LLM入门课程#01
大语言模型与生成式模型介绍
非常经典的一篇论文你需要进行了解。
Attention is all you need。
基础模型,也可以称为基本模型,一个模型拥有的参数越多,记忆越复杂,他能完成的任务也就越多。但是站在25年的观点来看,目前的数据已经基本饱和,如何去构造一个有效的模型也显得非常重要。目前的基础模型包含了很多,包含BERT、GPT、QWen或者是LLAma。这节课程中主要说明了我们的模型是如何在自然语言处理中来应用的。这些内容设计的代码主要通过API来进行开发。
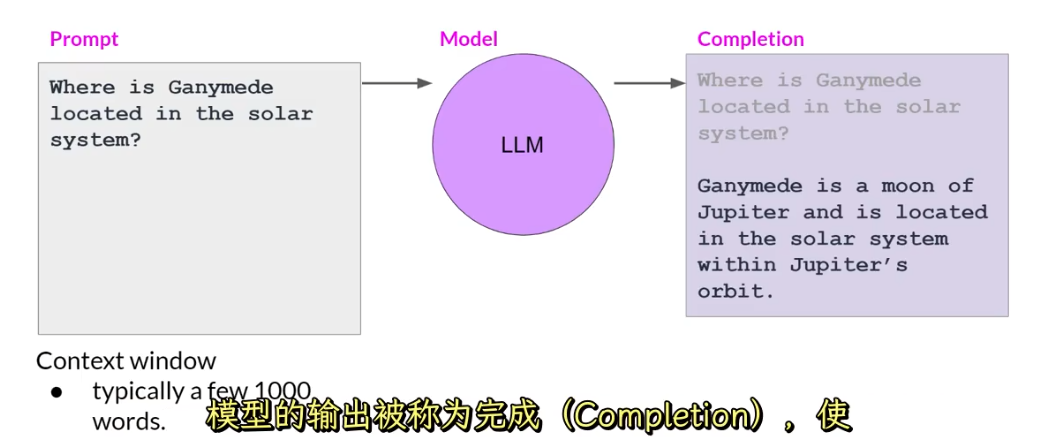
传递给大语言模型的指令文本称为prompt,prompt可以使用的空间以及记忆称为上下文窗口,通常可以放下几千的字,每个模型不同。
他们的基础是Next word prediction。给定一个文本去总结。给定一个文本去翻译。给定一个文本去预测代码。实体解读,给定文本识别其中的实词。将大模型和外部的数据进行结合,不需要进行训练就可以应用。
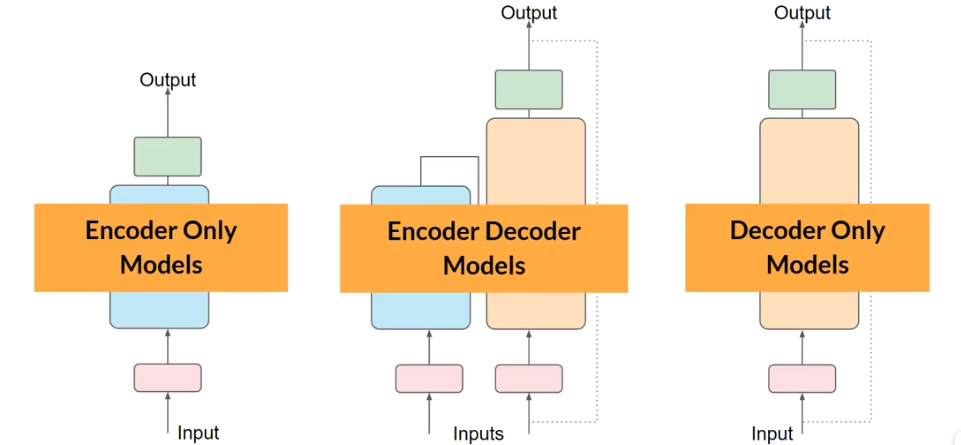
早期的神经网络结构RNN就是用来进行生成任务的。扩大RNN的规模,看到上下文之后,来进行预测。句子本身是存在歧义的。2017年的文章attention is all you need中提出重要的观点。学习每个单词之间的关系,全局的注意力。学习当前单词和其他单词之间的关系。整个模型分为encoder和decoder两个部分。
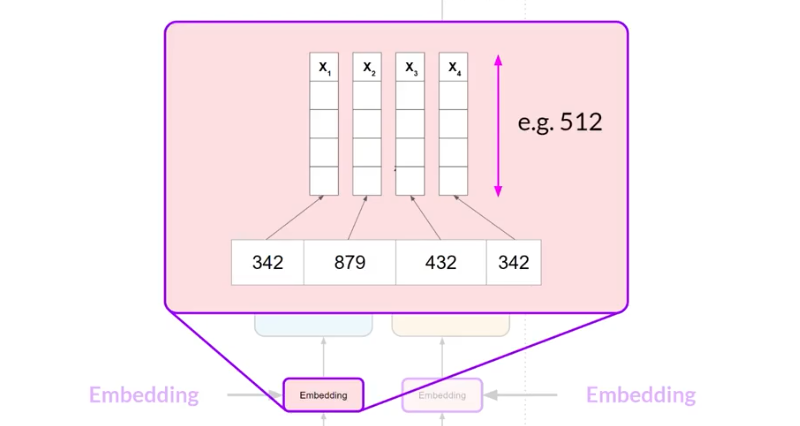
机器学习的模型是一个大型的统计计算器,处理的是数字,不是单词,所以要做的事情是将单词以数字的形式来进行表示,也就是分词。你的输入和输出需要保持一致的分词器。

