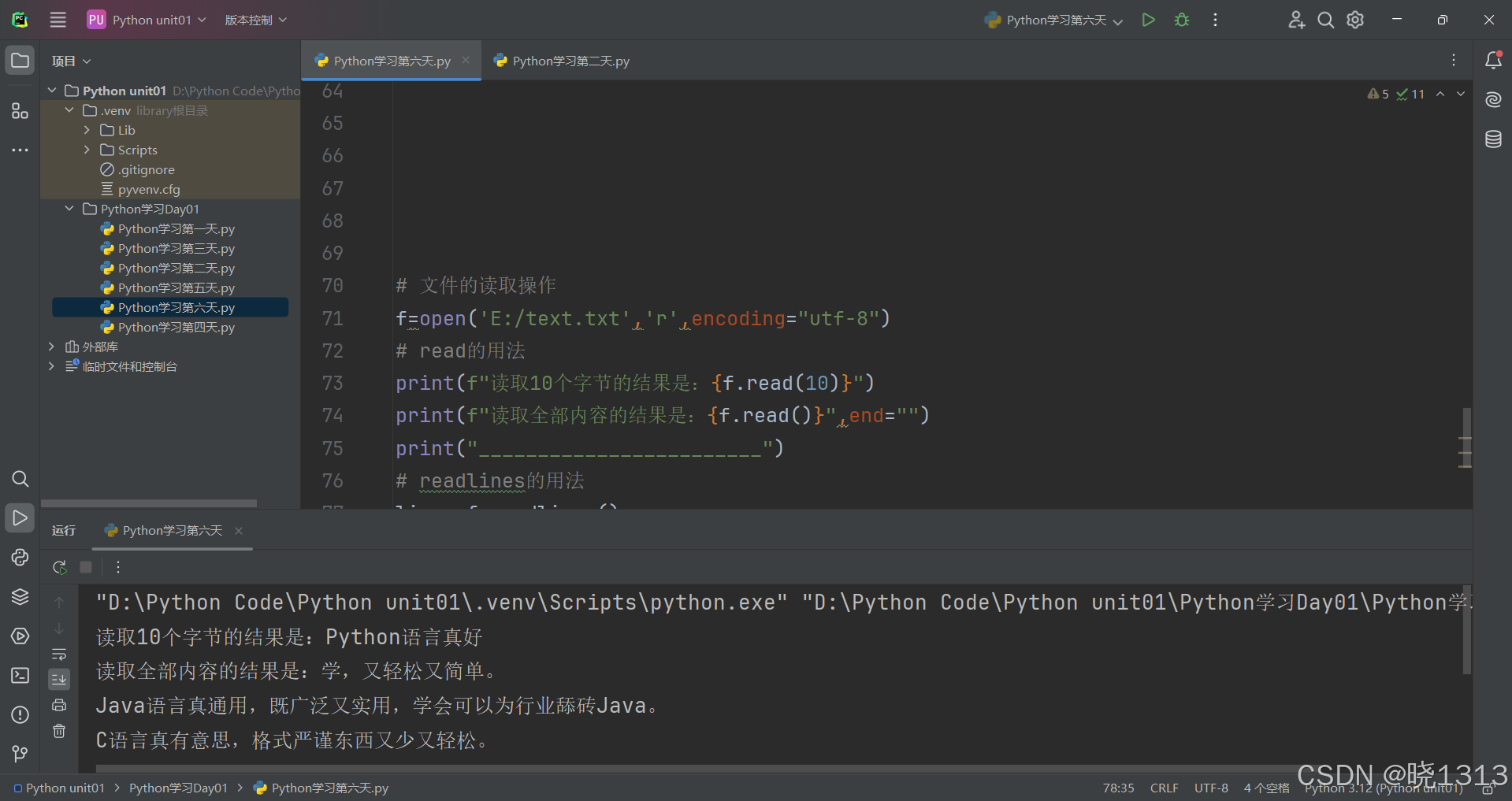
2.read()方法

num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据。
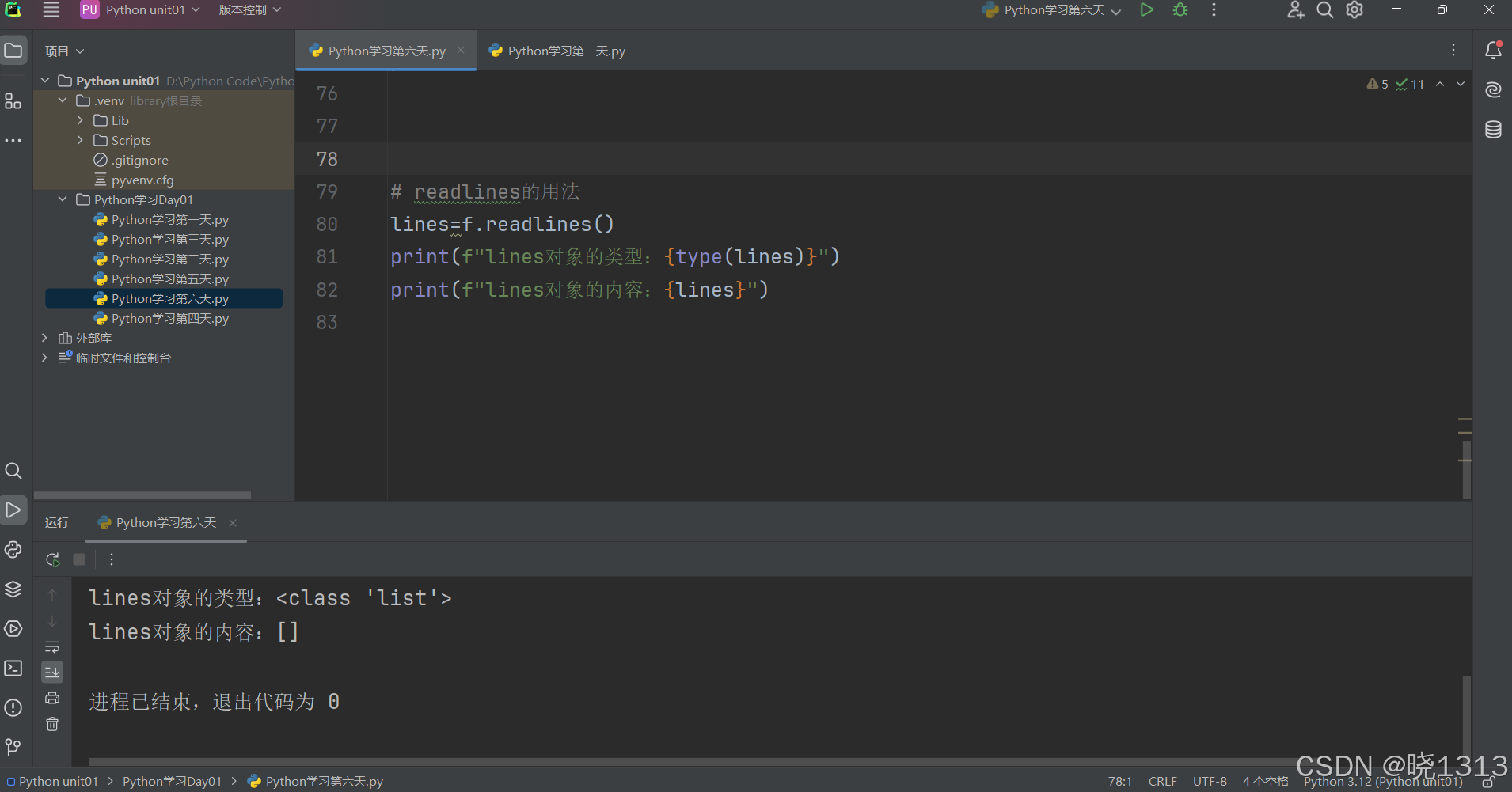
3.readlines()方法