一个经典的分词器是word2vec,也就是将单词处理为向量的形式。这个向量大概是可以衡量单词特征的,比如绿茶和红茶的相似度就会高一些,但是对于绿茶和可乐的相似度就会小一些,通过这种词向量的方式可以把他们映射在一个空间中,你会发现相似的单词总是在一起的。
除此之外,为了不丧失单词的顺序,这个时候还会在网络中添加绝对位置编码,绝对位置的编码将会和单词的编码结合在一起,一起作为下面自注意力层的输入。
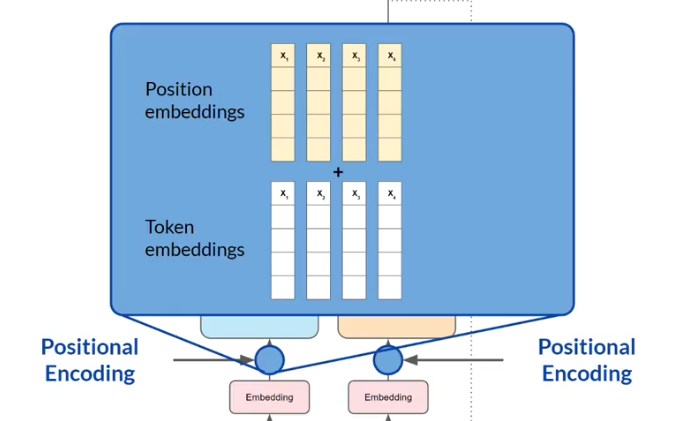
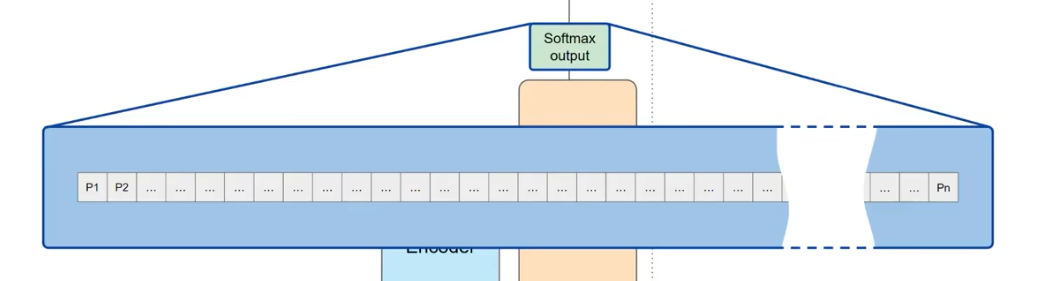
自注意力层中学习每个单词和其他单词的关联,但是为了让他更加强大,他的中间将会由多头自注意力来进行实现。多组自注意力进行并行的学习。头的数量根据模型来进行决定,一般情况下,这个模型的范围是在12-100之间。注意力计算后的数据通过一个全连接的前向网络,将会传递给最后的softmax层,在softmax层中,他们被归一化为每个单词的概率分数。注意这里的分数不是这个句子中单词所对应的概率值,这里的分数指的是整个词汇表中所对应单词的概率值,所以最后这个输出他超级无敌长。
对于一个翻译的任务来说,有点像是通过递归的形式来进行生成的。模型会首先将原始的句子进行分词和向量化,经过处理之后转化为对应第一个词的输出,第一个词重新反馈到模型的decoder中,再产生到第二个词中,直到整个过程结束。
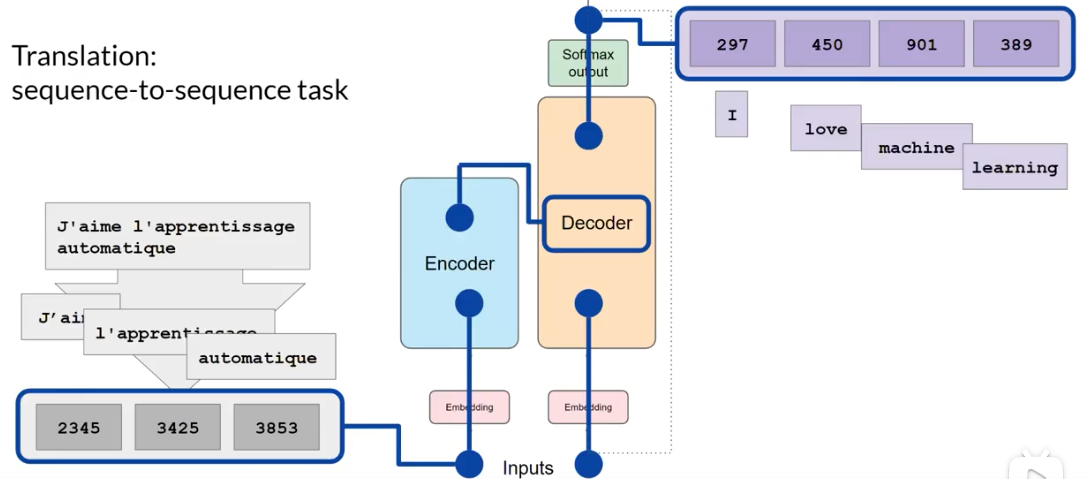
将这些组件分开之后,也可以进行不同的任务。只使用encoder可以用来分类的任务上,encoder-decoder模型可以使用在翻译或者是文本生成的任务上。只使用decoder模型也有很强的能力,比如GPT、Bloom和LLama。