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个
元素。
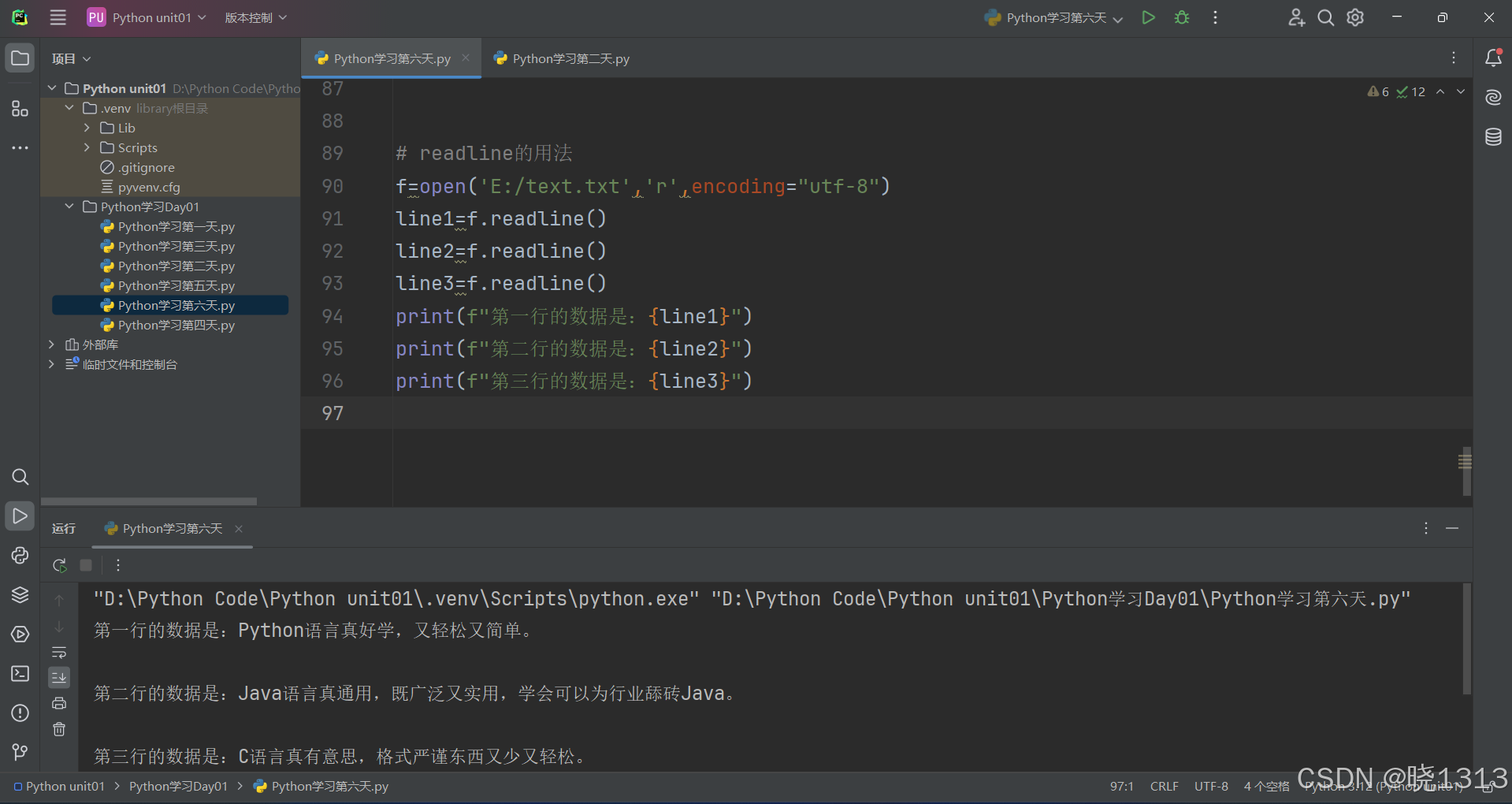
4.readline()方法
readline方法可以一次读取一行内容
文件的读取演示案例代码如下:
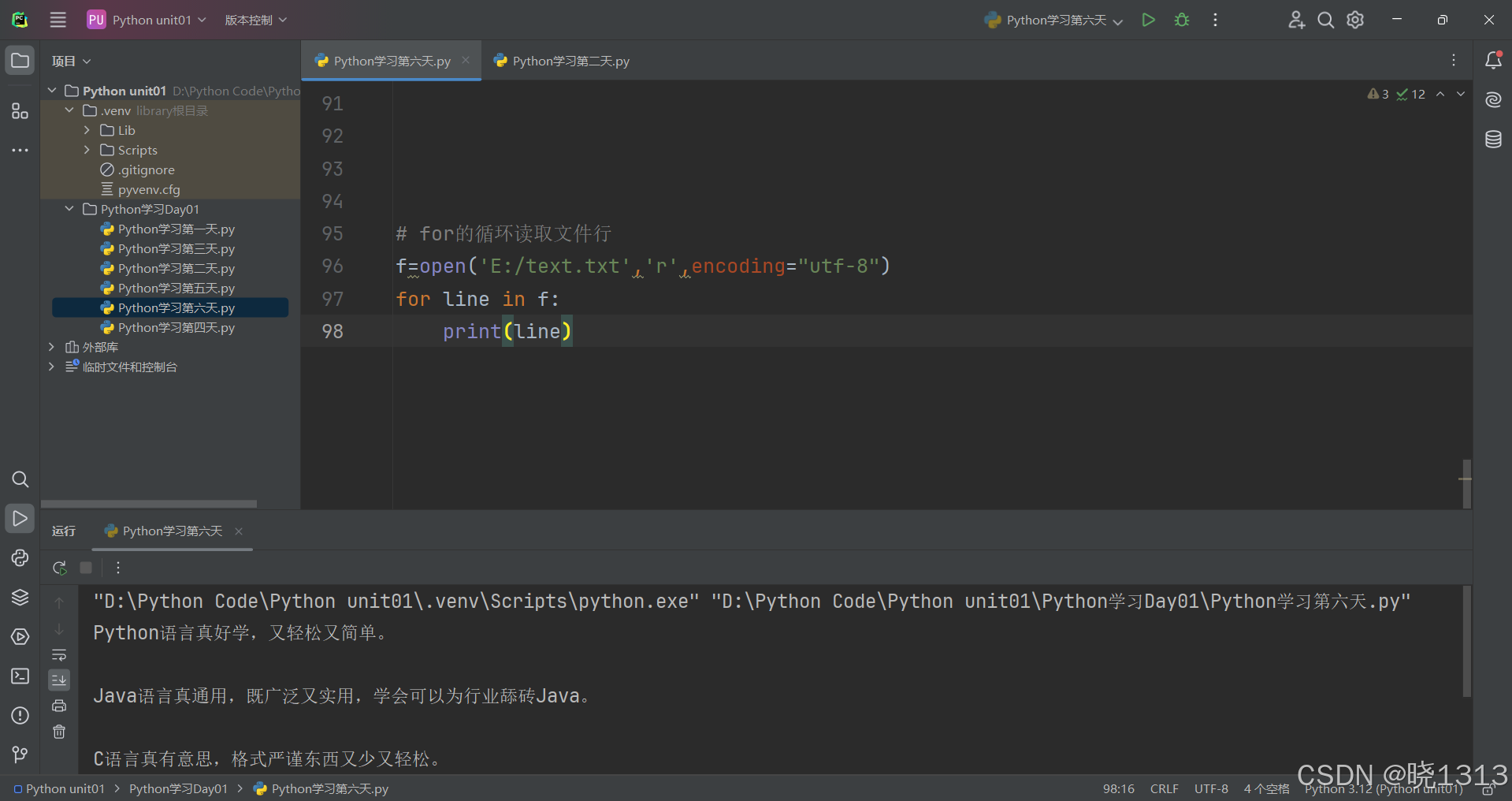
5.for循环读取文件行
for循环读取文件行的演示代码如下:
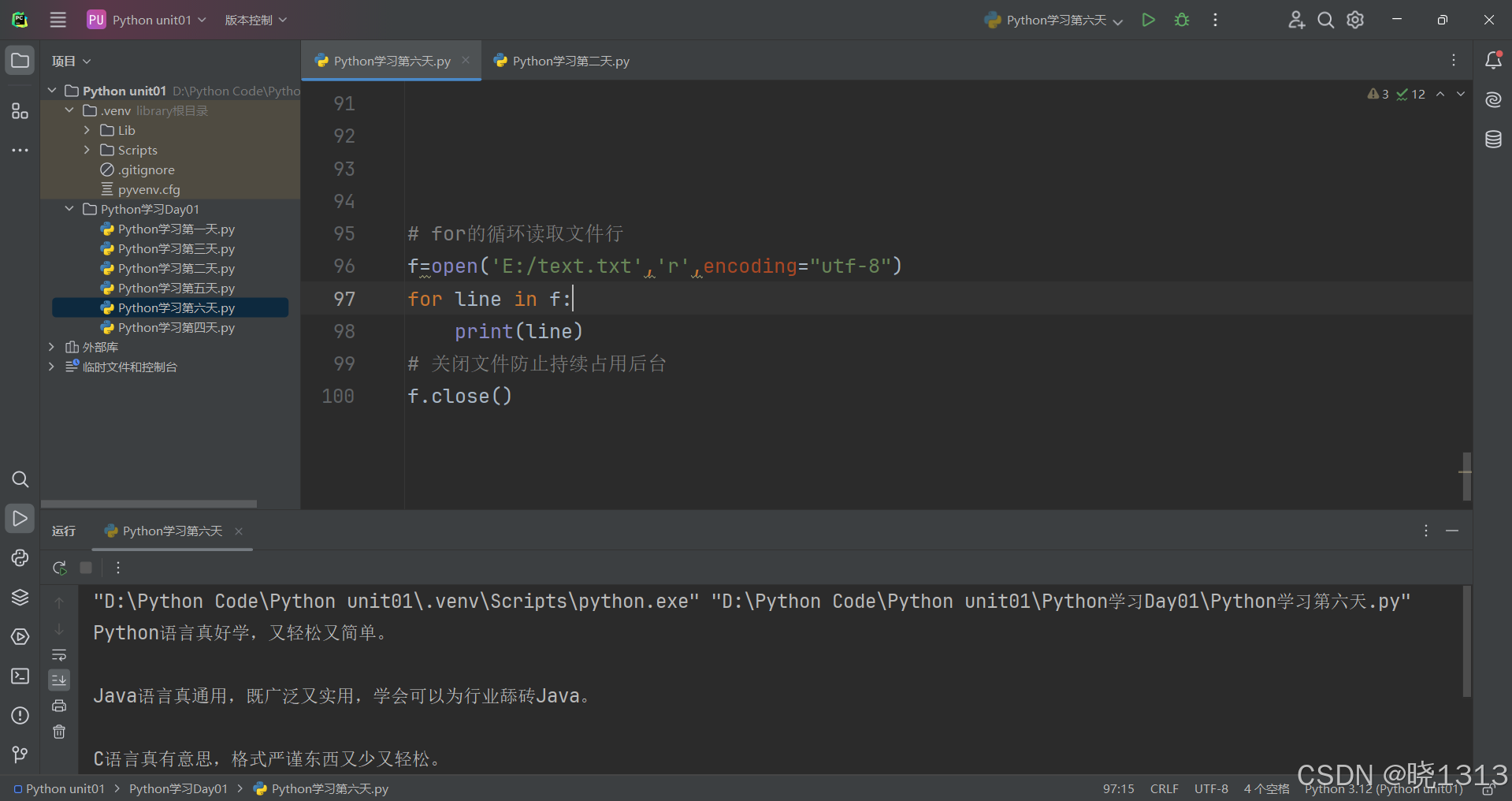
6.close()关闭文件对象
格式:文件对象.close()
关闭文件对象演示代码如下:
7.with open语句

with open语句的演示代码如下:
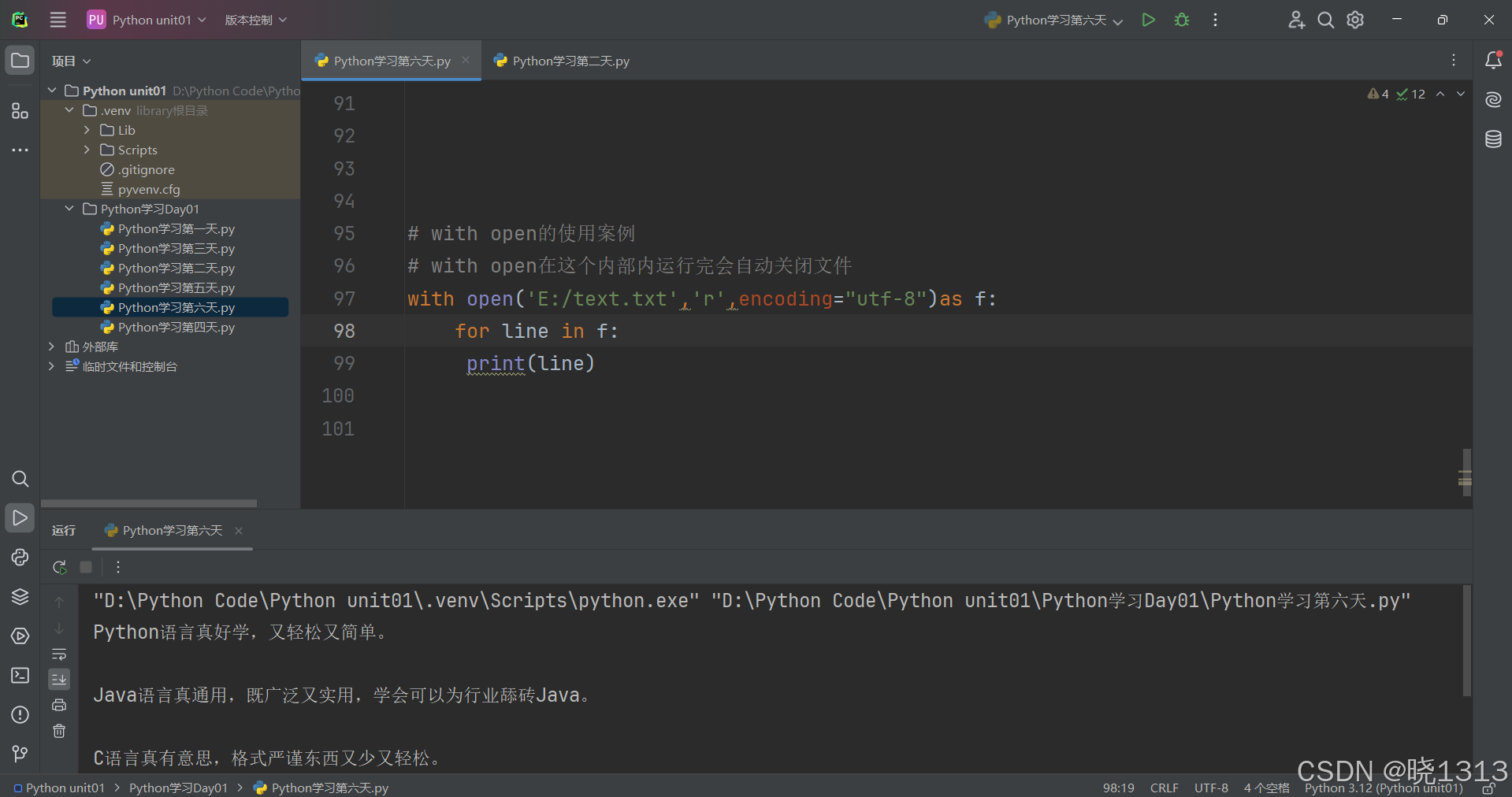
总结:

1.操作文件需要通过ppen函数打开文件得到文件对象
2.文件对象有如下读取方法
- read()
- readline()
- readlines()
- for line in 文件对象
3.文件读取完成后,要使用文件对象.close()方法关闭
文件对象,否则文件会被一直占用。
六.文件的写入
文件的写操作快速入门
案例演示:

注意:
- 直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
- 当调用flush的时候,内容会真正写入文件
- 这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)
文件写入的代码演示如下:
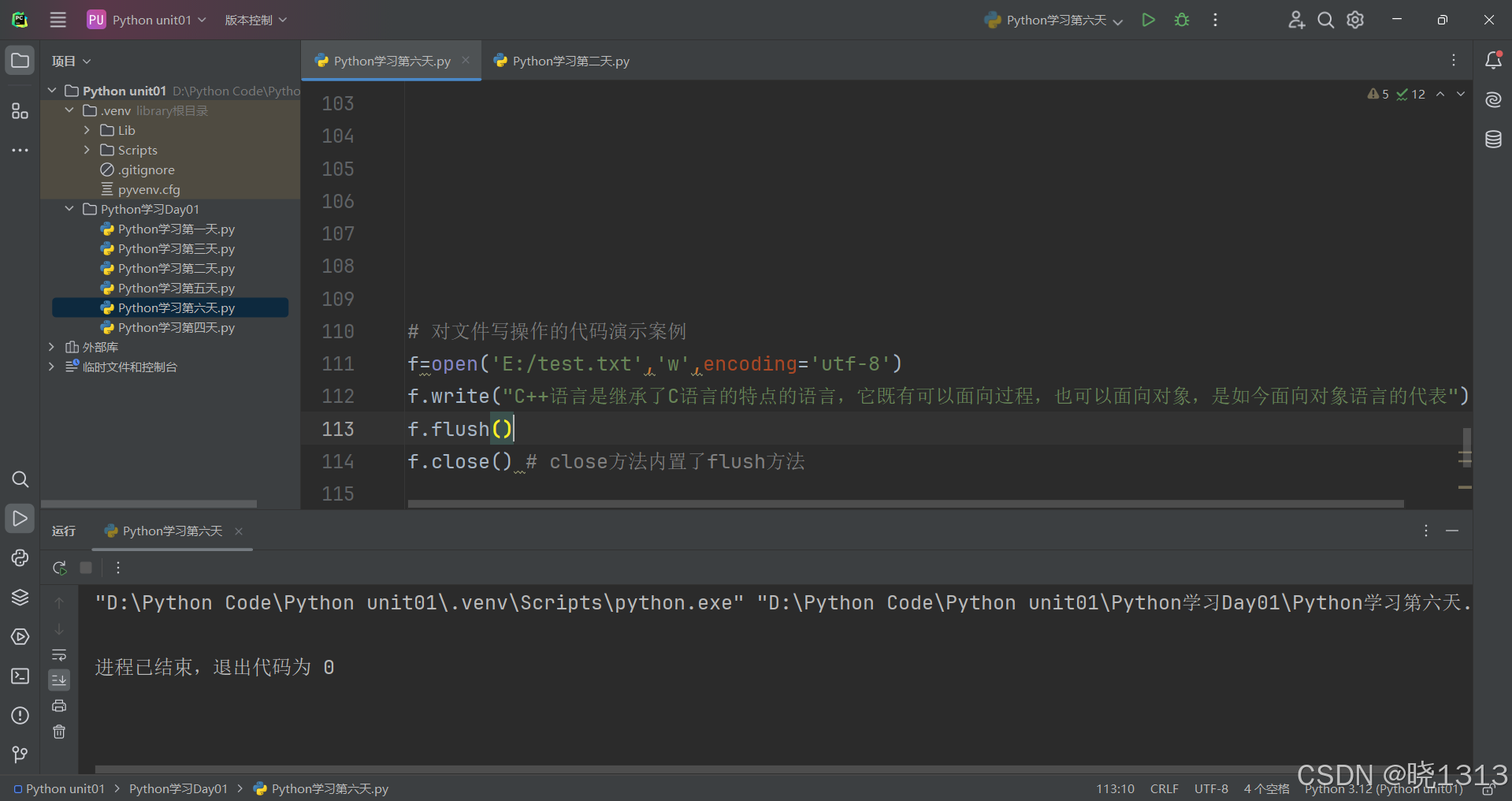
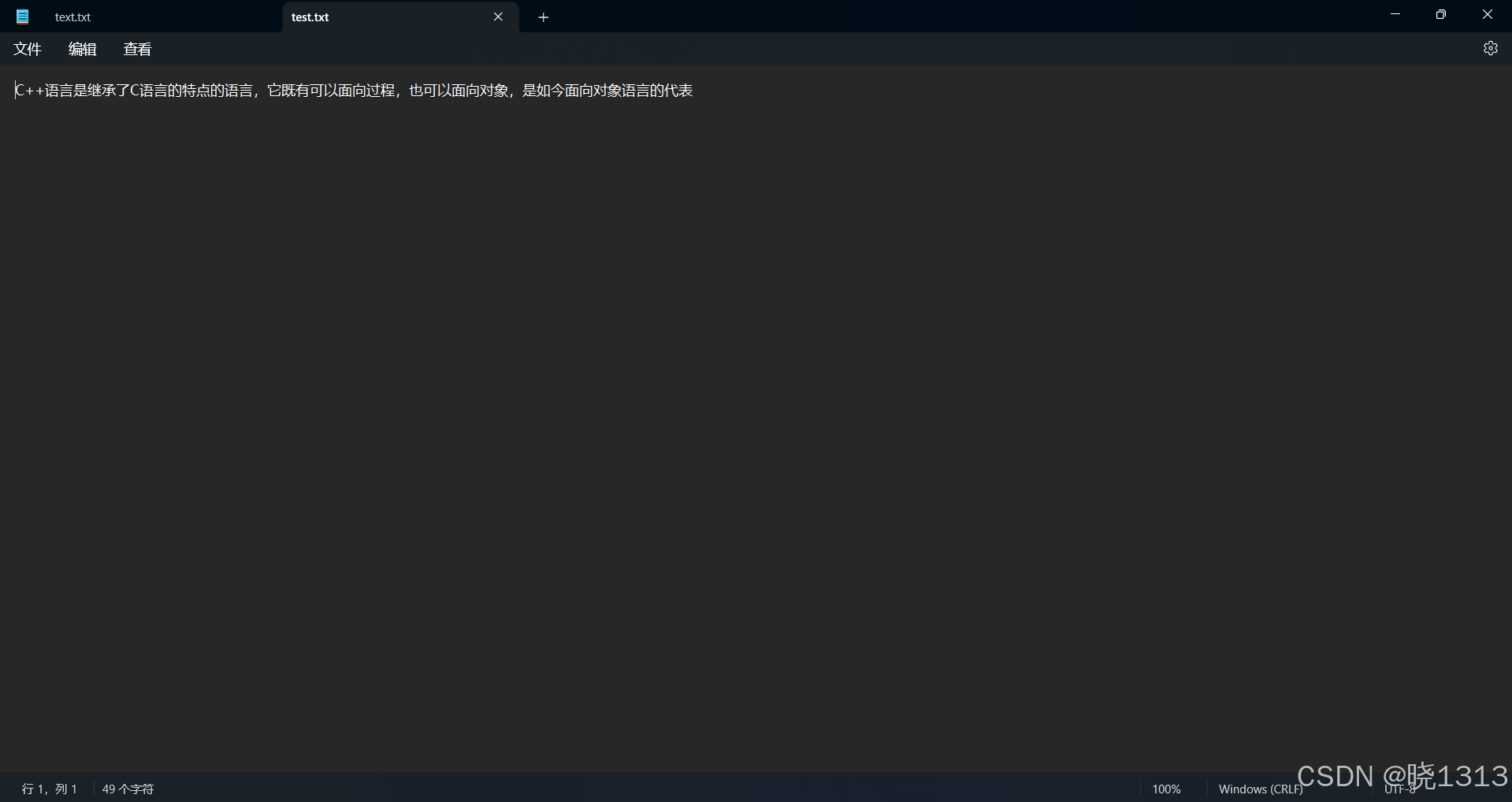
总结:
1.写入文件使用open函数的”w”模式进行写入
2.写入的方法有:
- wirte(),写入内容
- flush(),刷新内容到硬盘中
3.注意事项
- w模式,文件不存在,会创建新文件
- w模式,文件存在,会清空原有内容
- close()方法,带有flush()方法的功能
七.文件的追加
追加写入操作快速入门
案例演示:

注意:
- a模式,文件不存在会创建文件
- a模式,文件存在会在最后,追如写入文件
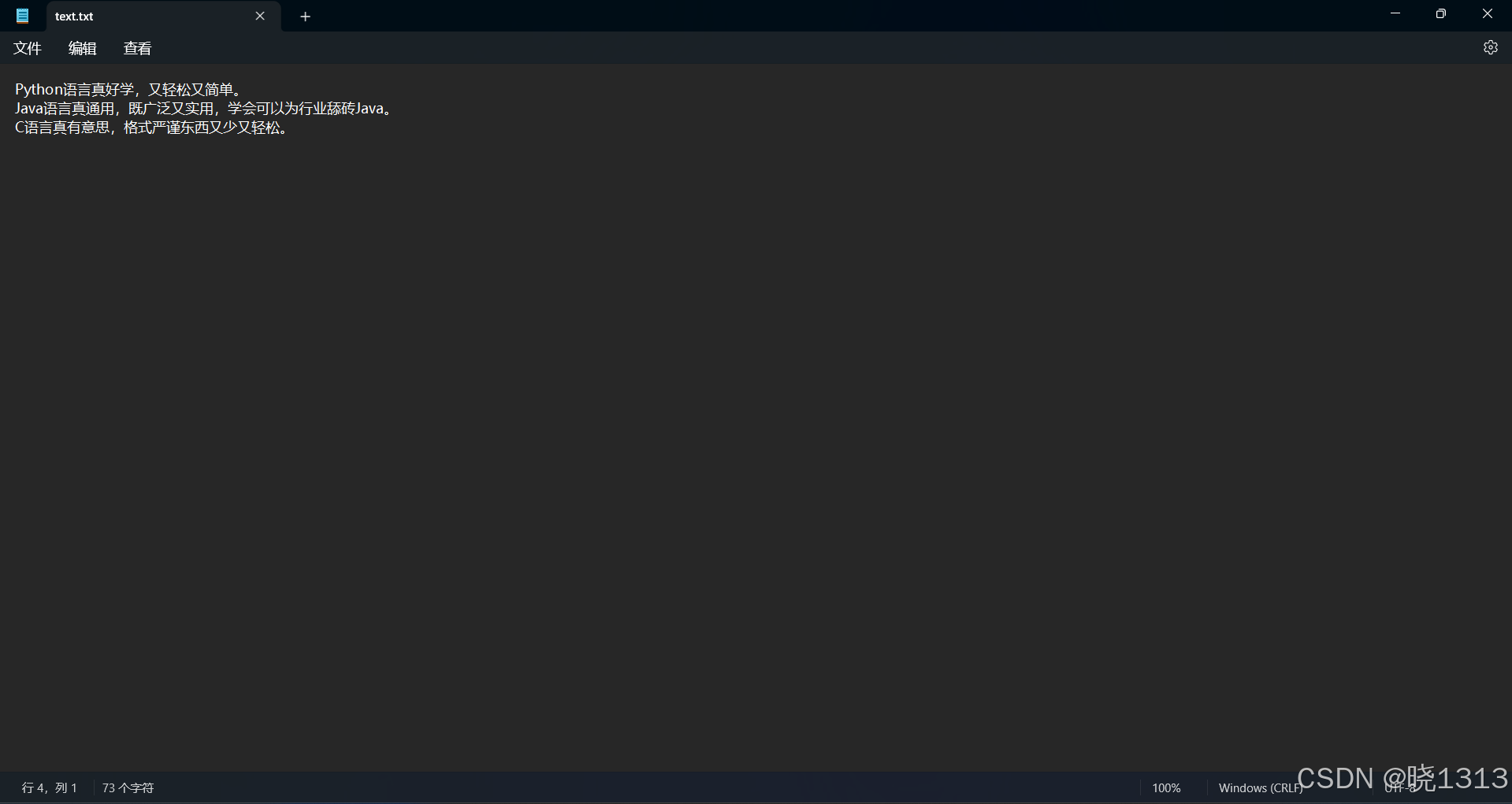
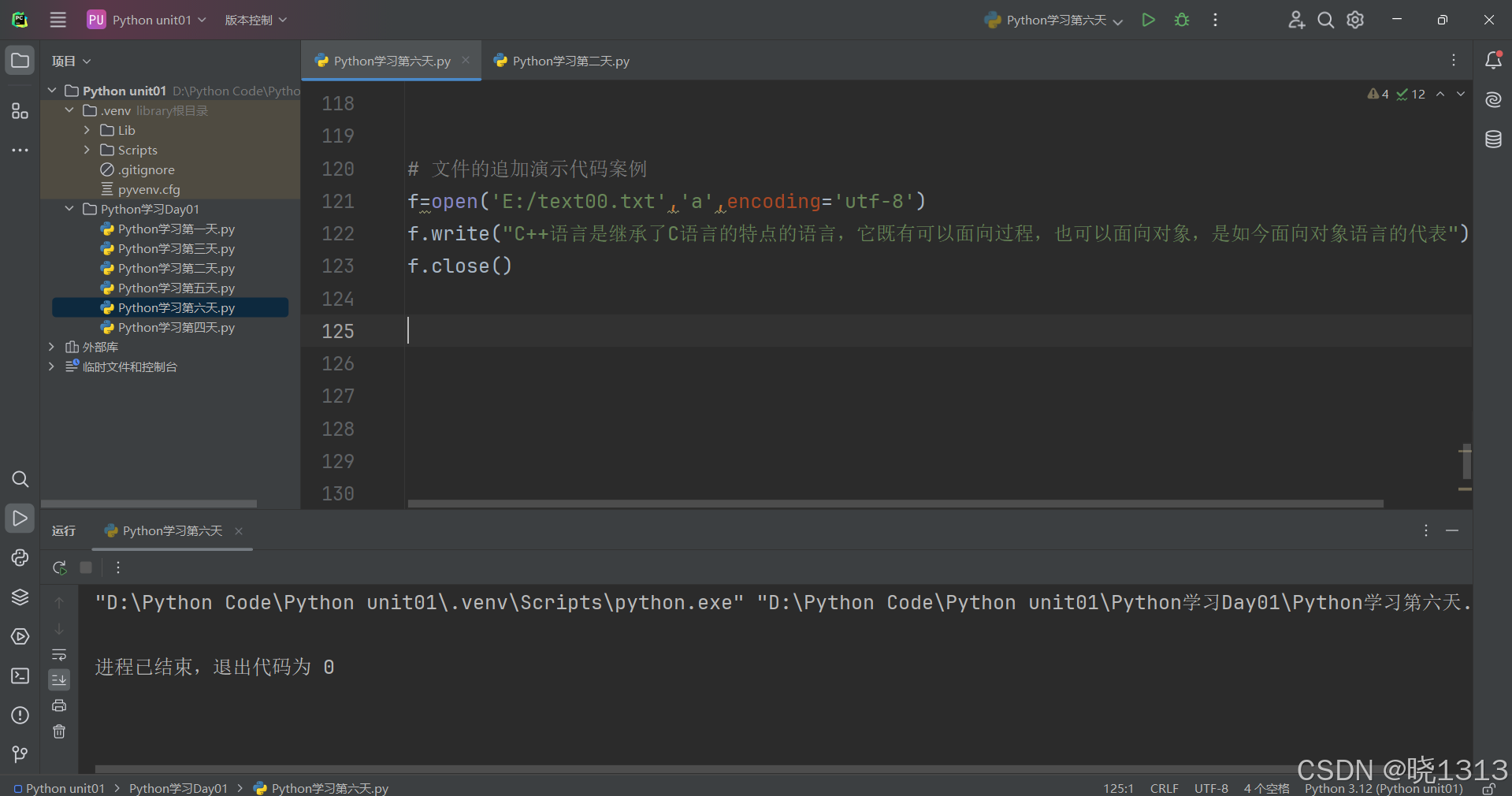
文件追加代码演示如下:
文件存在,使用追加。
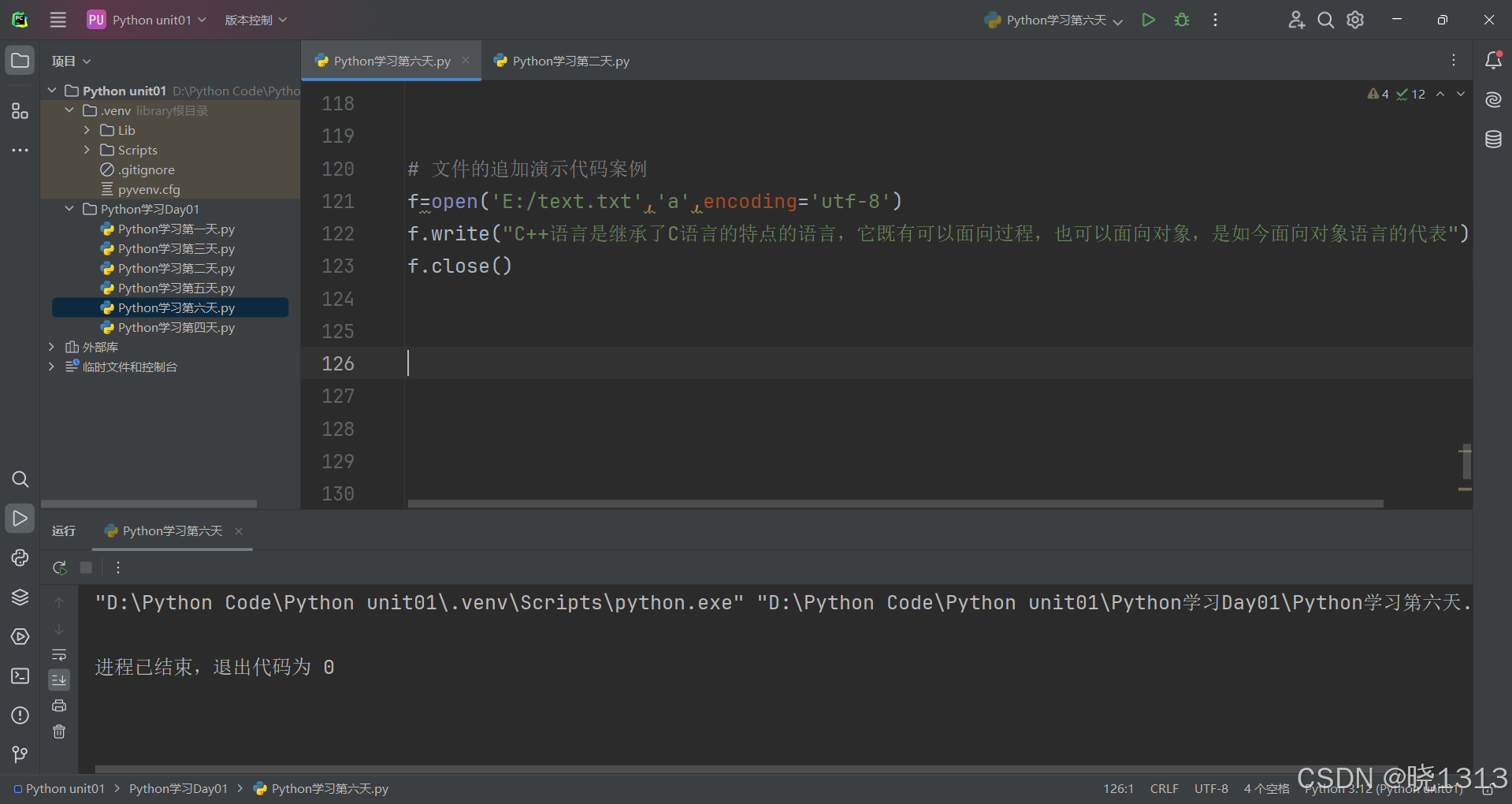
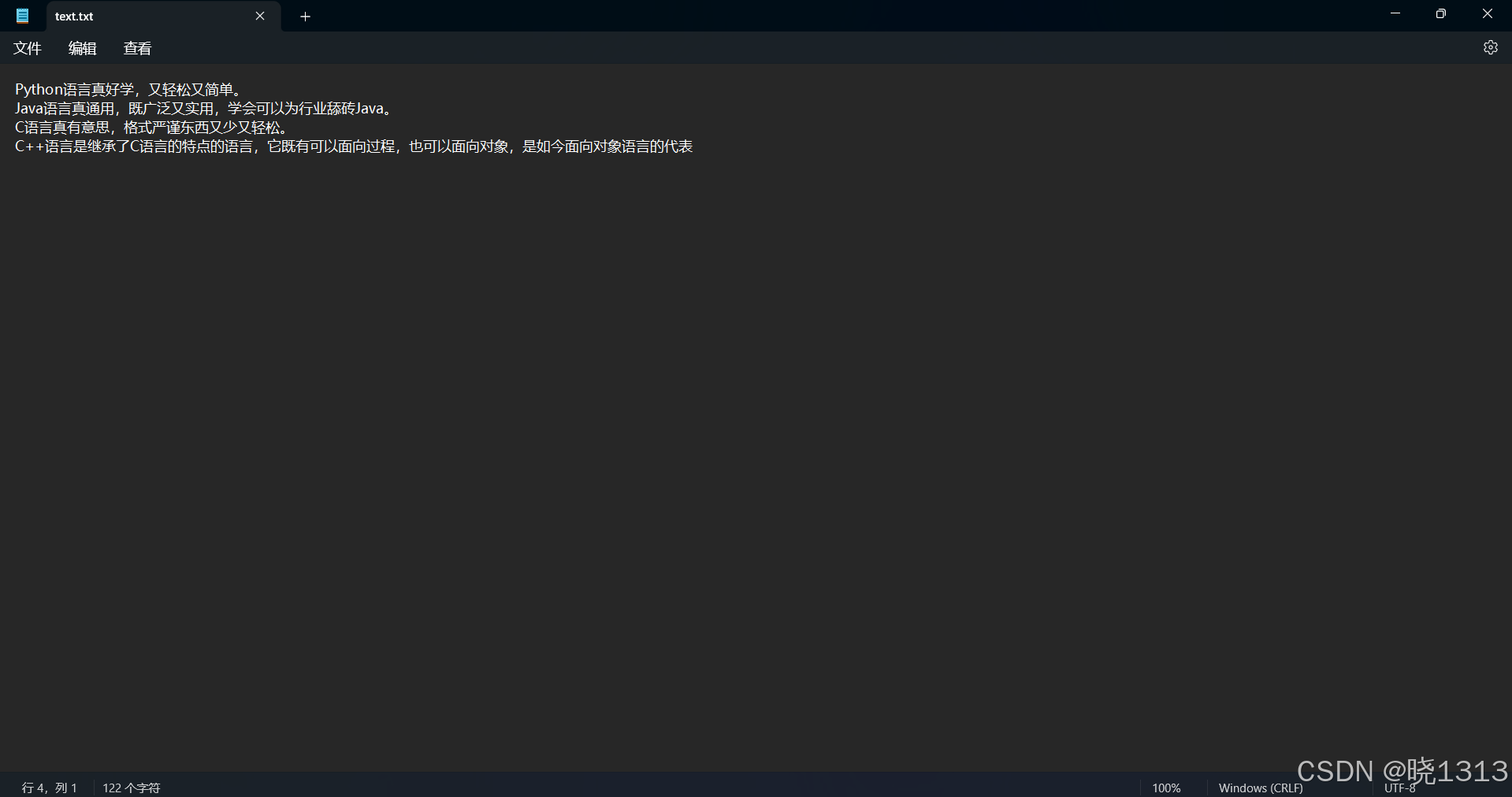
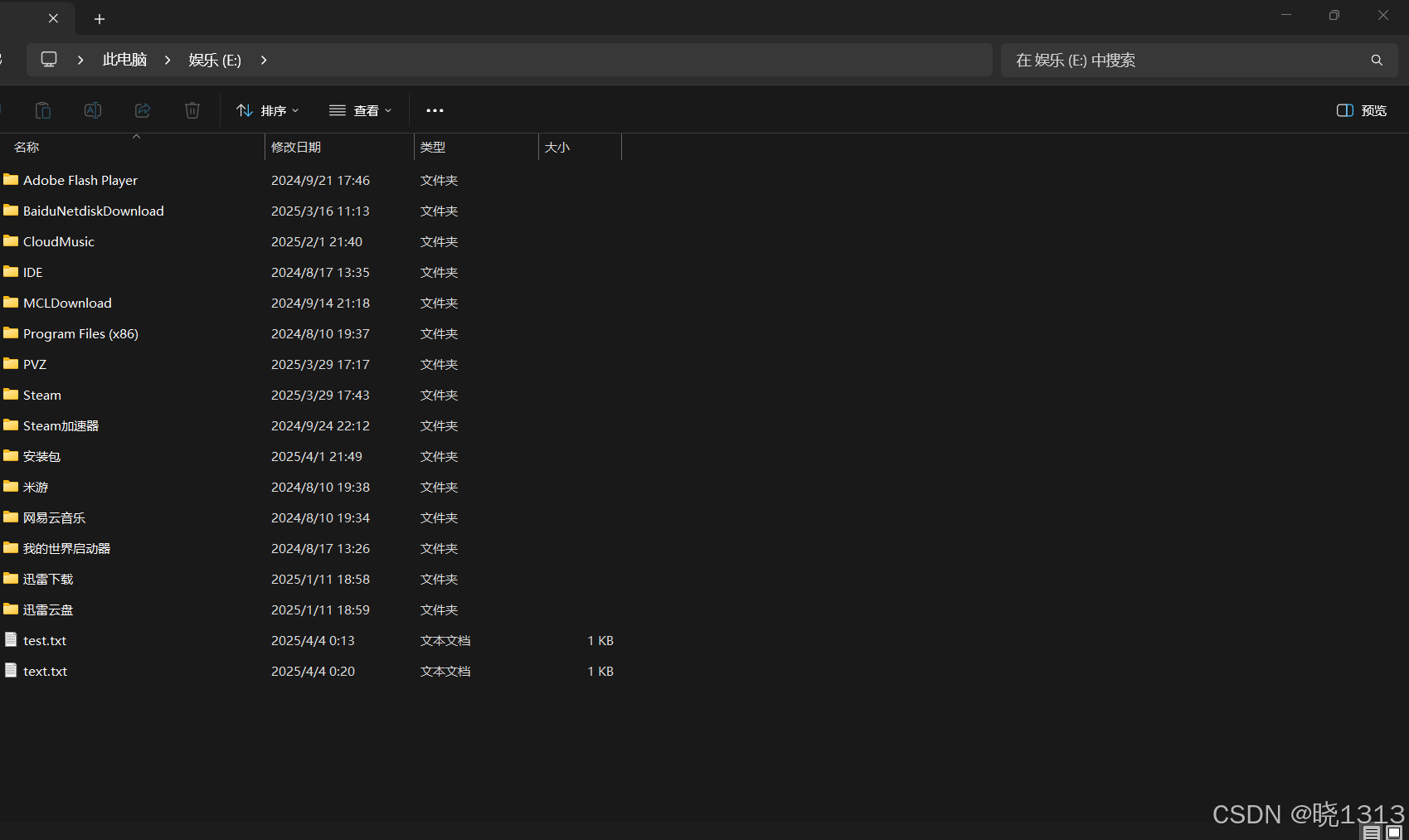
文件不存在的追加演示
总结:
1.追加写入文件使用open函数的”a”模式进行写入
2.追加写入的方法有(和w模式一致):
- wirte(),写入内容
- flush(),刷新内容到硬盘中
3.注意事项
- a模式,文件不存在,会创建新文件
- a模式,文件存在,会在原有内容后面继续写入
- 可以使用”\n”来写出换行符